Comparativa: Fortunata y Jacinta contra Fortunata y Jacinta lematizada
Índice
Información General
| Título: | Fortunata y Jacinta |
|---|
| Autor: | Benito Pérez Galdós |
|---|
| Idioma: | Castellano |
|---|
| #Palabras total: | 394672 |
|---|
| #Palabras distintas: | 29367 |
|---|
| Type-Token ratio: | 7.44% |
|---|
|
| Título: | Fortunata y Jacinta (lematizado) |
|---|
| Autor: | Benito Pérez Galdós (lematizado) |
|---|
| Idioma: | Castellano (lematizado) |
|---|
| #Palabras total: | 393844 |
|---|
| #Palabras distintas: | 13855 |
|---|
| Type-Token ratio: | 3.52% |
|---|
|
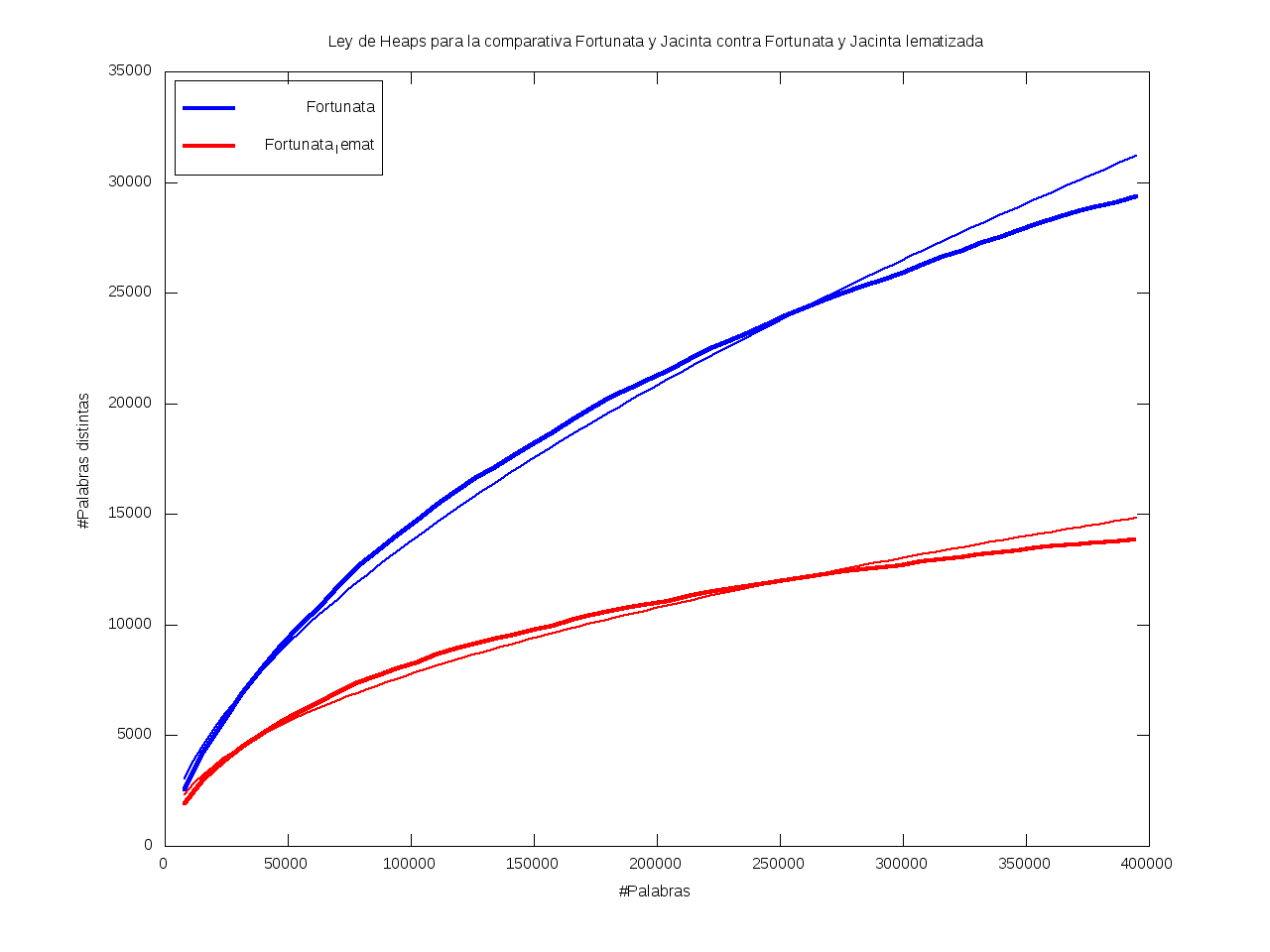
Ley de Heaps - Saturación léxica
La Ley de Heaps es una ley empírica que predice el tamaño del vocabulario dado un texto.
Esto es, nos da una estimación del número de palabras distintas (v) dado el número total de palabras (n) de que consta el texto,
según la fórmula
v = K*n^b
donde b está entre 0 y 1 (habitualmente entre 0.4 y 0.6)
y K es una cierta constante, habitualmente entre 10 y 100.
En particular, mayores valores de b se corresponden con vocabularios más grandes,
en el sentido de que aumentan rápidamente;
mientras que se tienen valores menores de b cuando casi todo el vocabulario aparece al principio
y luego se van añadiendo muy pocos términos nuevos (el vocabulario se satura rápidamente).
| Fortunata | Fortunata_lemat |
|---|
| #Palabras: | #Palabras distintas: |
|---|
| 7893 | 2565 |
| 15786 | 4264 |
| 23679 | 5618 |
| 31572 | 6883 |
| 39465 | 8003 |
| 47358 | 9041 |
| 55251 | 10012 |
| 63144 | 10853 |
| 71037 | 11795 |
| 78930 | 12676 |
| 86823 | 13361 |
| 94716 | 14081 |
| 102609 | 14711 |
| 110502 | 15429 |
| 118395 | 16060 |
| 126288 | 16619 |
| 134181 | 17131 |
| 142074 | 17675 |
| 149967 | 18208 |
| 157860 | 18684 |
| 165753 | 19289 |
| 173646 | 19816 |
| 181539 | 20285 |
| 189432 | 20724 |
| 197325 | 21105 |
| 205218 | 21491 |
| 213111 | 21983 |
| 221004 | 22443 |
| 228897 | 22823 |
| 236790 | 23160 |
| 244683 | 23592 |
| 252576 | 23966 |
| 260469 | 24316 |
| 268362 | 24700 |
| 276255 | 25017 |
| 284148 | 25313 |
| 292041 | 25575 |
| 299934 | 25919 |
| 307827 | 26259 |
| 315720 | 26604 |
| 323613 | 26910 |
| 331506 | 27234 |
| 339399 | 27507 |
| 347292 | 27816 |
| 355185 | 28142 |
| 363078 | 28404 |
| 370971 | 28671 |
| 378864 | 28907 |
| 386757 | 29093 |
| 394650 | 29367 |
| 394672 | 29367 |
|
| #Palabras: | #Palabras distintas: |
|---|
| 7876 | 1911 |
| 15752 | 2998 |
| 23628 | 3820 |
| 31504 | 4491 |
| 39380 | 5072 |
| 47256 | 5620 |
| 55132 | 6092 |
| 63008 | 6505 |
| 70884 | 6989 |
| 78760 | 7392 |
| 86636 | 7702 |
| 94512 | 8036 |
| 102388 | 8274 |
| 110264 | 8653 |
| 118140 | 8908 |
| 126016 | 9125 |
| 133892 | 9345 |
| 141768 | 9564 |
| 149644 | 9783 |
| 157520 | 9971 |
| 165396 | 10223 |
| 173272 | 10448 |
| 181148 | 10618 |
| 189024 | 10785 |
| 196900 | 10922 |
| 204776 | 11069 |
| 212652 | 11308 |
| 220528 | 11473 |
| 228404 | 11609 |
| 236280 | 11731 |
| 244156 | 11888 |
| 252032 | 12012 |
| 259908 | 12145 |
| 267784 | 12285 |
| 275660 | 12398 |
| 283536 | 12488 |
| 291412 | 12586 |
| 299288 | 12702 |
| 307164 | 12841 |
| 315040 | 12946 |
| 322916 | 13054 |
| 330792 | 13174 |
| 338668 | 13252 |
| 346544 | 13345 |
| 354420 | 13476 |
| 362296 | 13560 |
| 370172 | 13626 |
| 378048 | 13709 |
| 385924 | 13770 |
| 393800 | 13854 |
| 393844 | 13855 |
|
|
Ajuste por mínimos cuadrados de los datos a K*n^b: |
| Fortunata |
|
Fortunata_lemat |
| K = 14.613 |
|
K = 34.438 |
| b = 0.595 |
|
b = 0.471 |
|
Ley de Zipf
La ley de Zipf es una ley empírica que se basa en el principio de mínimos esfuerzo.
Esto es, supone que existe un pequeño número de palabras, las más "conocidas", que son utilizadas con mucha frecuencia,
mientras que hay un gran número de palabras son poco empleadas.
Matemáticamente esto quiere decir que la frecuencia (número de apariciones) de una palabra cualquiera
es inversamente proporcional a su ranking,
entendido como su posición en una lista de las palabras presentes en el texto ordenada descendentemente en función de su frecuencia.
Así, la palabra más frecuente aparecerá aproximadamente dos veces más que la segunda palabra más frecuente,
unas tres veces más que la tercera palabra más frecuente, etc.
Gráficamente, cuando una curva se encuentra por encima de la recta "ideal"
quiere decir que el texto emplea recurrentemente un número de palabras muy reducido,
habiendo muy pocas que aparezcan con poca frecuencia.
Por el contrario, cuando la curva se encuentra por debajo de la "ideal",
el texto contiene un vocabulario más amplio, con muchas palabras que aparecen relativamente pocas veces.
| Fortunata | Fortunata_lemat |
Ilustración del principio de mínimo esfuerzo: |
| Rank | Palabra | Frec |
|---|
| 1 | de | 18253 |
| 2 | que | 15616 |
| 3 | la | 14563 |
| 4 | y | 13277 |
| 5 | a | 9945 |
| 6 | el | 7919 |
| 7 | no | 7657 |
| 8 | en | 7609 |
| 9 | se | 6206 |
| 10 | con | 4637 |
| 11 | le | 4034 |
| 12 | lo | 4028 |
| 13 | su | 4000 |
| 14 | los | 3930 |
| 15 | un | 3767 |
| 16 | las | 3736 |
| 17 | por | 3617 |
| 18 | me | 3140 |
| 19 | una | 2873 |
| 20 | más | 2337 |
| 21 | al | 2312 |
| 22 | del | 2310 |
| 23 | como | 2294 |
| 24 | para | 2285 |
| 25 | es | 2263 |
| 26 | pero | 2097 |
| 27 | si | 2032 |
| 28 | qué | 1782 |
| 29 | yo | 1722 |
| 30 | era | 1656 |
| 31 | usted | 1626 |
| 32 | te | 1430 |
| 33 | había | 1393 |
| 34 | muy | 1215 |
| 35 | ya | 1180 |
| 36 | porque | 1094 |
| 37 | cuando | 1085 |
| 38 | ella | 1074 |
| 39 | dijo | 1073 |
| 40 | sus | 1041 |
| 41 | tan | 1028 |
| 42 | o | 989 |
| 43 | todo | 903 |
| 44 | pues | 903 |
| 45 | bien | 894 |
| 46 | él | 883 |
| 47 | casa | 874 |
| 48 | esta | 872 |
| 49 | fortunata | 869 |
| 50 | sin | 863 |
| 51 | estaba | 858 |
| 52 | mi | 801 |
| 53 | ha | 778 |
| 54 | tenía | 767 |
| 55 | sí | 758 |
| 56 | esto | 747 |
| 57 | ni | 736 |
| 58 | doña | 733 |
| 59 | aquel | 730 |
| 60 | nada | 690 |
| 61 | aquella | 666 |
| 62 | dos | 658 |
| 63 | este | 650 |
| 64 | otra | 629 |
| 65 | después | 622 |
| 66 | tú | 572 |
| 67 | jacinta | 571 |
| 68 | fue | 569 |
| 69 | ver | 560 |
| 70 | hay | 553 |
| 71 | está | 551 |
| 72 | mujer | 542 |
| 73 | aquí | 530 |
| 74 | día | 522 |
| 75 | lupe | 521 |
| 76 | he | 519 |
| 77 | ser | 517 |
| 78 | mucho | 513 |
| 79 | poco | 512 |
| 80 | mí | 499 |
| 81 | sobre | 488 |
| 82 | hombre | 486 |
| 83 | ahora | 480 |
| 84 | señora | 473 |
| 85 | también | 466 |
| 86 | dios | 461 |
| 87 | otro | 453 |
| 88 | algo | 448 |
| 89 | eso | 446 |
| 90 | cabeza | 443 |
| 91 | hasta | 441 |
| 92 | tiene | 435 |
| 93 | calle | 425 |
| 94 | mismo | 421 |
| 95 | decir | 420 |
| 96 | así | 419 |
| 97 | siempre | 415 |
| 98 | tal | 414 |
| 99 | cosas | 414 |
| 100 | fin | 408 |
| 101 | vida | 405 |
| 102 | d | 404 |
| 103 | todos | 398 |
| 104 | cosa | 396 |
| 105 | santa | 392 |
| 106 | noche | 377 |
| 107 | iba | 375 |
| 108 | hacer | 371 |
| 109 | vez | 365 |
| 110 | allí | 361 |
| 111 | toda | 356 |
| 112 | tiempo | 354 |
| 113 | cómo | 351 |
| 114 | entre | 350 |
| 115 | tanto | 337 |
| 116 | decía | 337 |
| 117 | ojos | 333 |
| 118 | nos | 333 |
| 119 | quien | 331 |
| 120 | cara | 329 |
| 121 | parecía | 320 |
| 122 | guillermina | 320 |
| 123 | gran | 317 |
| 124 | les | 316 |
| 125 | tía | 315 |
| 126 | mano | 315 |
| 127 | rubín | 314 |
| 128 | juan | 310 |
| 129 | tengo | 309 |
| 130 | alma | 309 |
| 131 | idea | 305 |
| 132 | maxi | 304 |
| 133 | marido | 304 |
| 134 | sé | 300 |
| 135 | eran | 297 |
| 136 | parece | 296 |
| 137 | maximiliano | 295 |
| 138 | cual | 295 |
| 139 | todas | 294 |
| 140 | tu | 289 |
| 141 | esa | 289 |
| 142 | mal | 287 |
| 143 | mejor | 284 |
| 144 | podía | 283 |
| 145 | mundo | 280 |
| 146 | puerta | 277 |
| 147 | verdad | 276 |
| 148 | aunque | 276 |
| 149 | cruz | 275 |
| 150 | menos | 272 |
| 151 | hacía | 272 |
| 152 | estas | 270 |
| 153 | desde | 264 |
| 154 | mañana | 263 |
| 155 | digo | 261 |
| 156 | fuera | 260 |
| 157 | va | 259 |
| 158 | uno | 259 |
| 159 | hecho | 255 |
| 160 | señor | 254 |
| 161 | son | 253 |
| 162 | antes | 251 |
| 163 | días | 248 |
| 164 | buena | 243 |
| 165 | puede | 242 |
| 166 | hace | 239 |
| 167 | pobre | 238 |
| 168 | quiero | 237 |
| 169 | hija | 237 |
| 170 | dicho | 237 |
| 171 | dar | 237 |
| 172 | pronto | 236 |
| 173 | estoy | 235 |
| 174 | parte | 232 |
| 175 | luego | 232 |
| 176 | hijo | 232 |
| 177 | ese | 232 |
| 178 | voy | 231 |
| 179 | nunca | 230 |
| 180 | tres | 228 |
| 181 | sino | 227 |
| 182 | sabe | 227 |
| 183 | quería | 226 |
| 184 | hizo | 225 |
| 185 | allá | 224 |
| 186 | vaya | 223 |
| 187 | daba | 221 |
| 188 | donde | 218 |
| 189 | manos | 217 |
| 190 | quiere | 215 |
| 191 | voz | 213 |
| 192 | veces | 211 |
| 193 | tener | 208 |
| 194 | vio | 207 |
| 195 | soy | 203 |
| 196 | sólo | 203 |
| 197 | sido | 201 |
| 198 | cada | 201 |
| 199 | estos | 198 |
| 200 | caso | 198 |
| 201 | has | 197 |
| 202 | puso | 196 |
| 203 | buen | 196 |
| 204 | entró | 195 |
| 205 | boca | 193 |
| 206 | visto | 192 |
| 207 | mauricia | 192 |
| 208 | volvió | 191 |
| 209 | vamos | 191 |
| 210 | dio | 191 |
| 211 | palabras | 190 |
| 212 | barbarita | 190 |
| 213 | bueno | 189 |
| 214 | amigo | 187 |
| 215 | otras | 186 |
| 216 | mala | 186 |
| 217 | salir | 185 |
| 218 | han | 184 |
| 219 | persona | 183 |
| 220 | tarde | 182 |
| 221 | chico | 182 |
| 222 | ay | 182 |
| 223 | ah | 182 |
| 224 | modo | 180 |
| 225 | habían | 180 |
| 226 | sabía | 178 |
| 227 | joven | 178 |
| 228 | dice | 178 |
| 229 | quién | 177 |
| 230 | misma | 177 |
| 231 | hoy | 176 |
| 232 | hacia | 176 |
| 233 | ido | 175 |
| 234 | familia | 175 |
| 235 | tienes | 174 |
| 236 | ti | 173 |
| 237 | corazón | 173 |
| 238 | años | 171 |
| 239 | alguna | 167 |
| 240 | medio | 165 |
| 241 | saber | 164 |
| 242 | dónde | 164 |
| 243 | diciendo | 163 |
| 244 | entonces | 162 |
| 245 | da | 162 |
| 246 | sea | 161 |
| 247 | rato | 161 |
| 248 | palabra | 161 |
| 249 | ir | 161 |
| 250 | amiga | 161 |
| 251 | ideas | 160 |
| 252 | nadie | 159 |
| 253 | mayor | 159 |
| 254 | dentro | 159 |
| 255 | moreno | 158 |
| 256 | grande | 156 |
| 257 | aquellos | 156 |
| 258 | amor | 156 |
| 259 | tuvo | 155 |
| 260 | mil | 155 |
| 261 | manera | 154 |
| 262 | hablar | 153 |
| 263 | estaban | 151 |
| 264 | cuarto | 151 |
| 265 | mira | 150 |
| 266 | madrid | 150 |
| 267 | personas | 149 |
| 268 | hubiera | 148 |
| 269 | estuvo | 148 |
| 270 | entrar | 148 |
| 271 | salió | 145 |
| 272 | pablo | 145 |
| 273 | izquierdo | 145 |
| 274 | cuerpo | 145 |
| 275 | lado | 144 |
| 276 | estás | 144 |
| 277 | dinero | 143 |
| 278 | niño | 142 |
| 279 | mesa | 141 |
| 280 | delante | 141 |
| 281 | estar | 140 |
| 282 | cuatro | 140 |
| 283 | dando | 139 |
| 284 | unos | 138 |
| 285 | sabes | 138 |
| 286 | dado | 138 |
| 287 | cuenta | 138 |
| 288 | hora | 137 |
| 289 | algunas | 137 |
| 290 | madre | 135 |
| 291 | punto | 134 |
| 292 | pudo | 134 |
| 293 | esas | 134 |
| 294 | ballester | 134 |
| 295 | otros | 133 |
| 296 | gente | 133 |
| 297 | ellos | 133 |
| 298 | aquellas | 133 |
| 299 | mientras | 132 |
| 300 | habría | 132 |
| 301 | falta | 132 |
| 302 | contra | 132 |
| 303 | cierto | 132 |
| 304 | cuanto | 131 |
| 305 | haciendo | 130 |
| 306 | casi | 130 |
| 307 | replicó | 129 |
| 308 | aquello | 129 |
| 309 | momento | 128 |
| 310 | estado | 128 |
| 311 | algún | 128 |
| 312 | mujeres | 126 |
| 313 | mío | 125 |
| 314 | ahí | 125 |
| 315 | duda | 124 |
| 316 | tomar | 123 |
| 317 | estupiñá | 123 |
| 318 | aún | 123 |
| 319 | veía | 122 |
| 320 | sentía | 122 |
| 321 | miedo | 122 |
| 322 | viene | 120 |
| 323 | ropa | 119 |
| 324 | razón | 119 |
| 325 | quieres | 119 |
| 326 | puesto | 119 |
| 327 | feijoo | 119 |
| 328 | café | 119 |
| 329 | baldomero | 119 |
| 330 | unas | 118 |
| 331 | pasar | 118 |
| 332 | mía | 118 |
| 333 | eres | 118 |
| 334 | pensaba | 117 |
| 335 | gusto | 116 |
| 336 | sala | 115 |
| 337 | puedo | 115 |
| 338 | pasado | 115 |
| 339 | ninguna | 115 |
| 340 | tenían | 114 |
| 341 | poner | 114 |
| 342 | papitos | 114 |
| 343 | empezó | 114 |
| 344 | ponía | 113 |
| 345 | pasaba | 113 |
| 346 | nicolás | 113 |
| 347 | mucha | 113 |
| 348 | amigos | 113 |
| 349 | agua | 113 |
| 350 | pasó | 112 |
| 351 | muchos | 112 |
| 352 | instante | 112 |
| 353 | volver | 111 |
| 354 | san | 111 |
| 355 | preciso | 111 |
| 356 | paso | 111 |
| 357 | muchas | 111 |
| 358 | miraba | 111 |
| 359 | sola | 110 |
| 360 | primero | 110 |
| 361 | mis | 109 |
| 362 | mirando | 109 |
| 363 | hermano | 109 |
| 364 | comer | 109 |
| 365 | creo | 108 |
| 366 | algunos | 108 |
| 367 | segunda | 107 |
| 368 | debía | 105 |
| 369 | cama | 105 |
| 370 | ve | 104 |
| 371 | conciencia | 104 |
| 372 | veo | 103 |
| 373 | será | 103 |
| 374 | gracia | 103 |
| 375 | tienda | 102 |
| 376 | mamá | 102 |
| 377 | evaristo | 102 |
| 378 | están | 102 |
| 379 | plácido | 101 |
| 380 | sintió | 100 |
| 381 | pensamiento | 100 |
| 382 | diez | 100 |
| 383 | aun | 100 |
| 384 | primera | 99 |
| 385 | padre | 99 |
| 386 | luz | 99 |
| 387 | haber | 99 |
| 388 | ellas | 99 |
| 389 | claro | 99 |
| 390 | cielo | 99 |
| 391 | brazo | 99 |
| 392 | juanito | 98 |
| 393 | trabajo | 97 |
| 394 | todavía | 97 |
| 395 | suelo | 97 |
| 396 | oír | 97 |
| 397 | alcoba | 97 |
| 398 | vivir | 96 |
| 399 | mas | 96 |
| 400 | fuerte | 96 |
| 401 | chica | 96 |
| 402 | tanta | 95 |
| 403 | iban | 94 |
| 404 | espíritu | 94 |
| 405 | esos | 94 |
| 406 | miró | 93 |
| 407 | media | 93 |
| 408 | fuerza | 93 |
| 409 | delfín | 93 |
| 410 | conversación | 93 |
| 411 | sobrino | 92 |
| 412 | sería | 92 |
| 413 | propio | 92 |
| 414 | junto | 92 |
| 415 | horas | 92 |
| 416 | grandes | 92 |
| 417 | ganas | 92 |
| 418 | demás | 92 |
| 419 | brazos | 92 |
| 420 | tenido | 91 |
| 421 | siguiente | 91 |
| 422 | preguntó | 91 |
| 423 | llegó | 91 |
| 424 | infeliz | 91 |
| 425 | hombres | 89 |
| 426 | querer | 88 |
| 427 | debe | 88 |
| 428 | remedio | 87 |
| 429 | llevaba | 87 |
| 430 | cuidado | 87 |
| 431 | llegar | 86 |
| 432 | josé | 86 |
| 433 | aire | 86 |
| 434 | viendo | 85 |
| 435 | año | 85 |
| 436 | quiera | 84 |
| 437 | quedó | 84 |
| 438 | malo | 84 |
| 439 | venía | 83 |
| 440 | tampoco | 83 |
| 441 | señoras | 83 |
| 442 | posible | 83 |
| 443 | lástima | 83 |
| 444 | conmigo | 83 |
| 445 | cinco | 83 |
| 446 | vino | 82 |
| 447 | vi | 82 |
| 448 | venir | 82 |
| 449 | nombre | 82 |
| 450 | esposa | 82 |
| 451 | cualquier | 82 |
| 452 | arriba | 82 |
| 453 | quizás | 81 |
| 454 | muerte | 81 |
| 455 | mirar | 81 |
| 456 | ello | 81 |
| 457 | echó | 81 |
| 458 | bastante | 81 |
| 459 | verás | 80 |
| 460 | tono | 80 |
| 461 | niña | 80 |
| 462 | exclamó | 80 |
| 463 | dejó | 80 |
| 464 | viuda | 79 |
| 465 | sueño | 79 |
| 466 | ningún | 79 |
| 467 | mente | 79 |
| 468 | frente | 79 |
| 469 | escalera | 79 |
| 470 | entraba | 79 |
| 471 | don | 79 |
| 472 | tras | 78 |
| 473 | salía | 78 |
| 474 | pueblo | 78 |
| 475 | podría | 78 |
| 476 | pie | 78 |
| 477 | pasos | 78 |
| 478 | papel | 78 |
| 479 | camino | 78 |
| 480 | abajo | 78 |
| 481 | reales | 77 |
| 482 | quiso | 77 |
| 483 | pensó | 77 |
| 484 | obra | 77 |
| 485 | creía | 77 |
| 486 | ustedes | 76 |
| 487 | jáuregui | 76 |
| 488 | historia | 76 |
| 489 | cierta | 76 |
| 490 | aurora | 76 |
| 491 | orden | 75 |
| 492 | oído | 75 |
| 493 | gusta | 75 |
| 494 | pasa | 74 |
| 495 | cocina | 74 |
| 496 | ángel | 74 |
| 497 | villalonga | 73 |
| 498 | severiana | 73 |
| 499 | pensar | 73 |
| 500 | negro | 73 |
| 501 | hermana | 73 |
| 502 | gana | 73 |
| 503 | durante | 73 |
| 504 | van | 72 |
| 505 | solo | 72 |
| 506 | samaniego | 72 |
| 507 | hijos | 72 |
| 508 | estamos | 72 |
| 509 | dije | 72 |
| 510 | bajo | 72 |
| 511 | vista | 71 |
| 512 | verla | 71 |
| 513 | último | 71 |
| 514 | pecho | 71 |
| 515 | hubo | 71 |
| 516 | fueron | 71 |
| 517 | darle | 71 |
| 518 | ves | 70 |
| 519 | tienen | 70 |
| 520 | señorita | 70 |
| 521 | poder | 70 |
| 522 | cariño | 70 |
| 523 | buenas | 70 |
| 524 | apenas | 70 |
| 525 | peor | 69 |
| 526 | pañuelo | 69 |
| 527 | llevar | 69 |
| 528 | labios | 69 |
| 529 | iglesia | 69 |
| 530 | gracias | 69 |
| 531 | casta | 69 |
| 532 | ante | 69 |
| 533 | vuelta | 68 |
| 534 | sangre | 68 |
| 535 | reír | 68 |
| 536 | quisiera | 68 |
| 537 | nuevo | 68 |
| 538 | importa | 68 |
| 539 | hemos | 68 |
| 540 | hacen | 68 |
| 541 | encima | 68 |
| 542 | curiosidad | 68 |
| 543 | ciertas | 68 |
| 544 | atención | 68 |
| 545 | e | 67 |
| 546 | cerca | 67 |
| 547 | situación | 66 |
| 548 | semejante | 66 |
| 549 | santo | 66 |
| 550 | arnaiz | 66 |
| 551 | meses | 65 |
| 552 | honrada | 65 |
| 553 | expresión | 65 |
| 554 | tales | 64 |
| 555 | plaza | 64 |
| 556 | moral | 64 |
| 557 | miradas | 64 |
| 558 | habrá | 64 |
| 559 | hablaba | 64 |
| 560 | dama | 64 |
| 561 | creer | 64 |
| 562 | ambos | 64 |
| 563 | alegría | 64 |
| 564 | acá | 64 |
| 565 | sor | 63 |
| 566 | según | 63 |
| 567 | risa | 63 |
| 568 | niños | 63 |
| 569 | mirada | 63 |
| 570 | visita | 62 |
| 571 | verdadero | 62 |
| 572 | vas | 62 |
| 573 | único | 62 |
| 574 | siguió | 62 |
| 575 | primer | 62 |
| 576 | ponerse | 62 |
| 577 | largo | 62 |
| 578 | casas | 62 |
| 579 | ayer | 62 |
| 580 | siquiera | 61 |
| 581 | repente | 61 |
| 582 | memoria | 61 |
| 583 | ii | 61 |
| 584 | enfermo | 61 |
| 585 | vueltas | 60 |
| 586 | venga | 60 |
| 587 | pensando | 60 |
| 588 | oh | 60 |
| 589 | nueva | 60 |
| 590 | echar | 60 |
| 591 | chicos | 60 |
| 592 | cerebro | 60 |
| 593 | ama | 60 |
| 594 | virgen | 59 |
| 595 | viera | 59 |
| 596 | verle | 59 |
| 597 | ven | 59 |
| 598 | vale | 59 |
| 599 | pituso | 59 |
| 600 | pena | 59 |
| 601 | pelo | 59 |
| 602 | dedos | 59 |
| 603 | decirle | 59 |
| 604 | cura | 59 |
| 605 | tiempos | 58 |
| 606 | tenemos | 58 |
| 607 | sr | 58 |
| 608 | propia | 58 |
| 609 | hablando | 58 |
| 610 | fuese | 58 |
| 611 | efecto | 58 |
| 612 | echando | 58 |
| 613 | diré | 58 |
| 614 | dan | 58 |
| 615 | caer | 58 |
| 616 | vivo | 57 |
| 617 | venido | 57 |
| 618 | silla | 57 |
| 619 | sale | 57 |
| 620 | naturaleza | 57 |
| 621 | dicen | 57 |
| 622 | creyó | 57 |
| 623 | anoche | 57 |
| 624 | tus | 56 |
| 625 | suya | 56 |
| 626 | poniendo | 56 |
| 627 | paciencia | 56 |
| 628 | habló | 56 |
| 629 | detrás | 56 |
| 630 | derecho | 56 |
| 631 | dejar | 56 |
| 632 | color | 56 |
| 633 | carne | 56 |
| 634 | suyo | 55 |
| 635 | sociedad | 55 |
| 636 | ruido | 55 |
| 637 | puedes | 55 |
| 638 | perdido | 55 |
| 639 | noches | 55 |
| 640 | natural | 55 |
| 641 | disparates | 55 |
| 642 | público | 54 |
| 643 | oyó | 54 |
| 644 | lógica | 54 |
| 645 | doce | 54 |
| 646 | añadió | 54 |
| 647 | veras | 53 |
| 648 | vea | 53 |
| 649 | triste | 53 |
| 650 | toma | 53 |
| 651 | sombrero | 53 |
| 652 | sol | 53 |
| 653 | sofá | 53 |
| 654 | silencio | 53 |
| 655 | pudiera | 53 |
| 656 | indicó | 53 |
| 657 | dolor | 53 |
| 658 | diferentes | 53 |
| 659 | dejaba | 53 |
| 660 | culpa | 53 |
| 661 | cuánto | 53 |
| 662 | coche | 53 |
| 663 | clase | 53 |
| 664 | atrás | 53 |
| 665 | andar | 53 |
| 666 | solía | 52 |
| 667 | sentido | 52 |
| 668 | mona | 52 |
| 669 | llevó | 52 |
| 670 | feliz | 52 |
| 671 | cuales | 52 |
| 672 | botica | 52 |
| 673 | bonita | 52 |
| 674 | además | 52 |
| 675 | tantas | 51 |
| 676 | segundo | 51 |
| 677 | paz | 51 |
| 678 | parecían | 51 |
| 679 | mentira | 51 |
| 680 | ley | 51 |
| 681 | lejos | 51 |
| 682 | gabinete | 51 |
| 683 | frío | 51 |
| 684 | faltaba | 51 |
| 685 | cogió | 51 |
| 686 | calor | 51 |
| 687 | buenos | 51 |
| 688 | basilio | 51 |
| 689 | viejo | 50 |
| 690 | tonta | 50 |
| 691 | tantos | 50 |
| 692 | sentimiento | 50 |
| 693 | realidad | 50 |
| 694 | pesar | 50 |
| 695 | médico | 50 |
| 696 | i | 50 |
| 697 | fe | 50 |
| 698 | di | 50 |
| 699 | dé | 50 |
| 700 | balcón | 50 |
| 701 | vivía | 49 |
| 702 | tonto | 49 |
| 703 | tertulia | 49 |
| 704 | talento | 49 |
| 705 | sobrina | 49 |
| 706 | particular | 49 |
| 707 | observó | 49 |
| 708 | nariz | 49 |
| 709 | misa | 49 |
| 710 | mire | 49 |
| 711 | llamar | 49 |
| 712 | llaman | 49 |
| 713 | llama | 49 |
| 714 | lengua | 49 |
| 715 | honor | 49 |
| 716 | contar | 49 |
| 717 | arte | 49 |
| 718 | tomó | 48 |
| 719 | tomaba | 48 |
| 720 | seguía | 48 |
| 721 | sacar | 48 |
| 722 | respeto | 48 |
| 723 | principio | 48 |
| 724 | paseo | 48 |
| 725 | oro | 48 |
| 726 | maría | 48 |
| 727 | llorar | 48 |
| 728 | fundadora | 48 |
| 729 | conviene | 48 |
| 730 | contigo | 48 |
| 731 | confianza | 48 |
| 732 | causa | 48 |
| 733 | ánimo | 48 |
| 734 | anda | 48 |
| 735 | alta | 48 |
| 736 | adelante | 48 |
| 737 | vestido | 47 |
| 738 | valor | 47 |
| 739 | tuviera | 47 |
| 740 | tomando | 47 |
| 741 | tenga | 47 |
| 742 | suerte | 47 |
| 743 | rostro | 47 |
| 744 | ratos | 47 |
| 745 | pone | 47 |
| 746 | pies | 47 |
| 747 | loco | 47 |
| 748 | interés | 47 |
| 749 | gustaba | 47 |
| 750 | dormir | 47 |
| 751 | diga | 47 |
| 752 | difícil | 47 |
| 753 | carácter | 47 |
| 754 | bonito | 47 |
| 755 | baja | 47 |
| 756 | ambas | 47 |
| 757 | verá | 46 |
| 758 | tristeza | 46 |
| 759 | torquemada | 46 |
| 760 | tío | 46 |
| 761 | siete | 46 |
| 762 | repitió | 46 |
| 763 | querida | 46 |
| 764 | pasando | 46 |
| 765 | derecha | 46 |
| 766 | cuya | 46 |
| 767 | cree | 46 |
| 768 | cayó | 46 |
| 769 | asunto | 46 |
| 770 | vuelto | 45 |
| 771 | poca | 45 |
| 772 | par | 45 |
| 773 | ocasión | 45 |
| 774 | micaelas | 45 |
| 775 | juicio | 45 |
| 776 | interior | 45 |
| 777 | empezaba | 45 |
| 778 | duros | 45 |
| 779 | cristo | 45 |
| 780 | crees | 45 |
| 781 | costumbre | 45 |
| 782 | corredor | 45 |
| 783 | convento | 45 |
| 784 | caballero | 45 |
| 785 | vergüenza | 44 |
| 786 | sitio | 44 |
| 787 | sentimientos | 44 |
| 788 | seis | 44 |
| 789 | sacó | 44 |
| 790 | ojo | 44 |
| 791 | nosotros | 44 |
| 792 | muerto | 44 |
| 793 | humana | 44 |
| 794 | golpe | 44 |
| 795 | edad | 44 |
| 796 | diciéndole | 44 |
| 797 | criada | 44 |
| 798 | conocía | 44 |
| 799 | comedor | 44 |
| 800 | bárbara | 44 |
| 801 | amigas | 44 |
| 802 | tierra | 43 |
| 803 | sentir | 43 |
| 804 | segismundo | 43 |
| 805 | sacaba | 43 |
| 806 | real | 43 |
| 807 | querido | 43 |
| 808 | oye | 43 |
| 809 | mes | 43 |
| 810 | mar | 43 |
| 811 | loca | 43 |
| 812 | llena | 43 |
| 813 | llegaba | 43 |
| 814 | leche | 43 |
| 815 | lágrimas | 43 |
| 816 | ja | 43 |
| 817 | deseo | 43 |
| 818 | debajo | 43 |
| 819 | botas | 43 |
| 820 | aparisi | 43 |
| 821 | subir | 42 |
| 822 | pura | 42 |
| 823 | pongo | 42 |
| 824 | política | 42 |
| 825 | pareció | 42 |
| 826 | oía | 42 |
| 827 | monjas | 42 |
| 828 | mitad | 42 |
| 829 | ira | 42 |
| 830 | ilusión | 42 |
| 831 | haya | 42 |
| 832 | género | 42 |
| 833 | establecimiento | 42 |
| 834 | dices | 42 |
| 835 | daban | 42 |
| 836 | ciertos | 42 |
| 837 | alguien | 42 |
| 838 | volviendo | 41 |
| 839 | vive | 41 |
| 840 | veremos | 41 |
| 841 | señores | 41 |
| 842 | quita | 41 |
| 843 | principal | 41 |
| 844 | pepe | 41 |
| 845 | patio | 41 |
| 846 | pan | 41 |
| 847 | música | 41 |
| 848 | lenguaje | 41 |
| 849 | justicia | 41 |
| 850 | hechos | 41 |
| 851 | hacían | 41 |
| 852 | fácil | 41 |
| 853 | esperaba | 41 |
| 854 | dura | 41 |
| 855 | deseos | 41 |
| 856 | comprar | 41 |
| 857 | caído | 41 |
| 858 | alguno | 41 |
| 859 | absolutamente | 41 |
| 860 | vuelve | 40 |
| 861 | víctima | 40 |
| 862 | traía | 40 |
| 863 | tontería | 40 |
| 864 | perdón | 40 |
| 865 | lleva | 40 |
| 866 | gritó | 40 |
| 867 | fueran | 40 |
| 868 | entrado | 40 |
| 869 | echado | 40 |
| 870 | dejando | 40 |
| 871 | coger | 40 |
| 872 | busca | 40 |
| 873 | andaba | 40 |
| 874 | volvía | 39 |
| 875 | voluntad | 39 |
| 876 | traer | 39 |
| 877 | serio | 39 |
| 878 | religión | 39 |
| 879 | quieras | 39 |
| 880 | quedaba | 39 |
| 881 | pueden | 39 |
| 882 | pieza | 39 |
| 883 | nuestro | 39 |
| 884 | noticia | 39 |
| 885 | muñoz | 39 |
| 886 | meter | 39 |
| 887 | marqués | 39 |
| 888 | malas | 39 |
| 889 | madres | 39 |
| 890 | jamás | 39 |
| 891 | horrible | 39 |
| 892 | hago | 39 |
| 893 | hacerle | 39 |
| 894 | forma | 39 |
| 895 | figura | 39 |
| 896 | enteramente | 39 |
| 897 | duro | 39 |
| 898 | doy | 39 |
| 899 | correr | 39 |
| 900 | casarse | 39 |
| 901 | cargo | 39 |
| 902 | calles | 39 |
| 903 | bromas | 39 |
| 904 | azul | 39 |
| 905 | abrió | 39 |
| 906 | tendrá | 38 |
| 907 | supo | 38 |
| 908 | siento | 38 |
| 909 | siendo | 38 |
| 910 | salida | 38 |
| 911 | portal | 38 |
| 912 | perder | 38 |
| 913 | pedir | 38 |
| 914 | obras | 38 |
| 915 | negra | 38 |
| 916 | libre | 38 |
| 917 | libertad | 38 |
| 918 | genio | 38 |
| 919 | encontraba | 38 |
| 920 | deseaba | 38 |
| 921 | cuyo | 38 |
| 922 | crea | 38 |
| 923 | chiquilla | 38 |
| 924 | casos | 38 |
| 925 | banco | 38 |
| 926 | viva | 37 |
| 927 | quevedo | 37 |
| 928 | próxima | 37 |
| 929 | podían | 37 |
| 930 | opinión | 37 |
| 931 | matrimonio | 37 |
| 932 | matar | 37 |
| 933 | llave | 37 |
| 934 | haga | 37 |
| 935 | grave | 37 |
| 936 | favor | 37 |
| 937 | cuento | 37 |
| 938 | contestó | 37 |
| 939 | comercio | 37 |
| 940 | asilo | 37 |
| 941 | social | 36 |
| 942 | señorito | 36 |
| 943 | salido | 36 |
| 944 | ruiz | 36 |
| 945 | ratito | 36 |
| 946 | prosiguió | 36 |
| 947 | parecido | 36 |
| 948 | órdenes | 36 |
| 949 | necesidad | 36 |
| 950 | movimiento | 36 |
| 951 | mantón | 36 |
| 952 | mandó | 36 |
| 953 | llegado | 36 |
| 954 | juanín | 36 |
| 955 | iii | 36 |
| 956 | haces | 36 |
| 957 | habitación | 36 |
| 958 | fondo | 36 |
| 959 | encontró | 36 |
| 960 | demasiado | 36 |
| 961 | cuentas | 36 |
| 962 | contrario | 36 |
| 963 | campo | 36 |
| 964 | basta | 36 |
| 965 | terror | 35 |
| 966 | salud | 35 |
| 967 | puertas | 35 |
| 968 | pobres | 35 |
| 969 | piedra | 35 |
| 970 | pico | 35 |
| 971 | pasillo | 35 |
| 972 | malos | 35 |
| 973 | cuartos | 35 |
| 974 | conozco | 35 |
| 975 | virtud | 34 |
| 976 | verdadera | 34 |
| 977 | ventana | 34 |
| 978 | treinta | 34 |
| 979 | tranquilo | 34 |
| 980 | tema | 34 |
| 981 | sonriendo | 34 |
| 982 | sentó | 34 |
| 983 | seguro | 34 |
| 984 | rico | 34 |
| 985 | reía | 34 |
| 986 | querían | 34 |
| 987 | puro | 34 |
| 988 | pecado | 34 |
| 989 | país | 34 |
| 990 | nuestra | 34 |
| 991 | noticias | 34 |
| 992 | ninguno | 34 |
| 993 | murmuró | 34 |
| 994 | modelo | 34 |
| 995 | lleno | 34 |
| 996 | levantó | 34 |
| 997 | leer | 34 |
| 998 | ji | 34 |
| 999 | hermosa | 34 |
| 1000 | hablado | 34 |
| 1001 | gobierno | 34 |
| 1002 | francamente | 34 |
| 1003 | estómago | 34 |
| 1004 | echaba | 34 |
| 1005 | dientes | 34 |
| 1006 | criatura | 34 |
| 1007 | compañía | 34 |
| 1008 | cómoda | 34 |
| 1009 | chocolate | 34 |
| 1010 | chiquillos | 34 |
| 1011 | capa | 34 |
| 1012 | broma | 34 |
| 1013 | apetito | 34 |
| 1014 | alto | 34 |
| 1015 | afirmó | 34 |
| 1016 | veinte | 33 |
| 1017 | última | 33 |
| 1018 | trato | 33 |
| 1019 | trabajar | 33 |
| 1020 | somos | 33 |
| 1021 | seguir | 33 |
| 1022 | salían | 33 |
| 1023 | respecto | 33 |
| 1024 | queda | 33 |
| 1025 | primeros | 33 |
| 1026 | platón | 33 |
| 1027 | parecer | 33 |
| 1028 | olmedo | 33 |
| 1029 | objeto | 33 |
| 1030 | motivo | 33 |
| 1031 | manía | 33 |
| 1032 | manda | 33 |
| 1033 | maldita | 33 |
| 1034 | llamaba | 33 |
| 1035 | hombros | 33 |
| 1036 | hecha | 33 |
| 1037 | gordo | 33 |
| 1038 | gloria | 33 |
| 1039 | fuego | 33 |
| 1040 | frase | 33 |
| 1041 | estuviera | 33 |
| 1042 | entraron | 33 |
| 1043 | encontrar | 33 |
| 1044 | ejemplo | 33 |
| 1045 | disparate | 33 |
| 1046 | dignidad | 33 |
| 1047 | delfina | 33 |
| 1048 | consigo | 33 |
| 1049 | caridad | 33 |
| 1050 | caña | 33 |
| 1051 | cantidad | 33 |
| 1052 | caía | 33 |
| 1053 | blanco | 33 |
| 1054 | acciones | 33 |
| 1055 | vicio | 32 |
| 1056 | tonterías | 32 |
| 1057 | subió | 32 |
| 1058 | sonrisa | 32 |
| 1059 | segura | 32 |
| 1060 | sacando | 32 |
| 1061 | relaciones | 32 |
| 1062 | rabia | 32 |
| 1063 | quieren | 32 |
| 1064 | polvo | 32 |
| 1065 | pase | 32 |
| 1066 | pared | 32 |
| 1067 | papá | 32 |
| 1068 | os | 32 |
| 1069 | ocurrió | 32 |
| 1070 | nueve | 32 |
| 1071 | muchacho | 32 |
| 1072 | metió | 32 |
| 1073 | lecho | 32 |
| 1074 | imposible | 32 |
| 1075 | hierro | 32 |
| 1076 | hacerlo | 32 |
| 1077 | habla | 32 |
| 1078 | gritos | 32 |
| 1079 | flores | 32 |
| 1080 | estuvieron | 32 |
| 1081 | esposo | 32 |
| 1082 | entusiasmo | 32 |
| 1083 | educación | 32 |
| 1084 | demonio | 32 |
| 1085 | deja | 32 |
| 1086 | decían | 32 |
| 1087 | decente | 32 |
| 1088 | cualquiera | 32 |
| 1089 | cuál | 32 |
| 1090 | completamente | 32 |
| 1091 | benigna | 32 |
| 1092 | acuerdo | 32 |
| 1093 | actitud | 32 |
| 1094 | trataba | 31 |
| 1095 | toledo | 31 |
| 1096 | tendría | 31 |
| 1097 | superiora | 31 |
| 1098 | santísima | 31 |
| 1099 | salieron | 31 |
| 1100 | reloj | 31 |
| 1101 | pueda | 31 |
| 1102 | poquito | 31 |
| 1103 | piso | 31 |
| 1104 | pasión | 31 |
| 1105 | pareja | 31 |
| 1106 | número | 31 |
| 1107 | mostraba | 31 |
| 1108 | llevado | 31 |
| 1109 | libros | 31 |
| 1110 | juro | 31 |
| 1111 | hombro | 31 |
| 1112 | hermosura | 31 |
| 1113 | fino | 31 |
| 1114 | estilo | 31 |
| 1115 | dulce | 31 |
| 1116 | dormido | 31 |
| 1117 | diría | 31 |
| 1118 | demonios | 31 |
| 1119 | cuello | 31 |
| 1120 | corrió | 31 |
| 1121 | cogía | 31 |
| 1122 | cava | 31 |
| 1123 | cambio | 31 |
| 1124 | visitas | 30 |
| 1125 | única | 30 |
| 1126 | tomado | 30 |
| 1127 | teatro | 30 |
| 1128 | serlo | 30 |
| 1129 | riendo | 30 |
| 1130 | quedose | 30 |
| 1131 | punta | 30 |
| 1132 | puestos | 30 |
| 1133 | prisa | 30 |
| 1134 | poniéndose | 30 |
| 1135 | pocas | 30 |
| 1136 | piernas | 30 |
| 1137 | ocho | 30 |
| 1138 | negocio | 30 |
| 1139 | necesitaba | 30 |
| 1140 | morir | 30 |
| 1141 | miseria | 30 |
| 1142 | lugar | 30 |
| 1143 | llega | 30 |
| 1144 | jaqueca | 30 |
| 1145 | imaginación | 30 |
| 1146 | igual | 30 |
| 1147 | honradez | 30 |
| 1148 | espiritual | 30 |
| 1149 | entra | 30 |
| 1150 | destino | 30 |
| 1151 | creí | 30 |
| 1152 | calma | 30 |
| 1153 | bajó | 30 |
| 1154 | asiento | 30 |
| 1155 | acto | 30 |
| 1156 | vieron | 29 |
| 1157 | suspiro | 29 |
| 1158 | saca | 29 |
| 1159 | saben | 29 |
| 1160 | río | 29 |
| 1161 | rey | 29 |
| 1162 | respuesta | 29 |
| 1163 | primo | 29 |
| 1164 | pregunta | 29 |
| 1165 | pocos | 29 |
| 1166 | pobrecito | 29 |
| 1167 | manifestó | 29 |
| 1168 | llamó | 29 |
| 1169 | levantarse | 29 |
| 1170 | infame | 29 |
| 1171 | impresión | 29 |
| 1172 | humor | 29 |
| 1173 | general | 29 |
| 1174 | fresco | 29 |
| 1175 | feliciana | 29 |
| 1176 | españa | 29 |
| 1177 | enferma | 29 |
| 1178 | dormía | 29 |
| 1179 | disposición | 29 |
| 1180 | dieron | 29 |
| 1181 | debo | 29 |
| 1182 | dándole | 29 |
| 1183 | damas | 29 |
| 1184 | conforme | 29 |
| 1185 | cogido | 29 |
| 1186 | casar | 29 |
| 1187 | carrera | 29 |
| 1188 | buscar | 29 |
| 1189 | blanca | 29 |
| 1190 | belén | 29 |
| 1191 | autoridad | 29 |
| 1192 | viento | 28 |
| 1193 | verse | 28 |
| 1194 | trae | 28 |
| 1195 | terreno | 28 |
| 1196 | superior | 28 |
| 1197 | sombra | 28 |
| 1198 | rodillas | 28 |
| 1199 | recuerdo | 28 |
| 1200 | quite | 28 |
| 1201 | quitado | 28 |
| 1202 | quitaba | 28 |
| 1203 | piensa | 28 |
| 1204 | permitía | 28 |
| 1205 | pensamientos | 28 |
| 1206 | ocurre | 28 |
| 1207 | muebles | 28 |
| 1208 | miraban | 28 |
| 1209 | juego | 28 |
| 1210 | iv | 28 |
| 1211 | hará | 28 |
| 1212 | farmacia | 28 |
| 1213 | farmacéutico | 28 |
| 1214 | expresar | 28 |
| 1215 | esperando | 28 |
| 1216 | entrando | 28 |
| 1217 | dueño | 28 |
| 1218 | dedo | 28 |
| 1219 | curas | 28 |
| 1220 | creyendo | 28 |
| 1221 | contento | 28 |
| 1222 | conque | 28 |
| 1223 | conocer | 28 |
| 1224 | conoce | 28 |
| 1225 | compras | 28 |
| 1226 | claridad | 28 |
| 1227 | carta | 28 |
| 1228 | capaz | 28 |
| 1229 | besos | 28 |
| 1230 | ave | 28 |
| 1231 | adiós | 28 |
| 1232 | acento | 28 |
| 1233 | acababa | 28 |
| 1234 | voces | 27 |
| 1235 | varias | 27 |
| 1236 | v | 27 |
| 1237 | tren | 27 |
| 1238 | tranquila | 27 |
| 1239 | trajo | 27 |
| 1240 | teniendo | 27 |
| 1241 | temor | 27 |
| 1242 | soltó | 27 |
| 1243 | solos | 27 |
| 1244 | serenidad | 27 |
| 1245 | sepa | 27 |
| 1246 | sentado | 27 |
| 1247 | semblante | 27 |
| 1248 | seguramente | 27 |
| 1249 | seda | 27 |
| 1250 | salvaje | 27 |
| 1251 | presente | 27 |
| 1252 | plato | 27 |
| 1253 | plata | 27 |
| 1254 | plan | 27 |
| 1255 | pintado | 27 |
| 1256 | pez | 27 |
| 1257 | padres | 27 |
| 1258 | oficio | 27 |
| 1259 | ocurrido | 27 |
| 1260 | niñas | 27 |
| 1261 | nene | 27 |
| 1262 | maldito | 27 |
| 1263 | larga | 27 |
| 1264 | juntos | 27 |
| 1265 | humano | 27 |
| 1266 | hice | 27 |
| 1267 | extremo | 27 |
| 1268 | esté | 27 |
| 1269 | escribir | 27 |
| 1270 | entendía | 27 |
| 1271 | entender | 27 |
| 1272 | encarnación | 27 |
| 1273 | dispuesto | 27 |
| 1274 | dirección | 27 |
| 1275 | desgracia | 27 |
| 1276 | déjame | 27 |
| 1277 | dejado | 27 |
| 1278 | clérigo | 27 |
| 1279 | cincuenta | 27 |
| 1280 | barrio | 27 |
| 1281 | barbaridad | 27 |
| 1282 | apareció | 27 |
| 1283 | amistad | 27 |
| 1284 | alegre | 27 |
| 1285 | vuelvo | 26 |
| 1286 | vienen | 26 |
| 1287 | verde | 26 |
| 1288 | vengo | 26 |
| 1289 | vendrá | 26 |
| 1290 | vecindad | 26 |
| 1291 | total | 26 |
| 1292 | resultado | 26 |
| 1293 | respondió | 26 |
| 1294 | respondía | 26 |
| 1295 | ramo | 26 |
| 1296 | queriendo | 26 |
| 1297 | puesta | 26 |
| 1298 | prójima | 26 |
| 1299 | presencia | 26 |
| 1300 | piedad | 26 |
| 1301 | perfectamente | 26 |
| 1302 | pasaron | 26 |
| 1303 | orgullo | 26 |
| 1304 | ocurría | 26 |
| 1305 | muerta | 26 |
| 1306 | meterse | 26 |
| 1307 | medicina | 26 |
| 1308 | limpia | 26 |
| 1309 | isla | 26 |
| 1310 | inocente | 26 |
| 1311 | inglés | 26 |
| 1312 | hucha | 26 |
| 1313 | hostia | 26 |
| 1314 | hijas | 26 |
| 1315 | fina | 26 |
| 1316 | feo | 26 |
| 1317 | existencia | 26 |
| 1318 | estará | 26 |
| 1319 | época | 26 |
| 1320 | dicha | 26 |
| 1321 | cuándo | 26 |
| 1322 | convicción | 26 |
| 1323 | contaba | 26 |
| 1324 | ciencia | 26 |
| 1325 | ciego | 26 |
| 1326 | celos | 26 |
| 1327 | capellán | 26 |
| 1328 | cae | 26 |
| 1329 | cabo | 26 |
| 1330 | bestia | 26 |
| 1331 | abrir | 26 |
| 1332 | villuendas | 25 |
| 1333 | traído | 25 |
| 1334 | toca | 25 |
| 1335 | timidez | 25 |
| 1336 | términos | 25 |
| 1337 | sustancia | 25 |
| 1338 | soledad | 25 |
| 1339 | simpático | 25 |
| 1340 | sigue | 25 |
| 1341 | seriedad | 25 |
| 1342 | secreto | 25 |
| 1343 | satisfacción | 25 |
| 1344 | rincón | 25 |
| 1345 | ricos | 25 |
| 1346 | recibir | 25 |
| 1347 | rara | 25 |
| 1348 | quedado | 25 |
| 1349 | prendas | 25 |
| 1350 | ponen | 25 |
| 1351 | piezas | 25 |
| 1352 | pienso | 25 |
| 1353 | perro | 25 |
| 1354 | parís | 25 |
| 1355 | parecen | 25 |
| 1356 | papeles | 25 |
| 1357 | nuevas | 25 |
| 1358 | nicanora | 25 |
| 1359 | metido | 25 |
| 1360 | máquina | 25 |
| 1361 | maestro | 25 |
| 1362 | levantándose | 25 |
| 1363 | lección | 25 |
| 1364 | iré | 25 |
| 1365 | imagen | 25 |
| 1366 | hermanos | 25 |
| 1367 | herencia | 25 |
| 1368 | esquina | 25 |
| 1369 | espejo | 25 |
| 1370 | entiende | 25 |
| 1371 | diera | 25 |
| 1372 | darse | 25 |
| 1373 | cumplir | 25 |
| 1374 | compra | 25 |
| 1375 | completo | 25 |
| 1376 | compasión | 25 |
| 1377 | comida | 25 |
| 1378 | comía | 25 |
| 1379 | cojo | 25 |
| 1380 | circunstancias | 25 |
| 1381 | buscando | 25 |
| 1382 | bolsillo | 25 |
| 1383 | boda | 25 |
| 1384 | amante | 25 |
| 1385 | admirable | 25 |
| 1386 | vela | 24 |
| 1387 | uso | 24 |
| 1388 | usaba | 24 |
| 1389 | tuvieron | 24 |
| 1390 | tuve | 24 |
| 1391 | sorpresa | 24 |
| 1392 | sintiendo | 24 |
| 1393 | sillas | 24 |
| 1394 | severidad | 24 |
| 1395 | servicio | 24 |
| 1396 | seria | 24 |
| 1397 | sentarse | 24 |
| 1398 | seguida | 24 |
| 1399 | sabido | 24 |
| 1400 | recogidas | 24 |
| 1401 | rafaela | 24 |
| 1402 | quienes | 24 |
| 1403 | pusieron | 24 |
| 1404 | propios | 24 |
| 1405 | podrá | 24 |
| 1406 | pide | 24 |
| 1407 | pedazo | 24 |
| 1408 | patricia | 24 |
| 1409 | pacheco | 24 |
| 1410 | oyendo | 24 |
| 1411 | olor | 24 |
| 1412 | ocasiones | 24 |
| 1413 | nones | 24 |
| 1414 | narices | 24 |
| 1415 | medios | 24 |
| 1416 | manto | 24 |
| 1417 | leyes | 24 |
| 1418 | izquierda | 24 |
| 1419 | imaginar | 24 |
| 1420 | humanidad | 24 |
| 1421 | humanas | 24 |
| 1422 | haré | 24 |
| 1423 | hambre | 24 |
| 1424 | hacerse | 24 |
| 1425 | guerra | 24 |
| 1426 | grado | 24 |
| 1427 | gozo | 24 |
| 1428 | fiera | 24 |
| 1429 | falda | 24 |
| 1430 | esperar | 24 |
| 1431 | escena | 24 |
| 1432 | entendimiento | 24 |
| 1433 | empezar | 24 |
| 1434 | desgraciado | 24 |
| 1435 | decirse | 24 |
| 1436 | debían | 24 |
| 1437 | cuestión | 24 |
| 1438 | criado | 24 |
| 1439 | creerás | 24 |
| 1440 | contenta | 24 |
| 1441 | cogiendo | 24 |
| 1442 | chiquillo | 24 |
| 1443 | bendito | 24 |
| 1444 | ayuda | 24 |
| 1445 | asombro | 24 |
| 1446 | anterior | 24 |
| 1447 | adoración | 24 |
| 1448 | abrigo | 24 |
| 1449 | verte | 23 |
| 1450 | valiente | 23 |
| 1451 | tiro | 23 |
| 1452 | tiendas | 23 |
| 1453 | techo | 23 |
| 1454 | sinceridad | 23 |
| 1455 | sillón | 23 |
| 1456 | seré | 23 |
| 1457 | saliendo | 23 |
| 1458 | romper | 23 |
| 1459 | retiró | 23 |
| 1460 | retirarse | 23 |
| 1461 | religiosa | 23 |
| 1462 | rápidamente | 23 |
| 1463 | probar | 23 |
| 1464 | ponían | 23 |
| 1465 | podido | 23 |
| 1466 | pillo | 23 |
| 1467 | pasaban | 23 |
| 1468 | olimpia | 23 |
| 1469 | observando | 23 |
| 1470 | novia | 23 |
| 1471 | nosotras | 23 |
| 1472 | nena | 23 |
| 1473 | nacido | 23 |
| 1474 | monja | 23 |
| 1475 | metía | 23 |
| 1476 | marcela | 23 |
| 1477 | local | 23 |
| 1478 | limosna | 23 |
| 1479 | libro | 23 |
| 1480 | león | 23 |
| 1481 | jesús | 23 |
| 1482 | isabel | 23 |
| 1483 | hubieran | 23 |
| 1484 | hiciera | 23 |
| 1485 | guapa | 23 |
| 1486 | gato | 23 |
| 1487 | firme | 23 |
| 1488 | filosofía | 23 |
| 1489 | fijo | 23 |
| 1490 | felicidad | 23 |
| 1491 | entero | 23 |
| 1492 | enfermedad | 23 |
| 1493 | daría | 23 |
| 1494 | cuentos | 23 |
| 1495 | continuaba | 23 |
| 1496 | conocido | 23 |
| 1497 | chulita | 23 |
| 1498 | casada | 23 |
| 1499 | acerca | 23 |
| 1500 | acción | 23 |
| 1501 | verdaderamente | 22 |
| 1502 | vaso | 22 |
| 1503 | tratar | 22 |
| 1504 | tranquilidad | 22 |
| 1505 | tirar | 22 |
| 1506 | temprano | 22 |
| 1507 | temía | 22 |
| 1508 | siglo | 22 |
| 1509 | señal | 22 |
| 1510 | sentada | 22 |
| 1511 | seno | 22 |
| 1512 | salen | 22 |
| 1513 | sacerdote | 22 |
| 1514 | retrato | 22 |
| 1515 | razones | 22 |
| 1516 | quia | 22 |
| 1517 | preguntas | 22 |
| 1518 | práctica | 22 |
| 1519 | peso | 22 |
| 1520 | pecados | 22 |
| 1521 | partes | 22 |
| 1522 | palo | 22 |
| 1523 | norte | 22 |
| 1524 | necesito | 22 |
| 1525 | mérito | 22 |
| 1526 | mejores | 22 |
| 1527 | mayores | 22 |
| 1528 | manuel | 22 |
| 1529 | lujo | 22 |
| 1530 | llevo | 22 |
| 1531 | importancia | 22 |
| 1532 | hicieron | 22 |
| 1533 | haría | 22 |
| 1534 | hagas | 22 |
| 1535 | habrían | 22 |
| 1536 | fría | 22 |
| 1537 | frases | 22 |
| 1538 | formalidad | 22 |
| 1539 | figuras | 22 |
| 1540 | expresó | 22 |
| 1541 | español | 22 |
| 1542 | espalda | 22 |
| 1543 | enemigo | 22 |
| 1544 | encuentro | 22 |
| 1545 | embargo | 22 |
| 1546 | elegante | 22 |
| 1547 | eh | 22 |
| 1548 | ea | 22 |
| 1549 | dijera | 22 |
| 1550 | diferencia | 22 |
| 1551 | declaró | 22 |
| 1552 | casado | 22 |
| 1553 | carnes | 22 |
| 1554 | caras | 22 |
| 1555 | amo | 22 |
| 1556 | altar | 22 |
| 1557 | almorzar | 22 |
| 1558 | adentro | 22 |
| 1559 | acercó | 22 |
| 1560 | acera | 22 |
| 1561 | últimos | 21 |
| 1562 | tocar | 21 |
| 1563 | tira | 21 |
| 1564 | tendré | 21 |
| 1565 | tela | 21 |
| 1566 | sostener | 21 |
| 1567 | solas | 21 |
| 1568 | sentándose | 21 |
| 1569 | semana | 21 |
| 1570 | seguridad | 21 |
| 1571 | sano | 21 |
| 1572 | salto | 21 |
| 1573 | sagrario | 21 |
| 1574 | quitó | 21 |
| 1575 | prueba | 21 |
| 1576 | problema | 21 |
| 1577 | primeras | 21 |
| 1578 | plazuela | 21 |
| 1579 | pensado | 21 |
| 1580 | patria | 21 |
| 1581 | pasiones | 21 |
| 1582 | partido | 21 |
| 1583 | oscuridad | 21 |
| 1584 | momentos | 21 |
| 1585 | minutos | 21 |
| 1586 | mesas | 21 |
| 1587 | mandar | 21 |
| 1588 | limpio | 21 |
| 1589 | letras | 21 |
| 1590 | inteligencia | 21 |
| 1591 | hoja | 21 |
| 1592 | hablaban | 21 |
| 1593 | fortuna | 21 |
| 1594 | expresaba | 21 |
| 1595 | excelente | 21 |
| 1596 | estaría | 21 |
| 1597 | esposos | 21 |
| 1598 | escuela | 21 |
| 1599 | entrada | 21 |
| 1600 | enterarse | 21 |
| 1601 | enfrente | 21 |
| 1602 | edificio | 21 |
| 1603 | dudas | 21 |
| 1604 | dispuesta | 21 |
| 1605 | disimular | 21 |
| 1606 | deseando | 21 |
| 1607 | decirlo | 21 |
| 1608 | debilidad | 21 |
| 1609 | cuerda | 21 |
| 1610 | corría | 21 |
| 1611 | conoces | 21 |
| 1612 | conducta | 21 |
| 1613 | coja | 21 |
| 1614 | coge | 21 |
| 1615 | cintura | 21 |
| 1616 | callar | 21 |
| 1617 | averiguar | 21 |
| 1618 | aseguro | 21 |
| 1619 | arma | 21 |
| 1620 | antonio | 21 |
| 1621 | andando | 21 |
| 1622 | anciano | 21 |
| 1623 | admiración | 21 |
| 1624 | actos | 21 |
| 1625 | acaso | 21 |
| 1626 | acabó | 21 |
| 1627 | abur | 21 |
| 1628 | volvería | 20 |
| 1629 | verme | 20 |
| 1630 | varios | 20 |
| 1631 | vanidad | 20 |
| 1632 | valía | 20 |
| 1633 | tratando | 20 |
| 1634 | tocan | 20 |
| 1635 | subía | 20 |
| 1636 | socorro | 20 |
| 1637 | sentar | 20 |
| 1638 | santidad | 20 |
| 1639 | salón | 20 |
| 1640 | saco | 20 |
| 1641 | principios | 20 |
| 1642 | ponga | 20 |
| 1643 | pido | 20 |
| 1644 | pelos | 20 |
| 1645 | pecadora | 20 |
| 1646 | pasan | 20 |
| 1647 | partida | 20 |
| 1648 | nuevos | 20 |
| 1649 | nuestros | 20 |
| 1650 | noble | 20 |
| 1651 | nerviosa | 20 |
| 1652 | necesita | 20 |
| 1653 | naturalmente | 20 |
| 1654 | mozo | 20 |
| 1655 | mete | 20 |
| 1656 | menor | 20 |
| 1657 | marcha | 20 |
| 1658 | mando | 20 |
| 1659 | maestra | 20 |
| 1660 | largas | 20 |
| 1661 | juntas | 20 |
| 1662 | jueves | 20 |
| 1663 | inquietud | 20 |
| 1664 | impulso | 20 |
| 1665 | huerta | 20 |
| 1666 | ginés | 20 |
| 1667 | gesto | 20 |
| 1668 | fui | 20 |
| 1669 | francisco | 20 |
| 1670 | estuve | 20 |
| 1671 | envidia | 20 |
| 1672 | encargo | 20 |
| 1673 | echarle | 20 |
| 1674 | distancia | 20 |
| 1675 | dirá | 20 |
| 1676 | digas | 20 |
| 1677 | desdén | 20 |
| 1678 | dejo | 20 |
| 1679 | deje | 20 |
| 1680 | decoro | 20 |
| 1681 | creas | 20 |
| 1682 | corte | 20 |
| 1683 | corriente | 20 |
| 1684 | consejos | 20 |
| 1685 | círculo | 20 |
| 1686 | cafés | 20 |
| 1687 | breve | 20 |
| 1688 | bondad | 20 |
| 1689 | balcones | 20 |
| 1690 | bah | 20 |
| 1691 | apreciar | 20 |
| 1692 | amantes | 20 |
| 1693 | almuerzo | 20 |
| 1694 | agregó | 20 |
| 1695 | abierta | 20 |
| 1696 | zalamero | 19 |
| 1697 | volverse | 19 |
| 1698 | vinieron | 19 |
| 1699 | vete | 19 |
| 1700 | vengan | 19 |
| 1701 | veían | 19 |
| 1702 | vara | 19 |
| 1703 | trujillo | 19 |
| 1704 | tocaba | 19 |
| 1705 | tercera | 19 |
| 1706 | suegra | 19 |
| 1707 | sucesos | 19 |
| 1708 | sonreía | 19 |
| 1709 | soltar | 19 |
| 1710 | sesos | 19 |
| 1711 | satisfecho | 19 |
| 1712 | rompió | 19 |
| 1713 | revólver | 19 |
| 1714 | responder | 19 |
| 1715 | reserva | 19 |
| 1716 | recado | 19 |
| 1717 | quitar | 19 |
| 1718 | pudiendo | 19 |
| 1719 | pública | 19 |
| 1720 | protección | 19 |
| 1721 | propósito | 19 |
| 1722 | perros | 19 |
| 1723 | perdone | 19 |
| 1724 | pavos | 19 |
| 1725 | paredes | 19 |
| 1726 | oscuro | 19 |
| 1727 | once | 19 |
| 1728 | obligación | 19 |
| 1729 | nuera | 19 |
| 1730 | nervioso | 19 |
| 1731 | natividad | 19 |
| 1732 | moda | 19 |
| 1733 | miserable | 19 |
| 1734 | mañanas | 19 |
| 1735 | limpieza | 19 |
| 1736 | levita | 19 |
| 1737 | intención | 19 |
| 1738 | inspiraba | 19 |
| 1739 | indecente | 19 |
| 1740 | increíble | 19 |
| 1741 | importante | 19 |
| 1742 | hilo | 19 |
| 1743 | hacienda | 19 |
| 1744 | habiendo | 19 |
| 1745 | gumersindo | 19 |
| 1746 | fresca | 19 |
| 1747 | franqueza | 19 |
| 1748 | flor | 19 |
| 1749 | espera | 19 |
| 1750 | escaleras | 19 |
| 1751 | entraban | 19 |
| 1752 | energía | 19 |
| 1753 | encontrado | 19 |
| 1754 | domingos | 19 |
| 1755 | disgusto | 19 |
| 1756 | despacho | 19 |
| 1757 | custodia | 19 |
| 1758 | corta | 19 |
| 1759 | correspondencia | 19 |
| 1760 | cordero | 19 |
| 1761 | confusión | 19 |
| 1762 | condición | 19 |
| 1763 | común | 19 |
| 1764 | claramente | 19 |
| 1765 | clara | 19 |
| 1766 | casó | 19 |
| 1767 | cárcel | 19 |
| 1768 | capital | 19 |
| 1769 | capilla | 19 |
| 1770 | caminos | 19 |
| 1771 | cabello | 19 |
| 1772 | bribona | 19 |
| 1773 | botón | 19 |
| 1774 | atrevía | 19 |
| 1775 | aspecto | 19 |
| 1776 | arreglo | 19 |
| 1777 | antiguo | 19 |
| 1778 | antigua | 19 |
| 1779 | aires | 19 |
| 1780 | acabar | 19 |
| 1781 | viaje | 18 |
| 1782 | velas | 18 |
| 1783 | veinticinco | 18 |
| 1784 | vecinas | 18 |
| 1785 | tremendo | 18 |
| 1786 | traje | 18 |
| 1787 | terrible | 18 |
| 1788 | ten | 18 |
| 1789 | tarasca | 18 |
| 1790 | suelto | 18 |
| 1791 | suavemente | 18 |
| 1792 | soberbia | 18 |
| 1793 | sistema | 18 |
| 1794 | sirve | 18 |
| 1795 | simple | 18 |
| 1796 | serían | 18 |
| 1797 | revelaba | 18 |
| 1798 | rencor | 18 |
| 1799 | recibido | 18 |
| 1800 | ramas | 18 |
| 1801 | quieran | 18 |
| 1802 | quedar | 18 |
| 1803 | pruebas | 18 |
| 1804 | prudente | 18 |
| 1805 | providencia | 18 |
| 1806 | precisamente | 18 |
| 1807 | peligro | 18 |
| 1808 | patas | 18 |
| 1809 | pañuelos | 18 |
| 1810 | pájaros | 18 |
| 1811 | oscuras | 18 |
| 1812 | observación | 18 |
| 1813 | negocios | 18 |
| 1814 | murió | 18 |
| 1815 | montes | 18 |
| 1816 | modales | 18 |
| 1817 | menudo | 18 |
| 1818 | llevaron | 18 |
| 1819 | llamaban | 18 |
| 1820 | juicios | 18 |
| 1821 | infierno | 18 |
| 1822 | improviso | 18 |
| 1823 | impresiones | 18 |
| 1824 | ilustre | 18 |
| 1825 | honrado | 18 |
| 1826 | hablaron | 18 |
| 1827 | gustan | 18 |
| 1828 | graciosa | 18 |
| 1829 | furor | 18 |
| 1830 | funciones | 18 |
| 1831 | fuertes | 18 |
| 1832 | francia | 18 |
| 1833 | formas | 18 |
| 1834 | fija | 18 |
| 1835 | figúrate | 18 |
| 1836 | fenelón | 18 |
| 1837 | federico | 18 |
| 1838 | fea | 18 |
| 1839 | familias | 18 |
| 1840 | facha | 18 |
| 1841 | evitar | 18 |
| 1842 | esperanza | 18 |
| 1843 | especie | 18 |
| 1844 | española | 18 |
| 1845 | espanto | 18 |
| 1846 | esfuerzos | 18 |
| 1847 | emoción | 18 |
| 1848 | echarse | 18 |
| 1849 | duque | 18 |
| 1850 | dichoso | 18 |
| 1851 | despertar | 18 |
| 1852 | delirio | 18 |
| 1853 | deben | 18 |
| 1854 | cuarenta | 18 |
| 1855 | cristiano | 18 |
| 1856 | convenía | 18 |
| 1857 | contado | 18 |
| 1858 | consuelo | 18 |
| 1859 | compañero | 18 |
| 1860 | comedia | 18 |
| 1861 | come | 18 |
| 1862 | centro | 18 |
| 1863 | cayendo | 18 |
| 1864 | campanilla | 18 |
| 1865 | buscaba | 18 |
| 1866 | bruto | 18 |
| 1867 | bajar | 18 |
| 1868 | azúcar | 18 |
| 1869 | ataque | 18 |
| 1870 | animal | 18 |
| 1871 | alegro | 18 |
| 1872 | acuerdas | 18 |
| 1873 | volvieron | 17 |
| 1874 | vivos | 17 |
| 1875 | vii | 17 |
| 1876 | vendría | 17 |
| 1877 | vecino | 17 |
| 1878 | valen | 17 |
| 1879 | tropa | 17 |
| 1880 | trance | 17 |
| 1881 | trabajaba | 17 |
| 1882 | tontos | 17 |
| 1883 | tardó | 17 |
| 1884 | tamaño | 17 |
| 1885 | taller | 17 |
| 1886 | supiera | 17 |
| 1887 | suceso | 17 |
| 1888 | sublime | 17 |
| 1889 | sonaba | 17 |
| 1890 | simpatía | 17 |
| 1891 | seguido | 17 |
| 1892 | seca | 17 |
| 1893 | seas | 17 |
| 1894 | sean | 17 |
| 1895 | sacado | 17 |
| 1896 | sábanas | 17 |
| 1897 | rica | 17 |
| 1898 | retiro | 17 |
| 1899 | resulta | 17 |
| 1900 | repetía | 17 |
| 1901 | remediar | 17 |
| 1902 | reja | 17 |
| 1903 | regular | 17 |
| 1904 | rata | 17 |
| 1905 | ramón | 17 |
| 1906 | quince | 17 |
| 1907 | quedarse | 17 |
| 1908 | pusiera | 17 |
| 1909 | próximo | 17 |
| 1910 | propuso | 17 |
| 1911 | propias | 17 |
| 1912 | profundo | 17 |
| 1913 | profunda | 17 |
| 1914 | preguntar | 17 |
| 1915 | pierna | 17 |
| 1916 | periódicos | 17 |
| 1917 | perdida | 17 |
| 1918 | pequeña | 17 |
| 1919 | pedazos | 17 |
| 1920 | pasillos | 17 |
| 1921 | parar | 17 |
| 1922 | pa | 17 |
| 1923 | oyeron | 17 |
| 1924 | oían | 17 |
| 1925 | novedades | 17 |
| 1926 | notar | 17 |
| 1927 | nacimiento | 17 |
| 1928 | muchísimo | 17 |
| 1929 | morenos | 17 |
| 1930 | monte | 17 |
| 1931 | mirándola | 17 |
| 1932 | merece | 17 |
| 1933 | mental | 17 |
| 1934 | medida | 17 |
| 1935 | manolo | 17 |
| 1936 | madera | 17 |
| 1937 | lance | 17 |
| 1938 | jugar | 17 |
| 1939 | inmenso | 17 |
| 1940 | individuos | 17 |
| 1941 | imágenes | 17 |
| 1942 | humo | 17 |
| 1943 | hermoso | 17 |
| 1944 | grupo | 17 |
| 1945 | golpes | 17 |
| 1946 | fenómeno | 17 |
| 1947 | extraordinariamente | 17 |
| 1948 | estación | 17 |
| 1949 | espacio | 17 |
| 1950 | engañado | 17 |
| 1951 | empezado | 17 |
| 1952 | doctrina | 17 |
| 1953 | divina | 17 |
| 1954 | dime | 17 |
| 1955 | dígame | 17 |
| 1956 | desgraciada | 17 |
| 1957 | defensa | 17 |
| 1958 | débil | 17 |
| 1959 | das | 17 |
| 1960 | cuerdo | 17 |
| 1961 | cuantos | 17 |
| 1962 | crecía | 17 |
| 1963 | contener | 17 |
| 1964 | conocimiento | 17 |
| 1965 | concluir | 17 |
| 1966 | concepto | 17 |
| 1967 | compañera | 17 |
| 1968 | colores | 17 |
| 1969 | ciento | 17 |
| 1970 | cien | 17 |
| 1971 | célebre | 17 |
| 1972 | cartas | 17 |
| 1973 | camisa | 17 |
| 1974 | caja | 17 |
| 1975 | caían | 17 |
| 1976 | cabía | 17 |
| 1977 | caballo | 17 |
| 1978 | bruscamente | 17 |
| 1979 | bola | 17 |
| 1980 | billetes | 17 |
| 1981 | belleza | 17 |
| 1982 | aguas | 17 |
| 1983 | ademán | 17 |
| 1984 | vienes | 16 |
| 1985 | vestir | 16 |
| 1986 | tuyo | 16 |
| 1987 | tuya | 16 |
| 1988 | turbación | 16 |
| 1989 | trató | 16 |
| 1990 | trampa | 16 |
| 1991 | tocayo | 16 |
| 1992 | tiró | 16 |
| 1993 | sujeto | 16 |
| 1994 | sostenía | 16 |
| 1995 | servía | 16 |
| 1996 | sereno | 16 |
| 1997 | sentidos | 16 |
| 1998 | sales | 16 |
| 1999 | rojo | 16 |
| 2000 | resistir | 16 |
| 2001 | reían | 16 |
| 2002 | refugio | 16 |
| 2003 | recibió | 16 |
| 2004 | quedándose | 16 |
| 2005 | púsose | 16 |
| 2006 | profesor | 16 |
| 2007 | prenda | 16 |
| 2008 | pontejos | 16 |
| 2009 | pitusa | 16 |
| 2010 | pidió | 16 |
| 2011 | personal | 16 |
| 2012 | periodo | 16 |
| 2013 | perdía | 16 |
| 2014 | pegar | 16 |
| 2015 | pedro | 16 |
| 2016 | paseos | 16 |
| 2017 | pariente | 16 |
| 2018 | pago | 16 |
| 2019 | pagar | 16 |
| 2020 | orejas | 16 |
| 2021 | olvidar | 16 |
| 2022 | oiga | 16 |
| 2023 | ofrecía | 16 |
| 2024 | novio | 16 |
| 2025 | notó | 16 |
| 2026 | nervios | 16 |
| 2027 | negras | 16 |
| 2028 | mostrando | 16 |
| 2029 | montón | 16 |
| 2030 | misas | 16 |
| 2031 | mata | 16 |
| 2032 | masa | 16 |
| 2033 | lotería | 16 |
| 2034 | llevándose | 16 |
| 2035 | llevando | 16 |
| 2036 | llevan | 16 |
| 2037 | lío | 16 |
| 2038 | lecciones | 16 |
| 2039 | inspiración | 16 |
| 2040 | infantil | 16 |
| 2041 | hueco | 16 |
| 2042 | hubieras | 16 |
| 2043 | hermanas | 16 |
| 2044 | hallaba | 16 |
| 2045 | hable | 16 |
| 2046 | hábitos | 16 |
| 2047 | habías | 16 |
| 2048 | guapo | 16 |
| 2049 | graves | 16 |
| 2050 | fuerzas | 16 |
| 2051 | filomenas | 16 |
| 2052 | fiel | 16 |
| 2053 | extranjero | 16 |
| 2054 | estuviese | 16 |
| 2055 | estúpido | 16 |
| 2056 | estudio | 16 |
| 2057 | estudiar | 16 |
| 2058 | estaré | 16 |
| 2059 | entierro | 16 |
| 2060 | encontré | 16 |
| 2061 | empezaban | 16 |
| 2062 | echa | 16 |
| 2063 | duró | 16 |
| 2064 | domicilio | 16 |
| 2065 | difunto | 16 |
| 2066 | dificultades | 16 |
| 2067 | detuvo | 16 |
| 2068 | despertó | 16 |
| 2069 | desconsuelo | 16 |
| 2070 | desconocido | 16 |
| 2071 | delicado | 16 |
| 2072 | decirme | 16 |
| 2073 | debemos | 16 |
| 2074 | crisis | 16 |
| 2075 | creen | 16 |
| 2076 | copa | 16 |
| 2077 | contó | 16 |
| 2078 | contestar | 16 |
| 2079 | contemplando | 16 |
| 2080 | contarle | 16 |
| 2081 | consejo | 16 |
| 2082 | concluido | 16 |
| 2083 | comprendió | 16 |
| 2084 | completa | 16 |
| 2085 | coches | 16 |
| 2086 | clases | 16 |
| 2087 | chasco | 16 |
| 2088 | castelar | 16 |
| 2089 | casamiento | 16 |
| 2090 | cansado | 16 |
| 2091 | cajas | 16 |
| 2092 | botella | 16 |
| 2093 | barba | 16 |
| 2094 | ayudaba | 16 |
| 2095 | artista | 16 |
| 2096 | artículo | 16 |
| 2097 | arroz | 16 |
| 2098 | ardor | 16 |
| 2099 | árbol | 16 |
| 2100 | apariencias | 16 |
| 2101 | ansiedad | 16 |
| 2102 | amiguita | 16 |
| 2103 | afán | 16 |
| 2104 | acercaba | 16 |
| 2105 | absoluta | 16 |
| 2106 | abierto | 16 |
| 2107 | viven | 15 |
| 2108 | venían | 15 |
| 2109 | vengas | 15 |
| 2110 | velo | 15 |
| 2111 | tuviese | 15 |
| 2112 | tremenda | 15 |
| 2113 | trastos | 15 |
| 2114 | traigo | 15 |
| 2115 | toros | 15 |
| 2116 | tomo | 15 |
| 2117 | tocando | 15 |
| 2118 | tengas | 15 |
| 2119 | té | 15 |
| 2120 | susto | 15 |
| 2121 | suspiros | 15 |
| 2122 | simón | 15 |
| 2123 | señá | 15 |
| 2124 | seco | 15 |
| 2125 | salita | 15 |
| 2126 | sagrada | 15 |
| 2127 | rumor | 15 |
| 2128 | rosario | 15 |
| 2129 | respirar | 15 |
| 2130 | respiración | 15 |
| 2131 | representaba | 15 |
| 2132 | regente | 15 |
| 2133 | recoger | 15 |
| 2134 | re | 15 |
| 2135 | razonable | 15 |
| 2136 | quedaron | 15 |
| 2137 | quedaban | 15 |
| 2138 | puño | 15 |
| 2139 | pueblos | 15 |
| 2140 | pozo | 15 |
| 2141 | ponerle | 15 |
| 2142 | pescuezo | 15 |
| 2143 | perfecta | 15 |
| 2144 | pensé | 15 |
| 2145 | pego | 15 |
| 2146 | pausa | 15 |
| 2147 | paño | 15 |
| 2148 | paca | 15 |
| 2149 | ochoa | 15 |
| 2150 | observar | 15 |
| 2151 | nuestras | 15 |
| 2152 | niñez | 15 |
| 2153 | nació | 15 |
| 2154 | monstruo | 15 |
| 2155 | modestia | 15 |
| 2156 | mías | 15 |
| 2157 | locura | 15 |
| 2158 | llevarle | 15 |
| 2159 | llamado | 15 |
| 2160 | lista | 15 |
| 2161 | levantose | 15 |
| 2162 | levantar | 15 |
| 2163 | letra | 15 |
| 2164 | lentamente | 15 |
| 2165 | ladrón | 15 |
| 2166 | ladrillos | 15 |
| 2167 | ladrillo | 15 |
| 2168 | jóvenes | 15 |
| 2169 | insigne | 15 |
| 2170 | huevo | 15 |
| 2171 | hubiese | 15 |
| 2172 | horror | 15 |
| 2173 | herida | 15 |
| 2174 | haciéndole | 15 |
| 2175 | habitaciones | 15 |
| 2176 | guardia | 15 |
| 2177 | garganta | 15 |
| 2178 | formaban | 15 |
| 2179 | fisonomía | 15 |
| 2180 | faltó | 15 |
| 2181 | facciones | 15 |
| 2182 | extraña | 15 |
| 2183 | extensión | 15 |
| 2184 | expresarse | 15 |
| 2185 | estrellas | 15 |
| 2186 | escándalo | 15 |
| 2187 | entrañas | 15 |
| 2188 | encargado | 15 |
| 2189 | empezaron | 15 |
| 2190 | eclesiástica | 15 |
| 2191 | durmió | 15 |
| 2192 | díjole | 15 |
| 2193 | desprecio | 15 |
| 2194 | despidió | 15 |
| 2195 | desorden | 15 |
| 2196 | desdémona | 15 |
| 2197 | desagradable | 15 |
| 2198 | debió | 15 |
| 2199 | crimen | 15 |
| 2200 | corriendo | 15 |
| 2201 | conseguir | 15 |
| 2202 | consecuencia | 15 |
| 2203 | conferencia | 15 |
| 2204 | conceptos | 15 |
| 2205 | comprendo | 15 |
| 2206 | comprender | 15 |
| 2207 | cólera | 15 |
| 2208 | codo | 15 |
| 2209 | claras | 15 |
| 2210 | chillidos | 15 |
| 2211 | chamberí | 15 |
| 2212 | cejas | 15 |
| 2213 | carga | 15 |
| 2214 | candelaria | 15 |
| 2215 | cállate | 15 |
| 2216 | cajón | 15 |
| 2217 | cabezas | 15 |
| 2218 | bulto | 15 |
| 2219 | bulla | 15 |
| 2220 | beso | 15 |
| 2221 | bata | 15 |
| 2222 | bajaba | 15 |
| 2223 | armó | 15 |
| 2224 | armar | 15 |
| 2225 | argumentos | 15 |
| 2226 | ángeles | 15 |
| 2227 | amar | 15 |
| 2228 | alzar | 15 |
| 2229 | acordaba | 15 |
| 2230 | vuelves | 14 |
| 2231 | vuelva | 14 |
| 2232 | volví | 14 |
| 2233 | vía | 14 |
| 2234 | vestidos | 14 |
| 2235 | verdes | 14 |
| 2236 | verdades | 14 |
| 2237 | verano | 14 |
| 2238 | vayas | 14 |
| 2239 | valencia | 14 |
| 2240 | tunante | 14 |
| 2241 | tratado | 14 |
| 2242 | trata | 14 |
| 2243 | trasto | 14 |
| 2244 | trapo | 14 |
| 2245 | trabajos | 14 |
| 2246 | tenéis | 14 |
| 2247 | sueños | 14 |
| 2248 | suelta | 14 |
| 2249 | sonó | 14 |
| 2250 | solución | 14 |
| 2251 | soltando | 14 |
| 2252 | silvia | 14 |
| 2253 | siente | 14 |
| 2254 | seres | 14 |
| 2255 | sal | 14 |
| 2256 | sabiendo | 14 |
| 2257 | risueña | 14 |
| 2258 | rezar | 14 |
| 2259 | revés | 14 |
| 2260 | recibía | 14 |
| 2261 | raza | 14 |
| 2262 | querrá | 14 |
| 2263 | quedo | 14 |
| 2264 | pulso | 14 |
| 2265 | provincia | 14 |
| 2266 | progreso | 14 |
| 2267 | profundamente | 14 |
| 2268 | procesión | 14 |
| 2269 | presunción | 14 |
| 2270 | preparado | 14 |
| 2271 | porvenir | 14 |
| 2272 | pones | 14 |
| 2273 | podrían | 14 |
| 2274 | pobreza | 14 |
| 2275 | pobrecilla | 14 |
| 2276 | planta | 14 |
| 2277 | píldoras | 14 |
| 2278 | pidiendo | 14 |
| 2279 | perdona | 14 |
| 2280 | pequeño | 14 |
| 2281 | penas | 14 |
| 2282 | pegado | 14 |
| 2283 | pasará | 14 |
| 2284 | pálida | 14 |
| 2285 | ordinaria | 14 |
| 2286 | ocurren | 14 |
| 2287 | novedad | 14 |
| 2288 | notas | 14 |
| 2289 | notaba | 14 |
| 2290 | muertos | 14 |
| 2291 | muere | 14 |
| 2292 | muera | 14 |
| 2293 | moviendo | 14 |
| 2294 | moscas | 14 |
| 2295 | monedas | 14 |
| 2296 | meto | 14 |
| 2297 | merezco | 14 |
| 2298 | marzo | 14 |
| 2299 | maridos | 14 |
| 2300 | marcharse | 14 |
| 2301 | manta | 14 |
| 2302 | mandaba | 14 |
| 2303 | londres | 14 |
| 2304 | llegaron | 14 |
| 2305 | llegando | 14 |
| 2306 | llaves | 14 |
| 2307 | liberación | 14 |
| 2308 | leía | 14 |
| 2309 | lados | 14 |
| 2310 | jefe | 14 |
| 2311 | jaquecas | 14 |
| 2312 | irse | 14 |
| 2313 | iremos | 14 |
| 2314 | inmensa | 14 |
| 2315 | importaba | 14 |
| 2316 | hueso | 14 |
| 2317 | hallábase | 14 |
| 2318 | hacerme | 14 |
| 2319 | habrás | 14 |
| 2320 | hablarle | 14 |
| 2321 | haberse | 14 |
| 2322 | grito | 14 |
| 2323 | gorro | 14 |
| 2324 | gorda | 14 |
| 2325 | gas | 14 |
| 2326 | ganado | 14 |
| 2327 | finas | 14 |
| 2328 | fíjate | 14 |
| 2329 | fiebre | 14 |
| 2330 | febril | 14 |
| 2331 | faltado | 14 |
| 2332 | fácilmente | 14 |
| 2333 | fábrica | 14 |
| 2334 | extraordinario | 14 |
| 2335 | explicaciones | 14 |
| 2336 | existe | 14 |
| 2337 | estancia | 14 |
| 2338 | esfuerzo | 14 |
| 2339 | escape | 14 |
| 2340 | entiendo | 14 |
| 2341 | enterado | 14 |
| 2342 | enfermos | 14 |
| 2343 | enamorado | 14 |
| 2344 | empleado | 14 |
| 2345 | duele | 14 |
| 2346 | domingo | 14 |
| 2347 | divertido | 14 |
| 2348 | digan | 14 |
| 2349 | despacio | 14 |
| 2350 | descubrir | 14 |
| 2351 | dependientes | 14 |
| 2352 | delantal | 14 |
| 2353 | déjate | 14 |
| 2354 | deber | 14 |
| 2355 | dándose | 14 |
| 2356 | cuantas | 14 |
| 2357 | cristiana | 14 |
| 2358 | cristales | 14 |
| 2359 | creerlo | 14 |
| 2360 | creeríase | 14 |
| 2361 | costumbres | 14 |
| 2362 | cortesía | 14 |
| 2363 | coronel | 14 |
| 2364 | conveniente | 14 |
| 2365 | contestaba | 14 |
| 2366 | conocí | 14 |
| 2367 | comprendía | 14 |
| 2368 | comandanta | 14 |
| 2369 | clavado | 14 |
| 2370 | cerró | 14 |
| 2371 | cerrada | 14 |
| 2372 | casualidad | 14 |
| 2373 | cariñosa | 14 |
| 2374 | cantar | 14 |
| 2375 | cállese | 14 |
| 2376 | bonitas | 14 |
| 2377 | bocas | 14 |
| 2378 | billete | 14 |
| 2379 | beber | 14 |
| 2380 | baúl | 14 |
| 2381 | bastón | 14 |
| 2382 | atroz | 14 |
| 2383 | atrevió | 14 |
| 2384 | argumento | 14 |
| 2385 | aprendido | 14 |
| 2386 | aplicación | 14 |
| 2387 | apartar | 14 |
| 2388 | angelical | 14 |
| 2389 | amas | 14 |
| 2390 | aguantar | 14 |
| 2391 | actividad | 14 |
| 2392 | abriendo | 14 |
| 2393 | vulgar | 13 |
| 2394 | vivido | 13 |
| 2395 | vestirse | 13 |
| 2396 | vestida | 13 |
| 2397 | vecinos | 13 |
| 2398 | vean | 13 |
| 2399 | uñas | 13 |
| 2400 | tuvieran | 13 |
| 2401 | traían | 13 |
| 2402 | trabajando | 13 |
| 2403 | tome | 13 |
| 2404 | tocó | 13 |
| 2405 | tocante | 13 |
| 2406 | tirando | 13 |
| 2407 | tipo | 13 |
| 2408 | tesoro | 13 |
| 2409 | temores | 13 |
| 2410 | temo | 13 |
| 2411 | talle | 13 |
| 2412 | suponer | 13 |
| 2413 | suma | 13 |
| 2414 | sucia | 13 |
| 2415 | subiendo | 13 |
| 2416 | sube | 13 |
| 2417 | sosiego | 13 |
| 2418 | sofocada | 13 |
| 2419 | síntomas | 13 |
| 2420 | signo | 13 |
| 2421 | servir | 13 |
| 2422 | sermón | 13 |
| 2423 | señales | 13 |
| 2424 | sentirse | 13 |
| 2425 | rubio | 13 |
| 2426 | rigor | 13 |
| 2427 | ricas | 13 |
| 2428 | resto | 13 |
| 2429 | resolución | 13 |
| 2430 | regalo | 13 |
| 2431 | referente | 13 |
| 2432 | recordaba | 13 |
| 2433 | recogió | 13 |
| 2434 | quitarle | 13 |
| 2435 | puramente | 13 |
| 2436 | pude | 13 |
| 2437 | principalmente | 13 |
| 2438 | pretensiones | 13 |
| 2439 | presentes | 13 |
| 2440 | preguntaba | 13 |
| 2441 | práctico | 13 |
| 2442 | pondría | 13 |
| 2443 | pondré | 13 |
| 2444 | piedras | 13 |
| 2445 | pícara | 13 |
| 2446 | perdonar | 13 |
| 2447 | perdió | 13 |
| 2448 | pensarlo | 13 |
| 2449 | pedernero | 13 |
| 2450 | parezca | 13 |
| 2451 | parecíale | 13 |
| 2452 | paraba | 13 |
| 2453 | paja | 13 |
| 2454 | olvidado | 13 |
| 2455 | oigo | 13 |
| 2456 | ofreció | 13 |
| 2457 | novela | 13 |
| 2458 | negros | 13 |
| 2459 | muero | 13 |
| 2460 | muchacha | 13 |
| 2461 | mostrador | 13 |
| 2462 | mosca | 13 |
| 2463 | misterios | 13 |
| 2464 | mismos | 13 |
| 2465 | miraron | 13 |
| 2466 | mirarle | 13 |
| 2467 | mirado | 13 |
| 2468 | ministerio | 13 |
| 2469 | metal | 13 |
| 2470 | mesías | 13 |
| 2471 | matado | 13 |
| 2472 | marras | 13 |
| 2473 | manolita | 13 |
| 2474 | majestad | 13 |
| 2475 | madrugada | 13 |
| 2476 | lumbre | 13 |
| 2477 | llorando | 13 |
| 2478 | llamada | 13 |
| 2479 | liberal | 13 |
| 2480 | lectura | 13 |
| 2481 | lanzó | 13 |
| 2482 | justo | 13 |
| 2483 | juez | 13 |
| 2484 | judío | 13 |
| 2485 | interesante | 13 |
| 2486 | inteligente | 13 |
| 2487 | influencia | 13 |
| 2488 | infancia | 13 |
| 2489 | indulgencia | 13 |
| 2490 | iguales | 13 |
| 2491 | humildad | 13 |
| 2492 | huevos | 13 |
| 2493 | horriblemente | 13 |
| 2494 | hebra | 13 |
| 2495 | hablaremos | 13 |
| 2496 | guardar | 13 |
| 2497 | guardaba | 13 |
| 2498 | grupos | 13 |
| 2499 | gratitud | 13 |
| 2500 | gallo | 13 |
| 2501 | frialdad | 13 |
| 2502 | fórmula | 13 |
| 2503 | final | 13 |
| 2504 | felices | 13 |
| 2505 | fecha | 13 |
| 2506 | faltas | 13 |
| 2507 | falsa | 13 |
| 2508 | facunda | 13 |
| 2509 | facultades | 13 |
| 2510 | extraño | 13 |
| 2511 | expresiones | 13 |
| 2512 | éxito | 13 |
| 2513 | estuvieran | 13 |
| 2514 | enorme | 13 |
| 2515 | engañar | 13 |
| 2516 | encuentra | 13 |
| 2517 | encender | 13 |
| 2518 | ejercicio | 13 |
| 2519 | echo | 13 |
| 2520 | echaron | 13 |
| 2521 | echándose | 13 |
| 2522 | dormida | 13 |
| 2523 | disimulo | 13 |
| 2524 | discurso | 13 |
| 2525 | discurriendo | 13 |
| 2526 | dijeron | 13 |
| 2527 | diente | 13 |
| 2528 | diablo | 13 |
| 2529 | devoción | 13 |
| 2530 | deshonra | 13 |
| 2531 | desea | 13 |
| 2532 | delicada | 13 |
| 2533 | dejan | 13 |
| 2534 | dejaban | 13 |
| 2535 | decirte | 13 |
| 2536 | debes | 13 |
| 2537 | dale | 13 |
| 2538 | cuchillo | 13 |
| 2539 | cuántas | 13 |
| 2540 | crítica | 13 |
| 2541 | créetelo | 13 |
| 2542 | copas | 13 |
| 2543 | conservaba | 13 |
| 2544 | concepción | 13 |
| 2545 | comprendiendo | 13 |
| 2546 | compañeras | 13 |
| 2547 | colmo | 13 |
| 2548 | chuletas | 13 |
| 2549 | causaba | 13 |
| 2550 | carcajada | 13 |
| 2551 | canto | 13 |
| 2552 | calzado | 13 |
| 2553 | benevolencia | 13 |
| 2554 | bajando | 13 |
| 2555 | asuntos | 13 |
| 2556 | asco | 13 |
| 2557 | artículos | 13 |
| 2558 | arranque | 13 |
| 2559 | apretó | 13 |
| 2560 | apretaba | 13 |
| 2561 | apoyando | 13 |
| 2562 | aparecer | 13 |
| 2563 | alzando | 13 |
| 2564 | almas | 13 |
| 2565 | aguardiente | 13 |
| 2566 | admirablemente | 13 |
| 2567 | acostarse | 13 |
| 2568 | acordó | 13 |
| 2569 | abría | 13 |
| 2570 | abra | 13 |
| 2571 | vuelvas | 12 |
| 2572 | villa | 12 |
| 2573 | viii | 12 |
| 2574 | ventanas | 12 |
| 2575 | venganza | 12 |
| 2576 | únicamente | 12 |
| 2577 | últimas | 12 |
| 2578 | tristezas | 12 |
| 2579 | trapos | 12 |
| 2580 | traeré | 12 |
| 2581 | toquilla | 12 |
| 2582 | tomarlo | 12 |
| 2583 | tercero | 12 |
| 2584 | tendremos | 12 |
| 2585 | temeroso | 12 |
| 2586 | tardes | 12 |
| 2587 | suyos | 12 |
| 2588 | sufrir | 12 |
| 2589 | sucesión | 12 |
| 2590 | sospechaba | 12 |
| 2591 | soñado | 12 |
| 2592 | sociales | 12 |
| 2593 | síntoma | 12 |
| 2594 | siguieron | 12 |
| 2595 | significaba | 12 |
| 2596 | sesenta | 12 |
| 2597 | serás | 12 |
| 2598 | señas | 12 |
| 2599 | sentaba | 12 |
| 2600 | sencillez | 12 |
| 2601 | secretos | 12 |
| 2602 | seamos | 12 |
| 2603 | sazón | 12 |
| 2604 | santísimo | 12 |
| 2605 | saltó | 12 |
| 2606 | saliera | 12 |
| 2607 | saberlo | 12 |
| 2608 | roto | 12 |
| 2609 | riqueza | 12 |
| 2610 | república | 12 |
| 2611 | repito | 12 |
| 2612 | regla | 12 |
| 2613 | registro | 12 |
| 2614 | recibimiento | 12 |
| 2615 | realmente | 12 |
| 2616 | rasgos | 12 |
| 2617 | quedan | 12 |
| 2618 | pronunciar | 12 |
| 2619 | príncipe | 12 |
| 2620 | prima | 12 |
| 2621 | pretexto | 12 |
| 2622 | presteza | 12 |
| 2623 | préstamos | 12 |
| 2624 | presentarse | 12 |
| 2625 | premio | 12 |
| 2626 | ponerme | 12 |
| 2627 | pollo | 12 |
| 2628 | pluma | 12 |
| 2629 | piensas | 12 |
| 2630 | peseta | 12 |
| 2631 | personalidad | 12 |
| 2632 | pelota | 12 |
| 2633 | pedirle | 12 |
| 2634 | pasas | 12 |
| 2635 | parroquia | 12 |
| 2636 | parientes | 12 |
| 2637 | parentesco | 12 |
| 2638 | paquete | 12 |
| 2639 | pantalones | 12 |
| 2640 | padecía | 12 |
| 2641 | padecer | 12 |
| 2642 | oyera | 12 |
| 2643 | oírla | 12 |
| 2644 | oí | 12 |
| 2645 | obstante | 12 |
| 2646 | objetos | 12 |
| 2647 | nubes | 12 |
| 2648 | nombres | 12 |
| 2649 | nieto | 12 |
| 2650 | multitud | 12 |
| 2651 | movimientos | 12 |
| 2652 | moverse | 12 |
| 2653 | motivos | 12 |
| 2654 | morirme | 12 |
| 2655 | mirarla | 12 |
| 2656 | militares | 12 |
| 2657 | miguel | 12 |
| 2658 | medicinas | 12 |
| 2659 | mecánica | 12 |
| 2660 | manila | 12 |
| 2661 | malicia | 12 |
| 2662 | llenos | 12 |
| 2663 | líneas | 12 |
| 2664 | leopoldo | 12 |
| 2665 | leña | 12 |
| 2666 | lecturas | 12 |
| 2667 | jugando | 12 |
| 2668 | joaquín | 12 |
| 2669 | jerónima | 12 |
| 2670 | ix | 12 |
| 2671 | iría | 12 |
| 2672 | instinto | 12 |
| 2673 | inglaterra | 12 |
| 2674 | inferior | 12 |
| 2675 | inexplicable | 12 |
| 2676 | individuo | 12 |
| 2677 | indecible | 12 |
| 2678 | inclinándose | 12 |
| 2679 | impulsos | 12 |
| 2680 | impertinente | 12 |
| 2681 | horribles | 12 |
| 2682 | hogar | 12 |
| 2683 | guantes | 12 |
| 2684 | grosería | 12 |
| 2685 | gravedad | 12 |
| 2686 | gobernación | 12 |
| 2687 | gatos | 12 |
| 2688 | furioso | 12 |
| 2689 | furiosa | 12 |
| 2690 | frescura | 12 |
| 2691 | forzoso | 12 |
| 2692 | físico | 12 |
| 2693 | falso | 12 |
| 2694 | faldas | 12 |
| 2695 | extrañas | 12 |
| 2696 | exaltación | 12 |
| 2697 | etc | 12 |
| 2698 | estremecer | 12 |
| 2699 | espectáculo | 12 |
| 2700 | escritorio | 12 |
| 2701 | escalones | 12 |
| 2702 | error | 12 |
| 2703 | entré | 12 |
| 2704 | emplear | 12 |
| 2705 | divertirse | 12 |
| 2706 | distinta | 12 |
| 2707 | digno | 12 |
| 2708 | dieran | 12 |
| 2709 | diabla | 12 |
| 2710 | despierto | 12 |
| 2711 | deseado | 12 |
| 2712 | descubierto | 12 |
| 2713 | descompuesto | 12 |
| 2714 | desazón | 12 |
| 2715 | dejara | 12 |
| 2716 | cumplido | 12 |
| 2717 | cuesta | 12 |
| 2718 | cuarta | 12 |
| 2719 | cuadros | 12 |
| 2720 | cruel | 12 |
| 2721 | crítico | 12 |
| 2722 | cría | 12 |
| 2723 | creído | 12 |
| 2724 | costura | 12 |
| 2725 | corrido | 12 |
| 2726 | concluyó | 12 |
| 2727 | concluida | 12 |
| 2728 | compromiso | 12 |
| 2729 | comprendido | 12 |
| 2730 | comprado | 12 |
| 2731 | comían | 12 |
| 2732 | colegio | 12 |
| 2733 | colcha | 12 |
| 2734 | cochero | 12 |
| 2735 | charla | 12 |
| 2736 | cesta | 12 |
| 2737 | cerebral | 12 |
| 2738 | cementerio | 12 |
| 2739 | celestial | 12 |
| 2740 | cavilaciones | 12 |
| 2741 | casadas | 12 |
| 2742 | carlos | 12 |
| 2743 | caracteres | 12 |
| 2744 | aventuras | 12 |
| 2745 | atrevido | 12 |
| 2746 | asesino | 12 |
| 2747 | arrojar | 12 |
| 2748 | arrojando | 12 |
| 2749 | arreglar | 12 |
| 2750 | aparte | 12 |
| 2751 | añadiendo | 12 |
| 2752 | andan | 12 |
| 2753 | amores | 12 |
| 2754 | alrededor | 12 |
| 2755 | alhajas | 12 |
| 2756 | ajeno | 12 |
| 2757 | agujeros | 12 |
| 2758 | aguja | 12 |
| 2759 | advirtió | 12 |
| 2760 | acompañado | 12 |
| 2761 | aceite | 12 |
| 2762 | acaba | 12 |
| 2763 | volveré | 11 |
| 2764 | viveza | 11 |
| 2765 | visitar | 11 |
| 2766 | viéndole | 11 |
| 2767 | viciosa | 11 |
| 2768 | verán | 11 |
| 2769 | vencido | 11 |
| 2770 | vecina | 11 |
| 2771 | veas | 11 |
| 2772 | unidos | 11 |
| 2773 | tuno | 11 |
| 2774 | trastorno | 11 |
| 2775 | trajeron | 11 |
| 2776 | tontas | 11 |
| 2777 | tomándole | 11 |
| 2778 | tiraba | 11 |
| 2779 | tiestos | 11 |
| 2780 | terciopelo | 11 |
| 2781 | tengamos | 11 |
| 2782 | temerosa | 11 |
| 2783 | suyas | 11 |
| 2784 | supe | 11 |
| 2785 | sueltas | 11 |
| 2786 | suele | 11 |
| 2787 | sucio | 11 |
| 2788 | suceder | 11 |
| 2789 | subido | 11 |
| 2790 | sopa | 11 |
| 2791 | sonreír | 11 |
| 2792 | soltaba | 11 |
| 2793 | sociedades | 11 |
| 2794 | sobra | 11 |
| 2795 | simpática | 11 |
| 2796 | siga | 11 |
| 2797 | servido | 11 |
| 2798 | sepas | 11 |
| 2799 | saque | 11 |
| 2800 | salvación | 11 |
| 2801 | sacristán | 11 |
| 2802 | sacan | 11 |
| 2803 | sabemos | 11 |
| 2804 | rossini | 11 |
| 2805 | robado | 11 |
| 2806 | risas | 11 |
| 2807 | restauración | 11 |
| 2808 | respetable | 11 |
| 2809 | relato | 11 |
| 2810 | relativa | 11 |
| 2811 | relación | 11 |
| 2812 | reconozco | 11 |
| 2813 | recelo | 11 |
| 2814 | rayo | 11 |
| 2815 | raya | 11 |
| 2816 | rastro | 11 |
| 2817 | quisieran | 11 |
| 2818 | quieto | 11 |
| 2819 | querías | 11 |
| 2820 | puntos | 11 |
| 2821 | provecho | 11 |
| 2822 | principales | 11 |
| 2823 | posición | 11 |
| 2824 | poseía | 11 |
| 2825 | portero | 11 |
| 2826 | pormenores | 11 |
| 2827 | poniéndole | 11 |
| 2828 | policía | 11 |
| 2829 | podré | 11 |
| 2830 | podemos | 11 |
| 2831 | pintura | 11 |
| 2832 | pesetas | 11 |
| 2833 | pertenecía | 11 |
| 2834 | permitió | 11 |
| 2835 | perdición | 11 |
| 2836 | peores | 11 |
| 2837 | peldaños | 11 |
| 2838 | pega | 11 |
| 2839 | pavo | 11 |
| 2840 | parroquianos | 11 |
| 2841 | paréceme | 11 |
| 2842 | papa | 11 |
| 2843 | palos | 11 |
| 2844 | oírle | 11 |
| 2845 | odio | 11 |
| 2846 | obtener | 11 |
| 2847 | observaba | 11 |
| 2848 | obrador | 11 |
| 2849 | nube | 11 |
| 2850 | novelas | 11 |
| 2851 | muchachos | 11 |
| 2852 | moza | 11 |
| 2853 | movía | 11 |
| 2854 | miro | 11 |
| 2855 | ministro | 11 |
| 2856 | merecido | 11 |
| 2857 | mejilla | 11 |
| 2858 | maternidad | 11 |
| 2859 | materia | 11 |
| 2860 | marfil | 11 |
| 2861 | marchar | 11 |
| 2862 | mantener | 11 |
| 2863 | mande | 11 |
| 2864 | mandado | 11 |
| 2865 | males | 11 |
| 2866 | luna | 11 |
| 2867 | luces | 11 |
| 2868 | llanto | 11 |
| 2869 | ligero | 11 |
| 2870 | levantaba | 11 |
| 2871 | leal | 11 |
| 2872 | lavar | 11 |
| 2873 | inútil | 11 |
| 2874 | insignificante | 11 |
| 2875 | inocencia | 11 |
| 2876 | infidelidad | 11 |
| 2877 | independencia | 11 |
| 2878 | incredulidad | 11 |
| 2879 | ideal | 11 |
| 2880 | huesos | 11 |
| 2881 | hiciese | 11 |
| 2882 | hazte | 11 |
| 2883 | haz | 11 |
| 2884 | harto | 11 |
| 2885 | hallándose | 11 |
| 2886 | haciéndose | 11 |
| 2887 | hablan | 11 |
| 2888 | hablamos | 11 |
| 2889 | hablador | 11 |
| 2890 | gustaban | 11 |
| 2891 | guitarra | 11 |
| 2892 | gorra | 11 |
| 2893 | gasto | 11 |
| 2894 | ganaba | 11 |
| 2895 | furia | 11 |
| 2896 | formando | 11 |
| 2897 | filipinas | 11 |
| 2898 | figurarte | 11 |
| 2899 | favorable | 11 |
| 2900 | farsa | 11 |
| 2901 | fama | 11 |
| 2902 | extraordinaria | 11 |
| 2903 | éxtasis | 11 |
| 2904 | excitación | 11 |
| 2905 | entran | 11 |
| 2906 | enseñar | 11 |
| 2907 | enojo | 11 |
| 2908 | engaño | 11 |
| 2909 | encontraron | 11 |
| 2910 | encendió | 11 |
| 2911 | ejército | 11 |
| 2912 | ejemplos | 11 |
| 2913 | doctor | 11 |
| 2914 | distinguir | 11 |
| 2915 | dispuso | 11 |
| 2916 | disponer | 11 |
| 2917 | dichosa | 11 |
| 2918 | dichas | 11 |
| 2919 | determinó | 11 |
| 2920 | despedirse | 11 |
| 2921 | despecho | 11 |
| 2922 | desear | 11 |
| 2923 | descanso | 11 |
| 2924 | derechos | 11 |
| 2925 | den | 11 |
| 2926 | déjeme | 11 |
| 2927 | dejarla | 11 |
| 2928 | defender | 11 |
| 2929 | decentes | 11 |
| 2930 | decencia | 11 |
| 2931 | debiera | 11 |
| 2932 | deberes | 11 |
| 2933 | dato | 11 |
| 2934 | daré | 11 |
| 2935 | dará | 11 |
| 2936 | daño | 11 |
| 2937 | cuyas | 11 |
| 2938 | cuidar | 11 |
| 2939 | cuente | 11 |
| 2940 | cuartel | 11 |
| 2941 | cuadro | 11 |
| 2942 | criterio | 11 |
| 2943 | costaba | 11 |
| 2944 | cosquillas | 11 |
| 2945 | corto | 11 |
| 2946 | cortado | 11 |
| 2947 | corre | 11 |
| 2948 | continuó | 11 |
| 2949 | consiste | 11 |
| 2950 | considerar | 11 |
| 2951 | consideración | 11 |
| 2952 | condenada | 11 |
| 2953 | comprende | 11 |
| 2954 | comiendo | 11 |
| 2955 | comido | 11 |
| 2956 | comercial | 11 |
| 2957 | cola | 11 |
| 2958 | civilización | 11 |
| 2959 | charlando | 11 |
| 2960 | cerrado | 11 |
| 2961 | cera | 11 |
| 2962 | ceja | 11 |
| 2963 | caricias | 11 |
| 2964 | capas | 11 |
| 2965 | callado | 11 |
| 2966 | breves | 11 |
| 2967 | botones | 11 |
| 2968 | bonitos | 11 |
| 2969 | bonifacio | 11 |
| 2970 | bofetadas | 11 |
| 2971 | bofetada | 11 |
| 2972 | blancos | 11 |
| 2973 | blancas | 11 |
| 2974 | bendición | 11 |
| 2975 | barrios | 11 |
| 2976 | barcelona | 11 |
| 2977 | autor | 11 |
| 2978 | arrepentimiento | 11 |
| 2979 | armas | 11 |
| 2980 | ardiente | 11 |
| 2981 | árboles | 11 |
| 2982 | apuntó | 11 |
| 2983 | animación | 11 |
| 2984 | amistades | 11 |
| 2985 | aliento | 11 |
| 2986 | algodón | 11 |
| 2987 | afecto | 11 |
| 2988 | admirables | 11 |
| 2989 | acostumbrado | 11 |
| 2990 | acostar | 11 |
| 2991 | aburrimiento | 11 |
| 2992 | abre | 11 |
| 2993 | zaragoza | 10 |
| 2994 | zapatos | 10 |
| 2995 | vuelo | 10 |
| 2996 | volvían | 10 |
| 2997 | visiones | 10 |
| 2998 | vieja | 10 |
| 2999 | vestía | 10 |
| 3000 | verbo | 10 |
| 3001 | vencer | 10 |
| 3002 | velar | 10 |
| 3003 | variedad | 10 |
| 3004 | turrón | 10 |
| 3005 | tristes | 10 |
| 3006 | trayendo | 10 |
| 3007 | través | 10 |
| 3008 | trastornada | 10 |
| 3009 | toque | 10 |
| 3010 | tomaron | 10 |
| 3011 | tomaban | 10 |
| 3012 | tiros | 10 |
| 3013 | tipos | 10 |
| 3014 | término | 10 |
| 3015 | tenderos | 10 |
| 3016 | temblaba | 10 |
| 3017 | temas | 10 |
| 3018 | telas | 10 |
| 3019 | taberna | 10 |
| 3020 | sur | 10 |
| 3021 | suelen | 10 |
| 3022 | subían | 10 |
| 3023 | sospecha | 10 |
| 3024 | soñaba | 10 |
| 3025 | sobrinito | 10 |
| 3026 | so | 10 |
| 3027 | sirven | 10 |
| 3028 | sentose | 10 |
| 3029 | sentados | 10 |
| 3030 | sensación | 10 |
| 3031 | sencilla | 10 |
| 3032 | semanas | 10 |
| 3033 | satisfecha | 10 |
| 3034 | salvo | 10 |
| 3035 | salga | 10 |
| 3036 | sacramento | 10 |
| 3037 | sabrá | 10 |
| 3038 | sabios | 10 |
| 3039 | ronca | 10 |
| 3040 | ridículo | 10 |
| 3041 | responsabilidad | 10 |
| 3042 | resistencia | 10 |
| 3043 | reposo | 10 |
| 3044 | relucir | 10 |
| 3045 | religioso | 10 |
| 3046 | reinaba | 10 |
| 3047 | redonda | 10 |
| 3048 | ratón | 10 |
| 3049 | ramsés | 10 |
| 3050 | quizá | 10 |
| 3051 | quise | 10 |
| 3052 | queja | 10 |
| 3053 | puse | 10 |
| 3054 | puños | 10 |
| 3055 | puñal | 10 |
| 3056 | pulgas | 10 |
| 3057 | proyecto | 10 |
| 3058 | proposición | 10 |
| 3059 | prometió | 10 |
| 3060 | produjo | 10 |
| 3061 | producía | 10 |
| 3062 | primogénito | 10 |
| 3063 | prestaba | 10 |
| 3064 | presentaba | 10 |
| 3065 | presenta | 10 |
| 3066 | preguntarle | 10 |
| 3067 | precio | 10 |
| 3068 | postura | 10 |
| 3069 | ponte | 10 |
| 3070 | pobrecita | 10 |
| 3071 | platos | 10 |
| 3072 | pizca | 10 |
| 3073 | piel | 10 |
| 3074 | pesadilla | 10 |
| 3075 | permiso | 10 |
| 3076 | periódico | 10 |
| 3077 | perdono | 10 |
| 3078 | peines | 10 |
| 3079 | pedía | 10 |
| 3080 | pata | 10 |
| 3081 | pascual | 10 |
| 3082 | pareces | 10 |
| 3083 | paquetes | 10 |
| 3084 | papeletas | 10 |
| 3085 | paloma | 10 |
| 3086 | palmadas | 10 |
| 3087 | palillo | 10 |
| 3088 | paga | 10 |
| 3089 | padrino | 10 |
| 3090 | padilla | 10 |
| 3091 | oyose | 10 |
| 3092 | orgullosa | 10 |
| 3093 | oreja | 10 |
| 3094 | operación | 10 |
| 3095 | oídos | 10 |
| 3096 | ofrece | 10 |
| 3097 | obispo | 10 |
| 3098 | nota | 10 |
| 3099 | nobleza | 10 |
| 3100 | negar | 10 |
| 3101 | navidad | 10 |
| 3102 | nacional | 10 |
| 3103 | músculos | 10 |
| 3104 | municipal | 10 |
| 3105 | morales | 10 |
| 3106 | moneda | 10 |
| 3107 | molestia | 10 |
| 3108 | mismamente | 10 |
| 3109 | misión | 10 |
| 3110 | miren | 10 |
| 3111 | miras | 10 |
| 3112 | mirándole | 10 |
| 3113 | millones | 10 |
| 3114 | milagro | 10 |
| 3115 | miel | 10 |
| 3116 | mesilla | 10 |
| 3117 | menudencias | 10 |
| 3118 | menester | 10 |
| 3119 | mayo | 10 |
| 3120 | materialismo | 10 |
| 3121 | mármol | 10 |
| 3122 | mañas | 10 |
| 3123 | mantas | 10 |
| 3124 | manicomio | 10 |
| 3125 | mangas | 10 |
| 3126 | maneras | 10 |
| 3127 | maldad | 10 |
| 3128 | magnífico | 10 |
| 3129 | maderas | 10 |
| 3130 | lloraba | 10 |
| 3131 | lleve | 10 |
| 3132 | llenó | 10 |
| 3133 | llamaron | 10 |
| 3134 | listo | 10 |
| 3135 | línea | 10 |
| 3136 | leído | 10 |
| 3137 | juventud | 10 |
| 3138 | juárez | 10 |
| 3139 | josefinas | 10 |
| 3140 | isidro | 10 |
| 3141 | insolente | 10 |
| 3142 | inquieto | 10 |
| 3143 | inocentes | 10 |
| 3144 | inmediato | 10 |
| 3145 | inmediata | 10 |
| 3146 | inglesa | 10 |
| 3147 | infelices | 10 |
| 3148 | infalible | 10 |
| 3149 | inconveniente | 10 |
| 3150 | imposibles | 10 |
| 3151 | imponía | 10 |
| 3152 | imperio | 10 |
| 3153 | iglesias | 10 |
| 3154 | hola | 10 |
| 3155 | hojas | 10 |
| 3156 | hayas | 10 |
| 3157 | harás | 10 |
| 3158 | hacerla | 10 |
| 3159 | habrías | 10 |
| 3160 | hablo | 10 |
| 3161 | haberle | 10 |
| 3162 | haberla | 10 |
| 3163 | guardo | 10 |
| 3164 | grandísima | 10 |
| 3165 | gozosa | 10 |
| 3166 | fuesen | 10 |
| 3167 | fuertemente | 10 |
| 3168 | frenesí | 10 |
| 3169 | formal | 10 |
| 3170 | física | 10 |
| 3171 | fatiga | 10 |
| 3172 | facultad | 10 |
| 3173 | extravagancias | 10 |
| 3174 | experiencia | 10 |
| 3175 | existía | 10 |
| 3176 | exaltado | 10 |
| 3177 | ex | 10 |
| 3178 | eulalia | 10 |
| 3179 | eterno | 10 |
| 3180 | estudios | 10 |
| 3181 | estrella | 10 |
| 3182 | estate | 10 |
| 3183 | estando | 10 |
| 3184 | estallido | 10 |
| 3185 | espero | 10 |
| 3186 | escapó | 10 |
| 3187 | envuelto | 10 |
| 3188 | entro | 10 |
| 3189 | entretenía | 10 |
| 3190 | endivido | 10 |
| 3191 | encontrando | 10 |
| 3192 | elegantes | 10 |
| 3193 | elegancia | 10 |
| 3194 | efusión | 10 |
| 3195 | efectivamente | 10 |
| 3196 | eché | 10 |
| 3197 | echan | 10 |
| 3198 | duermo | 10 |
| 3199 | dudar | 10 |
| 3200 | dolores | 10 |
| 3201 | dolía | 10 |
| 3202 | diversos | 10 |
| 3203 | disputa | 10 |
| 3204 | disposiciones | 10 |
| 3205 | discurrió | 10 |
| 3206 | disco | 10 |
| 3207 | director | 10 |
| 3208 | dirás | 10 |
| 3209 | dirán | 10 |
| 3210 | desvaríos | 10 |
| 3211 | despierta | 10 |
| 3212 | desesperación | 10 |
| 3213 | descuido | 10 |
| 3214 | desconocida | 10 |
| 3215 | descompuesta | 10 |
| 3216 | deogracias | 10 |
| 3217 | dejase | 10 |
| 3218 | dejarse | 10 |
| 3219 | declaraba | 10 |
| 3220 | datos | 10 |
| 3221 | darte | 10 |
| 3222 | darme | 10 |
| 3223 | dame | 10 |
| 3224 | dábale | 10 |
| 3225 | cuestiones | 10 |
| 3226 | cuba | 10 |
| 3227 | criminal | 10 |
| 3228 | crédito | 10 |
| 3229 | corrida | 10 |
| 3230 | corrección | 10 |
| 3231 | contando | 10 |
| 3232 | conoció | 10 |
| 3233 | conocían | 10 |
| 3234 | conjunto | 10 |
| 3235 | condenado | 10 |
| 3236 | comunicaba | 10 |
| 3237 | cometido | 10 |
| 3238 | comerciante | 10 |
| 3239 | comedias | 10 |
| 3240 | coma | 10 |
| 3241 | cobre | 10 |
| 3242 | ciudad | 10 |
| 3243 | cigarro | 10 |
| 3244 | chaleco | 10 |
| 3245 | cesar | 10 |
| 3246 | cerrando | 10 |
| 3247 | ceremonia | 10 |
| 3248 | ceño | 10 |
| 3249 | catorce | 10 |
| 3250 | castigo | 10 |
| 3251 | casarme | 10 |
| 3252 | carro | 10 |
| 3253 | canas | 10 |
| 3254 | caballerito | 10 |
| 3255 | burla | 10 |
| 3256 | bota | 10 |
| 3257 | borde | 10 |
| 3258 | blas | 10 |
| 3259 | bebida | 10 |
| 3260 | barbas | 10 |
| 3261 | auxilio | 10 |
| 3262 | ausencia | 10 |
| 3263 | atreverse | 10 |
| 3264 | asegurar | 10 |
| 3265 | arreglará | 10 |
| 3266 | armonía | 10 |
| 3267 | apresuró | 10 |
| 3268 | aparecía | 10 |
| 3269 | anunciaba | 10 |
| 3270 | antonia | 10 |
| 3271 | angustia | 10 |
| 3272 | andrés | 10 |
| 3273 | amparo | 10 |
| 3274 | ambiente | 10 |
| 3275 | amada | 10 |
| 3276 | amable | 10 |
| 3277 | alumnos | 10 |
| 3278 | almohada | 10 |
| 3279 | almacén | 10 |
| 3280 | alargando | 10 |
| 3281 | agujero | 10 |
| 3282 | agradaba | 10 |
| 3283 | advertir | 10 |
| 3284 | adquirir | 10 |
| 3285 | adquirido | 10 |
| 3286 | administración | 10 |
| 3287 | acostumbrada | 10 |
| 3288 | acecho | 10 |
| 3289 | abrazo | 10 |
| 3290 | abandono | 10 |
| 3291 | zancuda | 9 |
| 3292 | zalamerías | 9 |
| 3293 | yema | 9 |
| 3294 | volviéndose | 9 |
| 3295 | vivían | 9 |
| 3296 | vivamente | 9 |
| 3297 | virtuosa | 9 |
| 3298 | vidas | 9 |
| 3299 | viático | 9 |
| 3300 | viajes | 9 |
| 3301 | verlas | 9 |
| 3302 | vería | 9 |
| 3303 | verdugo | 9 |
| 3304 | vendía | 9 |
| 3305 | veis | 9 |
| 3306 | ved | 9 |
| 3307 | varonil | 9 |
| 3308 | varón | 9 |
| 3309 | vallejo | 9 |
| 3310 | vacío | 9 |
| 3311 | vacía | 9 |
| 3312 | u | 9 |
| 3313 | tronco | 9 |
| 3314 | tratara | 9 |
| 3315 | trajes | 9 |
| 3316 | traiga | 9 |
| 3317 | tragaba | 9 |
| 3318 | traen | 9 |
| 3319 | tontín | 9 |
| 3320 | tom | 9 |
| 3321 | tolerancia | 9 |
| 3322 | tenedor | 9 |
| 3323 | tarea | 9 |
| 3324 | suplicio | 9 |
| 3325 | súbito | 9 |
| 3326 | sosegada | 9 |
| 3327 | solemne | 9 |
| 3328 | soldados | 9 |
| 3329 | sirvió | 9 |
| 3330 | siguientes | 9 |
| 3331 | setiembre | 9 |
| 3332 | señalando | 9 |
| 3333 | semejantes | 9 |
| 3334 | santos | 9 |
| 3335 | sana | 9 |
| 3336 | salvajes | 9 |
| 3337 | salva | 9 |
| 3338 | salta | 9 |
| 3339 | saliva | 9 |
| 3340 | salí | 9 |
| 3341 | saldría | 9 |
| 3342 | sacrificio | 9 |
| 3343 | sacarle | 9 |
| 3344 | sabían | 9 |
| 3345 | ronda | 9 |
| 3346 | ríe | 9 |
| 3347 | resultaba | 9 |
| 3348 | resuelto | 9 |
| 3349 | respetar | 9 |
| 3350 | repugnancia | 9 |
| 3351 | renglón | 9 |
| 3352 | reino | 9 |
| 3353 | regocijo | 9 |
| 3354 | redondo | 9 |
| 3355 | recién | 9 |
| 3356 | rasgo | 9 |
| 3357 | raro | 9 |
| 3358 | quitándose | 9 |
| 3359 | quedé | 9 |
| 3360 | purísima | 9 |
| 3361 | puntillas | 9 |
| 3362 | puntas | 9 |
| 3363 | pulmones | 9 |
| 3364 | puedas | 9 |
| 3365 | pudieran | 9 |
| 3366 | propiedad | 9 |
| 3367 | propiamente | 9 |
| 3368 | primitivo | 9 |
| 3369 | prim | 9 |
| 3370 | presentó | 9 |
| 3371 | preparaba | 9 |
| 3372 | precioso | 9 |
| 3373 | portería | 9 |
| 3374 | portamonedas | 9 |
| 3375 | popular | 9 |
| 3376 | ponce | 9 |
| 3377 | pólvora | 9 |
| 3378 | poeta | 9 |
| 3379 | plantón | 9 |
| 3380 | pitusín | 9 |
| 3381 | pillín | 9 |
| 3382 | piden | 9 |
| 3383 | picos | 9 |
| 3384 | pícaro | 9 |
| 3385 | pi | 9 |
| 3386 | permitían | 9 |
| 3387 | perfil | 9 |
| 3388 | perfecto | 9 |
| 3389 | perdiendo | 9 |
| 3390 | pensativo | 9 |
| 3391 | penitencia | 9 |
| 3392 | pater | 9 |
| 3393 | patatas | 9 |
| 3394 | pasara | 9 |
| 3395 | párpado | 9 |
| 3396 | pareciole | 9 |
| 3397 | pardo | 9 |
| 3398 | paraíso | 9 |
| 3399 | papás | 9 |
| 3400 | pájara | 9 |
| 3401 | pagaba | 9 |
| 3402 | ocultar | 9 |
| 3403 | números | 9 |
| 3404 | necesitas | 9 |
| 3405 | necesidades | 9 |
| 3406 | napoleón | 9 |
| 3407 | nación | 9 |
| 3408 | mundano | 9 |
| 3409 | mu | 9 |
| 3410 | mover | 9 |
| 3411 | mostrarse | 9 |
| 3412 | mostrar | 9 |
| 3413 | mono | 9 |
| 3414 | molina | 9 |
| 3415 | modas | 9 |
| 3416 | misteriosa | 9 |
| 3417 | misterio | 9 |
| 3418 | miran | 9 |
| 3419 | míos | 9 |
| 3420 | minuto | 9 |
| 3421 | meterle | 9 |
| 3422 | merluza | 9 |
| 3423 | merecía | 9 |
| 3424 | mereces | 9 |
| 3425 | mercado | 9 |
| 3426 | mentiras | 9 |
| 3427 | meditaciones | 9 |
| 3428 | matrimonios | 9 |
| 3429 | materna | 9 |
| 3430 | máscara | 9 |
| 3431 | martirio | 9 |
| 3432 | mantones | 9 |
| 3433 | mantilla | 9 |
| 3434 | magdalena | 9 |
| 3435 | llevaban | 9 |
| 3436 | llenaba | 9 |
| 3437 | llegue | 9 |
| 3438 | llamas | 9 |
| 3439 | llamando | 9 |
| 3440 | leyó | 9 |
| 3441 | levantado | 9 |
| 3442 | letrero | 9 |
| 3443 | largos | 9 |
| 3444 | lana | 9 |
| 3445 | lámpara | 9 |
| 3446 | ladrones | 9 |
| 3447 | ladrona | 9 |
| 3448 | judías | 9 |
| 3449 | jarabe | 9 |
| 3450 | jacinto | 9 |
| 3451 | jabón | 9 |
| 3452 | irá | 9 |
| 3453 | íntima | 9 |
| 3454 | intentó | 9 |
| 3455 | inspirado | 9 |
| 3456 | insistió | 9 |
| 3457 | insignificantes | 9 |
| 3458 | ingenio | 9 |
| 3459 | indulgente | 9 |
| 3460 | indudablemente | 9 |
| 3461 | indignación | 9 |
| 3462 | indiferencia | 9 |
| 3463 | indecentes | 9 |
| 3464 | incluso | 9 |
| 3465 | inclusa | 9 |
| 3466 | inclinó | 9 |
| 3467 | implacable | 9 |
| 3468 | imperial | 9 |
| 3469 | impaciencia | 9 |
| 3470 | ídolo | 9 |
| 3471 | humilde | 9 |
| 3472 | hule | 9 |
| 3473 | huéspedes | 9 |
| 3474 | huecos | 9 |
| 3475 | horizonte | 9 |
| 3476 | horacio | 9 |
| 3477 | honra | 9 |
| 3478 | heredero | 9 |
| 3479 | hagan | 9 |
| 3480 | habido | 9 |
| 3481 | guarda | 9 |
| 3482 | gruesa | 9 |
| 3483 | gritando | 9 |
| 3484 | gritaba | 9 |
| 3485 | gracioso | 9 |
| 3486 | gota | 9 |
| 3487 | goces | 9 |
| 3488 | goce | 9 |
| 3489 | gobernar | 9 |
| 3490 | gobernador | 9 |
| 3491 | gastaba | 9 |
| 3492 | gasta | 9 |
| 3493 | gala | 9 |
| 3494 | función | 9 |
| 3495 | fuensanta | 9 |
| 3496 | fresa | 9 |
| 3497 | freno | 9 |
| 3498 | finca | 9 |
| 3499 | filósofo | 9 |
| 3500 | fila | 9 |
| 3501 | fijó | 9 |
| 3502 | figurado | 9 |
| 3503 | figurábase | 9 |
| 3504 | fiesta | 9 |
| 3505 | fiereza | 9 |
| 3506 | febrero | 9 |
| 3507 | fatigado | 9 |
| 3508 | familiar | 9 |
| 3509 | faena | 9 |
| 3510 | extravagantes | 9 |
| 3511 | exterior | 9 |
| 3512 | extendió | 9 |
| 3513 | expresándose | 9 |
| 3514 | exclusivamente | 9 |
| 3515 | excelentes | 9 |
| 3516 | examinaba | 9 |
| 3517 | examen | 9 |
| 3518 | evangelio | 9 |
| 3519 | estúpida | 9 |
| 3520 | estudiante | 9 |
| 3521 | estrépito | 9 |
| 3522 | estatura | 9 |
| 3523 | estarse | 9 |
| 3524 | estábamos | 9 |
| 3525 | especialidad | 9 |
| 3526 | españoles | 9 |
| 3527 | espaldas | 9 |
| 3528 | escrito | 9 |
| 3529 | escenas | 9 |
| 3530 | escalón | 9 |
| 3531 | entrole | 9 |
| 3532 | entrecejo | 9 |
| 3533 | entrase | 9 |
| 3534 | entiendes | 9 |
| 3535 | entere | 9 |
| 3536 | engracia | 9 |
| 3537 | enemigos | 9 |
| 3538 | encendido | 9 |
| 3539 | encendida | 9 |
| 3540 | empleados | 9 |
| 3541 | empieza | 9 |
| 3542 | durmiendo | 9 |
| 3543 | dulzura | 9 |
| 3544 | dotes | 9 |
| 3545 | dosis | 9 |
| 3546 | donaire | 9 |
| 3547 | docena | 9 |
| 3548 | distracción | 9 |
| 3549 | distinto | 9 |
| 3550 | dijese | 9 |
| 3551 | dificultad | 9 |
| 3552 | diciembre | 9 |
| 3553 | diario | 9 |
| 3554 | diálogo | 9 |
| 3555 | dialéctica | 9 |
| 3556 | deuda | 9 |
| 3557 | determinación | 9 |
| 3558 | detalles | 9 |
| 3559 | desventurado | 9 |
| 3560 | descuida | 9 |
| 3561 | desapareció | 9 |
| 3562 | depósito | 9 |
| 3563 | demente | 9 |
| 3564 | demencia | 9 |
| 3565 | delirante | 9 |
| 3566 | delincuente | 9 |
| 3567 | déjese | 9 |
| 3568 | defendía | 9 |
| 3569 | cuyos | 9 |
| 3570 | cubierto | 9 |
| 3571 | créelo | 9 |
| 3572 | costó | 9 |
| 3573 | corredores | 9 |
| 3574 | coro | 9 |
| 3575 | corbata | 9 |
| 3576 | contestación | 9 |
| 3577 | contenerse | 9 |
| 3578 | consideraba | 9 |
| 3579 | consentir | 9 |
| 3580 | conseguido | 9 |
| 3581 | confesar | 9 |
| 3582 | comunes | 9 |
| 3583 | comentarios | 9 |
| 3584 | comen | 9 |
| 3585 | colocar | 9 |
| 3586 | colocación | 9 |
| 3587 | cogiéndola | 9 |
| 3588 | cobrar | 9 |
| 3589 | cinta | 9 |
| 3590 | ciertamente | 9 |
| 3591 | ciega | 9 |
| 3592 | cesaba | 9 |
| 3593 | cerrar | 9 |
| 3594 | cena | 9 |
| 3595 | celda | 9 |
| 3596 | casados | 9 |
| 3597 | carros | 9 |
| 3598 | carmen | 9 |
| 3599 | capricho | 9 |
| 3600 | cantaba | 9 |
| 3601 | cansancio | 9 |
| 3602 | cálculo | 9 |
| 3603 | calamidad | 9 |
| 3604 | cádiz | 9 |
| 3605 | caballos | 9 |
| 3606 | bronce | 9 |
| 3607 | bolsillos | 9 |
| 3608 | bocado | 9 |
| 3609 | boba | 9 |
| 3610 | beneficencia | 9 |
| 3611 | bendita | 9 |
| 3612 | bastantes | 9 |
| 3613 | barro | 9 |
| 3614 | banca | 9 |
| 3615 | balbució | 9 |
| 3616 | bailar | 9 |
| 3617 | atmósfera | 9 |
| 3618 | atentamente | 9 |
| 3619 | atendía | 9 |
| 3620 | asustada | 9 |
| 3621 | aseo | 9 |
| 3622 | ascuas | 9 |
| 3623 | artes | 9 |
| 3624 | arrojó | 9 |
| 3625 | arrepentida | 9 |
| 3626 | arreglando | 9 |
| 3627 | aprender | 9 |
| 3628 | apostamos | 9 |
| 3629 | apartaba | 9 |
| 3630 | antipático | 9 |
| 3631 | anteayer | 9 |
| 3632 | anhelo | 9 |
| 3633 | alzaba | 9 |
| 3634 | almirez | 9 |
| 3635 | algazara | 9 |
| 3636 | alfonso | 9 |
| 3637 | alcalde | 9 |
| 3638 | alargó | 9 |
| 3639 | afuera | 9 |
| 3640 | afligida | 9 |
| 3641 | afectos | 9 |
| 3642 | acuerda | 9 |
| 3643 | acordose | 9 |
| 3644 | acercarse | 9 |
| 3645 | acercándose | 9 |
| 3646 | aceptar | 9 |
| 3647 | aburrido | 9 |
| 3648 | absoluto | 9 |
| 3649 | abiertos | 9 |
| 3650 | zapatería | 8 |
| 3651 | yeso | 8 |
| 3652 | x | 8 |
| 3653 | volviose | 8 |
| 3654 | vivienda | 8 |
| 3655 | vivas | 8 |
| 3656 | vistazo | 8 |
| 3657 | viniese | 8 |
| 3658 | viese | 8 |
| 3659 | viejas | 8 |
| 3660 | victoria | 8 |
| 3661 | veréis | 8 |
| 3662 | veré | 8 |
| 3663 | veneno | 8 |
| 3664 | véase | 8 |
| 3665 | vámonos | 8 |
| 3666 | usar | 8 |
| 3667 | usan | 8 |
| 3668 | unión | 8 |
| 3669 | trujillos | 8 |
| 3670 | trataban | 8 |
| 3671 | traspaso | 8 |
| 3672 | transeúntes | 8 |
| 3673 | trago | 8 |
| 3674 | tos | 8 |
| 3675 | tomaría | 8 |
| 3676 | tirón | 8 |
| 3677 | tino | 8 |
| 3678 | tinieblas | 8 |
| 3679 | timo | 8 |
| 3680 | tilín | 8 |
| 3681 | teta | 8 |
| 3682 | tertulias | 8 |
| 3683 | ternura | 8 |
| 3684 | tercer | 8 |
| 3685 | temporada | 8 |
| 3686 | temblar | 8 |
| 3687 | supuesto | 8 |
| 3688 | superiores | 8 |
| 3689 | sumisión | 8 |
| 3690 | sujetos | 8 |
| 3691 | suelos | 8 |
| 3692 | sudor | 8 |
| 3693 | subida | 8 |
| 3694 | sordo | 8 |
| 3695 | sinvergüenza | 8 |
| 3696 | singular | 8 |
| 3697 | siglos | 8 |
| 3698 | siéntese | 8 |
| 3699 | sienten | 8 |
| 3700 | siéntate | 8 |
| 3701 | sienta | 8 |
| 3702 | seso | 8 |
| 3703 | señorío | 8 |
| 3704 | sentíase | 8 |
| 3705 | sentí | 8 |
| 3706 | semejanza | 8 |
| 3707 | seguían | 8 |
| 3708 | sed | 8 |
| 3709 | secar | 8 |
| 3710 | samaniegas | 8 |
| 3711 | salvar | 8 |
| 3712 | salmerón | 8 |
| 3713 | saldrá | 8 |
| 3714 | salado | 8 |
| 3715 | sacaron | 8 |
| 3716 | sabiduría | 8 |
| 3717 | rompiendo | 8 |
| 3718 | rompía | 8 |
| 3719 | rompe | 8 |
| 3720 | rojos | 8 |
| 3721 | rodando | 8 |
| 3722 | riéndose | 8 |
| 3723 | rezando | 8 |
| 3724 | revelación | 8 |
| 3725 | retirado | 8 |
| 3726 | resplandor | 8 |
| 3727 | reñir | 8 |
| 3728 | relimpio | 8 |
| 3729 | reina | 8 |
| 3730 | redentor | 8 |
| 3731 | rectitud | 8 |
| 3732 | recordar | 8 |
| 3733 | recordando | 8 |
| 3734 | reconocer | 8 |
| 3735 | reconciliación | 8 |
| 3736 | recogiendo | 8 |
| 3737 | rayas | 8 |
| 3738 | rápido | 8 |
| 3739 | rapidez | 8 |
| 3740 | rápida | 8 |
| 3741 | ramos | 8 |
| 3742 | rabiar | 8 |
| 3743 | quitaban | 8 |
| 3744 | queremos | 8 |
| 3745 | pusieran | 8 |
| 3746 | pulmonía | 8 |
| 3747 | pueril | 8 |
| 3748 | próximas | 8 |
| 3749 | protege | 8 |
| 3750 | propósitos | 8 |
| 3751 | proponía | 8 |
| 3752 | promesa | 8 |
| 3753 | procuraba | 8 |
| 3754 | proceder | 8 |
| 3755 | problemas | 8 |
| 3756 | probablemente | 8 |
| 3757 | probable | 8 |
| 3758 | pretextos | 8 |
| 3759 | presupuesto | 8 |
| 3760 | préstamo | 8 |
| 3761 | preso | 8 |
| 3762 | presa | 8 |
| 3763 | preguntando | 8 |
| 3764 | portarse | 8 |
| 3765 | poníase | 8 |
| 3766 | pongas | 8 |
| 3767 | político | 8 |
| 3768 | podríamos | 8 |
| 3769 | pliegues | 8 |
| 3770 | plenitud | 8 |
| 3771 | placer | 8 |
| 3772 | pintada | 8 |
| 3773 | picaba | 8 |
| 3774 | piano | 8 |
| 3775 | personales | 8 |
| 3776 | perra | 8 |
| 3777 | permaneció | 8 |
| 3778 | perdí | 8 |
| 3779 | percha | 8 |
| 3780 | pequeñuelo | 8 |
| 3781 | penitente | 8 |
| 3782 | penetrar | 8 |
| 3783 | peligros | 8 |
| 3784 | peine | 8 |
| 3785 | paternal | 8 |
| 3786 | patadas | 8 |
| 3787 | pastor | 8 |
| 3788 | pasmada | 8 |
| 3789 | pasaría | 8 |
| 3790 | pasados | 8 |
| 3791 | partía | 8 |
| 3792 | parroquiano | 8 |
| 3793 | pardos | 8 |
| 3794 | paños | 8 |
| 3795 | pañolería | 8 |
| 3796 | panderetas | 8 |
| 3797 | pálido | 8 |
| 3798 | palacio | 8 |
| 3799 | paisaje | 8 |
| 3800 | padecido | 8 |
| 3801 | oscura | 8 |
| 3802 | origen | 8 |
| 3803 | oriente | 8 |
| 3804 | ópera | 8 |
| 3805 | onda | 8 |
| 3806 | olvido | 8 |
| 3807 | olvidaba | 8 |
| 3808 | ojalá | 8 |
| 3809 | ofrecido | 8 |
| 3810 | oficina | 8 |
| 3811 | ofendida | 8 |
| 3812 | observaciones | 8 |
| 3813 | obligaciones | 8 |
| 3814 | novios | 8 |
| 3815 | nobles | 8 |
| 3816 | naranja | 8 |
| 3817 | muestras | 8 |
| 3818 | muestra | 8 |
| 3819 | movida | 8 |
| 3820 | mostró | 8 |
| 3821 | moría | 8 |
| 3822 | molino | 8 |
| 3823 | molestaba | 8 |
| 3824 | misterioso | 8 |
| 3825 | misántropo | 8 |
| 3826 | mezcla | 8 |
| 3827 | meta | 8 |
| 3828 | menuda | 8 |
| 3829 | melancolía | 8 |
| 3830 | meditación | 8 |
| 3831 | medir | 8 |
| 3832 | mediodía | 8 |
| 3833 | mayormente | 8 |
| 3834 | matrimonial | 8 |
| 3835 | mato | 8 |
| 3836 | matarme | 8 |
| 3837 | marchaba | 8 |
| 3838 | maravilla | 8 |
| 3839 | maña | 8 |
| 3840 | manifestaba | 8 |
| 3841 | manchas | 8 |
| 3842 | lustre | 8 |
| 3843 | lúgubre | 8 |
| 3844 | locos | 8 |
| 3845 | llevas | 8 |
| 3846 | llevarse | 8 |
| 3847 | llenas | 8 |
| 3848 | llamo | 8 |
| 3849 | llamarse | 8 |
| 3850 | ligera | 8 |
| 3851 | leyendo | 8 |
| 3852 | levanto | 8 |
| 3853 | lelo | 8 |
| 3854 | lela | 8 |
| 3855 | legua | 8 |
| 3856 | legítima | 8 |
| 3857 | latines | 8 |
| 3858 | labor | 8 |
| 3859 | junta | 8 |
| 3860 | juicioso | 8 |
| 3861 | juegos | 8 |
| 3862 | jota | 8 |
| 3863 | joaquinito | 8 |
| 3864 | irás | 8 |
| 3865 | interesaba | 8 |
| 3866 | instintos | 8 |
| 3867 | inspira | 8 |
| 3868 | insoportable | 8 |
| 3869 | insana | 8 |
| 3870 | inquieta | 8 |
| 3871 | inmóvil | 8 |
| 3872 | inmediatamente | 8 |
| 3873 | injurias | 8 |
| 3874 | ingleses | 8 |
| 3875 | infernal | 8 |
| 3876 | industria | 8 |
| 3877 | impaciente | 8 |
| 3878 | ilusiones | 8 |
| 3879 | ignominia | 8 |
| 3880 | hospital | 8 |
| 3881 | horteras | 8 |
| 3882 | honradas | 8 |
| 3883 | hízole | 8 |
| 3884 | hiel | 8 |
| 3885 | hermosas | 8 |
| 3886 | hazme | 8 |
| 3887 | harías | 8 |
| 3888 | hagamos | 8 |
| 3889 | hábito | 8 |
| 3890 | haberme | 8 |
| 3891 | guardó | 8 |
| 3892 | guardando | 8 |
| 3893 | guardado | 8 |
| 3894 | guapas | 8 |
| 3895 | gozaba | 8 |
| 3896 | gordos | 8 |
| 3897 | glacial | 8 |
| 3898 | gestos | 8 |
| 3899 | generoso | 8 |
| 3900 | garbanzos | 8 |
| 3901 | fugaz | 8 |
| 3902 | fruto | 8 |
| 3903 | fraternal | 8 |
| 3904 | formar | 8 |
| 3905 | fondos | 8 |
| 3906 | finísimo | 8 |
| 3907 | fingiendo | 8 |
| 3908 | felisa | 8 |
| 3909 | faltar | 8 |
| 3910 | extraños | 8 |
| 3911 | exactamente | 8 |
| 3912 | estudiantes | 8 |
| 3913 | estimación | 8 |
| 3914 | estarás | 8 |
| 3915 | estabas | 8 |
| 3916 | espectro | 8 |
| 3917 | espada | 8 |
| 3918 | esencial | 8 |
| 3919 | escondite | 8 |
| 3920 | escoba | 8 |
| 3921 | escapaba | 8 |
| 3922 | equivocado | 8 |
| 3923 | envuelta | 8 |
| 3924 | entereza | 8 |
| 3925 | enterando | 8 |
| 3926 | entendido | 8 |
| 3927 | enseñaba | 8 |
| 3928 | enseña | 8 |
| 3929 | enormes | 8 |
| 3930 | enfermedades | 8 |
| 3931 | enfadar | 8 |
| 3932 | empleo | 8 |
| 3933 | egoísmo | 8 |
| 3934 | edades | 8 |
| 3935 | económica | 8 |
| 3936 | echose | 8 |
| 3937 | echamos | 8 |
| 3938 | dulces | 8 |
| 3939 | dueña | 8 |
| 3940 | dudo | 8 |
| 3941 | doscientos | 8 |
| 3942 | dominar | 8 |
| 3943 | dominaba | 8 |
| 3944 | doméstico | 8 |
| 3945 | doméstica | 8 |
| 3946 | doble | 8 |
| 3947 | divinidad | 8 |
| 3948 | discutir | 8 |
| 3949 | discusión | 8 |
| 3950 | discurrir | 8 |
| 3951 | discreto | 8 |
| 3952 | discreta | 8 |
| 3953 | discreción | 8 |
| 3954 | diligencia | 8 |
| 3955 | digna | 8 |
| 3956 | dichosos | 8 |
| 3957 | determinado | 8 |
| 3958 | despertaba | 8 |
| 3959 | despedida | 8 |
| 3960 | desnudo | 8 |
| 3961 | desconcertó | 8 |
| 3962 | desasosiego | 8 |
| 3963 | desaparecido | 8 |
| 3964 | dentadura | 8 |
| 3965 | delicadeza | 8 |
| 3966 | dejes | 8 |
| 3967 | dejé | 8 |
| 3968 | defectos | 8 |
| 3969 | declaración | 8 |
| 3970 | decidido | 8 |
| 3971 | decidida | 8 |
| 3972 | dátiles | 8 |
| 3973 | curso | 8 |
| 3974 | culto | 8 |
| 3975 | cuidadosamente | 8 |
| 3976 | cuidados | 8 |
| 3977 | cuidaba | 8 |
| 3978 | cuerpos | 8 |
| 3979 | cuántos | 8 |
| 3980 | cuánta | 8 |
| 3981 | cristal | 8 |
| 3982 | criar | 8 |
| 3983 | crianza | 8 |
| 3984 | cráneo | 8 |
| 3985 | costado | 8 |
| 3986 | coser | 8 |
| 3987 | cortinas | 8 |
| 3988 | corrillo | 8 |
| 3989 | cordura | 8 |
| 3990 | corazones | 8 |
| 3991 | conversaciones | 8 |
| 3992 | contrabando | 8 |
| 3993 | contacto | 8 |
| 3994 | conste | 8 |
| 3995 | consistía | 8 |
| 3996 | considerablemente | 8 |
| 3997 | confusa | 8 |
| 3998 | conformidad | 8 |
| 3999 | conflicto | 8 |
| 4000 | condiciones | 8 |
| 4001 | competencia | 8 |
| 4002 | comisión | 8 |
| 4003 | comiéndose | 8 |
| 4004 | comentario | 8 |
| 4005 | colorada | 8 |
| 4006 | clavos | 8 |
| 4007 | clavo | 8 |
| 4008 | clarito | 8 |
| 4009 | civil | 8 |
| 4010 | cirila | 8 |
| 4011 | cesto | 8 |
| 4012 | cerrojo | 8 |
| 4013 | cerraba | 8 |
| 4014 | centinela | 8 |
| 4015 | caza | 8 |
| 4016 | castillo | 8 |
| 4017 | castiga | 8 |
| 4018 | casorio | 8 |
| 4019 | carita | 8 |
| 4020 | cariñoso | 8 |
| 4021 | cargado | 8 |
| 4022 | cambiado | 8 |
| 4023 | calló | 8 |
| 4024 | callaba | 8 |
| 4025 | calla | 8 |
| 4026 | cálculos | 8 |
| 4027 | cabra | 8 |
| 4028 | cabos | 8 |
| 4029 | cabe | 8 |
| 4030 | caballeros | 8 |
| 4031 | buscarle | 8 |
| 4032 | burro | 8 |
| 4033 | brillaban | 8 |
| 4034 | boticario | 8 |
| 4035 | bomba | 8 |
| 4036 | bolsa | 8 |
| 4037 | bigote | 8 |
| 4038 | basilisco | 8 |
| 4039 | bárbaro | 8 |
| 4040 | bajito | 8 |
| 4041 | bacalao | 8 |
| 4042 | aumentaba | 8 |
| 4043 | atrevimiento | 8 |
| 4044 | asusta | 8 |
| 4045 | aspavientos | 8 |
| 4046 | asomaban | 8 |
| 4047 | ascos | 8 |
| 4048 | aragón | 8 |
| 4049 | apuros | 8 |
| 4050 | apures | 8 |
| 4051 | aproximaba | 8 |
| 4052 | aprende | 8 |
| 4053 | apartó | 8 |
| 4054 | apartado | 8 |
| 4055 | aparato | 8 |
| 4056 | añadir | 8 |
| 4057 | antipatía | 8 |
| 4058 | anochecer | 8 |
| 4059 | ánimos | 8 |
| 4060 | ángulo | 8 |
| 4061 | anarquista | 8 |
| 4062 | americana | 8 |
| 4063 | amarillo | 8 |
| 4064 | alzó | 8 |
| 4065 | altas | 8 |
| 4066 | altares | 8 |
| 4067 | alborotada | 8 |
| 4068 | ahogaba | 8 |
| 4069 | aguanta | 8 |
| 4070 | agitación | 8 |
| 4071 | afición | 8 |
| 4072 | administrador | 8 |
| 4073 | acudió | 8 |
| 4074 | acostó | 8 |
| 4075 | acompañar | 8 |
| 4076 | acero | 8 |
| 4077 | acercose | 8 |
| 4078 | acabe | 8 |
| 4079 | acabado | 8 |
| 4080 | abnegación | 8 |
| 4081 | abandonó | 8 |
| 4082 | vulgaris | 7 |
| 4083 | vuestro | 7 |
| 4084 | voto | 7 |
| 4085 | vosotros | 7 |
| 4086 | volverá | 7 |
| 4087 | vocablos | 7 |
| 4088 | vivísima | 7 |
| 4089 | vistiendo | 7 |
| 4090 | viniera | 7 |
| 4091 | vigilar | 7 |
| 4092 | vigilancia | 7 |
| 4093 | viernes | 7 |
| 4094 | verídico | 7 |
| 4095 | verdaderas | 7 |
| 4096 | venus | 7 |
| 4097 | ventaja | 7 |
| 4098 | venden | 7 |
| 4099 | vencida | 7 |
| 4100 | váyase | 7 |
| 4101 | vástagos | 7 |
| 4102 | variar | 7 |
| 4103 | valientes | 7 |
| 4104 | valga | 7 |
| 4105 | vago | 7 |
| 4106 | vagamente | 7 |
| 4107 | vacilar | 7 |
| 4108 | uniforme | 7 |
| 4109 | tropiezo | 7 |
| 4110 | tremendas | 7 |
| 4111 | tratos | 7 |
| 4112 | tratamiento | 7 |
| 4113 | trastornado | 7 |
| 4114 | trampas | 7 |
| 4115 | traigan | 7 |
| 4116 | traes | 7 |
| 4117 | trabaja | 7 |
| 4118 | torpeza | 7 |
| 4119 | torno | 7 |
| 4120 | tormento | 7 |
| 4121 | torcido | 7 |
| 4122 | tonos | 7 |
| 4123 | tomara | 7 |
| 4124 | tocada | 7 |
| 4125 | tirria | 7 |
| 4126 | tiologías | 7 |
| 4127 | tieso | 7 |
| 4128 | tiesas | 7 |
| 4129 | tie | 7 |
| 4130 | testamento | 7 |
| 4131 | ternera | 7 |
| 4132 | teniente | 7 |
| 4133 | tenerle | 7 |
| 4134 | tendrían | 7 |
| 4135 | tendrás | 7 |
| 4136 | tendrán | 7 |
| 4137 | temple | 7 |
| 4138 | temiendo | 7 |
| 4139 | temblorosa | 7 |
| 4140 | temblando | 7 |
| 4141 | temblaban | 7 |
| 4142 | teatral | 7 |
| 4143 | tantísima | 7 |
| 4144 | talmente | 7 |
| 4145 | sueltos | 7 |
| 4146 | sueldo | 7 |
| 4147 | sublimes | 7 |
| 4148 | suavidad | 7 |
| 4149 | sostenían | 7 |
| 4150 | sonido | 7 |
| 4151 | sollozos | 7 |
| 4152 | solían | 7 |
| 4153 | solemnidad | 7 |
| 4154 | sobrinos | 7 |
| 4155 | sitios | 7 |
| 4156 | sintieron | 7 |
| 4157 | simplemente | 7 |
| 4158 | sigo | 7 |
| 4159 | serle | 7 |
| 4160 | serie | 7 |
| 4161 | seremos | 7 |
| 4162 | serán | 7 |
| 4163 | sequedad | 7 |
| 4164 | señoritos | 7 |
| 4165 | sencillo | 7 |
| 4166 | semos | 7 |
| 4167 | sarcasmo | 7 |
| 4168 | samaritana | 7 |
| 4169 | saludo | 7 |
| 4170 | saltando | 7 |
| 4171 | salgo | 7 |
| 4172 | sagunto | 7 |
| 4173 | sacudida | 7 |
| 4174 | sacristía | 7 |
| 4175 | rueda | 7 |
| 4176 | rubinius | 7 |
| 4177 | rosita | 7 |
| 4178 | rosas | 7 |
| 4179 | ropas | 7 |
| 4180 | rodilla | 7 |
| 4181 | rodeada | 7 |
| 4182 | rodeaba | 7 |
| 4183 | rival | 7 |
| 4184 | ricamente | 7 |
| 4185 | revolviendo | 7 |
| 4186 | revolución | 7 |
| 4187 | retratos | 7 |
| 4188 | resultó | 7 |
| 4189 | restos | 7 |
| 4190 | réspice | 7 |
| 4191 | respectivas | 7 |
| 4192 | resoplidos | 7 |
| 4193 | resmas | 7 |
| 4194 | reputación | 7 |
| 4195 | repuso | 7 |
| 4196 | repitiendo | 7 |
| 4197 | reparar | 7 |
| 4198 | renta | 7 |
| 4199 | rendida | 7 |
| 4200 | reírse | 7 |
| 4201 | regiones | 7 |
| 4202 | referentes | 7 |
| 4203 | redención | 7 |
| 4204 | recorrer | 7 |
| 4205 | reconocimiento | 7 |
| 4206 | reconociendo | 7 |
| 4207 | reconocía | 7 |
| 4208 | recogida | 7 |
| 4209 | recíprocamente | 7 |
| 4210 | recibían | 7 |
| 4211 | raso | 7 |
| 4212 | raras | 7 |
| 4213 | rabo | 7 |
| 4214 | quítate | 7 |
| 4215 | quisiese | 7 |
| 4216 | quieta | 7 |
| 4217 | quererle | 7 |
| 4218 | quedaría | 7 |
| 4219 | puñalada | 7 |
| 4220 | puñados | 7 |
| 4221 | proximidad | 7 |
| 4222 | protestantes | 7 |
| 4223 | protestante | 7 |
| 4224 | propuesto | 7 |
| 4225 | prontamente | 7 |
| 4226 | progresista | 7 |
| 4227 | programa | 7 |
| 4228 | profundísimo | 7 |
| 4229 | probarlo | 7 |
| 4230 | primerito | 7 |
| 4231 | preparando | 7 |
| 4232 | prensa | 7 |
| 4233 | pregunto | 7 |
| 4234 | preciosa | 7 |
| 4235 | postas | 7 |
| 4236 | portera | 7 |
| 4237 | pon | 7 |
| 4238 | polvos | 7 |
| 4239 | políticos | 7 |
| 4240 | poesía | 7 |
| 4241 | pobrecillo | 7 |
| 4242 | pleito | 7 |
| 4243 | planes | 7 |
| 4244 | placeras | 7 |
| 4245 | piojín | 7 |
| 4246 | pillos | 7 |
| 4247 | piense | 7 |
| 4248 | picardía | 7 |
| 4249 | picar | 7 |
| 4250 | pesado | 7 |
| 4251 | personaje | 7 |
| 4252 | perrerías | 7 |
| 4253 | permitido | 7 |
| 4254 | permanecía | 7 |
| 4255 | permanecer | 7 |
| 4256 | perla | 7 |
| 4257 | periodos | 7 |
| 4258 | perfecciones | 7 |
| 4259 | perfección | 7 |
| 4260 | perdonado | 7 |
| 4261 | pensión | 7 |
| 4262 | penosa | 7 |
| 4263 | penetró | 7 |
| 4264 | peinetas | 7 |
| 4265 | pegarle | 7 |
| 4266 | pechos | 7 |
| 4267 | paseíto | 7 |
| 4268 | paseaba | 7 |
| 4269 | pasada | 7 |
| 4270 | parta | 7 |
| 4271 | paró | 7 |
| 4272 | parándose | 7 |
| 4273 | parada | 7 |
| 4274 | pantalón | 7 |
| 4275 | pantalla | 7 |
| 4276 | palique | 7 |
| 4277 | pájaro | 7 |
| 4278 | pae | 7 |
| 4279 | padece | 7 |
| 4280 | oyen | 7 |
| 4281 | olas | 7 |
| 4282 | oírse | 7 |
| 4283 | oíase | 7 |
| 4284 | ofrecer | 7 |
| 4285 | ocurrían | 7 |
| 4286 | ocuparse | 7 |
| 4287 | ocupar | 7 |
| 4288 | ocupado | 7 |
| 4289 | ocupaciones | 7 |
| 4290 | obligado | 7 |
| 4291 | obediencia | 7 |
| 4292 | nieves | 7 |
| 4293 | negaba | 7 |
| 4294 | necesitan | 7 |
| 4295 | necesaria | 7 |
| 4296 | nacer | 7 |
| 4297 | murmuraba | 7 |
| 4298 | muriendo | 7 |
| 4299 | mundos | 7 |
| 4300 | muleta | 7 |
| 4301 | mozos | 7 |
| 4302 | mortificaba | 7 |
| 4303 | morada | 7 |
| 4304 | moño | 7 |
| 4305 | montado | 7 |
| 4306 | moderna | 7 |
| 4307 | mismas | 7 |
| 4308 | miserias | 7 |
| 4309 | ministra | 7 |
| 4310 | milicia | 7 |
| 4311 | migas | 7 |
| 4312 | metiose | 7 |
| 4313 | metida | 7 |
| 4314 | metí | 7 |
| 4315 | merino | 7 |
| 4316 | mercantil | 7 |
| 4317 | mejillas | 7 |
| 4318 | meditando | 7 |
| 4319 | medias | 7 |
| 4320 | material | 7 |
| 4321 | mate | 7 |
| 4322 | marchado | 7 |
| 4323 | marca | 7 |
| 4324 | malvina | 7 |
| 4325 | maldades | 7 |
| 4326 | magín | 7 |
| 4327 | lucido | 7 |
| 4328 | lozoya | 7 |
| 4329 | llevada | 7 |
| 4330 | llegué | 7 |
| 4331 | llegara | 7 |
| 4332 | llamamos | 7 |
| 4333 | limpiar | 7 |
| 4334 | ligeramente | 7 |
| 4335 | leo | 7 |
| 4336 | lejano | 7 |
| 4337 | lejana | 7 |
| 4338 | lealtad | 7 |
| 4339 | lazo | 7 |
| 4340 | lastimoso | 7 |
| 4341 | lances | 7 |
| 4342 | labio | 7 |
| 4343 | judía | 7 |
| 4344 | júbilo | 7 |
| 4345 | jarro | 7 |
| 4346 | irresistible | 7 |
| 4347 | ironía | 7 |
| 4348 | invierno | 7 |
| 4349 | inútiles | 7 |
| 4350 | introducir | 7 |
| 4351 | íntimo | 7 |
| 4352 | intentar | 7 |
| 4353 | instrumento | 7 |
| 4354 | inscripción | 7 |
| 4355 | inmensidad | 7 |
| 4356 | infamia | 7 |
| 4357 | indudable | 7 |
| 4358 | índole | 7 |
| 4359 | increíbles | 7 |
| 4360 | inclinando | 7 |
| 4361 | inclinaba | 7 |
| 4362 | impropio | 7 |
| 4363 | iluminado | 7 |
| 4364 | ignorancia | 7 |
| 4365 | hondo | 7 |
| 4366 | historias | 7 |
| 4367 | hipócrita | 7 |
| 4368 | hijito | 7 |
| 4369 | héroes | 7 |
| 4370 | hereje | 7 |
| 4371 | hembras | 7 |
| 4372 | hastío | 7 |
| 4373 | halló | 7 |
| 4374 | hágame | 7 |
| 4375 | hacerte | 7 |
| 4376 | hacemos | 7 |
| 4377 | hablándole | 7 |
| 4378 | habíamos | 7 |
| 4379 | gustos | 7 |
| 4380 | guardias | 7 |
| 4381 | guapísima | 7 |
| 4382 | guante | 7 |
| 4383 | guano | 7 |
| 4384 | grata | 7 |
| 4385 | grandeza | 7 |
| 4386 | gozar | 7 |
| 4387 | gotas | 7 |
| 4388 | gonzález | 7 |
| 4389 | generosidad | 7 |
| 4390 | ganando | 7 |
| 4391 | gafas | 7 |
| 4392 | futuro | 7 |
| 4393 | futura | 7 |
| 4394 | friolera | 7 |
| 4395 | francés | 7 |
| 4396 | fiscal | 7 |
| 4397 | firma | 7 |
| 4398 | finura | 7 |
| 4399 | finísima | 7 |
| 4400 | fines | 7 |
| 4401 | figurarse | 7 |
| 4402 | figuraba | 7 |
| 4403 | fidelidad | 7 |
| 4404 | feroz | 7 |
| 4405 | faltando | 7 |
| 4406 | faltaban | 7 |
| 4407 | faldones | 7 |
| 4408 | explicarse | 7 |
| 4409 | explicación | 7 |
| 4410 | exclamaciones | 7 |
| 4411 | excitado | 7 |
| 4412 | examinar | 7 |
| 4413 | éste | 7 |
| 4414 | estatua | 7 |
| 4415 | estampas | 7 |
| 4416 | estados | 7 |
| 4417 | espérate | 7 |
| 4418 | esperanzas | 7 |
| 4419 | espantosa | 7 |
| 4420 | esforzaba | 7 |
| 4421 | escritura | 7 |
| 4422 | escribe | 7 |
| 4423 | esclavitud | 7 |
| 4424 | escarola | 7 |
| 4425 | escándalos | 7 |
| 4426 | errores | 7 |
| 4427 | eras | 7 |
| 4428 | érale | 7 |
| 4429 | equivocación | 7 |
| 4430 | envolvía | 7 |
| 4431 | entrara | 7 |
| 4432 | enterada | 7 |
| 4433 | enseñando | 7 |
| 4434 | enracimaban | 7 |
| 4435 | enmienda | 7 |
| 4436 | enhorabuena | 7 |
| 4437 | engañas | 7 |
| 4438 | enfado | 7 |
| 4439 | energías | 7 |
| 4440 | encuentre | 7 |
| 4441 | encuentras | 7 |
| 4442 | encontrara | 7 |
| 4443 | encargó | 7 |
| 4444 | enamorarse | 7 |
| 4445 | empuje | 7 |
| 4446 | empresa | 7 |
| 4447 | empeño | 7 |
| 4448 | efectos | 7 |
| 4449 | edificios | 7 |
| 4450 | económico | 7 |
| 4451 | economía | 7 |
| 4452 | eche | 7 |
| 4453 | echándole | 7 |
| 4454 | echaban | 7 |
| 4455 | dureza | 7 |
| 4456 | dramas | 7 |
| 4457 | doncella | 7 |
| 4458 | dómine | 7 |
| 4459 | divinas | 7 |
| 4460 | divertía | 7 |
| 4461 | distraída | 7 |
| 4462 | distintos | 7 |
| 4463 | distintas | 7 |
| 4464 | disgustos | 7 |
| 4465 | dirigió | 7 |
| 4466 | dijeran | 7 |
| 4467 | dígale | 7 |
| 4468 | difunta | 7 |
| 4469 | diese | 7 |
| 4470 | diablos | 7 |
| 4471 | despedían | 7 |
| 4472 | desgracias | 7 |
| 4473 | descuide | 7 |
| 4474 | descansar | 7 |
| 4475 | desbordaba | 7 |
| 4476 | des | 7 |
| 4477 | departamento | 7 |
| 4478 | demostrando | 7 |
| 4479 | deme | 7 |
| 4480 | delito | 7 |
| 4481 | deliciosa | 7 |
| 4482 | delantera | 7 |
| 4483 | dejaron | 7 |
| 4484 | decidirse | 7 |
| 4485 | decíale | 7 |
| 4486 | cumplimiento | 7 |
| 4487 | cumple | 7 |
| 4488 | culpable | 7 |
| 4489 | cuentan | 7 |
| 4490 | cubierta | 7 |
| 4491 | cruzadas | 7 |
| 4492 | crudo | 7 |
| 4493 | crímenes | 7 |
| 4494 | creció | 7 |
| 4495 | créalo | 7 |
| 4496 | cosiendo | 7 |
| 4497 | cortos | 7 |
| 4498 | cortedad | 7 |
| 4499 | cortas | 7 |
| 4500 | cortar | 7 |
| 4501 | corro | 7 |
| 4502 | correo | 7 |
| 4503 | corona | 7 |
| 4504 | convulsiva | 7 |
| 4505 | contrariedad | 7 |
| 4506 | contraria | 7 |
| 4507 | conteniendo | 7 |
| 4508 | contenía | 7 |
| 4509 | construcción | 7 |
| 4510 | consideraciones | 7 |
| 4511 | consecuencias | 7 |
| 4512 | confesor | 7 |
| 4513 | confesión | 7 |
| 4514 | concejal | 7 |
| 4515 | comunidad | 7 |
| 4516 | comunicación | 7 |
| 4517 | compraré | 7 |
| 4518 | compinche | 7 |
| 4519 | compañeros | 7 |
| 4520 | cogí | 7 |
| 4521 | codos | 7 |
| 4522 | cobrador | 7 |
| 4523 | clavó | 7 |
| 4524 | cláusulas | 7 |
| 4525 | citas | 7 |
| 4526 | cifra | 7 |
| 4527 | chispas | 7 |
| 4528 | chiquitín | 7 |
| 4529 | china | 7 |
| 4530 | chilló | 7 |
| 4531 | chicas | 7 |
| 4532 | celoso | 7 |
| 4533 | cavilar | 7 |
| 4534 | causaban | 7 |
| 4535 | cascote | 7 |
| 4536 | cartilla | 7 |
| 4537 | cariñosas | 7 |
| 4538 | cargando | 7 |
| 4539 | caramba | 7 |
| 4540 | característico | 7 |
| 4541 | cañas | 7 |
| 4542 | cantón | 7 |
| 4543 | canela | 7 |
| 4544 | campaña | 7 |
| 4545 | cambiaría | 7 |
| 4546 | cambiar | 7 |
| 4547 | callarse | 7 |
| 4548 | callada | 7 |
| 4549 | caliente | 7 |
| 4550 | caiga | 7 |
| 4551 | cabecera | 7 |
| 4552 | busto | 7 |
| 4553 | burlesca | 7 |
| 4554 | bruja | 7 |
| 4555 | bromuro | 7 |
| 4556 | brillante | 7 |
| 4557 | bobo | 7 |
| 4558 | besó | 7 |
| 4559 | bebía | 7 |
| 4560 | baza | 7 |
| 4561 | basura | 7 |
| 4562 | barullo | 7 |
| 4563 | barriga | 7 |
| 4564 | bajado | 7 |
| 4565 | aumentar | 7 |
| 4566 | atrevo | 7 |
| 4567 | atónita | 7 |
| 4568 | atocha | 7 |
| 4569 | aterrada | 7 |
| 4570 | aterraba | 7 |
| 4571 | asentimiento | 7 |
| 4572 | arrastrando | 7 |
| 4573 | arrastrada | 7 |
| 4574 | arranca | 7 |
| 4575 | armada | 7 |
| 4576 | armaba | 7 |
| 4577 | aristocracia | 7 |
| 4578 | arena | 7 |
| 4579 | aptitud | 7 |
| 4580 | apretando | 7 |
| 4581 | aprendiendo | 7 |
| 4582 | apreciación | 7 |
| 4583 | apoyar | 7 |
| 4584 | apoyada | 7 |
| 4585 | aplicó | 7 |
| 4586 | aplicar | 7 |
| 4587 | ansia | 7 |
| 4588 | animales | 7 |
| 4589 | anarquía | 7 |
| 4590 | altura | 7 |
| 4591 | almohadas | 7 |
| 4592 | alhaja | 7 |
| 4593 | alegraba | 7 |
| 4594 | alburquerque | 7 |
| 4595 | alas | 7 |
| 4596 | alarmada | 7 |
| 4597 | agudo | 7 |
| 4598 | agradecido | 7 |
| 4599 | afable | 7 |
| 4600 | acudir | 7 |
| 4601 | acompañada | 7 |
| 4602 | acompañaba | 7 |
| 4603 | acometida | 7 |
| 4604 | acentuando | 7 |
| 4605 | acentuada | 7 |
| 4606 | abismo | 7 |
| 4607 | abiertas | 7 |
| 4608 | abandonado | 7 |
| 4609 | zaragata | 6 |
| 4610 | zapatillas | 6 |
| 4611 | xi | 6 |
| 4612 | vusté | 6 |
| 4613 | vulgo | 6 |
| 4614 | vuestra | 6 |
| 4615 | votación | 6 |
| 4616 | volverme | 6 |
| 4617 | volverlo | 6 |
| 4618 | voló | 6 |
| 4619 | viviera | 6 |
| 4620 | viste | 6 |
| 4621 | virtudes | 6 |
| 4622 | vieras | 6 |
| 4623 | viéndose | 6 |
| 4624 | viéndola | 6 |
| 4625 | vidriera | 6 |
| 4626 | vestidas | 6 |
| 4627 | verlos | 6 |
| 4628 | ventanilla | 6 |
| 4629 | ventajas | 6 |
| 4630 | vendiendo | 6 |
| 4631 | vender | 6 |
| 4632 | vayan | 6 |
| 4633 | vais | 6 |
| 4634 | vacilando | 6 |
| 4635 | vacilaba | 6 |
| 4636 | urbanidad | 6 |
| 4637 | universal | 6 |
| 4638 | últimamente | 6 |
| 4639 | ulmus | 6 |
| 4640 | turno | 6 |
| 4641 | turbada | 6 |
| 4642 | tunantes | 6 |
| 4643 | tumulto | 6 |
| 4644 | triunfo | 6 |
| 4645 | tripas | 6 |
| 4646 | tribunal | 6 |
| 4647 | trastada | 6 |
| 4648 | tranvía | 6 |
| 4649 | transformación | 6 |
| 4650 | tranquilizó | 6 |
| 4651 | traerle | 6 |
| 4652 | trabajado | 6 |
| 4653 | tonillo | 6 |
| 4654 | tomás | 6 |
| 4655 | tomas | 6 |
| 4656 | tomarse | 6 |
| 4657 | tomarle | 6 |
| 4658 | tocas | 6 |
| 4659 | tintoreros | 6 |
| 4660 | tintero | 6 |
| 4661 | tigre | 6 |
| 4662 | tierno | 6 |
| 4663 | tez | 6 |
| 4664 | testimonio | 6 |
| 4665 | terribles | 6 |
| 4666 | tengan | 6 |
| 4667 | tenerlo | 6 |
| 4668 | tendero | 6 |
| 4669 | tellería | 6 |
| 4670 | techos | 6 |
| 4671 | tardanza | 6 |
| 4672 | tapaba | 6 |
| 4673 | tapa | 6 |
| 4674 | tambor | 6 |
| 4675 | talentos | 6 |
| 4676 | tablero | 6 |
| 4677 | sylvestris | 6 |
| 4678 | superioridad | 6 |
| 4679 | sumamente | 6 |
| 4680 | suena | 6 |
| 4681 | sucesor | 6 |
| 4682 | súbitamente | 6 |
| 4683 | subieron | 6 |
| 4684 | sospechar | 6 |
| 4685 | sospechando | 6 |
| 4686 | sosona | 6 |
| 4687 | sopetón | 6 |
| 4688 | soñé | 6 |
| 4689 | sonrosada | 6 |
| 4690 | solutamente | 6 |
| 4691 | solitaria | 6 |
| 4692 | solar | 6 |
| 4693 | sofocado | 6 |
| 4694 | sirvo | 6 |
| 4695 | sintiera | 6 |
| 4696 | sílaba | 6 |
| 4697 | siguiendo | 6 |
| 4698 | sietemesino | 6 |
| 4699 | sientes | 6 |
| 4700 | sexos | 6 |
| 4701 | sevilla | 6 |
| 4702 | servidumbre | 6 |
| 4703 | servicios | 6 |
| 4704 | separación | 6 |
| 4705 | sentiré | 6 |
| 4706 | sentimental | 6 |
| 4707 | sentadas | 6 |
| 4708 | sensaciones | 6 |
| 4709 | seguirle | 6 |
| 4710 | saqué | 6 |
| 4711 | salvado | 6 |
| 4712 | saludar | 6 |
| 4713 | saludaba | 6 |
| 4714 | saltaba | 6 |
| 4715 | salimos | 6 |
| 4716 | saliese | 6 |
| 4717 | saladero | 6 |
| 4718 | sagrado | 6 |
| 4719 | sacara | 6 |
| 4720 | sabré | 6 |
| 4721 | sabio | 6 |
| 4722 | sábado | 6 |
| 4723 | rutinas | 6 |
| 4724 | run | 6 |
| 4725 | rudo | 6 |
| 4726 | rudeza | 6 |
| 4727 | rótulo | 6 |
| 4728 | rosquillas | 6 |
| 4729 | rosa | 6 |
| 4730 | rondaba | 6 |
| 4731 | rompiera | 6 |
| 4732 | rodar | 6 |
| 4733 | risueño | 6 |
| 4734 | ridícula | 6 |
| 4735 | rías | 6 |
| 4736 | rezo | 6 |
| 4737 | revolvió | 6 |
| 4738 | revolvía | 6 |
| 4739 | revoluciones | 6 |
| 4740 | revolucionario | 6 |
| 4741 | revienta | 6 |
| 4742 | reventaba | 6 |
| 4743 | retiraba | 6 |
| 4744 | responsable | 6 |
| 4745 | respaldo | 6 |
| 4746 | repugnante | 6 |
| 4747 | reproducción | 6 |
| 4748 | representación | 6 |
| 4749 | repóblica | 6 |
| 4750 | repetir | 6 |
| 4751 | repartir | 6 |
| 4752 | reparó | 6 |
| 4753 | reparación | 6 |
| 4754 | renunciar | 6 |
| 4755 | renegando | 6 |
| 4756 | remordimientos | 6 |
| 4757 | religiosos | 6 |
| 4758 | religiosas | 6 |
| 4759 | relativamente | 6 |
| 4760 | reírme | 6 |
| 4761 | reído | 6 |
| 4762 | regreso | 6 |
| 4763 | reglas | 6 |
| 4764 | regalos | 6 |
| 4765 | recta | 6 |
| 4766 | recomendado | 6 |
| 4767 | recobró | 6 |
| 4768 | recibe | 6 |
| 4769 | recados | 6 |
| 4770 | rebajo | 6 |
| 4771 | realizar | 6 |
| 4772 | raimundo | 6 |
| 4773 | rabiando | 6 |
| 4774 | quitárselo | 6 |
| 4775 | quitarse | 6 |
| 4776 | quinqué | 6 |
| 4777 | querré | 6 |
| 4778 | quererme | 6 |
| 4779 | queréis | 6 |
| 4780 | quede | 6 |
| 4781 | quedará | 6 |
| 4782 | quedando | 6 |
| 4783 | puros | 6 |
| 4784 | pum | 6 |
| 4785 | púlpito | 6 |
| 4786 | puestas | 6 |
| 4787 | prurito | 6 |
| 4788 | proyectos | 6 |
| 4789 | provisiones | 6 |
| 4790 | provenía | 6 |
| 4791 | protectora | 6 |
| 4792 | proporciones | 6 |
| 4793 | propongo | 6 |
| 4794 | propaganda | 6 |
| 4795 | pronunciando | 6 |
| 4796 | prometido | 6 |
| 4797 | prodigio | 6 |
| 4798 | procedimientos | 6 |
| 4799 | prisión | 6 |
| 4800 | presentimiento | 6 |
| 4801 | presentar | 6 |
| 4802 | prepararse | 6 |
| 4803 | preparada | 6 |
| 4804 | preguntado | 6 |
| 4805 | prácticas | 6 |
| 4806 | posibles | 6 |
| 4807 | portado | 6 |
| 4808 | porrazo | 6 |
| 4809 | porquerías | 6 |
| 4810 | poquitín | 6 |
| 4811 | pongamos | 6 |
| 4812 | ponerlo | 6 |
| 4813 | ponerla | 6 |
| 4814 | pondremos | 6 |
| 4815 | poetas | 6 |
| 4816 | podrás | 6 |
| 4817 | plantó | 6 |
| 4818 | plácida | 6 |
| 4819 | pito | 6 |
| 4820 | pisos | 6 |
| 4821 | pisando | 6 |
| 4822 | pierde | 6 |
| 4823 | picador | 6 |
| 4824 | pianito | 6 |
| 4825 | pianista | 6 |
| 4826 | petróleo | 6 |
| 4827 | pesados | 6 |
| 4828 | pesada | 6 |
| 4829 | pesaba | 6 |
| 4830 | perversidad | 6 |
| 4831 | pertenece | 6 |
| 4832 | persecución | 6 |
| 4833 | peregrino | 6 |
| 4834 | perdonaba | 6 |
| 4835 | perdidos | 6 |
| 4836 | pensador | 6 |
| 4837 | peinado | 6 |
| 4838 | pegó | 6 |
| 4839 | pegando | 6 |
| 4840 | pegaba | 6 |
| 4841 | pedido | 6 |
| 4842 | pedacitos | 6 |
| 4843 | pecar | 6 |
| 4844 | paterna | 6 |
| 4845 | pasito | 6 |
| 4846 | pasear | 6 |
| 4847 | pasé | 6 |
| 4848 | pascua | 6 |
| 4849 | párpados | 6 |
| 4850 | paréntesis | 6 |
| 4851 | parecida | 6 |
| 4852 | papas | 6 |
| 4853 | palotada | 6 |
| 4854 | palco | 6 |
| 4855 | paice | 6 |
| 4856 | pagarle | 6 |
| 4857 | pagaré | 6 |
| 4858 | oyéndole | 6 |
| 4859 | ordinario | 6 |
| 4860 | oponerse | 6 |
| 4861 | olvide | 6 |
| 4862 | olía | 6 |
| 4863 | oírte | 6 |
| 4864 | ofreciéndole | 6 |
| 4865 | oficiosidad | 6 |
| 4866 | ocupaban | 6 |
| 4867 | ocupaba | 6 |
| 4868 | obtuvo | 6 |
| 4869 | observadora | 6 |
| 4870 | obreros | 6 |
| 4871 | obligaba | 6 |
| 4872 | obedeciendo | 6 |
| 4873 | nudo | 6 |
| 4874 | notables | 6 |
| 4875 | noria | 6 |
| 4876 | nieve | 6 |
| 4877 | niegue | 6 |
| 4878 | narrador | 6 |
| 4879 | narciso | 6 |
| 4880 | nace | 6 |
| 4881 | na | 6 |
| 4882 | mugre | 6 |
| 4883 | muelas | 6 |
| 4884 | muda | 6 |
| 4885 | muchísima | 6 |
| 4886 | muchachas | 6 |
| 4887 | motor | 6 |
| 4888 | mortal | 6 |
| 4889 | morirse | 6 |
| 4890 | montones | 6 |
| 4891 | moderaos | 6 |
| 4892 | misteriosas | 6 |
| 4893 | mirarse | 6 |
| 4894 | mirándose | 6 |
| 4895 | mimos | 6 |
| 4896 | militar | 6 |
| 4897 | metieron | 6 |
| 4898 | meterme | 6 |
| 4899 | metamorfosis | 6 |
| 4900 | metálico | 6 |
| 4901 | memorable | 6 |
| 4902 | meditar | 6 |
| 4903 | médicos | 6 |
| 4904 | médicis | 6 |
| 4905 | medicamento | 6 |
| 4906 | mazapán | 6 |
| 4907 | maza | 6 |
| 4908 | mayoría | 6 |
| 4909 | matando | 6 |
| 4910 | martillo | 6 |
| 4911 | mango | 6 |
| 4912 | mancha | 6 |
| 4913 | mamarracho | 6 |
| 4914 | malditas | 6 |
| 4915 | majadero | 6 |
| 4916 | maja | 6 |
| 4917 | magnífica | 6 |
| 4918 | luto | 6 |
| 4919 | lulio | 6 |
| 4920 | luchando | 6 |
| 4921 | lógico | 6 |
| 4922 | llorado | 6 |
| 4923 | llora | 6 |
| 4924 | llego | 6 |
| 4925 | llegándose | 6 |
| 4926 | llavín | 6 |
| 4927 | llamándole | 6 |
| 4928 | limpios | 6 |
| 4929 | limpiando | 6 |
| 4930 | libres | 6 |
| 4931 | liberales | 6 |
| 4932 | letargo | 6 |
| 4933 | leguas | 6 |
| 4934 | legítimo | 6 |
| 4935 | leganés | 6 |
| 4936 | lavarse | 6 |
| 4937 | lámina | 6 |
| 4938 | junio | 6 |
| 4939 | julio | 6 |
| 4940 | jugado | 6 |
| 4941 | juega | 6 |
| 4942 | ju | 6 |
| 4943 | joya | 6 |
| 4944 | jovial | 6 |
| 4945 | jeta | 6 |
| 4946 | jerez | 6 |
| 4947 | jardín | 6 |
| 4948 | jarana | 6 |
| 4949 | irme | 6 |
| 4950 | invitó | 6 |
| 4951 | invisible | 6 |
| 4952 | intervenir | 6 |
| 4953 | intenciones | 6 |
| 4954 | instrucción | 6 |
| 4955 | insensato | 6 |
| 4956 | iniciativa | 6 |
| 4957 | ingenuidad | 6 |
| 4958 | infundía | 6 |
| 4959 | infaliblemente | 6 |
| 4960 | inefable | 6 |
| 4961 | indispensable | 6 |
| 4962 | indiferente | 6 |
| 4963 | indicaba | 6 |
| 4964 | incapaz | 6 |
| 4965 | impedir | 6 |
| 4966 | huyendo | 6 |
| 4967 | humanos | 6 |
| 4968 | huir | 6 |
| 4969 | horrores | 6 |
| 4970 | hongo | 6 |
| 4971 | hito | 6 |
| 4972 | histórico | 6 |
| 4973 | hierros | 6 |
| 4974 | hiciste | 6 |
| 4975 | hermosos | 6 |
| 4976 | hembra | 6 |
| 4977 | hechura | 6 |
| 4978 | haciéndola | 6 |
| 4979 | hables | 6 |
| 4980 | hablarte | 6 |
| 4981 | hablara | 6 |
| 4982 | hábil | 6 |
| 4983 | habéis | 6 |
| 4984 | gustaría | 6 |
| 4985 | gustar | 6 |
| 4986 | gustado | 6 |
| 4987 | groseras | 6 |
| 4988 | gravelinas | 6 |
| 4989 | grato | 6 |
| 4990 | grandísimo | 6 |
| 4991 | gozoso | 6 |
| 4992 | gozando | 6 |
| 4993 | golosina | 6 |
| 4994 | golosa | 6 |
| 4995 | gilimón | 6 |
| 4996 | gatitos | 6 |
| 4997 | garbanzo | 6 |
| 4998 | ganancias | 6 |
| 4999 | gallinas | 6 |
| 5000 | galán | 6 |
| 5001 | fusiles | 6 |
| 5002 | fundar | 6 |
| 5003 | fuente | 6 |
| 5004 | frotándose | 6 |
| 5005 | frías | 6 |
| 5006 | frescas | 6 |
| 5007 | frasco | 6 |
| 5008 | francesa | 6 |
| 5009 | fórmulas | 6 |
| 5010 | fonda | 6 |
| 5011 | fío | 6 |
| 5012 | finuras | 6 |
| 5013 | fincas | 6 |
| 5014 | finalmente | 6 |
| 5015 | filosófica | 6 |
| 5016 | fijas | 6 |
| 5017 | fijaba | 6 |
| 5018 | ferrocarriles | 6 |
| 5019 | ferocidad | 6 |
| 5020 | felipe | 6 |
| 5021 | faz | 6 |
| 5022 | fatigada | 6 |
| 5023 | fatal | 6 |
| 5024 | fárrago | 6 |
| 5025 | facilidad | 6 |
| 5026 | extracto | 6 |
| 5027 | expresando | 6 |
| 5028 | expresado | 6 |
| 5029 | existían | 6 |
| 5030 | existencias | 6 |
| 5031 | exigencias | 6 |
| 5032 | exclamaba | 6 |
| 5033 | examinó | 6 |
| 5034 | exactitud | 6 |
| 5035 | estorbaba | 6 |
| 5036 | estés | 6 |
| 5037 | estarían | 6 |
| 5038 | ésta | 6 |
| 5039 | espléndida | 6 |
| 5040 | espíritus | 6 |
| 5041 | espirituales | 6 |
| 5042 | espinazo | 6 |
| 5043 | espantoso | 6 |
| 5044 | escrúpulos | 6 |
| 5045 | escribía | 6 |
| 5046 | escondido | 6 |
| 5047 | escalofríos | 6 |
| 5048 | equilibrio | 6 |
| 5049 | entretener | 6 |
| 5050 | entresuelo | 6 |
| 5051 | entregar | 6 |
| 5052 | entregado | 6 |
| 5053 | entornada | 6 |
| 5054 | enteró | 6 |
| 5055 | enteraba | 6 |
| 5056 | enseñó | 6 |
| 5057 | enseñado | 6 |
| 5058 | engañan | 6 |
| 5059 | engaña | 6 |
| 5060 | énfasis | 6 |
| 5061 | enero | 6 |
| 5062 | encontrarse | 6 |
| 5063 | encontraban | 6 |
| 5064 | encierro | 6 |
| 5065 | encerrada | 6 |
| 5066 | encendidos | 6 |
| 5067 | encendía | 6 |
| 5068 | encargos | 6 |
| 5069 | encanto | 6 |
| 5070 | empiezan | 6 |
| 5071 | empezando | 6 |
| 5072 | emigración | 6 |
| 5073 | eléctrico | 6 |
| 5074 | ejecución | 6 |
| 5075 | efectiva | 6 |
| 5076 | eclesiástico | 6 |
| 5077 | dulcemente | 6 |
| 5078 | duerme | 6 |
| 5079 | dudaba | 6 |
| 5080 | droguería | 6 |
| 5081 | dormitorio | 6 |
| 5082 | dominio | 6 |
| 5083 | dolorosa | 6 |
| 5084 | dolorida | 6 |
| 5085 | divorcio | 6 |
| 5086 | diván | 6 |
| 5087 | distribución | 6 |
| 5088 | distracciones | 6 |
| 5089 | dispense | 6 |
| 5090 | diole | 6 |
| 5091 | dímelo | 6 |
| 5092 | dile | 6 |
| 5093 | difíciles | 6 |
| 5094 | diciéndose | 6 |
| 5095 | deudas | 6 |
| 5096 | determinar | 6 |
| 5097 | deteniéndose | 6 |
| 5098 | despidiose | 6 |
| 5099 | despedía | 6 |
| 5100 | desenvolverse | 6 |
| 5101 | desempeñar | 6 |
| 5102 | desdichado | 6 |
| 5103 | descubrió | 6 |
| 5104 | descollaba | 6 |
| 5105 | descarada | 6 |
| 5106 | dependiente | 6 |
| 5107 | depende | 6 |
| 5108 | dejose | 6 |
| 5109 | defecto | 6 |
| 5110 | decidió | 6 |
| 5111 | decide | 6 |
| 5112 | debido | 6 |
| 5113 | dárselo | 6 |
| 5114 | dándote | 6 |
| 5115 | dadas | 6 |
| 5116 | cursi | 6 |
| 5117 | cuñada | 6 |
| 5118 | culpas | 6 |
| 5119 | culebra | 6 |
| 5120 | cuidando | 6 |
| 5121 | cuerdas | 6 |
| 5122 | cuentes | 6 |
| 5123 | cuchara | 6 |
| 5124 | cuartito | 6 |
| 5125 | cruces | 6 |
| 5126 | criados | 6 |
| 5127 | creías | 6 |
| 5128 | créete | 6 |
| 5129 | creería | 6 |
| 5130 | creerá | 6 |
| 5131 | credencial | 6 |
| 5132 | créame | 6 |
| 5133 | coyuntura | 6 |
| 5134 | cosillas | 6 |
| 5135 | cortó | 6 |
| 5136 | cortes | 6 |
| 5137 | corrientes | 6 |
| 5138 | convenido | 6 |
| 5139 | contaré | 6 |
| 5140 | consternada | 6 |
| 5141 | constantemente | 6 |
| 5142 | constante | 6 |
| 5143 | consolaba | 6 |
| 5144 | conservaban | 6 |
| 5145 | conseguirlo | 6 |
| 5146 | conocidas | 6 |
| 5147 | conocida | 6 |
| 5148 | confesonario | 6 |
| 5149 | compuesta | 6 |
| 5150 | compró | 6 |
| 5151 | compré | 6 |
| 5152 | componía | 6 |
| 5153 | comió | 6 |
| 5154 | cómica | 6 |
| 5155 | comes | 6 |
| 5156 | combinación | 6 |
| 5157 | comandante | 6 |
| 5158 | comadrón | 6 |
| 5159 | coloquio | 6 |
| 5160 | cohibida | 6 |
| 5161 | cogiéndole | 6 |
| 5162 | coco | 6 |
| 5163 | cocinera | 6 |
| 5164 | cocido | 6 |
| 5165 | clavados | 6 |
| 5166 | clavaba | 6 |
| 5167 | claros | 6 |
| 5168 | círculos | 6 |
| 5169 | chucherías | 6 |
| 5170 | cesante | 6 |
| 5171 | cerrados | 6 |
| 5172 | ceniza | 6 |
| 5173 | cenar | 6 |
| 5174 | celo | 6 |
| 5175 | célebres | 6 |
| 5176 | ceder | 6 |
| 5177 | cautela | 6 |
| 5178 | causas | 6 |
| 5179 | caudal | 6 |
| 5180 | catarro | 6 |
| 5181 | casco | 6 |
| 5182 | casaron | 6 |
| 5183 | cartagena | 6 |
| 5184 | caro | 6 |
| 5185 | carlista | 6 |
| 5186 | cargue | 6 |
| 5187 | cargan | 6 |
| 5188 | canuto | 6 |
| 5189 | cantidades | 6 |
| 5190 | canonjía | 6 |
| 5191 | canónigo | 6 |
| 5192 | camisas | 6 |
| 5193 | calentura | 6 |
| 5194 | cajones | 6 |
| 5195 | cajita | 6 |
| 5196 | caí | 6 |
| 5197 | caen | 6 |
| 5198 | cabellera | 6 |
| 5199 | butaca | 6 |
| 5200 | buscó | 6 |
| 5201 | buscarme | 6 |
| 5202 | bullicio | 6 |
| 5203 | brutos | 6 |
| 5204 | brusca | 6 |
| 5205 | bronca | 6 |
| 5206 | brío | 6 |
| 5207 | brincos | 6 |
| 5208 | brillaba | 6 |
| 5209 | bordes | 6 |
| 5210 | bonilla | 6 |
| 5211 | bondadoso | 6 |
| 5212 | bolas | 6 |
| 5213 | blando | 6 |
| 5214 | bayona | 6 |
| 5215 | bautizo | 6 |
| 5216 | base | 6 |
| 5217 | barricadas | 6 |
| 5218 | banqueta | 6 |
| 5219 | bajaban | 6 |
| 5220 | baba | 6 |
| 5221 | azules | 6 |
| 5222 | azucenas | 6 |
| 5223 | ayún | 6 |
| 5224 | ayes | 6 |
| 5225 | aves | 6 |
| 5226 | aturdido | 6 |
| 5227 | aturdida | 6 |
| 5228 | atravesó | 6 |
| 5229 | atravesar | 6 |
| 5230 | atender | 6 |
| 5231 | atado | 6 |
| 5232 | asustó | 6 |
| 5233 | asustado | 6 |
| 5234 | asomaba | 6 |
| 5235 | arsénico | 6 |
| 5236 | arroyo | 6 |
| 5237 | arrojaba | 6 |
| 5238 | arrogante | 6 |
| 5239 | arreglarse | 6 |
| 5240 | arregla | 6 |
| 5241 | arranco | 6 |
| 5242 | arrancarle | 6 |
| 5243 | arquitectura | 6 |
| 5244 | apuntes | 6 |
| 5245 | apretón | 6 |
| 5246 | apretándole | 6 |
| 5247 | apretado | 6 |
| 5248 | aprecio | 6 |
| 5249 | apreciando | 6 |
| 5250 | apoyó | 6 |
| 5251 | aposento | 6 |
| 5252 | apetitos | 6 |
| 5253 | apellido | 6 |
| 5254 | apelar | 6 |
| 5255 | apariencia | 6 |
| 5256 | aparición | 6 |
| 5257 | aparentar | 6 |
| 5258 | anunció | 6 |
| 5259 | anunciar | 6 |
| 5260 | anunciando | 6 |
| 5261 | anteojos | 6 |
| 5262 | animado | 6 |
| 5263 | angelito | 6 |
| 5264 | andaban | 6 |
| 5265 | anchas | 6 |
| 5266 | amoroso | 6 |
| 5267 | amarillos | 6 |
| 5268 | amarilla | 6 |
| 5269 | amarga | 6 |
| 5270 | amalia | 6 |
| 5271 | amabilidad | 6 |
| 5272 | amaba | 6 |
| 5273 | alternativas | 6 |
| 5274 | altercado | 6 |
| 5275 | alivio | 6 |
| 5276 | alboroto | 6 |
| 5277 | albert | 6 |
| 5278 | alargaba | 6 |
| 5279 | alambre | 6 |
| 5280 | ajo | 6 |
| 5281 | ahorros | 6 |
| 5282 | agujas | 6 |
| 5283 | agradezco | 6 |
| 5284 | agradecida | 6 |
| 5285 | agradecer | 6 |
| 5286 | ágil | 6 |
| 5287 | agente | 6 |
| 5288 | afrenta | 6 |
| 5289 | aflicción | 6 |
| 5290 | afectando | 6 |
| 5291 | admiraba | 6 |
| 5292 | achuchón | 6 |
| 5293 | acertaba | 6 |
| 5294 | acechando | 6 |
| 5295 | acceso | 6 |
| 5296 | acabo | 6 |
| 5297 | acabaron | 6 |
| 5298 | acababan | 6 |
| 5299 | abundante | 6 |
| 5300 | abuela | 6 |
| 5301 | absurdo | 6 |
| 5302 | abatimiento | 6 |
| 5303 | abanicos | 6 |
| 5304 | abandonar | 6 |
| 5305 | abandonada | 6 |
| 5306 | zozobra | 5 |
| 5307 | zona | 5 |
| 5308 | zarpa | 5 |
| 5309 | yerba | 5 |
| 5310 | vulgares | 5 |
| 5311 | vuelven | 5 |
| 5312 | vosotras | 5 |
| 5313 | volverás | 5 |
| 5314 | volando | 5 |
| 5315 | volada | 5 |
| 5316 | viviendo | 5 |
| 5317 | viudo | 5 |
| 5318 | vistas | 5 |
| 5319 | visitación | 5 |
| 5320 | visitaba | 5 |
| 5321 | visión | 5 |
| 5322 | visible | 5 |
| 5323 | visajes | 5 |
| 5324 | violentamente | 5 |
| 5325 | violencia | 5 |
| 5326 | villaamil | 5 |
| 5327 | vigas | 5 |
| 5328 | vieran | 5 |
| 5329 | vientre | 5 |
| 5330 | viéndote | 5 |
| 5331 | vidrieras | 5 |
| 5332 | vicario | 5 |
| 5333 | vibración | 5 |
| 5334 | verlo | 5 |
| 5335 | verles | 5 |
| 5336 | verificado | 5 |
| 5337 | verdaderos | 5 |
| 5338 | venidas | 5 |
| 5339 | venerable | 5 |
| 5340 | vendré | 5 |
| 5341 | vende | 5 |
| 5342 | veleta | 5 |
| 5343 | vecindario | 5 |
| 5344 | veamos | 5 |
| 5345 | variedades | 5 |
| 5346 | vapor | 5 |
| 5347 | valiéndose | 5 |
| 5348 | valer | 5 |
| 5349 | vaga | 5 |
| 5350 | vaciló | 5 |
| 5351 | vacilación | 5 |
| 5352 | vaca | 5 |
| 5353 | usurero | 5 |
| 5354 | usado | 5 |
| 5355 | unirse | 5 |
| 5356 | turquesas | 5 |
| 5357 | tubos | 5 |
| 5358 | trompetilla | 5 |
| 5359 | triunfante | 5 |
| 5360 | triquiñuelas | 5 |
| 5361 | trecho | 5 |
| 5362 | trayecto | 5 |
| 5363 | travesura | 5 |
| 5364 | tránsito | 5 |
| 5365 | transigir | 5 |
| 5366 | transición | 5 |
| 5367 | tranquilizaba | 5 |
| 5368 | tramo | 5 |
| 5369 | trajera | 5 |
| 5370 | traigas | 5 |
| 5371 | trágica | 5 |
| 5372 | tragar | 5 |
| 5373 | tragando | 5 |
| 5374 | traerme | 5 |
| 5375 | trabajan | 5 |
| 5376 | tostada | 5 |
| 5377 | torres | 5 |
| 5378 | torpes | 5 |
| 5379 | tornó | 5 |
| 5380 | toques | 5 |
| 5381 | tomase | 5 |
| 5382 | tomarme | 5 |
| 5383 | tomaré | 5 |
| 5384 | tomándolo | 5 |
| 5385 | toman | 5 |
| 5386 | todito | 5 |
| 5387 | tocándole | 5 |
| 5388 | tocado | 5 |
| 5389 | título | 5 |
| 5390 | tiras | 5 |
| 5391 | tirado | 5 |
| 5392 | tinta | 5 |
| 5393 | tímidamente | 5 |
| 5394 | tiita | 5 |
| 5395 | tierna | 5 |
| 5396 | tientas | 5 |
| 5397 | tiembla | 5 |
| 5398 | tías | 5 |
| 5399 | terquedad | 5 |
| 5400 | tenías | 5 |
| 5401 | tenazas | 5 |
| 5402 | temporadas | 5 |
| 5403 | teme | 5 |
| 5404 | tejado | 5 |
| 5405 | tartera | 5 |
| 5406 | tarda | 5 |
| 5407 | tapujos | 5 |
| 5408 | tapia | 5 |
| 5409 | tambores | 5 |
| 5410 | tablas | 5 |
| 5411 | tabernillas | 5 |
| 5412 | sutil | 5 |
| 5413 | suponía | 5 |
| 5414 | suicidio | 5 |
| 5415 | suficiencia | 5 |
| 5416 | suelas | 5 |
| 5417 | sucedieron | 5 |
| 5418 | suba | 5 |
| 5419 | suaves | 5 |
| 5420 | sostenida | 5 |
| 5421 | sostengo | 5 |
| 5422 | sorprendió | 5 |
| 5423 | sorprendida | 5 |
| 5424 | sopor | 5 |
| 5425 | soplaba | 5 |
| 5426 | soñando | 5 |
| 5427 | soñadora | 5 |
| 5428 | sonrisilla | 5 |
| 5429 | sonar | 5 |
| 5430 | somnolencia | 5 |
| 5431 | sombreros | 5 |
| 5432 | sombras | 5 |
| 5433 | solteras | 5 |
| 5434 | solitario | 5 |
| 5435 | sólida | 5 |
| 5436 | socorrerla | 5 |
| 5437 | sobrinas | 5 |
| 5438 | sobrevino | 5 |
| 5439 | sobreponerse | 5 |
| 5440 | sobrenatural | 5 |
| 5441 | soberbio | 5 |
| 5442 | situaciones | 5 |
| 5443 | sincero | 5 |
| 5444 | sinceramente | 5 |
| 5445 | sincera | 5 |
| 5446 | simplezas | 5 |
| 5447 | silenciosa | 5 |
| 5448 | sílabas | 5 |
| 5449 | sierra | 5 |
| 5450 | sexo | 5 |
| 5451 | severa | 5 |
| 5452 | servidora | 5 |
| 5453 | sermones | 5 |
| 5454 | serias | 5 |
| 5455 | seriamente | 5 |
| 5456 | serena | 5 |
| 5457 | sentaban | 5 |
| 5458 | senquá | 5 |
| 5459 | seguros | 5 |
| 5460 | seguidos | 5 |
| 5461 | seductor | 5 |
| 5462 | sedación | 5 |
| 5463 | secta | 5 |
| 5464 | sayo | 5 |
| 5465 | satisfacer | 5 |
| 5466 | santas | 5 |
| 5467 | saltar | 5 |
| 5468 | salgas | 5 |
| 5469 | salamanca | 5 |
| 5470 | sacrificar | 5 |
| 5471 | sacarla | 5 |
| 5472 | sacaría | 5 |
| 5473 | sábana | 5 |
| 5474 | rufinita | 5 |
| 5475 | ruedas | 5 |
| 5476 | ruda | 5 |
| 5477 | ronquidos | 5 |
| 5478 | rompimiento | 5 |
| 5479 | rojas | 5 |
| 5480 | roja | 5 |
| 5481 | robustez | 5 |
| 5482 | rincones | 5 |
| 5483 | ríes | 5 |
| 5484 | reza | 5 |
| 5485 | reyes | 5 |
| 5486 | revuelto | 5 |
| 5487 | reviento | 5 |
| 5488 | reventando | 5 |
| 5489 | revelar | 5 |
| 5490 | reunión | 5 |
| 5491 | retirose | 5 |
| 5492 | resumidas | 5 |
| 5493 | resultando | 5 |
| 5494 | respondo | 5 |
| 5495 | resplandecía | 5 |
| 5496 | resistía | 5 |
| 5497 | repugnaba | 5 |
| 5498 | repetición | 5 |
| 5499 | repetían | 5 |
| 5500 | rendido | 5 |
| 5501 | religiones | 5 |
| 5502 | reinado | 5 |
| 5503 | región | 5 |
| 5504 | regalitos | 5 |
| 5505 | refunfuñando | 5 |
| 5506 | reducido | 5 |
| 5507 | red | 5 |
| 5508 | reconoció | 5 |
| 5509 | recomendó | 5 |
| 5510 | recomendación | 5 |
| 5511 | recobrando | 5 |
| 5512 | recobrado | 5 |
| 5513 | reclamo | 5 |
| 5514 | reciente | 5 |
| 5515 | recibo | 5 |
| 5516 | recadito | 5 |
| 5517 | reacción | 5 |
| 5518 | razonamiento | 5 |
| 5519 | rascaba | 5 |
| 5520 | rama | 5 |
| 5521 | ráfaga | 5 |
| 5522 | radiante | 5 |
| 5523 | quitose | 5 |
| 5524 | quitando | 5 |
| 5525 | quitan | 5 |
| 5526 | quintos | 5 |
| 5527 | quinto | 5 |
| 5528 | quinientos | 5 |
| 5529 | quijada | 5 |
| 5530 | quietud | 5 |
| 5531 | quicio | 5 |
| 5532 | quejas | 5 |
| 5533 | quejarse | 5 |
| 5534 | quédate | 5 |
| 5535 | quedase | 5 |
| 5536 | quedarme | 5 |
| 5537 | quedamos | 5 |
| 5538 | quedábase | 5 |
| 5539 | pureza | 5 |
| 5540 | puras | 5 |
| 5541 | pudieron | 5 |
| 5542 | pucheros | 5 |
| 5543 | puchero | 5 |
| 5544 | pseudo | 5 |
| 5545 | protector | 5 |
| 5546 | prosperidad | 5 |
| 5547 | prontito | 5 |
| 5548 | prometo | 5 |
| 5549 | promesas | 5 |
| 5550 | prójimo | 5 |
| 5551 | producían | 5 |
| 5552 | produce | 5 |
| 5553 | procurando | 5 |
| 5554 | procedencia | 5 |
| 5555 | probado | 5 |
| 5556 | primores | 5 |
| 5557 | pretendo | 5 |
| 5558 | pretendía | 5 |
| 5559 | presuroso | 5 |
| 5560 | presunciones | 5 |
| 5561 | presumida | 5 |
| 5562 | prestar | 5 |
| 5563 | prestamista | 5 |
| 5564 | presidio | 5 |
| 5565 | presentose | 5 |
| 5566 | presentan | 5 |
| 5567 | preparó | 5 |
| 5568 | preciosidad | 5 |
| 5569 | prácticos | 5 |
| 5570 | pozos | 5 |
| 5571 | postre | 5 |
| 5572 | posesión | 5 |
| 5573 | poseer | 5 |
| 5574 | poseen | 5 |
| 5575 | portillo | 5 |
| 5576 | porté | 5 |
| 5577 | portales | 5 |
| 5578 | poquillo | 5 |
| 5579 | populares | 5 |
| 5580 | pongan | 5 |
| 5581 | ponerte | 5 |
| 5582 | poderlo | 5 |
| 5583 | plumas | 5 |
| 5584 | plomo | 5 |
| 5585 | pliegos | 5 |
| 5586 | plazo | 5 |
| 5587 | platillo | 5 |
| 5588 | plancha | 5 |
| 5589 | plaf | 5 |
| 5590 | placera | 5 |
| 5591 | pisto | 5 |
| 5592 | pinturas | 5 |
| 5593 | pintoresco | 5 |
| 5594 | pintores | 5 |
| 5595 | pintados | 5 |
| 5596 | pintaba | 5 |
| 5597 | pino | 5 |
| 5598 | pillete | 5 |
| 5599 | pillería | 5 |
| 5600 | pierdo | 5 |
| 5601 | pierdes | 5 |
| 5602 | pierden | 5 |
| 5603 | pieles | 5 |
| 5604 | pides | 5 |
| 5605 | picor | 5 |
| 5606 | picaresca | 5 |
| 5607 | picante | 5 |
| 5608 | picada | 5 |
| 5609 | pesquis | 5 |
| 5610 | pescado | 5 |
| 5611 | pesca | 5 |
| 5612 | perteneciente | 5 |
| 5613 | pertenecían | 5 |
| 5614 | permitiéndose | 5 |
| 5615 | perdones | 5 |
| 5616 | pepa | 5 |
| 5617 | pensativa | 5 |
| 5618 | pendientes | 5 |
| 5619 | peldaño | 5 |
| 5620 | pelagatos | 5 |
| 5621 | pegarte | 5 |
| 5622 | pedían | 5 |
| 5623 | peces | 5 |
| 5624 | peca | 5 |
| 5625 | patrocinio | 5 |
| 5626 | patios | 5 |
| 5627 | patíbulo | 5 |
| 5628 | patética | 5 |
| 5629 | patada | 5 |
| 5630 | pastelera | 5 |
| 5631 | pasta | 5 |
| 5632 | pasmaron | 5 |
| 5633 | pasase | 5 |
| 5634 | pasaje | 5 |
| 5635 | partidario | 5 |
| 5636 | particularmente | 5 |
| 5637 | particulares | 5 |
| 5638 | parroquiana | 5 |
| 5639 | párrafos | 5 |
| 5640 | párrafo | 5 |
| 5641 | parido | 5 |
| 5642 | parecieron | 5 |
| 5643 | pareciendo | 5 |
| 5644 | parecerse | 5 |
| 5645 | papelito | 5 |
| 5646 | pánico | 5 |
| 5647 | panadería | 5 |
| 5648 | panacea | 5 |
| 5649 | pana | 5 |
| 5650 | palomas | 5 |
| 5651 | palmito | 5 |
| 5652 | palabritas | 5 |
| 5653 | palabrita | 5 |
| 5654 | paices | 5 |
| 5655 | pague | 5 |
| 5656 | pacífico | 5 |
| 5657 | paces | 5 |
| 5658 | oyéndola | 5 |
| 5659 | original | 5 |
| 5660 | ordenó | 5 |
| 5661 | oración | 5 |
| 5662 | ora | 5 |
| 5663 | oportuno | 5 |
| 5664 | opinó | 5 |
| 5665 | opiniones | 5 |
| 5666 | opinaba | 5 |
| 5667 | operaciones | 5 |
| 5668 | olvidó | 5 |
| 5669 | olían | 5 |
| 5670 | olfato | 5 |
| 5671 | oficinas | 5 |
| 5672 | oficial | 5 |
| 5673 | odoripherus | 5 |
| 5674 | ocurrieron | 5 |
| 5675 | ocupada | 5 |
| 5676 | ocultaba | 5 |
| 5677 | oculta | 5 |
| 5678 | observador | 5 |
| 5679 | observa | 5 |
| 5680 | obrar | 5 |
| 5681 | obligada | 5 |
| 5682 | numancia | 5 |
| 5683 | notaron | 5 |
| 5684 | notado | 5 |
| 5685 | notable | 5 |
| 5686 | nociones | 5 |
| 5687 | niega | 5 |
| 5688 | nido | 5 |
| 5689 | negarlo | 5 |
| 5690 | necesitó | 5 |
| 5691 | naturalidad | 5 |
| 5692 | napoleónica | 5 |
| 5693 | muñeco | 5 |
| 5694 | muñecas | 5 |
| 5695 | muñeca | 5 |
| 5696 | mulas | 5 |
| 5697 | muestrario | 5 |
| 5698 | muertas | 5 |
| 5699 | muelles | 5 |
| 5700 | mudarse | 5 |
| 5701 | muchedumbre | 5 |
| 5702 | movido | 5 |
| 5703 | mote | 5 |
| 5704 | mota | 5 |
| 5705 | mostrándose | 5 |
| 5706 | mostrándole | 5 |
| 5707 | mortuoria | 5 |
| 5708 | morros | 5 |
| 5709 | moros | 5 |
| 5710 | montera | 5 |
| 5711 | monarquía | 5 |
| 5712 | molde | 5 |
| 5713 | modos | 5 |
| 5714 | mismito | 5 |
| 5715 | mírame | 5 |
| 5716 | miquis | 5 |
| 5717 | mimoso | 5 |
| 5718 | milagros | 5 |
| 5719 | miiii | 5 |
| 5720 | mientes | 5 |
| 5721 | mia | 5 |
| 5722 | metiéndose | 5 |
| 5723 | metiendo | 5 |
| 5724 | metían | 5 |
| 5725 | méritos | 5 |
| 5726 | menudillos | 5 |
| 5727 | menudas | 5 |
| 5728 | menores | 5 |
| 5729 | melitona | 5 |
| 5730 | melenas | 5 |
| 5731 | mejorado | 5 |
| 5732 | mediano | 5 |
| 5733 | mecanismo | 5 |
| 5734 | maternal | 5 |
| 5735 | maten | 5 |
| 5736 | mártir | 5 |
| 5737 | marcos | 5 |
| 5738 | marco | 5 |
| 5739 | marchó | 5 |
| 5740 | marchas | 5 |
| 5741 | marcado | 5 |
| 5742 | mantillo | 5 |
| 5743 | manifiesto | 5 |
| 5744 | manías | 5 |
| 5745 | mandaré | 5 |
| 5746 | mamar | 5 |
| 5747 | mama | 5 |
| 5748 | maldición | 5 |
| 5749 | madura | 5 |
| 5750 | madrileños | 5 |
| 5751 | machacar | 5 |
| 5752 | lunes | 5 |
| 5753 | luis | 5 |
| 5754 | lugares | 5 |
| 5755 | lucida | 5 |
| 5756 | lucha | 5 |
| 5757 | lozanía | 5 |
| 5758 | lomo | 5 |
| 5759 | loba | 5 |
| 5760 | lleven | 5 |
| 5761 | llevarme | 5 |
| 5762 | llevaré | 5 |
| 5763 | llevaran | 5 |
| 5764 | llevándola | 5 |
| 5765 | llegase | 5 |
| 5766 | llegaría | 5 |
| 5767 | llegaré | 5 |
| 5768 | llegan | 5 |
| 5769 | llegada | 5 |
| 5770 | llamase | 5 |
| 5771 | llamaré | 5 |
| 5772 | llamándola | 5 |
| 5773 | líquido | 5 |
| 5774 | lindos | 5 |
| 5775 | limpiado | 5 |
| 5776 | ligeras | 5 |
| 5777 | lienzos | 5 |
| 5778 | libras | 5 |
| 5779 | librar | 5 |
| 5780 | libra | 5 |
| 5781 | liado | 5 |
| 5782 | levantaron | 5 |
| 5783 | levantando | 5 |
| 5784 | lenguas | 5 |
| 5785 | legal | 5 |
| 5786 | lee | 5 |
| 5787 | lavado | 5 |
| 5788 | largamente | 5 |
| 5789 | lanzado | 5 |
| 5790 | labores | 5 |
| 5791 | laboratorio | 5 |
| 5792 | labia | 5 |
| 5793 | juzgar | 5 |
| 5794 | joyas | 5 |
| 5795 | jesucristo | 5 |
| 5796 | jaula | 5 |
| 5797 | inverosímil | 5 |
| 5798 | inventaba | 5 |
| 5799 | invención | 5 |
| 5800 | intimidad | 5 |
| 5801 | interna | 5 |
| 5802 | intereses | 5 |
| 5803 | intento | 5 |
| 5804 | intensísimo | 5 |
| 5805 | inspección | 5 |
| 5806 | insistencia | 5 |
| 5807 | insensible | 5 |
| 5808 | inquilinos | 5 |
| 5809 | ingrato | 5 |
| 5810 | ínfulas | 5 |
| 5811 | infinito | 5 |
| 5812 | infiernos | 5 |
| 5813 | infalibles | 5 |
| 5814 | indigno | 5 |
| 5815 | índice | 5 |
| 5816 | indeciso | 5 |
| 5817 | incomodarse | 5 |
| 5818 | incomodado | 5 |
| 5819 | inaudita | 5 |
| 5820 | impresionó | 5 |
| 5821 | impertinentes | 5 |
| 5822 | imparcial | 5 |
| 5823 | iluminaba | 5 |
| 5824 | ideales | 5 |
| 5825 | ibas | 5 |
| 5826 | humorado | 5 |
| 5827 | humedad | 5 |
| 5828 | huérfanos | 5 |
| 5829 | hotel | 5 |
| 5830 | hospicio | 5 |
| 5831 | hormigas | 5 |
| 5832 | hondos | 5 |
| 5833 | hocicos | 5 |
| 5834 | hocico | 5 |
| 5835 | hízolo | 5 |
| 5836 | hipotecas | 5 |
| 5837 | hijita | 5 |
| 5838 | higos | 5 |
| 5839 | hígado | 5 |
| 5840 | hielo | 5 |
| 5841 | herir | 5 |
| 5842 | heredó | 5 |
| 5843 | heredado | 5 |
| 5844 | hechas | 5 |
| 5845 | hala | 5 |
| 5846 | hágase | 5 |
| 5847 | hágalo | 5 |
| 5848 | haciéndolo | 5 |
| 5849 | hablase | 5 |
| 5850 | hablaré | 5 |
| 5851 | habilidad | 5 |
| 5852 | haberlo | 5 |
| 5853 | guasa | 5 |
| 5854 | guapetona | 5 |
| 5855 | gruñido | 5 |
| 5856 | groseros | 5 |
| 5857 | gritar | 5 |
| 5858 | grises | 5 |
| 5859 | gravemente | 5 |
| 5860 | gratis | 5 |
| 5861 | gradualmente | 5 |
| 5862 | gordas | 5 |
| 5863 | glorias | 5 |
| 5864 | giro | 5 |
| 5865 | gentío | 5 |
| 5866 | gemido | 5 |
| 5867 | gatillos | 5 |
| 5868 | gatas | 5 |
| 5869 | gata | 5 |
| 5870 | gastos | 5 |
| 5871 | gastar | 5 |
| 5872 | garras | 5 |
| 5873 | ganga | 5 |
| 5874 | ganar | 5 |
| 5875 | gallardamente | 5 |
| 5876 | furibunda | 5 |
| 5877 | fúnebre | 5 |
| 5878 | fundamento | 5 |
| 5879 | fundada | 5 |
| 5880 | frecuencia | 5 |
| 5881 | franco | 5 |
| 5882 | franceses | 5 |
| 5883 | fotografías | 5 |
| 5884 | forzada | 5 |
| 5885 | fortaleza | 5 |
| 5886 | formado | 5 |
| 5887 | follaje | 5 |
| 5888 | flin | 5 |
| 5889 | flan | 5 |
| 5890 | filas | 5 |
| 5891 | fijarse | 5 |
| 5892 | fijamente | 5 |
| 5893 | figurines | 5 |
| 5894 | figúrese | 5 |
| 5895 | festivo | 5 |
| 5896 | feos | 5 |
| 5897 | feas | 5 |
| 5898 | fascinación | 5 |
| 5899 | farol | 5 |
| 5900 | fango | 5 |
| 5901 | famoso | 5 |
| 5902 | extrañeza | 5 |
| 5903 | extranjeros | 5 |
| 5904 | extranjera | 5 |
| 5905 | extendía | 5 |
| 5906 | explicar | 5 |
| 5907 | expectación | 5 |
| 5908 | exigía | 5 |
| 5909 | excursiones | 5 |
| 5910 | excitaba | 5 |
| 5911 | excepción | 5 |
| 5912 | examinando | 5 |
| 5913 | exámenes | 5 |
| 5914 | exaltada | 5 |
| 5915 | estúpidos | 5 |
| 5916 | estupenda | 5 |
| 5917 | estupefacción | 5 |
| 5918 | estudiaba | 5 |
| 5919 | estrecha | 5 |
| 5920 | estén | 5 |
| 5921 | estáis | 5 |
| 5922 | estaciones | 5 |
| 5923 | establecer | 5 |
| 5924 | espuma | 5 |
| 5925 | esperó | 5 |
| 5926 | espere | 5 |
| 5927 | esmero | 5 |
| 5928 | esforzándose | 5 |
| 5929 | escudo | 5 |
| 5930 | escuchaba | 5 |
| 5931 | escorial | 5 |
| 5932 | escondida | 5 |
| 5933 | esconde | 5 |
| 5934 | escoger | 5 |
| 5935 | escasa | 5 |
| 5936 | escaparates | 5 |
| 5937 | escapado | 5 |
| 5938 | escapa | 5 |
| 5939 | erudición | 5 |
| 5940 | equivocarse | 5 |
| 5941 | envoltorio | 5 |
| 5942 | entrevista | 5 |
| 5943 | entrever | 5 |
| 5944 | entretuvo | 5 |
| 5945 | entretenida | 5 |
| 5946 | entraría | 5 |
| 5947 | entera | 5 |
| 5948 | enseñarle | 5 |
| 5949 | enseñanza | 5 |
| 5950 | ensalada | 5 |
| 5951 | enredadera | 5 |
| 5952 | enemiga | 5 |
| 5953 | enderezar | 5 |
| 5954 | endeble | 5 |
| 5955 | encuentran | 5 |
| 5956 | encontrase | 5 |
| 5957 | encontraría | 5 |
| 5958 | encontramos | 5 |
| 5959 | encogimiento | 5 |
| 5960 | encerrado | 5 |
| 5961 | encajes | 5 |
| 5962 | empresas | 5 |
| 5963 | empeñó | 5 |
| 5964 | empeñadas | 5 |
| 5965 | empeña | 5 |
| 5966 | emociones | 5 |
| 5967 | elementales | 5 |
| 5968 | ejercicios | 5 |
| 5969 | ejercía | 5 |
| 5970 | eficaz | 5 |
| 5971 | efectivo | 5 |
| 5972 | económicas | 5 |
| 5973 | echada | 5 |
| 5974 | duermes | 5 |
| 5975 | dudoso | 5 |
| 5976 | duchas | 5 |
| 5977 | dormitorios | 5 |
| 5978 | dorado | 5 |
| 5979 | dominante | 5 |
| 5980 | doloroso | 5 |
| 5981 | documento | 5 |
| 5982 | doblar | 5 |
| 5983 | diversas | 5 |
| 5984 | disponiéndose | 5 |
| 5985 | displicente | 5 |
| 5986 | disparado | 5 |
| 5987 | disimulaba | 5 |
| 5988 | discurría | 5 |
| 5989 | disciplina | 5 |
| 5990 | dirigirse | 5 |
| 5991 | dirigir | 5 |
| 5992 | directamente | 5 |
| 5993 | dimpués | 5 |
| 5994 | dijiste | 5 |
| 5995 | dijéramos | 5 |
| 5996 | digamos | 5 |
| 5997 | diferencias | 5 |
| 5998 | diamante | 5 |
| 5999 | diabluras | 5 |
| 6000 | devociones | 5 |
| 6001 | detúvose | 5 |
| 6002 | determinaciones | 5 |
| 6003 | determinaba | 5 |
| 6004 | detenidamente | 5 |
| 6005 | detenía | 5 |
| 6006 | detenerse | 5 |
| 6007 | desvanecía | 5 |
| 6008 | desplegar | 5 |
| 6009 | despidiendo | 5 |
| 6010 | despertado | 5 |
| 6011 | despertaban | 5 |
| 6012 | despensa | 5 |
| 6013 | deslizándose | 5 |
| 6014 | desigual | 5 |
| 6015 | desierto | 5 |
| 6016 | deseosa | 5 |
| 6017 | deseara | 5 |
| 6018 | descuidada | 5 |
| 6019 | descubre | 5 |
| 6020 | descubierta | 5 |
| 6021 | descanse | 5 |
| 6022 | descansa | 5 |
| 6023 | descalza | 5 |
| 6024 | desayuno | 5 |
| 6025 | desatino | 5 |
| 6026 | desarrollo | 5 |
| 6027 | desarrollarse | 5 |
| 6028 | desaparecer | 5 |
| 6029 | desairada | 5 |
| 6030 | desabrido | 5 |
| 6031 | derramar | 5 |
| 6032 | deleite | 5 |
| 6033 | dejas | 5 |
| 6034 | dejarte | 5 |
| 6035 | dejarme | 5 |
| 6036 | dejarle | 5 |
| 6037 | dejaré | 5 |
| 6038 | dejándose | 5 |
| 6039 | dejándola | 5 |
| 6040 | deis | 5 |
| 6041 | dedillo | 5 |
| 6042 | dedicó | 5 |
| 6043 | declarar | 5 |
| 6044 | decírselo | 5 |
| 6045 | décimo | 5 |
| 6046 | decidir | 5 |
| 6047 | decías | 5 |
| 6048 | debilidades | 5 |
| 6049 | debí | 5 |
| 6050 | debate | 5 |
| 6051 | date | 5 |
| 6052 | darles | 5 |
| 6053 | darían | 5 |
| 6054 | curvas | 5 |
| 6055 | curva | 5 |
| 6056 | cursis | 5 |
| 6057 | curioso | 5 |
| 6058 | curiosear | 5 |
| 6059 | curar | 5 |
| 6060 | curado | 5 |
| 6061 | cuñado | 5 |
| 6062 | cuña | 5 |
| 6063 | cumplidos | 5 |
| 6064 | cuide | 5 |
| 6065 | cuero | 5 |
| 6066 | cubil | 5 |
| 6067 | cualidades | 5 |
| 6068 | cuadra | 5 |
| 6069 | cristóbal | 5 |
| 6070 | criaturas | 5 |
| 6071 | criadas | 5 |
| 6072 | creyeron | 5 |
| 6073 | creían | 5 |
| 6074 | creeré | 5 |
| 6075 | créeme | 5 |
| 6076 | cotorra | 5 |
| 6077 | coscorrones | 5 |
| 6078 | cortina | 5 |
| 6079 | cortés | 5 |
| 6080 | cortaba | 5 |
| 6081 | corsé | 5 |
| 6082 | corrieron | 5 |
| 6083 | correspondiente | 5 |
| 6084 | correspondía | 5 |
| 6085 | correos | 5 |
| 6086 | corredora | 5 |
| 6087 | coraje | 5 |
| 6088 | convino | 5 |
| 6089 | convierte | 5 |
| 6090 | convertir | 5 |
| 6091 | convertido | 5 |
| 6092 | convencimiento | 5 |
| 6093 | convencido | 5 |
| 6094 | convencer | 5 |
| 6095 | contuvo | 5 |
| 6096 | contrabandista | 5 |
| 6097 | continuar | 5 |
| 6098 | contenido | 5 |
| 6099 | contempló | 5 |
| 6100 | contara | 5 |
| 6101 | contadas | 5 |
| 6102 | consumados | 5 |
| 6103 | consulta | 5 |
| 6104 | consternación | 5 |
| 6105 | constancia | 5 |
| 6106 | consiguiente | 5 |
| 6107 | conservando | 5 |
| 6108 | conserva | 5 |
| 6109 | conquista | 5 |
| 6110 | conozca | 5 |
| 6111 | conocimientos | 5 |
| 6112 | conocidos | 5 |
| 6113 | conmovía | 5 |
| 6114 | congreso | 5 |
| 6115 | conformarse | 5 |
| 6116 | conformaba | 5 |
| 6117 | confidencias | 5 |
| 6118 | confidencia | 5 |
| 6119 | condenados | 5 |
| 6120 | concordia | 5 |
| 6121 | concluyendo | 5 |
| 6122 | conciencias | 5 |
| 6123 | comunicó | 5 |
| 6124 | comprendes | 5 |
| 6125 | comprenderá | 5 |
| 6126 | compraba | 5 |
| 6127 | compás | 5 |
| 6128 | comerse | 5 |
| 6129 | comería | 5 |
| 6130 | combinaciones | 5 |
| 6131 | combatir | 5 |
| 6132 | colgado | 5 |
| 6133 | cojita | 5 |
| 6134 | cogieron | 5 |
| 6135 | cogerle | 5 |
| 6136 | cogerla | 5 |
| 6137 | cofre | 5 |
| 6138 | cobarde | 5 |
| 6139 | clerical | 5 |
| 6140 | clareaba | 5 |
| 6141 | circunstantes | 5 |
| 6142 | cigarros | 5 |
| 6143 | cigarrillo | 5 |
| 6144 | ciegos | 5 |
| 6145 | choque | 5 |
| 6146 | chocho | 5 |
| 6147 | chistar | 5 |
| 6148 | chillando | 5 |
| 6149 | chillaba | 5 |
| 6150 | chí | 5 |
| 6151 | charlar | 5 |
| 6152 | chapa | 5 |
| 6153 | chalán | 5 |
| 6154 | cesó | 5 |
| 6155 | cerveza | 5 |
| 6156 | celosa | 5 |
| 6157 | cebada | 5 |
| 6158 | cazador | 5 |
| 6159 | cayetano | 5 |
| 6160 | cavidad | 5 |
| 6161 | católico | 5 |
| 6162 | católica | 5 |
| 6163 | catedral | 5 |
| 6164 | catástrofe | 5 |
| 6165 | castillos | 5 |
| 6166 | castigar | 5 |
| 6167 | cascos | 5 |
| 6168 | cascarón | 5 |
| 6169 | carteras | 5 |
| 6170 | cartera | 5 |
| 6171 | carnicería | 5 |
| 6172 | cariñosamente | 5 |
| 6173 | cariños | 5 |
| 6174 | cargada | 5 |
| 6175 | careta | 5 |
| 6176 | carcajadas | 5 |
| 6177 | cañón | 5 |
| 6178 | cansada | 5 |
| 6179 | cánovas | 5 |
| 6180 | cándido | 5 |
| 6181 | calva | 5 |
| 6182 | calmó | 5 |
| 6183 | calmarle | 5 |
| 6184 | callo | 5 |
| 6185 | callejón | 5 |
| 6186 | caletre | 5 |
| 6187 | calderilla | 5 |
| 6188 | caída | 5 |
| 6189 | cabezadas | 5 |
| 6190 | caballería | 5 |
| 6191 | busque | 5 |
| 6192 | burgos | 5 |
| 6193 | brasero | 5 |
| 6194 | botín | 5 |
| 6195 | bloque | 5 |
| 6196 | bilboquet | 5 |
| 6197 | bienes | 5 |
| 6198 | bicerra | 5 |
| 6199 | betún | 5 |
| 6200 | bestias | 5 |
| 6201 | bella | 5 |
| 6202 | batalla | 5 |
| 6203 | bastones | 5 |
| 6204 | bastero | 5 |
| 6205 | bastaba | 5 |
| 6206 | barbaridades | 5 |
| 6207 | barato | 5 |
| 6208 | bandeja | 5 |
| 6209 | bancos | 5 |
| 6210 | bajos | 5 |
| 6211 | bajón | 5 |
| 6212 | bajan | 5 |
| 6213 | baile | 5 |
| 6214 | ayuntamiento | 5 |
| 6215 | ayunas | 5 |
| 6216 | avisar | 5 |
| 6217 | avanzó | 5 |
| 6218 | avanzaba | 5 |
| 6219 | aumentó | 5 |
| 6220 | atributos | 5 |
| 6221 | atreve | 5 |
| 6222 | atravesaba | 5 |
| 6223 | atracción | 5 |
| 6224 | atento | 5 |
| 6225 | atenta | 5 |
| 6226 | atendiendo | 5 |
| 6227 | atada | 5 |
| 6228 | aspirar | 5 |
| 6229 | asomó | 5 |
| 6230 | asno | 5 |
| 6231 | aseguraba | 5 |
| 6232 | artesa | 5 |
| 6233 | arrojado | 5 |
| 6234 | arreglaré | 5 |
| 6235 | arreglada | 5 |
| 6236 | arrastrado | 5 |
| 6237 | armario | 5 |
| 6238 | arenas | 5 |
| 6239 | ardientes | 5 |
| 6240 | arco | 5 |
| 6241 | aquél | 5 |
| 6242 | apurar | 5 |
| 6243 | apurada | 5 |
| 6244 | apuntar | 5 |
| 6245 | aprisa | 5 |
| 6246 | apretar | 5 |
| 6247 | aprenden | 5 |
| 6248 | apreciable | 5 |
| 6249 | apreciaba | 5 |
| 6250 | apoyo | 5 |
| 6251 | apartando | 5 |
| 6252 | aparentaba | 5 |
| 6253 | aparecido | 5 |
| 6254 | apacible | 5 |
| 6255 | antipática | 5 |
| 6256 | antiespasmódica | 5 |
| 6257 | anteriores | 5 |
| 6258 | ansias | 5 |
| 6259 | angustias | 5 |
| 6260 | andado | 5 |
| 6261 | ancha | 5 |
| 6262 | amorosas | 5 |
| 6263 | alumnas | 5 |
| 6264 | alturas | 5 |
| 6265 | alquilar | 5 |
| 6266 | almacenes | 5 |
| 6267 | alimento | 5 |
| 6268 | alejó | 5 |
| 6269 | alejándose | 5 |
| 6270 | alejado | 5 |
| 6271 | alegres | 5 |
| 6272 | alcanzar | 5 |
| 6273 | alcance | 5 |
| 6274 | alcalá | 5 |
| 6275 | albañiles | 5 |
| 6276 | ajenas | 5 |
| 6277 | airada | 5 |
| 6278 | agudísimo | 5 |
| 6279 | agudeza | 5 |
| 6280 | agradeció | 5 |
| 6281 | agradecía | 5 |
| 6282 | agradable | 5 |
| 6283 | agonías | 5 |
| 6284 | afirmativamente | 5 |
| 6285 | afectaba | 5 |
| 6286 | adquiriendo | 5 |
| 6287 | adorno | 5 |
| 6288 | adorada | 5 |
| 6289 | adoptiva | 5 |
| 6290 | adivinaba | 5 |
| 6291 | acusaciones | 5 |
| 6292 | acudieron | 5 |
| 6293 | activo | 5 |
| 6294 | acostada | 5 |
| 6295 | acompañe | 5 |
| 6296 | acertó | 5 |
| 6297 | acerté | 5 |
| 6298 | acercando | 5 |
| 6299 | acepta | 5 |
| 6300 | acentuado | 5 |
| 6301 | acabara | 5 |
| 6302 | abuelito | 5 |
| 6303 | abstracción | 5 |
| 6304 | abro | 5 |
| 6305 | abrirle | 5 |
| 6306 | yerta | 4 |
| 6307 | yendo | 4 |
| 6308 | yeciones | 4 |
| 6309 | yeción | 4 |
| 6310 | xii | 4 |
| 6311 | vus | 4 |
| 6312 | vulgaridad | 4 |
| 6313 | volviese | 4 |
| 6314 | volviera | 4 |
| 6315 | volverla | 4 |
| 6316 | volcán | 4 |
| 6317 | vocablo | 4 |
| 6318 | vivirá | 4 |
| 6319 | vivió | 4 |
| 6320 | viviese | 4 |
| 6321 | viviente | 4 |
| 6322 | vistió | 4 |
| 6323 | vísperas | 4 |
| 6324 | visitado | 4 |
| 6325 | viruelas | 4 |
| 6326 | violín | 4 |
| 6327 | violentas | 4 |
| 6328 | violenta | 4 |
| 6329 | violencias | 4 |
| 6330 | viñas | 4 |
| 6331 | vínole | 4 |
| 6332 | vinieran | 4 |
| 6333 | viniendo | 4 |
| 6334 | vimos | 4 |
| 6335 | vientos | 4 |
| 6336 | vicios | 4 |
| 6337 | víbora | 4 |
| 6338 | viajar | 4 |
| 6339 | viajante | 4 |
| 6340 | vestíbulo | 4 |
| 6341 | verbi | 4 |
| 6342 | ventura | 4 |
| 6343 | vente | 4 |
| 6344 | ventanillo | 4 |
| 6345 | vengarse | 4 |
| 6346 | vengaré | 4 |
| 6347 | veneración | 4 |
| 6348 | vendrán | 4 |
| 6349 | vendida | 4 |
| 6350 | vena | 4 |
| 6351 | velocidad | 4 |
| 6352 | veinticuatro | 4 |
| 6353 | veíase | 4 |
| 6354 | vastísimo | 4 |
| 6355 | vástago | 4 |
| 6356 | varones | 4 |
| 6357 | valle | 4 |
| 6358 | valían | 4 |
| 6359 | vagas | 4 |
| 6360 | vagar | 4 |
| 6361 | vaciado | 4 |
| 6362 | uvas | 4 |
| 6363 | usté | 4 |
| 6364 | urna | 4 |
| 6365 | uña | 4 |
| 6366 | unción | 4 |
| 6367 | ultramar | 4 |
| 6368 | ultrajado | 4 |
| 6369 | tuvieras | 4 |
| 6370 | tute | 4 |
| 6371 | turco | 4 |
| 6372 | túnel | 4 |
| 6373 | tun | 4 |
| 6374 | tufo | 4 |
| 6375 | tubo | 4 |
| 6376 | trozo | 4 |
| 6377 | tropezó | 4 |
| 6378 | tropezaron | 4 |
| 6379 | tropas | 4 |
| 6380 | trono | 4 |
| 6381 | tronar | 4 |
| 6382 | trompeta | 4 |
| 6383 | trombón | 4 |
| 6384 | trocaba | 4 |
| 6385 | triunfos | 4 |
| 6386 | triunfar | 4 |
| 6387 | tristísima | 4 |
| 6388 | tristemente | 4 |
| 6389 | trinqué | 4 |
| 6390 | trenzas | 4 |
| 6391 | trémula | 4 |
| 6392 | trazas | 4 |
| 6393 | travieso | 4 |
| 6394 | tratarte | 4 |
| 6395 | trataron | 4 |
| 6396 | trataré | 4 |
| 6397 | tratándose | 4 |
| 6398 | tratan | 4 |
| 6399 | trastornos | 4 |
| 6400 | trastornaba | 4 |
| 6401 | trastamara | 4 |
| 6402 | trapitos | 4 |
| 6403 | trapisondas | 4 |
| 6404 | transijo | 4 |
| 6405 | transacción | 4 |
| 6406 | tranquilizarse | 4 |
| 6407 | tranquilizarla | 4 |
| 6408 | traidor | 4 |
| 6409 | traída | 4 |
| 6410 | traición | 4 |
| 6411 | tragedia | 4 |
| 6412 | tragaderas | 4 |
| 6413 | tráete | 4 |
| 6414 | tráeme | 4 |
| 6415 | tradiciones | 4 |
| 6416 | tradicional | 4 |
| 6417 | trabaje | 4 |
| 6418 | torre | 4 |
| 6419 | torpe | 4 |
| 6420 | toro | 4 |
| 6421 | torcer | 4 |
| 6422 | tomes | 4 |
| 6423 | tomé | 4 |
| 6424 | tomarla | 4 |
| 6425 | tocaya | 4 |
| 6426 | tocata | 4 |
| 6427 | tocara | 4 |
| 6428 | toalla | 4 |
| 6429 | tiran | 4 |
| 6430 | timbre | 4 |
| 6431 | tierras | 4 |
| 6432 | tiernas | 4 |
| 6433 | texto | 4 |
| 6434 | tétrica | 4 |
| 6435 | testigos | 4 |
| 6436 | testigo | 4 |
| 6437 | tesón | 4 |
| 6438 | terrorífica | 4 |
| 6439 | terrones | 4 |
| 6440 | terminantemente | 4 |
| 6441 | terminante | 4 |
| 6442 | teorías | 4 |
| 6443 | tentaciones | 4 |
| 6444 | tendido | 4 |
| 6445 | tendida | 4 |
| 6446 | tenaz | 4 |
| 6447 | tempranito | 4 |
| 6448 | templo | 4 |
| 6449 | templado | 4 |
| 6450 | tempestad | 4 |
| 6451 | temperamento | 4 |
| 6452 | temer | 4 |
| 6453 | temblor | 4 |
| 6454 | telón | 4 |
| 6455 | teje | 4 |
| 6456 | taza | 4 |
| 6457 | tarjeta | 4 |
| 6458 | tareas | 4 |
| 6459 | tardar | 4 |
| 6460 | tardaba | 4 |
| 6461 | tararí | 4 |
| 6462 | tapó | 4 |
| 6463 | tapias | 4 |
| 6464 | tapar | 4 |
| 6465 | tapándose | 4 |
| 6466 | tantísimos | 4 |
| 6467 | talonario | 4 |
| 6468 | talante | 4 |
| 6469 | tacto | 4 |
| 6470 | tacón | 4 |
| 6471 | tabla | 4 |
| 6472 | sutiles | 4 |
| 6473 | susurro | 4 |
| 6474 | sustancias | 4 |
| 6475 | suspicaz | 4 |
| 6476 | suspendiendo | 4 |
| 6477 | suponiendo | 4 |
| 6478 | supongo | 4 |
| 6479 | supongamos | 4 |
| 6480 | supieron | 4 |
| 6481 | supieran | 4 |
| 6482 | superficie | 4 |
| 6483 | sumo | 4 |
| 6484 | sujetó | 4 |
| 6485 | sujeta | 4 |
| 6486 | suizo | 4 |
| 6487 | sufría | 4 |
| 6488 | suegros | 4 |
| 6489 | sudorosa | 4 |
| 6490 | sudar | 4 |
| 6491 | sudaba | 4 |
| 6492 | sucias | 4 |
| 6493 | sucede | 4 |
| 6494 | sotanas | 4 |
| 6495 | sotana | 4 |
| 6496 | sostuvo | 4 |
| 6497 | sosteniendo | 4 |
| 6498 | sospechas | 4 |
| 6499 | soso | 4 |
| 6500 | sosiégate | 4 |
| 6501 | sosegado | 4 |
| 6502 | sortijillas | 4 |
| 6503 | soñar | 4 |
| 6504 | sonrió | 4 |
| 6505 | sonaban | 4 |
| 6506 | someter | 4 |
| 6507 | sombrío | 4 |
| 6508 | soltura | 4 |
| 6509 | soltero | 4 |
| 6510 | soltera | 4 |
| 6511 | solfa | 4 |
| 6512 | soldado | 4 |
| 6513 | sofía | 4 |
| 6514 | sodio | 4 |
| 6515 | sócrates | 4 |
| 6516 | socorros | 4 |
| 6517 | socios | 4 |
| 6518 | sobremesa | 4 |
| 6519 | sobras | 4 |
| 6520 | sobrante | 4 |
| 6521 | sirviera | 4 |
| 6522 | sirves | 4 |
| 6523 | sintiéndose | 4 |
| 6524 | simpatías | 4 |
| 6525 | símbolos | 4 |
| 6526 | sillita | 4 |
| 6527 | sillares | 4 |
| 6528 | siguiera | 4 |
| 6529 | signos | 4 |
| 6530 | significan | 4 |
| 6531 | significación | 4 |
| 6532 | significa | 4 |
| 6533 | severamente | 4 |
| 6534 | setenta | 4 |
| 6535 | servilleta | 4 |
| 6536 | serrano | 4 |
| 6537 | serrana | 4 |
| 6538 | serías | 4 |
| 6539 | seríamos | 4 |
| 6540 | sepulcro | 4 |
| 6541 | separó | 4 |
| 6542 | separaba | 4 |
| 6543 | sensible | 4 |
| 6544 | senderos | 4 |
| 6545 | seductores | 4 |
| 6546 | seductora | 4 |
| 6547 | secretario | 4 |
| 6548 | secretaría | 4 |
| 6549 | secándose | 4 |
| 6550 | sebastián | 4 |
| 6551 | satanás | 4 |
| 6552 | sáqueme | 4 |
| 6553 | santidades | 4 |
| 6554 | samaniegos | 4 |
| 6555 | salvarse | 4 |
| 6556 | saludó | 4 |
| 6557 | saltara | 4 |
| 6558 | sagaz | 4 |
| 6559 | sacudió | 4 |
| 6560 | sabroso | 4 |
| 6561 | sabrosas | 4 |
| 6562 | sabría | 4 |
| 6563 | sablazo | 4 |
| 6564 | sabias | 4 |
| 6565 | rutina | 4 |
| 6566 | rumbo | 4 |
| 6567 | ruina | 4 |
| 6568 | rótulos | 4 |
| 6569 | rotos | 4 |
| 6570 | rotas | 4 |
| 6571 | rota | 4 |
| 6572 | ropita | 4 |
| 6573 | romanticismo | 4 |
| 6574 | romántica | 4 |
| 6575 | roma | 4 |
| 6576 | rogar | 4 |
| 6577 | robo | 4 |
| 6578 | rió | 4 |
| 6579 | riñas | 4 |
| 6580 | ridiculez | 4 |
| 6581 | rezos | 4 |
| 6582 | rezaba | 4 |
| 6583 | revuelta | 4 |
| 6584 | revolviéndose | 4 |
| 6585 | revolver | 4 |
| 6586 | revolucionaria | 4 |
| 6587 | revolcándose | 4 |
| 6588 | revista | 4 |
| 6589 | reventar | 4 |
| 6590 | reveló | 4 |
| 6591 | revelado | 4 |
| 6592 | retroceso | 4 |
| 6593 | retiraron | 4 |
| 6594 | retirándose | 4 |
| 6595 | retintín | 4 |
| 6596 | reticencia | 4 |
| 6597 | resultados | 4 |
| 6598 | respetabilidad | 4 |
| 6599 | respectivos | 4 |
| 6600 | resolvió | 4 |
| 6601 | resistiéndose | 4 |
| 6602 | resiste | 4 |
| 6603 | res | 4 |
| 6604 | representar | 4 |
| 6605 | reposado | 4 |
| 6606 | repetidas | 4 |
| 6607 | repartió | 4 |
| 6608 | renegar | 4 |
| 6609 | remota | 4 |
| 6610 | remojo | 4 |
| 6611 | remilgos | 4 |
| 6612 | remiendos | 4 |
| 6613 | remedios | 4 |
| 6614 | remate | 4 |
| 6615 | religiosamente | 4 |
| 6616 | relámpago | 4 |
| 6617 | relajación | 4 |
| 6618 | relacionadas | 4 |
| 6619 | reías | 4 |
| 6620 | rehízo | 4 |
| 6621 | regularidad | 4 |
| 6622 | refrescaba | 4 |
| 6623 | reforma | 4 |
| 6624 | reflexión | 4 |
| 6625 | refirió | 4 |
| 6626 | refiero | 4 |
| 6627 | refiere | 4 |
| 6628 | referir | 4 |
| 6629 | refería | 4 |
| 6630 | reducida | 4 |
| 6631 | rédito | 4 |
| 6632 | redacciones | 4 |
| 6633 | recurso | 4 |
| 6634 | recurrir | 4 |
| 6635 | recto | 4 |
| 6636 | recreo | 4 |
| 6637 | recreándose | 4 |
| 6638 | recorriendo | 4 |
| 6639 | recomiendo | 4 |
| 6640 | recomendándole | 4 |
| 6641 | recomendaba | 4 |
| 6642 | recogido | 4 |
| 6643 | recoge | 4 |
| 6644 | recocho | 4 |
| 6645 | recobrar | 4 |
| 6646 | reclusa | 4 |
| 6647 | reclama | 4 |
| 6648 | recibiera | 4 |
| 6649 | recibí | 4 |
| 6650 | rechazo | 4 |
| 6651 | recetas | 4 |
| 6652 | receta | 4 |
| 6653 | recelosa | 4 |
| 6654 | rebelde | 4 |
| 6655 | rebaño | 4 |
| 6656 | ras | 4 |
| 6657 | raros | 4 |
| 6658 | ráfagas | 4 |
| 6659 | quitarán | 4 |
| 6660 | quitará | 4 |
| 6661 | quitara | 4 |
| 6662 | quisieras | 4 |
| 6663 | quinta | 4 |
| 6664 | quid | 4 |
| 6665 | querría | 4 |
| 6666 | quercus | 4 |
| 6667 | quejumbrosa | 4 |
| 6668 | quejándose | 4 |
| 6669 | quehaceres | 4 |
| 6670 | quédese | 4 |
| 6671 | quedara | 4 |
| 6672 | pusiese | 4 |
| 6673 | purificación | 4 |
| 6674 | purifica | 4 |
| 6675 | puntual | 4 |
| 6676 | puedan | 4 |
| 6677 | publicaciones | 4 |
| 6678 | púas | 4 |
| 6679 | prudencia | 4 |
| 6680 | provincias | 4 |
| 6681 | protesta | 4 |
| 6682 | proteger | 4 |
| 6683 | proponer | 4 |
| 6684 | propietario | 4 |
| 6685 | pronunciamiento | 4 |
| 6686 | pronunciación | 4 |
| 6687 | prontitud | 4 |
| 6688 | prolongar | 4 |
| 6689 | profundos | 4 |
| 6690 | profundísima | 4 |
| 6691 | profesión | 4 |
| 6692 | produzca | 4 |
| 6693 | produciéndole | 4 |
| 6694 | producido | 4 |
| 6695 | prodigios | 4 |
| 6696 | procedía | 4 |
| 6697 | probó | 4 |
| 6698 | privada | 4 |
| 6699 | previsto | 4 |
| 6700 | prevención | 4 |
| 6701 | pretenden | 4 |
| 6702 | presurosa | 4 |
| 6703 | prestó | 4 |
| 6704 | preparativos | 4 |
| 6705 | preparar | 4 |
| 6706 | preocupaciones | 4 |
| 6707 | preguntándole | 4 |
| 6708 | pregúntale | 4 |
| 6709 | prefiero | 4 |
| 6710 | precoz | 4 |
| 6711 | preciosísima | 4 |
| 6712 | prado | 4 |
| 6713 | prácticamente | 4 |
| 6714 | poseedor | 4 |
| 6715 | portó | 4 |
| 6716 | pondrán | 4 |
| 6717 | pondrá | 4 |
| 6718 | pollos | 4 |
| 6719 | pollas | 4 |
| 6720 | poéticas | 4 |
| 6721 | poética | 4 |
| 6722 | podrán | 4 |
| 6723 | podías | 4 |
| 6724 | poderosa | 4 |
| 6725 | pobrecitos | 4 |
| 6726 | población | 4 |
| 6727 | plencia | 4 |
| 6728 | plena | 4 |
| 6729 | platerías | 4 |
| 6730 | plantas | 4 |
| 6731 | plantado | 4 |
| 6732 | planchadora | 4 |
| 6733 | placidez | 4 |
| 6734 | plácemes | 4 |
| 6735 | pisadas | 4 |
| 6736 | pintor | 4 |
| 6737 | pinto | 4 |
| 6738 | pintar | 4 |
| 6739 | pintadas | 4 |
| 6740 | pierda | 4 |
| 6741 | pienses | 4 |
| 6742 | piénselo | 4 |
| 6743 | picoteando | 4 |
| 6744 | picarona | 4 |
| 6745 | picado | 4 |
| 6746 | pica | 4 |
| 6747 | pestes | 4 |
| 6748 | pestañear | 4 |
| 6749 | pesó | 4 |
| 6750 | pesimismo | 4 |
| 6751 | pescadores | 4 |
| 6752 | pesadumbre | 4 |
| 6753 | perverso | 4 |
| 6754 | perspicaz | 4 |
| 6755 | personajes | 4 |
| 6756 | perseguido | 4 |
| 6757 | perplejidad | 4 |
| 6758 | permitiera | 4 |
| 6759 | permite | 4 |
| 6760 | peripecia | 4 |
| 6761 | perfume | 4 |
| 6762 | perfiles | 4 |
| 6763 | perdulario | 4 |
| 6764 | perdónala | 4 |
| 6765 | perdis | 4 |
| 6766 | percal | 4 |
| 6767 | pequeños | 4 |
| 6768 | pequeñas | 4 |
| 6769 | pepito | 4 |
| 6770 | pensara | 4 |
| 6771 | penoso | 4 |
| 6772 | penetrante | 4 |
| 6773 | pendiente | 4 |
| 6774 | pellejo | 4 |
| 6775 | peligroso | 4 |
| 6776 | pelea | 4 |
| 6777 | peinarse | 4 |
| 6778 | pegarme | 4 |
| 6779 | pegándose | 4 |
| 6780 | pegan | 4 |
| 6781 | pegados | 4 |
| 6782 | pegada | 4 |
| 6783 | pediría | 4 |
| 6784 | pedernal | 4 |
| 6785 | pecadoras | 4 |
| 6786 | patriotismo | 4 |
| 6787 | patillas | 4 |
| 6788 | patético | 4 |
| 6789 | patata | 4 |
| 6790 | pasmado | 4 |
| 6791 | pasmaba | 4 |
| 6792 | pasearse | 4 |
| 6793 | pasarse | 4 |
| 6794 | pasajes | 4 |
| 6795 | partir | 4 |
| 6796 | parrafito | 4 |
| 6797 | parola | 4 |
| 6798 | pares | 4 |
| 6799 | parentescos | 4 |
| 6800 | parejas | 4 |
| 6801 | pararse | 4 |
| 6802 | pararon | 4 |
| 6803 | paquetito | 4 |
| 6804 | papelera | 4 |
| 6805 | pandereta | 4 |
| 6806 | palidez | 4 |
| 6807 | página | 4 |
| 6808 | pagarés | 4 |
| 6809 | pagado | 4 |
| 6810 | padeciendo | 4 |
| 6811 | paco | 4 |
| 6812 | pachorra | 4 |
| 6813 | oscuros | 4 |
| 6814 | orillo | 4 |
| 6815 | orilla | 4 |
| 6816 | orígenes | 4 |
| 6817 | órgano | 4 |
| 6818 | organización | 4 |
| 6819 | orgánica | 4 |
| 6820 | ordenaba | 4 |
| 6821 | opuesto | 4 |
| 6822 | onzas | 4 |
| 6823 | ondas | 4 |
| 6824 | olvides | 4 |
| 6825 | olvidarse | 4 |
| 6826 | olvida | 4 |
| 6827 | oler | 4 |
| 6828 | olé | 4 |
| 6829 | ojuelos | 4 |
| 6830 | oírlo | 4 |
| 6831 | oírlas | 4 |
| 6832 | ofrecimientos | 4 |
| 6833 | ofrecieron | 4 |
| 6834 | ofreciendo | 4 |
| 6835 | ofender | 4 |
| 6836 | odios | 4 |
| 6837 | odiaba | 4 |
| 6838 | ocurriole | 4 |
| 6839 | ocupó | 4 |
| 6840 | ocupación | 4 |
| 6841 | octubre | 4 |
| 6842 | obtenido | 4 |
| 6843 | observado | 4 |
| 6844 | obrera | 4 |
| 6845 | obedecía | 4 |
| 6846 | obedecer | 4 |
| 6847 | nuevamente | 4 |
| 6848 | noté | 4 |
| 6849 | notando | 4 |
| 6850 | nombró | 4 |
| 6851 | nodriza | 4 |
| 6852 | niñita | 4 |
| 6853 | niegues | 4 |
| 6854 | nidos | 4 |
| 6855 | neófita | 4 |
| 6856 | negarás | 4 |
| 6857 | necesarios | 4 |
| 6858 | necesario | 4 |
| 6859 | nave | 4 |
| 6860 | náuseas | 4 |
| 6861 | naturalezas | 4 |
| 6862 | naturales | 4 |
| 6863 | narcissus | 4 |
| 6864 | nacimientos | 4 |
| 6865 | nacidos | 4 |
| 6866 | nacen | 4 |
| 6867 | muslo | 4 |
| 6868 | músico | 4 |
| 6869 | muscular | 4 |
| 6870 | mus | 4 |
| 6871 | muros | 4 |
| 6872 | murmullo | 4 |
| 6873 | muriera | 4 |
| 6874 | mujeronas | 4 |
| 6875 | mugidos | 4 |
| 6876 | mugido | 4 |
| 6877 | mueren | 4 |
| 6878 | mudanzas | 4 |
| 6879 | movió | 4 |
| 6880 | moviéndose | 4 |
| 6881 | movían | 4 |
| 6882 | mostrábase | 4 |
| 6883 | moro | 4 |
| 6884 | moralmente | 4 |
| 6885 | moralidad | 4 |
| 6886 | moñas | 4 |
| 6887 | monos | 4 |
| 6888 | monas | 4 |
| 6889 | molido | 4 |
| 6890 | molestaban | 4 |
| 6891 | molesta | 4 |
| 6892 | mohín | 4 |
| 6893 | modistas | 4 |
| 6894 | modesto | 4 |
| 6895 | mocosos | 4 |
| 6896 | místico | 4 |
| 6897 | misericordia | 4 |
| 6898 | mírela | 4 |
| 6899 | miré | 4 |
| 6900 | mírala | 4 |
| 6901 | mirábale | 4 |
| 6902 | mimo | 4 |
| 6903 | miles | 4 |
| 6904 | mico | 4 |
| 6905 | metro | 4 |
| 6906 | metidos | 4 |
| 6907 | mercurio | 4 |
| 6908 | merced | 4 |
| 6909 | mequetrefe | 4 |
| 6910 | mentar | 4 |
| 6911 | mentalmente | 4 |
| 6912 | mensual | 4 |
| 6913 | menesteres | 4 |
| 6914 | memo | 4 |
| 6915 | melancólica | 4 |
| 6916 | mejoró | 4 |
| 6917 | mejoría | 4 |
| 6918 | meditabunda | 4 |
| 6919 | mechones | 4 |
| 6920 | matute | 4 |
| 6921 | materialista | 4 |
| 6922 | matarte | 4 |
| 6923 | matarle | 4 |
| 6924 | matarla | 4 |
| 6925 | marquesas | 4 |
| 6926 | marquesa | 4 |
| 6927 | marimorena | 4 |
| 6928 | maravillosa | 4 |
| 6929 | maquinalmente | 4 |
| 6930 | mañanita | 4 |
| 6931 | manotadas | 4 |
| 6932 | manifestarse | 4 |
| 6933 | manifestar | 4 |
| 6934 | manifestaciones | 4 |
| 6935 | maniática | 4 |
| 6936 | manguito | 4 |
| 6937 | mandarla | 4 |
| 6938 | mandando | 4 |
| 6939 | maná | 4 |
| 6940 | mampara | 4 |
| 6941 | malito | 4 |
| 6942 | maldiciones | 4 |
| 6943 | maldecido | 4 |
| 6944 | majo | 4 |
| 6945 | maduras | 4 |
| 6946 | madrecita | 4 |
| 6947 | machacárselo | 4 |
| 6948 | machacando | 4 |
| 6949 | luminosa | 4 |
| 6950 | lúgubres | 4 |
| 6951 | loza | 4 |
| 6952 | logró | 4 |
| 6953 | lograba | 4 |
| 6954 | llovía | 4 |
| 6955 | llorente | 4 |
| 6956 | llevársela | 4 |
| 6957 | llevarla | 4 |
| 6958 | llevaría | 4 |
| 6959 | llevaremos | 4 |
| 6960 | llevara | 4 |
| 6961 | llevándole | 4 |
| 6962 | llenar | 4 |
| 6963 | llegaban | 4 |
| 6964 | llano | 4 |
| 6965 | llamarle | 4 |
| 6966 | llamados | 4 |
| 6967 | llamábase | 4 |
| 6968 | lívida | 4 |
| 6969 | literarias | 4 |
| 6970 | linda | 4 |
| 6971 | limpiándose | 4 |
| 6972 | limosnas | 4 |
| 6973 | limón | 4 |
| 6974 | lienzo | 4 |
| 6975 | licor | 4 |
| 6976 | libremente | 4 |
| 6977 | librarse | 4 |
| 6978 | levitas | 4 |
| 6979 | leve | 4 |
| 6980 | leona | 4 |
| 6981 | lector | 4 |
| 6982 | lavapiés | 4 |
| 6983 | lavaba | 4 |
| 6984 | láudano | 4 |
| 6985 | latín | 4 |
| 6986 | lápiz | 4 |
| 6987 | lápida | 4 |
| 6988 | lagrimita | 4 |
| 6989 | lágrima | 4 |
| 6990 | labrado | 4 |
| 6991 | juntamente | 4 |
| 6992 | juncos | 4 |
| 6993 | juiciosa | 4 |
| 6994 | juguete | 4 |
| 6995 | jovialidad | 4 |
| 6996 | jaulas | 4 |
| 6997 | jamón | 4 |
| 6998 | islas | 4 |
| 6999 | irías | 4 |
| 7000 | invencible | 4 |
| 7001 | inundaba | 4 |
| 7002 | intranquilo | 4 |
| 7003 | intranquila | 4 |
| 7004 | interrumpió | 4 |
| 7005 | interlocutora | 4 |
| 7006 | interiormente | 4 |
| 7007 | intereso | 4 |
| 7008 | interesa | 4 |
| 7009 | intentaba | 4 |
| 7010 | instruirse | 4 |
| 7011 | instituciones | 4 |
| 7012 | institución | 4 |
| 7013 | instantes | 4 |
| 7014 | instantánea | 4 |
| 7015 | insinuó | 4 |
| 7016 | inseguro | 4 |
| 7017 | inscripciones | 4 |
| 7018 | inofensivo | 4 |
| 7019 | inmuebles | 4 |
| 7020 | ingratitud | 4 |
| 7021 | ingrata | 4 |
| 7022 | ingenua | 4 |
| 7023 | ingenioso | 4 |
| 7024 | ingeniosa | 4 |
| 7025 | inflexiones | 4 |
| 7026 | inferiores | 4 |
| 7027 | infames | 4 |
| 7028 | inerte | 4 |
| 7029 | inefables | 4 |
| 7030 | individual | 4 |
| 7031 | indignada | 4 |
| 7032 | indicación | 4 |
| 7033 | incorporose | 4 |
| 7034 | inconvenientes | 4 |
| 7035 | incomodada | 4 |
| 7036 | inclinose | 4 |
| 7037 | inclinada | 4 |
| 7038 | inclinaciones | 4 |
| 7039 | inciso | 4 |
| 7040 | inauguración | 4 |
| 7041 | in | 4 |
| 7042 | impulsaba | 4 |
| 7043 | imprenta | 4 |
| 7044 | importe | 4 |
| 7045 | imperturbable | 4 |
| 7046 | impedirlo | 4 |
| 7047 | imparcialidad | 4 |
| 7048 | imitando | 4 |
| 7049 | imitación | 4 |
| 7050 | imaginarse | 4 |
| 7051 | iluminados | 4 |
| 7052 | igualmente | 4 |
| 7053 | ignoraba | 4 |
| 7054 | ignominias | 4 |
| 7055 | ida | 4 |
| 7056 | humorístico | 4 |
| 7057 | humildes | 4 |
| 7058 | húmedos | 4 |
| 7059 | humedecieron | 4 |
| 7060 | huerfanito | 4 |
| 7061 | huchas | 4 |
| 7062 | hortera | 4 |
| 7063 | hortaleza | 4 |
| 7064 | horrorizada | 4 |
| 7065 | honradamente | 4 |
| 7066 | homicidio | 4 |
| 7067 | holanda | 4 |
| 7068 | hoguera | 4 |
| 7069 | históricos | 4 |
| 7070 | histórica | 4 |
| 7071 | hipocresía | 4 |
| 7072 | himno | 4 |
| 7073 | hilaridad | 4 |
| 7074 | hicieran | 4 |
| 7075 | herrero | 4 |
| 7076 | hermosísimo | 4 |
| 7077 | herido | 4 |
| 7078 | helada | 4 |
| 7079 | heces | 4 |
| 7080 | hartarse | 4 |
| 7081 | hartaba | 4 |
| 7082 | harta | 4 |
| 7083 | harían | 4 |
| 7084 | hambres | 4 |
| 7085 | hallarse | 4 |
| 7086 | habré | 4 |
| 7087 | hablemos | 4 |
| 7088 | hablas | 4 |
| 7089 | habladores | 4 |
| 7090 | habitual | 4 |
| 7091 | habíale | 4 |
| 7092 | gusanillo | 4 |
| 7093 | guisado | 4 |
| 7094 | guiñando | 4 |
| 7095 | guerras | 4 |
| 7096 | guarde | 4 |
| 7097 | guardas | 4 |
| 7098 | guardarropa | 4 |
| 7099 | guardaré | 4 |
| 7100 | guardan | 4 |
| 7101 | gruñidos | 4 |
| 7102 | grueso | 4 |
| 7103 | gris | 4 |
| 7104 | gresca | 4 |
| 7105 | greñas | 4 |
| 7106 | grecia | 4 |
| 7107 | grasa | 4 |
| 7108 | granuja | 4 |
| 7109 | grano | 4 |
| 7110 | grandioso | 4 |
| 7111 | grandiosa | 4 |
| 7112 | grana | 4 |
| 7113 | graciosas | 4 |
| 7114 | gozosos | 4 |
| 7115 | gori | 4 |
| 7116 | golosinas | 4 |
| 7117 | gobierna | 4 |
| 7118 | gobernaba | 4 |
| 7119 | gigantea | 4 |
| 7120 | géneros | 4 |
| 7121 | generala | 4 |
| 7122 | gemidos | 4 |
| 7123 | gastan | 4 |
| 7124 | ganó | 4 |
| 7125 | ganitas | 4 |
| 7126 | ganarse | 4 |
| 7127 | galera | 4 |
| 7128 | fundó | 4 |
| 7129 | fulgor | 4 |
| 7130 | fueras | 4 |
| 7131 | fuéramos | 4 |
| 7132 | frunció | 4 |
| 7133 | frunciendo | 4 |
| 7134 | frescos | 4 |
| 7135 | fraude | 4 |
| 7136 | fraternidad | 4 |
| 7137 | francos | 4 |
| 7138 | franca | 4 |
| 7139 | fragancia | 4 |
| 7140 | forro | 4 |
| 7141 | formarse | 4 |
| 7142 | formaba | 4 |
| 7143 | forastero | 4 |
| 7144 | flaquezas | 4 |
| 7145 | flaqueza | 4 |
| 7146 | flandes | 4 |
| 7147 | firmado | 4 |
| 7148 | fingiéndose | 4 |
| 7149 | filosóficas | 4 |
| 7150 | filo | 4 |
| 7151 | fijos | 4 |
| 7152 | fíjese | 4 |
| 7153 | fijando | 4 |
| 7154 | figuro | 4 |
| 7155 | figurando | 4 |
| 7156 | fieles | 4 |
| 7157 | fideos | 4 |
| 7158 | fiar | 4 |
| 7159 | ferrolana | 4 |
| 7160 | fernando | 4 |
| 7161 | fechas | 4 |
| 7162 | fealdad | 4 |
| 7163 | favorables | 4 |
| 7164 | fatuidad | 4 |
| 7165 | fatalidad | 4 |
| 7166 | farsante | 4 |
| 7167 | fardo | 4 |
| 7168 | famosa | 4 |
| 7169 | familiaridad | 4 |
| 7170 | faltara | 4 |
| 7171 | faja | 4 |
| 7172 | faetón | 4 |
| 7173 | extravagancia | 4 |
| 7174 | extrañaba | 4 |
| 7175 | extiende | 4 |
| 7176 | externo | 4 |
| 7177 | expresivo | 4 |
| 7178 | expresiva | 4 |
| 7179 | explosión | 4 |
| 7180 | explico | 4 |
| 7181 | explica | 4 |
| 7182 | existir | 4 |
| 7183 | existiera | 4 |
| 7184 | existen | 4 |
| 7185 | exige | 4 |
| 7186 | exhaló | 4 |
| 7187 | exhalación | 4 |
| 7188 | excusas | 4 |
| 7189 | excursión | 4 |
| 7190 | exclamación | 4 |
| 7191 | excitar | 4 |
| 7192 | excitada | 4 |
| 7193 | etiquetas | 4 |
| 7194 | etiqueta | 4 |
| 7195 | eternas | 4 |
| 7196 | eterna | 4 |
| 7197 | estuviste | 4 |
| 7198 | estruendo | 4 |
| 7199 | estremeció | 4 |
| 7200 | estrechez | 4 |
| 7201 | estirón | 4 |
| 7202 | estiró | 4 |
| 7203 | estipendio | 4 |
| 7204 | estanque | 4 |
| 7205 | estampía | 4 |
| 7206 | establecimientos | 4 |
| 7207 | esquelita | 4 |
| 7208 | esqueleto | 4 |
| 7209 | espontaneidad | 4 |
| 7210 | espiritistas | 4 |
| 7211 | espejos | 4 |
| 7212 | especial | 4 |
| 7213 | espartero | 4 |
| 7214 | españolas | 4 |
| 7215 | espantada | 4 |
| 7216 | espaciosa | 4 |
| 7217 | escurría | 4 |
| 7218 | escultura | 4 |
| 7219 | escrúpulo | 4 |
| 7220 | escritos | 4 |
| 7221 | escrita | 4 |
| 7222 | escribiendo | 4 |
| 7223 | escondrijo | 4 |
| 7224 | escondía | 4 |
| 7225 | escobas | 4 |
| 7226 | esclavo | 4 |
| 7227 | escaparate | 4 |
| 7228 | escapar | 4 |
| 7229 | escalerilla | 4 |
| 7230 | equivocó | 4 |
| 7231 | equivocada | 4 |
| 7232 | equivocaba | 4 |
| 7233 | equipaje | 4 |
| 7234 | épocas | 4 |
| 7235 | epiléptica | 4 |
| 7236 | envidio | 4 |
| 7237 | entusiasmos | 4 |
| 7238 | entretenerse | 4 |
| 7239 | entretanto | 4 |
| 7240 | entregó | 4 |
| 7241 | entregas | 4 |
| 7242 | entidad | 4 |
| 7243 | entendida | 4 |
| 7244 | entenderá | 4 |
| 7245 | entablar | 4 |
| 7246 | ensimismada | 4 |
| 7247 | ensayo | 4 |
| 7248 | enredos | 4 |
| 7249 | enredo | 4 |
| 7250 | enojada | 4 |
| 7251 | engañó | 4 |
| 7252 | engañé | 4 |
| 7253 | engañarme | 4 |
| 7254 | engañando | 4 |
| 7255 | engañaba | 4 |
| 7256 | enfadada | 4 |
| 7257 | enfada | 4 |
| 7258 | enérgico | 4 |
| 7259 | encubridora | 4 |
| 7260 | encerrarme | 4 |
| 7261 | encerrarle | 4 |
| 7262 | encaró | 4 |
| 7263 | encarnado | 4 |
| 7264 | empujándole | 4 |
| 7265 | emprender | 4 |
| 7266 | empleos | 4 |
| 7267 | emplearía | 4 |
| 7268 | empleando | 4 |
| 7269 | empleaba | 4 |
| 7270 | emperador | 4 |
| 7271 | empeñan | 4 |
| 7272 | empeñado | 4 |
| 7273 | empeñaba | 4 |
| 7274 | embustero | 4 |
| 7275 | embriaguez | 4 |
| 7276 | elogió | 4 |
| 7277 | elección | 4 |
| 7278 | ejercer | 4 |
| 7279 | educado | 4 |
| 7280 | edificar | 4 |
| 7281 | eco | 4 |
| 7282 | eches | 4 |
| 7283 | echas | 4 |
| 7284 | echarme | 4 |
| 7285 | echarla | 4 |
| 7286 | durara | 4 |
| 7287 | duraba | 4 |
| 7288 | duquesa | 4 |
| 7289 | duérmete | 4 |
| 7290 | dueños | 4 |
| 7291 | drogas | 4 |
| 7292 | dramático | 4 |
| 7293 | dorotea | 4 |
| 7294 | dormirse | 4 |
| 7295 | donnell | 4 |
| 7296 | donativos | 4 |
| 7297 | domésticos | 4 |
| 7298 | docenas | 4 |
| 7299 | distraído | 4 |
| 7300 | distinguía | 4 |
| 7301 | disputaban | 4 |
| 7302 | disponía | 4 |
| 7303 | dispongo | 4 |
| 7304 | dispone | 4 |
| 7305 | displicencia | 4 |
| 7306 | disminuir | 4 |
| 7307 | disimulado | 4 |
| 7308 | disfrutaba | 4 |
| 7309 | discutía | 4 |
| 7310 | discurro | 4 |
| 7311 | discretamente | 4 |
| 7312 | discípulo | 4 |
| 7313 | directora | 4 |
| 7314 | dioses | 4 |
| 7315 | dineros | 4 |
| 7316 | dilo | 4 |
| 7317 | diligencias | 4 |
| 7318 | dilema | 4 |
| 7319 | díjome | 4 |
| 7320 | dignos | 4 |
| 7321 | diciéndome | 4 |
| 7322 | diciéndolo | 4 |
| 7323 | dichos | 4 |
| 7324 | dibujos | 4 |
| 7325 | devuelve | 4 |
| 7326 | devolver | 4 |
| 7327 | devaneos | 4 |
| 7328 | deudor | 4 |
| 7329 | detenerla | 4 |
| 7330 | detalle | 4 |
| 7331 | desvelada | 4 |
| 7332 | desusado | 4 |
| 7333 | desusada | 4 |
| 7334 | desprendimiento | 4 |
| 7335 | desprenderse | 4 |
| 7336 | desplegaban | 4 |
| 7337 | desplegaba | 4 |
| 7338 | despierte | 4 |
| 7339 | despidiéndose | 4 |
| 7340 | despejado | 4 |
| 7341 | despejada | 4 |
| 7342 | despedidas | 4 |
| 7343 | despachó | 4 |
| 7344 | despachaba | 4 |
| 7345 | despabilado | 4 |
| 7346 | desmejorado | 4 |
| 7347 | desmejorada | 4 |
| 7348 | desmedido | 4 |
| 7349 | deshora | 4 |
| 7350 | deshonrada | 4 |
| 7351 | desgraciadamente | 4 |
| 7352 | desempeñaba | 4 |
| 7353 | deseamos | 4 |
| 7354 | desdichas | 4 |
| 7355 | desdichada | 4 |
| 7356 | desdeñoso | 4 |
| 7357 | descubría | 4 |
| 7358 | describiendo | 4 |
| 7359 | desconsolado | 4 |
| 7360 | desconsolada | 4 |
| 7361 | desconocidas | 4 |
| 7362 | desconcierto | 4 |
| 7363 | desconcertado | 4 |
| 7364 | descomponiéndose | 4 |
| 7365 | descomponerse | 4 |
| 7366 | descarga | 4 |
| 7367 | desatinos | 4 |
| 7368 | desaparecieron | 4 |
| 7369 | desaliento | 4 |
| 7370 | desairado | 4 |
| 7371 | desahogo | 4 |
| 7372 | derramado | 4 |
| 7373 | derivativo | 4 |
| 7374 | demostró | 4 |
| 7375 | demostrar | 4 |
| 7376 | demostraciones | 4 |
| 7377 | defiende | 4 |
| 7378 | defenderse | 4 |
| 7379 | dedicaba | 4 |
| 7380 | decoración | 4 |
| 7381 | declaro | 4 |
| 7382 | debieran | 4 |
| 7383 | darlos | 4 |
| 7384 | dañada | 4 |
| 7385 | danzante | 4 |
| 7386 | damos | 4 |
| 7387 | dámaso | 4 |
| 7388 | dada | 4 |
| 7389 | curita | 4 |
| 7390 | cuna | 4 |
| 7391 | cumplía | 4 |
| 7392 | cultivaba | 4 |
| 7393 | cuidarse | 4 |
| 7394 | cuidarle | 4 |
| 7395 | cuida | 4 |
| 7396 | cuerno | 4 |
| 7397 | cuchufletas | 4 |
| 7398 | cuchilleros | 4 |
| 7399 | cuchicheo | 4 |
| 7400 | cuchichearon | 4 |
| 7401 | cucharilla | 4 |
| 7402 | cucharada | 4 |
| 7403 | cuantito | 4 |
| 7404 | cuán | 4 |
| 7405 | cuáles | 4 |
| 7406 | cruzó | 4 |
| 7407 | cruzando | 4 |
| 7408 | cruzados | 4 |
| 7409 | crueldad | 4 |
| 7410 | crudos | 4 |
| 7411 | crónico | 4 |
| 7412 | cristianos | 4 |
| 7413 | cristianar | 4 |
| 7414 | crío | 4 |
| 7415 | crines | 4 |
| 7416 | criminales | 4 |
| 7417 | criando | 4 |
| 7418 | criaba | 4 |
| 7419 | creyera | 4 |
| 7420 | cretonas | 4 |
| 7421 | crespón | 4 |
| 7422 | creerse | 4 |
| 7423 | creerán | 4 |
| 7424 | crecer | 4 |
| 7425 | costra | 4 |
| 7426 | costa | 4 |
| 7427 | corteza | 4 |
| 7428 | correspondían | 4 |
| 7429 | corresponde | 4 |
| 7430 | correcciones | 4 |
| 7431 | corra | 4 |
| 7432 | corpus | 4 |
| 7433 | coquetería | 4 |
| 7434 | coplas | 4 |
| 7435 | coñac | 4 |
| 7436 | convinieron | 4 |
| 7437 | convido | 4 |
| 7438 | conventos | 4 |
| 7439 | convenientes | 4 |
| 7440 | convéncete | 4 |
| 7441 | convencerás | 4 |
| 7442 | contraste | 4 |
| 7443 | contrarios | 4 |
| 7444 | contrarias | 4 |
| 7445 | contorsiones | 4 |
| 7446 | continuo | 4 |
| 7447 | continuando | 4 |
| 7448 | contestarle | 4 |
| 7449 | contemplarla | 4 |
| 7450 | contemplaba | 4 |
| 7451 | contante | 4 |
| 7452 | contándole | 4 |
| 7453 | contados | 4 |
| 7454 | consultar | 4 |
| 7455 | consuelos | 4 |
| 7456 | constituye | 4 |
| 7457 | constitución | 4 |
| 7458 | consorte | 4 |
| 7459 | consolidado | 4 |
| 7460 | consiento | 4 |
| 7461 | considerando | 4 |
| 7462 | conservar | 4 |
| 7463 | consejera | 4 |
| 7464 | conseguía | 4 |
| 7465 | conocieron | 4 |
| 7466 | conociera | 4 |
| 7467 | conocen | 4 |
| 7468 | conocemos | 4 |
| 7469 | confundir | 4 |
| 7470 | confiese | 4 |
| 7471 | confianzas | 4 |
| 7472 | confiaba | 4 |
| 7473 | confesora | 4 |
| 7474 | conducto | 4 |
| 7475 | conducía | 4 |
| 7476 | condenar | 4 |
| 7477 | condenadas | 4 |
| 7478 | concierto | 4 |
| 7479 | concerniente | 4 |
| 7480 | comunicarle | 4 |
| 7481 | comunica | 4 |
| 7482 | comprometo | 4 |
| 7483 | comprarle | 4 |
| 7484 | comprada | 4 |
| 7485 | compostura | 4 |
| 7486 | composición | 4 |
| 7487 | componían | 4 |
| 7488 | complexión | 4 |
| 7489 | completar | 4 |
| 7490 | completaban | 4 |
| 7491 | compasiva | 4 |
| 7492 | compararse | 4 |
| 7493 | comodidad | 4 |
| 7494 | comieron | 4 |
| 7495 | comezón | 4 |
| 7496 | comestibles | 4 |
| 7497 | comerciantes | 4 |
| 7498 | comensales | 4 |
| 7499 | combinados | 4 |
| 7500 | combinado | 4 |
| 7501 | combinadas | 4 |
| 7502 | colonia | 4 |
| 7503 | colocado | 4 |
| 7504 | colgar | 4 |
| 7505 | colgando | 4 |
| 7506 | colgados | 4 |
| 7507 | coleta | 4 |
| 7508 | colchones | 4 |
| 7509 | col | 4 |
| 7510 | cogidos | 4 |
| 7511 | cogida | 4 |
| 7512 | cogían | 4 |
| 7513 | cogerte | 4 |
| 7514 | cogeré | 4 |
| 7515 | cobranza | 4 |
| 7516 | cobra | 4 |
| 7517 | clero | 4 |
| 7518 | clérigos | 4 |
| 7519 | clavar | 4 |
| 7520 | clavando | 4 |
| 7521 | clavada | 4 |
| 7522 | circunstancia | 4 |
| 7523 | cifras | 4 |
| 7524 | cierra | 4 |
| 7525 | chuletita | 4 |
| 7526 | chorreando | 4 |
| 7527 | chocar | 4 |
| 7528 | chistes | 4 |
| 7529 | chiquito | 4 |
| 7530 | chiquillas | 4 |
| 7531 | chino | 4 |
| 7532 | chimenea | 4 |
| 7533 | chillonas | 4 |
| 7534 | chiflada | 4 |
| 7535 | chaveta | 4 |
| 7536 | champagne | 4 |
| 7537 | chacota | 4 |
| 7538 | cerdo | 4 |
| 7539 | central | 4 |
| 7540 | céntimos | 4 |
| 7541 | celebraron | 4 |
| 7542 | celebraba | 4 |
| 7543 | cediendo | 4 |
| 7544 | categoría | 4 |
| 7545 | cátedra | 4 |
| 7546 | catecismo | 4 |
| 7547 | casita | 4 |
| 7548 | casero | 4 |
| 7549 | caserío | 4 |
| 7550 | casera | 4 |
| 7551 | casé | 4 |
| 7552 | casarredonda | 4 |
| 7553 | carretillas | 4 |
| 7554 | carnero | 4 |
| 7555 | carlistas | 4 |
| 7556 | cargaba | 4 |
| 7557 | carcelera | 4 |
| 7558 | carbonero | 4 |
| 7559 | carbón | 4 |
| 7560 | caramelos | 4 |
| 7561 | caramelo | 4 |
| 7562 | carambita | 4 |
| 7563 | capitales | 4 |
| 7564 | capirotes | 4 |
| 7565 | cañizares | 4 |
| 7566 | cantinela | 4 |
| 7567 | cantero | 4 |
| 7568 | cantería | 4 |
| 7569 | cantera | 4 |
| 7570 | canta | 4 |
| 7571 | canso | 4 |
| 7572 | cansaba | 4 |
| 7573 | canción | 4 |
| 7574 | canalla | 4 |
| 7575 | campanadas | 4 |
| 7576 | camorra | 4 |
| 7577 | camelias | 4 |
| 7578 | calzones | 4 |
| 7579 | calumnia | 4 |
| 7580 | callose | 4 |
| 7581 | callaron | 4 |
| 7582 | callando | 4 |
| 7583 | callados | 4 |
| 7584 | calladita | 4 |
| 7585 | calixta | 4 |
| 7586 | calcula | 4 |
| 7587 | calaverada | 4 |
| 7588 | cal | 4 |
| 7589 | caes | 4 |
| 7590 | caerse | 4 |
| 7591 | cadáveres | 4 |
| 7592 | cadáver | 4 |
| 7593 | cacharro | 4 |
| 7594 | buscas | 4 |
| 7595 | burlarse | 4 |
| 7596 | bulle | 4 |
| 7597 | bufanda | 4 |
| 7598 | brutal | 4 |
| 7599 | brotaba | 4 |
| 7600 | bromazo | 4 |
| 7601 | bringas | 4 |
| 7602 | bravo | 4 |
| 7603 | borrado | 4 |
| 7604 | borrachos | 4 |
| 7605 | boquita | 4 |
| 7606 | bondadosa | 4 |
| 7607 | bonaparte | 4 |
| 7608 | bolsín | 4 |
| 7609 | bilis | 4 |
| 7610 | bicho | 4 |
| 7611 | biblia | 4 |
| 7612 | biberón | 4 |
| 7613 | biarritz | 4 |
| 7614 | besugo | 4 |
| 7615 | besándola | 4 |
| 7616 | benévola | 4 |
| 7617 | bayeta | 4 |
| 7618 | bautismo | 4 |
| 7619 | barrer | 4 |
| 7620 | barreño | 4 |
| 7621 | barrenderos | 4 |
| 7622 | barras | 4 |
| 7623 | baratijas | 4 |
| 7624 | baños | 4 |
| 7625 | bandera | 4 |
| 7626 | bálsamo | 4 |
| 7627 | bala | 4 |
| 7628 | bajaron | 4 |
| 7629 | bajaré | 4 |
| 7630 | babero | 4 |
| 7631 | babas | 4 |
| 7632 | azorado | 4 |
| 7633 | ayudado | 4 |
| 7634 | aversión | 4 |
| 7635 | averiguarlo | 4 |
| 7636 | aventuró | 4 |
| 7637 | aventura | 4 |
| 7638 | avariento | 4 |
| 7639 | avaricia | 4 |
| 7640 | avanzando | 4 |
| 7641 | auxiliar | 4 |
| 7642 | autores | 4 |
| 7643 | austria | 4 |
| 7644 | ausencias | 4 |
| 7645 | aureola | 4 |
| 7646 | auditorio | 4 |
| 7647 | aturdimiento | 4 |
| 7648 | atrozmente | 4 |
| 7649 | atrocidades | 4 |
| 7650 | atrevida | 4 |
| 7651 | atractivos | 4 |
| 7652 | ató | 4 |
| 7653 | atizó | 4 |
| 7654 | ateo | 4 |
| 7655 | atavío | 4 |
| 7656 | ataques | 4 |
| 7657 | asustarse | 4 |
| 7658 | asquerosa | 4 |
| 7659 | aspirando | 4 |
| 7660 | aspereza | 4 |
| 7661 | áspera | 4 |
| 7662 | asista | 4 |
| 7663 | asimilación | 4 |
| 7664 | ascendiente | 4 |
| 7665 | artístico | 4 |
| 7666 | articular | 4 |
| 7667 | arrepentidas | 4 |
| 7668 | arreglos | 4 |
| 7669 | arrastraba | 4 |
| 7670 | arrancarse | 4 |
| 7671 | arrancar | 4 |
| 7672 | arrancaba | 4 |
| 7673 | armando | 4 |
| 7674 | arman | 4 |
| 7675 | arguyó | 4 |
| 7676 | argumentación | 4 |
| 7677 | arca | 4 |
| 7678 | apurado | 4 |
| 7679 | apunta | 4 |
| 7680 | apuesto | 4 |
| 7681 | aptitudes | 4 |
| 7682 | aproximarse | 4 |
| 7683 | aprovechando | 4 |
| 7684 | aprensión | 4 |
| 7685 | aprenderá | 4 |
| 7686 | aprenda | 4 |
| 7687 | apostolado | 4 |
| 7688 | apóstol | 4 |
| 7689 | aplomo | 4 |
| 7690 | apetecer | 4 |
| 7691 | apatía | 4 |
| 7692 | aparecieron | 4 |
| 7693 | apagada | 4 |
| 7694 | añadidura | 4 |
| 7695 | antón | 4 |
| 7696 | antipáticos | 4 |
| 7697 | antiguos | 4 |
| 7698 | antiguas | 4 |
| 7699 | anteanoche | 4 |
| 7700 | animalito | 4 |
| 7701 | animaba | 4 |
| 7702 | anhelaba | 4 |
| 7703 | angosta | 4 |
| 7704 | anegada | 4 |
| 7705 | anécdotas | 4 |
| 7706 | andaluz | 4 |
| 7707 | anaquelería | 4 |
| 7708 | amplitud | 4 |
| 7709 | amos | 4 |
| 7710 | amenazaba | 4 |
| 7711 | amena | 4 |
| 7712 | ambición | 4 |
| 7713 | amargo | 4 |
| 7714 | amadeo | 4 |
| 7715 | alfonsismo | 4 |
| 7716 | alfombra | 4 |
| 7717 | alfileres | 4 |
| 7718 | alegrías | 4 |
| 7719 | alegraría | 4 |
| 7720 | alcohol | 4 |
| 7721 | alcobas | 4 |
| 7722 | alcanzaba | 4 |
| 7723 | alborotados | 4 |
| 7724 | alborotado | 4 |
| 7725 | alborotaba | 4 |
| 7726 | alarde | 4 |
| 7727 | alabardero | 4 |
| 7728 | ala | 4 |
| 7729 | ajuar | 4 |
| 7730 | ajetreo | 4 |
| 7731 | ajenos | 4 |
| 7732 | ajena | 4 |
| 7733 | airosa | 4 |
| 7734 | ahínco | 4 |
| 7735 | agujerito | 4 |
| 7736 | aguárdese | 4 |
| 7737 | agradecimiento | 4 |
| 7738 | agradecidísimo | 4 |
| 7739 | agradar | 4 |
| 7740 | agitó | 4 |
| 7741 | áfrica | 4 |
| 7742 | afligido | 4 |
| 7743 | afirmativo | 4 |
| 7744 | aficiones | 4 |
| 7745 | aficionado | 4 |
| 7746 | afectuoso | 4 |
| 7747 | afectada | 4 |
| 7748 | afabilidad | 4 |
| 7749 | adúuultera | 4 |
| 7750 | adúlteros | 4 |
| 7751 | aduana | 4 |
| 7752 | adrede | 4 |
| 7753 | adoro | 4 |
| 7754 | adoraba | 4 |
| 7755 | administrativa | 4 |
| 7756 | ademanes | 4 |
| 7757 | adefesio | 4 |
| 7758 | acuesto | 4 |
| 7759 | actriz | 4 |
| 7760 | acreedor | 4 |
| 7761 | acostumbrando | 4 |
| 7762 | acostumbraba | 4 |
| 7763 | acostado | 4 |
| 7764 | acordé | 4 |
| 7765 | acordarse | 4 |
| 7766 | acordar | 4 |
| 7767 | acordándose | 4 |
| 7768 | acordábase | 4 |
| 7769 | acompañaré | 4 |
| 7770 | acompañadas | 4 |
| 7771 | acometido | 4 |
| 7772 | acometer | 4 |
| 7773 | achaques | 4 |
| 7774 | acertar | 4 |
| 7775 | aceptó | 4 |
| 7776 | acentos | 4 |
| 7777 | acecha | 4 |
| 7778 | accidentes | 4 |
| 7779 | accidente | 4 |
| 7780 | acariciándole | 4 |
| 7781 | acalorada | 4 |
| 7782 | acabaría | 4 |
| 7783 | acaban | 4 |
| 7784 | acabadita | 4 |
| 7785 | abusando | 4 |
| 7786 | aburría | 4 |
| 7787 | abundaba | 4 |
| 7788 | abuelita | 4 |
| 7789 | absurda | 4 |
| 7790 | abril | 4 |
| 7791 | abrían | 4 |
| 7792 | abren | 4 |
| 7793 | abrazos | 4 |
| 7794 | abrazó | 4 |
| 7795 | abrazándola | 4 |
| 7796 | abanico | 4 |
| 7797 | zas | 3 |
| 7798 | zarzuela | 3 |
| 7799 | zapatones | 3 |
| 7800 | zapatero | 3 |
| 7801 | zancas | 3 |
| 7802 | vulgarmente | 3 |
| 7803 | vueltos | 3 |
| 7804 | vuelca | 3 |
| 7805 | votos | 3 |
| 7806 | votar | 3 |
| 7807 | vómitos | 3 |
| 7808 | volvemos | 3 |
| 7809 | volumen | 3 |
| 7810 | volar | 3 |
| 7811 | vizcaína | 3 |
| 7812 | vivísimo | 3 |
| 7813 | vivimos | 3 |
| 7814 | viviendas | 3 |
| 7815 | vivan | 3 |
| 7816 | vitoria | 3 |
| 7817 | vistoso | 3 |
| 7818 | visitó | 3 |
| 7819 | visionaria | 3 |
| 7820 | visiblemente | 3 |
| 7821 | violentísimo | 3 |
| 7822 | vinagre | 3 |
| 7823 | vil | 3 |
| 7824 | vigor | 3 |
| 7825 | viejos | 3 |
| 7826 | vidrio | 3 |
| 7827 | víctimas | 3 |
| 7828 | vibraciones | 3 |
| 7829 | viajeros | 3 |
| 7830 | veterano | 3 |
| 7831 | vestirle | 3 |
| 7832 | vestiré | 3 |
| 7833 | versó | 3 |
| 7834 | verificose | 3 |
| 7835 | verificó | 3 |
| 7836 | verídicamente | 3 |
| 7837 | vergonzosos | 3 |
| 7838 | vergonzosas | 3 |
| 7839 | vergonzosa | 3 |
| 7840 | veredas | 3 |
| 7841 | venturoso | 3 |
| 7842 | ventas | 3 |
| 7843 | venta | 3 |
| 7844 | vengaba | 3 |
| 7845 | vendrás | 3 |
| 7846 | vendían | 3 |
| 7847 | vendedores | 3 |
| 7848 | vendedor | 3 |
| 7849 | venció | 3 |
| 7850 | vencedora | 3 |
| 7851 | vemos | 3 |
| 7852 | velos | 3 |
| 7853 | velón | 3 |
| 7854 | vello | 3 |
| 7855 | velador | 3 |
| 7856 | vejez | 3 |
| 7857 | veintitrés | 3 |
| 7858 | veintisiete | 3 |
| 7859 | veíanse | 3 |
| 7860 | vehículo | 3 |
| 7861 | vehementes | 3 |
| 7862 | vehemencia | 3 |
| 7863 | vayamos | 3 |
| 7864 | vasos | 3 |
| 7865 | varoniles | 3 |
| 7866 | variaron | 3 |
| 7867 | variando | 3 |
| 7868 | variado | 3 |
| 7869 | variaba | 3 |
| 7870 | varía | 3 |
| 7871 | varas | 3 |
| 7872 | valido | 3 |
| 7873 | valerosa | 3 |
| 7874 | valeriano | 3 |
| 7875 | valdría | 3 |
| 7876 | vagón | 3 |
| 7877 | vagabundo | 3 |
| 7878 | vagabunda | 3 |
| 7879 | vagaban | 3 |
| 7880 | uy | 3 |
| 7881 | útil | 3 |
| 7882 | usuales | 3 |
| 7883 | usaron | 3 |
| 7884 | usando | 3 |
| 7885 | usadas | 3 |
| 7886 | universo | 3 |
| 7887 | universidad | 3 |
| 7888 | unido | 3 |
| 7889 | unida | 3 |
| 7890 | uníase | 3 |
| 7891 | ultrajar | 3 |
| 7892 | tuviesen | 3 |
| 7893 | turbó | 3 |
| 7894 | turbar | 3 |
| 7895 | tunanta | 3 |
| 7896 | tufillo | 3 |
| 7897 | tropezando | 3 |
| 7898 | trocó | 3 |
| 7899 | triviales | 3 |
| 7900 | tristísimo | 3 |
| 7901 | triquitraque | 3 |
| 7902 | trinidad | 3 |
| 7903 | trifulca | 3 |
| 7904 | tributo | 3 |
| 7905 | tribunales | 3 |
| 7906 | tribulación | 3 |
| 7907 | tresillo | 3 |
| 7908 | trepidación | 3 |
| 7909 | trémulo | 3 |
| 7910 | tremendos | 3 |
| 7911 | trece | 3 |
| 7912 | trazar | 3 |
| 7913 | traté | 3 |
| 7914 | tratarse | 3 |
| 7915 | tratarla | 3 |
| 7916 | tratante | 3 |
| 7917 | tratándole | 3 |
| 7918 | trastorna | 3 |
| 7919 | trastienda | 3 |
| 7920 | trapisondista | 3 |
| 7921 | transparentes | 3 |
| 7922 | transcurrido | 3 |
| 7923 | tranquilízate | 3 |
| 7924 | tramando | 3 |
| 7925 | trajín | 3 |
| 7926 | trajeran | 3 |
| 7927 | trajecito | 3 |
| 7928 | tráiganme | 3 |
| 7929 | tragué | 3 |
| 7930 | tragos | 3 |
| 7931 | tragado | 3 |
| 7932 | tráfico | 3 |
| 7933 | traerla | 3 |
| 7934 | traería | 3 |
| 7935 | trabajó | 3 |
| 7936 | trabajadora | 3 |
| 7937 | toser | 3 |
| 7938 | tosca | 3 |
| 7939 | torero | 3 |
| 7940 | torcidas | 3 |
| 7941 | toquillas | 3 |
| 7942 | tontaina | 3 |
| 7943 | tomándose | 3 |
| 7944 | tomada | 3 |
| 7945 | toleraba | 3 |
| 7946 | toditos | 3 |
| 7947 | tocaban | 3 |
| 7948 | tisis | 3 |
| 7949 | tirita | 3 |
| 7950 | tirarlos | 3 |
| 7951 | tirarle | 3 |
| 7952 | tirándole | 3 |
| 7953 | tíos | 3 |
| 7954 | tiorras | 3 |
| 7955 | tiñe | 3 |
| 7956 | tila | 3 |
| 7957 | tifus | 3 |
| 7958 | tiesos | 3 |
| 7959 | tiesa | 3 |
| 7960 | tiernísimo | 3 |
| 7961 | textos | 3 |
| 7962 | tetuán | 3 |
| 7963 | tesis | 3 |
| 7964 | tertulios | 3 |
| 7965 | ternezas | 3 |
| 7966 | terminando | 3 |
| 7967 | tenue | 3 |
| 7968 | tentativas | 3 |
| 7969 | teníamos | 3 |
| 7970 | tenerlos | 3 |
| 7971 | tenducho | 3 |
| 7972 | tendiendo | 3 |
| 7973 | temió | 3 |
| 7974 | temido | 3 |
| 7975 | temerario | 3 |
| 7976 | tembló | 3 |
| 7977 | telégrafos | 3 |
| 7978 | tejados | 3 |
| 7979 | tedio | 3 |
| 7980 | teclas | 3 |
| 7981 | teatros | 3 |
| 7982 | teatrales | 3 |
| 7983 | tasa | 3 |
| 7984 | tartán | 3 |
| 7985 | tardaron | 3 |
| 7986 | tardado | 3 |
| 7987 | tarambana | 3 |
| 7988 | tapando | 3 |
| 7989 | tantísimo | 3 |
| 7990 | tantísimas | 3 |
| 7991 | talla | 3 |
| 7992 | talentazo | 3 |
| 7993 | talco | 3 |
| 7994 | tagarotes | 3 |
| 7995 | tácita | 3 |
| 7996 | tabiques | 3 |
| 7997 | tabique | 3 |
| 7998 | tabernas | 3 |
| 7999 | t | 3 |
| 8000 | suspirando | 3 |
| 8001 | suscriciones | 3 |
| 8002 | surgido | 3 |
| 8003 | suposición | 3 |
| 8004 | suplico | 3 |
| 8005 | suplicante | 3 |
| 8006 | sujetar | 3 |
| 8007 | sujetándole | 3 |
| 8008 | suiza | 3 |
| 8009 | sufrimientos | 3 |
| 8010 | suficiente | 3 |
| 8011 | sueña | 3 |
| 8012 | suéltame | 3 |
| 8013 | suela | 3 |
| 8014 | sudando | 3 |
| 8015 | sucios | 3 |
| 8016 | sucesivos | 3 |
| 8017 | subsecretario | 3 |
| 8018 | subordinación | 3 |
| 8019 | súbita | 3 |
| 8020 | subiéndose | 3 |
| 8021 | subí | 3 |
| 8022 | sótano | 3 |
| 8023 | sostiene | 3 |
| 8024 | sostenido | 3 |
| 8025 | sospechó | 3 |
| 8026 | sorprendido | 3 |
| 8027 | sorda | 3 |
| 8028 | soportar | 3 |
| 8029 | soportales | 3 |
| 8030 | soplo | 3 |
| 8031 | sopas | 3 |
| 8032 | soñó | 3 |
| 8033 | sonríe | 3 |
| 8034 | sonda | 3 |
| 8035 | sonaran | 3 |
| 8036 | sonada | 3 |
| 8037 | sombrerito | 3 |
| 8038 | solterón | 3 |
| 8039 | soltaron | 3 |
| 8040 | soltado | 3 |
| 8041 | solomillo | 3 |
| 8042 | solitarios | 3 |
| 8043 | solita | 3 |
| 8044 | soliloquios | 3 |
| 8045 | sólido | 3 |
| 8046 | solidaridad | 3 |
| 8047 | solicitaba | 3 |
| 8048 | solamente | 3 |
| 8049 | sois | 3 |
| 8050 | sofoques | 3 |
| 8051 | sofocadísima | 3 |
| 8052 | sofismas | 3 |
| 8053 | soeces | 3 |
| 8054 | socio | 3 |
| 8055 | socarronería | 3 |
| 8056 | sobriedad | 3 |
| 8057 | sobresalto | 3 |
| 8058 | sobresaltada | 3 |
| 8059 | soberano | 3 |
| 8060 | sirviente | 3 |
| 8061 | sirva | 3 |
| 8062 | siniestra | 3 |
| 8063 | singularmente | 3 |
| 8064 | singapore | 3 |
| 8065 | simpleza | 3 |
| 8066 | símbolo | 3 |
| 8067 | sillar | 3 |
| 8068 | sigüenza | 3 |
| 8069 | siguen | 3 |
| 8070 | significaban | 3 |
| 8071 | sienes | 3 |
| 8072 | sien | 3 |
| 8073 | severo | 3 |
| 8074 | sesión | 3 |
| 8075 | serpiente | 3 |
| 8076 | serenos | 3 |
| 8077 | serenó | 3 |
| 8078 | serenarse | 3 |
| 8079 | serafines | 3 |
| 8080 | septiembre | 3 |
| 8081 | separarse | 3 |
| 8082 | separar | 3 |
| 8083 | separados | 3 |
| 8084 | separaban | 3 |
| 8085 | señaló | 3 |
| 8086 | señalado | 3 |
| 8087 | seña | 3 |
| 8088 | sentían | 3 |
| 8089 | sentase | 3 |
| 8090 | sentara | 3 |
| 8091 | sensata | 3 |
| 8092 | senos | 3 |
| 8093 | semejaban | 3 |
| 8094 | semejaba | 3 |
| 8095 | sello | 3 |
| 8096 | segundos | 3 |
| 8097 | seguiría | 3 |
| 8098 | seguirá | 3 |
| 8099 | seguimos | 3 |
| 8100 | secreteo | 3 |
| 8101 | secreteándose | 3 |
| 8102 | secreta | 3 |
| 8103 | secos | 3 |
| 8104 | secciones | 3 |
| 8105 | secas | 3 |
| 8106 | savia | 3 |
| 8107 | satánica | 3 |
| 8108 | sastres | 3 |
| 8109 | sartén | 3 |
| 8110 | sardinas | 3 |
| 8111 | sarampión | 3 |
| 8112 | saques | 3 |
| 8113 | saña | 3 |
| 8114 | sandeces | 3 |
| 8115 | sándalo | 3 |
| 8116 | sánchez | 3 |
| 8117 | samaniega | 3 |
| 8118 | salvó | 3 |
| 8119 | salve | 3 |
| 8120 | salvarme | 3 |
| 8121 | saludando | 3 |
| 8122 | saluda | 3 |
| 8123 | saltaron | 3 |
| 8124 | saliste | 3 |
| 8125 | salirse | 3 |
| 8126 | salidita | 3 |
| 8127 | saldo | 3 |
| 8128 | sahumar | 3 |
| 8129 | sagaces | 3 |
| 8130 | sacudirse | 3 |
| 8131 | sacudiendo | 3 |
| 8132 | sacudía | 3 |
| 8133 | sacuden | 3 |
| 8134 | sacrificios | 3 |
| 8135 | sacramentos | 3 |
| 8136 | sacas | 3 |
| 8137 | sacada | 3 |
| 8138 | sabrosa | 3 |
| 8139 | sabidurías | 3 |
| 8140 | sabia | 3 |
| 8141 | sabéis | 3 |
| 8142 | sabedor | 3 |
| 8143 | rusia | 3 |
| 8144 | ruinas | 3 |
| 8145 | ruidosa | 3 |
| 8146 | ruidos | 3 |
| 8147 | rúbrica | 3 |
| 8148 | rondas | 3 |
| 8149 | ron | 3 |
| 8150 | rompo | 3 |
| 8151 | rompería | 3 |
| 8152 | romero | 3 |
| 8153 | románticas | 3 |
| 8154 | romanos | 3 |
| 8155 | rogó | 3 |
| 8156 | roe | 3 |
| 8157 | rodeos | 3 |
| 8158 | rodearon | 3 |
| 8159 | rodeaban | 3 |
| 8160 | rodea | 3 |
| 8161 | roce | 3 |
| 8162 | robusto | 3 |
| 8163 | robusta | 3 |
| 8164 | robar | 3 |
| 8165 | robaba | 3 |
| 8166 | roba | 3 |
| 8167 | rivalidad | 3 |
| 8168 | rito | 3 |
| 8169 | riquísimos | 3 |
| 8170 | riquísimo | 3 |
| 8171 | riquezas | 3 |
| 8172 | riñón | 3 |
| 8173 | riñendo | 3 |
| 8174 | rinconada | 3 |
| 8175 | ríete | 3 |
| 8176 | rieron | 3 |
| 8177 | riego | 3 |
| 8178 | ridículos | 3 |
| 8179 | ribetes | 3 |
| 8180 | ría | 3 |
| 8181 | revueltos | 3 |
| 8182 | revueltas | 3 |
| 8183 | revolvían | 3 |
| 8184 | revolucionarios | 3 |
| 8185 | reventones | 3 |
| 8186 | revelaciones | 3 |
| 8187 | revelaban | 3 |
| 8188 | revancha | 3 |
| 8189 | reunidos | 3 |
| 8190 | reunían | 3 |
| 8191 | reuma | 3 |
| 8192 | retuvo | 3 |
| 8193 | retrocedió | 3 |
| 8194 | retiráronse | 3 |
| 8195 | retirar | 3 |
| 8196 | retirada | 3 |
| 8197 | resurrección | 3 |
| 8198 | resueltamente | 3 |
| 8199 | resuello | 3 |
| 8200 | resquicio | 3 |
| 8201 | respuestas | 3 |
| 8202 | responderle | 3 |
| 8203 | respiró | 3 |
| 8204 | respirando | 3 |
| 8205 | respiraba | 3 |
| 8206 | respetos | 3 |
| 8207 | respetando | 3 |
| 8208 | respetabilísima | 3 |
| 8209 | resignada | 3 |
| 8210 | resignación | 3 |
| 8211 | reservada | 3 |
| 8212 | resentimientos | 3 |
| 8213 | resabio | 3 |
| 8214 | reproducía | 3 |
| 8215 | reprimenda | 3 |
| 8216 | representaban | 3 |
| 8217 | reprendía | 3 |
| 8218 | reprender | 3 |
| 8219 | reponerse | 3 |
| 8220 | replicaba | 3 |
| 8221 | repitiera | 3 |
| 8222 | repentino | 3 |
| 8223 | repaso | 3 |
| 8224 | repasar | 3 |
| 8225 | repartiendo | 3 |
| 8226 | reparo | 3 |
| 8227 | reparador | 3 |
| 8228 | reoyos | 3 |
| 8229 | rentas | 3 |
| 8230 | renovación | 3 |
| 8231 | remotos | 3 |
| 8232 | remoto | 3 |
| 8233 | remotas | 3 |
| 8234 | remordimiento | 3 |
| 8235 | relieve | 3 |
| 8236 | relativo | 3 |
| 8237 | relamía | 3 |
| 8238 | rejilla | 3 |
| 8239 | reiría | 3 |
| 8240 | regularmente | 3 |
| 8241 | regresó | 3 |
| 8242 | reglamento | 3 |
| 8243 | registrar | 3 |
| 8244 | regaliz | 3 |
| 8245 | refrescó | 3 |
| 8246 | refrán | 3 |
| 8247 | reformas | 3 |
| 8248 | reflexiones | 3 |
| 8249 | referirse | 3 |
| 8250 | refajo | 3 |
| 8251 | réditos | 3 |
| 8252 | redes | 3 |
| 8253 | recursos | 3 |
| 8254 | recuerdos | 3 |
| 8255 | recreaba | 3 |
| 8256 | recortar | 3 |
| 8257 | recorrió | 3 |
| 8258 | recorría | 3 |
| 8259 | recordó | 3 |
| 8260 | reconocieron | 3 |
| 8261 | reconocerle | 3 |
| 8262 | recomienda | 3 |
| 8263 | recomendara | 3 |
| 8264 | recomendaciones | 3 |
| 8265 | recogimiento | 3 |
| 8266 | recogieron | 3 |
| 8267 | recobraba | 3 |
| 8268 | reclusas | 3 |
| 8269 | recinto | 3 |
| 8270 | recibiría | 3 |
| 8271 | recibieron | 3 |
| 8272 | recibida | 3 |
| 8273 | rechazaba | 3 |
| 8274 | recato | 3 |
| 8275 | rebotica | 3 |
| 8276 | rebosando | 3 |
| 8277 | rayos | 3 |
| 8278 | rayado | 3 |
| 8279 | raudal | 3 |
| 8280 | rasguñar | 3 |
| 8281 | rasgueadas | 3 |
| 8282 | randa | 3 |
| 8283 | ramoncita | 3 |
| 8284 | ramaje | 3 |
| 8285 | ralo | 3 |
| 8286 | ración | 3 |
| 8287 | raciocinio | 3 |
| 8288 | racimo | 3 |
| 8289 | racha | 3 |
| 8290 | rabioso | 3 |
| 8291 | rabiosa | 3 |
| 8292 | quito | 3 |
| 8293 | quítese | 3 |
| 8294 | quiten | 3 |
| 8295 | quitaron | 3 |
| 8296 | quitándole | 3 |
| 8297 | quisieron | 3 |
| 8298 | quijote | 3 |
| 8299 | quietecito | 3 |
| 8300 | querrías | 3 |
| 8301 | quererse | 3 |
| 8302 | quererla | 3 |
| 8303 | querencia | 3 |
| 8304 | quepa | 3 |
| 8305 | quelo | 3 |
| 8306 | quejaba | 3 |
| 8307 | quedas | 3 |
| 8308 | quedaré | 3 |
| 8309 | quedábanse | 3 |
| 8310 | pusiéronle | 3 |
| 8311 | pupitre | 3 |
| 8312 | punzada | 3 |
| 8313 | puntualmente | 3 |
| 8314 | puntualidad | 3 |
| 8315 | pulcritud | 3 |
| 8316 | puff | 3 |
| 8317 | pueriles | 3 |
| 8318 | puerca | 3 |
| 8319 | puente | 3 |
| 8320 | pudor | 3 |
| 8321 | pudiese | 3 |
| 8322 | púa | 3 |
| 8323 | prusianos | 3 |
| 8324 | próximos | 3 |
| 8325 | protegida | 3 |
| 8326 | protegía | 3 |
| 8327 | proposiciones | 3 |
| 8328 | propiedades | 3 |
| 8329 | propagandista | 3 |
| 8330 | pronunciada | 3 |
| 8331 | pronunciaba | 3 |
| 8332 | pronta | 3 |
| 8333 | prometiendo | 3 |
| 8334 | prométeme | 3 |
| 8335 | productos | 3 |
| 8336 | producir | 3 |
| 8337 | producíale | 3 |
| 8338 | producen | 3 |
| 8339 | prodigiosa | 3 |
| 8340 | proceso | 3 |
| 8341 | probaré | 3 |
| 8342 | probando | 3 |
| 8343 | probabilidades | 3 |
| 8344 | privado | 3 |
| 8345 | privaciones | 3 |
| 8346 | prisionera | 3 |
| 8347 | prisas | 3 |
| 8348 | principia | 3 |
| 8349 | primorosas | 3 |
| 8350 | primitivos | 3 |
| 8351 | primitiva | 3 |
| 8352 | primas | 3 |
| 8353 | previsión | 3 |
| 8354 | preverlo | 3 |
| 8355 | prevengo | 3 |
| 8356 | pretextando | 3 |
| 8357 | presumir | 3 |
| 8358 | presumía | 3 |
| 8359 | prestan | 3 |
| 8360 | prestado | 3 |
| 8361 | presos | 3 |
| 8362 | presintió | 3 |
| 8363 | presento | 3 |
| 8364 | presentimientos | 3 |
| 8365 | presentará | 3 |
| 8366 | presentara | 3 |
| 8367 | presentado | 3 |
| 8368 | presenciado | 3 |
| 8369 | presbítero | 3 |
| 8370 | preparémonos | 3 |
| 8371 | preocupada | 3 |
| 8372 | premios | 3 |
| 8373 | preguntita | 3 |
| 8374 | pregunté | 3 |
| 8375 | pregúntaselo | 3 |
| 8376 | preguntaban | 3 |
| 8377 | pregones | 3 |
| 8378 | pregonar | 3 |
| 8379 | prefiriendo | 3 |
| 8380 | prefería | 3 |
| 8381 | preferencia | 3 |
| 8382 | predilecto | 3 |
| 8383 | predicar | 3 |
| 8384 | precursores | 3 |
| 8385 | precipitó | 3 |
| 8386 | precipitadamente | 3 |
| 8387 | precios | 3 |
| 8388 | preciaba | 3 |
| 8389 | precedieron | 3 |
| 8390 | precauciones | 3 |
| 8391 | practicante | 3 |
| 8392 | practicaba | 3 |
| 8393 | potásico | 3 |
| 8394 | postración | 3 |
| 8395 | positiva | 3 |
| 8396 | posibilidad | 3 |
| 8397 | posee | 3 |
| 8398 | posada | 3 |
| 8399 | portezuela | 3 |
| 8400 | portarme | 3 |
| 8401 | porta | 3 |
| 8402 | porrazos | 3 |
| 8403 | porquería | 3 |
| 8404 | poros | 3 |
| 8405 | porción | 3 |
| 8406 | poquitito | 3 |
| 8407 | ponme | 3 |
| 8408 | ponlo | 3 |
| 8409 | póngase | 3 |
| 8410 | ponérselo | 3 |
| 8411 | pondrás | 3 |
| 8412 | ponderar | 3 |
| 8413 | polla | 3 |
| 8414 | polkas | 3 |
| 8415 | polisón | 3 |
| 8416 | podremos | 3 |
| 8417 | poderoso | 3 |
| 8418 | podéis | 3 |
| 8419 | platillos | 3 |
| 8420 | planto | 3 |
| 8421 | plantan | 3 |
| 8422 | planchar | 3 |
| 8423 | pistola | 3 |
| 8424 | pío | 3 |
| 8425 | pintón | 3 |
| 8426 | pintarte | 3 |
| 8427 | pingajos | 3 |
| 8428 | pim | 3 |
| 8429 | píldora | 3 |
| 8430 | pilas | 3 |
| 8431 | piensan | 3 |
| 8432 | pidiera | 3 |
| 8433 | pida | 3 |
| 8434 | picotazos | 3 |
| 8435 | picaresco | 3 |
| 8436 | picardías | 3 |
| 8437 | picantes | 3 |
| 8438 | picando | 3 |
| 8439 | piar | 3 |
| 8440 | pianitos | 3 |
| 8441 | piadoso | 3 |
| 8442 | piadosa | 3 |
| 8443 | petitorios | 3 |
| 8444 | peste | 3 |
| 8445 | pestañas | 3 |
| 8446 | pescar | 3 |
| 8447 | pesara | 3 |
| 8448 | pesadito | 3 |
| 8449 | pesadas | 3 |
| 8450 | pesa | 3 |
| 8451 | perversos | 3 |
| 8452 | persuasión | 3 |
| 8453 | perspicacia | 3 |
| 8454 | perrito | 3 |
| 8455 | perrera | 3 |
| 8456 | peros | 3 |
| 8457 | permito | 3 |
| 8458 | permitir | 3 |
| 8459 | permitieron | 3 |
| 8460 | permanente | 3 |
| 8461 | perjuicio | 3 |
| 8462 | peripecias | 3 |
| 8463 | pérfido | 3 |
| 8464 | perdóneme | 3 |
| 8465 | perdonaría | 3 |
| 8466 | perdiz | 3 |
| 8467 | perdiéndose | 3 |
| 8468 | pérdidas | 3 |
| 8469 | percibió | 3 |
| 8470 | peras | 3 |
| 8471 | pequeñuelos | 3 |
| 8472 | peña | 3 |
| 8473 | pentecostés | 3 |
| 8474 | pensaría | 3 |
| 8475 | pensará | 3 |
| 8476 | pensamos | 3 |
| 8477 | penitentes | 3 |
| 8478 | penitenciario | 3 |
| 8479 | penita | 3 |
| 8480 | penetraba | 3 |
| 8481 | penando | 3 |
| 8482 | penales | 3 |
| 8483 | peluquería | 3 |
| 8484 | peludo | 3 |
| 8485 | peluca | 3 |
| 8486 | peloteras | 3 |
| 8487 | pellizcos | 3 |
| 8488 | pellizco | 3 |
| 8489 | peinar | 3 |
| 8490 | peinadas | 3 |
| 8491 | pegarse | 3 |
| 8492 | pegaría | 3 |
| 8493 | pegadizo | 3 |
| 8494 | pedradas | 3 |
| 8495 | pedidos | 3 |
| 8496 | peco | 3 |
| 8497 | pechuga | 3 |
| 8498 | pecador | 3 |
| 8499 | pavía | 3 |
| 8500 | pavero | 3 |
| 8501 | pausadamente | 3 |
| 8502 | patrona | 3 |
| 8503 | patriota | 3 |
| 8504 | patraña | 3 |
| 8505 | patochada | 3 |
| 8506 | patita | 3 |
| 8507 | pateo | 3 |
| 8508 | pateada | 3 |
| 8509 | pastillas | 3 |
| 8510 | pasmo | 3 |
| 8511 | pasmará | 3 |
| 8512 | pasmadas | 3 |
| 8513 | pasen | 3 |
| 8514 | paseándose | 3 |
| 8515 | paseando | 3 |
| 8516 | paseaban | 3 |
| 8517 | pascuas | 3 |
| 8518 | pasándole | 3 |
| 8519 | pasadas | 3 |
| 8520 | partos | 3 |
| 8521 | partieron | 3 |
| 8522 | particularidades | 3 |
| 8523 | participar | 3 |
| 8524 | participación | 3 |
| 8525 | participaba | 3 |
| 8526 | partición | 3 |
| 8527 | parose | 3 |
| 8528 | parentela | 3 |
| 8529 | pareciese | 3 |
| 8530 | parecerme | 3 |
| 8531 | parecerlo | 3 |
| 8532 | parecería | 3 |
| 8533 | paralela | 3 |
| 8534 | paraguas | 3 |
| 8535 | parados | 3 |
| 8536 | parado | 3 |
| 8537 | paraban | 3 |
| 8538 | papamoscas | 3 |
| 8539 | panecillo | 3 |
| 8540 | pamplinas | 3 |
| 8541 | palomos | 3 |
| 8542 | palmo | 3 |
| 8543 | palmada | 3 |
| 8544 | palma | 3 |
| 8545 | paliza | 3 |
| 8546 | palideciendo | 3 |
| 8547 | palanca | 3 |
| 8548 | pajarito | 3 |
| 8549 | pagos | 3 |
| 8550 | pagará | 3 |
| 8551 | padezco | 3 |
| 8552 | padeció | 3 |
| 8553 | pacífica | 3 |
| 8554 | oyes | 3 |
| 8555 | ovillo | 3 |
| 8556 | ovejas | 3 |
| 8557 | ostentación | 3 |
| 8558 | oscurísimo | 3 |
| 8559 | orquesta | 3 |
| 8560 | orificios | 3 |
| 8561 | ordinarios | 3 |
| 8562 | ordinarias | 3 |
| 8563 | ordenada | 3 |
| 8564 | órdago | 3 |
| 8565 | orador | 3 |
| 8566 | oraciones | 3 |
| 8567 | opuso | 3 |
| 8568 | oprimiendo | 3 |
| 8569 | oprimida | 3 |
| 8570 | oprimía | 3 |
| 8571 | opresión | 3 |
| 8572 | oposiciones | 3 |
| 8573 | oportuna | 3 |
| 8574 | oponer | 3 |
| 8575 | omitir | 3 |
| 8576 | olvidaré | 3 |
| 8577 | olvidara | 3 |
| 8578 | olorcillo | 3 |
| 8579 | olivo | 3 |
| 8580 | oliente | 3 |
| 8581 | oliendo | 3 |
| 8582 | óleo | 3 |
| 8583 | ola | 3 |
| 8584 | ojitos | 3 |
| 8585 | ojerosa | 3 |
| 8586 | ojeras | 3 |
| 8587 | ojazos | 3 |
| 8588 | oída | 3 |
| 8589 | oficiando | 3 |
| 8590 | oferta | 3 |
| 8591 | ofensas | 3 |
| 8592 | ofensa | 3 |
| 8593 | ofendido | 3 |
| 8594 | ofendería | 3 |
| 8595 | odioso | 3 |
| 8596 | odiosa | 3 |
| 8597 | ocurrir | 3 |
| 8598 | ocurriósele | 3 |
| 8599 | ocurriera | 3 |
| 8600 | ocupe | 3 |
| 8601 | ocuparon | 3 |
| 8602 | ocultó | 3 |
| 8603 | ociosidad | 3 |
| 8604 | ociosas | 3 |
| 8605 | obvio | 3 |
| 8606 | obstrucciones | 3 |
| 8607 | obstáculo | 3 |
| 8608 | obligó | 3 |
| 8609 | obispa | 3 |
| 8610 | obedezca | 3 |
| 8611 | obedeció | 3 |
| 8612 | obedece | 3 |
| 8613 | nuez | 3 |
| 8614 | nudillos | 3 |
| 8615 | nublaron | 3 |
| 8616 | noviembre | 3 |
| 8617 | novelda | 3 |
| 8618 | notoria | 3 |
| 8619 | normal | 3 |
| 8620 | nombro | 3 |
| 8621 | niñito | 3 |
| 8622 | niñería | 3 |
| 8623 | nieblas | 3 |
| 8624 | nicolasa | 3 |
| 8625 | neurosis | 3 |
| 8626 | nenito | 3 |
| 8627 | nenín | 3 |
| 8628 | negrito | 3 |
| 8629 | negociante | 3 |
| 8630 | negó | 3 |
| 8631 | negativo | 3 |
| 8632 | negativa | 3 |
| 8633 | nefando | 3 |
| 8634 | necesitaban | 3 |
| 8635 | náufrago | 3 |
| 8636 | naturalistas | 3 |
| 8637 | nativo | 3 |
| 8638 | nacionales | 3 |
| 8639 | nacía | 3 |
| 8640 | musgo | 3 |
| 8641 | museo | 3 |
| 8642 | músculo | 3 |
| 8643 | murrias | 3 |
| 8644 | murria | 3 |
| 8645 | muro | 3 |
| 8646 | murillo | 3 |
| 8647 | murieron | 3 |
| 8648 | mugrienta | 3 |
| 8649 | mueve | 3 |
| 8650 | muertes | 3 |
| 8651 | mueras | 3 |
| 8652 | muecas | 3 |
| 8653 | mueble | 3 |
| 8654 | mudos | 3 |
| 8655 | mudó | 3 |
| 8656 | mudo | 3 |
| 8657 | mudar | 3 |
| 8658 | mudanza | 3 |
| 8659 | móvil | 3 |
| 8660 | movidas | 3 |
| 8661 | mostrarle | 3 |
| 8662 | mosquitos | 3 |
| 8663 | mosquito | 3 |
| 8664 | mortificación | 3 |
| 8665 | morrión | 3 |
| 8666 | morisquetas | 3 |
| 8667 | moriré | 3 |
| 8668 | morirá | 3 |
| 8669 | moriones | 3 |
| 8670 | moribunda | 3 |
| 8671 | morfina | 3 |
| 8672 | morena | 3 |
| 8673 | morejón | 3 |
| 8674 | morder | 3 |
| 8675 | moraba | 3 |
| 8676 | montaña | 3 |
| 8677 | monstruosidad | 3 |
| 8678 | monserga | 3 |
| 8679 | monosílabos | 3 |
| 8680 | monosílabo | 3 |
| 8681 | monólogo | 3 |
| 8682 | monísimo | 3 |
| 8683 | monísima | 3 |
| 8684 | molinillos | 3 |
| 8685 | molesto | 3 |
| 8686 | molestias | 3 |
| 8687 | moleste | 3 |
| 8688 | molestar | 3 |
| 8689 | mojado | 3 |
| 8690 | modesta | 3 |
| 8691 | modernas | 3 |
| 8692 | mocedad | 3 |
| 8693 | mitones | 3 |
| 8694 | misticismo | 3 |
| 8695 | místicas | 3 |
| 8696 | mísero | 3 |
| 8697 | miserables | 3 |
| 8698 | mires | 3 |
| 8699 | mírenlo | 3 |
| 8700 | miremos | 3 |
| 8701 | miraré | 3 |
| 8702 | mirara | 3 |
| 8703 | mirándome | 3 |
| 8704 | míralos | 3 |
| 8705 | miradores | 3 |
| 8706 | mirad | 3 |
| 8707 | minuciosamente | 3 |
| 8708 | ministración | 3 |
| 8709 | mimosos | 3 |
| 8710 | mimaba | 3 |
| 8711 | miembros | 3 |
| 8712 | mezquino | 3 |
| 8713 | mezclando | 3 |
| 8714 | mezcladas | 3 |
| 8715 | método | 3 |
| 8716 | metiera | 3 |
| 8717 | meterla | 3 |
| 8718 | merecen | 3 |
| 8719 | merecemos | 3 |
| 8720 | mercados | 3 |
| 8721 | mequetrefes | 3 |
| 8722 | menudeaban | 3 |
| 8723 | mendigos | 3 |
| 8724 | mendigo | 3 |
| 8725 | mendicidad | 3 |
| 8726 | melindres | 3 |
| 8727 | melchor | 3 |
| 8728 | mejorar | 3 |
| 8729 | meditaba | 3 |
| 8730 | medita | 3 |
| 8731 | medidas | 3 |
| 8732 | medicamentos | 3 |
| 8733 | mediante | 3 |
| 8734 | mediana | 3 |
| 8735 | mechón | 3 |
| 8736 | mecheros | 3 |
| 8737 | mató | 3 |
| 8738 | maternales | 3 |
| 8739 | matas | 3 |
| 8740 | mataré | 3 |
| 8741 | matara | 3 |
| 8742 | matan | 3 |
| 8743 | matadero | 3 |
| 8744 | masticando | 3 |
| 8745 | máscaras | 3 |
| 8746 | mascando | 3 |
| 8747 | martín | 3 |
| 8748 | marrullerías | 3 |
| 8749 | marianas | 3 |
| 8750 | mares | 3 |
| 8751 | mareas | 3 |
| 8752 | marear | 3 |
| 8753 | marean | 3 |
| 8754 | mareaba | 3 |
| 8755 | marea | 3 |
| 8756 | marcial | 3 |
| 8757 | marcharte | 3 |
| 8758 | marchara | 3 |
| 8759 | marcando | 3 |
| 8760 | maravillosas | 3 |
| 8761 | máquinas | 3 |
| 8762 | maquinal | 3 |
| 8763 | manzanares | 3 |
| 8764 | manzana | 3 |
| 8765 | manubrio | 3 |
| 8766 | mantiene | 3 |
| 8767 | manteca | 3 |
| 8768 | mansedumbre | 3 |
| 8769 | manoteando | 3 |
| 8770 | manotada | 3 |
| 8771 | maniquís | 3 |
| 8772 | manifiestan | 3 |
| 8773 | manifestación | 3 |
| 8774 | manifestábase | 3 |
| 8775 | mangonear | 3 |
| 8776 | manejar | 3 |
| 8777 | mandil | 3 |
| 8778 | manden | 3 |
| 8779 | mandarle | 3 |
| 8780 | mandara | 3 |
| 8781 | mandaban | 3 |
| 8782 | manchada | 3 |
| 8783 | mancebo | 3 |
| 8784 | manceba | 3 |
| 8785 | mamás | 3 |
| 8786 | mamarrachos | 3 |
| 8787 | malísimo | 3 |
| 8788 | maliciosa | 3 |
| 8789 | maleza | 3 |
| 8790 | magras | 3 |
| 8791 | magníficas | 3 |
| 8792 | madrugar | 3 |
| 8793 | madriz | 3 |
| 8794 | luminosos | 3 |
| 8795 | lujosa | 3 |
| 8796 | lucidos | 3 |
| 8797 | lucía | 3 |
| 8798 | luchas | 3 |
| 8799 | lodo | 3 |
| 8800 | locuras | 3 |
| 8801 | locuaz | 3 |
| 8802 | lobo | 3 |
| 8803 | lluvia | 3 |
| 8804 | lloro | 3 |
| 8805 | lléveselo | 3 |
| 8806 | llévate | 3 |
| 8807 | llevase | 3 |
| 8808 | llevarte | 3 |
| 8809 | llevará | 3 |
| 8810 | llenaron | 3 |
| 8811 | llenan | 3 |
| 8812 | llenado | 3 |
| 8813 | llamole | 3 |
| 8814 | llamarme | 3 |
| 8815 | llamarla | 3 |
| 8816 | llamaran | 3 |
| 8817 | llamará | 3 |
| 8818 | lívido | 3 |
| 8819 | literatura | 3 |
| 8820 | lisonja | 3 |
| 8821 | liquidación | 3 |
| 8822 | lindo | 3 |
| 8823 | lindísimo | 3 |
| 8824 | lindas | 3 |
| 8825 | linajes | 3 |
| 8826 | linaje | 3 |
| 8827 | limpiaba | 3 |
| 8828 | límite | 3 |
| 8829 | ligereza | 3 |
| 8830 | licencias | 3 |
| 8831 | librarle | 3 |
| 8832 | libertades | 3 |
| 8833 | leves | 3 |
| 8834 | levante | 3 |
| 8835 | levantara | 3 |
| 8836 | levantada | 3 |
| 8837 | levanta | 3 |
| 8838 | letreros | 3 |
| 8839 | leopardi | 3 |
| 8840 | lento | 3 |
| 8841 | lengüetazos | 3 |
| 8842 | legalidad | 3 |
| 8843 | lectoral | 3 |
| 8844 | lazos | 3 |
| 8845 | lavo | 3 |
| 8846 | laven | 3 |
| 8847 | lava | 3 |
| 8848 | latas | 3 |
| 8849 | lata | 3 |
| 8850 | lárgate | 3 |
| 8851 | lanzar | 3 |
| 8852 | lanzada | 3 |
| 8853 | lanzaba | 3 |
| 8854 | lanilla | 3 |
| 8855 | lamentaba | 3 |
| 8856 | lago | 3 |
| 8857 | ladronas | 3 |
| 8858 | lacio | 3 |
| 8859 | lacayo | 3 |
| 8860 | jurisdicción | 3 |
| 8861 | juraría | 3 |
| 8862 | juramento | 3 |
| 8863 | juntar | 3 |
| 8864 | jui | 3 |
| 8865 | juguetes | 3 |
| 8866 | jugaban | 3 |
| 8867 | jugaba | 3 |
| 8868 | judas | 3 |
| 8869 | juana | 3 |
| 8870 | jotas | 3 |
| 8871 | jinete | 3 |
| 8872 | jarras | 3 |
| 8873 | japonesa | 3 |
| 8874 | jamases | 3 |
| 8875 | jaime | 3 |
| 8876 | jacintilla | 3 |
| 8877 | isabelita | 3 |
| 8878 | irritación | 3 |
| 8879 | irregular | 3 |
| 8880 | irían | 3 |
| 8881 | irán | 3 |
| 8882 | ioduro | 3 |
| 8883 | invocando | 3 |
| 8884 | inventó | 3 |
| 8885 | inundada | 3 |
| 8886 | intrigas | 3 |
| 8887 | intranquilidad | 3 |
| 8888 | íntimos | 3 |
| 8889 | íntimamente | 3 |
| 8890 | interrumpía | 3 |
| 8891 | interrogó | 3 |
| 8892 | interrogaba | 3 |
| 8893 | interponía | 3 |
| 8894 | intermitentes | 3 |
| 8895 | interiores | 3 |
| 8896 | interesarse | 3 |
| 8897 | intentaban | 3 |
| 8898 | intenso | 3 |
| 8899 | intensísima | 3 |
| 8900 | institutriz | 3 |
| 8901 | institutos | 3 |
| 8902 | instintivamente | 3 |
| 8903 | inspiran | 3 |
| 8904 | inspiraban | 3 |
| 8905 | insomnio | 3 |
| 8906 | insistía | 3 |
| 8907 | insensiblemente | 3 |
| 8908 | insensata | 3 |
| 8909 | insano | 3 |
| 8910 | inquisidora | 3 |
| 8911 | inquilina | 3 |
| 8912 | inocentona | 3 |
| 8913 | inmundicia | 3 |
| 8914 | inmiscuirse | 3 |
| 8915 | inmemorial | 3 |
| 8916 | injusticia | 3 |
| 8917 | iniciarse | 3 |
| 8918 | inglesas | 3 |
| 8919 | ingeniosas | 3 |
| 8920 | ingenieros | 3 |
| 8921 | infunde | 3 |
| 8922 | infracción | 3 |
| 8923 | inflexible | 3 |
| 8924 | infinitos | 3 |
| 8925 | infinitamente | 3 |
| 8926 | infinita | 3 |
| 8927 | infiel | 3 |
| 8928 | infernales | 3 |
| 8929 | inferioridad | 3 |
| 8930 | inevitable | 3 |
| 8931 | inesperadamente | 3 |
| 8932 | industriales | 3 |
| 8933 | industrial | 3 |
| 8934 | indulgentes | 3 |
| 8935 | indolencia | 3 |
| 8936 | individua | 3 |
| 8937 | indispensables | 3 |
| 8938 | indirecta | 3 |
| 8939 | indicio | 3 |
| 8940 | indefinible | 3 |
| 8941 | indecoroso | 3 |
| 8942 | incrédulo | 3 |
| 8943 | incorporó | 3 |
| 8944 | incorporado | 3 |
| 8945 | inconstante | 3 |
| 8946 | inconsolable | 3 |
| 8947 | incomparable | 3 |
| 8948 | inclinación | 3 |
| 8949 | incierta | 3 |
| 8950 | incertidumbre | 3 |
| 8951 | incendio | 3 |
| 8952 | inapreciable | 3 |
| 8953 | impropia | 3 |
| 8954 | imposibilidad | 3 |
| 8955 | importaría | 3 |
| 8956 | importará | 3 |
| 8957 | importan | 3 |
| 8958 | impone | 3 |
| 8959 | impetuosa | 3 |
| 8960 | imperiosa | 3 |
| 8961 | imperdible | 3 |
| 8962 | imitaba | 3 |
| 8963 | imbécil | 3 |
| 8964 | imaginó | 3 |
| 8965 | imaginaba | 3 |
| 8966 | ilustrado | 3 |
| 8967 | iluminó | 3 |
| 8968 | ilumina | 3 |
| 8969 | ildefonso | 3 |
| 8970 | idolatraba | 3 |
| 8971 | idiota | 3 |
| 8972 | idioma | 3 |
| 8973 | idas | 3 |
| 8974 | íbase | 3 |
| 8975 | íbamos | 3 |
| 8976 | huyó | 3 |
| 8977 | huye | 3 |
| 8978 | hundido | 3 |
| 8979 | humorismo | 3 |
| 8980 | húmeda | 3 |
| 8981 | humareda | 3 |
| 8982 | huevera | 3 |
| 8983 | huelen | 3 |
| 8984 | huele | 3 |
| 8985 | hubieron | 3 |
| 8986 | hubiéramos | 3 |
| 8987 | hostias | 3 |
| 8988 | horizontes | 3 |
| 8989 | horizontal | 3 |
| 8990 | hondísimo | 3 |
| 8991 | hoc | 3 |
| 8992 | históricas | 3 |
| 8993 | hinchazón | 3 |
| 8994 | hilos | 3 |
| 8995 | hervía | 3 |
| 8996 | herramientas | 3 |
| 8997 | herméticamente | 3 |
| 8998 | hermanitas | 3 |
| 8999 | heridas | 3 |
| 9000 | heladas | 3 |
| 9001 | hayan | 3 |
| 9002 | hato | 3 |
| 9003 | haremos | 3 |
| 9004 | hambriento | 3 |
| 9005 | hallazgo | 3 |
| 9006 | hallando | 3 |
| 9007 | halla | 3 |
| 9008 | haciéndoles | 3 |
| 9009 | hacernos | 3 |
| 9010 | habríamos | 3 |
| 9011 | habrán | 3 |
| 9012 | hablose | 3 |
| 9013 | hablarles | 3 |
| 9014 | hablaran | 3 |
| 9015 | hablará | 3 |
| 9016 | habladurías | 3 |
| 9017 | habitantes | 3 |
| 9018 | habitante | 3 |
| 9019 | habíase | 3 |
| 9020 | habíalo | 3 |
| 9021 | habana | 3 |
| 9022 | gustó | 3 |
| 9023 | guste | 3 |
| 9024 | gustavito | 3 |
| 9025 | gustará | 3 |
| 9026 | guita | 3 |
| 9027 | guisantes | 3 |
| 9028 | guindillas | 3 |
| 9029 | guedejas | 3 |
| 9030 | guardaron | 3 |
| 9031 | guapote | 3 |
| 9032 | gruñó | 3 |
| 9033 | gruesas | 3 |
| 9034 | gritería | 3 |
| 9035 | grillete | 3 |
| 9036 | granito | 3 |
| 9037 | graciosos | 3 |
| 9038 | gracejo | 3 |
| 9039 | gozaban | 3 |
| 9040 | golpeando | 3 |
| 9041 | golosos | 3 |
| 9042 | glorioso | 3 |
| 9043 | gimnasia | 3 |
| 9044 | gesticulando | 3 |
| 9045 | geografía | 3 |
| 9046 | gentuza | 3 |
| 9047 | generalmente | 3 |
| 9048 | generales | 3 |
| 9049 | gemir | 3 |
| 9050 | gases | 3 |
| 9051 | garrotillo | 3 |
| 9052 | gargarismos | 3 |
| 9053 | garfios | 3 |
| 9054 | garcía | 3 |
| 9055 | garatusas | 3 |
| 9056 | garabatos | 3 |
| 9057 | ganancia | 3 |
| 9058 | ganan | 3 |
| 9059 | ganaban | 3 |
| 9060 | gallina | 3 |
| 9061 | gallegos | 3 |
| 9062 | gallarda | 3 |
| 9063 | galante | 3 |
| 9064 | gabinetito | 3 |
| 9065 | gabanes | 3 |
| 9066 | gabán | 3 |
| 9067 | futuras | 3 |
| 9068 | funesta | 3 |
| 9069 | fundado | 3 |
| 9070 | fundaba | 3 |
| 9071 | fulano | 3 |
| 9072 | fuiste | 3 |
| 9073 | fuga | 3 |
| 9074 | fuero | 3 |
| 9075 | frutas | 3 |
| 9076 | fruncido | 3 |
| 9077 | frugal | 3 |
| 9078 | frontera | 3 |
| 9079 | fritos | 3 |
| 9080 | fritangas | 3 |
| 9081 | friegas | 3 |
| 9082 | fregar | 3 |
| 9083 | frecuentes | 3 |
| 9084 | frecuente | 3 |
| 9085 | frecuentaba | 3 |
| 9086 | frascos | 3 |
| 9087 | fraile | 3 |
| 9088 | fragua | 3 |
| 9089 | frágiles | 3 |
| 9090 | fraganti | 3 |
| 9091 | fraga | 3 |
| 9092 | fósforos | 3 |
| 9093 | fósforo | 3 |
| 9094 | fosfato | 3 |
| 9095 | formidables | 3 |
| 9096 | formidable | 3 |
| 9097 | formaron | 3 |
| 9098 | formales | 3 |
| 9099 | for | 3 |
| 9100 | flexible | 3 |
| 9101 | fleco | 3 |
| 9102 | flaco | 3 |
| 9103 | flaca | 3 |
| 9104 | físicas | 3 |
| 9105 | físicamente | 3 |
| 9106 | firmeza | 3 |
| 9107 | finos | 3 |
| 9108 | fingir | 3 |
| 9109 | finge | 3 |
| 9110 | fineza | 3 |
| 9111 | financieras | 3 |
| 9112 | filosófico | 3 |
| 9113 | filosofías | 3 |
| 9114 | filípica | 3 |
| 9115 | fijaron | 3 |
| 9116 | fijar | 3 |
| 9117 | fijado | 3 |
| 9118 | figurar | 3 |
| 9119 | figurándose | 3 |
| 9120 | figueras | 3 |
| 9121 | fiestas | 3 |
| 9122 | fieras | 3 |
| 9123 | ficción | 3 |
| 9124 | fibra | 3 |
| 9125 | fervor | 3 |
| 9126 | ferias | 3 |
| 9127 | fenómenos | 3 |
| 9128 | femenino | 3 |
| 9129 | felpudo | 3 |
| 9130 | felizmente | 3 |
| 9131 | fecundo | 3 |
| 9132 | febriles | 3 |
| 9133 | favores | 3 |
| 9134 | favorecido | 3 |
| 9135 | favorecía | 3 |
| 9136 | favorece | 3 |
| 9137 | favorcito | 3 |
| 9138 | fatigadísima | 3 |
| 9139 | fatigadas | 3 |
| 9140 | fastidio | 3 |
| 9141 | faroles | 3 |
| 9142 | farmacéuticos | 3 |
| 9143 | farmacéutica | 3 |
| 9144 | fardos | 3 |
| 9145 | fantástico | 3 |
| 9146 | fantasía | 3 |
| 9147 | famélico | 3 |
| 9148 | falte | 3 |
| 9149 | faltábale | 3 |
| 9150 | falsos | 3 |
| 9151 | falsete | 3 |
| 9152 | falleció | 3 |
| 9153 | facundia | 3 |
| 9154 | facturas | 3 |
| 9155 | fáciles | 3 |
| 9156 | fábricas | 3 |
| 9157 | fabricante | 3 |
| 9158 | fabricando | 3 |
| 9159 | extremos | 3 |
| 9160 | extremidades | 3 |
| 9161 | extremada | 3 |
| 9162 | extraviados | 3 |
| 9163 | extraviada | 3 |
| 9164 | extranjeras | 3 |
| 9165 | externa | 3 |
| 9166 | extendido | 3 |
| 9167 | exquisitos | 3 |
| 9168 | exquisito | 3 |
| 9169 | expuso | 3 |
| 9170 | expresan | 3 |
| 9171 | explotar | 3 |
| 9172 | explosiva | 3 |
| 9173 | explicase | 3 |
| 9174 | explicaré | 3 |
| 9175 | explicara | 3 |
| 9176 | explanada | 3 |
| 9177 | experimentaba | 3 |
| 9178 | expectativa | 3 |
| 9179 | expectante | 3 |
| 9180 | existido | 3 |
| 9181 | exhalando | 3 |
| 9182 | excitó | 3 |
| 9183 | excesivo | 3 |
| 9184 | examinarse | 3 |
| 9185 | examinándole | 3 |
| 9186 | exaltándose | 3 |
| 9187 | exageración | 3 |
| 9188 | exageraba | 3 |
| 9189 | exacta | 3 |
| 9190 | evolución | 3 |
| 9191 | evocando | 3 |
| 9192 | evasivamente | 3 |
| 9193 | evasión | 3 |
| 9194 | europa | 3 |
| 9195 | eternidad | 3 |
| 9196 | estuviéramos | 3 |
| 9197 | estudiando | 3 |
| 9198 | estudiado | 3 |
| 9199 | estrujón | 3 |
| 9200 | estridente | 3 |
| 9201 | estricnina | 3 |
| 9202 | estribillo | 3 |
| 9203 | estrepitoso | 3 |
| 9204 | estrechó | 3 |
| 9205 | estrechamente | 3 |
| 9206 | estrafalario | 3 |
| 9207 | estirar | 3 |
| 9208 | estima | 3 |
| 9209 | estéis | 3 |
| 9210 | estarlo | 3 |
| 9211 | estaremos | 3 |
| 9212 | estarán | 3 |
| 9213 | establecerse | 3 |
| 9214 | esquinas | 3 |
| 9215 | esplín | 3 |
| 9216 | espléndido | 3 |
| 9217 | espionaje | 3 |
| 9218 | espeso | 3 |
| 9219 | espesa | 3 |
| 9220 | esperpento | 3 |
| 9221 | esperase | 3 |
| 9222 | esperaron | 3 |
| 9223 | esperaremos | 3 |
| 9224 | esperan | 3 |
| 9225 | esperaban | 3 |
| 9226 | espectáculos | 3 |
| 9227 | específico | 3 |
| 9228 | esparto | 3 |
| 9229 | esparció | 3 |
| 9230 | espantado | 3 |
| 9231 | espadas | 3 |
| 9232 | espacios | 3 |
| 9233 | esfinge | 3 |
| 9234 | esenciales | 3 |
| 9235 | esencia | 3 |
| 9236 | escupiendo | 3 |
| 9237 | escuelas | 3 |
| 9238 | escuchar | 3 |
| 9239 | escucha | 3 |
| 9240 | escrupuloso | 3 |
| 9241 | escondidos | 3 |
| 9242 | esconder | 3 |
| 9243 | esconden | 3 |
| 9244 | escogía | 3 |
| 9245 | escocesa | 3 |
| 9246 | escobillón | 3 |
| 9247 | esclava | 3 |
| 9248 | escepticismo | 3 |
| 9249 | escayolas | 3 |
| 9250 | escarmiento | 3 |
| 9251 | escapatorias | 3 |
| 9252 | escandalosa | 3 |
| 9253 | escandalizar | 3 |
| 9254 | escala | 3 |
| 9255 | escabeche | 3 |
| 9256 | errante | 3 |
| 9257 | éranle | 3 |
| 9258 | éralo | 3 |
| 9259 | equivoco | 3 |
| 9260 | equivalía | 3 |
| 9261 | equivale | 3 |
| 9262 | epigastrio | 3 |
| 9263 | envueltos | 3 |
| 9264 | envolvían | 3 |
| 9265 | envolverse | 3 |
| 9266 | envido | 3 |
| 9267 | envidiosa | 3 |
| 9268 | envidiaba | 3 |
| 9269 | envenenar | 3 |
| 9270 | envenenamiento | 3 |
| 9271 | envalentonó | 3 |
| 9272 | entusiastas | 3 |
| 9273 | entusiasmarse | 3 |
| 9274 | entusiasmado | 3 |
| 9275 | entusiasmaba | 3 |
| 9276 | entrometida | 3 |
| 9277 | entretiene | 3 |
| 9278 | entretenimientos | 3 |
| 9279 | entretenido | 3 |
| 9280 | entres | 3 |
| 9281 | entren | 3 |
| 9282 | entrego | 3 |
| 9283 | entregaba | 3 |
| 9284 | entrecano | 3 |
| 9285 | entras | 3 |
| 9286 | entráronle | 3 |
| 9287 | entraré | 3 |
| 9288 | entrañablemente | 3 |
| 9289 | entrambos | 3 |
| 9290 | entrábale | 3 |
| 9291 | entienden | 3 |
| 9292 | enterose | 3 |
| 9293 | enterase | 3 |
| 9294 | enteraron | 3 |
| 9295 | enterándose | 3 |
| 9296 | entenderse | 3 |
| 9297 | enseñaron | 3 |
| 9298 | enseñaré | 3 |
| 9299 | enseñanzas | 3 |
| 9300 | enredar | 3 |
| 9301 | enojosa | 3 |
| 9302 | ennoblece | 3 |
| 9303 | enigma | 3 |
| 9304 | engañada | 3 |
| 9305 | enfadó | 3 |
| 9306 | enfadarse | 3 |
| 9307 | enérgica | 3 |
| 9308 | eneas | 3 |
| 9309 | encontrarla | 3 |
| 9310 | encinas | 3 |
| 9311 | encerrarse | 3 |
| 9312 | encerraba | 3 |
| 9313 | encendieron | 3 |
| 9314 | encendiendo | 3 |
| 9315 | encendidas | 3 |
| 9316 | encarnados | 3 |
| 9317 | encarnadas | 3 |
| 9318 | encarnada | 3 |
| 9319 | encargar | 3 |
| 9320 | encarga | 3 |
| 9321 | encandilados | 3 |
| 9322 | encaminó | 3 |
| 9323 | enana | 3 |
| 9324 | enaguas | 3 |
| 9325 | emulación | 3 |
| 9326 | empujó | 3 |
| 9327 | empujaba | 3 |
| 9328 | emprendió | 3 |
| 9329 | emplasto | 3 |
| 9330 | empiezo | 3 |
| 9331 | empezaría | 3 |
| 9332 | empeñas | 3 |
| 9333 | empeñarse | 3 |
| 9334 | empedrado | 3 |
| 9335 | empaque | 3 |
| 9336 | empalagosas | 3 |
| 9337 | embuste | 3 |
| 9338 | embozo | 3 |
| 9339 | emblema | 3 |
| 9340 | embargaba | 3 |
| 9341 | embarazo | 3 |
| 9342 | elogios | 3 |
| 9343 | elocuentes | 3 |
| 9344 | elocuencia | 3 |
| 9345 | elevando | 3 |
| 9346 | elemento | 3 |
| 9347 | elemental | 3 |
| 9348 | elegir | 3 |
| 9349 | elegida | 3 |
| 9350 | electrizaba | 3 |
| 9351 | eléctrica | 3 |
| 9352 | elecciones | 3 |
| 9353 | ejercitarse | 3 |
| 9354 | ejemplares | 3 |
| 9355 | ejemplar | 3 |
| 9356 | eje | 3 |
| 9357 | edificación | 3 |
| 9358 | echárselas | 3 |
| 9359 | echaré | 3 |
| 9360 | echándoselas | 3 |
| 9361 | durmiose | 3 |
| 9362 | durmieron | 3 |
| 9363 | durmiera | 3 |
| 9364 | durase | 3 |
| 9365 | duras | 3 |
| 9366 | duraría | 3 |
| 9367 | dulcísimos | 3 |
| 9368 | duerma | 3 |
| 9369 | duela | 3 |
| 9370 | ducha | 3 |
| 9371 | dramática | 3 |
| 9372 | dragón | 3 |
| 9373 | doradas | 3 |
| 9374 | domina | 3 |
| 9375 | domiciliaria | 3 |
| 9376 | dogma | 3 |
| 9377 | doctrinas | 3 |
| 9378 | doblado | 3 |
| 9379 | divino | 3 |
| 9380 | divinidades | 3 |
| 9381 | diversión | 3 |
| 9382 | distrajo | 3 |
| 9383 | distraía | 3 |
| 9384 | distraerse | 3 |
| 9385 | distinguió | 3 |
| 9386 | distinguían | 3 |
| 9387 | distantes | 3 |
| 9388 | dispensa | 3 |
| 9389 | disparada | 3 |
| 9390 | disolventes | 3 |
| 9391 | disminuía | 3 |
| 9392 | disimulando | 3 |
| 9393 | disgustó | 3 |
| 9394 | disgustada | 3 |
| 9395 | disgustaba | 3 |
| 9396 | disfrazado | 3 |
| 9397 | discurrido | 3 |
| 9398 | discretos | 3 |
| 9399 | discretas | 3 |
| 9400 | dirigiose | 3 |
| 9401 | dirigiéndose | 3 |
| 9402 | dirigiendo | 3 |
| 9403 | dirigían | 3 |
| 9404 | diplomático | 3 |
| 9405 | diplomacia | 3 |
| 9406 | dinidá | 3 |
| 9407 | diligentes | 3 |
| 9408 | dígole | 3 |
| 9409 | dignó | 3 |
| 9410 | digerir | 3 |
| 9411 | dígase | 3 |
| 9412 | difícilmente | 3 |
| 9413 | dificilillo | 3 |
| 9414 | diferente | 3 |
| 9415 | dieciocho | 3 |
| 9416 | dictando | 3 |
| 9417 | dictamen | 3 |
| 9418 | dializado | 3 |
| 9419 | devoto | 3 |
| 9420 | determinaron | 3 |
| 9421 | deteniendo | 3 |
| 9422 | detener | 3 |
| 9423 | desvelado | 3 |
| 9424 | desvanecimiento | 3 |
| 9425 | desvanecido | 3 |
| 9426 | destrozado | 3 |
| 9427 | destrozaba | 3 |
| 9428 | destempladas | 3 |
| 9429 | destacaba | 3 |
| 9430 | despropósitos | 3 |
| 9431 | desproporción | 3 |
| 9432 | despreciar | 3 |
| 9433 | desprecia | 3 |
| 9434 | despotismo | 3 |
| 9435 | despojos | 3 |
| 9436 | desplegó | 3 |
| 9437 | desplegando | 3 |
| 9438 | despertaron | 3 |
| 9439 | desparpajo | 3 |
| 9440 | despacito | 3 |
| 9441 | despachar | 3 |
| 9442 | desórdenes | 3 |
| 9443 | desordenada | 3 |
| 9444 | desolada | 3 |
| 9445 | desnudos | 3 |
| 9446 | desnudarse | 3 |
| 9447 | desnuda | 3 |
| 9448 | desmedrada | 3 |
| 9449 | desmayada | 3 |
| 9450 | desigualdades | 3 |
| 9451 | deshonrar | 3 |
| 9452 | deshizo | 3 |
| 9453 | deshilachada | 3 |
| 9454 | deshacer | 3 |
| 9455 | deshace | 3 |
| 9456 | desgraciados | 3 |
| 9457 | desesperados | 3 |
| 9458 | desenfado | 3 |
| 9459 | desempeñó | 3 |
| 9460 | descubrirse | 3 |
| 9461 | descubrimiento | 3 |
| 9462 | descubrían | 3 |
| 9463 | descrito | 3 |
| 9464 | descontento | 3 |
| 9465 | desconoce | 3 |
| 9466 | desconfianza | 3 |
| 9467 | descendiendo | 3 |
| 9468 | descendía | 3 |
| 9469 | descaro | 3 |
| 9470 | descargar | 3 |
| 9471 | descargaba | 3 |
| 9472 | descalzo | 3 |
| 9473 | desbarajuste | 3 |
| 9474 | desasirse | 3 |
| 9475 | desarrolló | 3 |
| 9476 | desaires | 3 |
| 9477 | desairar | 3 |
| 9478 | desagradaba | 3 |
| 9479 | desabrimiento | 3 |
| 9480 | derroche | 3 |
| 9481 | derechita | 3 |
| 9482 | deplorable | 3 |
| 9483 | denunciaba | 3 |
| 9484 | dengue | 3 |
| 9485 | delitos | 3 |
| 9486 | delicia | 3 |
| 9487 | delicados | 3 |
| 9488 | delicadas | 3 |
| 9489 | delgado | 3 |
| 9490 | dejen | 3 |
| 9491 | dejemos | 3 |
| 9492 | dejémonos | 3 |
| 9493 | déjele | 3 |
| 9494 | dejaría | 3 |
| 9495 | dejaran | 3 |
| 9496 | dejándole | 3 |
| 9497 | definitivo | 3 |
| 9498 | definitiva | 3 |
| 9499 | defenderle | 3 |
| 9500 | dedicarse | 3 |
| 9501 | dedicado | 3 |
| 9502 | declaraban | 3 |
| 9503 | declara | 3 |
| 9504 | decisión | 3 |
| 9505 | decírmelo | 3 |
| 9506 | decirles | 3 |
| 9507 | decido | 3 |
| 9508 | debiste | 3 |
| 9509 | debidos | 3 |
| 9510 | dársele | 3 |
| 9511 | dársela | 3 |
| 9512 | daremos | 3 |
| 9513 | darás | 3 |
| 9514 | danza | 3 |
| 9515 | dándome | 3 |
| 9516 | damasco | 3 |
| 9517 | curiosidades | 3 |
| 9518 | curarse | 3 |
| 9519 | curarle | 3 |
| 9520 | cumpliría | 3 |
| 9521 | cumplidas | 3 |
| 9522 | cumpla | 3 |
| 9523 | culebras | 3 |
| 9524 | cuitas | 3 |
| 9525 | cuidadito | 3 |
| 9526 | cuestas | 3 |
| 9527 | cueros | 3 |
| 9528 | cuéntame | 3 |
| 9529 | cuelga | 3 |
| 9530 | cuchitril | 3 |
| 9531 | cuchicheos | 3 |
| 9532 | cucharas | 3 |
| 9533 | cuatrocientos | 3 |
| 9534 | cuajados | 3 |
| 9535 | cuajada | 3 |
| 9536 | crujía | 3 |
| 9537 | crueles | 3 |
| 9538 | cruda | 3 |
| 9539 | crucifijo | 3 |
| 9540 | cristiandad | 3 |
| 9541 | crié | 3 |
| 9542 | críe | 3 |
| 9543 | crezca | 3 |
| 9544 | creyéndolo | 3 |
| 9545 | crepúsculo | 3 |
| 9546 | creerte | 3 |
| 9547 | creeréis | 3 |
| 9548 | creencia | 3 |
| 9549 | crecimiento | 3 |
| 9550 | crecido | 3 |
| 9551 | créanmelo | 3 |
| 9552 | costados | 3 |
| 9553 | cortada | 3 |
| 9554 | corros | 3 |
| 9555 | corrigen | 3 |
| 9556 | corriéndose | 3 |
| 9557 | corrían | 3 |
| 9558 | corrí | 3 |
| 9559 | corretaje | 3 |
| 9560 | correspondientes | 3 |
| 9561 | corresponden | 3 |
| 9562 | correcta | 3 |
| 9563 | coronilla | 3 |
| 9564 | corista | 3 |
| 9565 | corinto | 3 |
| 9566 | corazonada | 3 |
| 9567 | convidó | 3 |
| 9568 | convidados | 3 |
| 9569 | convidaba | 3 |
| 9570 | convenza | 3 |
| 9571 | convenga | 3 |
| 9572 | convendría | 3 |
| 9573 | convencional | 3 |
| 9574 | convencida | 3 |
| 9575 | convencía | 3 |
| 9576 | contratas | 3 |
| 9577 | contradecía | 3 |
| 9578 | contracción | 3 |
| 9579 | continuidad | 3 |
| 9580 | continuaban | 3 |
| 9581 | continua | 3 |
| 9582 | contingencia | 3 |
| 9583 | continente | 3 |
| 9584 | contesta | 3 |
| 9585 | contentos | 3 |
| 9586 | contentísima | 3 |
| 9587 | contentará | 3 |
| 9588 | contenían | 3 |
| 9589 | contemporizar | 3 |
| 9590 | contemporánea | 3 |
| 9591 | contemplar | 3 |
| 9592 | contemplación | 3 |
| 9593 | contemplaban | 3 |
| 9594 | contaste | 3 |
| 9595 | contarse | 3 |
| 9596 | contarles | 3 |
| 9597 | contaban | 3 |
| 9598 | consumado | 3 |
| 9599 | consultarle | 3 |
| 9600 | consultado | 3 |
| 9601 | consuele | 3 |
| 9602 | construir | 3 |
| 9603 | constituían | 3 |
| 9604 | constaba | 3 |
| 9605 | conspiradores | 3 |
| 9606 | consolar | 3 |
| 9607 | consiente | 3 |
| 9608 | considerado | 3 |
| 9609 | considerables | 3 |
| 9610 | conserve | 3 |
| 9611 | conservarse | 3 |
| 9612 | conservación | 3 |
| 9613 | consentido | 3 |
| 9614 | consentía | 3 |
| 9615 | consecuente | 3 |
| 9616 | consagrar | 3 |
| 9617 | consabida | 3 |
| 9618 | conquistar | 3 |
| 9619 | conocimos | 3 |
| 9620 | conociendo | 3 |
| 9621 | conocerle | 3 |
| 9622 | conocería | 3 |
| 9623 | conocedor | 3 |
| 9624 | conmovido | 3 |
| 9625 | conmovida | 3 |
| 9626 | conjunción | 3 |
| 9627 | confundidos | 3 |
| 9628 | confirmó | 3 |
| 9629 | confieso | 3 |
| 9630 | confiesa | 3 |
| 9631 | confiando | 3 |
| 9632 | confesó | 3 |
| 9633 | confesarse | 3 |
| 9634 | conducen | 3 |
| 9635 | conde | 3 |
| 9636 | concurso | 3 |
| 9637 | concurrir | 3 |
| 9638 | concurrencia | 3 |
| 9639 | conclusión | 3 |
| 9640 | concedo | 3 |
| 9641 | comúnmente | 3 |
| 9642 | comunión | 3 |
| 9643 | comunicativo | 3 |
| 9644 | comunicaciones | 3 |
| 9645 | comulgar | 3 |
| 9646 | compromisos | 3 |
| 9647 | comprometido | 3 |
| 9648 | comprendieron | 3 |
| 9649 | compre | 3 |
| 9650 | comportamiento | 3 |
| 9651 | componer | 3 |
| 9652 | cómplice | 3 |
| 9653 | compasivo | 3 |
| 9654 | comparado | 3 |
| 9655 | comparaciones | 3 |
| 9656 | comparación | 3 |
| 9657 | compaginar | 3 |
| 9658 | comitiva | 3 |
| 9659 | comidas | 3 |
| 9660 | cómico | 3 |
| 9661 | cometía | 3 |
| 9662 | comérselo | 3 |
| 9663 | comerciales | 3 |
| 9664 | comerá | 3 |
| 9665 | combinar | 3 |
| 9666 | comas | 3 |
| 9667 | coman | 3 |
| 9668 | columna | 3 |
| 9669 | colosal | 3 |
| 9670 | colorines | 3 |
| 9671 | colorados | 3 |
| 9672 | colorado | 3 |
| 9673 | coloradita | 3 |
| 9674 | coloque | 3 |
| 9675 | colocarse | 3 |
| 9676 | colmena | 3 |
| 9677 | colgadas | 3 |
| 9678 | colgaban | 3 |
| 9679 | colegiales | 3 |
| 9680 | colega | 3 |
| 9681 | colación | 3 |
| 9682 | cojín | 3 |
| 9683 | cogiera | 3 |
| 9684 | cogidas | 3 |
| 9685 | cogerlo | 3 |
| 9686 | cogería | 3 |
| 9687 | cochinada | 3 |
| 9688 | coces | 3 |
| 9689 | clavándole | 3 |
| 9690 | clavan | 3 |
| 9691 | claustro | 3 |
| 9692 | claritas | 3 |
| 9693 | claques | 3 |
| 9694 | clamó | 3 |
| 9695 | ciudadanos | 3 |
| 9696 | citada | 3 |
| 9697 | cita | 3 |
| 9698 | circulación | 3 |
| 9699 | cipreses | 3 |
| 9700 | cimiento | 3 |
| 9701 | cielos | 3 |
| 9702 | cicatero | 3 |
| 9703 | chupando | 3 |
| 9704 | chupaba | 3 |
| 9705 | chupa | 3 |
| 9706 | chulos | 3 |
| 9707 | chuleta | 3 |
| 9708 | chorros | 3 |
| 9709 | chistera | 3 |
| 9710 | chiste | 3 |
| 9711 | chisme | 3 |
| 9712 | chinitas | 3 |
| 9713 | chinita | 3 |
| 9714 | chimeneas | 3 |
| 9715 | chillones | 3 |
| 9716 | chillido | 3 |
| 9717 | chillar | 3 |
| 9718 | chilla | 3 |
| 9719 | charló | 3 |
| 9720 | charlaron | 3 |
| 9721 | charco | 3 |
| 9722 | chanza | 3 |
| 9723 | chal | 3 |
| 9724 | cese | 3 |
| 9725 | cesaron | 3 |
| 9726 | cerillas | 3 |
| 9727 | cerilla | 3 |
| 9728 | cerebrales | 3 |
| 9729 | cerco | 3 |
| 9730 | cerciorarse | 3 |
| 9731 | cercano | 3 |
| 9732 | céntimo | 3 |
| 9733 | cencerro | 3 |
| 9734 | cementerios | 3 |
| 9735 | celebrar | 3 |
| 9736 | cedía | 3 |
| 9737 | cebolla | 3 |
| 9738 | cayera | 3 |
| 9739 | cavilo | 3 |
| 9740 | cavilación | 3 |
| 9741 | cavernosa | 3 |
| 9742 | cautiverio | 3 |
| 9743 | cautivaba | 3 |
| 9744 | cautelosamente | 3 |
| 9745 | católicas | 3 |
| 9746 | catado | 3 |
| 9747 | castrense | 3 |
| 9748 | castita | 3 |
| 9749 | castigos | 3 |
| 9750 | case | 3 |
| 9751 | cáscara | 3 |
| 9752 | casarte | 3 |
| 9753 | casara | 3 |
| 9754 | casamos | 3 |
| 9755 | casaca | 3 |
| 9756 | carúnculas | 3 |
| 9757 | caros | 3 |
| 9758 | carnicero | 3 |
| 9759 | carmín | 3 |
| 9760 | caricia | 3 |
| 9761 | cargar | 3 |
| 9762 | cargados | 3 |
| 9763 | cargadas | 3 |
| 9764 | carecía | 3 |
| 9765 | carecer | 3 |
| 9766 | cárdenas | 3 |
| 9767 | carcas | 3 |
| 9768 | carbones | 3 |
| 9769 | carbonería | 3 |
| 9770 | caracoles | 3 |
| 9771 | cápsulas | 3 |
| 9772 | caprichos | 3 |
| 9773 | capota | 3 |
| 9774 | cañones | 3 |
| 9775 | cáñamo | 3 |
| 9776 | cantoras | 3 |
| 9777 | cantara | 3 |
| 9778 | cantando | 3 |
| 9779 | cansarse | 3 |
| 9780 | cansar | 3 |
| 9781 | cansados | 3 |
| 9782 | cansa | 3 |
| 9783 | candoroso | 3 |
| 9784 | canastillas | 3 |
| 9785 | canario | 3 |
| 9786 | camps | 3 |
| 9787 | campos | 3 |
| 9788 | campechano | 3 |
| 9789 | campanillas | 3 |
| 9790 | campana | 3 |
| 9791 | cambios | 3 |
| 9792 | cambió | 3 |
| 9793 | cambiazo | 3 |
| 9794 | cambian | 3 |
| 9795 | cambiaba | 3 |
| 9796 | camastro | 3 |
| 9797 | camaraíta | 3 |
| 9798 | cámara | 3 |
| 9799 | calzón | 3 |
| 9800 | calumnias | 3 |
| 9801 | calmar | 3 |
| 9802 | callejuelas | 3 |
| 9803 | callandito | 3 |
| 9804 | calladito | 3 |
| 9805 | calentarse | 3 |
| 9806 | calentando | 3 |
| 9807 | calculo | 3 |
| 9808 | calavera | 3 |
| 9809 | calado | 3 |
| 9810 | caimán | 3 |
| 9811 | caerá | 3 |
| 9812 | cadena | 3 |
| 9813 | cachivaches | 3 |
| 9814 | cacharros | 3 |
| 9815 | caca | 3 |
| 9816 | cabras | 3 |
| 9817 | butacas | 3 |
| 9818 | busqué | 3 |
| 9819 | buscarse | 3 |
| 9820 | buscarlo | 3 |
| 9821 | buscarla | 3 |
| 9822 | buscaría | 3 |
| 9823 | burros | 3 |
| 9824 | burras | 3 |
| 9825 | burrada | 3 |
| 9826 | burlona | 3 |
| 9827 | burlas | 3 |
| 9828 | burlar | 3 |
| 9829 | burdeos | 3 |
| 9830 | buenazo | 3 |
| 9831 | bruces | 3 |
| 9832 | bromitas | 3 |
| 9833 | brocha | 3 |
| 9834 | brisas | 3 |
| 9835 | bríos | 3 |
| 9836 | brea | 3 |
| 9837 | bravas | 3 |
| 9838 | bramido | 3 |
| 9839 | bóveda | 3 |
| 9840 | botines | 3 |
| 9841 | botijos | 3 |
| 9842 | botijo | 3 |
| 9843 | bostezos | 3 |
| 9844 | borró | 3 |
| 9845 | borrascas | 3 |
| 9846 | borrar | 3 |
| 9847 | borrachona | 3 |
| 9848 | borracho | 3 |
| 9849 | bofes | 3 |
| 9850 | bodegón | 3 |
| 9851 | bobos | 3 |
| 9852 | blanda | 3 |
| 9853 | blancura | 3 |
| 9854 | bizcocho | 3 |
| 9855 | biblioteca | 3 |
| 9856 | besar | 3 |
| 9857 | berroqueña | 3 |
| 9858 | berrinchín | 3 |
| 9859 | berridos | 3 |
| 9860 | berrido | 3 |
| 9861 | benditos | 3 |
| 9862 | belga | 3 |
| 9863 | belenes | 3 |
| 9864 | bebiéndose | 3 |
| 9865 | bebido | 3 |
| 9866 | bazar | 3 |
| 9867 | bayetas | 3 |
| 9868 | baúles | 3 |
| 9869 | bastaban | 3 |
| 9870 | bases | 3 |
| 9871 | barros | 3 |
| 9872 | barriles | 3 |
| 9873 | barricada | 3 |
| 9874 | barcos | 3 |
| 9875 | barco | 3 |
| 9876 | barbián | 3 |
| 9877 | baratura | 3 |
| 9878 | baratos | 3 |
| 9879 | barandal | 3 |
| 9880 | baqueta | 3 |
| 9881 | baño | 3 |
| 9882 | banquete | 3 |
| 9883 | banda | 3 |
| 9884 | baldosines | 3 |
| 9885 | baldomerito | 3 |
| 9886 | bájate | 3 |
| 9887 | bailes | 3 |
| 9888 | bailando | 3 |
| 9889 | baila | 3 |
| 9890 | babosos | 3 |
| 9891 | azoramiento | 3 |
| 9892 | azorada | 3 |
| 9893 | ayudará | 3 |
| 9894 | ayudar | 3 |
| 9895 | ayudando | 3 |
| 9896 | ayudan | 3 |
| 9897 | ayúdame | 3 |
| 9898 | avivó | 3 |
| 9899 | aviso | 3 |
| 9900 | aviado | 3 |
| 9901 | averigüe | 3 |
| 9902 | averiguado | 3 |
| 9903 | avergonzado | 3 |
| 9904 | avergonzaba | 3 |
| 9905 | avanzaron | 3 |
| 9906 | autoritario | 3 |
| 9907 | autoritaria | 3 |
| 9908 | autoridades | 3 |
| 9909 | autócrata | 3 |
| 9910 | aumento | 3 |
| 9911 | aumentan | 3 |
| 9912 | aullidos | 3 |
| 9913 | aula | 3 |
| 9914 | audiencia | 3 |
| 9915 | audacia | 3 |
| 9916 | atropellarse | 3 |
| 9917 | atropellado | 3 |
| 9918 | atropelladamente | 3 |
| 9919 | atrocidad | 3 |
| 9920 | atroces | 3 |
| 9921 | atreviera | 3 |
| 9922 | atreviéndose | 3 |
| 9923 | atrayéndola | 3 |
| 9924 | atrayendo | 3 |
| 9925 | atrasado | 3 |
| 9926 | atrasadas | 3 |
| 9927 | atractivo | 3 |
| 9928 | atormentando | 3 |
| 9929 | atontado | 3 |
| 9930 | atontada | 3 |
| 9931 | atolladero | 3 |
| 9932 | atiza | 3 |
| 9933 | atienda | 3 |
| 9934 | aterradora | 3 |
| 9935 | atando | 3 |
| 9936 | atados | 3 |
| 9937 | asustes | 3 |
| 9938 | asuste | 3 |
| 9939 | asustar | 3 |
| 9940 | asustaba | 3 |
| 9941 | asunción | 3 |
| 9942 | astuta | 3 |
| 9943 | astorga | 3 |
| 9944 | aspiraciones | 3 |
| 9945 | aspiraba | 3 |
| 9946 | asombrada | 3 |
| 9947 | asomáronse | 3 |
| 9948 | asomándose | 3 |
| 9949 | asomando | 3 |
| 9950 | asistir | 3 |
| 9951 | asistía | 3 |
| 9952 | asistencia | 3 |
| 9953 | asimismo | 3 |
| 9954 | asimilarse | 3 |
| 9955 | asfixia | 3 |
| 9956 | aseveración | 3 |
| 9957 | asesinato | 3 |
| 9958 | aseguró | 3 |
| 9959 | asegura | 3 |
| 9960 | ascendía | 3 |
| 9961 | asaltaron | 3 |
| 9962 | asado | 3 |
| 9963 | artistas | 3 |
| 9964 | artificial | 3 |
| 9965 | artesón | 3 |
| 9966 | arsenal | 3 |
| 9967 | arrugando | 3 |
| 9968 | arrojan | 3 |
| 9969 | arrojaban | 3 |
| 9970 | arroja | 3 |
| 9971 | arrogancia | 3 |
| 9972 | arrodillándose | 3 |
| 9973 | arrobas | 3 |
| 9974 | arrepiéntete | 3 |
| 9975 | arrepentirse | 3 |
| 9976 | arrepentido | 3 |
| 9977 | arreglaría | 3 |
| 9978 | arreglaremos | 3 |
| 9979 | arreglan | 3 |
| 9980 | arreglaban | 3 |
| 9981 | arreglaba | 3 |
| 9982 | arrechucho | 3 |
| 9983 | arrebató | 3 |
| 9984 | arrebatada | 3 |
| 9985 | arrastrar | 3 |
| 9986 | arranques | 3 |
| 9987 | arrancó | 3 |
| 9988 | árnica | 3 |
| 9989 | armado | 3 |
| 9990 | armaban | 3 |
| 9991 | aritmético | 3 |
| 9992 | aritmética | 3 |
| 9993 | arenal | 3 |
| 9994 | ardientemente | 3 |
| 9995 | ardía | 3 |
| 9996 | arcos | 3 |
| 9997 | arcas | 3 |
| 9998 | apuró | 3 |
| 9999 | apuro | 3 |
| 10000 | apure | 3 |
| 10001 | apunte | 3 |
| 10002 | apuntaba | 3 |
| 10003 | apuestas | 3 |
| 10004 | aprueba | 3 |
| 10005 | aproximó | 3 |
| 10006 | aprovechar | 3 |
| 10007 | aprobó | 3 |
| 10008 | aprobar | 3 |
| 10009 | aprisita | 3 |
| 10010 | aprieta | 3 |
| 10011 | apretones | 3 |
| 10012 | apretadas | 3 |
| 10013 | apretada | 3 |
| 10014 | apresurándose | 3 |
| 10015 | aprendía | 3 |
| 10016 | aprendería | 3 |
| 10017 | apreció | 3 |
| 10018 | apoyado | 3 |
| 10019 | apóstoles | 3 |
| 10020 | aposentos | 3 |
| 10021 | apoderarse | 3 |
| 10022 | apoderaba | 3 |
| 10023 | aplastada | 3 |
| 10024 | aplacar | 3 |
| 10025 | aplacado | 3 |
| 10026 | apetecía | 3 |
| 10027 | apático | 3 |
| 10028 | apasionado | 3 |
| 10029 | aparente | 3 |
| 10030 | aparentando | 3 |
| 10031 | apareciendo | 3 |
| 10032 | aparecían | 3 |
| 10033 | aparece | 3 |
| 10034 | apagaba | 3 |
| 10035 | anuncio | 3 |
| 10036 | anulación | 3 |
| 10037 | antojó | 3 |
| 10038 | antoje | 3 |
| 10039 | antoja | 3 |
| 10040 | anticipar | 3 |
| 10041 | anticipaba | 3 |
| 10042 | antemano | 3 |
| 10043 | antecedentes | 3 |
| 10044 | ansiosa | 3 |
| 10045 | anochecido | 3 |
| 10046 | ánimas | 3 |
| 10047 | animados | 3 |
| 10048 | animada | 3 |
| 10049 | angustiosa | 3 |
| 10050 | angelitos | 3 |
| 10051 | anduvo | 3 |
| 10052 | andrajos | 3 |
| 10053 | ándate | 3 |
| 10054 | andas | 3 |
| 10055 | andalucía | 3 |
| 10056 | andadas | 3 |
| 10057 | amenazó | 3 |
| 10058 | amenazándole | 3 |
| 10059 | amenaza | 3 |
| 10060 | amén | 3 |
| 10061 | ambulantes | 3 |
| 10062 | amasando | 3 |
| 10063 | amarillas | 3 |
| 10064 | amargura | 3 |
| 10065 | amaneramiento | 3 |
| 10066 | amanecer | 3 |
| 10067 | amado | 3 |
| 10068 | alusión | 3 |
| 10069 | alucinación | 3 |
| 10070 | altos | 3 |
| 10071 | alquiler | 3 |
| 10072 | alpiste | 3 |
| 10073 | almorzado | 3 |
| 10074 | almorzaba | 3 |
| 10075 | almendra | 3 |
| 10076 | alimentos | 3 |
| 10077 | alijo | 3 |
| 10078 | alientos | 3 |
| 10079 | algarrobos | 3 |
| 10080 | alfiler | 3 |
| 10081 | aletargaba | 3 |
| 10082 | alejar | 3 |
| 10083 | alejandro | 3 |
| 10084 | alegrarse | 3 |
| 10085 | alegrar | 3 |
| 10086 | alegraban | 3 |
| 10087 | alcanzó | 3 |
| 10088 | alcanza | 3 |
| 10089 | alcantarilla | 3 |
| 10090 | alcances | 3 |
| 10091 | alborote | 3 |
| 10092 | alborotando | 3 |
| 10093 | alborotaban | 3 |
| 10094 | albañil | 3 |
| 10095 | alba | 3 |
| 10096 | alarmante | 3 |
| 10097 | alarmadísima | 3 |
| 10098 | alarma | 3 |
| 10099 | alambique | 3 |
| 10100 | alabado | 3 |
| 10101 | ajustarle | 3 |
| 10102 | ajustado | 3 |
| 10103 | ajustada | 3 |
| 10104 | ajedrez | 3 |
| 10105 | ahumado | 3 |
| 10106 | ahorro | 3 |
| 10107 | ahogar | 3 |
| 10108 | agujereada | 3 |
| 10109 | águila | 3 |
| 10110 | aguardó | 3 |
| 10111 | aguarde | 3 |
| 10112 | aguarda | 3 |
| 10113 | aguanto | 3 |
| 10114 | aguantando | 3 |
| 10115 | aguador | 3 |
| 10116 | agravios | 3 |
| 10117 | agrandaba | 3 |
| 10118 | agradeciendo | 3 |
| 10119 | agradables | 3 |
| 10120 | agradaban | 3 |
| 10121 | agraciados | 3 |
| 10122 | agraciada | 3 |
| 10123 | agotado | 3 |
| 10124 | agitaba | 3 |
| 10125 | agilidad | 3 |
| 10126 | agarró | 3 |
| 10127 | agarrándose | 3 |
| 10128 | agarrada | 3 |
| 10129 | agachó | 3 |
| 10130 | afueras | 3 |
| 10131 | afirmar | 3 |
| 10132 | afirmaciones | 3 |
| 10133 | afectó | 3 |
| 10134 | afanaba | 3 |
| 10135 | advierto | 3 |
| 10136 | adusta | 3 |
| 10137 | adquisición | 3 |
| 10138 | adquirió | 3 |
| 10139 | adquiridos | 3 |
| 10140 | adornada | 3 |
| 10141 | adorado | 3 |
| 10142 | adoquines | 3 |
| 10143 | adoptar | 3 |
| 10144 | adónde | 3 |
| 10145 | admito | 3 |
| 10146 | admirando | 3 |
| 10147 | adivina | 3 |
| 10148 | adelantado | 3 |
| 10149 | adefesios | 3 |
| 10150 | adarme | 3 |
| 10151 | ad | 3 |
| 10152 | acusón | 3 |
| 10153 | acumulando | 3 |
| 10154 | acuestes | 3 |
| 10155 | acuéstate | 3 |
| 10156 | acuérdate | 3 |
| 10157 | acudiendo | 3 |
| 10158 | acudían | 3 |
| 10159 | actual | 3 |
| 10160 | activa | 3 |
| 10161 | acritud | 3 |
| 10162 | acreedores | 3 |
| 10163 | acostose | 3 |
| 10164 | acostarle | 3 |
| 10165 | acostaré | 3 |
| 10166 | acordarás | 3 |
| 10167 | acordara | 3 |
| 10168 | acontecía | 3 |
| 10169 | acontecer | 3 |
| 10170 | aconsejar | 3 |
| 10171 | aconsejaba | 3 |
| 10172 | acompañarla | 3 |
| 10173 | acompañando | 3 |
| 10174 | acompañamiento | 3 |
| 10175 | acompaña | 3 |
| 10176 | acomodaba | 3 |
| 10177 | acierta | 3 |
| 10178 | ácido | 3 |
| 10179 | aciago | 3 |
| 10180 | acertando | 3 |
| 10181 | acercaron | 3 |
| 10182 | acercar | 3 |
| 10183 | acercábase | 3 |
| 10184 | acepto | 3 |
| 10185 | aceptado | 3 |
| 10186 | aceptaba | 3 |
| 10187 | acentuaba | 3 |
| 10188 | aceitunas | 3 |
| 10189 | accionando | 3 |
| 10190 | accesible | 3 |
| 10191 | acariciar | 3 |
| 10192 | acantonamos | 3 |
| 10193 | acaloraba | 3 |
| 10194 | acabose | 3 |
| 10195 | acabase | 3 |
| 10196 | acabando | 3 |
| 10197 | acabados | 3 |
| 10198 | aburrirse | 3 |
| 10199 | abundancia | 3 |
| 10200 | absurdos | 3 |
| 10201 | abstraído | 3 |
| 10202 | absorbedero | 3 |
| 10203 | absolutismo | 3 |
| 10204 | abrumador | 3 |
| 10205 | abriose | 3 |
| 10206 | abrigado | 3 |
| 10207 | abriese | 3 |
| 10208 | abriéndose | 3 |
| 10209 | abreviar | 3 |
| 10210 | abrazando | 3 |
| 10211 | abrasaba | 3 |
| 10212 | abrasa | 3 |
| 10213 | aborrezco | 3 |
| 10214 | aborrecía | 3 |
| 10215 | aborrecer | 3 |
| 10216 | aborrecen | 3 |
| 10217 | abatido | 3 |
| 10218 | abandonará | 3 |
| 10219 | zurrón | 2 |
| 10220 | zurita | 2 |
| 10221 | zurcir | 2 |
| 10222 | zumbido | 2 |
| 10223 | zorro | 2 |
| 10224 | zócalo | 2 |
| 10225 | zipizape | 2 |
| 10226 | zascandil | 2 |
| 10227 | zarzuelas | 2 |
| 10228 | zarandearte | 2 |
| 10229 | zapato | 2 |
| 10230 | zapatilla | 2 |
| 10231 | zángano | 2 |
| 10232 | zambulló | 2 |
| 10233 | zagalona | 2 |
| 10234 | yoduro | 2 |
| 10235 | yio | 2 |
| 10236 | yia | 2 |
| 10237 | yerbas | 2 |
| 10238 | yéndose | 2 |
| 10239 | yemas | 2 |
| 10240 | yacente | 2 |
| 10241 | xvi | 2 |
| 10242 | wagner | 2 |
| 10243 | vulgaridades | 2 |
| 10244 | vuestras | 2 |
| 10245 | vuélvete | 2 |
| 10246 | voraz | 2 |
| 10247 | voracidad | 2 |
| 10248 | vomitar | 2 |
| 10249 | volviste | 2 |
| 10250 | volviéndolo | 2 |
| 10251 | volviéndole | 2 |
| 10252 | volvías | 2 |
| 10253 | volveríamos | 2 |
| 10254 | volveremos | 2 |
| 10255 | volverán | 2 |
| 10256 | volteretas | 2 |
| 10257 | volcados | 2 |
| 10258 | volarse | 2 |
| 10259 | volaron | 2 |
| 10260 | vocerrón | 2 |
| 10261 | vocación | 2 |
| 10262 | vivísimos | 2 |
| 10263 | viviremos | 2 |
| 10264 | viviré | 2 |
| 10265 | vives | 2 |
| 10266 | viveros | 2 |
| 10267 | víveres | 2 |
| 10268 | vivaracha | 2 |
| 10269 | vivacidad | 2 |
| 10270 | vivaaaa | 2 |
| 10271 | viudita | 2 |
| 10272 | viudas | 2 |
| 10273 | vistiéndose | 2 |
| 10274 | vistiéndome | 2 |
| 10275 | visos | 2 |
| 10276 | visitarte | 2 |
| 10277 | visitarla | 2 |
| 10278 | visitaban | 2 |
| 10279 | visera | 2 |
| 10280 | vira | 2 |
| 10281 | viose | 2 |
| 10282 | violentísima | 2 |
| 10283 | viole | 2 |
| 10284 | violado | 2 |
| 10285 | vinos | 2 |
| 10286 | vine | 2 |
| 10287 | vínculos | 2 |
| 10288 | vilo | 2 |
| 10289 | vigorosos | 2 |
| 10290 | vigilarla | 2 |
| 10291 | vigilaban | 2 |
| 10292 | viéronle | 2 |
| 10293 | viena | 2 |
| 10294 | vidrioso | 2 |
| 10295 | vidrios | 2 |
| 10296 | viciosos | 2 |
| 10297 | vicioso | 2 |
| 10298 | viceversa | 2 |
| 10299 | vicente | 2 |
| 10300 | vibraba | 2 |
| 10301 | viajantes | 2 |
| 10302 | viaducto | 2 |
| 10303 | vestigios | 2 |
| 10304 | vértigo | 2 |
| 10305 | versos | 2 |
| 10306 | vernos | 2 |
| 10307 | verídicos | 2 |
| 10308 | verídica | 2 |
| 10309 | veríamos | 2 |
| 10310 | vergonzoso | 2 |
| 10311 | verbigracia | 2 |
| 10312 | veranos | 2 |
| 10313 | ventorro | 2 |
| 10314 | ventilación | 2 |
| 10315 | venimos | 2 |
| 10316 | venida | 2 |
| 10317 | venid | 2 |
| 10318 | venganzas | 2 |
| 10319 | venenos | 2 |
| 10320 | venecia | 2 |
| 10321 | vendrían | 2 |
| 10322 | venderlo | 2 |
| 10323 | venda | 2 |
| 10324 | vellón | 2 |
| 10325 | velarla | 2 |
| 10326 | veintiséis | 2 |
| 10327 | veíais | 2 |
| 10328 | vegetales | 2 |
| 10329 | vega | 2 |
| 10330 | vascular | 2 |
| 10331 | variadísima | 2 |
| 10332 | vano | 2 |
| 10333 | vanidosa | 2 |
| 10334 | valiosas | 2 |
| 10335 | válgame | 2 |
| 10336 | vales | 2 |
| 10337 | valeroso | 2 |
| 10338 | valentías | 2 |
| 10339 | valenciana | 2 |
| 10340 | valemos | 2 |
| 10341 | valdrá | 2 |
| 10342 | vajilla | 2 |
| 10343 | vaguedades | 2 |
| 10344 | vaguedad | 2 |
| 10345 | vagos | 2 |
| 10346 | vagando | 2 |
| 10347 | vacíos | 2 |
| 10348 | vacilado | 2 |
| 10349 | vacante | 2 |
| 10350 | utilidad | 2 |
| 10351 | útiles | 2 |
| 10352 | usura | 2 |
| 10353 | uste | 2 |
| 10354 | usaban | 2 |
| 10355 | usa | 2 |
| 10356 | unir | 2 |
| 10357 | uniéndose | 2 |
| 10358 | uniendo | 2 |
| 10359 | únicos | 2 |
| 10360 | unía | 2 |
| 10361 | undécimo | 2 |
| 10362 | unánimemente | 2 |
| 10363 | ultraje | 2 |
| 10364 | tuyas | 2 |
| 10365 | tuvimos | 2 |
| 10366 | tutelar | 2 |
| 10367 | tuteaban | 2 |
| 10368 | turbarse | 2 |
| 10369 | turbado | 2 |
| 10370 | tupé | 2 |
| 10371 | tumor | 2 |
| 10372 | tul | 2 |
| 10373 | tuerce | 2 |
| 10374 | trun | 2 |
| 10375 | trozos | 2 |
| 10376 | trovador | 2 |
| 10377 | trousseaux | 2 |
| 10378 | trote | 2 |
| 10379 | tropical | 2 |
| 10380 | tropezones | 2 |
| 10381 | tropezar | 2 |
| 10382 | tropezaba | 2 |
| 10383 | tropel | 2 |
| 10384 | troncos | 2 |
| 10385 | trompicones | 2 |
| 10386 | trofeo | 2 |
| 10387 | trocándose | 2 |
| 10388 | trocado | 2 |
| 10389 | trivial | 2 |
| 10390 | triunfales | 2 |
| 10391 | triunfado | 2 |
| 10392 | trinquetada | 2 |
| 10393 | trinos | 2 |
| 10394 | trincó | 2 |
| 10395 | trincando | 2 |
| 10396 | trinando | 2 |
| 10397 | trinaba | 2 |
| 10398 | trimestre | 2 |
| 10399 | triangular | 2 |
| 10400 | tremolina | 2 |
| 10401 | tregua | 2 |
| 10402 | trechos | 2 |
| 10403 | trazada | 2 |
| 10404 | trazaba | 2 |
| 10405 | travesuras | 2 |
| 10406 | traten | 2 |
| 10407 | trate | 2 |
| 10408 | tratarme | 2 |
| 10409 | tratarlo | 2 |
| 10410 | tratarles | 2 |
| 10411 | tratarían | 2 |
| 10412 | trataría | 2 |
| 10413 | trasunto | 2 |
| 10414 | trastorné | 2 |
| 10415 | trastornase | 2 |
| 10416 | trastornar | 2 |
| 10417 | trastornan | 2 |
| 10418 | trasteando | 2 |
| 10419 | trastadas | 2 |
| 10420 | traspasado | 2 |
| 10421 | traspasaba | 2 |
| 10422 | trasluz | 2 |
| 10423 | traseros | 2 |
| 10424 | traqueteo | 2 |
| 10425 | trapicheos | 2 |
| 10426 | transporte | 2 |
| 10427 | transparencias | 2 |
| 10428 | transmitido | 2 |
| 10429 | transformó | 2 |
| 10430 | transformaciones | 2 |
| 10431 | transformaba | 2 |
| 10432 | transfigurado | 2 |
| 10433 | transfigurada | 2 |
| 10434 | transferencia | 2 |
| 10435 | transeúnte | 2 |
| 10436 | tranquilos | 2 |
| 10437 | tranquilas | 2 |
| 10438 | trangullones | 2 |
| 10439 | trancos | 2 |
| 10440 | tramposa | 2 |
| 10441 | trámite | 2 |
| 10442 | trajese | 2 |
| 10443 | trajecitos | 2 |
| 10444 | trajeado | 2 |
| 10445 | tráigame | 2 |
| 10446 | traidora | 2 |
| 10447 | traídas | 2 |
| 10448 | traiciones | 2 |
| 10449 | traicionero | 2 |
| 10450 | traicionera | 2 |
| 10451 | traías | 2 |
| 10452 | tragó | 2 |
| 10453 | trágicas | 2 |
| 10454 | tragaldabas | 2 |
| 10455 | tráfago | 2 |
| 10456 | traerlo | 2 |
| 10457 | traerá | 2 |
| 10458 | traemos | 2 |
| 10459 | tradicionalista | 2 |
| 10460 | trabar | 2 |
| 10461 | trabajillo | 2 |
| 10462 | trabajen | 2 |
| 10463 | trabajaron | 2 |
| 10464 | trabajaré | 2 |
| 10465 | trabajara | 2 |
| 10466 | trabajador | 2 |
| 10467 | trabajaban | 2 |
| 10468 | totalidad | 2 |
| 10469 | toscamente | 2 |
| 10470 | tosa | 2 |
| 10471 | torva | 2 |
| 10472 | tortuosa | 2 |
| 10473 | tórtola | 2 |
| 10474 | tortilla | 2 |
| 10475 | tortas | 2 |
| 10476 | torpemente | 2 |
| 10477 | tornillo | 2 |
| 10478 | torneados | 2 |
| 10479 | tornaron | 2 |
| 10480 | tornaba | 2 |
| 10481 | tormenta | 2 |
| 10482 | toreros | 2 |
| 10483 | torcida | 2 |
| 10484 | torbellino | 2 |
| 10485 | topete | 2 |
| 10486 | tontuela | 2 |
| 10487 | tontito | 2 |
| 10488 | tontamente | 2 |
| 10489 | tontainas | 2 |
| 10490 | tonadilla | 2 |
| 10491 | tomen | 2 |
| 10492 | tómelo | 2 |
| 10493 | tomate | 2 |
| 10494 | tomarlos | 2 |
| 10495 | tómalo | 2 |
| 10496 | tomad | 2 |
| 10497 | toleraría | 2 |
| 10498 | tolerar | 2 |
| 10499 | toledana | 2 |
| 10500 | tole | 2 |
| 10501 | toldo | 2 |
| 10502 | toíto | 2 |
| 10503 | todita | 2 |
| 10504 | tocino | 2 |
| 10505 | tocase | 2 |
| 10506 | tocaron | 2 |
| 10507 | tocará | 2 |
| 10508 | tocándose | 2 |
| 10509 | tocador | 2 |
| 10510 | tizne | 2 |
| 10511 | tiznada | 2 |
| 10512 | titulada | 2 |
| 10513 | tisú | 2 |
| 10514 | tirito | 2 |
| 10515 | tiré | 2 |
| 10516 | tire | 2 |
| 10517 | tirarte | 2 |
| 10518 | tirarlo | 2 |
| 10519 | tiraría | 2 |
| 10520 | tiraré | 2 |
| 10521 | tirantes | 2 |
| 10522 | tiranía | 2 |
| 10523 | tirana | 2 |
| 10524 | tiraban | 2 |
| 10525 | tiqui | 2 |
| 10526 | tinturas | 2 |
| 10527 | tinte | 2 |
| 10528 | tintas | 2 |
| 10529 | tinglado | 2 |
| 10530 | tin | 2 |
| 10531 | tímido | 2 |
| 10532 | timideces | 2 |
| 10533 | tijeretas | 2 |
| 10534 | tijeras | 2 |
| 10535 | tiito | 2 |
| 10536 | tiernos | 2 |
| 10537 | tienta | 2 |
| 10538 | tesoros | 2 |
| 10539 | teruel | 2 |
| 10540 | tertulio | 2 |
| 10541 | terso | 2 |
| 10542 | terrenos | 2 |
| 10543 | terrenal | 2 |
| 10544 | ternuras | 2 |
| 10545 | terno | 2 |
| 10546 | ternero | 2 |
| 10547 | terminó | 2 |
| 10548 | terminar | 2 |
| 10549 | terminantes | 2 |
| 10550 | terminados | 2 |
| 10551 | tercia | 2 |
| 10552 | terca | 2 |
| 10553 | teología | 2 |
| 10554 | teñir | 2 |
| 10555 | teñidas | 2 |
| 10556 | tenuemente | 2 |
| 10557 | tentativa | 2 |
| 10558 | tentando | 2 |
| 10559 | tentación | 2 |
| 10560 | tenlo | 2 |
| 10561 | teníase | 2 |
| 10562 | teníale | 2 |
| 10563 | teníala | 2 |
| 10564 | tenerte | 2 |
| 10565 | tenerme | 2 |
| 10566 | tenerla | 2 |
| 10567 | tendrías | 2 |
| 10568 | tendríamos | 2 |
| 10569 | tendió | 2 |
| 10570 | tendencias | 2 |
| 10571 | tendencia | 2 |
| 10572 | tenacidad | 2 |
| 10573 | tenaces | 2 |
| 10574 | temprana | 2 |
| 10575 | temporales | 2 |
| 10576 | templar | 2 |
| 10577 | templada | 2 |
| 10578 | tempestuoso | 2 |
| 10579 | temperamentos | 2 |
| 10580 | temiera | 2 |
| 10581 | temían | 2 |
| 10582 | temerarios | 2 |
| 10583 | temblorosas | 2 |
| 10584 | telégrafo | 2 |
| 10585 | telarañas | 2 |
| 10586 | tejidos | 2 |
| 10587 | tejido | 2 |
| 10588 | tejares | 2 |
| 10589 | teja | 2 |
| 10590 | tecla | 2 |
| 10591 | techumbre | 2 |
| 10592 | tate | 2 |
| 10593 | tarumba | 2 |
| 10594 | tarro | 2 |
| 10595 | tardando | 2 |
| 10596 | tarascas | 2 |
| 10597 | tapizada | 2 |
| 10598 | tapiz | 2 |
| 10599 | tapaban | 2 |
| 10600 | tantismo | 2 |
| 10601 | tantismas | 2 |
| 10602 | tanda | 2 |
| 10603 | tamañitos | 2 |
| 10604 | tamañita | 2 |
| 10605 | tallado | 2 |
| 10606 | tallada | 2 |
| 10607 | tálamo | 2 |
| 10608 | taimada | 2 |
| 10609 | tácitamente | 2 |
| 10610 | tableado | 2 |
| 10611 | tabacos | 2 |
| 10612 | tabaco | 2 |
| 10613 | susurró | 2 |
| 10614 | sustraerse | 2 |
| 10615 | sustitución | 2 |
| 10616 | sustentada | 2 |
| 10617 | suspirar | 2 |
| 10618 | suspiraba | 2 |
| 10619 | suspensión | 2 |
| 10620 | suspensa | 2 |
| 10621 | suspendió | 2 |
| 10622 | suspendidos | 2 |
| 10623 | suspendía | 2 |
| 10624 | suspender | 2 |
| 10625 | suscrición | 2 |
| 10626 | susceptible | 2 |
| 10627 | susceptibilidad | 2 |
| 10628 | susana | 2 |
| 10629 | surtían | 2 |
| 10630 | surgió | 2 |
| 10631 | surgían | 2 |
| 10632 | surge | 2 |
| 10633 | surcos | 2 |
| 10634 | suprimir | 2 |
| 10635 | supremo | 2 |
| 10636 | supremacía | 2 |
| 10637 | suponerse | 2 |
| 10638 | supone | 2 |
| 10639 | supón | 2 |
| 10640 | supieras | 2 |
| 10641 | supersticioso | 2 |
| 10642 | supersticiosas | 2 |
| 10643 | superchería | 2 |
| 10644 | suministrarle | 2 |
| 10645 | sumergirse | 2 |
| 10646 | sumergido | 2 |
| 10647 | sumergía | 2 |
| 10648 | sulfato | 2 |
| 10649 | sujetas | 2 |
| 10650 | sujetarle | 2 |
| 10651 | sujetarla | 2 |
| 10652 | sujeción | 2 |
| 10653 | suicida | 2 |
| 10654 | sui | 2 |
| 10655 | sugirió | 2 |
| 10656 | sugestivo | 2 |
| 10657 | sufrirá | 2 |
| 10658 | sufrió | 2 |
| 10659 | suficientemente | 2 |
| 10660 | suez | 2 |
| 10661 | suene | 2 |
| 10662 | suéltela | 2 |
| 10663 | sueltan | 2 |
| 10664 | sudores | 2 |
| 10665 | suciedad | 2 |
| 10666 | sucesivo | 2 |
| 10667 | sucesivamente | 2 |
| 10668 | sucedió | 2 |
| 10669 | sucedido | 2 |
| 10670 | suceda | 2 |
| 10671 | subterráneo | 2 |
| 10672 | subterfugios | 2 |
| 10673 | subo | 2 |
| 10674 | sublimemente | 2 |
| 10675 | sublevaban | 2 |
| 10676 | suben | 2 |
| 10677 | subastas | 2 |
| 10678 | suavizando | 2 |
| 10679 | sostienen | 2 |
| 10680 | sostenga | 2 |
| 10681 | sostendrá | 2 |
| 10682 | sospechoso | 2 |
| 10683 | sospechosas | 2 |
| 10684 | sospechará | 2 |
| 10685 | sosón | 2 |
| 10686 | soslayo | 2 |
| 10687 | sortija | 2 |
| 10688 | sorprendía | 2 |
| 10689 | sorprendente | 2 |
| 10690 | sorprende | 2 |
| 10691 | sordos | 2 |
| 10692 | sordera | 2 |
| 10693 | sopicaldo | 2 |
| 10694 | sopera | 2 |
| 10695 | soñador | 2 |
| 10696 | sonsonete | 2 |
| 10697 | sonriente | 2 |
| 10698 | sonreían | 2 |
| 10699 | sonora | 2 |
| 10700 | sonidos | 2 |
| 10701 | sonatas | 2 |
| 10702 | sonando | 2 |
| 10703 | sometido | 2 |
| 10704 | sombrilla | 2 |
| 10705 | sombrías | 2 |
| 10706 | solteros | 2 |
| 10707 | soltarle | 2 |
| 10708 | sollozaba | 2 |
| 10709 | solitarias | 2 |
| 10710 | soliloquio | 2 |
| 10711 | solicitud | 2 |
| 10712 | solemnísimo | 2 |
| 10713 | solemnes | 2 |
| 10714 | solemnemente | 2 |
| 10715 | solares | 2 |
| 10716 | solapa | 2 |
| 10717 | soga | 2 |
| 10718 | sofocó | 2 |
| 10719 | sofocar | 2 |
| 10720 | sofocante | 2 |
| 10721 | sofocados | 2 |
| 10722 | sofocaba | 2 |
| 10723 | socorrida | 2 |
| 10724 | socorrer | 2 |
| 10725 | socialismo | 2 |
| 10726 | socarrona | 2 |
| 10727 | sobrinitos | 2 |
| 10728 | sobrinita | 2 |
| 10729 | sobrinillo | 2 |
| 10730 | sobresaltado | 2 |
| 10731 | sobresalían | 2 |
| 10732 | sobres | 2 |
| 10733 | sobrado | 2 |
| 10734 | sobraba | 2 |
| 10735 | sobones | 2 |
| 10736 | sobón | 2 |
| 10737 | soberanamente | 2 |
| 10738 | soba | 2 |
| 10739 | sito | 2 |
| 10740 | sistemas | 2 |
| 10741 | sirvan | 2 |
| 10742 | sintiose | 2 |
| 10743 | sintéticas | 2 |
| 10744 | siniestro | 2 |
| 10745 | singularísimas | 2 |
| 10746 | singularísima | 2 |
| 10747 | sinceros | 2 |
| 10748 | simpatizaba | 2 |
| 10749 | simpáticas | 2 |
| 10750 | simetría | 2 |
| 10751 | simbolizaba | 2 |
| 10752 | sillero | 2 |
| 10753 | sillería | 2 |
| 10754 | silenciosamente | 2 |
| 10755 | silbaba | 2 |
| 10756 | siguiese | 2 |
| 10757 | significara | 2 |
| 10758 | sigilo | 2 |
| 10759 | sigamos | 2 |
| 10760 | siesta | 2 |
| 10761 | sientas | 2 |
| 10762 | shakespeare | 2 |
| 10763 | sesuda | 2 |
| 10764 | sesada | 2 |
| 10765 | servidos | 2 |
| 10766 | servidor | 2 |
| 10767 | serpentón | 2 |
| 10768 | seretas | 2 |
| 10769 | serafín | 2 |
| 10770 | sepultura | 2 |
| 10771 | sepulcral | 2 |
| 10772 | sépase | 2 |
| 10773 | separas | 2 |
| 10774 | separaron | 2 |
| 10775 | separan | 2 |
| 10776 | separa | 2 |
| 10777 | sepan | 2 |
| 10778 | sepamos | 2 |
| 10779 | sépalo | 2 |
| 10780 | señoronas | 2 |
| 10781 | señoritingo | 2 |
| 10782 | señalar | 2 |
| 10783 | sentirlo | 2 |
| 10784 | sentida | 2 |
| 10785 | sentencias | 2 |
| 10786 | sentencia | 2 |
| 10787 | sentaron | 2 |
| 10788 | sentándola | 2 |
| 10789 | sentando | 2 |
| 10790 | sensatez | 2 |
| 10791 | sensatas | 2 |
| 10792 | semíramis | 2 |
| 10793 | seminario | 2 |
| 10794 | sembrado | 2 |
| 10795 | sellada | 2 |
| 10796 | selectas | 2 |
| 10797 | segundas | 2 |
| 10798 | seguirla | 2 |
| 10799 | seguiré | 2 |
| 10800 | seguimiento | 2 |
| 10801 | seguidita | 2 |
| 10802 | seguidas | 2 |
| 10803 | segovia | 2 |
| 10804 | seductoras | 2 |
| 10805 | seducía | 2 |
| 10806 | seduce | 2 |
| 10807 | seducciones | 2 |
| 10808 | sedas | 2 |
| 10809 | seculares | 2 |
| 10810 | secuestrador | 2 |
| 10811 | secando | 2 |
| 10812 | seáis | 2 |
| 10813 | satisfizo | 2 |
| 10814 | satánico | 2 |
| 10815 | sarcástica | 2 |
| 10816 | saraos | 2 |
| 10817 | saquen | 2 |
| 10818 | santurrona | 2 |
| 10819 | santito | 2 |
| 10820 | santificación | 2 |
| 10821 | santiago | 2 |
| 10822 | santamente | 2 |
| 10823 | sanó | 2 |
| 10824 | sanidad | 2 |
| 10825 | samaritanas | 2 |
| 10826 | salvarnos | 2 |
| 10827 | salvan | 2 |
| 10828 | salvajismo | 2 |
| 10829 | saludos | 2 |
| 10830 | salude | 2 |
| 10831 | saludaron | 2 |
| 10832 | saludarla | 2 |
| 10833 | saludable | 2 |
| 10834 | saludaban | 2 |
| 10835 | salteados | 2 |
| 10836 | salte | 2 |
| 10837 | salones | 2 |
| 10838 | salmón | 2 |
| 10839 | salitas | 2 |
| 10840 | saliéndole | 2 |
| 10841 | salíamos | 2 |
| 10842 | salgan | 2 |
| 10843 | salero | 2 |
| 10844 | saldré | 2 |
| 10845 | saldrás | 2 |
| 10846 | salada | 2 |
| 10847 | saint | 2 |
| 10848 | sahumaremos | 2 |
| 10849 | sagasta | 2 |
| 10850 | saeta | 2 |
| 10851 | sacudir | 2 |
| 10852 | sacudiéndose | 2 |
| 10853 | sacudidas | 2 |
| 10854 | sacudían | 2 |
| 10855 | sacrílega | 2 |
| 10856 | sacrificada | 2 |
| 10857 | sacrifica | 2 |
| 10858 | sacramentado | 2 |
| 10859 | sacola | 2 |
| 10860 | sacerdotes | 2 |
| 10861 | sacerdocio | 2 |
| 10862 | sacaste | 2 |
| 10863 | sacase | 2 |
| 10864 | sacarme | 2 |
| 10865 | sacarlos | 2 |
| 10866 | sacarían | 2 |
| 10867 | sacaré | 2 |
| 10868 | sacaran | 2 |
| 10869 | sacándola | 2 |
| 10870 | sácalo | 2 |
| 10871 | sacaban | 2 |
| 10872 | sacábale | 2 |
| 10873 | sabrosísimo | 2 |
| 10874 | sabrás | 2 |
| 10875 | saborear | 2 |
| 10876 | saboreando | 2 |
| 10877 | sabías | 2 |
| 10878 | saberse | 2 |
| 10879 | rutinarias | 2 |
| 10880 | ruptura | 2 |
| 10881 | rumorcillo | 2 |
| 10882 | rum | 2 |
| 10883 | ruidosas | 2 |
| 10884 | rugido | 2 |
| 10885 | rufina | 2 |
| 10886 | rudos | 2 |
| 10887 | rudas | 2 |
| 10888 | rúbricas | 2 |
| 10889 | rubia | 2 |
| 10890 | royan | 2 |
| 10891 | rostros | 2 |
| 10892 | rosarios | 2 |
| 10893 | rorró | 2 |
| 10894 | roñoso | 2 |
| 10895 | rondón | 2 |
| 10896 | rondando | 2 |
| 10897 | rompieron | 2 |
| 10898 | rompían | 2 |
| 10899 | rompen | 2 |
| 10900 | rompa | 2 |
| 10901 | romano | 2 |
| 10902 | rodrigo | 2 |
| 10903 | rodilleras | 2 |
| 10904 | rodeado | 2 |
| 10905 | rodeadas | 2 |
| 10906 | rodaba | 2 |
| 10907 | roca | 2 |
| 10908 | robustos | 2 |
| 10909 | roble | 2 |
| 10910 | robarle | 2 |
| 10911 | robándome | 2 |
| 10912 | ro | 2 |
| 10913 | rizado | 2 |
| 10914 | rivero | 2 |
| 10915 | ritmo | 2 |
| 10916 | risueños | 2 |
| 10917 | risita | 2 |
| 10918 | risilla | 2 |
| 10919 | riquísimas | 2 |
| 10920 | riñones | 2 |
| 10921 | riñonadas | 2 |
| 10922 | rigurosa | 2 |
| 10923 | rigores | 2 |
| 10924 | rígido | 2 |
| 10925 | rígida | 2 |
| 10926 | rifa | 2 |
| 10927 | rienda | 2 |
| 10928 | ríen | 2 |
| 10929 | ridiculizar | 2 |
| 10930 | riales | 2 |
| 10931 | rezongando | 2 |
| 10932 | rezonas | 2 |
| 10933 | rezó | 2 |
| 10934 | rezaré | 2 |
| 10935 | reyertas | 2 |
| 10936 | reyerta | 2 |
| 10937 | revuelven | 2 |
| 10938 | revolverse | 2 |
| 10939 | revoltijo | 2 |
| 10940 | revoco | 2 |
| 10941 | revivir | 2 |
| 10942 | revivió | 2 |
| 10943 | revisó | 2 |
| 10944 | revisando | 2 |
| 10945 | reviente | 2 |
| 10946 | revestía | 2 |
| 10947 | reventara | 2 |
| 10948 | reventado | 2 |
| 10949 | revelando | 2 |
| 10950 | revela | 2 |
| 10951 | reunirse | 2 |
| 10952 | retumbar | 2 |
| 10953 | retrospectivos | 2 |
| 10954 | retroceder | 2 |
| 10955 | retratado | 2 |
| 10956 | retozona | 2 |
| 10957 | retozar | 2 |
| 10958 | retozaba | 2 |
| 10959 | retóricas | 2 |
| 10960 | retorciéndose | 2 |
| 10961 | retorcer | 2 |
| 10962 | retírate | 2 |
| 10963 | retirarme | 2 |
| 10964 | retiraría | 2 |
| 10965 | retiraré | 2 |
| 10966 | retirara | 2 |
| 10967 | retiran | 2 |
| 10968 | retira | 2 |
| 10969 | retener | 2 |
| 10970 | retahíla | 2 |
| 10971 | resulte | 2 |
| 10972 | resultas | 2 |
| 10973 | resultaría | 2 |
| 10974 | resultaban | 2 |
| 10975 | resuelve | 2 |
| 10976 | resuelta | 2 |
| 10977 | restregándose | 2 |
| 10978 | restallido | 2 |
| 10979 | respondiéndose | 2 |
| 10980 | respondiendo | 2 |
| 10981 | respondido | 2 |
| 10982 | respondí | 2 |
| 10983 | responderme | 2 |
| 10984 | respóndeme | 2 |
| 10985 | responde | 2 |
| 10986 | resplandeciente | 2 |
| 10987 | respiros | 2 |
| 10988 | respiro | 2 |
| 10989 | respira | 2 |
| 10990 | respeten | 2 |
| 10991 | respetables | 2 |
| 10992 | resonó | 2 |
| 10993 | resolviose | 2 |
| 10994 | resolvieron | 2 |
| 10995 | resolver | 2 |
| 10996 | resignarse | 2 |
| 10997 | residentes | 2 |
| 10998 | residencia | 2 |
| 10999 | resguardándose | 2 |
| 11000 | reservar | 2 |
| 11001 | reservándose | 2 |
| 11002 | reservados | 2 |
| 11003 | reservaba | 2 |
| 11004 | resbalando | 2 |
| 11005 | resabios | 2 |
| 11006 | requetefinos | 2 |
| 11007 | requemada | 2 |
| 11008 | requemaba | 2 |
| 11009 | reputado | 2 |
| 11010 | repugnantes | 2 |
| 11011 | repugnaban | 2 |
| 11012 | repugna | 2 |
| 11013 | repuesto | 2 |
| 11014 | republicano | 2 |
| 11015 | reprodujo | 2 |
| 11016 | reproducían | 2 |
| 11017 | representó | 2 |
| 11018 | representante | 2 |
| 11019 | representándose | 2 |
| 11020 | reposadas | 2 |
| 11021 | repoblicanos | 2 |
| 11022 | réplica | 2 |
| 11023 | repleto | 2 |
| 11024 | repite | 2 |
| 11025 | repicar | 2 |
| 11026 | repetirlo | 2 |
| 11027 | repetida | 2 |
| 11028 | repelones | 2 |
| 11029 | repecho | 2 |
| 11030 | reparten | 2 |
| 11031 | reparos | 2 |
| 11032 | reparan | 2 |
| 11033 | reparadora | 2 |
| 11034 | reparaciones | 2 |
| 11035 | reos | 2 |
| 11036 | reñirle | 2 |
| 11037 | reñiría | 2 |
| 11038 | reñido | 2 |
| 11039 | reñida | 2 |
| 11040 | reñía | 2 |
| 11041 | renunció | 2 |
| 11042 | renqueando | 2 |
| 11043 | renovando | 2 |
| 11044 | renovados | 2 |
| 11045 | renovado | 2 |
| 11046 | reniegue | 2 |
| 11047 | rendirse | 2 |
| 11048 | rendidas | 2 |
| 11049 | remontarse | 2 |
| 11050 | remesas | 2 |
| 11051 | remedándole | 2 |
| 11052 | rematado | 2 |
| 11053 | relumbraban | 2 |
| 11054 | religiosidad | 2 |
| 11055 | relatores | 2 |
| 11056 | relacionarse | 2 |
| 11057 | relacionados | 2 |
| 11058 | rejas | 2 |
| 11059 | reírnos | 2 |
| 11060 | reirá | 2 |
| 11061 | reintegro | 2 |
| 11062 | reinaban | 2 |
| 11063 | rehusó | 2 |
| 11064 | rehuía | 2 |
| 11065 | regurgitación | 2 |
| 11066 | reguapo | 2 |
| 11067 | regresaría | 2 |
| 11068 | regresaban | 2 |
| 11069 | regocijaba | 2 |
| 11070 | registros | 2 |
| 11071 | registrando | 2 |
| 11072 | registra | 2 |
| 11073 | regio | 2 |
| 11074 | regimiento | 2 |
| 11075 | régimen | 2 |
| 11076 | regeneración | 2 |
| 11077 | regazo | 2 |
| 11078 | regañón | 2 |
| 11079 | regalito | 2 |
| 11080 | regalar | 2 |
| 11081 | refunfuñó | 2 |
| 11082 | refugiose | 2 |
| 11083 | refrescarle | 2 |
| 11084 | refregándose | 2 |
| 11085 | reflexionó | 2 |
| 11086 | reflexionar | 2 |
| 11087 | reflexiona | 2 |
| 11088 | reflejos | 2 |
| 11089 | reflejo | 2 |
| 11090 | refistolera | 2 |
| 11091 | refiriéndole | 2 |
| 11092 | refiriendo | 2 |
| 11093 | referidos | 2 |
| 11094 | refajos | 2 |
| 11095 | reducirla | 2 |
| 11096 | reduciendo | 2 |
| 11097 | reducía | 2 |
| 11098 | reduce | 2 |
| 11099 | redobló | 2 |
| 11100 | redimido | 2 |
| 11101 | redimía | 2 |
| 11102 | redentora | 2 |
| 11103 | recuerdan | 2 |
| 11104 | recuerda | 2 |
| 11105 | rectificar | 2 |
| 11106 | rectifica | 2 |
| 11107 | rectas | 2 |
| 11108 | recortarlo | 2 |
| 11109 | recortados | 2 |
| 11110 | recorrido | 2 |
| 11111 | recorre | 2 |
| 11112 | recordarlo | 2 |
| 11113 | reconocerse | 2 |
| 11114 | reconocerla | 2 |
| 11115 | reconocería | 2 |
| 11116 | reconoce | 2 |
| 11117 | recóndito | 2 |
| 11118 | recónditas | 2 |
| 11119 | reconciliarse | 2 |
| 11120 | reconcentrar | 2 |
| 11121 | recomendar | 2 |
| 11122 | recogiéndose | 2 |
| 11123 | recogía | 2 |
| 11124 | recogí | 2 |
| 11125 | recógete | 2 |
| 11126 | recogen | 2 |
| 11127 | reclusión | 2 |
| 11128 | reclinar | 2 |
| 11129 | reclamar | 2 |
| 11130 | reclamación | 2 |
| 11131 | recientemente | 2 |
| 11132 | recibirlos | 2 |
| 11133 | recibirla | 2 |
| 11134 | recibes | 2 |
| 11135 | reciben | 2 |
| 11136 | reciba | 2 |
| 11137 | rechinar | 2 |
| 11138 | recetaba | 2 |
| 11139 | receptividad | 2 |
| 11140 | recepción | 2 |
| 11141 | receloso | 2 |
| 11142 | recela | 2 |
| 11143 | recataba | 2 |
| 11144 | recaer | 2 |
| 11145 | rebosar | 2 |
| 11146 | rebeldes | 2 |
| 11147 | rebajarme | 2 |
| 11148 | reanudó | 2 |
| 11149 | realizó | 2 |
| 11150 | realizarse | 2 |
| 11151 | realizarlo | 2 |
| 11152 | realizando | 2 |
| 11153 | realidades | 2 |
| 11154 | razonar | 2 |
| 11155 | razonaba | 2 |
| 11156 | rayaban | 2 |
| 11157 | ratones | 2 |
| 11158 | ratero | 2 |
| 11159 | ratas | 2 |
| 11160 | rastras | 2 |
| 11161 | rasguños | 2 |
| 11162 | rascó | 2 |
| 11163 | rasa | 2 |
| 11164 | rarísima | 2 |
| 11165 | rareza | 2 |
| 11166 | raquítico | 2 |
| 11167 | raquítica | 2 |
| 11168 | rápidas | 2 |
| 11169 | rapaza | 2 |
| 11170 | rapaz | 2 |
| 11171 | rancio | 2 |
| 11172 | rameado | 2 |
| 11173 | raigones | 2 |
| 11174 | racional | 2 |
| 11175 | racimos | 2 |
| 11176 | rabietina | 2 |
| 11177 | rabien | 2 |
| 11178 | rabie | 2 |
| 11179 | rábano | 2 |
| 11180 | rabadilla | 2 |
| 11181 | ra | 2 |
| 11182 | quitaste | 2 |
| 11183 | quitarvos | 2 |
| 11184 | quitarte | 2 |
| 11185 | quitársela | 2 |
| 11186 | quitarles | 2 |
| 11187 | quítame | 2 |
| 11188 | quisiéramos | 2 |
| 11189 | quintales | 2 |
| 11190 | quincena | 2 |
| 11191 | química | 2 |
| 11192 | quimeras | 2 |
| 11193 | quiéreme | 2 |
| 11194 | quiénes | 2 |
| 11195 | quiebro | 2 |
| 11196 | quevedos | 2 |
| 11197 | quesos | 2 |
| 11198 | querindango | 2 |
| 11199 | queridas | 2 |
| 11200 | quererte | 2 |
| 11201 | queráis | 2 |
| 11202 | quemó | 2 |
| 11203 | quemo | 2 |
| 11204 | quemas | 2 |
| 11205 | quemarse | 2 |
| 11206 | quemar | 2 |
| 11207 | quemado | 2 |
| 11208 | quemaba | 2 |
| 11209 | quema | 2 |
| 11210 | quejó | 2 |
| 11211 | quejidos | 2 |
| 11212 | quejido | 2 |
| 11213 | quejarte | 2 |
| 11214 | quedito | 2 |
| 11215 | quedes | 2 |
| 11216 | queden | 2 |
| 11217 | quedáronse | 2 |
| 11218 | quedaremos | 2 |
| 11219 | quedamente | 2 |
| 11220 | quebrantan | 2 |
| 11221 | quebraderos | 2 |
| 11222 | pusiste | 2 |
| 11223 | pusieras | 2 |
| 11224 | purificarse | 2 |
| 11225 | purgatorio | 2 |
| 11226 | pur | 2 |
| 11227 | pupila | 2 |
| 11228 | puñetazo | 2 |
| 11229 | puñaladas | 2 |
| 11230 | puntería | 2 |
| 11231 | puntera | 2 |
| 11232 | puntapié | 2 |
| 11233 | puntal | 2 |
| 11234 | puntadita | 2 |
| 11235 | pulpitillo | 2 |
| 11236 | pulga | 2 |
| 11237 | puéstose | 2 |
| 11238 | puerto | 2 |
| 11239 | pué | 2 |
| 11240 | pue | 2 |
| 11241 | pudiente | 2 |
| 11242 | publicidad | 2 |
| 11243 | pruritos | 2 |
| 11244 | pruebes | 2 |
| 11245 | prueben | 2 |
| 11246 | pruebe | 2 |
| 11247 | proyectil | 2 |
| 11248 | proyectada | 2 |
| 11249 | próximamente | 2 |
| 11250 | provocar | 2 |
| 11251 | provocado | 2 |
| 11252 | provista | 2 |
| 11253 | provisional | 2 |
| 11254 | provisión | 2 |
| 11255 | proveerse | 2 |
| 11256 | protestar | 2 |
| 11257 | protestanta | 2 |
| 11258 | protegiendo | 2 |
| 11259 | protegían | 2 |
| 11260 | prostitución | 2 |
| 11261 | prospectos | 2 |
| 11262 | prorrumpiendo | 2 |
| 11263 | prórroga | 2 |
| 11264 | propuesta | 2 |
| 11265 | proporción | 2 |
| 11266 | proponían | 2 |
| 11267 | proponga | 2 |
| 11268 | propietaria | 2 |
| 11269 | pronunciado | 2 |
| 11270 | prometía | 2 |
| 11271 | prometí | 2 |
| 11272 | prométame | 2 |
| 11273 | prolongación | 2 |
| 11274 | prohibirle | 2 |
| 11275 | prohibiendo | 2 |
| 11276 | prohibido | 2 |
| 11277 | profundas | 2 |
| 11278 | profetizando | 2 |
| 11279 | profético | 2 |
| 11280 | profesores | 2 |
| 11281 | profeso | 2 |
| 11282 | profesado | 2 |
| 11283 | profesaba | 2 |
| 11284 | profecías | 2 |
| 11285 | profecía | 2 |
| 11286 | profanaciones | 2 |
| 11287 | producirse | 2 |
| 11288 | producida | 2 |
| 11289 | procures | 2 |
| 11290 | procurarse | 2 |
| 11291 | procedimiento | 2 |
| 11292 | procedían | 2 |
| 11293 | procederes | 2 |
| 11294 | probarme | 2 |
| 11295 | probara | 2 |
| 11296 | probada | 2 |
| 11297 | probables | 2 |
| 11298 | probaba | 2 |
| 11299 | privados | 2 |
| 11300 | privación | 2 |
| 11301 | pringue | 2 |
| 11302 | principian | 2 |
| 11303 | principiaba | 2 |
| 11304 | princesa | 2 |
| 11305 | primitivas | 2 |
| 11306 | previsor | 2 |
| 11307 | previo | 2 |
| 11308 | prevenir | 2 |
| 11309 | prevaleció | 2 |
| 11310 | pretendientes | 2 |
| 11311 | pretendiente | 2 |
| 11312 | pretender | 2 |
| 11313 | pretende | 2 |
| 11314 | presumiendo | 2 |
| 11315 | presto | 2 |
| 11316 | preste | 2 |
| 11317 | prestase | 2 |
| 11318 | prestada | 2 |
| 11319 | presión | 2 |
| 11320 | presidente | 2 |
| 11321 | presentando | 2 |
| 11322 | presentable | 2 |
| 11323 | presentábase | 2 |
| 11324 | presentaban | 2 |
| 11325 | presenciar | 2 |
| 11326 | presagio | 2 |
| 11327 | prepárese | 2 |
| 11328 | prepare | 2 |
| 11329 | prepárate | 2 |
| 11330 | preparación | 2 |
| 11331 | prepara | 2 |
| 11332 | preocupaba | 2 |
| 11333 | prendida | 2 |
| 11334 | prendado | 2 |
| 11335 | premeditación | 2 |
| 11336 | prehistórica | 2 |
| 11337 | preguntole | 2 |
| 11338 | preguntes | 2 |
| 11339 | pregunte | 2 |
| 11340 | preguntarles | 2 |
| 11341 | preguntara | 2 |
| 11342 | pregón | 2 |
| 11343 | prefieres | 2 |
| 11344 | preferiré | 2 |
| 11345 | preferido | 2 |
| 11346 | predominio | 2 |
| 11347 | precursor | 2 |
| 11348 | precoces | 2 |
| 11349 | precisado | 2 |
| 11350 | precisa | 2 |
| 11351 | precipitemos | 2 |
| 11352 | precipitaste | 2 |
| 11353 | precipitación | 2 |
| 11354 | preciosidades | 2 |
| 11355 | preciados | 2 |
| 11356 | precedido | 2 |
| 11357 | precedidas | 2 |
| 11358 | precedida | 2 |
| 11359 | precaución | 2 |
| 11360 | praga | 2 |
| 11361 | practicar | 2 |
| 11362 | potro | 2 |
| 11363 | potencia | 2 |
| 11364 | potaje | 2 |
| 11365 | posturas | 2 |
| 11366 | postizo | 2 |
| 11367 | posterior | 2 |
| 11368 | positivos | 2 |
| 11369 | posesionarse | 2 |
| 11370 | poseedores | 2 |
| 11371 | posarse | 2 |
| 11372 | posados | 2 |
| 11373 | posado | 2 |
| 11374 | pórtico | 2 |
| 11375 | portaré | 2 |
| 11376 | portar | 2 |
| 11377 | portante | 2 |
| 11378 | portando | 2 |
| 11379 | portaba | 2 |
| 11380 | porcelana | 2 |
| 11381 | poniéndome | 2 |
| 11382 | poniéndolos | 2 |
| 11383 | poniéndoles | 2 |
| 11384 | poníale | 2 |
| 11385 | ponferrada | 2 |
| 11386 | ponérsele | 2 |
| 11387 | ponerlos | 2 |
| 11388 | ponemos | 2 |
| 11389 | pompas | 2 |
| 11390 | pompadour | 2 |
| 11391 | polvoriento | 2 |
| 11392 | polluelo | 2 |
| 11393 | pollería | 2 |
| 11394 | políticas | 2 |
| 11395 | polisones | 2 |
| 11396 | policías | 2 |
| 11397 | polémica | 2 |
| 11398 | podridos | 2 |
| 11399 | podrida | 2 |
| 11400 | podrías | 2 |
| 11401 | poderosas | 2 |
| 11402 | poderlas | 2 |
| 11403 | poderla | 2 |
| 11404 | poderes | 2 |
| 11405 | pobretín | 2 |
| 11406 | pobretería | 2 |
| 11407 | pluralidad | 2 |
| 11408 | plumaje | 2 |
| 11409 | plum | 2 |
| 11410 | plin | 2 |
| 11411 | plieguecitos | 2 |
| 11412 | pleno | 2 |
| 11413 | plegando | 2 |
| 11414 | plebeyo | 2 |
| 11415 | plebe | 2 |
| 11416 | plazos | 2 |
| 11417 | plazoleta | 2 |
| 11418 | plazas | 2 |
| 11419 | playa | 2 |
| 11420 | platito | 2 |
| 11421 | pláticas | 2 |
| 11422 | platicar | 2 |
| 11423 | plática | 2 |
| 11424 | plasencia | 2 |
| 11425 | plañidero | 2 |
| 11426 | plantose | 2 |
| 11427 | planteando | 2 |
| 11428 | planté | 2 |
| 11429 | plantarse | 2 |
| 11430 | plantarle | 2 |
| 11431 | plantar | 2 |
| 11432 | plancheta | 2 |
| 11433 | planchando | 2 |
| 11434 | planas | 2 |
| 11435 | plam | 2 |
| 11436 | placeres | 2 |
| 11437 | placentera | 2 |
| 11438 | pla | 2 |
| 11439 | pivote | 2 |
| 11440 | pitando | 2 |
| 11441 | pistoletazo | 2 |
| 11442 | pisotones | 2 |
| 11443 | pisoteando | 2 |
| 11444 | pirran | 2 |
| 11445 | pirraba | 2 |
| 11446 | pirámides | 2 |
| 11447 | pirámide | 2 |
| 11448 | piores | 2 |
| 11449 | piñón | 2 |
| 11450 | pinturera | 2 |
| 11451 | pintoresca | 2 |
| 11452 | pintó | 2 |
| 11453 | pinté | 2 |
| 11454 | pintas | 2 |
| 11455 | pintándole | 2 |
| 11456 | pintando | 2 |
| 11457 | pingos | 2 |
| 11458 | pingo | 2 |
| 11459 | pindongona | 2 |
| 11460 | pinchazos | 2 |
| 11461 | pinchas | 2 |
| 11462 | pincha | 2 |
| 11463 | pilletes | 2 |
| 11464 | pildoritas | 2 |
| 11465 | pilar | 2 |
| 11466 | pif | 2 |
| 11467 | piececita | 2 |
| 11468 | pidiole | 2 |
| 11469 | picarescos | 2 |
| 11470 | pezón | 2 |
| 11471 | petrolero | 2 |
| 11472 | petra | 2 |
| 11473 | petaca | 2 |
| 11474 | pesos | 2 |
| 11475 | pesimistas | 2 |
| 11476 | pescó | 2 |
| 11477 | pescas | 2 |
| 11478 | pescados | 2 |
| 11479 | pescador | 2 |
| 11480 | pescadero | 2 |
| 11481 | pesas | 2 |
| 11482 | pesares | 2 |
| 11483 | pesando | 2 |
| 11484 | pesadez | 2 |
| 11485 | pesadamente | 2 |
| 11486 | perversión | 2 |
| 11487 | perversa | 2 |
| 11488 | pertinentes | 2 |
| 11489 | pertenecido | 2 |
| 11490 | persuasiva | 2 |
| 11491 | personalmente | 2 |
| 11492 | persiguiendo | 2 |
| 11493 | persignándose | 2 |
| 11494 | persignaba | 2 |
| 11495 | perseverancia | 2 |
| 11496 | perseguir | 2 |
| 11497 | perseguía | 2 |
| 11498 | persecuciones | 2 |
| 11499 | persa | 2 |
| 11500 | perrillo | 2 |
| 11501 | perradas | 2 |
| 11502 | perpetua | 2 |
| 11503 | perorata | 2 |
| 11504 | peroles | 2 |
| 11505 | permitirle | 2 |
| 11506 | permaneciendo | 2 |
| 11507 | periodista | 2 |
| 11508 | periodismo | 2 |
| 11509 | periódicamente | 2 |
| 11510 | perilla | 2 |
| 11511 | peri | 2 |
| 11512 | perfectos | 2 |
| 11513 | perezoso | 2 |
| 11514 | perezosa | 2 |
| 11515 | pereza | 2 |
| 11516 | perdurable | 2 |
| 11517 | perdularios | 2 |
| 11518 | perdonarla | 2 |
| 11519 | perdonará | 2 |
| 11520 | perdóname | 2 |
| 11521 | perdiste | 2 |
| 11522 | perderlo | 2 |
| 11523 | perderle | 2 |
| 11524 | percibía | 2 |
| 11525 | percales | 2 |
| 11526 | pequeñito | 2 |
| 11527 | pequeñez | 2 |
| 11528 | pepitas | 2 |
| 11529 | pepes | 2 |
| 11530 | peorcito | 2 |
| 11531 | peón | 2 |
| 11532 | penumbra | 2 |
| 11533 | pensaron | 2 |
| 11534 | pensándolo | 2 |
| 11535 | pensada | 2 |
| 11536 | pensaban | 2 |
| 11537 | penosos | 2 |
| 11538 | penitencias | 2 |
| 11539 | peniques | 2 |
| 11540 | península | 2 |
| 11541 | penetraron | 2 |
| 11542 | penetrando | 2 |
| 11543 | peneque | 2 |
| 11544 | pelotera | 2 |
| 11545 | pelotazo | 2 |
| 11546 | pelmazos | 2 |
| 11547 | pella | 2 |
| 11548 | pelitos | 2 |
| 11549 | pelito | 2 |
| 11550 | peletería | 2 |
| 11551 | pelear | 2 |
| 11552 | pelayo | 2 |
| 11553 | pelaban | 2 |
| 11554 | pela | 2 |
| 11555 | peineta | 2 |
| 11556 | peinándose | 2 |
| 11557 | peinadoras | 2 |
| 11558 | peinadora | 2 |
| 11559 | peinada | 2 |
| 11560 | peinaba | 2 |
| 11561 | pegué | 2 |
| 11562 | pegotes | 2 |
| 11563 | pegaron | 2 |
| 11564 | pegadas | 2 |
| 11565 | pedirte | 2 |
| 11566 | pedirme | 2 |
| 11567 | pedirles | 2 |
| 11568 | pediremos | 2 |
| 11569 | pedimos | 2 |
| 11570 | pedí | 2 |
| 11571 | pedantería | 2 |
| 11572 | pechera | 2 |
| 11573 | pecas | 2 |
| 11574 | pecadillos | 2 |
| 11575 | payo | 2 |
| 11576 | pavorosa | 2 |
| 11577 | pavor | 2 |
| 11578 | paveros | 2 |
| 11579 | pava | 2 |
| 11580 | paul | 2 |
| 11581 | patrones | 2 |
| 11582 | patriarcal | 2 |
| 11583 | patitas | 2 |
| 11584 | paternales | 2 |
| 11585 | patente | 2 |
| 11586 | pateando | 2 |
| 11587 | patatín | 2 |
| 11588 | patatán | 2 |
| 11589 | pataleta | 2 |
| 11590 | pataleos | 2 |
| 11591 | pataleando | 2 |
| 11592 | pataditas | 2 |
| 11593 | patá | 2 |
| 11594 | pastores | 2 |
| 11595 | pastora | 2 |
| 11596 | pasto | 2 |
| 11597 | pastilla | 2 |
| 11598 | pasteles | 2 |
| 11599 | pastelero | 2 |
| 11600 | pastelería | 2 |
| 11601 | pasteleras | 2 |
| 11602 | pastas | 2 |
| 11603 | pasmosas | 2 |
| 11604 | pasmó | 2 |
| 11605 | pásmense | 2 |
| 11606 | pasmarote | 2 |
| 11607 | pasmaban | 2 |
| 11608 | pases | 2 |
| 11609 | pasemos | 2 |
| 11610 | pasee | 2 |
| 11611 | pasearon | 2 |
| 11612 | pasean | 2 |
| 11613 | paseamos | 2 |
| 11614 | pasasen | 2 |
| 11615 | pasarlo | 2 |
| 11616 | pasarle | 2 |
| 11617 | pasarían | 2 |
| 11618 | pasaré | 2 |
| 11619 | pasándose | 2 |
| 11620 | pasamos | 2 |
| 11621 | pasamanos | 2 |
| 11622 | pasajeros | 2 |
| 11623 | pasajera | 2 |
| 11624 | parto | 2 |
| 11625 | partiendo | 2 |
| 11626 | partidos | 2 |
| 11627 | partidas | 2 |
| 11628 | particularidad | 2 |
| 11629 | participando | 2 |
| 11630 | partían | 2 |
| 11631 | parson | 2 |
| 11632 | parroquianas | 2 |
| 11633 | parrilla | 2 |
| 11634 | parque | 2 |
| 11635 | parlamento | 2 |
| 11636 | parisiense | 2 |
| 11637 | parió | 2 |
| 11638 | parezco | 2 |
| 11639 | párese | 2 |
| 11640 | pareciéndose | 2 |
| 11641 | parecidas | 2 |
| 11642 | parecíame | 2 |
| 11643 | paré | 2 |
| 11644 | pardas | 2 |
| 11645 | parda | 2 |
| 11646 | pararrayos | 2 |
| 11647 | paradójico | 2 |
| 11648 | paradojas | 2 |
| 11649 | paradero | 2 |
| 11650 | paradas | 2 |
| 11651 | parabienes | 2 |
| 11652 | papelista | 2 |
| 11653 | paparrucha | 2 |
| 11654 | pañosa | 2 |
| 11655 | pañolón | 2 |
| 11656 | pañolito | 2 |
| 11657 | pañería | 2 |
| 11658 | panza | 2 |
| 11659 | panorama | 2 |
| 11660 | panfilona | 2 |
| 11661 | panes | 2 |
| 11662 | panderetazos | 2 |
| 11663 | pamema | 2 |
| 11664 | palpitaciones | 2 |
| 11665 | palpitación | 2 |
| 11666 | palpitaba | 2 |
| 11667 | palmotear | 2 |
| 11668 | palmitas | 2 |
| 11669 | palmetazos | 2 |
| 11670 | palmetazo | 2 |
| 11671 | palmatoria | 2 |
| 11672 | palitos | 2 |
| 11673 | palio | 2 |
| 11674 | palillos | 2 |
| 11675 | pálidas | 2 |
| 11676 | paletos | 2 |
| 11677 | paletada | 2 |
| 11678 | paleta | 2 |
| 11679 | paladar | 2 |
| 11680 | palacios | 2 |
| 11681 | palabrería | 2 |
| 11682 | pajeles | 2 |
| 11683 | pajaritas | 2 |
| 11684 | pajarillos | 2 |
| 11685 | pajarete | 2 |
| 11686 | países | 2 |
| 11687 | paisano | 2 |
| 11688 | paicía | 2 |
| 11689 | páginas | 2 |
| 11690 | pagarla | 2 |
| 11691 | pagarás | 2 |
| 11692 | pagan | 2 |
| 11693 | padillita | 2 |
| 11694 | pacíficos | 2 |
| 11695 | paciente | 2 |
| 11696 | oyese | 2 |
| 11697 | oyéronse | 2 |
| 11698 | oyeran | 2 |
| 11699 | oyentes | 2 |
| 11700 | oveja | 2 |
| 11701 | osuna | 2 |
| 11702 | ostras | 2 |
| 11703 | ostentaba | 2 |
| 11704 | oscurece | 2 |
| 11705 | osadía | 2 |
| 11706 | ortografía | 2 |
| 11707 | ortiz | 2 |
| 11708 | oriundo | 2 |
| 11709 | originalidad | 2 |
| 11710 | orgulloso | 2 |
| 11711 | orgullosas | 2 |
| 11712 | orgías | 2 |
| 11713 | organismo | 2 |
| 11714 | orfila | 2 |
| 11715 | ordinariamente | 2 |
| 11716 | ordenar | 2 |
| 11717 | ordenanzas | 2 |
| 11718 | ordenan | 2 |
| 11719 | ordenado | 2 |
| 11720 | ordena | 2 |
| 11721 | oratorias | 2 |
| 11722 | orán | 2 |
| 11723 | opulentos | 2 |
| 11724 | opulenta | 2 |
| 11725 | optimistas | 2 |
| 11726 | optimismo | 2 |
| 11727 | oprimido | 2 |
| 11728 | oposición | 2 |
| 11729 | oportunidad | 2 |
| 11730 | oportunas | 2 |
| 11731 | opone | 2 |
| 11732 | óperas | 2 |
| 11733 | olvidos | 2 |
| 11734 | olvidará | 2 |
| 11735 | olvidando | 2 |
| 11736 | olvidan | 2 |
| 11737 | olvidada | 2 |
| 11738 | olorosas | 2 |
| 11739 | olivos | 2 |
| 11740 | olivares | 2 |
| 11741 | olfatorios | 2 |
| 11742 | ojival | 2 |
| 11743 | ojal | 2 |
| 11744 | oírme | 2 |
| 11745 | oirá | 2 |
| 11746 | óigame | 2 |
| 11747 | oíanse | 2 |
| 11748 | oíale | 2 |
| 11749 | ofuscado | 2 |
| 11750 | ofrezca | 2 |
| 11751 | ofreciera | 2 |
| 11752 | ofrecí | 2 |
| 11753 | ofrecerle | 2 |
| 11754 | oficiosa | 2 |
| 11755 | oficiar | 2 |
| 11756 | oficialas | 2 |
| 11757 | oficiala | 2 |
| 11758 | oficiaba | 2 |
| 11759 | ofende | 2 |
| 11760 | ofenda | 2 |
| 11761 | ocurrírseme | 2 |
| 11762 | ocurriría | 2 |
| 11763 | ocurrirá | 2 |
| 11764 | ocurra | 2 |
| 11765 | ocupemos | 2 |
| 11766 | ocuparme | 2 |
| 11767 | ocupan | 2 |
| 11768 | ocupa | 2 |
| 11769 | oculte | 2 |
| 11770 | ocultado | 2 |
| 11771 | ocioso | 2 |
| 11772 | ociosa | 2 |
| 11773 | ochocientos | 2 |
| 11774 | ochavo | 2 |
| 11775 | occidente | 2 |
| 11776 | occidental | 2 |
| 11777 | obtenerla | 2 |
| 11778 | obstrucción | 2 |
| 11779 | observo | 2 |
| 11780 | observaron | 2 |
| 11781 | observándole | 2 |
| 11782 | observándola | 2 |
| 11783 | observancia | 2 |
| 11784 | obsequiar | 2 |
| 11785 | obliga | 2 |
| 11786 | obedeces | 2 |
| 11787 | nupcial | 2 |
| 11788 | núñez | 2 |
| 11789 | numeradas | 2 |
| 11790 | numen | 2 |
| 11791 | nuca | 2 |
| 11792 | novillos | 2 |
| 11793 | noviazgo | 2 |
| 11794 | noventa | 2 |
| 11795 | novena | 2 |
| 11796 | novelescos | 2 |
| 11797 | novelería | 2 |
| 11798 | novelera | 2 |
| 11799 | novar | 2 |
| 11800 | noto | 2 |
| 11801 | notase | 2 |
| 11802 | notarse | 2 |
| 11803 | notada | 2 |
| 11804 | normalmente | 2 |
| 11805 | nombrar | 2 |
| 11806 | nómbrame | 2 |
| 11807 | noé | 2 |
| 11808 | nocturna | 2 |
| 11809 | niñera | 2 |
| 11810 | nietos | 2 |
| 11811 | nichos | 2 |
| 11812 | nicarona | 2 |
| 11813 | nevada | 2 |
| 11814 | netos | 2 |
| 11815 | neta | 2 |
| 11816 | neri | 2 |
| 11817 | nenes | 2 |
| 11818 | nenas | 2 |
| 11819 | neísmo | 2 |
| 11820 | negose | 2 |
| 11821 | negarse | 2 |
| 11822 | negarle | 2 |
| 11823 | negarán | 2 |
| 11824 | necios | 2 |
| 11825 | necesite | 2 |
| 11826 | necesitara | 2 |
| 11827 | necesitamos | 2 |
| 11828 | necesarias | 2 |
| 11829 | necesariamente | 2 |
| 11830 | nebulosa | 2 |
| 11831 | nea | 2 |
| 11832 | nazcan | 2 |
| 11833 | nazca | 2 |
| 11834 | nazareno | 2 |
| 11835 | navegando | 2 |
| 11836 | naturalismo | 2 |
| 11837 | nasal | 2 |
| 11838 | narrando | 2 |
| 11839 | nardos | 2 |
| 11840 | nardo | 2 |
| 11841 | naranjos | 2 |
| 11842 | naranjas | 2 |
| 11843 | nápoles | 2 |
| 11844 | nalgas | 2 |
| 11845 | nadar | 2 |
| 11846 | nadando | 2 |
| 11847 | naciste | 2 |
| 11848 | nacieron | 2 |
| 11849 | naciente | 2 |
| 11850 | naciendo | 2 |
| 11851 | nabucodonosor | 2 |
| 11852 | mutuos | 2 |
| 11853 | músicas | 2 |
| 11854 | musicales | 2 |
| 11855 | musical | 2 |
| 11856 | murmurando | 2 |
| 11857 | murmullos | 2 |
| 11858 | muove | 2 |
| 11859 | muñecos | 2 |
| 11860 | municipales | 2 |
| 11861 | multiplicaba | 2 |
| 11862 | muletillas | 2 |
| 11863 | muletilla | 2 |
| 11864 | muladar | 2 |
| 11865 | mujerzuela | 2 |
| 11866 | mujerona | 2 |
| 11867 | mujeril | 2 |
| 11868 | muge | 2 |
| 11869 | muevo | 2 |
| 11870 | muevas | 2 |
| 11871 | muertecito | 2 |
| 11872 | muérete | 2 |
| 11873 | mueres | 2 |
| 11874 | muerdo | 2 |
| 11875 | mueran | 2 |
| 11876 | muelle | 2 |
| 11877 | muele | 2 |
| 11878 | mudéjares | 2 |
| 11879 | mudéjar | 2 |
| 11880 | mudaba | 2 |
| 11881 | movilidad | 2 |
| 11882 | móviles | 2 |
| 11883 | moverme | 2 |
| 11884 | motivada | 2 |
| 11885 | motas | 2 |
| 11886 | mostrase | 2 |
| 11887 | mostráronse | 2 |
| 11888 | mostrarlo | 2 |
| 11889 | mostaza | 2 |
| 11890 | mortificaban | 2 |
| 11891 | mortales | 2 |
| 11892 | morriña | 2 |
| 11893 | morrazo | 2 |
| 11894 | mormón | 2 |
| 11895 | moriría | 2 |
| 11896 | morimos | 2 |
| 11897 | morenito | 2 |
| 11898 | morcilla | 2 |
| 11899 | morboso | 2 |
| 11900 | moralista | 2 |
| 11901 | moraleja | 2 |
| 11902 | moradas | 2 |
| 11903 | moñuca | 2 |
| 11904 | montada | 2 |
| 11905 | monta | 2 |
| 11906 | monjil | 2 |
| 11907 | monerías | 2 |
| 11908 | mondongo | 2 |
| 11909 | monaguillo | 2 |
| 11910 | momia | 2 |
| 11911 | momentito | 2 |
| 11912 | molinete | 2 |
| 11913 | molestarme | 2 |
| 11914 | molestaran | 2 |
| 11915 | mole | 2 |
| 11916 | moldes | 2 |
| 11917 | modosa | 2 |
| 11918 | modestita | 2 |
| 11919 | moderno | 2 |
| 11920 | moderado | 2 |
| 11921 | modelado | 2 |
| 11922 | moco | 2 |
| 11923 | mitón | 2 |
| 11924 | mitología | 2 |
| 11925 | miss | 2 |
| 11926 | mismísima | 2 |
| 11927 | misita | 2 |
| 11928 | misionero | 2 |
| 11929 | misericordioso | 2 |
| 11930 | miserere | 2 |
| 11931 | misantropía | 2 |
| 11932 | mirosté | 2 |
| 11933 | mirolo | 2 |
| 11934 | míreme | 2 |
| 11935 | mírelos | 2 |
| 11936 | mírele | 2 |
| 11937 | miráronla | 2 |
| 11938 | mirarlo | 2 |
| 11939 | miraría | 2 |
| 11940 | mirará | 2 |
| 11941 | miramientos | 2 |
| 11942 | mirador | 2 |
| 11943 | mirábalas | 2 |
| 11944 | minucioso | 2 |
| 11945 | ministros | 2 |
| 11946 | ministerios | 2 |
| 11947 | minio | 2 |
| 11948 | mínimo | 2 |
| 11949 | mineral | 2 |
| 11950 | mimir | 2 |
| 11951 | mímica | 2 |
| 11952 | mimbres | 2 |
| 11953 | mimar | 2 |
| 11954 | mimando | 2 |
| 11955 | mimado | 2 |
| 11956 | mima | 2 |
| 11957 | miento | 2 |
| 11958 | mieles | 2 |
| 11959 | miedos | 2 |
| 11960 | miajita | 2 |
| 11961 | mezquinos | 2 |
| 11962 | mezclado | 2 |
| 11963 | mezclada | 2 |
| 11964 | mezclábase | 2 |
| 11965 | metódica | 2 |
| 11966 | metieran | 2 |
| 11967 | metiéndolo | 2 |
| 11968 | metiéndole | 2 |
| 11969 | metálica | 2 |
| 11970 | metafísico | 2 |
| 11971 | metafísica | 2 |
| 11972 | merinos | 2 |
| 11973 | merienda | 2 |
| 11974 | mereciera | 2 |
| 11975 | merecidos | 2 |
| 11976 | merecer | 2 |
| 11977 | mercaderes | 2 |
| 11978 | mercachifle | 2 |
| 11979 | meñique | 2 |
| 11980 | mentarle | 2 |
| 11981 | mensajeros | 2 |
| 11982 | mensaje | 2 |
| 11983 | menosprecio | 2 |
| 11984 | menestrala | 2 |
| 11985 | menestra | 2 |
| 11986 | menesterosos | 2 |
| 11987 | meneos | 2 |
| 11988 | meneó | 2 |
| 11989 | menéese | 2 |
| 11990 | menear | 2 |
| 11991 | meneando | 2 |
| 11992 | mendizábal | 2 |
| 11993 | mención | 2 |
| 11994 | mena | 2 |
| 11995 | memorias | 2 |
| 11996 | melodrama | 2 |
| 11997 | melancólico | 2 |
| 11998 | melancolías | 2 |
| 11999 | mejorcito | 2 |
| 12000 | médula | 2 |
| 12001 | mediterránea | 2 |
| 12002 | meditemos | 2 |
| 12003 | meditabundo | 2 |
| 12004 | médica | 2 |
| 12005 | medianería | 2 |
| 12006 | medianamente | 2 |
| 12007 | mediados | 2 |
| 12008 | mediación | 2 |
| 12009 | mecánico | 2 |
| 12010 | meca | 2 |
| 12011 | mausoleos | 2 |
| 12012 | matritenses | 2 |
| 12013 | matorral | 2 |
| 12014 | matinal | 2 |
| 12015 | matilde | 2 |
| 12016 | materno | 2 |
| 12017 | materias | 2 |
| 12018 | materiales | 2 |
| 12019 | matemático | 2 |
| 12020 | matemáticas | 2 |
| 12021 | mataron | 2 |
| 12022 | matarles | 2 |
| 12023 | mataran | 2 |
| 12024 | mastín | 2 |
| 12025 | masticación | 2 |
| 12026 | masónica | 2 |
| 12027 | masón | 2 |
| 12028 | mascar | 2 |
| 12029 | masas | 2 |
| 12030 | martos | 2 |
| 12031 | martirizaba | 2 |
| 12032 | mártires | 2 |
| 12033 | martínez | 2 |
| 12034 | marrasquino | 2 |
| 12035 | marmotona | 2 |
| 12036 | marmolillo | 2 |
| 12037 | mariposita | 2 |
| 12038 | marina | 2 |
| 12039 | maridillo | 2 |
| 12040 | mareos | 2 |
| 12041 | marees | 2 |
| 12042 | mareados | 2 |
| 12043 | mareada | 2 |
| 12044 | márchese | 2 |
| 12045 | marché | 2 |
| 12046 | marchase | 2 |
| 12047 | marcharon | 2 |
| 12048 | marcharme | 2 |
| 12049 | marcharía | 2 |
| 12050 | marcharé | 2 |
| 12051 | marcar | 2 |
| 12052 | marcados | 2 |
| 12053 | marcada | 2 |
| 12054 | marcaban | 2 |
| 12055 | marcaba | 2 |
| 12056 | maravillosamente | 2 |
| 12057 | maravillas | 2 |
| 12058 | maravillada | 2 |
| 12059 | maquinaria | 2 |
| 12060 | mañosa | 2 |
| 12061 | mantuvo | 2 |
| 12062 | mantillas | 2 |
| 12063 | manteniendo | 2 |
| 12064 | mantenerle | 2 |
| 12065 | mantelería | 2 |
| 12066 | mantecadas | 2 |
| 12067 | manotazos | 2 |
| 12068 | manojo | 2 |
| 12069 | manjavacas | 2 |
| 12070 | manirroto | 2 |
| 12071 | manifestaron | 2 |
| 12072 | manifestarlo | 2 |
| 12073 | maniáticas | 2 |
| 12074 | manguitos | 2 |
| 12075 | manejo | 2 |
| 12076 | maneje | 2 |
| 12077 | manejaba | 2 |
| 12078 | mandes | 2 |
| 12079 | mándeme | 2 |
| 12080 | mandé | 2 |
| 12081 | mandarte | 2 |
| 12082 | mandarines | 2 |
| 12083 | mandará | 2 |
| 12084 | mandan | 2 |
| 12085 | máncharras | 2 |
| 12086 | manchado | 2 |
| 12087 | manazas | 2 |
| 12088 | mamón | 2 |
| 12089 | mamando | 2 |
| 12090 | maltrecho | 2 |
| 12091 | maltrató | 2 |
| 12092 | maltratar | 2 |
| 12093 | maltratado | 2 |
| 12094 | malsanos | 2 |
| 12095 | malograse | 2 |
| 12096 | malla | 2 |
| 12097 | malita | 2 |
| 12098 | maligna | 2 |
| 12099 | malicioso | 2 |
| 12100 | maliciosas | 2 |
| 12101 | malestar | 2 |
| 12102 | maleante | 2 |
| 12103 | malditos | 2 |
| 12104 | majadería | 2 |
| 12105 | magníficos | 2 |
| 12106 | magistral | 2 |
| 12107 | mágico | 2 |
| 12108 | magia | 2 |
| 12109 | maestras | 2 |
| 12110 | madrugones | 2 |
| 12111 | madrina | 2 |
| 12112 | madrileño | 2 |
| 12113 | madrileña | 2 |
| 12114 | madriguera | 2 |
| 12115 | maderos | 2 |
| 12116 | madero | 2 |
| 12117 | madejas | 2 |
| 12118 | madapolanes | 2 |
| 12119 | máculas | 2 |
| 12120 | macho | 2 |
| 12121 | machacaba | 2 |
| 12122 | macana | 2 |
| 12123 | luteranos | 2 |
| 12124 | lutera | 2 |
| 12125 | lustroso | 2 |
| 12126 | lustrosa | 2 |
| 12127 | lunática | 2 |
| 12128 | luminoso | 2 |
| 12129 | lujos | 2 |
| 12130 | lúgubremente | 2 |
| 12131 | lucirse | 2 |
| 12132 | lucimiento | 2 |
| 12133 | lucidas | 2 |
| 12134 | lucían | 2 |
| 12135 | lucero | 2 |
| 12136 | lotes | 2 |
| 12137 | loterías | 2 |
| 12138 | losa | 2 |
| 12139 | lord | 2 |
| 12140 | loquinaria | 2 |
| 12141 | lópez | 2 |
| 12142 | logrado | 2 |
| 12143 | logra | 2 |
| 12144 | locomotoras | 2 |
| 12145 | lóbrega | 2 |
| 12146 | llovido | 2 |
| 12147 | llover | 2 |
| 12148 | lloriqueando | 2 |
| 12149 | llore | 2 |
| 12150 | lloraste | 2 |
| 12151 | lloraban | 2 |
| 12152 | llévese | 2 |
| 12153 | llevéis | 2 |
| 12154 | llevé | 2 |
| 12155 | llevárselo | 2 |
| 12156 | llevarían | 2 |
| 12157 | llevándolo | 2 |
| 12158 | llevamos | 2 |
| 12159 | llevadera | 2 |
| 12160 | llenarse | 2 |
| 12161 | llenara | 2 |
| 12162 | llenando | 2 |
| 12163 | llegarían | 2 |
| 12164 | llegaremos | 2 |
| 12165 | llegaran | 2 |
| 12166 | llegamos | 2 |
| 12167 | llamémosle | 2 |
| 12168 | llame | 2 |
| 12169 | llamarte | 2 |
| 12170 | llamador | 2 |
| 12171 | llamábanla | 2 |
| 12172 | liviano | 2 |
| 12173 | literario | 2 |
| 12174 | literaria | 2 |
| 12175 | lisonjeras | 2 |
| 12176 | líquidos | 2 |
| 12177 | lipendi | 2 |
| 12178 | líos | 2 |
| 12179 | linterna | 2 |
| 12180 | lindísimos | 2 |
| 12181 | lindísimas | 2 |
| 12182 | lince | 2 |
| 12183 | limpión | 2 |
| 12184 | límites | 2 |
| 12185 | limitado | 2 |
| 12186 | liga | 2 |
| 12187 | liebre | 2 |
| 12188 | lié | 2 |
| 12189 | licencia | 2 |
| 12190 | libritos | 2 |
| 12191 | librería | 2 |
| 12192 | libertino | 2 |
| 12193 | liberaremos | 2 |
| 12194 | liberar | 2 |
| 12195 | liada | 2 |
| 12196 | liaba | 2 |
| 12197 | lía | 2 |
| 12198 | leyenda | 2 |
| 12199 | levemente | 2 |
| 12200 | levantaría | 2 |
| 12201 | levantan | 2 |
| 12202 | leoneses | 2 |
| 12203 | lentitud | 2 |
| 12204 | lentes | 2 |
| 12205 | lente | 2 |
| 12206 | lenta | 2 |
| 12207 | lema | 2 |
| 12208 | leída | 2 |
| 12209 | legítimos | 2 |
| 12210 | leerás | 2 |
| 12211 | lebrel | 2 |
| 12212 | lea | 2 |
| 12213 | lavó | 2 |
| 12214 | lavadas | 2 |
| 12215 | lavada | 2 |
| 12216 | latitud | 2 |
| 12217 | latidos | 2 |
| 12218 | lastimeros | 2 |
| 12219 | lastimada | 2 |
| 12220 | largó | 2 |
| 12221 | largarse | 2 |
| 12222 | largaba | 2 |
| 12223 | laredo | 2 |
| 12224 | lanzaron | 2 |
| 12225 | lanzarme | 2 |
| 12226 | lanzarla | 2 |
| 12227 | lanzando | 2 |
| 12228 | lanza | 2 |
| 12229 | lanillas | 2 |
| 12230 | láminas | 2 |
| 12231 | lamentos | 2 |
| 12232 | lamentar | 2 |
| 12233 | lamentable | 2 |
| 12234 | laissez | 2 |
| 12235 | lagrimones | 2 |
| 12236 | lagarto | 2 |
| 12237 | lagarta | 2 |
| 12238 | ladrar | 2 |
| 12239 | ladrando | 2 |
| 12240 | ladino | 2 |
| 12241 | labrar | 2 |
| 12242 | labrador | 2 |
| 12243 | labrada | 2 |
| 12244 | laberinto | 2 |
| 12245 | laberíntico | 2 |
| 12246 | kock | 2 |
| 12247 | king | 2 |
| 12248 | juzgue | 2 |
| 12249 | juzgó | 2 |
| 12250 | juzgando | 2 |
| 12251 | jures | 2 |
| 12252 | jure | 2 |
| 12253 | juramentos | 2 |
| 12254 | juntando | 2 |
| 12255 | junde | 2 |
| 12256 | junda | 2 |
| 12257 | junco | 2 |
| 12258 | juimos | 2 |
| 12259 | jugador | 2 |
| 12260 | juegan | 2 |
| 12261 | judíos | 2 |
| 12262 | judicial | 2 |
| 12263 | judaísmo | 2 |
| 12264 | jubilar | 2 |
| 12265 | jorobar | 2 |
| 12266 | jornal | 2 |
| 12267 | jicarazo | 2 |
| 12268 | jergón | 2 |
| 12269 | javiera | 2 |
| 12270 | jardines | 2 |
| 12271 | jarabes | 2 |
| 12272 | japonés | 2 |
| 12273 | jaleo | 2 |
| 12274 | jadeante | 2 |
| 12275 | jactándose | 2 |
| 12276 | jactábase | 2 |
| 12277 | jaciendo | 2 |
| 12278 | italiano | 2 |
| 12279 | italia | 2 |
| 12280 | irún | 2 |
| 12281 | írsele | 2 |
| 12282 | irresponsable | 2 |
| 12283 | irresistibles | 2 |
| 12284 | irregularidad | 2 |
| 12285 | irradiación | 2 |
| 12286 | irónica | 2 |
| 12287 | irguiéndose | 2 |
| 12288 | involucrar | 2 |
| 12289 | invitados | 2 |
| 12290 | invitado | 2 |
| 12291 | invitación | 2 |
| 12292 | invisibles | 2 |
| 12293 | invento | 2 |
| 12294 | inventé | 2 |
| 12295 | invente | 2 |
| 12296 | inventas | 2 |
| 12297 | inventario | 2 |
| 12298 | inventar | 2 |
| 12299 | inventan | 2 |
| 12300 | inventado | 2 |
| 12301 | invasión | 2 |
| 12302 | invariablemente | 2 |
| 12303 | invariable | 2 |
| 12304 | inválida | 2 |
| 12305 | invadiendo | 2 |
| 12306 | invadía | 2 |
| 12307 | inútilmente | 2 |
| 12308 | inutilidad | 2 |
| 12309 | inundaron | 2 |
| 12310 | intriga | 2 |
| 12311 | intimidades | 2 |
| 12312 | íntimas | 2 |
| 12313 | intimar | 2 |
| 12314 | intervenía | 2 |
| 12315 | intervengo | 2 |
| 12316 | interrupción | 2 |
| 12317 | interrumpido | 2 |
| 12318 | interpretación | 2 |
| 12319 | interno | 2 |
| 12320 | intermitente | 2 |
| 12321 | intermitencias | 2 |
| 12322 | interminable | 2 |
| 12323 | intermediario | 2 |
| 12324 | interesara | 2 |
| 12325 | interesantísima | 2 |
| 12326 | interesada | 2 |
| 12327 | intentara | 2 |
| 12328 | intentando | 2 |
| 12329 | intellectus | 2 |
| 12330 | intelectualmente | 2 |
| 12331 | intelectuales | 2 |
| 12332 | intelectual | 2 |
| 12333 | intacto | 2 |
| 12334 | intachable | 2 |
| 12335 | insustancial | 2 |
| 12336 | insultado | 2 |
| 12337 | insufrible | 2 |
| 12338 | insubordinaba | 2 |
| 12339 | instructivo | 2 |
| 12340 | instrucciones | 2 |
| 12341 | instintivo | 2 |
| 12342 | instantáneamente | 2 |
| 12343 | instaláronse | 2 |
| 12344 | instalada | 2 |
| 12345 | instalación | 2 |
| 12346 | inspirábale | 2 |
| 12347 | inspector | 2 |
| 12348 | insignias | 2 |
| 12349 | inservibles | 2 |
| 12350 | insensatos | 2 |
| 12351 | inseguridad | 2 |
| 12352 | inquisición | 2 |
| 12353 | inquina | 2 |
| 12354 | inquilinas | 2 |
| 12355 | inquietudes | 2 |
| 12356 | inquietó | 2 |
| 12357 | inquietísima | 2 |
| 12358 | inquietarse | 2 |
| 12359 | innata | 2 |
| 12360 | inmortalidad | 2 |
| 12361 | inmortales | 2 |
| 12362 | inmensos | 2 |
| 12363 | inmediatos | 2 |
| 12364 | ininteligibles | 2 |
| 12365 | inició | 2 |
| 12366 | iniciativas | 2 |
| 12367 | inicial | 2 |
| 12368 | iniciada | 2 |
| 12369 | inicia | 2 |
| 12370 | ingredientes | 2 |
| 12371 | ingratos | 2 |
| 12372 | ingenuamente | 2 |
| 12373 | infundió | 2 |
| 12374 | infortunado | 2 |
| 12375 | informes | 2 |
| 12376 | informe | 2 |
| 12377 | inflado | 2 |
| 12378 | infinitas | 2 |
| 12379 | infausto | 2 |
| 12380 | infatigable | 2 |
| 12381 | infantiles | 2 |
| 12382 | infamante | 2 |
| 12383 | inexplicables | 2 |
| 12384 | inexperta | 2 |
| 12385 | inestimable | 2 |
| 12386 | inequívocas | 2 |
| 12387 | ineficacia | 2 |
| 12388 | indiscutible | 2 |
| 12389 | indiscreto | 2 |
| 12390 | indiscreción | 2 |
| 12391 | indisciplina | 2 |
| 12392 | indilugencias | 2 |
| 12393 | indignó | 2 |
| 12394 | indignado | 2 |
| 12395 | indignaba | 2 |
| 12396 | indigna | 2 |
| 12397 | indicios | 2 |
| 12398 | indicar | 2 |
| 12399 | indicándole | 2 |
| 12400 | indicada | 2 |
| 12401 | indicaciones | 2 |
| 12402 | indica | 2 |
| 12403 | indiano | 2 |
| 12404 | independientes | 2 |
| 12405 | independiente | 2 |
| 12406 | indemnización | 2 |
| 12407 | indefinidamente | 2 |
| 12408 | indecisa | 2 |
| 12409 | indecencias | 2 |
| 12410 | indagar | 2 |
| 12411 | incurría | 2 |
| 12412 | incumbencias | 2 |
| 12413 | inculta | 2 |
| 12414 | incrédula | 2 |
| 12415 | incorporarse | 2 |
| 12416 | incorporándose | 2 |
| 12417 | incorporada | 2 |
| 12418 | inconstantes | 2 |
| 12419 | inconscientemente | 2 |
| 12420 | incomprensibles | 2 |
| 12421 | incomodó | 2 |
| 12422 | incomodidad | 2 |
| 12423 | incomodaba | 2 |
| 12424 | incoherente | 2 |
| 12425 | inclinar | 2 |
| 12426 | inclinado | 2 |
| 12427 | incierto | 2 |
| 12428 | incendios | 2 |
| 12429 | incansable | 2 |
| 12430 | inapetencia | 2 |
| 12431 | inacabables | 2 |
| 12432 | impuso | 2 |
| 12433 | impulsada | 2 |
| 12434 | impuesto | 2 |
| 12435 | imprudente | 2 |
| 12436 | imprimiendo | 2 |
| 12437 | impreso | 2 |
| 12438 | impresionaron | 2 |
| 12439 | impresionado | 2 |
| 12440 | impresionables | 2 |
| 12441 | impresa | 2 |
| 12442 | impotentes | 2 |
| 12443 | imposibilitaban | 2 |
| 12444 | importantes | 2 |
| 12445 | imponían | 2 |
| 12446 | imponerse | 2 |
| 12447 | imponente | 2 |
| 12448 | impidiera | 2 |
| 12449 | impertinencias | 2 |
| 12450 | impertinencia | 2 |
| 12451 | imperioso | 2 |
| 12452 | imperceptible | 2 |
| 12453 | impedirme | 2 |
| 12454 | impedían | 2 |
| 12455 | impedía | 2 |
| 12456 | impavidez | 2 |
| 12457 | impacientaba | 2 |
| 12458 | imitar | 2 |
| 12459 | imita | 2 |
| 12460 | imaginándose | 2 |
| 12461 | ilustradas | 2 |
| 12462 | iluminen | 2 |
| 12463 | iluminaron | 2 |
| 12464 | iluminadas | 2 |
| 12465 | iluminada | 2 |
| 12466 | igualdad | 2 |
| 12467 | ignorantes | 2 |
| 12468 | ignorante | 2 |
| 12469 | ignorando | 2 |
| 12470 | íes | 2 |
| 12471 | idumeo | 2 |
| 12472 | idolatría | 2 |
| 12473 | idolatraré | 2 |
| 12474 | idolatrando | 2 |
| 12475 | idiotas | 2 |
| 12476 | idilio | 2 |
| 12477 | ideación | 2 |
| 12478 | íbanse | 2 |
| 12479 | huyeron | 2 |
| 12480 | hurtadillas | 2 |
| 12481 | huraño | 2 |
| 12482 | hundida | 2 |
| 12483 | hunda | 2 |
| 12484 | humillarse | 2 |
| 12485 | humillar | 2 |
| 12486 | humillado | 2 |
| 12487 | humillación | 2 |
| 12488 | humildemente | 2 |
| 12489 | húmera | 2 |
| 12490 | humaredas | 2 |
| 12491 | huéspeda | 2 |
| 12492 | huerfanitos | 2 |
| 12493 | huérfana | 2 |
| 12494 | huellas | 2 |
| 12495 | huella | 2 |
| 12496 | hueca | 2 |
| 12497 | hubiérase | 2 |
| 12498 | hoyo | 2 |
| 12499 | hostilidad | 2 |
| 12500 | hostil | 2 |
| 12501 | hosanna | 2 |
| 12502 | horrorosas | 2 |
| 12503 | horrorizado | 2 |
| 12504 | horripilaba | 2 |
| 12505 | horrendo | 2 |
| 12506 | hornillo | 2 |
| 12507 | hormigueo | 2 |
| 12508 | horchata | 2 |
| 12509 | horca | 2 |
| 12510 | honroso | 2 |
| 12511 | honras | 2 |
| 12512 | honrados | 2 |
| 12513 | honores | 2 |
| 12514 | honesto | 2 |
| 12515 | honestas | 2 |
| 12516 | honesta | 2 |
| 12517 | hondura | 2 |
| 12518 | hondísima | 2 |
| 12519 | hondamente | 2 |
| 12520 | honda | 2 |
| 12521 | homicida | 2 |
| 12522 | hombruna | 2 |
| 12523 | holgura | 2 |
| 12524 | hocicuda | 2 |
| 12525 | hízose | 2 |
| 12526 | hipocritona | 2 |
| 12527 | hipócritas | 2 |
| 12528 | hinchado | 2 |
| 12529 | hincapié | 2 |
| 12530 | hilada | 2 |
| 12531 | hijitos | 2 |
| 12532 | higiénico | 2 |
| 12533 | hidalguía | 2 |
| 12534 | hidalgo | 2 |
| 12535 | hicieras | 2 |
| 12536 | heterogeneidad | 2 |
| 12537 | hervidero | 2 |
| 12538 | heroísmo | 2 |
| 12539 | heroína | 2 |
| 12540 | heroico | 2 |
| 12541 | héroe | 2 |
| 12542 | hernán | 2 |
| 12543 | hermosuras | 2 |
| 12544 | hermosota | 2 |
| 12545 | hermanita | 2 |
| 12546 | heredar | 2 |
| 12547 | heredada | 2 |
| 12548 | helado | 2 |
| 12549 | hebilla | 2 |
| 12550 | hazlo | 2 |
| 12551 | hazle | 2 |
| 12552 | hayamos | 2 |
| 12553 | hatchisschina | 2 |
| 12554 | hastiaba | 2 |
| 12555 | harte | 2 |
| 12556 | hartas | 2 |
| 12557 | harmonium | 2 |
| 12558 | haraganes | 2 |
| 12559 | hamos | 2 |
| 12560 | hambrienta | 2 |
| 12561 | hallábanse | 2 |
| 12562 | hagáis | 2 |
| 12563 | haciéndote | 2 |
| 12564 | hacías | 2 |
| 12565 | hacíamos | 2 |
| 12566 | hacíalo | 2 |
| 12567 | hacíala | 2 |
| 12568 | hacha | 2 |
| 12569 | hacerlos | 2 |
| 12570 | hacerles | 2 |
| 12571 | hablillas | 2 |
| 12572 | hablé | 2 |
| 12573 | hablarían | 2 |
| 12574 | hablaría | 2 |
| 12575 | hablándoles | 2 |
| 12576 | habladora | 2 |
| 12577 | habitados | 2 |
| 12578 | habilidoso | 2 |
| 12579 | habilidades | 2 |
| 12580 | habiéndose | 2 |
| 12581 | habiéndole | 2 |
| 12582 | habíanle | 2 |
| 12583 | haberte | 2 |
| 12584 | habérselas | 2 |
| 12585 | habaneras | 2 |
| 12586 | gustase | 2 |
| 12587 | gustarme | 2 |
| 12588 | gustarle | 2 |
| 12589 | gustando | 2 |
| 12590 | gustábale | 2 |
| 12591 | gusanos | 2 |
| 12592 | guitarreo | 2 |
| 12593 | guisa | 2 |
| 12594 | guiñaba | 2 |
| 12595 | guillotina | 2 |
| 12596 | guillati | 2 |
| 12597 | guijarros | 2 |
| 12598 | guía | 2 |
| 12599 | guasoncita | 2 |
| 12600 | guasitas | 2 |
| 12601 | guasas | 2 |
| 12602 | guárdese | 2 |
| 12603 | guardarlos | 2 |
| 12604 | guardaría | 2 |
| 12605 | guardadito | 2 |
| 12606 | guardada | 2 |
| 12607 | guapetonas | 2 |
| 12608 | gruñir | 2 |
| 12609 | gruñía | 2 |
| 12610 | gruñendo | 2 |
| 12611 | gruesos | 2 |
| 12612 | grotesco | 2 |
| 12613 | grosero | 2 |
| 12614 | groseramente | 2 |
| 12615 | gro | 2 |
| 12616 | gritaron | 2 |
| 12617 | gritaban | 2 |
| 12618 | grillera | 2 |
| 12619 | grifo | 2 |
| 12620 | grietas | 2 |
| 12621 | greda | 2 |
| 12622 | gratas | 2 |
| 12623 | granujería | 2 |
| 12624 | granujas | 2 |
| 12625 | granos | 2 |
| 12626 | grandón | 2 |
| 12627 | grandísimas | 2 |
| 12628 | granada | 2 |
| 12629 | gramática | 2 |
| 12630 | gradual | 2 |
| 12631 | grados | 2 |
| 12632 | grada | 2 |
| 12633 | gozándose | 2 |
| 12634 | gotitas | 2 |
| 12635 | gorras | 2 |
| 12636 | goma | 2 |
| 12637 | golpecitos | 2 |
| 12638 | gobiernos | 2 |
| 12639 | gobernaor | 2 |
| 12640 | gobernadores | 2 |
| 12641 | gloriosa | 2 |
| 12642 | globos | 2 |
| 12643 | gitanesca | 2 |
| 12644 | giró | 2 |
| 12645 | gibraltar | 2 |
| 12646 | getafe | 2 |
| 12647 | gentes | 2 |
| 12648 | geniazo | 2 |
| 12649 | genial | 2 |
| 12650 | generosa | 2 |
| 12651 | generis | 2 |
| 12652 | generaciones | 2 |
| 12653 | gemía | 2 |
| 12654 | gelatinosas | 2 |
| 12655 | gaveta | 2 |
| 12656 | gatuperio | 2 |
| 12657 | gatito | 2 |
| 12658 | gatesca | 2 |
| 12659 | gateras | 2 |
| 12660 | gastarla | 2 |
| 12661 | gastando | 2 |
| 12662 | gastado | 2 |
| 12663 | gastadas | 2 |
| 12664 | garrote | 2 |
| 12665 | garrafales | 2 |
| 12666 | garbo | 2 |
| 12667 | garabato | 2 |
| 12668 | ganita | 2 |
| 12669 | gangas | 2 |
| 12670 | gandulones | 2 |
| 12671 | gande | 2 |
| 12672 | gancho | 2 |
| 12673 | ganara | 2 |
| 12674 | ganada | 2 |
| 12675 | gama | 2 |
| 12676 | galones | 2 |
| 12677 | galón | 2 |
| 12678 | gallardía | 2 |
| 12679 | galeras | 2 |
| 12680 | galapaguito | 2 |
| 12681 | galápago | 2 |
| 12682 | galantería | 2 |
| 12683 | gaita | 2 |
| 12684 | gaceta | 2 |
| 12685 | fusilen | 2 |
| 12686 | fusil | 2 |
| 12687 | furibundo | 2 |
| 12688 | fuoco | 2 |
| 12689 | fúnebres | 2 |
| 12690 | fundándose | 2 |
| 12691 | fundan | 2 |
| 12692 | fundamental | 2 |
| 12693 | fundadoras | 2 |
| 12694 | fundador | 2 |
| 12695 | fundación | 2 |
| 12696 | fumar | 2 |
| 12697 | fumando | 2 |
| 12698 | fuguilla | 2 |
| 12699 | fugó | 2 |
| 12700 | fugitivo | 2 |
| 12701 | fuertecillo | 2 |
| 12702 | fueros | 2 |
| 12703 | fuer | 2 |
| 12704 | fuentes | 2 |
| 12705 | fuelle | 2 |
| 12706 | fuegos | 2 |
| 12707 | fruta | 2 |
| 12708 | fruncimiento | 2 |
| 12709 | fruncidas | 2 |
| 12710 | frotó | 2 |
| 12711 | frotado | 2 |
| 12712 | frota | 2 |
| 12713 | frita | 2 |
| 12714 | fríos | 2 |
| 12715 | fresas | 2 |
| 12716 | frenéticos | 2 |
| 12717 | frenético | 2 |
| 12718 | fregado | 2 |
| 12719 | fray | 2 |
| 12720 | fraternales | 2 |
| 12721 | franquearon | 2 |
| 12722 | franqueaban | 2 |
| 12723 | francesota | 2 |
| 12724 | frailes | 2 |
| 12725 | fracasos | 2 |
| 12726 | fracaso | 2 |
| 12727 | frac | 2 |
| 12728 | forzosamente | 2 |
| 12729 | fortísimo | 2 |
| 12730 | forraje | 2 |
| 12731 | forrados | 2 |
| 12732 | forrado | 2 |
| 12733 | forrada | 2 |
| 12734 | fornos | 2 |
| 12735 | fornido | 2 |
| 12736 | formulando | 2 |
| 12737 | formó | 2 |
| 12738 | formara | 2 |
| 12739 | fogosa | 2 |
| 12740 | foco | 2 |
| 12741 | fluxión | 2 |
| 12742 | fluctuando | 2 |
| 12743 | flotante | 2 |
| 12744 | florín | 2 |
| 12745 | floreados | 2 |
| 12746 | flojos | 2 |
| 12747 | flojilla | 2 |
| 12748 | floja | 2 |
| 12749 | flequillo | 2 |
| 12750 | flechas | 2 |
| 12751 | flauteados | 2 |
| 12752 | flamantes | 2 |
| 12753 | flacos | 2 |
| 12754 | flácida | 2 |
| 12755 | flacas | 2 |
| 12756 | fisiológica | 2 |
| 12757 | físicos | 2 |
| 12758 | fisgona | 2 |
| 12759 | fiscalizadora | 2 |
| 12760 | fiscales | 2 |
| 12761 | firmemente | 2 |
| 12762 | firmas | 2 |
| 12763 | firmaba | 2 |
| 12764 | finísimas | 2 |
| 12765 | fingido | 2 |
| 12766 | fingía | 2 |
| 12767 | finezas | 2 |
| 12768 | finales | 2 |
| 12769 | filtrándose | 2 |
| 12770 | filósofos | 2 |
| 12771 | filosóficos | 2 |
| 12772 | filomena | 2 |
| 12773 | filigranas | 2 |
| 12774 | fijose | 2 |
| 12775 | fijeza | 2 |
| 12776 | fijaremos | 2 |
| 12777 | fijándose | 2 |
| 12778 | figuran | 2 |
| 12779 | figurada | 2 |
| 12780 | figuración | 2 |
| 12781 | fiero | 2 |
| 12782 | fierecita | 2 |
| 12783 | fieltro | 2 |
| 12784 | fiebres | 2 |
| 12785 | fichú | 2 |
| 12786 | fichas | 2 |
| 12787 | feudal | 2 |
| 12788 | fétida | 2 |
| 12789 | festín | 2 |
| 12790 | fernández | 2 |
| 12791 | feria | 2 |
| 12792 | fenelona | 2 |
| 12793 | felicitar | 2 |
| 12794 | felicitaciones | 2 |
| 12795 | felicitaban | 2 |
| 12796 | felicísima | 2 |
| 12797 | federal | 2 |
| 12798 | fecundidad | 2 |
| 12799 | favorezca | 2 |
| 12800 | favoreció | 2 |
| 12801 | fausto | 2 |
| 12802 | fatigoso | 2 |
| 12803 | fatigosa | 2 |
| 12804 | fatigados | 2 |
| 12805 | fases | 2 |
| 12806 | fase | 2 |
| 12807 | farolón | 2 |
| 12808 | faro | 2 |
| 12809 | fantásticos | 2 |
| 12810 | fantasmona | 2 |
| 12811 | fanfarronadas | 2 |
| 12812 | famosos | 2 |
| 12813 | familiarmente | 2 |
| 12814 | familiares | 2 |
| 12815 | faltarme | 2 |
| 12816 | faltará | 2 |
| 12817 | falsas | 2 |
| 12818 | fallido | 2 |
| 12819 | fallecimiento | 2 |
| 12820 | fallar | 2 |
| 12821 | falansterio | 2 |
| 12822 | faenas | 2 |
| 12823 | factible | 2 |
| 12824 | facilitado | 2 |
| 12825 | facilillo | 2 |
| 12826 | fachada | 2 |
| 12827 | facetas | 2 |
| 12828 | facción | 2 |
| 12829 | fabulista | 2 |
| 12830 | fábulas | 2 |
| 12831 | fábula | 2 |
| 12832 | fabricación | 2 |
| 12833 | f | 2 |
| 12834 | extremeño | 2 |
| 12835 | extremado | 2 |
| 12836 | extravíos | 2 |
| 12837 | extravío | 2 |
| 12838 | extravagante | 2 |
| 12839 | extinguida | 2 |
| 12840 | extinguían | 2 |
| 12841 | extienden | 2 |
| 12842 | externos | 2 |
| 12843 | extenso | 2 |
| 12844 | extendiendo | 2 |
| 12845 | extendidos | 2 |
| 12846 | extendidas | 2 |
| 12847 | extender | 2 |
| 12848 | exquisita | 2 |
| 12849 | expulsión | 2 |
| 12850 | expulsado | 2 |
| 12851 | expuestos | 2 |
| 12852 | expuesto | 2 |
| 12853 | expuesta | 2 |
| 12854 | exprisiones | 2 |
| 12855 | expresivos | 2 |
| 12856 | expresada | 2 |
| 12857 | expresa | 2 |
| 12858 | exponía | 2 |
| 12859 | exponga | 2 |
| 12860 | exponer | 2 |
| 12861 | explotan | 2 |
| 12862 | explotación | 2 |
| 12863 | expliques | 2 |
| 12864 | expliquemos | 2 |
| 12865 | explique | 2 |
| 12866 | explicó | 2 |
| 12867 | explícate | 2 |
| 12868 | explicarme | 2 |
| 12869 | explicarlo | 2 |
| 12870 | explicarle | 2 |
| 12871 | explícame | 2 |
| 12872 | explicaba | 2 |
| 12873 | expirando | 2 |
| 12874 | experimentaron | 2 |
| 12875 | expeditivo | 2 |
| 12876 | expedir | 2 |
| 12877 | expedición | 2 |
| 12878 | expansiva | 2 |
| 12879 | expansiones | 2 |
| 12880 | éxitos | 2 |
| 12881 | existió | 2 |
| 12882 | exigencia | 2 |
| 12883 | exhortación | 2 |
| 12884 | excluía | 2 |
| 12885 | exclamar | 2 |
| 12886 | excitantes | 2 |
| 12887 | excitante | 2 |
| 12888 | excitadísima | 2 |
| 12889 | exceso | 2 |
| 12890 | excelsa | 2 |
| 12891 | excelentísimo | 2 |
| 12892 | excelencia | 2 |
| 12893 | examinarle | 2 |
| 12894 | examinan | 2 |
| 12895 | examinado | 2 |
| 12896 | exageradas | 2 |
| 12897 | exacto | 2 |
| 12898 | evitarlo | 2 |
| 12899 | evitarle | 2 |
| 12900 | evitado | 2 |
| 12901 | evitaba | 2 |
| 12902 | evita | 2 |
| 12903 | evidentes | 2 |
| 12904 | evidente | 2 |
| 12905 | evidencia | 2 |
| 12906 | evasivas | 2 |
| 12907 | europea | 2 |
| 12908 | eucaristía | 2 |
| 12909 | etcétera | 2 |
| 12910 | etapas | 2 |
| 12911 | etapa | 2 |
| 12912 | estupor | 2 |
| 12913 | estupidez | 2 |
| 12914 | estúpidas | 2 |
| 12915 | estúpidamente | 2 |
| 12916 | estupefacta | 2 |
| 12917 | estudió | 2 |
| 12918 | estudian | 2 |
| 12919 | estudiadas | 2 |
| 12920 | estudiada | 2 |
| 12921 | estuche | 2 |
| 12922 | estucadas | 2 |
| 12923 | estrofa | 2 |
| 12924 | estribos | 2 |
| 12925 | estribillos | 2 |
| 12926 | estreno | 2 |
| 12927 | estrenar | 2 |
| 12928 | estrenada | 2 |
| 12929 | estremecimientos | 2 |
| 12930 | estremecimiento | 2 |
| 12931 | estremecía | 2 |
| 12932 | estrelló | 2 |
| 12933 | estrello | 2 |
| 12934 | estrellarse | 2 |
| 12935 | estrecho | 2 |
| 12936 | estrecheces | 2 |
| 12937 | estrechas | 2 |
| 12938 | estrechándole | 2 |
| 12939 | estragos | 2 |
| 12940 | estorbo | 2 |
| 12941 | estorba | 2 |
| 12942 | estirones | 2 |
| 12943 | estirándose | 2 |
| 12944 | estirada | 2 |
| 12945 | estiraba | 2 |
| 12946 | estimulaba | 2 |
| 12947 | estimula | 2 |
| 12948 | estimo | 2 |
| 12949 | estimaba | 2 |
| 12950 | estilos | 2 |
| 12951 | estiércol | 2 |
| 12952 | estético | 2 |
| 12953 | estética | 2 |
| 12954 | estese | 2 |
| 12955 | estertor | 2 |
| 12956 | esterilidad | 2 |
| 12957 | estéril | 2 |
| 12958 | estarla | 2 |
| 12959 | estaríamos | 2 |
| 12960 | estampada | 2 |
| 12961 | estampa | 2 |
| 12962 | estallar | 2 |
| 12963 | estafa | 2 |
| 12964 | estacazo | 2 |
| 12965 | estaca | 2 |
| 12966 | estableció | 2 |
| 12967 | establecido | 2 |
| 12968 | establece | 2 |
| 12969 | espumarajos | 2 |
| 12970 | esponja | 2 |
| 12971 | espliego | 2 |
| 12972 | espléndidos | 2 |
| 12973 | espiritui | 2 |
| 12974 | espiritualmente | 2 |
| 12975 | espiral | 2 |
| 12976 | espinas | 2 |
| 12977 | espinal | 2 |
| 12978 | esperé | 2 |
| 12979 | esperarle | 2 |
| 12980 | esperaré | 2 |
| 12981 | esperándote | 2 |
| 12982 | espectros | 2 |
| 12983 | especias | 2 |
| 12984 | espasmódico | 2 |
| 12985 | espasmódica | 2 |
| 12986 | esparteros | 2 |
| 12987 | esparcir | 2 |
| 12988 | esparcimiento | 2 |
| 12989 | esparcieron | 2 |
| 12990 | esparciendo | 2 |
| 12991 | esparcido | 2 |
| 12992 | esparcía | 2 |
| 12993 | esparce | 2 |
| 12994 | espantajo | 2 |
| 12995 | espantables | 2 |
| 12996 | espantaba | 2 |
| 12997 | espanta | 2 |
| 12998 | esmerose | 2 |
| 12999 | eslabón | 2 |
| 13000 | esgrimía | 2 |
| 13001 | esforzaban | 2 |
| 13002 | esférica | 2 |
| 13003 | eses | 2 |
| 13004 | esencialmente | 2 |
| 13005 | escupo | 2 |
| 13006 | escupió | 2 |
| 13007 | escupía | 2 |
| 13008 | escueza | 2 |
| 13009 | escuece | 2 |
| 13010 | escritores | 2 |
| 13011 | escritor | 2 |
| 13012 | escribo | 2 |
| 13013 | escribirle | 2 |
| 13014 | escribirlas | 2 |
| 13015 | escribió | 2 |
| 13016 | escribieran | 2 |
| 13017 | escondió | 2 |
| 13018 | escondiendo | 2 |
| 13019 | escondidas | 2 |
| 13020 | escombros | 2 |
| 13021 | escolta | 2 |
| 13022 | escogió | 2 |
| 13023 | escogiese | 2 |
| 13024 | escocia | 2 |
| 13025 | esclavina | 2 |
| 13026 | escéptica | 2 |
| 13027 | escenario | 2 |
| 13028 | escaso | 2 |
| 13029 | escarnecerle | 2 |
| 13030 | escapas | 2 |
| 13031 | escapan | 2 |
| 13032 | escapaban | 2 |
| 13033 | escandaloso | 2 |
| 13034 | escandalizada | 2 |
| 13035 | escandalera | 2 |
| 13036 | escanciar | 2 |
| 13037 | escalonados | 2 |
| 13038 | escabulló | 2 |
| 13039 | erizo | 2 |
| 13040 | erizadas | 2 |
| 13041 | ergotina | 2 |
| 13042 | éramos | 2 |
| 13043 | er | 2 |
| 13044 | equivocadamente | 2 |
| 13045 | equivocaciones | 2 |
| 13046 | equívoca | 2 |
| 13047 | equilibrado | 2 |
| 13048 | equidad | 2 |
| 13049 | epístola | 2 |
| 13050 | episodio | 2 |
| 13051 | episcopal | 2 |
| 13052 | epiléptico | 2 |
| 13053 | epidermis | 2 |
| 13054 | enzarzando | 2 |
| 13055 | envolvió | 2 |
| 13056 | envolviéndose | 2 |
| 13057 | envolviendo | 2 |
| 13058 | envolver | 2 |
| 13059 | enviudar | 2 |
| 13060 | envidiosona | 2 |
| 13061 | enviaba | 2 |
| 13062 | envejecido | 2 |
| 13063 | envalentonándose | 2 |
| 13064 | entusiasta | 2 |
| 13065 | entusiasmada | 2 |
| 13066 | entristeció | 2 |
| 13067 | entrevió | 2 |
| 13068 | entreveía | 2 |
| 13069 | entretienes | 2 |
| 13070 | entreteniéndose | 2 |
| 13071 | entretenidas | 2 |
| 13072 | entretenían | 2 |
| 13073 | entremos | 2 |
| 13074 | entremezclaban | 2 |
| 13075 | entremedio | 2 |
| 13076 | entregarse | 2 |
| 13077 | entregarás | 2 |
| 13078 | entregaran | 2 |
| 13079 | entregándole | 2 |
| 13080 | entregan | 2 |
| 13081 | entraste | 2 |
| 13082 | entraran | 2 |
| 13083 | entrará | 2 |
| 13084 | entrañaban | 2 |
| 13085 | entrábamos | 2 |
| 13086 | entonado | 2 |
| 13087 | entonación | 2 |
| 13088 | entona | 2 |
| 13089 | entierros | 2 |
| 13090 | entiéndete | 2 |
| 13091 | entiéndelo | 2 |
| 13092 | enteros | 2 |
| 13093 | enternecían | 2 |
| 13094 | enteras | 2 |
| 13095 | enterara | 2 |
| 13096 | entendió | 2 |
| 13097 | entendimientos | 2 |
| 13098 | entendiese | 2 |
| 13099 | entendieron | 2 |
| 13100 | entendiera | 2 |
| 13101 | entendernos | 2 |
| 13102 | entenderemos | 2 |
| 13103 | entendemos | 2 |
| 13104 | ensueños | 2 |
| 13105 | ensimismado | 2 |
| 13106 | enséñemela | 2 |
| 13107 | enseñarla | 2 |
| 13108 | enseñaría | 2 |
| 13109 | enseñan | 2 |
| 13110 | ensayándose | 2 |
| 13111 | ensalmo | 2 |
| 13112 | ensaladera | 2 |
| 13113 | enroscadas | 2 |
| 13114 | enredando | 2 |
| 13115 | enredan | 2 |
| 13116 | enorgullecía | 2 |
| 13117 | enojoso | 2 |
| 13118 | enojarse | 2 |
| 13119 | enmendó | 2 |
| 13120 | enmendado | 2 |
| 13121 | enmedio | 2 |
| 13122 | enlaces | 2 |
| 13123 | enlace | 2 |
| 13124 | enjuta | 2 |
| 13125 | enjambre | 2 |
| 13126 | enhoramala | 2 |
| 13127 | enhebrada | 2 |
| 13128 | engrudo | 2 |
| 13129 | engranados | 2 |
| 13130 | engrana | 2 |
| 13131 | engordado | 2 |
| 13132 | engolosinar | 2 |
| 13133 | engatusarás | 2 |
| 13134 | engañes | 2 |
| 13135 | engañarte | 2 |
| 13136 | engañados | 2 |
| 13137 | engañaban | 2 |
| 13138 | enfurruñaba | 2 |
| 13139 | enfriado | 2 |
| 13140 | enfrenar | 2 |
| 13141 | enfermiza | 2 |
| 13142 | enfático | 2 |
| 13143 | enfática | 2 |
| 13144 | enfadas | 2 |
| 13145 | enfadado | 2 |
| 13146 | enfadaba | 2 |
| 13147 | enérgicos | 2 |
| 13148 | endilgó | 2 |
| 13149 | endiablada | 2 |
| 13150 | enderezando | 2 |
| 13151 | endemoniada | 2 |
| 13152 | encuentres | 2 |
| 13153 | encorvado | 2 |
| 13154 | encontrose | 2 |
| 13155 | encontronazo | 2 |
| 13156 | encontreme | 2 |
| 13157 | encontrarle | 2 |
| 13158 | encontrará | 2 |
| 13159 | encontradizo | 2 |
| 13160 | encontrábamos | 2 |
| 13161 | encogidos | 2 |
| 13162 | encienden | 2 |
| 13163 | encerrose | 2 |
| 13164 | encerrar | 2 |
| 13165 | encerrados | 2 |
| 13166 | encerradita | 2 |
| 13167 | encerradas | 2 |
| 13168 | encendían | 2 |
| 13169 | encefalitis | 2 |
| 13170 | encargándole | 2 |
| 13171 | encargando | 2 |
| 13172 | encargaba | 2 |
| 13173 | encarar | 2 |
| 13174 | encarándose | 2 |
| 13175 | encaramándose | 2 |
| 13176 | encantos | 2 |
| 13177 | encantado | 2 |
| 13178 | encantada | 2 |
| 13179 | encantaban | 2 |
| 13180 | encantaba | 2 |
| 13181 | encaminado | 2 |
| 13182 | encalabrinado | 2 |
| 13183 | encaje | 2 |
| 13184 | encajado | 2 |
| 13185 | encadenamiento | 2 |
| 13186 | enamorar | 2 |
| 13187 | enamorados | 2 |
| 13188 | enamorada | 2 |
| 13189 | empuñó | 2 |
| 13190 | empuñando | 2 |
| 13191 | empujón | 2 |
| 13192 | empujaron | 2 |
| 13193 | empujar | 2 |
| 13194 | empujándola | 2 |
| 13195 | empujan | 2 |
| 13196 | empréstito | 2 |
| 13197 | emprendieron | 2 |
| 13198 | emprendedor | 2 |
| 13199 | empolvado | 2 |
| 13200 | empleomanía | 2 |
| 13201 | empleó | 2 |
| 13202 | emplee | 2 |
| 13203 | emplearon | 2 |
| 13204 | emplean | 2 |
| 13205 | empleada | 2 |
| 13206 | empinada | 2 |
| 13207 | empiezas | 2 |
| 13208 | empiece | 2 |
| 13209 | empezamos | 2 |
| 13210 | empeñe | 2 |
| 13211 | empeñar | 2 |
| 13212 | empeñada | 2 |
| 13213 | empecé | 2 |
| 13214 | empaquetado | 2 |
| 13215 | empapado | 2 |
| 13216 | empañados | 2 |
| 13217 | eminencia | 2 |
| 13218 | embustes | 2 |
| 13219 | embustera | 2 |
| 13220 | embrutecimiento | 2 |
| 13221 | embrujado | 2 |
| 13222 | embozó | 2 |
| 13223 | embozado | 2 |
| 13224 | emborrachaba | 2 |
| 13225 | embocó | 2 |
| 13226 | embistió | 2 |
| 13227 | embeleso | 2 |
| 13228 | embebecido | 2 |
| 13229 | embebecía | 2 |
| 13230 | embarazada | 2 |
| 13231 | embajada | 2 |
| 13232 | emanación | 2 |
| 13233 | emanaba | 2 |
| 13234 | emana | 2 |
| 13235 | elogio | 2 |
| 13236 | elogiaba | 2 |
| 13237 | elocuente | 2 |
| 13238 | elevarse | 2 |
| 13239 | elevar | 2 |
| 13240 | elevadas | 2 |
| 13241 | elementos | 2 |
| 13242 | elegantísima | 2 |
| 13243 | electricidad | 2 |
| 13244 | electoral | 2 |
| 13245 | ejes | 2 |
| 13246 | ejercitar | 2 |
| 13247 | ejercen | 2 |
| 13248 | ejemplaridad | 2 |
| 13249 | ejecutivo | 2 |
| 13250 | egoistón | 2 |
| 13251 | egoístas | 2 |
| 13252 | egipto | 2 |
| 13253 | egipcia | 2 |
| 13254 | efigie | 2 |
| 13255 | eficacísimo | 2 |
| 13256 | eficacia | 2 |
| 13257 | educatriz | 2 |
| 13258 | educativas | 2 |
| 13259 | educarla | 2 |
| 13260 | educar | 2 |
| 13261 | edredón | 2 |
| 13262 | editores | 2 |
| 13263 | ecos | 2 |
| 13264 | económicos | 2 |
| 13265 | eclipsaba | 2 |
| 13266 | eclesiásticas | 2 |
| 13267 | échate | 2 |
| 13268 | echaremos | 2 |
| 13269 | echándosela | 2 |
| 13270 | echados | 2 |
| 13271 | echábaselas | 2 |
| 13272 | durmientes | 2 |
| 13273 | durmiente | 2 |
| 13274 | durito | 2 |
| 13275 | dure | 2 |
| 13276 | duraron | 2 |
| 13277 | durar | 2 |
| 13278 | duramente | 2 |
| 13279 | duquesas | 2 |
| 13280 | dulzona | 2 |
| 13281 | duermen | 2 |
| 13282 | dueñas | 2 |
| 13283 | duelen | 2 |
| 13284 | dudó | 2 |
| 13285 | dudes | 2 |
| 13286 | dudarse | 2 |
| 13287 | dudarlo | 2 |
| 13288 | dudando | 2 |
| 13289 | droga | 2 |
| 13290 | dramáticos | 2 |
| 13291 | drama | 2 |
| 13292 | doscientas | 2 |
| 13293 | dorregaray | 2 |
| 13294 | dormirme | 2 |
| 13295 | dormidito | 2 |
| 13296 | dormían | 2 |
| 13297 | dormí | 2 |
| 13298 | dorada | 2 |
| 13299 | doncellas | 2 |
| 13300 | donaires | 2 |
| 13301 | domingueras | 2 |
| 13302 | dominaron | 2 |
| 13303 | dominarle | 2 |
| 13304 | dominando | 2 |
| 13305 | domésticas | 2 |
| 13306 | domada | 2 |
| 13307 | doler | 2 |
| 13308 | docto | 2 |
| 13309 | docilidad | 2 |
| 13310 | dócil | 2 |
| 13311 | dobleces | 2 |
| 13312 | doblaron | 2 |
| 13313 | doblándose | 2 |
| 13314 | doblaba | 2 |
| 13315 | divirtiéndote | 2 |
| 13316 | divierten | 2 |
| 13317 | divierte | 2 |
| 13318 | divierta | 2 |
| 13319 | dividieron | 2 |
| 13320 | divide | 2 |
| 13321 | divertidas | 2 |
| 13322 | divertida | 2 |
| 13323 | divertían | 2 |
| 13324 | distrito | 2 |
| 13325 | distribuir | 2 |
| 13326 | distraerme | 2 |
| 13327 | distintivo | 2 |
| 13328 | distinguiendo | 2 |
| 13329 | distinguidos | 2 |
| 13330 | distinguido | 2 |
| 13331 | distinguidas | 2 |
| 13332 | distinguida | 2 |
| 13333 | distinguen | 2 |
| 13334 | distancias | 2 |
| 13335 | disputas | 2 |
| 13336 | disputar | 2 |
| 13337 | disputaba | 2 |
| 13338 | dispuestos | 2 |
| 13339 | disponiendo | 2 |
| 13340 | disponga | 2 |
| 13341 | dispensar | 2 |
| 13342 | disparidad | 2 |
| 13343 | disparatado | 2 |
| 13344 | disparatadas | 2 |
| 13345 | disparadero | 2 |
| 13346 | disolviendo | 2 |
| 13347 | disipado | 2 |
| 13348 | disimularla | 2 |
| 13349 | disgustado | 2 |
| 13350 | disfrutan | 2 |
| 13351 | disfavor | 2 |
| 13352 | discutiendo | 2 |
| 13353 | discusiones | 2 |
| 13354 | discursos | 2 |
| 13355 | disculpando | 2 |
| 13356 | discípulos | 2 |
| 13357 | disciplinas | 2 |
| 13358 | dirigirlo | 2 |
| 13359 | dirigido | 2 |
| 13360 | dirigida | 2 |
| 13361 | dirigía | 2 |
| 13362 | dirigen | 2 |
| 13363 | dirige | 2 |
| 13364 | diríale | 2 |
| 13365 | diretes | 2 |
| 13366 | directo | 2 |
| 13367 | directa | 2 |
| 13368 | diputado | 2 |
| 13369 | diócesis | 2 |
| 13370 | dinerales | 2 |
| 13371 | dimisión | 2 |
| 13372 | diminutivo | 2 |
| 13373 | dimes | 2 |
| 13374 | diluvio | 2 |
| 13375 | dilatado | 2 |
| 13376 | dijimos | 2 |
| 13377 | dignas | 2 |
| 13378 | digámoslo | 2 |
| 13379 | difusa | 2 |
| 13380 | diéronle | 2 |
| 13381 | diego | 2 |
| 13382 | dieciséis | 2 |
| 13383 | dictadas | 2 |
| 13384 | dicta | 2 |
| 13385 | diciéndoles | 2 |
| 13386 | dibujo | 2 |
| 13387 | diapasón | 2 |
| 13388 | diabólico | 2 |
| 13389 | devoró | 2 |
| 13390 | devolvió | 2 |
| 13391 | devolvía | 2 |
| 13392 | devolución | 2 |
| 13393 | devaneo | 2 |
| 13394 | devane | 2 |
| 13395 | devanaba | 2 |
| 13396 | deudos | 2 |
| 13397 | deudores | 2 |
| 13398 | detuviéronse | 2 |
| 13399 | detuvieron | 2 |
| 13400 | detuvieran | 2 |
| 13401 | detiene | 2 |
| 13402 | determinose | 2 |
| 13403 | detenerme | 2 |
| 13404 | desvergüenza | 2 |
| 13405 | desventurada | 2 |
| 13406 | desvelos | 2 |
| 13407 | desvarío | 2 |
| 13408 | desvanecida | 2 |
| 13409 | destruyendo | 2 |
| 13410 | destruyen | 2 |
| 13411 | destruir | 2 |
| 13412 | destrozados | 2 |
| 13413 | destreza | 2 |
| 13414 | destinos | 2 |
| 13415 | destinillo | 2 |
| 13416 | destinados | 2 |
| 13417 | destinado | 2 |
| 13418 | destinadas | 2 |
| 13419 | destinada | 2 |
| 13420 | desterrar | 2 |
| 13421 | desterrado | 2 |
| 13422 | desprende | 2 |
| 13423 | despreciarle | 2 |
| 13424 | despreciable | 2 |
| 13425 | despreciaba | 2 |
| 13426 | déspota | 2 |
| 13427 | desposada | 2 |
| 13428 | desplomó | 2 |
| 13429 | desplomarse | 2 |
| 13430 | despintadas | 2 |
| 13431 | despidiéronse | 2 |
| 13432 | despide | 2 |
| 13433 | despertara | 2 |
| 13434 | despertando | 2 |
| 13435 | desperdicios | 2 |
| 13436 | despejo | 2 |
| 13437 | despejar | 2 |
| 13438 | despeinada | 2 |
| 13439 | despego | 2 |
| 13440 | despega | 2 |
| 13441 | despedirme | 2 |
| 13442 | despedirla | 2 |
| 13443 | despavorida | 2 |
| 13444 | despachaderas | 2 |
| 13445 | despabiló | 2 |
| 13446 | despabilo | 2 |
| 13447 | despabilarse | 2 |
| 13448 | despabilándose | 2 |
| 13449 | despabilada | 2 |
| 13450 | desolación | 2 |
| 13451 | desnudaba | 2 |
| 13452 | desmentirse | 2 |
| 13453 | desmentiría | 2 |
| 13454 | desmentir | 2 |
| 13455 | desmentía | 2 |
| 13456 | desmedrado | 2 |
| 13457 | desmayo | 2 |
| 13458 | desmayar | 2 |
| 13459 | desmaya | 2 |
| 13460 | desmañado | 2 |
| 13461 | desmandarse | 2 |
| 13462 | deslomo | 2 |
| 13463 | deslizaba | 2 |
| 13464 | desleían | 2 |
| 13465 | desilusionó | 2 |
| 13466 | desiguales | 2 |
| 13467 | desigualdad | 2 |
| 13468 | desierta | 2 |
| 13469 | deshonroso | 2 |
| 13470 | deshonre | 2 |
| 13471 | deshonor | 2 |
| 13472 | deshilachados | 2 |
| 13473 | deshilachado | 2 |
| 13474 | deshago | 2 |
| 13475 | deshacerse | 2 |
| 13476 | desgarrada | 2 |
| 13477 | desgarraba | 2 |
| 13478 | desgarbado | 2 |
| 13479 | desgana | 2 |
| 13480 | desgajaba | 2 |
| 13481 | desgaire | 2 |
| 13482 | desflorando | 2 |
| 13483 | desfilando | 2 |
| 13484 | desfilaban | 2 |
| 13485 | desfavorable | 2 |
| 13486 | desenvueltas | 2 |
| 13487 | desempeñara | 2 |
| 13488 | desembuchaba | 2 |
| 13489 | desembozándose | 2 |
| 13490 | desechos | 2 |
| 13491 | deseas | 2 |
| 13492 | deseaban | 2 |
| 13493 | desdigo | 2 |
| 13494 | desdenes | 2 |
| 13495 | descuidado | 2 |
| 13496 | descubro | 2 |
| 13497 | descubriese | 2 |
| 13498 | descubriéndose | 2 |
| 13499 | descubriendo | 2 |
| 13500 | descubra | 2 |
| 13501 | descubiertas | 2 |
| 13502 | descrédito | 2 |
| 13503 | descosido | 2 |
| 13504 | descortés | 2 |
| 13505 | desconsoladas | 2 |
| 13506 | desconocía | 2 |
| 13507 | desconfiaba | 2 |
| 13508 | desconcertada | 2 |
| 13509 | descomunal | 2 |
| 13510 | descompuso | 2 |
| 13511 | descomponía | 2 |
| 13512 | descompone | 2 |
| 13513 | descolgar | 2 |
| 13514 | descifrar | 2 |
| 13515 | descendió | 2 |
| 13516 | descendientes | 2 |
| 13517 | descender | 2 |
| 13518 | descendencia | 2 |
| 13519 | descendemos | 2 |
| 13520 | descarriada | 2 |
| 13521 | descargado | 2 |
| 13522 | descaradamente | 2 |
| 13523 | descansos | 2 |
| 13524 | descalzos | 2 |
| 13525 | descabezar | 2 |
| 13526 | desazones | 2 |
| 13527 | desavenencias | 2 |
| 13528 | desató | 2 |
| 13529 | desatinar | 2 |
| 13530 | desatinado | 2 |
| 13531 | desatinada | 2 |
| 13532 | desastroso | 2 |
| 13533 | desarrollar | 2 |
| 13534 | desarrollando | 2 |
| 13535 | desarmada | 2 |
| 13536 | desaparición | 2 |
| 13537 | desapacible | 2 |
| 13538 | desanimaba | 2 |
| 13539 | desalquilado | 2 |
| 13540 | desalentada | 2 |
| 13541 | desalado | 2 |
| 13542 | desahogar | 2 |
| 13543 | desaguisado | 2 |
| 13544 | desagradables | 2 |
| 13545 | desacato | 2 |
| 13546 | derrumbaba | 2 |
| 13547 | derrota | 2 |
| 13548 | derribo | 2 |
| 13549 | derribados | 2 |
| 13550 | derredor | 2 |
| 13551 | derivan | 2 |
| 13552 | derechito | 2 |
| 13553 | depresiones | 2 |
| 13554 | depreciación | 2 |
| 13555 | depravación | 2 |
| 13556 | depósitos | 2 |
| 13557 | depositaría | 2 |
| 13558 | deplorando | 2 |
| 13559 | denuncias | 2 |
| 13560 | dengoso | 2 |
| 13561 | demuestra | 2 |
| 13562 | demostración | 2 |
| 13563 | demostraba | 2 |
| 13564 | demos | 2 |
| 13565 | demonches | 2 |
| 13566 | democrático | 2 |
| 13567 | demagogia | 2 |
| 13568 | delirando | 2 |
| 13569 | deliraba | 2 |
| 13570 | delineantes | 2 |
| 13571 | delicadísimo | 2 |
| 13572 | delicadezas | 2 |
| 13573 | delgada | 2 |
| 13574 | deleites | 2 |
| 13575 | dele | 2 |
| 13576 | dejosas | 2 |
| 13577 | dejos | 2 |
| 13578 | dejarlas | 2 |
| 13579 | dejará | 2 |
| 13580 | dejándote | 2 |
| 13581 | dejándoles | 2 |
| 13582 | dejamos | 2 |
| 13583 | déjale | 2 |
| 13584 | dejábase | 2 |
| 13585 | degradación | 2 |
| 13586 | deforme | 2 |
| 13587 | definitivamente | 2 |
| 13588 | definir | 2 |
| 13589 | definición | 2 |
| 13590 | defendió | 2 |
| 13591 | defendido | 2 |
| 13592 | defendían | 2 |
| 13593 | defenderme | 2 |
| 13594 | defenderé | 2 |
| 13595 | dedito | 2 |
| 13596 | dedicarme | 2 |
| 13597 | decorosa | 2 |
| 13598 | declarado | 2 |
| 13599 | decírsela | 2 |
| 13600 | decidirá | 2 |
| 13601 | decidía | 2 |
| 13602 | dechado | 2 |
| 13603 | decálogo | 2 |
| 13604 | decaimiento | 2 |
| 13605 | decadencia | 2 |
| 13606 | debida | 2 |
| 13607 | debías | 2 |
| 13608 | debíamos | 2 |
| 13609 | deambulación | 2 |
| 13610 | databa | 2 |
| 13611 | darnos | 2 |
| 13612 | darla | 2 |
| 13613 | dardo | 2 |
| 13614 | daña | 2 |
| 13615 | dándoles | 2 |
| 13616 | dándolas | 2 |
| 13617 | dámele | 2 |
| 13618 | dais | 2 |
| 13619 | dádivas | 2 |
| 13620 | dábase | 2 |
| 13621 | cutis | 2 |
| 13622 | curtis | 2 |
| 13623 | curiosa | 2 |
| 13624 | curial | 2 |
| 13625 | cure | 2 |
| 13626 | curaría | 2 |
| 13627 | curan | 2 |
| 13628 | curada | 2 |
| 13629 | cúpula | 2 |
| 13630 | cundía | 2 |
| 13631 | cúmulo | 2 |
| 13632 | cumplo | 2 |
| 13633 | cumplió | 2 |
| 13634 | cumpliendo | 2 |
| 13635 | cumplida | 2 |
| 13636 | cultura | 2 |
| 13637 | cultivado | 2 |
| 13638 | cultivada | 2 |
| 13639 | cuidó | 2 |
| 13640 | cuidaban | 2 |
| 13641 | cuervos | 2 |
| 13642 | cuerdos | 2 |
| 13643 | cuentecita | 2 |
| 13644 | cuellos | 2 |
| 13645 | cucurucho | 2 |
| 13646 | cuchillos | 2 |
| 13647 | cucharadas | 2 |
| 13648 | cubrirla | 2 |
| 13649 | cubrir | 2 |
| 13650 | cubrió | 2 |
| 13651 | cubo | 2 |
| 13652 | cubiertas | 2 |
| 13653 | cúbico | 2 |
| 13654 | cubas | 2 |
| 13655 | cuartillo | 2 |
| 13656 | cuarterón | 2 |
| 13657 | cuarentena | 2 |
| 13658 | cualsiquiera | 2 |
| 13659 | cuajarones | 2 |
| 13660 | cuadrote | 2 |
| 13661 | cuadritos | 2 |
| 13662 | cuadrito | 2 |
| 13663 | cuadrilátero | 2 |
| 13664 | cuadernillos | 2 |
| 13665 | cruzaron | 2 |
| 13666 | cruzan | 2 |
| 13667 | cruzaba | 2 |
| 13668 | crujir | 2 |
| 13669 | crucero | 2 |
| 13670 | cromo | 2 |
| 13671 | críticos | 2 |
| 13672 | críticas | 2 |
| 13673 | cristina | 2 |
| 13674 | cristianas | 2 |
| 13675 | crió | 2 |
| 13676 | criaturita | 2 |
| 13677 | crías | 2 |
| 13678 | criarle | 2 |
| 13679 | criamos | 2 |
| 13680 | criadita | 2 |
| 13681 | cretona | 2 |
| 13682 | creída | 2 |
| 13683 | creíase | 2 |
| 13684 | creerle | 2 |
| 13685 | creencias | 2 |
| 13686 | creemos | 2 |
| 13687 | créemelo | 2 |
| 13688 | creciente | 2 |
| 13689 | creciendo | 2 |
| 13690 | crean | 2 |
| 13691 | créamelo | 2 |
| 13692 | creados | 2 |
| 13693 | creador | 2 |
| 13694 | crasa | 2 |
| 13695 | cotorrearon | 2 |
| 13696 | cotarro | 2 |
| 13697 | costurera | 2 |
| 13698 | costeó | 2 |
| 13699 | cositas | 2 |
| 13700 | cosita | 2 |
| 13701 | cosecha | 2 |
| 13702 | cose | 2 |
| 13703 | corva | 2 |
| 13704 | coruñas | 2 |
| 13705 | cortesías | 2 |
| 13706 | corté | 2 |
| 13707 | cortarse | 2 |
| 13708 | cortaron | 2 |
| 13709 | cortarle | 2 |
| 13710 | cortaran | 2 |
| 13711 | cortándole | 2 |
| 13712 | cortando | 2 |
| 13713 | cortados | 2 |
| 13714 | cortadillo | 2 |
| 13715 | cortaban | 2 |
| 13716 | corruptor | 2 |
| 13717 | corrupción | 2 |
| 13718 | corrompida | 2 |
| 13719 | corroborando | 2 |
| 13720 | corrigió | 2 |
| 13721 | corriese | 2 |
| 13722 | corresponder | 2 |
| 13723 | corren | 2 |
| 13724 | corregir | 2 |
| 13725 | corregida | 2 |
| 13726 | correctamente | 2 |
| 13727 | correccional | 2 |
| 13728 | corporación | 2 |
| 13729 | corpacho | 2 |
| 13730 | cornezuelo | 2 |
| 13731 | cornetas | 2 |
| 13732 | corizas | 2 |
| 13733 | coriza | 2 |
| 13734 | córdoba | 2 |
| 13735 | cordial | 2 |
| 13736 | cordera | 2 |
| 13737 | cordel | 2 |
| 13738 | corcho | 2 |
| 13739 | corbatas | 2 |
| 13740 | corazonadas | 2 |
| 13741 | corales | 2 |
| 13742 | copita | 2 |
| 13743 | copioso | 2 |
| 13744 | copiaba | 2 |
| 13745 | cónyuges | 2 |
| 13746 | conyugales | 2 |
| 13747 | conyugal | 2 |
| 13748 | convulsiones | 2 |
| 13749 | convirtiose | 2 |
| 13750 | convidaron | 2 |
| 13751 | convidar | 2 |
| 13752 | convidando | 2 |
| 13753 | convidado | 2 |
| 13754 | convicciones | 2 |
| 13755 | convertirla | 2 |
| 13756 | convertimos | 2 |
| 13757 | convertida | 2 |
| 13758 | conveniencia | 2 |
| 13759 | conveníale | 2 |
| 13760 | convengo | 2 |
| 13761 | convenció | 2 |
| 13762 | convenciera | 2 |
| 13763 | convenciendo | 2 |
| 13764 | convencerse | 2 |
| 13765 | convencerle | 2 |
| 13766 | convencerla | 2 |
| 13767 | convence | 2 |
| 13768 | convaleciente | 2 |
| 13769 | convalecencia | 2 |
| 13770 | contusiones | 2 |
| 13771 | contusión | 2 |
| 13772 | contundentes | 2 |
| 13773 | contundente | 2 |
| 13774 | controversia | 2 |
| 13775 | contrición | 2 |
| 13776 | contribuir | 2 |
| 13777 | contrato | 2 |
| 13778 | contratiempos | 2 |
| 13779 | contrata | 2 |
| 13780 | contrastes | 2 |
| 13781 | contrasentido | 2 |
| 13782 | contrariarle | 2 |
| 13783 | contrariaba | 2 |
| 13784 | contradecir | 2 |
| 13785 | contradecían | 2 |
| 13786 | contole | 2 |
| 13787 | continuas | 2 |
| 13788 | contiene | 2 |
| 13789 | contienda | 2 |
| 13790 | contestole | 2 |
| 13791 | contesté | 2 |
| 13792 | conteste | 2 |
| 13793 | contestaron | 2 |
| 13794 | contestara | 2 |
| 13795 | contestando | 2 |
| 13796 | contestado | 2 |
| 13797 | contestaciones | 2 |
| 13798 | contentas | 2 |
| 13799 | contentarse | 2 |
| 13800 | contenerle | 2 |
| 13801 | contenerla | 2 |
| 13802 | contemplativa | 2 |
| 13803 | contemplado | 2 |
| 13804 | contaron | 2 |
| 13805 | contarlas | 2 |
| 13806 | contagio | 2 |
| 13807 | contador | 2 |
| 13808 | contada | 2 |
| 13809 | contabilidad | 2 |
| 13810 | consumos | 2 |
| 13811 | consumo | 2 |
| 13812 | consumir | 2 |
| 13813 | consume | 2 |
| 13814 | consumar | 2 |
| 13815 | consumada | 2 |
| 13816 | consultara | 2 |
| 13817 | consultaba | 2 |
| 13818 | consuelan | 2 |
| 13819 | construida | 2 |
| 13820 | constituyéndose | 2 |
| 13821 | constituía | 2 |
| 13822 | constipar | 2 |
| 13823 | consternado | 2 |
| 13824 | constar | 2 |
| 13825 | constantes | 2 |
| 13826 | conspiración | 2 |
| 13827 | consortes | 2 |
| 13828 | consoló | 2 |
| 13829 | consolara | 2 |
| 13830 | consolando | 2 |
| 13831 | consoladora | 2 |
| 13832 | consolábase | 2 |
| 13833 | consintió | 2 |
| 13834 | consintiera | 2 |
| 13835 | consienta | 2 |
| 13836 | consideró | 2 |
| 13837 | considero | 2 |
| 13838 | considere | 2 |
| 13839 | considerándose | 2 |
| 13840 | considerándole | 2 |
| 13841 | consideran | 2 |
| 13842 | considerable | 2 |
| 13843 | considera | 2 |
| 13844 | conservatorio | 2 |
| 13845 | conservado | 2 |
| 13846 | consagró | 2 |
| 13847 | consagrados | 2 |
| 13848 | consagrada | 2 |
| 13849 | consagración | 2 |
| 13850 | consagraba | 2 |
| 13851 | conquistas | 2 |
| 13852 | conozcan | 2 |
| 13853 | conocieran | 2 |
| 13854 | conocerse | 2 |
| 13855 | conmoción | 2 |
| 13856 | conmiseración | 2 |
| 13857 | conllevar | 2 |
| 13858 | confuso | 2 |
| 13859 | confusiones | 2 |
| 13860 | confundidas | 2 |
| 13861 | confundían | 2 |
| 13862 | confundía | 2 |
| 13863 | confió | 2 |
| 13864 | confines | 2 |
| 13865 | configuración | 2 |
| 13866 | confidente | 2 |
| 13867 | confiar | 2 |
| 13868 | confianzudo | 2 |
| 13869 | confianzuda | 2 |
| 13870 | confiado | 2 |
| 13871 | confesarme | 2 |
| 13872 | confesado | 2 |
| 13873 | confesaba | 2 |
| 13874 | confecciones | 2 |
| 13875 | conejos | 2 |
| 13876 | conejo | 2 |
| 13877 | conducir | 2 |
| 13878 | condescendencia | 2 |
| 13879 | condensaba | 2 |
| 13880 | condenes | 2 |
| 13881 | condena | 2 |
| 13882 | concurría | 2 |
| 13883 | concubinato | 2 |
| 13884 | concreto | 2 |
| 13885 | concluyen | 2 |
| 13886 | concluía | 2 |
| 13887 | conciliadora | 2 |
| 13888 | conciliador | 2 |
| 13889 | conciliación | 2 |
| 13890 | concha | 2 |
| 13891 | concertando | 2 |
| 13892 | concertada | 2 |
| 13893 | conceptuaba | 2 |
| 13894 | concedido | 2 |
| 13895 | concavidad | 2 |
| 13896 | comunicarse | 2 |
| 13897 | comunicaron | 2 |
| 13898 | comunicando | 2 |
| 13899 | comunicaban | 2 |
| 13900 | comulgan | 2 |
| 13901 | compungida | 2 |
| 13902 | compuesto | 2 |
| 13903 | comprometía | 2 |
| 13904 | comprometer | 2 |
| 13905 | comprometas | 2 |
| 13906 | compres | 2 |
| 13907 | comprendida | 2 |
| 13908 | compradora | 2 |
| 13909 | compradas | 2 |
| 13910 | compota | 2 |
| 13911 | composturas | 2 |
| 13912 | componendas | 2 |
| 13913 | compone | 2 |
| 13914 | complicidad | 2 |
| 13915 | complicada | 2 |
| 13916 | complicación | 2 |
| 13917 | completaba | 2 |
| 13918 | complaciente | 2 |
| 13919 | complacencia | 2 |
| 13920 | compensaba | 2 |
| 13921 | comparó | 2 |
| 13922 | comparo | 2 |
| 13923 | compararme | 2 |
| 13924 | compañías | 2 |
| 13925 | compadezco | 2 |
| 13926 | compadecía | 2 |
| 13927 | compadecer | 2 |
| 13928 | compadece | 2 |
| 13929 | comisiones | 2 |
| 13930 | comiera | 2 |
| 13931 | comienzos | 2 |
| 13932 | cometiera | 2 |
| 13933 | cometían | 2 |
| 13934 | cometer | 2 |
| 13935 | comerías | 2 |
| 13936 | comedero | 2 |
| 13937 | combinando | 2 |
| 13938 | combatirle | 2 |
| 13939 | combatientes | 2 |
| 13940 | columnas | 2 |
| 13941 | colorista | 2 |
| 13942 | colonias | 2 |
| 13943 | colocó | 2 |
| 13944 | colocase | 2 |
| 13945 | colocaron | 2 |
| 13946 | colocara | 2 |
| 13947 | colocados | 2 |
| 13948 | colocadas | 2 |
| 13949 | colgándose | 2 |
| 13950 | colgada | 2 |
| 13951 | colgaba | 2 |
| 13952 | coleto | 2 |
| 13953 | colérica | 2 |
| 13954 | colegas | 2 |
| 13955 | colección | 2 |
| 13956 | coincidir | 2 |
| 13957 | cogiéndose | 2 |
| 13958 | coges | 2 |
| 13959 | cogerlos | 2 |
| 13960 | cogen | 2 |
| 13961 | codearse | 2 |
| 13962 | cocinilla | 2 |
| 13963 | cocinerita | 2 |
| 13964 | cocinas | 2 |
| 13965 | cociendo | 2 |
| 13966 | cocía | 2 |
| 13967 | cochina | 2 |
| 13968 | cobro | 2 |
| 13969 | cobrando | 2 |
| 13970 | club | 2 |
| 13971 | clorótica | 2 |
| 13972 | clorhidrato | 2 |
| 13973 | clínicas | 2 |
| 13974 | cleriguito | 2 |
| 13975 | claveteado | 2 |
| 13976 | clavelero | 2 |
| 13977 | clavadas | 2 |
| 13978 | claustral | 2 |
| 13979 | clarita | 2 |
| 13980 | clarear | 2 |
| 13981 | claraboyas | 2 |
| 13982 | claque | 2 |
| 13983 | ciudades | 2 |
| 13984 | citunas | 2 |
| 13985 | citado | 2 |
| 13986 | citaba | 2 |
| 13987 | cisterna | 2 |
| 13988 | cisco | 2 |
| 13989 | cirio | 2 |
| 13990 | circular | 2 |
| 13991 | cintas | 2 |
| 13992 | cinismo | 2 |
| 13993 | cimientos | 2 |
| 13994 | cierran | 2 |
| 13995 | ciencias | 2 |
| 13996 | ciegamente | 2 |
| 13997 | chusma | 2 |
| 13998 | chusco | 2 |
| 13999 | chuscadas | 2 |
| 14000 | churumbé | 2 |
| 14001 | chumbos | 2 |
| 14002 | chulas | 2 |
| 14003 | chufas | 2 |
| 14004 | chuchería | 2 |
| 14005 | chubasco | 2 |
| 14006 | chubasca | 2 |
| 14007 | choza | 2 |
| 14008 | chorro | 2 |
| 14009 | chorreaban | 2 |
| 14010 | chocolatito | 2 |
| 14011 | chocolates | 2 |
| 14012 | chocolatera | 2 |
| 14013 | chocheces | 2 |
| 14014 | chocando | 2 |
| 14015 | chitito | 2 |
| 14016 | chistó | 2 |
| 14017 | chisté | 2 |
| 14018 | chistaba | 2 |
| 14019 | chispita | 2 |
| 14020 | chispeantes | 2 |
| 14021 | chismes | 2 |
| 14022 | chirris | 2 |
| 14023 | chiquititas | 2 |
| 14024 | chiquilladas | 2 |
| 14025 | chiquillada | 2 |
| 14026 | chínchirri | 2 |
| 14027 | chinche | 2 |
| 14028 | chillería | 2 |
| 14029 | chifle | 2 |
| 14030 | chiflarse | 2 |
| 14031 | chifladura | 2 |
| 14032 | chiflados | 2 |
| 14033 | chifla | 2 |
| 14034 | chicuela | 2 |
| 14035 | chic | 2 |
| 14036 | chi | 2 |
| 14037 | cheong | 2 |
| 14038 | chavales | 2 |
| 14039 | chavala | 2 |
| 14040 | chata | 2 |
| 14041 | chascos | 2 |
| 14042 | charol | 2 |
| 14043 | charlatánicas | 2 |
| 14044 | charlaban | 2 |
| 14045 | charlaba | 2 |
| 14046 | charca | 2 |
| 14047 | chaquetas | 2 |
| 14048 | chaqueta | 2 |
| 14049 | chaqué | 2 |
| 14050 | chanchullos | 2 |
| 14051 | chamusquina | 2 |
| 14052 | chambras | 2 |
| 14053 | chales | 2 |
| 14054 | chalana | 2 |
| 14055 | chafalditas | 2 |
| 14056 | chafado | 2 |
| 14057 | chafada | 2 |
| 14058 | cháchara | 2 |
| 14059 | cevil | 2 |
| 14060 | ceuta | 2 |
| 14061 | cesantía | 2 |
| 14062 | cesantes | 2 |
| 14063 | cesaban | 2 |
| 14064 | cervantes | 2 |
| 14065 | certidumbre | 2 |
| 14066 | certeza | 2 |
| 14067 | cerrojos | 2 |
| 14068 | cerrase | 2 |
| 14069 | cerradura | 2 |
| 14070 | cerradas | 2 |
| 14071 | cerraban | 2 |
| 14072 | cerdos | 2 |
| 14073 | cerciorose | 2 |
| 14074 | ceñudo | 2 |
| 14075 | ceñidos | 2 |
| 14076 | centrales | 2 |
| 14077 | centigramo | 2 |
| 14078 | centeno | 2 |
| 14079 | cencerrada | 2 |
| 14080 | cenando | 2 |
| 14081 | celestina | 2 |
| 14082 | celeste | 2 |
| 14083 | celebró | 2 |
| 14084 | celador | 2 |
| 14085 | cejijunta | 2 |
| 14086 | cegó | 2 |
| 14087 | cedo | 2 |
| 14088 | cedió | 2 |
| 14089 | ceca | 2 |
| 14090 | cebollino | 2 |
| 14091 | cazar | 2 |
| 14092 | cazando | 2 |
| 14093 | cayese | 2 |
| 14094 | caviloso | 2 |
| 14095 | cavilaba | 2 |
| 14096 | cavernas | 2 |
| 14097 | caverna | 2 |
| 14098 | cavador | 2 |
| 14099 | cautivar | 2 |
| 14100 | cautivaban | 2 |
| 14101 | cautelosa | 2 |
| 14102 | causó | 2 |
| 14103 | causar | 2 |
| 14104 | causante | 2 |
| 14105 | causado | 2 |
| 14106 | caudillo | 2 |
| 14107 | caudaloso | 2 |
| 14108 | cato | 2 |
| 14109 | caten | 2 |
| 14110 | categóricas | 2 |
| 14111 | categóricamente | 2 |
| 14112 | catedrático | 2 |
| 14113 | catedrales | 2 |
| 14114 | catarroso | 2 |
| 14115 | catarlo | 2 |
| 14116 | catar | 2 |
| 14117 | catálogos | 2 |
| 14118 | catalán | 2 |
| 14119 | cataclismo | 2 |
| 14120 | castos | 2 |
| 14121 | castidad | 2 |
| 14122 | castellano | 2 |
| 14123 | castaño | 2 |
| 14124 | castañetazos | 2 |
| 14125 | castaña | 2 |
| 14126 | casillero | 2 |
| 14127 | cásese | 2 |
| 14128 | cases | 2 |
| 14129 | caserón | 2 |
| 14130 | caseríos | 2 |
| 14131 | cáscaras | 2 |
| 14132 | cascabel | 2 |
| 14133 | cásate | 2 |
| 14134 | casaría | 2 |
| 14135 | casaban | 2 |
| 14136 | casaba | 2 |
| 14137 | carunculosa | 2 |
| 14138 | cartones | 2 |
| 14139 | cartón | 2 |
| 14140 | cartitas | 2 |
| 14141 | carteles | 2 |
| 14142 | cartea | 2 |
| 14143 | carruaje | 2 |
| 14144 | carromato | 2 |
| 14145 | carromatero | 2 |
| 14146 | carreteros | 2 |
| 14147 | carretas | 2 |
| 14148 | carpanta | 2 |
| 14149 | carlismo | 2 |
| 14150 | cariz | 2 |
| 14151 | caritativo | 2 |
| 14152 | caritativas | 2 |
| 14153 | caritativa | 2 |
| 14154 | cariñosos | 2 |
| 14155 | caridades | 2 |
| 14156 | caricaturas | 2 |
| 14157 | cargó | 2 |
| 14158 | cargante | 2 |
| 14159 | cargamento | 2 |
| 14160 | cargaban | 2 |
| 14161 | carece | 2 |
| 14162 | cardenales | 2 |
| 14163 | carbonera | 2 |
| 14164 | carátula | 2 |
| 14165 | carantoñas | 2 |
| 14166 | caracol | 2 |
| 14167 | capotes | 2 |
| 14168 | capones | 2 |
| 14169 | capítulo | 2 |
| 14170 | capitana | 2 |
| 14171 | capitalito | 2 |
| 14172 | capitalista | 2 |
| 14173 | capirote | 2 |
| 14174 | capellanes | 2 |
| 14175 | capciosas | 2 |
| 14176 | capacidad | 2 |
| 14177 | capaces | 2 |
| 14178 | caoba | 2 |
| 14179 | cañamón | 2 |
| 14180 | cantos | 2 |
| 14181 | cantonales | 2 |
| 14182 | canteros | 2 |
| 14183 | cántaro | 2 |
| 14184 | cantaría | 2 |
| 14185 | cantan | 2 |
| 14186 | cansadas | 2 |
| 14187 | candorosamente | 2 |
| 14188 | candelabros | 2 |
| 14189 | canciller | 2 |
| 14190 | canaleja | 2 |
| 14191 | canal | 2 |
| 14192 | campechana | 2 |
| 14193 | campar | 2 |
| 14194 | campante | 2 |
| 14195 | campanillazo | 2 |
| 14196 | campanario | 2 |
| 14197 | campanada | 2 |
| 14198 | camisería | 2 |
| 14199 | camello | 2 |
| 14200 | cambrí | 2 |
| 14201 | cambiazos | 2 |
| 14202 | cambiaron | 2 |
| 14203 | cambiara | 2 |
| 14204 | cambiante | 2 |
| 14205 | cambiando | 2 |
| 14206 | camas | 2 |
| 14207 | camarada | 2 |
| 14208 | calzonazos | 2 |
| 14209 | calzados | 2 |
| 14210 | calzada | 2 |
| 14211 | calza | 2 |
| 14212 | calvas | 2 |
| 14213 | calvario | 2 |
| 14214 | calurosos | 2 |
| 14215 | calumnió | 2 |
| 14216 | calores | 2 |
| 14217 | cálmese | 2 |
| 14218 | calmarse | 2 |
| 14219 | calmaba | 2 |
| 14220 | callosa | 2 |
| 14221 | callejera | 2 |
| 14222 | calladas | 2 |
| 14223 | callaban | 2 |
| 14224 | calidad | 2 |
| 14225 | calibre | 2 |
| 14226 | caldo | 2 |
| 14227 | caldeado | 2 |
| 14228 | caldeada | 2 |
| 14229 | calcule | 2 |
| 14230 | calculan | 2 |
| 14231 | calaveradas | 2 |
| 14232 | calambres | 2 |
| 14233 | calados | 2 |
| 14234 | calabozo | 2 |
| 14235 | calabaza | 2 |
| 14236 | cajitas | 2 |
| 14237 | caín | 2 |
| 14238 | caigo | 2 |
| 14239 | cafetero | 2 |
| 14240 | caerle | 2 |
| 14241 | caerás | 2 |
| 14242 | caderas | 2 |
| 14243 | cachetes | 2 |
| 14244 | cachemira | 2 |
| 14245 | cabizbajo | 2 |
| 14246 | cabildo | 2 |
| 14247 | cabían | 2 |
| 14248 | cabezada | 2 |
| 14249 | cabellos | 2 |
| 14250 | cabecita | 2 |
| 14251 | caballete | 2 |
| 14252 | caballerosidad | 2 |
| 14253 | caballera | 2 |
| 14254 | cabal | 2 |
| 14255 | cab | 2 |
| 14256 | buscarlos | 2 |
| 14257 | buscaré | 2 |
| 14258 | buscara | 2 |
| 14259 | buscándole | 2 |
| 14260 | buscan | 2 |
| 14261 | burradas | 2 |
| 14262 | burocráticas | 2 |
| 14263 | burlaba | 2 |
| 14264 | burda | 2 |
| 14265 | bultos | 2 |
| 14266 | bujías | 2 |
| 14267 | buey | 2 |
| 14268 | buenavista | 2 |
| 14269 | buche | 2 |
| 14270 | búcaros | 2 |
| 14271 | brutalidades | 2 |
| 14272 | brutales | 2 |
| 14273 | brujería | 2 |
| 14274 | brotar | 2 |
| 14275 | bromear | 2 |
| 14276 | brochar | 2 |
| 14277 | brochado | 2 |
| 14278 | brocal | 2 |
| 14279 | brindose | 2 |
| 14280 | brindó | 2 |
| 14281 | brindis | 2 |
| 14282 | brinco | 2 |
| 14283 | brillo | 2 |
| 14284 | brillantes | 2 |
| 14285 | brígida | 2 |
| 14286 | bribonaza | 2 |
| 14287 | bribonas | 2 |
| 14288 | bribón | 2 |
| 14289 | brevemente | 2 |
| 14290 | breva | 2 |
| 14291 | bregó | 2 |
| 14292 | bregar | 2 |
| 14293 | bregando | 2 |
| 14294 | brecolera | 2 |
| 14295 | bravura | 2 |
| 14296 | bravos | 2 |
| 14297 | bozo | 2 |
| 14298 | botonaduras | 2 |
| 14299 | botitas | 2 |
| 14300 | boticas | 2 |
| 14301 | boteros | 2 |
| 14302 | botellita | 2 |
| 14303 | botellas | 2 |
| 14304 | botarate | 2 |
| 14305 | bostezar | 2 |
| 14306 | borroso | 2 |
| 14307 | borrego | 2 |
| 14308 | borrando | 2 |
| 14309 | borrachera | 2 |
| 14310 | borlas | 2 |
| 14311 | bordados | 2 |
| 14312 | bordado | 2 |
| 14313 | bordadas | 2 |
| 14314 | borceguíes | 2 |
| 14315 | boquete | 2 |
| 14316 | bonos | 2 |
| 14317 | bonitísimos | 2 |
| 14318 | bonitísimo | 2 |
| 14319 | bónibus | 2 |
| 14320 | bondades | 2 |
| 14321 | bombo | 2 |
| 14322 | bomberos | 2 |
| 14323 | bolsistas | 2 |
| 14324 | bojío | 2 |
| 14325 | bodegones | 2 |
| 14326 | bodas | 2 |
| 14327 | bocaza | 2 |
| 14328 | bocados | 2 |
| 14329 | bobito | 2 |
| 14330 | bóbilis | 2 |
| 14331 | bobas | 2 |
| 14332 | bobalicón | 2 |
| 14333 | blanquísimos | 2 |
| 14334 | blanduras | 2 |
| 14335 | blandos | 2 |
| 14336 | bistec | 2 |
| 14337 | biografía | 2 |
| 14338 | billar | 2 |
| 14339 | bierzo | 2 |
| 14340 | bienestar | 2 |
| 14341 | bienaventurados | 2 |
| 14342 | besuqueos | 2 |
| 14343 | besarme | 2 |
| 14344 | besándole | 2 |
| 14345 | besado | 2 |
| 14346 | berzas | 2 |
| 14347 | berrinche | 2 |
| 14348 | berreaba | 2 |
| 14349 | bernardino | 2 |
| 14350 | bermellón | 2 |
| 14351 | bermejos | 2 |
| 14352 | berlina | 2 |
| 14353 | benigno | 2 |
| 14354 | benéfico | 2 |
| 14355 | beneficio | 2 |
| 14356 | benéficas | 2 |
| 14357 | benditas | 2 |
| 14358 | bendiciones | 2 |
| 14359 | bendecirán | 2 |
| 14360 | bellísima | 2 |
| 14361 | bellezas | 2 |
| 14362 | bellas | 2 |
| 14363 | béjar | 2 |
| 14364 | beethoven | 2 |
| 14365 | bedmar | 2 |
| 14366 | bebo | 2 |
| 14367 | bebió | 2 |
| 14368 | beberemos | 2 |
| 14369 | bebe | 2 |
| 14370 | beatriz | 2 |
| 14371 | beatas | 2 |
| 14372 | bazares | 2 |
| 14373 | batistas | 2 |
| 14374 | batidor | 2 |
| 14375 | batería | 2 |
| 14376 | batallas | 2 |
| 14377 | basurero | 2 |
| 14378 | basto | 2 |
| 14379 | bastidor | 2 |
| 14380 | bastas | 2 |
| 14381 | bastara | 2 |
| 14382 | bastado | 2 |
| 14383 | bastábale | 2 |
| 14384 | barruntaba | 2 |
| 14385 | barrionuevo | 2 |
| 14386 | barrabás | 2 |
| 14387 | barra | 2 |
| 14388 | bárbaros | 2 |
| 14389 | barbarie | 2 |
| 14390 | bárbaras | 2 |
| 14391 | baratas | 2 |
| 14392 | barajar | 2 |
| 14393 | bando | 2 |
| 14394 | bandido | 2 |
| 14395 | banderillas | 2 |
| 14396 | banderas | 2 |
| 14397 | baldosín | 2 |
| 14398 | baldosa | 2 |
| 14399 | balbuciente | 2 |
| 14400 | balanza | 2 |
| 14401 | balances | 2 |
| 14402 | bajen | 2 |
| 14403 | bajé | 2 |
| 14404 | baje | 2 |
| 14405 | bajas | 2 |
| 14406 | bajarlo | 2 |
| 14407 | bailad | 2 |
| 14408 | badulaques | 2 |
| 14409 | babilla | 2 |
| 14410 | babia | 2 |
| 14411 | baberos | 2 |
| 14412 | azuzaba | 2 |
| 14413 | azuleaba | 2 |
| 14414 | azucarillos | 2 |
| 14415 | azucarada | 2 |
| 14416 | azotes | 2 |
| 14417 | azoten | 2 |
| 14418 | azotaba | 2 |
| 14419 | azahares | 2 |
| 14420 | azahar | 2 |
| 14421 | ayudarás | 2 |
| 14422 | ayudante | 2 |
| 14423 | ayudadas | 2 |
| 14424 | ayudada | 2 |
| 14425 | ayudaban | 2 |
| 14426 | avivando | 2 |
| 14427 | avivaba | 2 |
| 14428 | avisos | 2 |
| 14429 | avise | 2 |
| 14430 | avisas | 2 |
| 14431 | avisaré | 2 |
| 14432 | avisadas | 2 |
| 14433 | avío | 2 |
| 14434 | avino | 2 |
| 14435 | ávida | 2 |
| 14436 | aviada | 2 |
| 14437 | averiguo | 2 |
| 14438 | averiguando | 2 |
| 14439 | avergonzada | 2 |
| 14440 | aventurera | 2 |
| 14441 | avanzara | 2 |
| 14442 | avanza | 2 |
| 14443 | auxilios | 2 |
| 14444 | autora | 2 |
| 14445 | auténtico | 2 |
| 14446 | ausentarse | 2 |
| 14447 | aumentaban | 2 |
| 14448 | aulas | 2 |
| 14449 | aujeritos | 2 |
| 14450 | augusto | 2 |
| 14451 | augusta | 2 |
| 14452 | atufado | 2 |
| 14453 | atufa | 2 |
| 14454 | atropina | 2 |
| 14455 | atrio | 2 |
| 14456 | atreviose | 2 |
| 14457 | atrevimientos | 2 |
| 14458 | atrevidas | 2 |
| 14459 | atrevíase | 2 |
| 14460 | atrevían | 2 |
| 14461 | atreveré | 2 |
| 14462 | atreva | 2 |
| 14463 | atravesada | 2 |
| 14464 | atrasada | 2 |
| 14465 | atraían | 2 |
| 14466 | atraer | 2 |
| 14467 | atracones | 2 |
| 14468 | atormentado | 2 |
| 14469 | atormentaban | 2 |
| 14470 | atormentaba | 2 |
| 14471 | atontadas | 2 |
| 14472 | atónito | 2 |
| 14473 | atiendo | 2 |
| 14474 | aterrador | 2 |
| 14475 | aterra | 2 |
| 14476 | atenuar | 2 |
| 14477 | atenuado | 2 |
| 14478 | atentado | 2 |
| 14479 | atengo | 2 |
| 14480 | atenciones | 2 |
| 14481 | atemperar | 2 |
| 14482 | ataúdes | 2 |
| 14483 | ataúd | 2 |
| 14484 | atarlas | 2 |
| 14485 | atareada | 2 |
| 14486 | atar | 2 |
| 14487 | atajarla | 2 |
| 14488 | atadero | 2 |
| 14489 | ataca | 2 |
| 14490 | ataba | 2 |
| 14491 | asusto | 2 |
| 14492 | asustan | 2 |
| 14493 | asustadísimo | 2 |
| 14494 | asturiana | 2 |
| 14495 | asquerosos | 2 |
| 14496 | asperezas | 2 |
| 14497 | aspectos | 2 |
| 14498 | aspas | 2 |
| 14499 | asomose | 2 |
| 14500 | asomé | 2 |
| 14501 | asombres | 2 |
| 14502 | asombrarse | 2 |
| 14503 | asombra | 2 |
| 14504 | asomarse | 2 |
| 14505 | asomar | 2 |
| 14506 | asomado | 2 |
| 14507 | asomada | 2 |
| 14508 | asociar | 2 |
| 14509 | asociaciones | 2 |
| 14510 | asociaba | 2 |
| 14511 | asiste | 2 |
| 14512 | asintió | 2 |
| 14513 | asiáticos | 2 |
| 14514 | asiático | 2 |
| 14515 | asesinos | 2 |
| 14516 | asesinarme | 2 |
| 14517 | asesinaban | 2 |
| 14518 | asentadores | 2 |
| 14519 | asegurártelo | 2 |
| 14520 | asegurarte | 2 |
| 14521 | asegurarse | 2 |
| 14522 | asegurarlo | 2 |
| 14523 | asegurándose | 2 |
| 14524 | asegurando | 2 |
| 14525 | aseguran | 2 |
| 14526 | asechanzas | 2 |
| 14527 | ascenso | 2 |
| 14528 | asaltado | 2 |
| 14529 | asaltaba | 2 |
| 14530 | artísticas | 2 |
| 14531 | artística | 2 |
| 14532 | arrulló | 2 |
| 14533 | arrullándole | 2 |
| 14534 | arrullaba | 2 |
| 14535 | arruinado | 2 |
| 14536 | arrugó | 2 |
| 14537 | arrugas | 2 |
| 14538 | arropó | 2 |
| 14539 | arrope | 2 |
| 14540 | arrojé | 2 |
| 14541 | arrojase | 2 |
| 14542 | arrojándose | 2 |
| 14543 | arrogantísima | 2 |
| 14544 | arrogantes | 2 |
| 14545 | arroba | 2 |
| 14546 | arrimados | 2 |
| 14547 | arrimaba | 2 |
| 14548 | arriendo | 2 |
| 14549 | arribita | 2 |
| 14550 | arrepintiéndose | 2 |
| 14551 | arrepiente | 2 |
| 14552 | arregló | 2 |
| 14553 | arreglarlo | 2 |
| 14554 | arreglara | 2 |
| 14555 | arreglador | 2 |
| 14556 | arreglado | 2 |
| 14557 | arregladito | 2 |
| 14558 | arreció | 2 |
| 14559 | arrebatos | 2 |
| 14560 | arrebato | 2 |
| 14561 | arrebatado | 2 |
| 14562 | arrastren | 2 |
| 14563 | arrancose | 2 |
| 14564 | arrancando | 2 |
| 14565 | arrancado | 2 |
| 14566 | arrancada | 2 |
| 14567 | arrabal | 2 |
| 14568 | arqueando | 2 |
| 14569 | arpegios | 2 |
| 14570 | aro | 2 |
| 14571 | armatoste | 2 |
| 14572 | armara | 2 |
| 14573 | armadura | 2 |
| 14574 | armados | 2 |
| 14575 | aristocrático | 2 |
| 14576 | aristocrática | 2 |
| 14577 | aristócrata | 2 |
| 14578 | argumentaba | 2 |
| 14579 | arganzuela | 2 |
| 14580 | ardores | 2 |
| 14581 | ardiendo | 2 |
| 14582 | ardían | 2 |
| 14583 | arder | 2 |
| 14584 | ardentísima | 2 |
| 14585 | arcón | 2 |
| 14586 | arcano | 2 |
| 14587 | arbustos | 2 |
| 14588 | ara | 2 |
| 14589 | aquiescencia | 2 |
| 14590 | aquélla | 2 |
| 14591 | apuras | 2 |
| 14592 | apurarse | 2 |
| 14593 | apuradas | 2 |
| 14594 | apuntaron | 2 |
| 14595 | apuntalada | 2 |
| 14596 | aproximaciones | 2 |
| 14597 | aproximación | 2 |
| 14598 | aprovechó | 2 |
| 14599 | aprovechaba | 2 |
| 14600 | apropiarse | 2 |
| 14601 | aprobaba | 2 |
| 14602 | apretándosela | 2 |
| 14603 | apretados | 2 |
| 14604 | aprensiones | 2 |
| 14605 | aprendió | 2 |
| 14606 | aprendas | 2 |
| 14607 | aprendamos | 2 |
| 14608 | apreciaciones | 2 |
| 14609 | apreciaban | 2 |
| 14610 | apoyarse | 2 |
| 14611 | apoyándose | 2 |
| 14612 | apóstrofes | 2 |
| 14613 | apostaba | 2 |
| 14614 | apodo | 2 |
| 14615 | apoderose | 2 |
| 14616 | aplicara | 2 |
| 14617 | aplicando | 2 |
| 14618 | aplicaba | 2 |
| 14619 | aplaudo | 2 |
| 14620 | aplacarle | 2 |
| 14621 | aplacarla | 2 |
| 14622 | aplacara | 2 |
| 14623 | apilados | 2 |
| 14624 | apestaba | 2 |
| 14625 | apesta | 2 |
| 14626 | apenada | 2 |
| 14627 | apegada | 2 |
| 14628 | apee | 2 |
| 14629 | apechugar | 2 |
| 14630 | apasionadas | 2 |
| 14631 | apartarse | 2 |
| 14632 | apartaron | 2 |
| 14633 | apartara | 2 |
| 14634 | apartados | 2 |
| 14635 | apartadas | 2 |
| 14636 | apartada | 2 |
| 14637 | apariciones | 2 |
| 14638 | aparentó | 2 |
| 14639 | aparecen | 2 |
| 14640 | aparadores | 2 |
| 14641 | apañaditas | 2 |
| 14642 | apagar | 2 |
| 14643 | apagado | 2 |
| 14644 | añejos | 2 |
| 14645 | añadía | 2 |
| 14646 | anzuelo | 2 |
| 14647 | anunciándole | 2 |
| 14648 | anuncia | 2 |
| 14649 | antojo | 2 |
| 14650 | antojaron | 2 |
| 14651 | antipatías | 2 |
| 14652 | anti | 2 |
| 14653 | antagonismo | 2 |
| 14654 | ansiosas | 2 |
| 14655 | ansiaba | 2 |
| 14656 | anonadada | 2 |
| 14657 | anonada | 2 |
| 14658 | anises | 2 |
| 14659 | animó | 2 |
| 14660 | animar | 2 |
| 14661 | animándose | 2 |
| 14662 | anhelantes | 2 |
| 14663 | angustioso | 2 |
| 14664 | angosto | 2 |
| 14665 | angelote | 2 |
| 14666 | angelón | 2 |
| 14667 | angélica | 2 |
| 14668 | aneurisma | 2 |
| 14669 | anémico | 2 |
| 14670 | andróminas | 2 |
| 14671 | andrea | 2 |
| 14672 | ándese | 2 |
| 14673 | ande | 2 |
| 14674 | andaría | 2 |
| 14675 | andante | 2 |
| 14676 | andanada | 2 |
| 14677 | andana | 2 |
| 14678 | andamos | 2 |
| 14679 | ancianos | 2 |
| 14680 | anchos | 2 |
| 14681 | ancho | 2 |
| 14682 | anatemas | 2 |
| 14683 | anatema | 2 |
| 14684 | anacoreta | 2 |
| 14685 | ampliación | 2 |
| 14686 | amoscándose | 2 |
| 14687 | amoratada | 2 |
| 14688 | amonestando | 2 |
| 14689 | amonestaciones | 2 |
| 14690 | amonestación | 2 |
| 14691 | amiguitos | 2 |
| 14692 | amiguitas | 2 |
| 14693 | amigote | 2 |
| 14694 | americanos | 2 |
| 14695 | américa | 2 |
| 14696 | ameno | 2 |
| 14697 | amenazas | 2 |
| 14698 | amenazando | 2 |
| 14699 | amenazado | 2 |
| 14700 | ambiciosa | 2 |
| 14701 | amasado | 2 |
| 14702 | amarra | 2 |
| 14703 | amarguras | 2 |
| 14704 | amargas | 2 |
| 14705 | amará | 2 |
| 14706 | amaneció | 2 |
| 14707 | amanece | 2 |
| 14708 | amancebamiento | 2 |
| 14709 | alzaban | 2 |
| 14710 | alza | 2 |
| 14711 | álvarez | 2 |
| 14712 | alumna | 2 |
| 14713 | alumbrada | 2 |
| 14714 | alumbraba | 2 |
| 14715 | alucinar | 2 |
| 14716 | altísimo | 2 |
| 14717 | alteró | 2 |
| 14718 | alternar | 2 |
| 14719 | altere | 2 |
| 14720 | altercados | 2 |
| 14721 | alterar | 2 |
| 14722 | alteraba | 2 |
| 14723 | altarito | 2 |
| 14724 | alquiló | 2 |
| 14725 | alquileres | 2 |
| 14726 | alpargatas | 2 |
| 14727 | almuerzos | 2 |
| 14728 | almorzando | 2 |
| 14729 | almendras | 2 |
| 14730 | almejas | 2 |
| 14731 | almacenistas | 2 |
| 14732 | allegados | 2 |
| 14733 | alimenta | 2 |
| 14734 | alimaña | 2 |
| 14735 | alias | 2 |
| 14736 | algos | 2 |
| 14737 | algas | 2 |
| 14738 | alfonsino | 2 |
| 14739 | alevoso | 2 |
| 14740 | aletargado | 2 |
| 14741 | aletargada | 2 |
| 14742 | aleros | 2 |
| 14743 | alejose | 2 |
| 14744 | alejaban | 2 |
| 14745 | alejaba | 2 |
| 14746 | alegrose | 2 |
| 14747 | alegró | 2 |
| 14748 | alegrará | 2 |
| 14749 | aldea | 2 |
| 14750 | alcoy | 2 |
| 14751 | alcázar | 2 |
| 14752 | alcanzan | 2 |
| 14753 | alcanzado | 2 |
| 14754 | álbumes | 2 |
| 14755 | albricias | 2 |
| 14756 | alborozo | 2 |
| 14757 | alborotó | 2 |
| 14758 | alborotase | 2 |
| 14759 | alborotaría | 2 |
| 14760 | alborotar | 2 |
| 14761 | alborota | 2 |
| 14762 | albo | 2 |
| 14763 | albergue | 2 |
| 14764 | albardero | 2 |
| 14765 | alarmó | 2 |
| 14766 | alarmantes | 2 |
| 14767 | alarmaba | 2 |
| 14768 | alargándole | 2 |
| 14769 | alardes | 2 |
| 14770 | alambres | 2 |
| 14771 | alabando | 2 |
| 14772 | ajuste | 2 |
| 14773 | ajumao | 2 |
| 14774 | ajajá | 2 |
| 14775 | ajadas | 2 |
| 14776 | aislamiento | 2 |
| 14777 | airosos | 2 |
| 14778 | airosas | 2 |
| 14779 | airados | 2 |
| 14780 | ahumadas | 2 |
| 14781 | ahorraba | 2 |
| 14782 | ahorita | 2 |
| 14783 | ahogue | 2 |
| 14784 | ahogo | 2 |
| 14785 | ahogas | 2 |
| 14786 | ahilada | 2 |
| 14787 | aguzando | 2 |
| 14788 | agüero | 2 |
| 14789 | aguda | 2 |
| 14790 | aguárdate | 2 |
| 14791 | aguardar | 2 |
| 14792 | aguardando | 2 |
| 14793 | aguántate | 2 |
| 14794 | agrícola | 2 |
| 14795 | agria | 2 |
| 14796 | agresora | 2 |
| 14797 | agresión | 2 |
| 14798 | agrado | 2 |
| 14799 | agradeceré | 2 |
| 14800 | agradecen | 2 |
| 14801 | agradábale | 2 |
| 14802 | agrada | 2 |
| 14803 | agotó | 2 |
| 14804 | agosto | 2 |
| 14805 | agonizante | 2 |
| 14806 | agitándose | 2 |
| 14807 | agitado | 2 |
| 14808 | agitaban | 2 |
| 14809 | agasajado | 2 |
| 14810 | agasajaditos | 2 |
| 14811 | agasajaba | 2 |
| 14812 | agarrarse | 2 |
| 14813 | agarrando | 2 |
| 14814 | agarraban | 2 |
| 14815 | afrontar | 2 |
| 14816 | afortunadamente | 2 |
| 14817 | aflojó | 2 |
| 14818 | afloja | 2 |
| 14819 | afloencias | 2 |
| 14820 | afligidas | 2 |
| 14821 | afligía | 2 |
| 14822 | afirmo | 2 |
| 14823 | afirmativas | 2 |
| 14824 | afirmación | 2 |
| 14825 | afirmaba | 2 |
| 14826 | afinidad | 2 |
| 14827 | afinar | 2 |
| 14828 | afilado | 2 |
| 14829 | aficionados | 2 |
| 14830 | aficionada | 2 |
| 14831 | afeitarse | 2 |
| 14832 | afeitado | 2 |
| 14833 | afeitaba | 2 |
| 14834 | afectan | 2 |
| 14835 | afectación | 2 |
| 14836 | afeaba | 2 |
| 14837 | afanes | 2 |
| 14838 | afables | 2 |
| 14839 | advertía | 2 |
| 14840 | advertencias | 2 |
| 14841 | adulterio | 2 |
| 14842 | adulterado | 2 |
| 14843 | adúltera | 2 |
| 14844 | adulación | 2 |
| 14845 | adquiridas | 2 |
| 14846 | adquiría | 2 |
| 14847 | adormeció | 2 |
| 14848 | adorar | 2 |
| 14849 | adora | 2 |
| 14850 | adoptivo | 2 |
| 14851 | admitirla | 2 |
| 14852 | admitir | 2 |
| 14853 | admitía | 2 |
| 14854 | admite | 2 |
| 14855 | admiró | 2 |
| 14856 | admiro | 2 |
| 14857 | admirarla | 2 |
| 14858 | admirar | 2 |
| 14859 | admirada | 2 |
| 14860 | administraron | 2 |
| 14861 | administradora | 2 |
| 14862 | adivinó | 2 |
| 14863 | adivinación | 2 |
| 14864 | adelantos | 2 |
| 14865 | adelantó | 2 |
| 14866 | adelantaba | 2 |
| 14867 | adelanta | 2 |
| 14868 | adecuado | 2 |
| 14869 | adecuada | 2 |
| 14870 | acusador | 2 |
| 14871 | acusado | 2 |
| 14872 | acumular | 2 |
| 14873 | acuéstese | 2 |
| 14874 | acuestas | 2 |
| 14875 | acuerde | 2 |
| 14876 | acudido | 2 |
| 14877 | acude | 2 |
| 14878 | acuarelas | 2 |
| 14879 | actores | 2 |
| 14880 | actor | 2 |
| 14881 | actividades | 2 |
| 14882 | acreditado | 2 |
| 14883 | acostumbran | 2 |
| 14884 | acostase | 2 |
| 14885 | acostarte | 2 |
| 14886 | acostáronse | 2 |
| 14887 | acostados | 2 |
| 14888 | acostaba | 2 |
| 14889 | acosado | 2 |
| 14890 | acorralada | 2 |
| 14891 | acordeón | 2 |
| 14892 | acordarte | 2 |
| 14893 | acordaron | 2 |
| 14894 | acordando | 2 |
| 14895 | acoquinar | 2 |
| 14896 | aconsejarle | 2 |
| 14897 | acongojadísima | 2 |
| 14898 | acompañó | 2 |
| 14899 | acompaño | 2 |
| 14900 | acompañase | 2 |
| 14901 | acompañaría | 2 |
| 14902 | acompañados | 2 |
| 14903 | acompañaban | 2 |
| 14904 | acomode | 2 |
| 14905 | acometió | 2 |
| 14906 | acometiese | 2 |
| 14907 | acometiendo | 2 |
| 14908 | acólito | 2 |
| 14909 | acogoto | 2 |
| 14910 | acobardó | 2 |
| 14911 | aclarar | 2 |
| 14912 | aclaraban | 2 |
| 14913 | acierto | 2 |
| 14914 | acíbar | 2 |
| 14915 | acertado | 2 |
| 14916 | acercaban | 2 |
| 14917 | aceptarlo | 2 |
| 14918 | aceptaría | 2 |
| 14919 | aceptada | 2 |
| 14920 | aceptable | 2 |
| 14921 | acentuó | 2 |
| 14922 | aceitosas | 2 |
| 14923 | accidental | 2 |
| 14924 | accesos | 2 |
| 14925 | accedió | 2 |
| 14926 | acariciando | 2 |
| 14927 | acaricia | 2 |
| 14928 | acallarle | 2 |
| 14929 | academia | 2 |
| 14930 | acabes | 2 |
| 14931 | acabé | 2 |
| 14932 | acabamiento | 2 |
| 14933 | abyección | 2 |
| 14934 | abusos | 2 |
| 14935 | aburrirás | 2 |
| 14936 | aburre | 2 |
| 14937 | abundamiento | 2 |
| 14938 | abultado | 2 |
| 14939 | abultaba | 2 |
| 14940 | absurdas | 2 |
| 14941 | absorto | 2 |
| 14942 | absorta | 2 |
| 14943 | absorbiendo | 2 |
| 14944 | absolutas | 2 |
| 14945 | abrumada | 2 |
| 14946 | abrirse | 2 |
| 14947 | abrígate | 2 |
| 14948 | abrigadito | 2 |
| 14949 | abrieron | 2 |
| 14950 | abres | 2 |
| 14951 | abrazaron | 2 |
| 14952 | abrazarle | 2 |
| 14953 | abrazarla | 2 |
| 14954 | abrazar | 2 |
| 14955 | aborreciendo | 2 |
| 14956 | aborrecerte | 2 |
| 14957 | aborrecerla | 2 |
| 14958 | aborreceré | 2 |
| 14959 | abordó | 2 |
| 14960 | abollada | 2 |
| 14961 | aboliciones | 2 |
| 14962 | abogados | 2 |
| 14963 | abismos | 2 |
| 14964 | abatir | 2 |
| 14965 | abatieron | 2 |
| 14966 | abandone | 2 |
| 14967 | abandonarla | 2 |
| 14968 | abandonando | 2 |
| 14969 | abandona | 2 |
| 14970 | abalanzó | 2 |
| 14971 | zurriago | 1 |
| 14972 | zurcidor | 1 |
| 14973 | zurcido | 1 |
| 14974 | zumo | 1 |
| 14975 | zumbón | 1 |
| 14976 | zumban | 1 |
| 14977 | zozobras | 1 |
| 14978 | zote | 1 |
| 14979 | zoquetes | 1 |
| 14980 | zoquete | 1 |
| 14981 | zopencos | 1 |
| 14982 | zarzal | 1 |
| 14983 | zarandearse | 1 |
| 14984 | zarandean | 1 |
| 14985 | zarandajas | 1 |
| 14986 | zaragüelles | 1 |
| 14987 | zapatito | 1 |
| 14988 | zapatetas | 1 |
| 14989 | zapateros | 1 |
| 14990 | zapateado | 1 |
| 14991 | zapatas | 1 |
| 14992 | zánganos | 1 |
| 14993 | zancadilla | 1 |
| 14994 | zanahorias | 1 |
| 14995 | zampo | 1 |
| 14996 | zampado | 1 |
| 14997 | zampa | 1 |
| 14998 | zamoranos | 1 |
| 14999 | zambullida | 1 |
| 15000 | zambombazos | 1 |
| 15001 | zamarras | 1 |
| 15002 | zaleas | 1 |
| 15003 | zalea | 1 |
| 15004 | zalamera | 1 |
| 15005 | zahúrdas | 1 |
| 15006 | zahorí | 1 |
| 15007 | zagalote | 1 |
| 15008 | zagalón | 1 |
| 15009 | zafiote | 1 |
| 15010 | zafias | 1 |
| 15011 | zafia | 1 |
| 15012 | zafarme | 1 |
| 15013 | zacarías | 1 |
| 15014 | yesos | 1 |
| 15015 | yeserías | 1 |
| 15016 | yerra | 1 |
| 15017 | yernos | 1 |
| 15018 | yermo | 1 |
| 15019 | yéndome | 1 |
| 15020 | yacía | 1 |
| 15021 | yacen | 1 |
| 15022 | xv | 1 |
| 15023 | xix | 1 |
| 15024 | xiv | 1 |
| 15025 | xiii | 1 |
| 15026 | werther | 1 |
| 15027 | wellington | 1 |
| 15028 | wamba | 1 |
| 15029 | walses | 1 |
| 15030 | vulgarote | 1 |
| 15031 | vulgarísimo | 1 |
| 15032 | vuestros | 1 |
| 15033 | vuelvan | 1 |
| 15034 | vueltecita | 1 |
| 15035 | vuelos | 1 |
| 15036 | vuelco | 1 |
| 15037 | vuelan | 1 |
| 15038 | vuela | 1 |
| 15039 | vuecencia | 1 |
| 15040 | vu | 1 |
| 15041 | votó | 1 |
| 15042 | votantes | 1 |
| 15043 | votando | 1 |
| 15044 | votaba | 1 |
| 15045 | vómito | 1 |
| 15046 | vomitivos | 1 |
| 15047 | volviole | 1 |
| 15048 | volvime | 1 |
| 15049 | volviesen | 1 |
| 15050 | volviéronle | 1 |
| 15051 | volviéndolos | 1 |
| 15052 | volviéndoles | 1 |
| 15053 | volvíase | 1 |
| 15054 | volvíale | 1 |
| 15055 | volverte | 1 |
| 15056 | volverle | 1 |
| 15057 | volvámonos | 1 |
| 15058 | voluntariosa | 1 |
| 15059 | voluntarios | 1 |
| 15060 | voluntaria | 1 |
| 15061 | voluminoso | 1 |
| 15062 | voluminosa | 1 |
| 15063 | voluble | 1 |
| 15064 | volteo | 1 |
| 15065 | volteando | 1 |
| 15066 | volé | 1 |
| 15067 | volcó | 1 |
| 15068 | volcara | 1 |
| 15069 | volcar | 1 |
| 15070 | volcado | 1 |
| 15071 | volatines | 1 |
| 15072 | volátil | 1 |
| 15073 | volandas | 1 |
| 15074 | voladora | 1 |
| 15075 | volado | 1 |
| 15076 | volaba | 1 |
| 15077 | vocerío | 1 |
| 15078 | vocecilla | 1 |
| 15079 | vocear | 1 |
| 15080 | vocales | 1 |
| 15081 | vocabulario | 1 |
| 15082 | vivito | 1 |
| 15083 | vivísimas | 1 |
| 15084 | vivís | 1 |
| 15085 | vivirías | 1 |
| 15086 | vivirían | 1 |
| 15087 | viviría | 1 |
| 15088 | vivieron | 1 |
| 15089 | vivieras | 1 |
| 15090 | vivieran | 1 |
| 15091 | vivíamos | 1 |
| 15092 | vivaracho | 1 |
| 15093 | vivaaa | 1 |
| 15094 | viudos | 1 |
| 15095 | vitrina | 1 |
| 15096 | vitalicio | 1 |
| 15097 | visual | 1 |
| 15098 | vistosos | 1 |
| 15099 | vistos | 1 |
| 15100 | vistiose | 1 |
| 15101 | vistillas | 1 |
| 15102 | vistiese | 1 |
| 15103 | vistiéndolo | 1 |
| 15104 | vistiéndola | 1 |
| 15105 | vistes | 1 |
| 15106 | visten | 1 |
| 15107 | víspera | 1 |
| 15108 | viso | 1 |
| 15109 | vislumbran | 1 |
| 15110 | vislumbraba | 1 |
| 15111 | visito | 1 |
| 15112 | visítela | 1 |
| 15113 | visitase | 1 |
| 15114 | visitaron | 1 |
| 15115 | visitarme | 1 |
| 15116 | visitarle | 1 |
| 15117 | visitante | 1 |
| 15118 | visitándola | 1 |
| 15119 | visitando | 1 |
| 15120 | visitada | 1 |
| 15121 | visionario | 1 |
| 15122 | visillos | 1 |
| 15123 | visibles | 1 |
| 15124 | virutas | 1 |
| 15125 | virus | 1 |
| 15126 | viruela | 1 |
| 15127 | virtuosas | 1 |
| 15128 | virosos | 1 |
| 15129 | viró | 1 |
| 15130 | viril | 1 |
| 15131 | vírgulas | 1 |
| 15132 | vírgenes | 1 |
| 15133 | violo | 1 |
| 15134 | violines | 1 |
| 15135 | violentó | 1 |
| 15136 | violentísimas | 1 |
| 15137 | violentarse | 1 |
| 15138 | violados | 1 |
| 15139 | violadas | 1 |
| 15140 | vinosas | 1 |
| 15141 | viniéronle | 1 |
| 15142 | vinieras | 1 |
| 15143 | vindicta | 1 |
| 15144 | vínculo | 1 |
| 15145 | vinazo | 1 |
| 15146 | vinateros | 1 |
| 15147 | villaviciosa | 1 |
| 15148 | villas | 1 |
| 15149 | villarreal | 1 |
| 15150 | villanía | 1 |
| 15151 | villancicos | 1 |
| 15152 | villahermosa | 1 |
| 15153 | viles | 1 |
| 15154 | vigoroso | 1 |
| 15155 | vigorizó | 1 |
| 15156 | vigorizan | 1 |
| 15157 | vigorización | 1 |
| 15158 | vigorizaba | 1 |
| 15159 | vigilia | 1 |
| 15160 | vigilase | 1 |
| 15161 | vigilarlas | 1 |
| 15162 | vigilantes | 1 |
| 15163 | vigilante | 1 |
| 15164 | vigilando | 1 |
| 15165 | vigilado | 1 |
| 15166 | vigilada | 1 |
| 15167 | vigilaba | 1 |
| 15168 | vigía | 1 |
| 15169 | vigente | 1 |
| 15170 | viesen | 1 |
| 15171 | vierte | 1 |
| 15172 | viéronse | 1 |
| 15173 | vierais | 1 |
| 15174 | viente | 1 |
| 15175 | viéndoselo | 1 |
| 15176 | viéndome | 1 |
| 15177 | viéndolos | 1 |
| 15178 | viéndolo | 1 |
| 15179 | viéndoles | 1 |
| 15180 | viejona | 1 |
| 15181 | viejecillos | 1 |
| 15182 | vidita | 1 |
| 15183 | victorioso | 1 |
| 15184 | victorias | 1 |
| 15185 | vicisitudes | 1 |
| 15186 | viciosote | 1 |
| 15187 | viciosonas | 1 |
| 15188 | viciosas | 1 |
| 15189 | viciado | 1 |
| 15190 | vicaría | 1 |
| 15191 | vibró | 1 |
| 15192 | vibratorio | 1 |
| 15193 | vibrante | 1 |
| 15194 | víboras | 1 |
| 15195 | vías | 1 |
| 15196 | viana | 1 |
| 15197 | viajecito | 1 |
| 15198 | viajado | 1 |
| 15199 | viabilidad | 1 |
| 15200 | via | 1 |
| 15201 | vetustos | 1 |
| 15202 | veto | 1 |
| 15203 | vestuario | 1 |
| 15204 | vestimos | 1 |
| 15205 | vestimenta | 1 |
| 15206 | vestiglo | 1 |
| 15207 | vestigio | 1 |
| 15208 | vestidito | 1 |
| 15209 | vestidita | 1 |
| 15210 | vestían | 1 |
| 15211 | vertiente | 1 |
| 15212 | vertido | 1 |
| 15213 | vertidas | 1 |
| 15214 | vértice | 1 |
| 15215 | vertical | 1 |
| 15216 | verter | 1 |
| 15217 | versiones | 1 |
| 15218 | versión | 1 |
| 15219 | verruguita | 1 |
| 15220 | verosímil | 1 |
| 15221 | vernet | 1 |
| 15222 | verja | 1 |
| 15223 | verificaría | 1 |
| 15224 | verificar | 1 |
| 15225 | verifican | 1 |
| 15226 | verificada | 1 |
| 15227 | verificábase | 1 |
| 15228 | verídicas | 1 |
| 15229 | vericuetos | 1 |
| 15230 | verías | 1 |
| 15231 | verían | 1 |
| 15232 | veríais | 1 |
| 15233 | vergüenzas | 1 |
| 15234 | vergonzante | 1 |
| 15235 | verduras | 1 |
| 15236 | verdura | 1 |
| 15237 | verduleras | 1 |
| 15238 | verdulera | 1 |
| 15239 | verdoso | 1 |
| 15240 | verdosa | 1 |
| 15241 | verdor | 1 |
| 15242 | verbales | 1 |
| 15243 | verba | 1 |
| 15244 | veraz | 1 |
| 15245 | veranear | 1 |
| 15246 | veracidad | 1 |
| 15247 | vera | 1 |
| 15248 | venturosa | 1 |
| 15249 | ventosa | 1 |
| 15250 | ventorrillo | 1 |
| 15251 | ventilara | 1 |
| 15252 | ventilados | 1 |
| 15253 | ventanuchos | 1 |
| 15254 | ventanucha | 1 |
| 15255 | ventanillas | 1 |
| 15256 | ventajoso | 1 |
| 15257 | venís | 1 |
| 15258 | venirte | 1 |
| 15259 | venirse | 1 |
| 15260 | venirme | 1 |
| 15261 | venideros | 1 |
| 15262 | venialmente | 1 |
| 15263 | venia | 1 |
| 15264 | vengativos | 1 |
| 15265 | véngase | 1 |
| 15266 | vengarme | 1 |
| 15267 | vengado | 1 |
| 15268 | venerandas | 1 |
| 15269 | venerado | 1 |
| 15270 | veneradas | 1 |
| 15271 | venera | 1 |
| 15272 | venenosas | 1 |
| 15273 | venenosa | 1 |
| 15274 | vendo | 1 |
| 15275 | vendió | 1 |
| 15276 | vendiéndolos | 1 |
| 15277 | vendidos | 1 |
| 15278 | vendido | 1 |
| 15279 | vendíalos | 1 |
| 15280 | vendí | 1 |
| 15281 | vendes | 1 |
| 15282 | venderse | 1 |
| 15283 | venderlos | 1 |
| 15284 | venderle | 1 |
| 15285 | venderla | 1 |
| 15286 | venderían | 1 |
| 15287 | vendehumos | 1 |
| 15288 | vencimiento | 1 |
| 15289 | venciendo | 1 |
| 15290 | vencidas | 1 |
| 15291 | vencía | 1 |
| 15292 | vencerme | 1 |
| 15293 | vencerlo | 1 |
| 15294 | vencerá | 1 |
| 15295 | vencedor | 1 |
| 15296 | venas | 1 |
| 15297 | velito | 1 |
| 15298 | velitas | 1 |
| 15299 | veletas | 1 |
| 15300 | velaría | 1 |
| 15301 | velaremos | 1 |
| 15302 | velándosele | 1 |
| 15303 | veladores | 1 |
| 15304 | velaban | 1 |
| 15305 | velaba | 1 |
| 15306 | vejiga | 1 |
| 15307 | vejeces | 1 |
| 15308 | veintiuno | 1 |
| 15309 | veintiocho | 1 |
| 15310 | veíalos | 1 |
| 15311 | veíala | 1 |
| 15312 | vehemente | 1 |
| 15313 | vegetativa | 1 |
| 15314 | vegetación | 1 |
| 15315 | veee | 1 |
| 15316 | vedlo | 1 |
| 15317 | vedlas | 1 |
| 15318 | vedan | 1 |
| 15319 | vecindades | 1 |
| 15320 | veámoslo | 1 |
| 15321 | véalo | 1 |
| 15322 | váyanse | 1 |
| 15323 | vaticinó | 1 |
| 15324 | vaticinios | 1 |
| 15325 | vaticinar | 1 |
| 15326 | vaticinan | 1 |
| 15327 | vaticinaba | 1 |
| 15328 | vasto | 1 |
| 15329 | vasta | 1 |
| 15330 | vasito | 1 |
| 15331 | vasijas | 1 |
| 15332 | vascongadas | 1 |
| 15333 | vasco | 1 |
| 15334 | varoncitos | 1 |
| 15335 | varitas | 1 |
| 15336 | varita | 1 |
| 15337 | varisis | 1 |
| 15338 | varió | 1 |
| 15339 | varillas | 1 |
| 15340 | variarle | 1 |
| 15341 | variaran | 1 |
| 15342 | variantes | 1 |
| 15343 | variados | 1 |
| 15344 | variada | 1 |
| 15345 | variación | 1 |
| 15346 | vargueño | 1 |
| 15347 | vareo | 1 |
| 15348 | vareando | 1 |
| 15349 | vaqueta | 1 |
| 15350 | vapulean | 1 |
| 15351 | vapores | 1 |
| 15352 | vaporcito | 1 |
| 15353 | vanos | 1 |
| 15354 | vanas | 1 |
| 15355 | vanaglorió | 1 |
| 15356 | vanagloriarse | 1 |
| 15357 | vana | 1 |
| 15358 | vampiros | 1 |
| 15359 | valores | 1 |
| 15360 | valoraciones | 1 |
| 15361 | vallehermoso | 1 |
| 15362 | valledor | 1 |
| 15363 | vallecas | 1 |
| 15364 | valioso | 1 |
| 15365 | valimiento | 1 |
| 15366 | valieran | 1 |
| 15367 | válida | 1 |
| 15368 | valgo | 1 |
| 15369 | válganos | 1 |
| 15370 | valgamos | 1 |
| 15371 | valerte | 1 |
| 15372 | valerse | 1 |
| 15373 | valeriana | 1 |
| 15374 | valera | 1 |
| 15375 | valenciennes | 1 |
| 15376 | vaivenes | 1 |
| 15377 | vaho | 1 |
| 15378 | vagones | 1 |
| 15379 | vagancia | 1 |
| 15380 | vagabundos | 1 |
| 15381 | vagaba | 1 |
| 15382 | vadita | 1 |
| 15383 | vacuna | 1 |
| 15384 | vació | 1 |
| 15385 | vacilo | 1 |
| 15386 | vacilaron | 1 |
| 15387 | vacilará | 1 |
| 15388 | vacilaciones | 1 |
| 15389 | vacías | 1 |
| 15390 | vaciaba | 1 |
| 15391 | vacas | 1 |
| 15392 | vacantes | 1 |
| 15393 | vacaciones | 1 |
| 15394 | utilitaria | 1 |
| 15395 | utilísimas | 1 |
| 15396 | usurparle | 1 |
| 15397 | usurpan | 1 |
| 15398 | usurpación | 1 |
| 15399 | usureros | 1 |
| 15400 | usurera | 1 |
| 15401 | usurarias | 1 |
| 15402 | usuraria | 1 |
| 15403 | usufructuaria | 1 |
| 15404 | usufructo | 1 |
| 15405 | ustés | 1 |
| 15406 | usos | 1 |
| 15407 | usó | 1 |
| 15408 | usía | 1 |
| 15409 | usaré | 1 |
| 15410 | usara | 1 |
| 15411 | usada | 1 |
| 15412 | uribe | 1 |
| 15413 | urgía | 1 |
| 15414 | urgentes | 1 |
| 15415 | urgente | 1 |
| 15416 | urgencia | 1 |
| 15417 | urdimbres | 1 |
| 15418 | urdidas | 1 |
| 15419 | urbanas | 1 |
| 15420 | untado | 1 |
| 15421 | untada | 1 |
| 15422 | universitario | 1 |
| 15423 | uniste | 1 |
| 15424 | unirte | 1 |
| 15425 | unirles | 1 |
| 15426 | uniones | 1 |
| 15427 | unió | 1 |
| 15428 | uniformidad | 1 |
| 15429 | uniformes | 1 |
| 15430 | uniformados | 1 |
| 15431 | unidas | 1 |
| 15432 | unicornio | 1 |
| 15433 | únicas | 1 |
| 15434 | uníanse | 1 |
| 15435 | unían | 1 |
| 15436 | ungüento | 1 |
| 15437 | ungidas | 1 |
| 15438 | unen | 1 |
| 15439 | unanimidad | 1 |
| 15440 | unánime | 1 |
| 15441 | umbral | 1 |
| 15442 | ultratumba | 1 |
| 15443 | ultramarinos | 1 |
| 15444 | úlceras | 1 |
| 15445 | ujeros | 1 |
| 15446 | ujeritos | 1 |
| 15447 | úes | 1 |
| 15448 | ubre | 1 |
| 15449 | tuyos | 1 |
| 15450 | tuviste | 1 |
| 15451 | tuviéronle | 1 |
| 15452 | tuviéronla | 1 |
| 15453 | tutti | 1 |
| 15454 | tutora | 1 |
| 15455 | tutor | 1 |
| 15456 | tutela | 1 |
| 15457 | tutearle | 1 |
| 15458 | tuteándose | 1 |
| 15459 | tuteándola | 1 |
| 15460 | tuteaba | 1 |
| 15461 | tutea | 1 |
| 15462 | tururú | 1 |
| 15463 | turulatos | 1 |
| 15464 | turulato | 1 |
| 15465 | turrones | 1 |
| 15466 | turris | 1 |
| 15467 | turquí | 1 |
| 15468 | turgentes | 1 |
| 15469 | turégano | 1 |
| 15470 | turcas | 1 |
| 15471 | turca | 1 |
| 15472 | turbulenta | 1 |
| 15473 | turbose | 1 |
| 15474 | turbo | 1 |
| 15475 | turbio | 1 |
| 15476 | turbia | 1 |
| 15477 | turbarle | 1 |
| 15478 | turbante | 1 |
| 15479 | turbadísima | 1 |
| 15480 | turbaban | 1 |
| 15481 | turbábala | 1 |
| 15482 | turbaba | 1 |
| 15483 | túnica | 1 |
| 15484 | tundiéndole | 1 |
| 15485 | tunanterías | 1 |
| 15486 | tunantas | 1 |
| 15487 | tuna | 1 |
| 15488 | tumultuoso | 1 |
| 15489 | tumban | 1 |
| 15490 | tumbaba | 1 |
| 15491 | tumba | 1 |
| 15492 | tullerías | 1 |
| 15493 | tugurios | 1 |
| 15494 | tuétano | 1 |
| 15495 | tubería | 1 |
| 15496 | tuberculosis | 1 |
| 15497 | truncadas | 1 |
| 15498 | truncada | 1 |
| 15499 | trujillesca | 1 |
| 15500 | trujillas | 1 |
| 15501 | truhán | 1 |
| 15502 | trufas | 1 |
| 15503 | trueque | 1 |
| 15504 | trueno | 1 |
| 15505 | truena | 1 |
| 15506 | truchimán | 1 |
| 15507 | trotes | 1 |
| 15508 | tropiezos | 1 |
| 15509 | tropezado | 1 |
| 15510 | tronó | 1 |
| 15511 | tronchos | 1 |
| 15512 | tronaron | 1 |
| 15513 | tronados | 1 |
| 15514 | tronado | 1 |
| 15515 | tronada | 1 |
| 15516 | trompo | 1 |
| 15517 | trompetitas | 1 |
| 15518 | trompetillas | 1 |
| 15519 | trompetas | 1 |
| 15520 | trompazos | 1 |
| 15521 | trompadas | 1 |
| 15522 | trofeos | 1 |
| 15523 | trocase | 1 |
| 15524 | trocaran | 1 |
| 15525 | trocara | 1 |
| 15526 | trocar | 1 |
| 15527 | trocábase | 1 |
| 15528 | trocaban | 1 |
| 15529 | trizas | 1 |
| 15530 | triunfase | 1 |
| 15531 | triunfara | 1 |
| 15532 | triunfal | 1 |
| 15533 | triunfaban | 1 |
| 15534 | triunfaba | 1 |
| 15535 | trituro | 1 |
| 15536 | triturada | 1 |
| 15537 | tristísimos | 1 |
| 15538 | tris | 1 |
| 15539 | triquiñuela | 1 |
| 15540 | tripudas | 1 |
| 15541 | trípode | 1 |
| 15542 | triple | 1 |
| 15543 | tripicallero | 1 |
| 15544 | tripa | 1 |
| 15545 | trinquis | 1 |
| 15546 | trinquen | 1 |
| 15547 | trinco | 1 |
| 15548 | trincaron | 1 |
| 15549 | trincan | 1 |
| 15550 | trinca | 1 |
| 15551 | trinan | 1 |
| 15552 | trimestres | 1 |
| 15553 | trigos | 1 |
| 15554 | trigo | 1 |
| 15555 | trifulcas | 1 |
| 15556 | tributar | 1 |
| 15557 | tribuna | 1 |
| 15558 | triana | 1 |
| 15559 | treta | 1 |
| 15560 | tresillistas | 1 |
| 15561 | trescientos | 1 |
| 15562 | trescientas | 1 |
| 15563 | trepar | 1 |
| 15564 | trepadora | 1 |
| 15565 | trenes | 1 |
| 15566 | trencilla | 1 |
| 15567 | tremens | 1 |
| 15568 | trebejos | 1 |
| 15569 | trazó | 1 |
| 15570 | trazo | 1 |
| 15571 | trazáronla | 1 |
| 15572 | trazarle | 1 |
| 15573 | trazando | 1 |
| 15574 | trazados | 1 |
| 15575 | trazadas | 1 |
| 15576 | traza | 1 |
| 15577 | trayéndole | 1 |
| 15578 | trayéndola | 1 |
| 15579 | traviesos | 1 |
| 15580 | traviesa | 1 |
| 15581 | traviatta | 1 |
| 15582 | traviatonas | 1 |
| 15583 | travesía | 1 |
| 15584 | tratose | 1 |
| 15585 | trátele | 1 |
| 15586 | tratas | 1 |
| 15587 | tratáronse | 1 |
| 15588 | tratarnos | 1 |
| 15589 | tratarlos | 1 |
| 15590 | tratarle | 1 |
| 15591 | trataremos | 1 |
| 15592 | tratándoles | 1 |
| 15593 | tratándola | 1 |
| 15594 | tratamos | 1 |
| 15595 | tratamientos | 1 |
| 15596 | trátame | 1 |
| 15597 | tratados | 1 |
| 15598 | tratadistas | 1 |
| 15599 | tratadas | 1 |
| 15600 | tratábase | 1 |
| 15601 | tratábame | 1 |
| 15602 | tratábala | 1 |
| 15603 | trastornarle | 1 |
| 15604 | trastornadas | 1 |
| 15605 | trastornaban | 1 |
| 15606 | trastocar | 1 |
| 15607 | trastea | 1 |
| 15608 | trastazos | 1 |
| 15609 | trasquilase | 1 |
| 15610 | traspiés | 1 |
| 15611 | traspié | 1 |
| 15612 | traspasó | 1 |
| 15613 | traspasar | 1 |
| 15614 | traspasándole | 1 |
| 15615 | traspasando | 1 |
| 15616 | traspasan | 1 |
| 15617 | traspasaban | 1 |
| 15618 | trasnochar | 1 |
| 15619 | trasnochadores | 1 |
| 15620 | trasmitiendo | 1 |
| 15621 | traslucirse | 1 |
| 15622 | trasladó | 1 |
| 15623 | trasladándose | 1 |
| 15624 | trasladándola | 1 |
| 15625 | trasladando | 1 |
| 15626 | trasladado | 1 |
| 15627 | trasladada | 1 |
| 15628 | traslación | 1 |
| 15629 | trasegarlo | 1 |
| 15630 | trascienden | 1 |
| 15631 | trascendencia | 1 |
| 15632 | trapillo | 1 |
| 15633 | trap | 1 |
| 15634 | tranvías | 1 |
| 15635 | transparente | 1 |
| 15636 | transparentarse | 1 |
| 15637 | transparentado | 1 |
| 15638 | transparencia | 1 |
| 15639 | transmitirlo | 1 |
| 15640 | transmitir | 1 |
| 15641 | transmitió | 1 |
| 15642 | transmitiendo | 1 |
| 15643 | transmitía | 1 |
| 15644 | transmiten | 1 |
| 15645 | transmite | 1 |
| 15646 | transmigrar | 1 |
| 15647 | transmigraban | 1 |
| 15648 | tránsitos | 1 |
| 15649 | transigiendo | 1 |
| 15650 | transigido | 1 |
| 15651 | transigían | 1 |
| 15652 | transiciones | 1 |
| 15653 | transformismo | 1 |
| 15654 | transforme | 1 |
| 15655 | transformase | 1 |
| 15656 | transformar | 1 |
| 15657 | transformándose | 1 |
| 15658 | transformado | 1 |
| 15659 | transformaban | 1 |
| 15660 | transforma | 1 |
| 15661 | transfiguraciones | 1 |
| 15662 | transfiguraba | 1 |
| 15663 | transcurso | 1 |
| 15664 | transcurrió | 1 |
| 15665 | transcurrían | 1 |
| 15666 | transacciones | 1 |
| 15667 | tranquilizarle | 1 |
| 15668 | tranquilizaré | 1 |
| 15669 | tranquilizar | 1 |
| 15670 | tranquilizándose | 1 |
| 15671 | tranquilizándola | 1 |
| 15672 | tranquilizando | 1 |
| 15673 | tranquilizadora | 1 |
| 15674 | tranquilizador | 1 |
| 15675 | tranquilizado | 1 |
| 15676 | tranquilices | 1 |
| 15677 | tranquilamente | 1 |
| 15678 | trancazo | 1 |
| 15679 | tranca | 1 |
| 15680 | tramposos | 1 |
| 15681 | trámites | 1 |
| 15682 | trajiste | 1 |
| 15683 | trajines | 1 |
| 15684 | trajineros | 1 |
| 15685 | trajesen | 1 |
| 15686 | trajéronle | 1 |
| 15687 | trajerais | 1 |
| 15688 | tráiganos | 1 |
| 15689 | tráigamela | 1 |
| 15690 | tráigala | 1 |
| 15691 | traídos | 1 |
| 15692 | traidores | 1 |
| 15693 | traidoras | 1 |
| 15694 | traicioneros | 1 |
| 15695 | traíanla | 1 |
| 15696 | trague | 1 |
| 15697 | tragón | 1 |
| 15698 | trágicos | 1 |
| 15699 | tragicómicos | 1 |
| 15700 | trágico | 1 |
| 15701 | tragedias | 1 |
| 15702 | tragándose | 1 |
| 15703 | tragándole | 1 |
| 15704 | tragan | 1 |
| 15705 | tragaluz | 1 |
| 15706 | tragaluces | 1 |
| 15707 | tragadero | 1 |
| 15708 | tragacanto | 1 |
| 15709 | tragábamos | 1 |
| 15710 | traga | 1 |
| 15711 | traficante | 1 |
| 15712 | trafalgar | 1 |
| 15713 | tráetelo | 1 |
| 15714 | traerte | 1 |
| 15715 | traerse | 1 |
| 15716 | traérnosle | 1 |
| 15717 | traerlas | 1 |
| 15718 | traerán | 1 |
| 15719 | tráele | 1 |
| 15720 | tradújose | 1 |
| 15721 | traducirse | 1 |
| 15722 | traducirla | 1 |
| 15723 | traducía | 1 |
| 15724 | traducción | 1 |
| 15725 | tradición | 1 |
| 15726 | trabucazos | 1 |
| 15727 | trabucan | 1 |
| 15728 | trabó | 1 |
| 15729 | trabillas | 1 |
| 15730 | trabase | 1 |
| 15731 | trabándose | 1 |
| 15732 | trabajosamente | 1 |
| 15733 | trabajillos | 1 |
| 15734 | trabajes | 1 |
| 15735 | trabajarla | 1 |
| 15736 | trabajaría | 1 |
| 15737 | trabájalo | 1 |
| 15738 | trabajadores | 1 |
| 15739 | trabajadoras | 1 |
| 15740 | trabado | 1 |
| 15741 | trababa | 1 |
| 15742 | tóxicos | 1 |
| 15743 | toxicación | 1 |
| 15744 | totalmente | 1 |
| 15745 | tostadita | 1 |
| 15746 | tostaba | 1 |
| 15747 | tosquedad | 1 |
| 15748 | toso | 1 |
| 15749 | tosió | 1 |
| 15750 | tosía | 1 |
| 15751 | tose | 1 |
| 15752 | toscos | 1 |
| 15753 | torzales | 1 |
| 15754 | torvamente | 1 |
| 15755 | tortuosos | 1 |
| 15756 | tortuoso | 1 |
| 15757 | tortuga | 1 |
| 15758 | tórtolos | 1 |
| 15759 | tortolitos | 1 |
| 15760 | tortoleo | 1 |
| 15761 | tortillita | 1 |
| 15762 | tortillas | 1 |
| 15763 | torrero | 1 |
| 15764 | torreón | 1 |
| 15765 | torrellas | 1 |
| 15766 | torrecilla | 1 |
| 15767 | torpezas | 1 |
| 15768 | torniquete | 1 |
| 15769 | tornillándola | 1 |
| 15770 | torneo | 1 |
| 15771 | torneando | 1 |
| 15772 | torneadita | 1 |
| 15773 | tornasol | 1 |
| 15774 | tornas | 1 |
| 15775 | torna | 1 |
| 15776 | tormentos | 1 |
| 15777 | toril | 1 |
| 15778 | toreado | 1 |
| 15779 | toreaba | 1 |
| 15780 | torcidos | 1 |
| 15781 | torcerse | 1 |
| 15782 | torceduras | 1 |
| 15783 | tórax | 1 |
| 15784 | torácica | 1 |
| 15785 | toquen | 1 |
| 15786 | toquéis | 1 |
| 15787 | toquecito | 1 |
| 15788 | tópico | 1 |
| 15789 | topetazo | 1 |
| 15790 | topar | 1 |
| 15791 | topacio | 1 |
| 15792 | tontuna | 1 |
| 15793 | tontita | 1 |
| 15794 | tontees | 1 |
| 15795 | tonteando | 1 |
| 15796 | tontadas | 1 |
| 15797 | tonsurados | 1 |
| 15798 | tonito | 1 |
| 15799 | tónicos | 1 |
| 15800 | tónica | 1 |
| 15801 | tonel | 1 |
| 15802 | tomole | 1 |
| 15803 | tomola | 1 |
| 15804 | tomemos | 1 |
| 15805 | toméis | 1 |
| 15806 | tómbola | 1 |
| 15807 | tomazo | 1 |
| 15808 | tomates | 1 |
| 15809 | tomarnos | 1 |
| 15810 | tomarlas | 1 |
| 15811 | tomarían | 1 |
| 15812 | tomaríale | 1 |
| 15813 | tomaremos | 1 |
| 15814 | tomáramos | 1 |
| 15815 | tomará | 1 |
| 15816 | tomándola | 1 |
| 15817 | tomamos | 1 |
| 15818 | tomáis | 1 |
| 15819 | tomador | 1 |
| 15820 | tomábase | 1 |
| 15821 | tomábala | 1 |
| 15822 | tolú | 1 |
| 15823 | tolosa | 1 |
| 15824 | tolondrón | 1 |
| 15825 | tollina | 1 |
| 15826 | tolerancias | 1 |
| 15827 | tolerable | 1 |
| 15828 | tolera | 1 |
| 15829 | toledano | 1 |
| 15830 | toilette | 1 |
| 15831 | toco | 1 |
| 15832 | tocati | 1 |
| 15833 | tocarme | 1 |
| 15834 | tocarlos | 1 |
| 15835 | tocarlo | 1 |
| 15836 | tocarle | 1 |
| 15837 | tocarían | 1 |
| 15838 | tocaría | 1 |
| 15839 | tocaré | 1 |
| 15840 | tocaran | 1 |
| 15841 | tocándoles | 1 |
| 15842 | tocados | 1 |
| 15843 | tocábamos | 1 |
| 15844 | toallas | 1 |
| 15845 | tizona | 1 |
| 15846 | tiznando | 1 |
| 15847 | títulos | 1 |
| 15848 | títulas | 1 |
| 15849 | titubear | 1 |
| 15850 | titubeando | 1 |
| 15851 | titubeaba | 1 |
| 15852 | tísico | 1 |
| 15853 | tiroteo | 1 |
| 15854 | tirotearse | 1 |
| 15855 | tiritos | 1 |
| 15856 | tiritar | 1 |
| 15857 | tiritaba | 1 |
| 15858 | tiren | 1 |
| 15859 | tirase | 1 |
| 15860 | tirársela | 1 |
| 15861 | tiraron | 1 |
| 15862 | tirarás | 1 |
| 15863 | tirantez | 1 |
| 15864 | tirano | 1 |
| 15865 | tiranístico | 1 |
| 15866 | tiránica | 1 |
| 15867 | tirándose | 1 |
| 15868 | tiranas | 1 |
| 15869 | tiradores | 1 |
| 15870 | tirador | 1 |
| 15871 | tirádola | 1 |
| 15872 | tirabuzones | 1 |
| 15873 | tirabas | 1 |
| 15874 | tirábalo | 1 |
| 15875 | tiquitique | 1 |
| 15876 | tiote | 1 |
| 15877 | tiotas | 1 |
| 15878 | tiota | 1 |
| 15879 | tiorra | 1 |
| 15880 | tiona | 1 |
| 15881 | tiólogos | 1 |
| 15882 | tiñoso | 1 |
| 15883 | tiñosa | 1 |
| 15884 | tiñéndosela | 1 |
| 15885 | tintura | 1 |
| 15886 | tinto | 1 |
| 15887 | tintes | 1 |
| 15888 | tiniente | 1 |
| 15889 | tinajas | 1 |
| 15890 | tina | 1 |
| 15891 | tímpano | 1 |
| 15892 | timos | 1 |
| 15893 | timonear | 1 |
| 15894 | tímidos | 1 |
| 15895 | tímida | 1 |
| 15896 | timbrado | 1 |
| 15897 | timbales | 1 |
| 15898 | timarte | 1 |
| 15899 | timan | 1 |
| 15900 | timadora | 1 |
| 15901 | timaba | 1 |
| 15902 | tílburi | 1 |
| 15903 | tijeretazo | 1 |
| 15904 | tijera | 1 |
| 15905 | tigres | 1 |
| 15906 | tiesto | 1 |
| 15907 | tiernísimos | 1 |
| 15908 | tiernísima | 1 |
| 15909 | tiento | 1 |
| 15910 | tientes | 1 |
| 15911 | tienden | 1 |
| 15912 | tien | 1 |
| 15913 | tiemblo | 1 |
| 15914 | tic | 1 |
| 15915 | tiburones | 1 |
| 15916 | tiburonas | 1 |
| 15917 | tibios | 1 |
| 15918 | tibidabo | 1 |
| 15919 | tibias | 1 |
| 15920 | tibia | 1 |
| 15921 | tiara | 1 |
| 15922 | thinville | 1 |
| 15923 | textualmente | 1 |
| 15924 | tétrico | 1 |
| 15925 | tetita | 1 |
| 15926 | tetera | 1 |
| 15927 | tetánica | 1 |
| 15928 | testuz | 1 |
| 15929 | testeros | 1 |
| 15930 | testero | 1 |
| 15931 | testera | 1 |
| 15932 | testar | 1 |
| 15933 | tesorería | 1 |
| 15934 | tertuliantes | 1 |
| 15935 | tersos | 1 |
| 15936 | tersas | 1 |
| 15937 | tersa | 1 |
| 15938 | terruño | 1 |
| 15939 | terrón | 1 |
| 15940 | territorio | 1 |
| 15941 | terrestre | 1 |
| 15942 | terraza | 1 |
| 15943 | terráqueo | 1 |
| 15944 | terranova | 1 |
| 15945 | terra | 1 |
| 15946 | ternos | 1 |
| 15947 | terneza | 1 |
| 15948 | ternerito | 1 |
| 15949 | terne | 1 |
| 15950 | terminase | 1 |
| 15951 | terminarse | 1 |
| 15952 | terminado | 1 |
| 15953 | terminadas | 1 |
| 15954 | terminada | 1 |
| 15955 | terciopelos | 1 |
| 15956 | terció | 1 |
| 15957 | tercio | 1 |
| 15958 | terciándose | 1 |
| 15959 | tercas | 1 |
| 15960 | terapéutico | 1 |
| 15961 | terapéuticas | 1 |
| 15962 | teóricas | 1 |
| 15963 | teólogos | 1 |
| 15964 | teólogo | 1 |
| 15965 | teológicas | 1 |
| 15966 | teogonías | 1 |
| 15967 | teogonía | 1 |
| 15968 | teñirse | 1 |
| 15969 | teñidos | 1 |
| 15970 | teñida | 1 |
| 15971 | tenuidad | 1 |
| 15972 | tenues | 1 |
| 15973 | tentó | 1 |
| 15974 | tente | 1 |
| 15975 | tentarte | 1 |
| 15976 | tentarían | 1 |
| 15977 | tentar | 1 |
| 15978 | tentador | 1 |
| 15979 | tentaba | 1 |
| 15980 | tenla | 1 |
| 15981 | teniéndose | 1 |
| 15982 | teniéndole | 1 |
| 15983 | teniéndola | 1 |
| 15984 | tenidas | 1 |
| 15985 | teníanle | 1 |
| 15986 | teníalas | 1 |
| 15987 | téngalo | 1 |
| 15988 | tenerlas | 1 |
| 15989 | tenedores | 1 |
| 15990 | tened | 1 |
| 15991 | tenebrosos | 1 |
| 15992 | tenebroso | 1 |
| 15993 | tendréis | 1 |
| 15994 | tendralos | 1 |
| 15995 | tendones | 1 |
| 15996 | tendiera | 1 |
| 15997 | tendidos | 1 |
| 15998 | tendíanse | 1 |
| 15999 | tendían | 1 |
| 16000 | tenderse | 1 |
| 16001 | tenderil | 1 |
| 16002 | tenderete | 1 |
| 16003 | tender | 1 |
| 16004 | tenacillas | 1 |
| 16005 | tenacidades | 1 |
| 16006 | temporal | 1 |
| 16007 | temporadillas | 1 |
| 16008 | temporadilla | 1 |
| 16009 | templos | 1 |
| 16010 | templadita | 1 |
| 16011 | tempestuosos | 1 |
| 16012 | temperatura | 1 |
| 16013 | temida | 1 |
| 16014 | temible | 1 |
| 16015 | temerás | 1 |
| 16016 | temeraria | 1 |
| 16017 | teméis | 1 |
| 16018 | temblorosos | 1 |
| 16019 | tembloroso | 1 |
| 16020 | tembláronle | 1 |
| 16021 | temblara | 1 |
| 16022 | tembladores | 1 |
| 16023 | temamos | 1 |
| 16024 | telegráficos | 1 |
| 16025 | telegráfico | 1 |
| 16026 | telegrafías | 1 |
| 16027 | telegrafiarse | 1 |
| 16028 | telegrafía | 1 |
| 16029 | telares | 1 |
| 16030 | tejiendo | 1 |
| 16031 | tejavana | 1 |
| 16032 | tejas | 1 |
| 16033 | tejar | 1 |
| 16034 | tegel | 1 |
| 16035 | tediosas | 1 |
| 16036 | tediosa | 1 |
| 16037 | tecleando | 1 |
| 16038 | tecleaban | 1 |
| 16039 | tecleaba | 1 |
| 16040 | tea | 1 |
| 16041 | tazón | 1 |
| 16042 | tazas | 1 |
| 16043 | tauromaquia | 1 |
| 16044 | taurómacas | 1 |
| 16045 | tasado | 1 |
| 16046 | tasada | 1 |
| 16047 | tasaba | 1 |
| 16048 | tartana | 1 |
| 16049 | tartamudeó | 1 |
| 16050 | tartamudeando | 1 |
| 16051 | tarima | 1 |
| 16052 | tardo | 1 |
| 16053 | tardío | 1 |
| 16054 | tardecillo | 1 |
| 16055 | tardé | 1 |
| 16056 | tardase | 1 |
| 16057 | tardas | 1 |
| 16058 | tardaré | 1 |
| 16059 | tardara | 1 |
| 16060 | tardan | 1 |
| 16061 | tardamos | 1 |
| 16062 | tarancón | 1 |
| 16063 | tarabilla | 1 |
| 16064 | tapujo | 1 |
| 16065 | tapujito | 1 |
| 16066 | tapón | 1 |
| 16067 | tapete | 1 |
| 16068 | tapase | 1 |
| 16069 | tapas | 1 |
| 16070 | taparle | 1 |
| 16071 | tapándoselo | 1 |
| 16072 | tapan | 1 |
| 16073 | tapado | 1 |
| 16074 | tapadita | 1 |
| 16075 | tapadera | 1 |
| 16076 | tapada | 1 |
| 16077 | tañido | 1 |
| 16078 | tañer | 1 |
| 16079 | tantooo | 1 |
| 16080 | tantismos | 1 |
| 16081 | tantearemos | 1 |
| 16082 | tantear | 1 |
| 16083 | tanteado | 1 |
| 16084 | tangible | 1 |
| 16085 | tangente | 1 |
| 16086 | tamizada | 1 |
| 16087 | tamiz | 1 |
| 16088 | tamente | 1 |
| 16089 | tamboril | 1 |
| 16090 | tamborazos | 1 |
| 16091 | tamañitas | 1 |
| 16092 | taludes | 1 |
| 16093 | talones | 1 |
| 16094 | talón | 1 |
| 16095 | talluditos | 1 |
| 16096 | talludito | 1 |
| 16097 | tallos | 1 |
| 16098 | tallo | 1 |
| 16099 | talles | 1 |
| 16100 | talleres | 1 |
| 16101 | tallas | 1 |
| 16102 | tallarla | 1 |
| 16103 | tallando | 1 |
| 16104 | talegas | 1 |
| 16105 | talcualita | 1 |
| 16106 | talavera | 1 |
| 16107 | talar | 1 |
| 16108 | taladraban | 1 |
| 16109 | tala | 1 |
| 16110 | tajadas | 1 |
| 16111 | tajada | 1 |
| 16112 | tahona | 1 |
| 16113 | tagarote | 1 |
| 16114 | tafetanes | 1 |
| 16115 | táctico | 1 |
| 16116 | tácticas | 1 |
| 16117 | táctica | 1 |
| 16118 | tacones | 1 |
| 16119 | taciturno | 1 |
| 16120 | taciturna | 1 |
| 16121 | tacita | 1 |
| 16122 | tachuelas | 1 |
| 16123 | tacaña | 1 |
| 16124 | tablitas | 1 |
| 16125 | tablajero | 1 |
| 16126 | tablajera | 1 |
| 16127 | tabernero | 1 |
| 16128 | tabacazo | 1 |
| 16129 | ta | 1 |
| 16130 | sutilizaron | 1 |
| 16131 | sutilizado | 1 |
| 16132 | sutilísimo | 1 |
| 16133 | sutilezas | 1 |
| 16134 | sutileza | 1 |
| 16135 | susurraron | 1 |
| 16136 | sustraernos | 1 |
| 16137 | sustraer | 1 |
| 16138 | sustos | 1 |
| 16139 | sustituyeron | 1 |
| 16140 | sustituye | 1 |
| 16141 | sustituirla | 1 |
| 16142 | sustancioso | 1 |
| 16143 | sustanciosa | 1 |
| 16144 | sustancial | 1 |
| 16145 | suspirona | 1 |
| 16146 | suspire | 1 |
| 16147 | suspiras | 1 |
| 16148 | suspirante | 1 |
| 16149 | suspicacia | 1 |
| 16150 | suspenso | 1 |
| 16151 | suspendido | 1 |
| 16152 | suspendida | 1 |
| 16153 | suspenderlo | 1 |
| 16154 | susodichos | 1 |
| 16155 | suscritoras | 1 |
| 16156 | suscritor | 1 |
| 16157 | suscripciones | 1 |
| 16158 | suscripción | 1 |
| 16159 | suscricioncita | 1 |
| 16160 | suscribió | 1 |
| 16161 | suscitara | 1 |
| 16162 | suscepciones | 1 |
| 16163 | surtidos | 1 |
| 16164 | surtidores | 1 |
| 16165 | surtido | 1 |
| 16166 | surtía | 1 |
| 16167 | surgir | 1 |
| 16168 | surgieron | 1 |
| 16169 | surgieran | 1 |
| 16170 | surgía | 1 |
| 16171 | surco | 1 |
| 16172 | surcaban | 1 |
| 16173 | supuesta | 1 |
| 16174 | suprimo | 1 |
| 16175 | suprimirse | 1 |
| 16176 | suprimirlo | 1 |
| 16177 | suprimido | 1 |
| 16178 | suprema | 1 |
| 16179 | súpose | 1 |
| 16180 | suponiéndolo | 1 |
| 16181 | suponiéndoles | 1 |
| 16182 | suponían | 1 |
| 16183 | suponíales | 1 |
| 16184 | suponga | 1 |
| 16185 | suponérsela | 1 |
| 16186 | suponeres | 1 |
| 16187 | suponemos | 1 |
| 16188 | suplió | 1 |
| 16189 | suplicó | 1 |
| 16190 | suplicándole | 1 |
| 16191 | suplicando | 1 |
| 16192 | súplica | 1 |
| 16193 | suplementos | 1 |
| 16194 | suplementario | 1 |
| 16195 | súpitas | 1 |
| 16196 | supiste | 1 |
| 16197 | supiese | 1 |
| 16198 | supersticiosa | 1 |
| 16199 | supersticiones | 1 |
| 16200 | superstición | 1 |
| 16201 | superfirolíticos | 1 |
| 16202 | superfirolíticas | 1 |
| 16203 | superficiales | 1 |
| 16204 | superficial | 1 |
| 16205 | superciliar | 1 |
| 16206 | superávit | 1 |
| 16207 | superarla | 1 |
| 16208 | superaban | 1 |
| 16209 | superaba | 1 |
| 16210 | supera | 1 |
| 16211 | sumisa | 1 |
| 16212 | suministrado | 1 |
| 16213 | sumida | 1 |
| 16214 | sumergirla | 1 |
| 16215 | sumergiendo | 1 |
| 16216 | sumergida | 1 |
| 16217 | sulfurándose | 1 |
| 16218 | sujetose | 1 |
| 16219 | sujetarse | 1 |
| 16220 | sujetaron | 1 |
| 16221 | sujetarles | 1 |
| 16222 | sujetaran | 1 |
| 16223 | sujetan | 1 |
| 16224 | sujetada | 1 |
| 16225 | sujetaban | 1 |
| 16226 | suicido | 1 |
| 16227 | suicide | 1 |
| 16228 | sugirieron | 1 |
| 16229 | sugiriera | 1 |
| 16230 | sugestiones | 1 |
| 16231 | sugestionada | 1 |
| 16232 | sugestión | 1 |
| 16233 | sugeríanle | 1 |
| 16234 | sugerían | 1 |
| 16235 | sugeríale | 1 |
| 16236 | sugería | 1 |
| 16237 | sufrirte | 1 |
| 16238 | sufriría | 1 |
| 16239 | sufrimiento | 1 |
| 16240 | sufrieron | 1 |
| 16241 | sufriendo | 1 |
| 16242 | sufridos | 1 |
| 16243 | sufragios | 1 |
| 16244 | suertes | 1 |
| 16245 | sueñecito | 1 |
| 16246 | sueñecillo | 1 |
| 16247 | sueñan | 1 |
| 16248 | sueno | 1 |
| 16249 | suenen | 1 |
| 16250 | suéltese | 1 |
| 16251 | sueltecito | 1 |
| 16252 | suegro | 1 |
| 16253 | sudario | 1 |
| 16254 | sudadas | 1 |
| 16255 | suda | 1 |
| 16256 | sucumbió | 1 |
| 16257 | suculento | 1 |
| 16258 | suculenta | 1 |
| 16259 | sucediera | 1 |
| 16260 | sucedidos | 1 |
| 16261 | sucedían | 1 |
| 16262 | sucederme | 1 |
| 16263 | sucederá | 1 |
| 16264 | subyugando | 1 |
| 16265 | subyugada | 1 |
| 16266 | subteniente | 1 |
| 16267 | subsistiendo | 1 |
| 16268 | subsistía | 1 |
| 16269 | subsistencia | 1 |
| 16270 | subsiste | 1 |
| 16271 | subsiguientes | 1 |
| 16272 | subsidio | 1 |
| 16273 | subsecretarios | 1 |
| 16274 | subrepticiamente | 1 |
| 16275 | sublimidades | 1 |
| 16276 | sublimaban | 1 |
| 16277 | sublevó | 1 |
| 16278 | sublevo | 1 |
| 16279 | sublevaba | 1 |
| 16280 | subleva | 1 |
| 16281 | súbitas | 1 |
| 16282 | subirlas | 1 |
| 16283 | subiría | 1 |
| 16284 | subiré | 1 |
| 16285 | subiese | 1 |
| 16286 | subiéronle | 1 |
| 16287 | subiera | 1 |
| 16288 | subiéndosele | 1 |
| 16289 | subiéndome | 1 |
| 16290 | subes | 1 |
| 16291 | súbdito | 1 |
| 16292 | subasta | 1 |
| 16293 | subamos | 1 |
| 16294 | subalternos | 1 |
| 16295 | subalterno | 1 |
| 16296 | subalterna | 1 |
| 16297 | suave | 1 |
| 16298 | suárez | 1 |
| 16299 | sport | 1 |
| 16300 | sotabanco | 1 |
| 16301 | sostienes | 1 |
| 16302 | sostenimiento | 1 |
| 16303 | sosteniéndose | 1 |
| 16304 | sosteniéndola | 1 |
| 16305 | sostenías | 1 |
| 16306 | sostenerse | 1 |
| 16307 | sostendré | 1 |
| 16308 | sostén | 1 |
| 16309 | sospechosa | 1 |
| 16310 | sospecho | 1 |
| 16311 | sospechen | 1 |
| 16312 | sospechara | 1 |
| 16313 | sospechabas | 1 |
| 16314 | sosos | 1 |
| 16315 | sosería | 1 |
| 16316 | sosegó | 1 |
| 16317 | sosegarle | 1 |
| 16318 | sosegando | 1 |
| 16319 | sosegadamente | 1 |
| 16320 | sosas | 1 |
| 16321 | sosamente | 1 |
| 16322 | sosa | 1 |
| 16323 | sortilegio | 1 |
| 16324 | sortijas | 1 |
| 16325 | sortearlo | 1 |
| 16326 | sortearle | 1 |
| 16327 | sortear | 1 |
| 16328 | sorteando | 1 |
| 16329 | sorpresita | 1 |
| 16330 | sorprendo | 1 |
| 16331 | sorprendiese | 1 |
| 16332 | sorprendieron | 1 |
| 16333 | sorprendidos | 1 |
| 16334 | sorprendidas | 1 |
| 16335 | sorprendí | 1 |
| 16336 | sorprenderá | 1 |
| 16337 | sorprender | 1 |
| 16338 | sorna | 1 |
| 16339 | sordina | 1 |
| 16340 | sordidez | 1 |
| 16341 | sordas | 1 |
| 16342 | sordamente | 1 |
| 16343 | sorbo | 1 |
| 16344 | sorbió | 1 |
| 16345 | sorbieran | 1 |
| 16346 | sorber | 1 |
| 16347 | sorbe | 1 |
| 16348 | soportan | 1 |
| 16349 | soportado | 1 |
| 16350 | soporífero | 1 |
| 16351 | soporífera | 1 |
| 16352 | soplaron | 1 |
| 16353 | soplao | 1 |
| 16354 | soplándose | 1 |
| 16355 | soplando | 1 |
| 16356 | sopesarlos | 1 |
| 16357 | soñoliento | 1 |
| 16358 | soñolientas | 1 |
| 16359 | soñolienta | 1 |
| 16360 | soñaron | 1 |
| 16361 | soñadas | 1 |
| 16362 | sonsaques | 1 |
| 16363 | sonsacado | 1 |
| 16364 | sonrosados | 1 |
| 16365 | sonrosado | 1 |
| 16366 | sonrosadas | 1 |
| 16367 | sonrojos | 1 |
| 16368 | sonrojo | 1 |
| 16369 | sonrisas | 1 |
| 16370 | sonríes | 1 |
| 16371 | sonriéndose | 1 |
| 16372 | sonoro | 1 |
| 16373 | sonoridad | 1 |
| 16374 | sonoras | 1 |
| 16375 | sondéela | 1 |
| 16376 | sondear | 1 |
| 16377 | sondeaba | 1 |
| 16378 | sondaje | 1 |
| 16379 | sonarme | 1 |
| 16380 | sonara | 1 |
| 16381 | sonándose | 1 |
| 16382 | sonándola | 1 |
| 16383 | sonambulismo | 1 |
| 16384 | sonámbula | 1 |
| 16385 | somnolencias | 1 |
| 16386 | sometiera | 1 |
| 16387 | sometiéndose | 1 |
| 16388 | sometida | 1 |
| 16389 | sometían | 1 |
| 16390 | sometía | 1 |
| 16391 | someterlas | 1 |
| 16392 | someta | 1 |
| 16393 | someras | 1 |
| 16394 | sombríos | 1 |
| 16395 | sombrillazo | 1 |
| 16396 | sombría | 1 |
| 16397 | sombreritos | 1 |
| 16398 | sombrerero | 1 |
| 16399 | sombreo | 1 |
| 16400 | sombrajos | 1 |
| 16401 | soluciones | 1 |
| 16402 | soltole | 1 |
| 16403 | solterones | 1 |
| 16404 | soltería | 1 |
| 16405 | soltaste | 1 |
| 16406 | soltarse | 1 |
| 16407 | soltarlo | 1 |
| 16408 | soltarla | 1 |
| 16409 | soltarían | 1 |
| 16410 | soltara | 1 |
| 16411 | soltaban | 1 |
| 16412 | sollozar | 1 |
| 16413 | sollozando | 1 |
| 16414 | soliviantada | 1 |
| 16415 | solitos | 1 |
| 16416 | solito | 1 |
| 16417 | sólidos | 1 |
| 16418 | solidificación | 1 |
| 16419 | solidificaba | 1 |
| 16420 | solidifica | 1 |
| 16421 | solidez | 1 |
| 16422 | sólidamente | 1 |
| 16423 | solicito | 1 |
| 16424 | solicitara | 1 |
| 16425 | solicitar | 1 |
| 16426 | solicitados | 1 |
| 16427 | solfeo | 1 |
| 16428 | soleta | 1 |
| 16429 | soles | 1 |
| 16430 | solemos | 1 |
| 16431 | solemnidades | 1 |
| 16432 | solecismos | 1 |
| 16433 | soldevilla | 1 |
| 16434 | soldarla | 1 |
| 16435 | soldadura | 1 |
| 16436 | soldaditos | 1 |
| 16437 | solaz | 1 |
| 16438 | solapas | 1 |
| 16439 | solana | 1 |
| 16440 | sojuzgado | 1 |
| 16441 | sogas | 1 |
| 16442 | soforas | 1 |
| 16443 | sofocones | 1 |
| 16444 | sofoco | 1 |
| 16445 | sofocase | 1 |
| 16446 | sofocarse | 1 |
| 16447 | sofocaban | 1 |
| 16448 | sofisterías | 1 |
| 16449 | soez | 1 |
| 16450 | socorriome | 1 |
| 16451 | socorrió | 1 |
| 16452 | socorriese | 1 |
| 16453 | socorridas | 1 |
| 16454 | socorrías | 1 |
| 16455 | socorría | 1 |
| 16456 | socorrerme | 1 |
| 16457 | socorreremos | 1 |
| 16458 | socorrerá | 1 |
| 16459 | socorre | 1 |
| 16460 | socórrale | 1 |
| 16461 | socialistas | 1 |
| 16462 | socialista | 1 |
| 16463 | socavaban | 1 |
| 16464 | socarronas | 1 |
| 16465 | sobro | 1 |
| 16466 | sobrio | 1 |
| 16467 | sobrevive | 1 |
| 16468 | sobreviniese | 1 |
| 16469 | sobreviene | 1 |
| 16470 | sobrevenirle | 1 |
| 16471 | sobrevenido | 1 |
| 16472 | sobrestante | 1 |
| 16473 | sobresaltos | 1 |
| 16474 | sobresaltó | 1 |
| 16475 | sobresalientes | 1 |
| 16476 | sobrepujó | 1 |
| 16477 | sobreponiéndose | 1 |
| 16478 | sobreponían | 1 |
| 16479 | sobreponía | 1 |
| 16480 | sobreparto | 1 |
| 16481 | sobredorada | 1 |
| 16482 | sobrecogía | 1 |
| 16483 | sobrecoge | 1 |
| 16484 | sobraron | 1 |
| 16485 | sobrantes | 1 |
| 16486 | sobrando | 1 |
| 16487 | sobran | 1 |
| 16488 | sobraban | 1 |
| 16489 | soberbios | 1 |
| 16490 | soberbias | 1 |
| 16491 | soberana | 1 |
| 16492 | sobar | 1 |
| 16493 | sobadas | 1 |
| 16494 | sobaco | 1 |
| 16495 | situó | 1 |
| 16496 | situados | 1 |
| 16497 | situado | 1 |
| 16498 | situada | 1 |
| 16499 | sita | 1 |
| 16500 | sístole | 1 |
| 16501 | sistematizar | 1 |
| 16502 | sirvieron | 1 |
| 16503 | sirvientes | 1 |
| 16504 | sirviéndole | 1 |
| 16505 | sirviendo | 1 |
| 16506 | sirvas | 1 |
| 16507 | siquera | 1 |
| 16508 | sinvergüenzones | 1 |
| 16509 | sinvergüenzonas | 1 |
| 16510 | sintiole | 1 |
| 16511 | sintieses | 1 |
| 16512 | sintieran | 1 |
| 16513 | sintético | 1 |
| 16514 | sinrazones | 1 |
| 16515 | sinrazón | 1 |
| 16516 | sinónimos | 1 |
| 16517 | sinodales | 1 |
| 16518 | sinificancia | 1 |
| 16519 | siniestros | 1 |
| 16520 | singularidad | 1 |
| 16521 | singulares | 1 |
| 16522 | singer | 1 |
| 16523 | sinfonías | 1 |
| 16524 | sinfonía | 1 |
| 16525 | síncope | 1 |
| 16526 | síncopas | 1 |
| 16527 | sinceridades | 1 |
| 16528 | sinceras | 1 |
| 16529 | simultáneos | 1 |
| 16530 | simultáneamente | 1 |
| 16531 | simulado | 1 |
| 16532 | simulacro | 1 |
| 16533 | simpson | 1 |
| 16534 | simplona | 1 |
| 16535 | simplín | 1 |
| 16536 | simplicitas | 1 |
| 16537 | simples | 1 |
| 16538 | simpatizase | 1 |
| 16539 | simpatizado | 1 |
| 16540 | simpáticos | 1 |
| 16541 | simones | 1 |
| 16542 | similares | 1 |
| 16543 | símil | 1 |
| 16544 | simiente | 1 |
| 16545 | simbolismo | 1 |
| 16546 | siluetas | 1 |
| 16547 | silogismos | 1 |
| 16548 | sillones | 1 |
| 16549 | silleta | 1 |
| 16550 | silfidones | 1 |
| 16551 | silfidona | 1 |
| 16552 | sílfide | 1 |
| 16553 | silenciosos | 1 |
| 16554 | silbidos | 1 |
| 16555 | silbido | 1 |
| 16556 | silbe | 1 |
| 16557 | silbante | 1 |
| 16558 | silbándole | 1 |
| 16559 | silbando | 1 |
| 16560 | silabeo | 1 |
| 16561 | sigunda | 1 |
| 16562 | siguiole | 1 |
| 16563 | siguiéndoles | 1 |
| 16564 | sigues | 1 |
| 16565 | significativa | 1 |
| 16566 | significado | 1 |
| 16567 | sigan | 1 |
| 16568 | sietes | 1 |
| 16569 | siervas | 1 |
| 16570 | sientan | 1 |
| 16571 | siéndolo | 1 |
| 16572 | siéndole | 1 |
| 16573 | siego | 1 |
| 16574 | sicilianas | 1 |
| 16575 | sicario | 1 |
| 16576 | sibila | 1 |
| 16577 | sibarita | 1 |
| 16578 | shangai | 1 |
| 16579 | sexto | 1 |
| 16580 | sexta | 1 |
| 16581 | sevicia | 1 |
| 16582 | severos | 1 |
| 16583 | severísimos | 1 |
| 16584 | severísimamente | 1 |
| 16585 | severidades | 1 |
| 16586 | severiano | 1 |
| 16587 | severas | 1 |
| 16588 | setos | 1 |
| 16589 | sétimo | 1 |
| 16590 | setecientas | 1 |
| 16591 | sesudo | 1 |
| 16592 | sesudas | 1 |
| 16593 | sesiones | 1 |
| 16594 | sesera | 1 |
| 16595 | servirte | 1 |
| 16596 | servirles | 1 |
| 16597 | servirle | 1 |
| 16598 | serviría | 1 |
| 16599 | servirá | 1 |
| 16600 | servilón | 1 |
| 16601 | serviles | 1 |
| 16602 | servidores | 1 |
| 16603 | servida | 1 |
| 16604 | servían | 1 |
| 16605 | servíale | 1 |
| 16606 | serte | 1 |
| 16607 | sert | 1 |
| 16608 | serpentine | 1 |
| 16609 | serosa | 1 |
| 16610 | serones | 1 |
| 16611 | sernos | 1 |
| 16612 | sermoneo | 1 |
| 16613 | sermonearle | 1 |
| 16614 | sermonearé | 1 |
| 16615 | sermoneaba | 1 |
| 16616 | sermoncito | 1 |
| 16617 | sermonazo | 1 |
| 16618 | sermonarias | 1 |
| 16619 | serme | 1 |
| 16620 | serios | 1 |
| 16621 | seríale | 1 |
| 16622 | sereta | 1 |
| 16623 | serénese | 1 |
| 16624 | serene | 1 |
| 16625 | serénate | 1 |
| 16626 | serenase | 1 |
| 16627 | serenaron | 1 |
| 16628 | serenarás | 1 |
| 16629 | serenado | 1 |
| 16630 | seráfica | 1 |
| 16631 | séquito | 1 |
| 16632 | seque | 1 |
| 16633 | sepulturas | 1 |
| 16634 | sepultarse | 1 |
| 16635 | sepultado | 1 |
| 16636 | séptimo | 1 |
| 16637 | separose | 1 |
| 16638 | separes | 1 |
| 16639 | separáronse | 1 |
| 16640 | separarnos | 1 |
| 16641 | separaremos | 1 |
| 16642 | separándose | 1 |
| 16643 | separado | 1 |
| 16644 | separadas | 1 |
| 16645 | separada | 1 |
| 16646 | separábanse | 1 |
| 16647 | seo | 1 |
| 16648 | señoriticas | 1 |
| 16649 | señoritas | 1 |
| 16650 | señoril | 1 |
| 16651 | señorete | 1 |
| 16652 | señó | 1 |
| 16653 | señale | 1 |
| 16654 | señalarse | 1 |
| 16655 | señalándote | 1 |
| 16656 | señalados | 1 |
| 16657 | señalada | 1 |
| 16658 | señalaba | 1 |
| 16659 | señala | 1 |
| 16660 | sentirme | 1 |
| 16661 | sentirla | 1 |
| 16662 | sentirás | 1 |
| 16663 | sentirá | 1 |
| 16664 | sentinas | 1 |
| 16665 | sentimos | 1 |
| 16666 | sentías | 1 |
| 16667 | sentíalo | 1 |
| 16668 | sentíala | 1 |
| 16669 | sentenciador | 1 |
| 16670 | senté | 1 |
| 16671 | sentáronse | 1 |
| 16672 | sentaré | 1 |
| 16673 | sentándosele | 1 |
| 16674 | sentadita | 1 |
| 16675 | sentábase | 1 |
| 16676 | sensibles | 1 |
| 16677 | sensiblemente | 1 |
| 16678 | sensato | 1 |
| 16679 | senil | 1 |
| 16680 | sencillos | 1 |
| 16681 | sencillísima | 1 |
| 16682 | senador | 1 |
| 16683 | semioscura | 1 |
| 16684 | semilla | 1 |
| 16685 | semestres | 1 |
| 16686 | semestre | 1 |
| 16687 | semeja | 1 |
| 16688 | sembrara | 1 |
| 16689 | sembrar | 1 |
| 16690 | sembrando | 1 |
| 16691 | sellos | 1 |
| 16692 | selló | 1 |
| 16693 | sellaíto | 1 |
| 16694 | selecto | 1 |
| 16695 | seiscientos | 1 |
| 16696 | seguridades | 1 |
| 16697 | seguras | 1 |
| 16698 | segundón | 1 |
| 16699 | seguirlos | 1 |
| 16700 | seguirlas | 1 |
| 16701 | seguirían | 1 |
| 16702 | seguiríamos | 1 |
| 16703 | seguiremos | 1 |
| 16704 | seguirás | 1 |
| 16705 | seguío | 1 |
| 16706 | seguimientos | 1 |
| 16707 | seguíales | 1 |
| 16708 | seguíala | 1 |
| 16709 | segovianos | 1 |
| 16710 | seglar | 1 |
| 16711 | segar | 1 |
| 16712 | segándole | 1 |
| 16713 | seducir | 1 |
| 16714 | seducido | 1 |
| 16715 | seducidas | 1 |
| 16716 | seducida | 1 |
| 16717 | seducción | 1 |
| 16718 | sedimentado | 1 |
| 16719 | sedientos | 1 |
| 16720 | sedienta | 1 |
| 16721 | sedeño | 1 |
| 16722 | sede | 1 |
| 16723 | sedante | 1 |
| 16724 | sedanes | 1 |
| 16725 | sedán | 1 |
| 16726 | secuestradoras | 1 |
| 16727 | secuestrado | 1 |
| 16728 | secretito | 1 |
| 16729 | secretillo | 1 |
| 16730 | secreteos | 1 |
| 16731 | secreteó | 1 |
| 16732 | secretearse | 1 |
| 16733 | secreteara | 1 |
| 16734 | secretas | 1 |
| 16735 | secó | 1 |
| 16736 | secaron | 1 |
| 16737 | secarle | 1 |
| 16738 | secara | 1 |
| 16739 | secamente | 1 |
| 16740 | secado | 1 |
| 16741 | secaderos | 1 |
| 16742 | secadero | 1 |
| 16743 | secaban | 1 |
| 16744 | sebosa | 1 |
| 16745 | scott | 1 |
| 16746 | scirroso | 1 |
| 16747 | schiller | 1 |
| 16748 | sc | 1 |
| 16749 | sazonarla | 1 |
| 16750 | sazonado | 1 |
| 16751 | sazonada | 1 |
| 16752 | sayos | 1 |
| 16753 | sayones | 1 |
| 16754 | saya | 1 |
| 16755 | saturada | 1 |
| 16756 | satisfechos | 1 |
| 16757 | satisfechas | 1 |
| 16758 | satisfactoria | 1 |
| 16759 | satisfacían | 1 |
| 16760 | satisfacía | 1 |
| 16761 | satisfacerse | 1 |
| 16762 | satisfacerlos | 1 |
| 16763 | satisfacerlo | 1 |
| 16764 | satisfacerla | 1 |
| 16765 | satisfacciones | 1 |
| 16766 | satíricos | 1 |
| 16767 | satenes | 1 |
| 16768 | satén | 1 |
| 16769 | sastrería | 1 |
| 16770 | sastre | 1 |
| 16771 | sastra | 1 |
| 16772 | sartas | 1 |
| 16773 | sarta | 1 |
| 16774 | sarna | 1 |
| 16775 | sargentos | 1 |
| 16776 | sargento | 1 |
| 16777 | sardina | 1 |
| 16778 | sarcástico | 1 |
| 16779 | sarao | 1 |
| 16780 | saquitos | 1 |
| 16781 | saquito | 1 |
| 16782 | saqueaban | 1 |
| 16783 | sapos | 1 |
| 16784 | sapientísimas | 1 |
| 16785 | sañudamente | 1 |
| 16786 | sañuda | 1 |
| 16787 | santuario | 1 |
| 16788 | santona | 1 |
| 16789 | santisma | 1 |
| 16790 | santifiquísimas | 1 |
| 16791 | santificarnos | 1 |
| 16792 | santander | 1 |
| 16793 | sanos | 1 |
| 16794 | sanitarismo | 1 |
| 16795 | sanguinolento | 1 |
| 16796 | sanguínea | 1 |
| 16797 | sanguinaria | 1 |
| 16798 | sangrientos | 1 |
| 16799 | sangrienta | 1 |
| 16800 | sangría | 1 |
| 16801 | sangraran | 1 |
| 16802 | sandía | 1 |
| 16803 | sandez | 1 |
| 16804 | sancta | 1 |
| 16805 | sancionadora | 1 |
| 16806 | sancho | 1 |
| 16807 | sanas | 1 |
| 16808 | sanarte | 1 |
| 16809 | sanara | 1 |
| 16810 | sanan | 1 |
| 16811 | sanado | 1 |
| 16812 | salvedades | 1 |
| 16813 | salvarías | 1 |
| 16814 | salvaré | 1 |
| 16815 | salvará | 1 |
| 16816 | salvando | 1 |
| 16817 | salvamento | 1 |
| 16818 | salvajito | 1 |
| 16819 | salvajita | 1 |
| 16820 | salvajadas | 1 |
| 16821 | salvadoras | 1 |
| 16822 | salvadora | 1 |
| 16823 | salvador | 1 |
| 16824 | salvadera | 1 |
| 16825 | saludes | 1 |
| 16826 | saludarte | 1 |
| 16827 | saludáronse | 1 |
| 16828 | saludarles | 1 |
| 16829 | saludarle | 1 |
| 16830 | saludarlas | 1 |
| 16831 | saludándola | 1 |
| 16832 | saludadores | 1 |
| 16833 | saludables | 1 |
| 16834 | saltos | 1 |
| 16835 | saltimbanquis | 1 |
| 16836 | saltase | 1 |
| 16837 | saltarla | 1 |
| 16838 | saltaran | 1 |
| 16839 | saltándosele | 1 |
| 16840 | saltándola | 1 |
| 16841 | saltan | 1 |
| 16842 | saltamontes | 1 |
| 16843 | saltado | 1 |
| 16844 | saltaban | 1 |
| 16845 | salsas | 1 |
| 16846 | salpicaron | 1 |
| 16847 | salpicado | 1 |
| 16848 | salpicada | 1 |
| 16849 | salomón | 1 |
| 16850 | salobre | 1 |
| 16851 | salmuera | 1 |
| 16852 | salivita | 1 |
| 16853 | salivazos | 1 |
| 16854 | salivazo | 1 |
| 16855 | salís | 1 |
| 16856 | salieran | 1 |
| 16857 | saliditas | 1 |
| 16858 | salesas | 1 |
| 16859 | saldrían | 1 |
| 16860 | saldrán | 1 |
| 16861 | saldar | 1 |
| 16862 | saldan | 1 |
| 16863 | salas | 1 |
| 16864 | salaremos | 1 |
| 16865 | saladísimo | 1 |
| 16866 | saladas | 1 |
| 16867 | sajonas | 1 |
| 16868 | sahumerio | 1 |
| 16869 | sagrados | 1 |
| 16870 | sagra | 1 |
| 16871 | sagacidad | 1 |
| 16872 | saetazos | 1 |
| 16873 | saetas | 1 |
| 16874 | sacudo | 1 |
| 16875 | sacudirme | 1 |
| 16876 | sacudirlas | 1 |
| 16877 | sacudiré | 1 |
| 16878 | sacudimientos | 1 |
| 16879 | sacudimiento | 1 |
| 16880 | sacudieran | 1 |
| 16881 | sacudiéndoles | 1 |
| 16882 | sacudiéndole | 1 |
| 16883 | sacudiéndola | 1 |
| 16884 | sacudido | 1 |
| 16885 | sacude | 1 |
| 16886 | sacristanes | 1 |
| 16887 | sacrílegos | 1 |
| 16888 | sacrílego | 1 |
| 16889 | sacrilegios | 1 |
| 16890 | sacrilegio | 1 |
| 16891 | sacrifíquese | 1 |
| 16892 | sacrifique | 1 |
| 16893 | sacrificaba | 1 |
| 16894 | sacos | 1 |
| 16895 | saciedad | 1 |
| 16896 | saciar | 1 |
| 16897 | saciaba | 1 |
| 16898 | sacerdotales | 1 |
| 16899 | sacerdotal | 1 |
| 16900 | sacáronla | 1 |
| 16901 | sacarles | 1 |
| 16902 | sacarlas | 1 |
| 16903 | sacarán | 1 |
| 16904 | sacará | 1 |
| 16905 | sácanos | 1 |
| 16906 | sacándose | 1 |
| 16907 | sacándome | 1 |
| 16908 | sacándolos | 1 |
| 16909 | sacándole | 1 |
| 16910 | sacamos | 1 |
| 16911 | sácalos | 1 |
| 16912 | sacados | 1 |
| 16913 | sacadas | 1 |
| 16914 | sacábala | 1 |
| 16915 | sabusté | 1 |
| 16916 | sabrosos | 1 |
| 16917 | sabríais | 1 |
| 16918 | sabremos | 1 |
| 16919 | sabrán | 1 |
| 16920 | saboréate | 1 |
| 16921 | saboreaba | 1 |
| 16922 | sabor | 1 |
| 16923 | sable | 1 |
| 16924 | sablazos | 1 |
| 16925 | sabiéndolas | 1 |
| 16926 | sabiendas | 1 |
| 16927 | sabíamos | 1 |
| 16928 | saberlas | 1 |
| 16929 | sabeees | 1 |
| 16930 | sabedoras | 1 |
| 16931 | sabañones | 1 |
| 16932 | sábados | 1 |
| 16933 | s | 1 |
| 16934 | rutinarios | 1 |
| 16935 | rutinario | 1 |
| 16936 | rutinaria | 1 |
| 16937 | rústicos | 1 |
| 16938 | rústicas | 1 |
| 16939 | rusticación | 1 |
| 16940 | rústica | 1 |
| 16941 | rusos | 1 |
| 16942 | rupertito | 1 |
| 16943 | rumores | 1 |
| 16944 | rumiarlas | 1 |
| 16945 | rumiaba | 1 |
| 16946 | rumboso | 1 |
| 16947 | rumbos | 1 |
| 16948 | rumbeles | 1 |
| 16949 | ruinosos | 1 |
| 16950 | ruinoso | 1 |
| 16951 | ruin | 1 |
| 16952 | ruidosos | 1 |
| 16953 | ruidito | 1 |
| 16954 | rugió | 1 |
| 16955 | rugidos | 1 |
| 16956 | rugía | 1 |
| 16957 | ruegos | 1 |
| 16958 | ruego | 1 |
| 16959 | ruedos | 1 |
| 16960 | ruedita | 1 |
| 16961 | ruede | 1 |
| 16962 | rudimentarios | 1 |
| 16963 | ruborizarse | 1 |
| 16964 | ruborizada | 1 |
| 16965 | rubor | 1 |
| 16966 | rubines | 1 |
| 16967 | rubias | 1 |
| 16968 | rubén | 1 |
| 16969 | rropa | 1 |
| 16970 | rozó | 1 |
| 16971 | rozamiento | 1 |
| 16972 | rozadura | 1 |
| 16973 | rozaban | 1 |
| 16974 | royendo | 1 |
| 16975 | rotura | 1 |
| 16976 | rothschild | 1 |
| 16977 | roten | 1 |
| 16978 | rostchild | 1 |
| 16979 | rossiniano | 1 |
| 16980 | rosicler | 1 |
| 16981 | rosca | 1 |
| 16982 | rosados | 1 |
| 16983 | rosada | 1 |
| 16984 | ros | 1 |
| 16985 | rorrooó | 1 |
| 16986 | roque | 1 |
| 16987 | ropillas | 1 |
| 16988 | ropaje | 1 |
| 16989 | roñosas | 1 |
| 16990 | roña | 1 |
| 16991 | ronde | 1 |
| 16992 | rondara | 1 |
| 16993 | rondar | 1 |
| 16994 | ronco | 1 |
| 16995 | roncas | 1 |
| 16996 | roncando | 1 |
| 16997 | roncaban | 1 |
| 16998 | roncaba | 1 |
| 16999 | rompiéndose | 1 |
| 17000 | rompí | 1 |
| 17001 | romperte | 1 |
| 17002 | romperse | 1 |
| 17003 | romperle | 1 |
| 17004 | romperla | 1 |
| 17005 | rompemos | 1 |
| 17006 | rómpeme | 1 |
| 17007 | rompelanzas | 1 |
| 17008 | romos | 1 |
| 17009 | romerías | 1 |
| 17010 | rombo | 1 |
| 17011 | romanzas | 1 |
| 17012 | romántico | 1 |
| 17013 | románicos | 1 |
| 17014 | romancesco | 1 |
| 17015 | romancesca | 1 |
| 17016 | romana | 1 |
| 17017 | romadizo | 1 |
| 17018 | rollos | 1 |
| 17019 | rollo | 1 |
| 17020 | rojizo | 1 |
| 17021 | rojizas | 1 |
| 17022 | roído | 1 |
| 17023 | roía | 1 |
| 17024 | roger | 1 |
| 17025 | rogaron | 1 |
| 17026 | rogarle | 1 |
| 17027 | rogando | 1 |
| 17028 | rogado | 1 |
| 17029 | roer | 1 |
| 17030 | roedor | 1 |
| 17031 | rodríguez | 1 |
| 17032 | rodó | 1 |
| 17033 | rodil | 1 |
| 17034 | rodeó | 1 |
| 17035 | rodeo | 1 |
| 17036 | rodearse | 1 |
| 17037 | rodean | 1 |
| 17038 | rodeados | 1 |
| 17039 | rodadas | 1 |
| 17040 | rocío | 1 |
| 17041 | rociada | 1 |
| 17042 | rocas | 1 |
| 17043 | robustecer | 1 |
| 17044 | robos | 1 |
| 17045 | robó | 1 |
| 17046 | robledo | 1 |
| 17047 | roben | 1 |
| 17048 | robe | 1 |
| 17049 | robaste | 1 |
| 17050 | robaron | 1 |
| 17051 | robármelo | 1 |
| 17052 | robaré | 1 |
| 17053 | robaran | 1 |
| 17054 | robará | 1 |
| 17055 | robara | 1 |
| 17056 | robándoselo | 1 |
| 17057 | roban | 1 |
| 17058 | robaban | 1 |
| 17059 | road | 1 |
| 17060 | rizoso | 1 |
| 17061 | rizosa | 1 |
| 17062 | rizarse | 1 |
| 17063 | rizada | 1 |
| 17064 | rivalidades | 1 |
| 17065 | ritual | 1 |
| 17066 | ritos | 1 |
| 17067 | ritornellos | 1 |
| 17068 | ritmos | 1 |
| 17069 | rítmico | 1 |
| 17070 | rita | 1 |
| 17071 | risitas | 1 |
| 17072 | risibles | 1 |
| 17073 | risible | 1 |
| 17074 | riquísima | 1 |
| 17075 | ripio | 1 |
| 17076 | riose | 1 |
| 17077 | ríos | 1 |
| 17078 | rioja | 1 |
| 17079 | riñó | 1 |
| 17080 | riñan | 1 |
| 17081 | riña | 1 |
| 17082 | ringorrangos | 1 |
| 17083 | rindiera | 1 |
| 17084 | rinden | 1 |
| 17085 | rinde | 1 |
| 17086 | rinconadas | 1 |
| 17087 | rimpuesta | 1 |
| 17088 | rimero | 1 |
| 17089 | rimados | 1 |
| 17090 | rija | 1 |
| 17091 | rigurosas | 1 |
| 17092 | rigoristas | 1 |
| 17093 | rígidamente | 1 |
| 17094 | rifle | 1 |
| 17095 | rifarla | 1 |
| 17096 | riesgo | 1 |
| 17097 | rieras | 1 |
| 17098 | rieran | 1 |
| 17099 | riéndole | 1 |
| 17100 | ridiculizando | 1 |
| 17101 | ridículas | 1 |
| 17102 | ridículamente | 1 |
| 17103 | ricardo | 1 |
| 17104 | ricacho | 1 |
| 17105 | ricacha | 1 |
| 17106 | ribeteada | 1 |
| 17107 | ribete | 1 |
| 17108 | ribera | 1 |
| 17109 | ríase | 1 |
| 17110 | ríanse | 1 |
| 17111 | rían | 1 |
| 17112 | rezumos | 1 |
| 17113 | rezumía | 1 |
| 17114 | rezumados | 1 |
| 17115 | rezongó | 1 |
| 17116 | rezongar | 1 |
| 17117 | rezongaba | 1 |
| 17118 | rezarían | 1 |
| 17119 | rezaría | 1 |
| 17120 | rezándole | 1 |
| 17121 | rézale | 1 |
| 17122 | rezagadas | 1 |
| 17123 | rezagada | 1 |
| 17124 | rezado | 1 |
| 17125 | rezaban | 1 |
| 17126 | revuelve | 1 |
| 17127 | revuelcos | 1 |
| 17128 | revuelco | 1 |
| 17129 | revolviese | 1 |
| 17130 | revolvieron | 1 |
| 17131 | revolviéndola | 1 |
| 17132 | revolverlas | 1 |
| 17133 | revoltosa | 1 |
| 17134 | revoloteó | 1 |
| 17135 | revolotear | 1 |
| 17136 | revoloteaban | 1 |
| 17137 | revolcose | 1 |
| 17138 | revolcarse | 1 |
| 17139 | reviviendo | 1 |
| 17140 | revistió | 1 |
| 17141 | revistiéndolas | 1 |
| 17142 | revisten | 1 |
| 17143 | revisión | 1 |
| 17144 | revisaré | 1 |
| 17145 | reviradas | 1 |
| 17146 | revientan | 1 |
| 17147 | revestirse | 1 |
| 17148 | revestir | 1 |
| 17149 | revestimiento | 1 |
| 17150 | revestido | 1 |
| 17151 | revestían | 1 |
| 17152 | reveses | 1 |
| 17153 | revertida | 1 |
| 17154 | reversión | 1 |
| 17155 | reverente | 1 |
| 17156 | reverencias | 1 |
| 17157 | reverencia | 1 |
| 17158 | reverdeció | 1 |
| 17159 | reverdeciendo | 1 |
| 17160 | reverdecidas | 1 |
| 17161 | reverdecer | 1 |
| 17162 | reverdece | 1 |
| 17163 | reverberos | 1 |
| 17164 | reverberar | 1 |
| 17165 | reventó | 1 |
| 17166 | reventas | 1 |
| 17167 | reventaban | 1 |
| 17168 | revenidos | 1 |
| 17169 | revelarte | 1 |
| 17170 | revelaron | 1 |
| 17171 | revelarle | 1 |
| 17172 | revelara | 1 |
| 17173 | reveladas | 1 |
| 17174 | revelada | 1 |
| 17175 | reunir | 1 |
| 17176 | reunió | 1 |
| 17177 | reunieran | 1 |
| 17178 | reuniendo | 1 |
| 17179 | reunido | 1 |
| 17180 | reunidas | 1 |
| 17181 | reunía | 1 |
| 17182 | reúne | 1 |
| 17183 | reumáticos | 1 |
| 17184 | retuvieron | 1 |
| 17185 | retumbó | 1 |
| 17186 | retumbantes | 1 |
| 17187 | retumban | 1 |
| 17188 | retumbado | 1 |
| 17189 | retumbaban | 1 |
| 17190 | retumbaba | 1 |
| 17191 | retuerce | 1 |
| 17192 | retrogradaba | 1 |
| 17193 | retratarse | 1 |
| 17194 | retratar | 1 |
| 17195 | retratada | 1 |
| 17196 | retrataaar | 1 |
| 17197 | retrasar | 1 |
| 17198 | retrasados | 1 |
| 17199 | retrasada | 1 |
| 17200 | retrasaba | 1 |
| 17201 | retraimiento | 1 |
| 17202 | retraerse | 1 |
| 17203 | retozos | 1 |
| 17204 | retortijado | 1 |
| 17205 | retortero | 1 |
| 17206 | retorta | 1 |
| 17207 | retóricos | 1 |
| 17208 | retórica | 1 |
| 17209 | retorciendo | 1 |
| 17210 | retorcidos | 1 |
| 17211 | retorcidas | 1 |
| 17212 | retorcía | 1 |
| 17213 | retorcedura | 1 |
| 17214 | retor | 1 |
| 17215 | retoñado | 1 |
| 17216 | retocando | 1 |
| 17217 | reto | 1 |
| 17218 | retires | 1 |
| 17219 | retiré | 1 |
| 17220 | retire | 1 |
| 17221 | retirase | 1 |
| 17222 | retirarlos | 1 |
| 17223 | retirarle | 1 |
| 17224 | retiraran | 1 |
| 17225 | retirándolo | 1 |
| 17226 | retirando | 1 |
| 17227 | retiradamente | 1 |
| 17228 | retirábase | 1 |
| 17229 | retiraban | 1 |
| 17230 | retina | 1 |
| 17231 | reticencias | 1 |
| 17232 | reteniéndole | 1 |
| 17233 | reteniéndola | 1 |
| 17234 | retenido | 1 |
| 17235 | retenían | 1 |
| 17236 | retenerlo | 1 |
| 17237 | retenerle | 1 |
| 17238 | retención | 1 |
| 17239 | retemblar | 1 |
| 17240 | retazos | 1 |
| 17241 | retardaba | 1 |
| 17242 | retaba | 1 |
| 17243 | resurgía | 1 |
| 17244 | resumen | 1 |
| 17245 | resultole | 1 |
| 17246 | resultasen | 1 |
| 17247 | resultase | 1 |
| 17248 | resultarle | 1 |
| 17249 | resultará | 1 |
| 17250 | resultara | 1 |
| 17251 | resultar | 1 |
| 17252 | resultan | 1 |
| 17253 | resuelven | 1 |
| 17254 | resuelva | 1 |
| 17255 | resueltos | 1 |
| 17256 | resuella | 1 |
| 17257 | resucitara | 1 |
| 17258 | resucitar | 1 |
| 17259 | resucitan | 1 |
| 17260 | resucitado | 1 |
| 17261 | restregón | 1 |
| 17262 | restregó | 1 |
| 17263 | restregáronle | 1 |
| 17264 | restregado | 1 |
| 17265 | restregaba | 1 |
| 17266 | restaurar | 1 |
| 17267 | restaurant | 1 |
| 17268 | restauradas | 1 |
| 17269 | restauraba | 1 |
| 17270 | restañaba | 1 |
| 17271 | restantes | 1 |
| 17272 | restallaban | 1 |
| 17273 | restablecimiento | 1 |
| 17274 | restablecido | 1 |
| 17275 | restablecer | 1 |
| 17276 | restaba | 1 |
| 17277 | resta | 1 |
| 17278 | resquebrajaba | 1 |
| 17279 | responso | 1 |
| 17280 | responsabilidades | 1 |
| 17281 | respondona | 1 |
| 17282 | respondiome | 1 |
| 17283 | respondieran | 1 |
| 17284 | respondiera | 1 |
| 17285 | respondiéndome | 1 |
| 17286 | respondiéndole | 1 |
| 17287 | respondería | 1 |
| 17288 | respóndame | 1 |
| 17289 | resplandores | 1 |
| 17290 | resplandeció | 1 |
| 17291 | resplandecientes | 1 |
| 17292 | resplandeciendo | 1 |
| 17293 | resplandecían | 1 |
| 17294 | respirase | 1 |
| 17295 | respiraron | 1 |
| 17296 | respirado | 1 |
| 17297 | respiraderos | 1 |
| 17298 | respirable | 1 |
| 17299 | respingar | 1 |
| 17300 | respingados | 1 |
| 17301 | respingadas | 1 |
| 17302 | réspices | 1 |
| 17303 | respetuosos | 1 |
| 17304 | respetuosamente | 1 |
| 17305 | respetosa | 1 |
| 17306 | respéteme | 1 |
| 17307 | respete | 1 |
| 17308 | respetaran | 1 |
| 17309 | respetado | 1 |
| 17310 | respetad | 1 |
| 17311 | respetabilísimo | 1 |
| 17312 | respetabilísimas | 1 |
| 17313 | respetaba | 1 |
| 17314 | respeta | 1 |
| 17315 | resortes | 1 |
| 17316 | resorte | 1 |
| 17317 | resoplido | 1 |
| 17318 | resonarán | 1 |
| 17319 | resonar | 1 |
| 17320 | resonantes | 1 |
| 17321 | resonaban | 1 |
| 17322 | resonaba | 1 |
| 17323 | resolvimos | 1 |
| 17324 | resolviéndose | 1 |
| 17325 | resolviendo | 1 |
| 17326 | resolvíase | 1 |
| 17327 | resolvía | 1 |
| 17328 | resolverse | 1 |
| 17329 | resolverlos | 1 |
| 17330 | resolverlo | 1 |
| 17331 | resolverá | 1 |
| 17332 | resoluciones | 1 |
| 17333 | resobándose | 1 |
| 17334 | resobado | 1 |
| 17335 | resobaba | 1 |
| 17336 | resma | 1 |
| 17337 | resisto | 1 |
| 17338 | resistirlo | 1 |
| 17339 | resistió | 1 |
| 17340 | resistiese | 1 |
| 17341 | resistieras | 1 |
| 17342 | resistiera | 1 |
| 17343 | resistiendo | 1 |
| 17344 | resistido | 1 |
| 17345 | resistes | 1 |
| 17346 | resistente | 1 |
| 17347 | resistencias | 1 |
| 17348 | resisten | 1 |
| 17349 | resinas | 1 |
| 17350 | resigne | 1 |
| 17351 | resignado | 1 |
| 17352 | resignadas | 1 |
| 17353 | resido | 1 |
| 17354 | residían | 1 |
| 17355 | residía | 1 |
| 17356 | reside | 1 |
| 17357 | resguardo | 1 |
| 17358 | resguardar | 1 |
| 17359 | reses | 1 |
| 17360 | reservo | 1 |
| 17361 | reservas | 1 |
| 17362 | reservarse | 1 |
| 17363 | reservarle | 1 |
| 17364 | reservando | 1 |
| 17365 | reservadísimo | 1 |
| 17366 | resentirse | 1 |
| 17367 | resentimiento | 1 |
| 17368 | reselles | 1 |
| 17369 | resecaban | 1 |
| 17370 | rescoldo | 1 |
| 17371 | resbalón | 1 |
| 17372 | resbalar | 1 |
| 17373 | resbalan | 1 |
| 17374 | resbaladiza | 1 |
| 17375 | resbalaban | 1 |
| 17376 | resaltar | 1 |
| 17377 | resalao | 1 |
| 17378 | requisito | 1 |
| 17379 | requetefinas | 1 |
| 17380 | requesón | 1 |
| 17381 | requerido | 1 |
| 17382 | requería | 1 |
| 17383 | requemo | 1 |
| 17384 | requemado | 1 |
| 17385 | requejo | 1 |
| 17386 | reputados | 1 |
| 17387 | reputaban | 1 |
| 17388 | repuntaba | 1 |
| 17389 | repulsión | 1 |
| 17390 | repulgos | 1 |
| 17391 | repulgo | 1 |
| 17392 | repugnaría | 1 |
| 17393 | repúblicas | 1 |
| 17394 | republicanismo | 1 |
| 17395 | reprodujeron | 1 |
| 17396 | reprodujera | 1 |
| 17397 | reproducir | 1 |
| 17398 | reproduciéndose | 1 |
| 17399 | reproduciéndolo | 1 |
| 17400 | reproduciendo | 1 |
| 17401 | reproducídose | 1 |
| 17402 | reproducidas | 1 |
| 17403 | reprobación | 1 |
| 17404 | reprobables | 1 |
| 17405 | reprimir | 1 |
| 17406 | represente | 1 |
| 17407 | representaron | 1 |
| 17408 | representando | 1 |
| 17409 | representan | 1 |
| 17410 | representaciones | 1 |
| 17411 | reprensión | 1 |
| 17412 | reprendieran | 1 |
| 17413 | reprenderla | 1 |
| 17414 | reprenden | 1 |
| 17415 | repreciosa | 1 |
| 17416 | repostero | 1 |
| 17417 | reposada | 1 |
| 17418 | reponiéndose | 1 |
| 17419 | reponiendo | 1 |
| 17420 | reponerte | 1 |
| 17421 | repoblicanas | 1 |
| 17422 | repliegue | 1 |
| 17423 | repliégate | 1 |
| 17424 | repitiese | 1 |
| 17425 | repitiéndose | 1 |
| 17426 | repitiéndole | 1 |
| 17427 | repítelas | 1 |
| 17428 | repiques | 1 |
| 17429 | repique | 1 |
| 17430 | repicando | 1 |
| 17431 | repetírselo | 1 |
| 17432 | repetido | 1 |
| 17433 | repentina | 1 |
| 17434 | repasó | 1 |
| 17435 | repasando | 1 |
| 17436 | repasaba | 1 |
| 17437 | repartirse | 1 |
| 17438 | repartiría | 1 |
| 17439 | repartido | 1 |
| 17440 | repartidas | 1 |
| 17441 | repartían | 1 |
| 17442 | repartía | 1 |
| 17443 | reparta | 1 |
| 17444 | reparona | 1 |
| 17445 | repares | 1 |
| 17446 | reparatrices | 1 |
| 17447 | repararía | 1 |
| 17448 | reparando | 1 |
| 17449 | reparaba | 1 |
| 17450 | repara | 1 |
| 17451 | repantigado | 1 |
| 17452 | reñían | 1 |
| 17453 | renuncia | 1 |
| 17454 | rentita | 1 |
| 17455 | renovó | 1 |
| 17456 | renovase | 1 |
| 17457 | renovará | 1 |
| 17458 | renovaciones | 1 |
| 17459 | renovaban | 1 |
| 17460 | renovaba | 1 |
| 17461 | rengloncito | 1 |
| 17462 | renegó | 1 |
| 17463 | rendirle | 1 |
| 17464 | rendir | 1 |
| 17465 | rendidísimo | 1 |
| 17466 | rendidísima | 1 |
| 17467 | rendía | 1 |
| 17468 | rencoroso | 1 |
| 17469 | rencorosa | 1 |
| 17470 | rencores | 1 |
| 17471 | rencorcillo | 1 |
| 17472 | renacimiento | 1 |
| 17473 | renacía | 1 |
| 17474 | remuerde | 1 |
| 17475 | removió | 1 |
| 17476 | removieran | 1 |
| 17477 | removía | 1 |
| 17478 | remotísimo | 1 |
| 17479 | remotamente | 1 |
| 17480 | remos | 1 |
| 17481 | remontó | 1 |
| 17482 | remontarme | 1 |
| 17483 | remontabas | 1 |
| 17484 | remontaba | 1 |
| 17485 | remonona | 1 |
| 17486 | remolque | 1 |
| 17487 | remolcándola | 1 |
| 17488 | remitiese | 1 |
| 17489 | remitidas | 1 |
| 17490 | remitía | 1 |
| 17491 | remite | 1 |
| 17492 | reminiscencias | 1 |
| 17493 | remilgadas | 1 |
| 17494 | remilgada | 1 |
| 17495 | remiendo | 1 |
| 17496 | remesa | 1 |
| 17497 | remendarla | 1 |
| 17498 | remendada | 1 |
| 17499 | remedos | 1 |
| 17500 | remedo | 1 |
| 17501 | remedie | 1 |
| 17502 | remediarlo | 1 |
| 17503 | remediaban | 1 |
| 17504 | remedando | 1 |
| 17505 | remeda | 1 |
| 17506 | remataron | 1 |
| 17507 | rematar | 1 |
| 17508 | rematados | 1 |
| 17509 | rematadas | 1 |
| 17510 | remataban | 1 |
| 17511 | remala | 1 |
| 17512 | remadera | 1 |
| 17513 | remachando | 1 |
| 17514 | relumbrones | 1 |
| 17515 | relumbrón | 1 |
| 17516 | relumbrantes | 1 |
| 17517 | relumbrante | 1 |
| 17518 | relucían | 1 |
| 17519 | relojero | 1 |
| 17520 | relojería | 1 |
| 17521 | reliquias | 1 |
| 17522 | relevase | 1 |
| 17523 | relevado | 1 |
| 17524 | relatos | 1 |
| 17525 | relatando | 1 |
| 17526 | relataba | 1 |
| 17527 | relampagueaban | 1 |
| 17528 | relamiendo | 1 |
| 17529 | relamida | 1 |
| 17530 | relámete | 1 |
| 17531 | relamerse | 1 |
| 17532 | relajadas | 1 |
| 17533 | relacionase | 1 |
| 17534 | relacionara | 1 |
| 17535 | relacionado | 1 |
| 17536 | relacionaban | 1 |
| 17537 | relacionaba | 1 |
| 17538 | relaciona | 1 |
| 17539 | rejuvenece | 1 |
| 17540 | reiterándole | 1 |
| 17541 | reiterando | 1 |
| 17542 | reiteradas | 1 |
| 17543 | reíros | 1 |
| 17544 | reirías | 1 |
| 17545 | reirían | 1 |
| 17546 | reiré | 1 |
| 17547 | reirás | 1 |
| 17548 | reintegraría | 1 |
| 17549 | reinos | 1 |
| 17550 | reinó | 1 |
| 17551 | reincidir | 1 |
| 17552 | reincidente | 1 |
| 17553 | reinara | 1 |
| 17554 | reímos | 1 |
| 17555 | reíase | 1 |
| 17556 | reíanse | 1 |
| 17557 | reíamos | 1 |
| 17558 | reí | 1 |
| 17559 | rehusaron | 1 |
| 17560 | rehuir | 1 |
| 17561 | rehuido | 1 |
| 17562 | rehecho | 1 |
| 17563 | rehacerse | 1 |
| 17564 | rehacer | 1 |
| 17565 | regulares | 1 |
| 17566 | reguapa | 1 |
| 17567 | regresar | 1 |
| 17568 | regresaba | 1 |
| 17569 | regresa | 1 |
| 17570 | regrande | 1 |
| 17571 | regordete | 1 |
| 17572 | regocijar | 1 |
| 17573 | regocijándose | 1 |
| 17574 | regocijadas | 1 |
| 17575 | regocijada | 1 |
| 17576 | reglamentario | 1 |
| 17577 | registraremos | 1 |
| 17578 | registrado | 1 |
| 17579 | regimientos | 1 |
| 17580 | regenerarte | 1 |
| 17581 | regenerarlas | 1 |
| 17582 | regenerada | 1 |
| 17583 | regeneraciones | 1 |
| 17584 | regeneraba | 1 |
| 17585 | regateando | 1 |
| 17586 | regateaba | 1 |
| 17587 | regar | 1 |
| 17588 | regaños | 1 |
| 17589 | regañona | 1 |
| 17590 | regañó | 1 |
| 17591 | regaño | 1 |
| 17592 | regañar | 1 |
| 17593 | regando | 1 |
| 17594 | regalona | 1 |
| 17595 | regaló | 1 |
| 17596 | regalé | 1 |
| 17597 | regalarte | 1 |
| 17598 | regaláronle | 1 |
| 17599 | regaláramos | 1 |
| 17600 | regalado | 1 |
| 17601 | regalaba | 1 |
| 17602 | regaderas | 1 |
| 17603 | regaba | 1 |
| 17604 | refutara | 1 |
| 17605 | refunfuños | 1 |
| 17606 | refunfuñas | 1 |
| 17607 | refunfuñan | 1 |
| 17608 | refundiéndose | 1 |
| 17609 | refundida | 1 |
| 17610 | refulgentes | 1 |
| 17611 | refugió | 1 |
| 17612 | refugiarse | 1 |
| 17613 | refuerzo | 1 |
| 17614 | refrescar | 1 |
| 17615 | refrescan | 1 |
| 17616 | refrénate | 1 |
| 17617 | refrenase | 1 |
| 17618 | refrenarse | 1 |
| 17619 | refrenar | 1 |
| 17620 | refregones | 1 |
| 17621 | refregarte | 1 |
| 17622 | refregar | 1 |
| 17623 | refractario | 1 |
| 17624 | reforme | 1 |
| 17625 | reformase | 1 |
| 17626 | reformar | 1 |
| 17627 | reformada | 1 |
| 17628 | reflexivo | 1 |
| 17629 | reflexiva | 1 |
| 17630 | reflexiono | 1 |
| 17631 | reflexionaba | 1 |
| 17632 | reflejándose | 1 |
| 17633 | reflejábase | 1 |
| 17634 | reflejaba | 1 |
| 17635 | refiriéndose | 1 |
| 17636 | refirencias | 1 |
| 17637 | refinarlos | 1 |
| 17638 | refinar | 1 |
| 17639 | refinamientos | 1 |
| 17640 | refinada | 1 |
| 17641 | refiérome | 1 |
| 17642 | refiera | 1 |
| 17643 | referirle | 1 |
| 17644 | referirían | 1 |
| 17645 | referido | 1 |
| 17646 | referían | 1 |
| 17647 | referencias | 1 |
| 17648 | referencia | 1 |
| 17649 | refeos | 1 |
| 17650 | refectorio | 1 |
| 17651 | reductos | 1 |
| 17652 | reducirlo | 1 |
| 17653 | reduciéndose | 1 |
| 17654 | reducidos | 1 |
| 17655 | reducidas | 1 |
| 17656 | reducen | 1 |
| 17657 | redondel | 1 |
| 17658 | redondear | 1 |
| 17659 | redondeado | 1 |
| 17660 | redondas | 1 |
| 17661 | redoblar | 1 |
| 17662 | redentorista | 1 |
| 17663 | redenciones | 1 |
| 17664 | redaño | 1 |
| 17665 | redactar | 1 |
| 17666 | redactada | 1 |
| 17667 | recuento | 1 |
| 17668 | rectos | 1 |
| 17669 | rectilíneas | 1 |
| 17670 | rectificó | 1 |
| 17671 | recrudecimiento | 1 |
| 17672 | recreábase | 1 |
| 17673 | recreaban | 1 |
| 17674 | recrea | 1 |
| 17675 | recostase | 1 |
| 17676 | recostaba | 1 |
| 17677 | recortaran | 1 |
| 17678 | recortándolo | 1 |
| 17679 | recortadas | 1 |
| 17680 | recortaba | 1 |
| 17681 | recorta | 1 |
| 17682 | recorrieron | 1 |
| 17683 | recorren | 1 |
| 17684 | recordase | 1 |
| 17685 | recordarme | 1 |
| 17686 | recordarás | 1 |
| 17687 | reconstruí | 1 |
| 17688 | reconstituyentes | 1 |
| 17689 | reconozca | 1 |
| 17690 | reconocidos | 1 |
| 17691 | reconocida | 1 |
| 17692 | reconocían | 1 |
| 17693 | reconoces | 1 |
| 17694 | reconocerlo | 1 |
| 17695 | reconocerlas | 1 |
| 17696 | reconoceremos | 1 |
| 17697 | reconocerá | 1 |
| 17698 | reconocen | 1 |
| 17699 | recondenada | 1 |
| 17700 | reconciliémonos | 1 |
| 17701 | reconciliaron | 1 |
| 17702 | reconciliar | 1 |
| 17703 | reconciliado | 1 |
| 17704 | reconciliaciones | 1 |
| 17705 | reconciliábamos | 1 |
| 17706 | reconcilia | 1 |
| 17707 | reconcentrado | 1 |
| 17708 | recomponía | 1 |
| 17709 | recompensaba | 1 |
| 17710 | recompensa | 1 |
| 17711 | recomiendan | 1 |
| 17712 | recomendé | 1 |
| 17713 | recomendando | 1 |
| 17714 | recomendados | 1 |
| 17715 | recomendadas | 1 |
| 17716 | recomendada | 1 |
| 17717 | recomendables | 1 |
| 17718 | recoletos | 1 |
| 17719 | recojo | 1 |
| 17720 | recoja | 1 |
| 17721 | recogiéndolo | 1 |
| 17722 | recogiéndole | 1 |
| 17723 | recogían | 1 |
| 17724 | recogerlos | 1 |
| 17725 | recogerlo | 1 |
| 17726 | recogerlas | 1 |
| 17727 | recogeremos | 1 |
| 17728 | recogeré | 1 |
| 17729 | recogerá | 1 |
| 17730 | recobrada | 1 |
| 17731 | recoba | 1 |
| 17732 | reclinó | 1 |
| 17733 | reclinatorios | 1 |
| 17734 | reclinado | 1 |
| 17735 | reclinada | 1 |
| 17736 | reclamarlo | 1 |
| 17737 | reclamará | 1 |
| 17738 | reclamando | 1 |
| 17739 | reclamado | 1 |
| 17740 | reclamaba | 1 |
| 17741 | recios | 1 |
| 17742 | recio | 1 |
| 17743 | recientes | 1 |
| 17744 | recibirme | 1 |
| 17745 | recibirle | 1 |
| 17746 | recibirás | 1 |
| 17747 | recibiome | 1 |
| 17748 | recibidas | 1 |
| 17749 | recibías | 1 |
| 17750 | recíbele | 1 |
| 17751 | rechupidos | 1 |
| 17752 | rechupete | 1 |
| 17753 | rechupando | 1 |
| 17754 | rechupado | 1 |
| 17755 | rechinando | 1 |
| 17756 | rechinaba | 1 |
| 17757 | rechina | 1 |
| 17758 | rechazó | 1 |
| 17759 | rechazara | 1 |
| 17760 | rechazándola | 1 |
| 17761 | rechazada | 1 |
| 17762 | rechacemos | 1 |
| 17763 | recetó | 1 |
| 17764 | recetaría | 1 |
| 17765 | recetábale | 1 |
| 17766 | recelos | 1 |
| 17767 | rece | 1 |
| 17768 | recayó | 1 |
| 17769 | recayese | 1 |
| 17770 | recayera | 1 |
| 17771 | recaudados | 1 |
| 17772 | recaudador | 1 |
| 17773 | recaudación | 1 |
| 17774 | recatarse | 1 |
| 17775 | recatándose | 1 |
| 17776 | recatado | 1 |
| 17777 | recargaba | 1 |
| 17778 | recapacitando | 1 |
| 17779 | recalentaban | 1 |
| 17780 | recalcar | 1 |
| 17781 | recaída | 1 |
| 17782 | recaía | 1 |
| 17783 | recaen | 1 |
| 17784 | recae | 1 |
| 17785 | recaditos | 1 |
| 17786 | rebuznó | 1 |
| 17787 | rebuznar | 1 |
| 17788 | rebusque | 1 |
| 17789 | rebuscó | 1 |
| 17790 | rebuscada | 1 |
| 17791 | rebuscaba | 1 |
| 17792 | rebullir | 1 |
| 17793 | rebullicio | 1 |
| 17794 | rebulle | 1 |
| 17795 | rebosaban | 1 |
| 17796 | rebosa | 1 |
| 17797 | reblandeció | 1 |
| 17798 | reblandecimiento | 1 |
| 17799 | rebeló | 1 |
| 17800 | rebelarse | 1 |
| 17801 | rebelaba | 1 |
| 17802 | rebeca | 1 |
| 17803 | rebasaron | 1 |
| 17804 | rebasados | 1 |
| 17805 | rebañaba | 1 |
| 17806 | rebaña | 1 |
| 17807 | rebanada | 1 |
| 17808 | rebajes | 1 |
| 17809 | rebajase | 1 |
| 17810 | rebajarse | 1 |
| 17811 | rebajaremos | 1 |
| 17812 | rebajar | 1 |
| 17813 | rebajado | 1 |
| 17814 | rebajada | 1 |
| 17815 | rebaja | 1 |
| 17816 | reapertura | 1 |
| 17817 | reapareció | 1 |
| 17818 | reaparecieron | 1 |
| 17819 | reaparecer | 1 |
| 17820 | reaparecen | 1 |
| 17821 | reanudar | 1 |
| 17822 | reanimaba | 1 |
| 17823 | realizarlos | 1 |
| 17824 | realizarla | 1 |
| 17825 | realizaría | 1 |
| 17826 | realizara | 1 |
| 17827 | realizado | 1 |
| 17828 | realizadas | 1 |
| 17829 | realizada | 1 |
| 17830 | realización | 1 |
| 17831 | realito | 1 |
| 17832 | realista | 1 |
| 17833 | realice | 1 |
| 17834 | realetes | 1 |
| 17835 | reacciones | 1 |
| 17836 | razonando | 1 |
| 17837 | razonamientos | 1 |
| 17838 | razonador | 1 |
| 17839 | razonables | 1 |
| 17840 | razona | 1 |
| 17841 | rayuela | 1 |
| 17842 | rayana | 1 |
| 17843 | rayaditas | 1 |
| 17844 | rayaba | 1 |
| 17845 | raudo | 1 |
| 17846 | raudales | 1 |
| 17847 | ratoncillo | 1 |
| 17848 | ratifico | 1 |
| 17849 | ratera | 1 |
| 17850 | rastros | 1 |
| 17851 | rastrear | 1 |
| 17852 | rásquese | 1 |
| 17853 | rasque | 1 |
| 17854 | raspe | 1 |
| 17855 | raspándolo | 1 |
| 17856 | rasos | 1 |
| 17857 | rasguñaban | 1 |
| 17858 | rasgueo | 1 |
| 17859 | rasguear | 1 |
| 17860 | rasgueando | 1 |
| 17861 | rasgar | 1 |
| 17862 | rascarse | 1 |
| 17863 | rascándose | 1 |
| 17864 | rascan | 1 |
| 17865 | ráscame | 1 |
| 17866 | rarificaciones | 1 |
| 17867 | rarezas | 1 |
| 17868 | raquitismo | 1 |
| 17869 | raquíticos | 1 |
| 17870 | rápidos | 1 |
| 17871 | rapé | 1 |
| 17872 | rapazuelo | 1 |
| 17873 | raparte | 1 |
| 17874 | rapadas | 1 |
| 17875 | rapada | 1 |
| 17876 | rapacidad | 1 |
| 17877 | ranero | 1 |
| 17878 | randas | 1 |
| 17879 | rancios | 1 |
| 17880 | rancias | 1 |
| 17881 | ranas | 1 |
| 17882 | rana | 1 |
| 17883 | ramplona | 1 |
| 17884 | rampas | 1 |
| 17885 | rampa | 1 |
| 17886 | ramona | 1 |
| 17887 | ramojo | 1 |
| 17888 | ramilletes | 1 |
| 17889 | rameados | 1 |
| 17890 | rameaditas | 1 |
| 17891 | ramalazo | 1 |
| 17892 | rallando | 1 |
| 17893 | ralea | 1 |
| 17894 | rajada | 1 |
| 17895 | raja | 1 |
| 17896 | raíz | 1 |
| 17897 | raída | 1 |
| 17898 | raíces | 1 |
| 17899 | radio | 1 |
| 17900 | radicalmente | 1 |
| 17901 | radical | 1 |
| 17902 | radicaba | 1 |
| 17903 | racionó | 1 |
| 17904 | racionarse | 1 |
| 17905 | racionarnos | 1 |
| 17906 | racionalistas | 1 |
| 17907 | racionales | 1 |
| 17908 | raciocinios | 1 |
| 17909 | rabos | 1 |
| 17910 | rabito | 1 |
| 17911 | rabiosito | 1 |
| 17912 | rabiosilla | 1 |
| 17913 | rabillo | 1 |
| 17914 | rabietinas | 1 |
| 17915 | rabiará | 1 |
| 17916 | rabiaba | 1 |
| 17917 | rabeles | 1 |
| 17918 | rabel | 1 |
| 17919 | r | 1 |
| 17920 | quo | 1 |
| 17921 | quitósele | 1 |
| 17922 | quitole | 1 |
| 17923 | quites | 1 |
| 17924 | quíteme | 1 |
| 17925 | quité | 1 |
| 17926 | quitas | 1 |
| 17927 | quitárselas | 1 |
| 17928 | quitáronle | 1 |
| 17929 | quitármelo | 1 |
| 17930 | quitármela | 1 |
| 17931 | quitarme | 1 |
| 17932 | quitarlos | 1 |
| 17933 | quitarlo | 1 |
| 17934 | quitaría | 1 |
| 17935 | quitaré | 1 |
| 17936 | quitaran | 1 |
| 17937 | quitaos | 1 |
| 17938 | quitándome | 1 |
| 17939 | quitamos | 1 |
| 17940 | quítale | 1 |
| 17941 | quitádmelo | 1 |
| 17942 | quisto | 1 |
| 17943 | quisquilloso | 1 |
| 17944 | quisieren | 1 |
| 17945 | quisierais | 1 |
| 17946 | quirúrgicamente | 1 |
| 17947 | quiquiriquí | 1 |
| 17948 | quintín | 1 |
| 17949 | quintillas | 1 |
| 17950 | quintero | 1 |
| 17951 | quintas | 1 |
| 17952 | quintal | 1 |
| 17953 | quinina | 1 |
| 17954 | quinientas | 1 |
| 17955 | quincalla | 1 |
| 17956 | quina | 1 |
| 17957 | químicos | 1 |
| 17958 | químico | 1 |
| 17959 | quilo | 1 |
| 17960 | quijotesco | 1 |
| 17961 | quijadas | 1 |
| 17962 | quietos | 1 |
| 17963 | quietas | 1 |
| 17964 | quieles | 1 |
| 17965 | quiebros | 1 |
| 17966 | quiebras | 1 |
| 17967 | quiebran | 1 |
| 17968 | queso | 1 |
| 17969 | quesitos | 1 |
| 17970 | quesada | 1 |
| 17971 | querrás | 1 |
| 17972 | querrán | 1 |
| 17973 | queriéndome | 1 |
| 17974 | queriéndole | 1 |
| 17975 | queriéndola | 1 |
| 17976 | queridos | 1 |
| 17977 | queridísimos | 1 |
| 17978 | queridísimo | 1 |
| 17979 | querenciosa | 1 |
| 17980 | querencias | 1 |
| 17981 | queramos | 1 |
| 17982 | querámonos | 1 |
| 17983 | quepan | 1 |
| 17984 | queme | 1 |
| 17985 | quemazón | 1 |
| 17986 | quemasteis | 1 |
| 17987 | quemaron | 1 |
| 17988 | quemándose | 1 |
| 17989 | quemando | 1 |
| 17990 | quejumbroso | 1 |
| 17991 | quejo | 1 |
| 17992 | quejáronse | 1 |
| 17993 | quejarás | 1 |
| 17994 | quejar | 1 |
| 17995 | quejando | 1 |
| 17996 | quejamos | 1 |
| 17997 | quejado | 1 |
| 17998 | quedeme | 1 |
| 17999 | quedaste | 1 |
| 18000 | quedasen | 1 |
| 18001 | quedarías | 1 |
| 18002 | quedarás | 1 |
| 18003 | quedaran | 1 |
| 18004 | quedaos | 1 |
| 18005 | quedábamos | 1 |
| 18006 | quebrantar | 1 |
| 18007 | quebrantado | 1 |
| 18008 | quebrantadas | 1 |
| 18009 | qartos | 1 |
| 18010 | putrefacción | 1 |
| 18011 | putona | 1 |
| 18012 | putativa | 1 |
| 18013 | púsolos | 1 |
| 18014 | púsole | 1 |
| 18015 | pusimos | 1 |
| 18016 | pusiéronla | 1 |
| 18017 | púseme | 1 |
| 18018 | purito | 1 |
| 18019 | purísimo | 1 |
| 18020 | purísimas | 1 |
| 18021 | purificarla | 1 |
| 18022 | purificará | 1 |
| 18023 | purificado | 1 |
| 18024 | purificada | 1 |
| 18025 | purga | 1 |
| 18026 | purezas | 1 |
| 18027 | purés | 1 |
| 18028 | pupilas | 1 |
| 18029 | puñetazos | 1 |
| 18030 | puñales | 1 |
| 18031 | puñado | 1 |
| 18032 | punzón | 1 |
| 18033 | punzantes | 1 |
| 18034 | punzadora | 1 |
| 18035 | puntualísimo | 1 |
| 18036 | puntualidades | 1 |
| 18037 | puntillosa | 1 |
| 18038 | puntilla | 1 |
| 18039 | puntiagudos | 1 |
| 18040 | puntear | 1 |
| 18041 | punteados | 1 |
| 18042 | puntapiés | 1 |
| 18043 | puntadas | 1 |
| 18044 | puntada | 1 |
| 18045 | pundonorosas | 1 |
| 18046 | pulverizo | 1 |
| 18047 | pulverizado | 1 |
| 18048 | pulverizadas | 1 |
| 18049 | pulsera | 1 |
| 18050 | pulsaciones | 1 |
| 18051 | pulsación | 1 |
| 18052 | pulpejo | 1 |
| 18053 | pulpa | 1 |
| 18054 | pulmonías | 1 |
| 18055 | pulirse | 1 |
| 18056 | pulimentado | 1 |
| 18057 | puliéndola | 1 |
| 18058 | puliendo | 1 |
| 18059 | pulgares | 1 |
| 18060 | pulgar | 1 |
| 18061 | pulgada | 1 |
| 18062 | pulcra | 1 |
| 18063 | pujanza | 1 |
| 18064 | pujante | 1 |
| 18065 | pugilato | 1 |
| 18066 | puertecilla | 1 |
| 18067 | puerquísima | 1 |
| 18068 | puerilidad | 1 |
| 18069 | puercos | 1 |
| 18070 | puercas | 1 |
| 18071 | puercachones | 1 |
| 18072 | pueblecitos | 1 |
| 18073 | pudre | 1 |
| 18074 | pudiste | 1 |
| 18075 | pudimos | 1 |
| 18076 | pudieras | 1 |
| 18077 | pucheta | 1 |
| 18078 | pucheritos | 1 |
| 18079 | pucherito | 1 |
| 18080 | públicos | 1 |
| 18081 | publicó | 1 |
| 18082 | publicista | 1 |
| 18083 | publicarlos | 1 |
| 18084 | publicantones | 1 |
| 18085 | publicanos | 1 |
| 18086 | publicaban | 1 |
| 18087 | publicaba | 1 |
| 18088 | publica | 1 |
| 18089 | psch | 1 |
| 18090 | pruuun | 1 |
| 18091 | prum | 1 |
| 18092 | pruebo | 1 |
| 18093 | prueban | 1 |
| 18094 | prudhonianas | 1 |
| 18095 | prudentes | 1 |
| 18096 | prudencial | 1 |
| 18097 | proyectiles | 1 |
| 18098 | proyectando | 1 |
| 18099 | proyectan | 1 |
| 18100 | proyectado | 1 |
| 18101 | proyección | 1 |
| 18102 | provocó | 1 |
| 18103 | provocada | 1 |
| 18104 | provisto | 1 |
| 18105 | provino | 1 |
| 18106 | provincianos | 1 |
| 18107 | provincial | 1 |
| 18108 | provenirle | 1 |
| 18109 | provenir | 1 |
| 18110 | provenido | 1 |
| 18111 | provenían | 1 |
| 18112 | provendrá | 1 |
| 18113 | proveía | 1 |
| 18114 | provechosos | 1 |
| 18115 | provechosas | 1 |
| 18116 | protoioduro | 1 |
| 18117 | protestas | 1 |
| 18118 | protestaron | 1 |
| 18119 | protestamos | 1 |
| 18120 | protejo | 1 |
| 18121 | proteja | 1 |
| 18122 | protegiéndole | 1 |
| 18123 | protegidos | 1 |
| 18124 | protegido | 1 |
| 18125 | protegerte | 1 |
| 18126 | protegerle | 1 |
| 18127 | protegería | 1 |
| 18128 | protegeré | 1 |
| 18129 | protegerá | 1 |
| 18130 | protegen | 1 |
| 18131 | protectoras | 1 |
| 18132 | proteccionistas | 1 |
| 18133 | protecciones | 1 |
| 18134 | prostituyese | 1 |
| 18135 | prosterne | 1 |
| 18136 | prospera | 1 |
| 18137 | prosiguieron | 1 |
| 18138 | prosiguiendo | 1 |
| 18139 | prosélitos | 1 |
| 18140 | proscenio | 1 |
| 18141 | prosa | 1 |
| 18142 | prorrumpió | 1 |
| 18143 | prorrumpieron | 1 |
| 18144 | prórrogas | 1 |
| 18145 | propusimos | 1 |
| 18146 | propusieran | 1 |
| 18147 | propuse | 1 |
| 18148 | proporcionó | 1 |
| 18149 | proporcionase | 1 |
| 18150 | proporcionales | 1 |
| 18151 | proporcionado | 1 |
| 18152 | proporcionadamente | 1 |
| 18153 | proporcionada | 1 |
| 18154 | proporcionábale | 1 |
| 18155 | proporcionaba | 1 |
| 18156 | proporciona | 1 |
| 18157 | proponiéndose | 1 |
| 18158 | proponiendo | 1 |
| 18159 | propongámosla | 1 |
| 18160 | propongamos | 1 |
| 18161 | propones | 1 |
| 18162 | proponerte | 1 |
| 18163 | proponérselo | 1 |
| 18164 | proponerse | 1 |
| 18165 | proponerles | 1 |
| 18166 | proponerle | 1 |
| 18167 | propónense | 1 |
| 18168 | propinó | 1 |
| 18169 | propinilla | 1 |
| 18170 | propinas | 1 |
| 18171 | propina | 1 |
| 18172 | propicios | 1 |
| 18173 | propicia | 1 |
| 18174 | propenso | 1 |
| 18175 | propensa | 1 |
| 18176 | propendían | 1 |
| 18177 | propalar | 1 |
| 18178 | propague | 1 |
| 18179 | propagar | 1 |
| 18180 | pronunció | 1 |
| 18181 | pronunciaron | 1 |
| 18182 | pronunciarlo | 1 |
| 18183 | pronunciara | 1 |
| 18184 | pronunciándolas | 1 |
| 18185 | pronuncian | 1 |
| 18186 | pronunciadas | 1 |
| 18187 | pronunciaban | 1 |
| 18188 | pronuncia | 1 |
| 18189 | prontos | 1 |
| 18190 | prontísimo | 1 |
| 18191 | pronósticos | 1 |
| 18192 | pronosticando | 1 |
| 18193 | promulgando | 1 |
| 18194 | promulga | 1 |
| 18195 | promontorio | 1 |
| 18196 | prominentes | 1 |
| 18197 | prometiste | 1 |
| 18198 | prometiéndole | 1 |
| 18199 | prometida | 1 |
| 18200 | prometíaselas | 1 |
| 18201 | prometer | 1 |
| 18202 | promete | 1 |
| 18203 | prolongarse | 1 |
| 18204 | prolongando | 1 |
| 18205 | prolongado | 1 |
| 18206 | prolongaba | 1 |
| 18207 | prolonga | 1 |
| 18208 | prolijidad | 1 |
| 18209 | prolijamente | 1 |
| 18210 | prolífica | 1 |
| 18211 | prójimas | 1 |
| 18212 | proive | 1 |
| 18213 | prohijar | 1 |
| 18214 | prohibió | 1 |
| 18215 | prohibiciones | 1 |
| 18216 | prohibición | 1 |
| 18217 | prohibía | 1 |
| 18218 | prohibí | 1 |
| 18219 | prohíben | 1 |
| 18220 | prohíbe | 1 |
| 18221 | progresos | 1 |
| 18222 | progresivo | 1 |
| 18223 | progresistón | 1 |
| 18224 | progresistas | 1 |
| 18225 | progresado | 1 |
| 18226 | progenie | 1 |
| 18227 | profundísimamente | 1 |
| 18228 | profundidad | 1 |
| 18229 | profetizaron | 1 |
| 18230 | profeta | 1 |
| 18231 | profesora | 1 |
| 18232 | profesionales | 1 |
| 18233 | profesando | 1 |
| 18234 | profesaban | 1 |
| 18235 | profano | 1 |
| 18236 | profanidad | 1 |
| 18237 | profanar | 1 |
| 18238 | profana | 1 |
| 18239 | proezas | 1 |
| 18240 | prodújose | 1 |
| 18241 | produjeron | 1 |
| 18242 | produjera | 1 |
| 18243 | productores | 1 |
| 18244 | producto | 1 |
| 18245 | producirlos | 1 |
| 18246 | producirán | 1 |
| 18247 | produciéndose | 1 |
| 18248 | producidos | 1 |
| 18249 | producidas | 1 |
| 18250 | producíase | 1 |
| 18251 | prodrómico | 1 |
| 18252 | prodigole | 1 |
| 18253 | pródigo | 1 |
| 18254 | prodigioso | 1 |
| 18255 | prodigar | 1 |
| 18256 | prodigándole | 1 |
| 18257 | prodigando | 1 |
| 18258 | prodigaban | 1 |
| 18259 | prodigaba | 1 |
| 18260 | procuró | 1 |
| 18261 | procuro | 1 |
| 18262 | procuremos | 1 |
| 18263 | procure | 1 |
| 18264 | procurarle | 1 |
| 18265 | procuraré | 1 |
| 18266 | procurará | 1 |
| 18267 | procura | 1 |
| 18268 | proclamas | 1 |
| 18269 | proclamar | 1 |
| 18270 | prócida | 1 |
| 18271 | procesionalmente | 1 |
| 18272 | proceroso | 1 |
| 18273 | procediera | 1 |
| 18274 | procedentes | 1 |
| 18275 | procede | 1 |
| 18276 | procedamos | 1 |
| 18277 | procaz | 1 |
| 18278 | procacidad | 1 |
| 18279 | probrecilla | 1 |
| 18280 | probeza | 1 |
| 18281 | probes | 1 |
| 18282 | probe | 1 |
| 18283 | probártelo | 1 |
| 18284 | probarla | 1 |
| 18285 | probaría | 1 |
| 18286 | probaran | 1 |
| 18287 | probará | 1 |
| 18288 | probadas | 1 |
| 18289 | pro | 1 |
| 18290 | privar | 1 |
| 18291 | privándose | 1 |
| 18292 | privándole | 1 |
| 18293 | privadas | 1 |
| 18294 | prismática | 1 |
| 18295 | prisma | 1 |
| 18296 | prisiones | 1 |
| 18297 | prisioneros | 1 |
| 18298 | prisionero | 1 |
| 18299 | pringado | 1 |
| 18300 | pringadas | 1 |
| 18301 | principiar | 1 |
| 18302 | príncipes | 1 |
| 18303 | primos | 1 |
| 18304 | primordial | 1 |
| 18305 | primito | 1 |
| 18306 | primita | 1 |
| 18307 | primeramente | 1 |
| 18308 | primarias | 1 |
| 18309 | primaria | 1 |
| 18310 | price | 1 |
| 18311 | previstos | 1 |
| 18312 | previsora | 1 |
| 18313 | previas | 1 |
| 18314 | previa | 1 |
| 18315 | preventivo | 1 |
| 18316 | prevenirlo | 1 |
| 18317 | prevenidos | 1 |
| 18318 | prevenida | 1 |
| 18319 | prevenciones | 1 |
| 18320 | preveía | 1 |
| 18321 | prevaricaban | 1 |
| 18322 | prevalecido | 1 |
| 18323 | prevalecer | 1 |
| 18324 | prevalece | 1 |
| 18325 | pretérita | 1 |
| 18326 | pretensión | 1 |
| 18327 | pretendiera | 1 |
| 18328 | pretenderás | 1 |
| 18329 | presunta | 1 |
| 18330 | presumiera | 1 |
| 18331 | presumes | 1 |
| 18332 | prestigio | 1 |
| 18333 | prestidigitador | 1 |
| 18334 | prestidigitaciones | 1 |
| 18335 | prestaros | 1 |
| 18336 | prestarle | 1 |
| 18337 | prestara | 1 |
| 18338 | prestándole | 1 |
| 18339 | prestamistas | 1 |
| 18340 | prestaban | 1 |
| 18341 | presta | 1 |
| 18342 | presona | 1 |
| 18343 | presientes | 1 |
| 18344 | presienten | 1 |
| 18345 | presidir | 1 |
| 18346 | presidios | 1 |
| 18347 | presidieran | 1 |
| 18348 | presidiendo | 1 |
| 18349 | presidida | 1 |
| 18350 | presidiarios | 1 |
| 18351 | presidiario | 1 |
| 18352 | presidencial | 1 |
| 18353 | presidencia | 1 |
| 18354 | preservativo | 1 |
| 18355 | presentido | 1 |
| 18356 | preséntate | 1 |
| 18357 | presentársele | 1 |
| 18358 | presentáronse | 1 |
| 18359 | presentarles | 1 |
| 18360 | presentándose | 1 |
| 18361 | presentándole | 1 |
| 18362 | presentándola | 1 |
| 18363 | presentados | 1 |
| 18364 | presentación | 1 |
| 18365 | presenció | 1 |
| 18366 | presencié | 1 |
| 18367 | presenciaron | 1 |
| 18368 | presenciara | 1 |
| 18369 | presencian | 1 |
| 18370 | prescrito | 1 |
| 18371 | prescindir | 1 |
| 18372 | presbíteros | 1 |
| 18373 | presbiterio | 1 |
| 18374 | presagiar | 1 |
| 18375 | preparo | 1 |
| 18376 | preparen | 1 |
| 18377 | preparé | 1 |
| 18378 | preparatorias | 1 |
| 18379 | preparase | 1 |
| 18380 | prepararon | 1 |
| 18381 | prepararla | 1 |
| 18382 | prepararemos | 1 |
| 18383 | preparándose | 1 |
| 18384 | preparándole | 1 |
| 18385 | preparábase | 1 |
| 18386 | preparaban | 1 |
| 18387 | preocuparse | 1 |
| 18388 | preocupado | 1 |
| 18389 | preocupación | 1 |
| 18390 | prendió | 1 |
| 18391 | prendiendo | 1 |
| 18392 | prendidas | 1 |
| 18393 | prender | 1 |
| 18394 | prendarse | 1 |
| 18395 | prendara | 1 |
| 18396 | prendaba | 1 |
| 18397 | premiten | 1 |
| 18398 | premite | 1 |
| 18399 | premiso | 1 |
| 18400 | premiados | 1 |
| 18401 | prematuro | 1 |
| 18402 | preliminares | 1 |
| 18403 | prejuicios | 1 |
| 18404 | preguntonas | 1 |
| 18405 | preguntome | 1 |
| 18406 | preguntitas | 1 |
| 18407 | pregúnteselo | 1 |
| 18408 | pregúntenle | 1 |
| 18409 | pregunten | 1 |
| 18410 | preguntárselo | 1 |
| 18411 | preguntársela | 1 |
| 18412 | preguntaron | 1 |
| 18413 | preguntarme | 1 |
| 18414 | preguntarlo | 1 |
| 18415 | preguntaría | 1 |
| 18416 | preguntará | 1 |
| 18417 | preguntándose | 1 |
| 18418 | preguntábamos | 1 |
| 18419 | pregone | 1 |
| 18420 | pregonaba | 1 |
| 18421 | prefiere | 1 |
| 18422 | prefieras | 1 |
| 18423 | preferiremos | 1 |
| 18424 | preferir | 1 |
| 18425 | preferible | 1 |
| 18426 | predisposición | 1 |
| 18427 | predilecta | 1 |
| 18428 | predicó | 1 |
| 18429 | predico | 1 |
| 18430 | predicara | 1 |
| 18431 | predicador | 1 |
| 18432 | predicaba | 1 |
| 18433 | predestinados | 1 |
| 18434 | predecesores | 1 |
| 18435 | predecesoras | 1 |
| 18436 | precursoras | 1 |
| 18437 | precozmente | 1 |
| 18438 | precocidad | 1 |
| 18439 | precisos | 1 |
| 18440 | precisión | 1 |
| 18441 | precisar | 1 |
| 18442 | precipites | 1 |
| 18443 | precipitada | 1 |
| 18444 | precipitaba | 1 |
| 18445 | precipicio | 1 |
| 18446 | preciosísimos | 1 |
| 18447 | preciosas | 1 |
| 18448 | preciábase | 1 |
| 18449 | precepto | 1 |
| 18450 | preceder | 1 |
| 18451 | precedente | 1 |
| 18452 | precede | 1 |
| 18453 | práxedes | 1 |
| 18454 | pragmáticas | 1 |
| 18455 | pragmática | 1 |
| 18456 | pradoluengo | 1 |
| 18457 | praderas | 1 |
| 18458 | practico | 1 |
| 18459 | practicarla | 1 |
| 18460 | practicantes | 1 |
| 18461 | practicando | 1 |
| 18462 | practicado | 1 |
| 18463 | practicadas | 1 |
| 18464 | practicable | 1 |
| 18465 | practica | 1 |
| 18466 | potingues | 1 |
| 18467 | potingue | 1 |
| 18468 | potestad | 1 |
| 18469 | potes | 1 |
| 18470 | potente | 1 |
| 18471 | potentadas | 1 |
| 18472 | potentada | 1 |
| 18473 | potasio | 1 |
| 18474 | póstuma | 1 |
| 18475 | postrimerías | 1 |
| 18476 | postrado | 1 |
| 18477 | postizas | 1 |
| 18478 | poste | 1 |
| 18479 | postal | 1 |
| 18480 | posta | 1 |
| 18481 | positivo | 1 |
| 18482 | positivas | 1 |
| 18483 | positivamente | 1 |
| 18484 | posiciones | 1 |
| 18485 | posesionarían | 1 |
| 18486 | poseo | 1 |
| 18487 | poseído | 1 |
| 18488 | poseída | 1 |
| 18489 | poseerte | 1 |
| 18490 | poseerlo | 1 |
| 18491 | poseedora | 1 |
| 18492 | posea | 1 |
| 18493 | posarle | 1 |
| 18494 | posadas | 1 |
| 18495 | portugal | 1 |
| 18496 | portentos | 1 |
| 18497 | portear | 1 |
| 18498 | porte | 1 |
| 18499 | portazos | 1 |
| 18500 | portazo | 1 |
| 18501 | portas | 1 |
| 18502 | portarte | 1 |
| 18503 | portarnos | 1 |
| 18504 | portan | 1 |
| 18505 | portamos | 1 |
| 18506 | portabas | 1 |
| 18507 | porra | 1 |
| 18508 | pormenor | 1 |
| 18509 | porfiado | 1 |
| 18510 | porfiaba | 1 |
| 18511 | pordiosero | 1 |
| 18512 | pordioseaba | 1 |
| 18513 | porcelanescas | 1 |
| 18514 | poquitos | 1 |
| 18515 | poquita | 1 |
| 18516 | poquísimos | 1 |
| 18517 | poquísimas | 1 |
| 18518 | popularidad | 1 |
| 18519 | ponzoñoso | 1 |
| 18520 | pontevedra | 1 |
| 18521 | ponle | 1 |
| 18522 | poniéndoselos | 1 |
| 18523 | poniéndola | 1 |
| 18524 | poníasele | 1 |
| 18525 | ponías | 1 |
| 18526 | poníala | 1 |
| 18527 | pongámosle | 1 |
| 18528 | pongámonos | 1 |
| 18529 | póngalo | 1 |
| 18530 | ponérteme | 1 |
| 18531 | ponérsela | 1 |
| 18532 | ponérmela | 1 |
| 18533 | ponerles | 1 |
| 18534 | ponéis | 1 |
| 18535 | ponedla | 1 |
| 18536 | pondrías | 1 |
| 18537 | pondrían | 1 |
| 18538 | pondríamos | 1 |
| 18539 | ponderarle | 1 |
| 18540 | ponderando | 1 |
| 18541 | ponderaciones | 1 |
| 18542 | ponderaban | 1 |
| 18543 | ponderaba | 1 |
| 18544 | poncio | 1 |
| 18545 | ponchera | 1 |
| 18546 | pómulos | 1 |
| 18547 | pompones | 1 |
| 18548 | pómez | 1 |
| 18549 | pomada | 1 |
| 18550 | polvorosos | 1 |
| 18551 | polvorosa | 1 |
| 18552 | polvorienta | 1 |
| 18553 | polvillo | 1 |
| 18554 | polluela | 1 |
| 18555 | pollita | 1 |
| 18556 | pollino | 1 |
| 18557 | polleros | 1 |
| 18558 | pollerías | 1 |
| 18559 | pollera | 1 |
| 18560 | polka | 1 |
| 18561 | polizonte | 1 |
| 18562 | politicastros | 1 |
| 18563 | polinesia | 1 |
| 18564 | policiacos | 1 |
| 18565 | policíaca | 1 |
| 18566 | polichinela | 1 |
| 18567 | polemista | 1 |
| 18568 | polémicas | 1 |
| 18569 | poético | 1 |
| 18570 | poesías | 1 |
| 18571 | poemas | 1 |
| 18572 | podrido | 1 |
| 18573 | podridas | 1 |
| 18574 | podredumbre | 1 |
| 18575 | podíamos | 1 |
| 18576 | poderse | 1 |
| 18577 | poderme | 1 |
| 18578 | poderle | 1 |
| 18579 | podamos | 1 |
| 18580 | poción | 1 |
| 18581 | pócima | 1 |
| 18582 | pocillo | 1 |
| 18583 | pocilga | 1 |
| 18584 | pobrísima | 1 |
| 18585 | pobrete | 1 |
| 18586 | pobrecitas | 1 |
| 18587 | pobrecillas | 1 |
| 18588 | poblaciones | 1 |
| 18589 | poblaban | 1 |
| 18590 | plumonía | 1 |
| 18591 | plumear | 1 |
| 18592 | plumacho | 1 |
| 18593 | plomizas | 1 |
| 18594 | plim | 1 |
| 18595 | pliegue | 1 |
| 18596 | pliego | 1 |
| 18597 | pléyade | 1 |
| 18598 | pleticó | 1 |
| 18599 | pleticar | 1 |
| 18600 | plenipotenciario | 1 |
| 18601 | pleitos | 1 |
| 18602 | pléiticas | 1 |
| 18603 | pleitazo | 1 |
| 18604 | platónicas | 1 |
| 18605 | platónica | 1 |
| 18606 | platicando | 1 |
| 18607 | platica | 1 |
| 18608 | platero | 1 |
| 18609 | platería | 1 |
| 18610 | plateado | 1 |
| 18611 | plateadas | 1 |
| 18612 | plateada | 1 |
| 18613 | plataformas | 1 |
| 18614 | plasta | 1 |
| 18615 | plañidera | 1 |
| 18616 | plantilla | 1 |
| 18617 | plantifiquen | 1 |
| 18618 | planteo | 1 |
| 18619 | plantear | 1 |
| 18620 | planteándole | 1 |
| 18621 | planteado | 1 |
| 18622 | planteaba | 1 |
| 18623 | plantea | 1 |
| 18624 | plantársele | 1 |
| 18625 | plantaron | 1 |
| 18626 | plantarme | 1 |
| 18627 | plantaremos | 1 |
| 18628 | plantándose | 1 |
| 18629 | plantada | 1 |
| 18630 | plantaba | 1 |
| 18631 | planos | 1 |
| 18632 | planicie | 1 |
| 18633 | planeta | 1 |
| 18634 | planche | 1 |
| 18635 | planchas | 1 |
| 18636 | planchándole | 1 |
| 18637 | planchado | 1 |
| 18638 | planchaba | 1 |
| 18639 | plaga | 1 |
| 18640 | placita | 1 |
| 18641 | placidito | 1 |
| 18642 | placeros | 1 |
| 18643 | placenteros | 1 |
| 18644 | placentero | 1 |
| 18645 | place | 1 |
| 18646 | placa | 1 |
| 18647 | pizarras | 1 |
| 18648 | pizarra | 1 |
| 18649 | pitusiana | 1 |
| 18650 | pituitaria | 1 |
| 18651 | pitos | 1 |
| 18652 | pitón | 1 |
| 18653 | pitoja | 1 |
| 18654 | pitofufito | 1 |
| 18655 | pitita | 1 |
| 18656 | pítima | 1 |
| 18657 | pitillo | 1 |
| 18658 | pitidos | 1 |
| 18659 | pitarás | 1 |
| 18660 | pitanza | 1 |
| 18661 | pitágoras | 1 |
| 18662 | pita | 1 |
| 18663 | pistos | 1 |
| 18664 | pisotearla | 1 |
| 18665 | pisoteado | 1 |
| 18666 | pisotea | 1 |
| 18667 | piscicultura | 1 |
| 18668 | pisas | 1 |
| 18669 | pisárselas | 1 |
| 18670 | pisándose | 1 |
| 18671 | pisándoles | 1 |
| 18672 | pisaba | 1 |
| 18673 | piruétano | 1 |
| 18674 | pirra | 1 |
| 18675 | pirineo | 1 |
| 18676 | piratería | 1 |
| 18677 | piratas | 1 |
| 18678 | pira | 1 |
| 18679 | piquito | 1 |
| 18680 | piques | 1 |
| 18681 | pique | 1 |
| 18682 | pior | 1 |
| 18683 | piojosa | 1 |
| 18684 | piñones | 1 |
| 18685 | pintorescos | 1 |
| 18686 | pintiparada | 1 |
| 18687 | pintarlas | 1 |
| 18688 | pintándose | 1 |
| 18689 | pintaban | 1 |
| 18690 | pinta | 1 |
| 18691 | pinos | 1 |
| 18692 | pinitos | 1 |
| 18693 | pingües | 1 |
| 18694 | pingajo | 1 |
| 18695 | pindonga | 1 |
| 18696 | pinchase | 1 |
| 18697 | pinchamos | 1 |
| 18698 | pinchacitos | 1 |
| 18699 | pinceles | 1 |
| 18700 | pincelada | 1 |
| 18701 | pincel | 1 |
| 18702 | pinares | 1 |
| 18703 | pináculo | 1 |
| 18704 | pin | 1 |
| 18705 | pimpollos | 1 |
| 18706 | pimientos | 1 |
| 18707 | piltrafas | 1 |
| 18708 | piltrafa | 1 |
| 18709 | pilosa | 1 |
| 18710 | pilluelos | 1 |
| 18711 | pillines | 1 |
| 18712 | pillincito | 1 |
| 18713 | pillinadas | 1 |
| 18714 | pille | 1 |
| 18715 | pillastres | 1 |
| 18716 | pilatos | 1 |
| 18717 | pilastrones | 1 |
| 18718 | pila | 1 |
| 18719 | pignoró | 1 |
| 18720 | pignorado | 1 |
| 18721 | pifias | 1 |
| 18722 | pifia | 1 |
| 18723 | piernazas | 1 |
| 18724 | pierdas | 1 |
| 18725 | pierdan | 1 |
| 18726 | piensen | 1 |
| 18727 | piensasté | 1 |
| 18728 | piedrecita | 1 |
| 18729 | piececitas | 1 |
| 18730 | pidiéronle | 1 |
| 18731 | pidieron | 1 |
| 18732 | pidieras | 1 |
| 18733 | pidieran | 1 |
| 18734 | pidiéndole | 1 |
| 18735 | pídeselo | 1 |
| 18736 | pídele | 1 |
| 18737 | pidas | 1 |
| 18738 | pidan | 1 |
| 18739 | pidámosle | 1 |
| 18740 | picorcillo | 1 |
| 18741 | picó | 1 |
| 18742 | pichoncitos | 1 |
| 18743 | pichona | 1 |
| 18744 | picazón | 1 |
| 18745 | picas | 1 |
| 18746 | pícaros | 1 |
| 18747 | picaronaza | 1 |
| 18748 | picará | 1 |
| 18749 | picaporte | 1 |
| 18750 | picapedreros | 1 |
| 18751 | pican | 1 |
| 18752 | picadura | 1 |
| 18753 | picadilly | 1 |
| 18754 | picadillo | 1 |
| 18755 | piazo | 1 |
| 18756 | pianino | 1 |
| 18757 | pianillo | 1 |
| 18758 | pian | 1 |
| 18759 | piadosos | 1 |
| 18760 | piache | 1 |
| 18761 | pía | 1 |
| 18762 | petrificada | 1 |
| 18763 | petrarca | 1 |
| 18764 | petitorio | 1 |
| 18765 | petimetres | 1 |
| 18766 | petaba | 1 |
| 18767 | pestilencia | 1 |
| 18768 | pestífera | 1 |
| 18769 | pesquisas | 1 |
| 18770 | pespuntar | 1 |
| 18771 | pesimista | 1 |
| 18772 | pésemelo | 1 |
| 18773 | pesebre | 1 |
| 18774 | pescuezos | 1 |
| 18775 | pesco | 1 |
| 18776 | pescadilla | 1 |
| 18777 | pescaban | 1 |
| 18778 | pescaba | 1 |
| 18779 | pesase | 1 |
| 18780 | pesadumbres | 1 |
| 18781 | pesadita | 1 |
| 18782 | pesadísima | 1 |
| 18783 | pesaban | 1 |
| 18784 | pervertírsele | 1 |
| 18785 | pervertir | 1 |
| 18786 | pervertimos | 1 |
| 18787 | perversas | 1 |
| 18788 | perturbe | 1 |
| 18789 | perturbase | 1 |
| 18790 | perturbar | 1 |
| 18791 | perturbado | 1 |
| 18792 | perturbadas | 1 |
| 18793 | perturbaciones | 1 |
| 18794 | perturbaba | 1 |
| 18795 | pertinencia | 1 |
| 18796 | pertenezco | 1 |
| 18797 | pertenecí | 1 |
| 18798 | pertenecer | 1 |
| 18799 | pertenecen | 1 |
| 18800 | persuasivas | 1 |
| 18801 | persuadirle | 1 |
| 18802 | persuadí | 1 |
| 18803 | perspectivas | 1 |
| 18804 | personó | 1 |
| 18805 | personificado | 1 |
| 18806 | personificaba | 1 |
| 18807 | personarse | 1 |
| 18808 | personaron | 1 |
| 18809 | personalizar | 1 |
| 18810 | personalizando | 1 |
| 18811 | personalidá | 1 |
| 18812 | persistió | 1 |
| 18813 | persistieron | 1 |
| 18814 | persistían | 1 |
| 18815 | persistía | 1 |
| 18816 | persistentes | 1 |
| 18817 | persiste | 1 |
| 18818 | persiguió | 1 |
| 18819 | persiguiéndole | 1 |
| 18820 | persiguen | 1 |
| 18821 | persignó | 1 |
| 18822 | persiga | 1 |
| 18823 | perseverando | 1 |
| 18824 | persépolis | 1 |
| 18825 | perseguirte | 1 |
| 18826 | perseguidora | 1 |
| 18827 | perseguían | 1 |
| 18828 | persecutorio | 1 |
| 18829 | perruna | 1 |
| 18830 | perrería | 1 |
| 18831 | perrazo | 1 |
| 18832 | perras | 1 |
| 18833 | perpleja | 1 |
| 18834 | perpiñá | 1 |
| 18835 | perpetuo | 1 |
| 18836 | perpetuidad | 1 |
| 18837 | perpetuase | 1 |
| 18838 | perpetuarse | 1 |
| 18839 | pernoctar | 1 |
| 18840 | perniquiebres | 1 |
| 18841 | pernetas | 1 |
| 18842 | permuta | 1 |
| 18843 | permitírselo | 1 |
| 18844 | permitirme | 1 |
| 18845 | permitirlos | 1 |
| 18846 | permitirles | 1 |
| 18847 | permitiría | 1 |
| 18848 | permitirá | 1 |
| 18849 | permitiole | 1 |
| 18850 | permitieran | 1 |
| 18851 | permitiéndole | 1 |
| 18852 | permitiendo | 1 |
| 18853 | permitíale | 1 |
| 18854 | permiten | 1 |
| 18855 | permitas | 1 |
| 18856 | permanentes | 1 |
| 18857 | permanecieron | 1 |
| 18858 | permanecían | 1 |
| 18859 | perlas | 1 |
| 18860 | perjudicial | 1 |
| 18861 | periquito | 1 |
| 18862 | periquillo | 1 |
| 18863 | período | 1 |
| 18864 | periodistas | 1 |
| 18865 | periodiqueros | 1 |
| 18866 | periódicas | 1 |
| 18867 | periódica | 1 |
| 18868 | perifollo | 1 |
| 18869 | periespíritu | 1 |
| 18870 | pericos | 1 |
| 18871 | pericial | 1 |
| 18872 | pergeñada | 1 |
| 18873 | pergenio | 1 |
| 18874 | pergaminos | 1 |
| 18875 | perfumes | 1 |
| 18876 | perfumadas | 1 |
| 18877 | perfilados | 1 |
| 18878 | perfeccionado | 1 |
| 18879 | perfec | 1 |
| 18880 | perezosas | 1 |
| 18881 | perezca | 1 |
| 18882 | pérez | 1 |
| 18883 | perenne | 1 |
| 18884 | perendengues | 1 |
| 18885 | perejil | 1 |
| 18886 | peregrinas | 1 |
| 18887 | peregrina | 1 |
| 18888 | pereciendo | 1 |
| 18889 | perecemos | 1 |
| 18890 | perece | 1 |
| 18891 | perdonó | 1 |
| 18892 | perdoné | 1 |
| 18893 | perdonas | 1 |
| 18894 | perdonarte | 1 |
| 18895 | perdonárselos | 1 |
| 18896 | perdonarnos | 1 |
| 18897 | perdonaré | 1 |
| 18898 | perdonara | 1 |
| 18899 | perdonándosela | 1 |
| 18900 | perdonan | 1 |
| 18901 | perdonamos | 1 |
| 18902 | perdonadas | 1 |
| 18903 | perdiose | 1 |
| 18904 | perdío | 1 |
| 18905 | perdiese | 1 |
| 18906 | perdieron | 1 |
| 18907 | perdiera | 1 |
| 18908 | perdidas | 1 |
| 18909 | perdidamente | 1 |
| 18910 | pérdida | 1 |
| 18911 | perdices | 1 |
| 18912 | perderte | 1 |
| 18913 | perderse | 1 |
| 18914 | perderme | 1 |
| 18915 | perderles | 1 |
| 18916 | perderla | 1 |
| 18917 | perdería | 1 |
| 18918 | perderé | 1 |
| 18919 | perdemos | 1 |
| 18920 | percusión | 1 |
| 18921 | percloruro | 1 |
| 18922 | percibir | 1 |
| 18923 | percibida | 1 |
| 18924 | percheros | 1 |
| 18925 | perchero | 1 |
| 18926 | perchel | 1 |
| 18927 | peques | 1 |
| 18928 | pequeñuelas | 1 |
| 18929 | pequeñitas | 1 |
| 18930 | pequeñita | 1 |
| 18931 | pequemos | 1 |
| 18932 | peque | 1 |
| 18933 | peptona | 1 |
| 18934 | pepita | 1 |
| 18935 | peñuelas | 1 |
| 18936 | peñascales | 1 |
| 18937 | peñas | 1 |
| 18938 | pentagrama | 1 |
| 18939 | pensiono | 1 |
| 18940 | pensaste | 1 |
| 18941 | pensasen | 1 |
| 18942 | pensase | 1 |
| 18943 | pensarse | 1 |
| 18944 | pensaré | 1 |
| 18945 | pensarás | 1 |
| 18946 | pensarán | 1 |
| 18947 | pensad | 1 |
| 18948 | pensabas | 1 |
| 18949 | penosísimos | 1 |
| 18950 | penosas | 1 |
| 18951 | penosamente | 1 |
| 18952 | penitas | 1 |
| 18953 | penetres | 1 |
| 18954 | penetré | 1 |
| 18955 | penetrase | 1 |
| 18956 | penetrarse | 1 |
| 18957 | penetraras | 1 |
| 18958 | penetrándose | 1 |
| 18959 | penetrada | 1 |
| 18960 | penetración | 1 |
| 18961 | penetraban | 1 |
| 18962 | pene | 1 |
| 18963 | péndulo | 1 |
| 18964 | pendoncillo | 1 |
| 18965 | pendolista | 1 |
| 18966 | pendían | 1 |
| 18967 | pendencia | 1 |
| 18968 | pencas | 1 |
| 18969 | penates | 1 |
| 18970 | penar | 1 |
| 18971 | penalidad | 1 |
| 18972 | penal | 1 |
| 18973 | penado | 1 |
| 18974 | pelusa | 1 |
| 18975 | peluda | 1 |
| 18976 | peluche | 1 |
| 18977 | pelotones | 1 |
| 18978 | pelotilla | 1 |
| 18979 | pelotada | 1 |
| 18980 | pelmazo | 1 |
| 18981 | pellizcándole | 1 |
| 18982 | pellizcando | 1 |
| 18983 | pellizcaban | 1 |
| 18984 | pelliza | 1 |
| 18985 | pellejos | 1 |
| 18986 | pelleja | 1 |
| 18987 | pelinegra | 1 |
| 18988 | peligrosos | 1 |
| 18989 | peligrosas | 1 |
| 18990 | peligrosa | 1 |
| 18991 | peleando | 1 |
| 18992 | pelando | 1 |
| 18993 | pelaje | 1 |
| 18994 | pelafustán | 1 |
| 18995 | peladilla | 1 |
| 18996 | peinose | 1 |
| 18997 | peinó | 1 |
| 18998 | peinarte | 1 |
| 18999 | peinando | 1 |
| 19000 | peinados | 1 |
| 19001 | peina | 1 |
| 19002 | pégueme | 1 |
| 19003 | pegue | 1 |
| 19004 | pegote | 1 |
| 19005 | pegasteis | 1 |
| 19006 | pegase | 1 |
| 19007 | pegárselo | 1 |
| 19008 | pegársela | 1 |
| 19009 | pegármela | 1 |
| 19010 | pegaré | 1 |
| 19011 | pegaras | 1 |
| 19012 | pegándomela | 1 |
| 19013 | pégame | 1 |
| 19014 | pegajosa | 1 |
| 19015 | pedrisco | 1 |
| 19016 | pedrada | 1 |
| 19017 | pedís | 1 |
| 19018 | pediré | 1 |
| 19019 | pedirás | 1 |
| 19020 | pedigüeñas | 1 |
| 19021 | pedías | 1 |
| 19022 | pedernales | 1 |
| 19023 | pedal | 1 |
| 19024 | pedacito | 1 |
| 19025 | pecosa | 1 |
| 19026 | pecó | 1 |
| 19027 | pechugón | 1 |
| 19028 | pechona | 1 |
| 19029 | pececillos | 1 |
| 19030 | pecase | 1 |
| 19031 | pecara | 1 |
| 19032 | pecando | 1 |
| 19033 | pecaminosos | 1 |
| 19034 | pecadores | 1 |
| 19035 | pecaban | 1 |
| 19036 | pecaba | 1 |
| 19037 | pe | 1 |
| 19038 | payasa | 1 |
| 19039 | pavonadas | 1 |
| 19040 | pavisosa | 1 |
| 19041 | pavimento | 1 |
| 19042 | pausas | 1 |
| 19043 | pausada | 1 |
| 19044 | paúl | 1 |
| 19045 | patulea | 1 |
| 19046 | patrón | 1 |
| 19047 | patrióticos | 1 |
| 19048 | patrióticas | 1 |
| 19049 | patrimonial | 1 |
| 19050 | patriarcalismo | 1 |
| 19051 | patriarca | 1 |
| 19052 | patrañas | 1 |
| 19053 | patoso | 1 |
| 19054 | patológicos | 1 |
| 19055 | patológico | 1 |
| 19056 | pato | 1 |
| 19057 | patito | 1 |
| 19058 | patinar | 1 |
| 19059 | patinadores | 1 |
| 19060 | patinación | 1 |
| 19061 | pátina | 1 |
| 19062 | pateta | 1 |
| 19063 | paterno | 1 |
| 19064 | paternidad | 1 |
| 19065 | paternalmente | 1 |
| 19066 | patencures | 1 |
| 19067 | patena | 1 |
| 19068 | patee | 1 |
| 19069 | pateándole | 1 |
| 19070 | patatitas | 1 |
| 19071 | pataplum | 1 |
| 19072 | pataleo | 1 |
| 19073 | patalea | 1 |
| 19074 | patadillas | 1 |
| 19075 | pastoreaba | 1 |
| 19076 | pastorales | 1 |
| 19077 | pastoral | 1 |
| 19078 | pastelón | 1 |
| 19079 | pastel | 1 |
| 19080 | passer | 1 |
| 19081 | pasola | 1 |
| 19082 | pasmoso | 1 |
| 19083 | pasmose | 1 |
| 19084 | pasmosa | 1 |
| 19085 | pásmese | 1 |
| 19086 | pasmarte | 1 |
| 19087 | pasmarotes | 1 |
| 19088 | pasmarías | 1 |
| 19089 | pasmaré | 1 |
| 19090 | pasmaran | 1 |
| 19091 | pasman | 1 |
| 19092 | pasmados | 1 |
| 19093 | pasmábase | 1 |
| 19094 | pasma | 1 |
| 19095 | pasivo | 1 |
| 19096 | pasividad | 1 |
| 19097 | pasivas | 1 |
| 19098 | pasiva | 1 |
| 19099 | pasitos | 1 |
| 19100 | pasita | 1 |
| 19101 | pasiega | 1 |
| 19102 | paseítos | 1 |
| 19103 | paséese | 1 |
| 19104 | paséate | 1 |
| 19105 | pasearnos | 1 |
| 19106 | paseante | 1 |
| 19107 | paseado | 1 |
| 19108 | paseábanse | 1 |
| 19109 | pasáronle | 1 |
| 19110 | pasarme | 1 |
| 19111 | pasaríamos | 1 |
| 19112 | pasaremos | 1 |
| 19113 | pasaras | 1 |
| 19114 | pasaran | 1 |
| 19115 | pasaporte | 1 |
| 19116 | pasamanería | 1 |
| 19117 | pasajero | 1 |
| 19118 | pasajeras | 1 |
| 19119 | pasadita | 1 |
| 19120 | pasábanse | 1 |
| 19121 | párvulos | 1 |
| 19122 | partirse | 1 |
| 19123 | partirle | 1 |
| 19124 | partiese | 1 |
| 19125 | partieran | 1 |
| 19126 | partiéndole | 1 |
| 19127 | partidita | 1 |
| 19128 | partícipes | 1 |
| 19129 | partícipe | 1 |
| 19130 | participaste | 1 |
| 19131 | participaciones | 1 |
| 19132 | participaban | 1 |
| 19133 | parten | 1 |
| 19134 | partan | 1 |
| 19135 | parroquias | 1 |
| 19136 | parriba | 1 |
| 19137 | parrales | 1 |
| 19138 | parral | 1 |
| 19139 | parra | 1 |
| 19140 | parlanchín | 1 |
| 19141 | parlamentarismo | 1 |
| 19142 | parlamentarios | 1 |
| 19143 | parlamentario | 1 |
| 19144 | parlamentaria | 1 |
| 19145 | parlamentando | 1 |
| 19146 | park | 1 |
| 19147 | parisienses | 1 |
| 19148 | parir | 1 |
| 19149 | pariera | 1 |
| 19150 | parienta | 1 |
| 19151 | pariendo | 1 |
| 19152 | paridas | 1 |
| 19153 | parida | 1 |
| 19154 | parias | 1 |
| 19155 | parían | 1 |
| 19156 | paría | 1 |
| 19157 | parezcas | 1 |
| 19158 | pareciome | 1 |
| 19159 | pareciesen | 1 |
| 19160 | pareciéronle | 1 |
| 19161 | pareciéralo | 1 |
| 19162 | pareciéndole | 1 |
| 19163 | parecidos | 1 |
| 19164 | parecíanle | 1 |
| 19165 | parecérsele | 1 |
| 19166 | parecerían | 1 |
| 19167 | pareceres | 1 |
| 19168 | parecerá | 1 |
| 19169 | pare | 1 |
| 19170 | pardillo | 1 |
| 19171 | pardessus | 1 |
| 19172 | parche | 1 |
| 19173 | parca | 1 |
| 19174 | párate | 1 |
| 19175 | parásito | 1 |
| 19176 | parasitario | 1 |
| 19177 | paráronse | 1 |
| 19178 | pararía | 1 |
| 19179 | parará | 1 |
| 19180 | parara | 1 |
| 19181 | paramento | 1 |
| 19182 | paralizado | 1 |
| 19183 | paralizadas | 1 |
| 19184 | paralítico | 1 |
| 19185 | paralítica | 1 |
| 19186 | parálisis | 1 |
| 19187 | paralelamente | 1 |
| 19188 | paraguazo | 1 |
| 19189 | paradójica | 1 |
| 19190 | parábolas | 1 |
| 19191 | parábola | 1 |
| 19192 | parábase | 1 |
| 19193 | paquito | 1 |
| 19194 | paquita | 1 |
| 19195 | paquetitos | 1 |
| 19196 | papos | 1 |
| 19197 | pápiros | 1 |
| 19198 | papelitos | 1 |
| 19199 | papelistas | 1 |
| 19200 | papelillo | 1 |
| 19201 | papeletitas | 1 |
| 19202 | papelejos | 1 |
| 19203 | papelejo | 1 |
| 19204 | papé | 1 |
| 19205 | papal | 1 |
| 19206 | papaíto | 1 |
| 19207 | papagayo | 1 |
| 19208 | pañero | 1 |
| 19209 | panzudo | 1 |
| 19210 | pantuflas | 1 |
| 19211 | panteístas | 1 |
| 19212 | pantaloncitos | 1 |
| 19213 | pantallas | 1 |
| 19214 | pantaleón | 1 |
| 19215 | panoli | 1 |
| 19216 | panificación | 1 |
| 19217 | pánfila | 1 |
| 19218 | panegírico | 1 |
| 19219 | pandillas | 1 |
| 19220 | pancorvo | 1 |
| 19221 | panadero | 1 |
| 19222 | panaceas | 1 |
| 19223 | pámpano | 1 |
| 19224 | paludismo | 1 |
| 19225 | palpó | 1 |
| 19226 | palpitar | 1 |
| 19227 | palpitante | 1 |
| 19228 | palpitando | 1 |
| 19229 | palpe | 1 |
| 19230 | palpar | 1 |
| 19231 | palpando | 1 |
| 19232 | palpables | 1 |
| 19233 | palpaban | 1 |
| 19234 | palpaba | 1 |
| 19235 | palotes | 1 |
| 19236 | palote | 1 |
| 19237 | palosanto | 1 |
| 19238 | palomar | 1 |
| 19239 | palmoteándole | 1 |
| 19240 | palmos | 1 |
| 19241 | palmeras | 1 |
| 19242 | palmas | 1 |
| 19243 | palmarios | 1 |
| 19244 | palmaria | 1 |
| 19245 | palmadita | 1 |
| 19246 | palito | 1 |
| 19247 | palideció | 1 |
| 19248 | palidecía | 1 |
| 19249 | palideces | 1 |
| 19250 | palidecer | 1 |
| 19251 | paliativos | 1 |
| 19252 | paleto | 1 |
| 19253 | paletilla | 1 |
| 19254 | palcos | 1 |
| 19255 | palatino | 1 |
| 19256 | palastro | 1 |
| 19257 | palas | 1 |
| 19258 | palante | 1 |
| 19259 | paladares | 1 |
| 19260 | palación | 1 |
| 19261 | palabrotas | 1 |
| 19262 | palabrillas | 1 |
| 19263 | palabrilla | 1 |
| 19264 | palabrero | 1 |
| 19265 | palabreja | 1 |
| 19266 | pala | 1 |
| 19267 | pal | 1 |
| 19268 | pajita | 1 |
| 19269 | pajes | 1 |
| 19270 | pajarraco | 1 |
| 19271 | pajaritos | 1 |
| 19272 | pajarera | 1 |
| 19273 | paisajista | 1 |
| 19274 | paicían | 1 |
| 19275 | paicerse | 1 |
| 19276 | paicen | 1 |
| 19277 | paguen | 1 |
| 19278 | pagué | 1 |
| 19279 | paginitas | 1 |
| 19280 | pagarme | 1 |
| 19281 | pagarlo | 1 |
| 19282 | pagarán | 1 |
| 19283 | pagara | 1 |
| 19284 | pagano | 1 |
| 19285 | paganismo | 1 |
| 19286 | pagándole | 1 |
| 19287 | pagando | 1 |
| 19288 | pagaban | 1 |
| 19289 | paella | 1 |
| 19290 | padrenuestros | 1 |
| 19291 | padrenuestro | 1 |
| 19292 | padezcamos | 1 |
| 19293 | padezca | 1 |
| 19294 | padecimientos | 1 |
| 19295 | padecían | 1 |
| 19296 | padecí | 1 |
| 19297 | padecerías | 1 |
| 19298 | padecería | 1 |
| 19299 | padecen | 1 |
| 19300 | pactos | 1 |
| 19301 | pacos | 1 |
| 19302 | pacificar | 1 |
| 19303 | pacíficamente | 1 |
| 19304 | pacificadoras | 1 |
| 19305 | pábilo | 1 |
| 19306 | pabellones | 1 |
| 19307 | p | 1 |
| 19308 | oyoles | 1 |
| 19309 | oyola | 1 |
| 19310 | oyeras | 1 |
| 19311 | óyense | 1 |
| 19312 | oyéndose | 1 |
| 19313 | oyéndolo | 1 |
| 19314 | óyeme | 1 |
| 19315 | óvalo | 1 |
| 19316 | otorgase | 1 |
| 19317 | otorgarle | 1 |
| 19318 | otorgándose | 1 |
| 19319 | otorgado | 1 |
| 19320 | otero | 1 |
| 19321 | otelo | 1 |
| 19322 | ostra | 1 |
| 19323 | ostentando | 1 |
| 19324 | ostentan | 1 |
| 19325 | ostentaban | 1 |
| 19326 | osos | 1 |
| 19327 | oso | 1 |
| 19328 | oscurecen | 1 |
| 19329 | oscilando | 1 |
| 19330 | oscilaba | 1 |
| 19331 | osaría | 1 |
| 19332 | osara | 1 |
| 19333 | osar | 1 |
| 19334 | osados | 1 |
| 19335 | orza | 1 |
| 19336 | ortógrafo | 1 |
| 19337 | oropel | 1 |
| 19338 | ornitológicas | 1 |
| 19339 | ornato | 1 |
| 19340 | orla | 1 |
| 19341 | oriundos | 1 |
| 19342 | orinó | 1 |
| 19343 | orillas | 1 |
| 19344 | orihuela | 1 |
| 19345 | originalísimo | 1 |
| 19346 | originales | 1 |
| 19347 | orientándose | 1 |
| 19348 | orientales | 1 |
| 19349 | oriental | 1 |
| 19350 | orgullosos | 1 |
| 19351 | orgullosamente | 1 |
| 19352 | orgía | 1 |
| 19353 | organizó | 1 |
| 19354 | organizarse | 1 |
| 19355 | organizador | 1 |
| 19356 | organizadas | 1 |
| 19357 | organizada | 1 |
| 19358 | organillo | 1 |
| 19359 | orfandad | 1 |
| 19360 | orejitas | 1 |
| 19361 | orejita | 1 |
| 19362 | orearan | 1 |
| 19363 | orea | 1 |
| 19364 | ordinariotes | 1 |
| 19365 | ordinariota | 1 |
| 19366 | ordinarieces | 1 |
| 19367 | ordenarse | 1 |
| 19368 | ordenanza | 1 |
| 19369 | ordenados | 1 |
| 19370 | ordenador | 1 |
| 19371 | ordenadas | 1 |
| 19372 | ordenación | 1 |
| 19373 | ordenaban | 1 |
| 19374 | orbe | 1 |
| 19375 | oratorios | 1 |
| 19376 | oratoria | 1 |
| 19377 | orates | 1 |
| 19378 | orangutanes | 1 |
| 19379 | oradores | 1 |
| 19380 | oráculo | 1 |
| 19381 | oraba | 1 |
| 19382 | opusiéronse | 1 |
| 19383 | opulento | 1 |
| 19384 | opulencia | 1 |
| 19385 | opuestos | 1 |
| 19386 | opuestas | 1 |
| 19387 | opuesta | 1 |
| 19388 | optimismos | 1 |
| 19389 | opta | 1 |
| 19390 | oprimidos | 1 |
| 19391 | oprimidas | 1 |
| 19392 | oprimían | 1 |
| 19393 | opresiones | 1 |
| 19394 | oportunos | 1 |
| 19395 | oportunista | 1 |
| 19396 | oponiendo | 1 |
| 19397 | oponía | 1 |
| 19398 | opongo | 1 |
| 19399 | opóngase | 1 |
| 19400 | oponga | 1 |
| 19401 | oponen | 1 |
| 19402 | opio | 1 |
| 19403 | opinado | 1 |
| 19404 | opiáceo | 1 |
| 19405 | ópalo | 1 |
| 19406 | opacos | 1 |
| 19407 | opacidad | 1 |
| 19408 | opaca | 1 |
| 19409 | ooooh | 1 |
| 19410 | onza | 1 |
| 19411 | onofre | 1 |
| 19412 | onduladas | 1 |
| 19413 | ondeando | 1 |
| 19414 | onde | 1 |
| 19415 | omoplato | 1 |
| 19416 | omnipotente | 1 |
| 19417 | omnipotencia | 1 |
| 19418 | omnímodo | 1 |
| 19419 | ómnibus | 1 |
| 19420 | omitida | 1 |
| 19421 | omisiones | 1 |
| 19422 | ombligo | 1 |
| 19423 | olviden | 1 |
| 19424 | olvídate | 1 |
| 19425 | olvidarte | 1 |
| 19426 | olvidárseles | 1 |
| 19427 | olvidaron | 1 |
| 19428 | olvidarla | 1 |
| 19429 | olvidáramos | 1 |
| 19430 | olvidándose | 1 |
| 19431 | olvidados | 1 |
| 19432 | olvidadizos | 1 |
| 19433 | olvidaban | 1 |
| 19434 | olózaga | 1 |
| 19435 | olorosísimas | 1 |
| 19436 | olorosa | 1 |
| 19437 | olores | 1 |
| 19438 | olmos | 1 |
| 19439 | olla | 1 |
| 19440 | oliva | 1 |
| 19441 | olió | 1 |
| 19442 | olimpa | 1 |
| 19443 | olido | 1 |
| 19444 | olfatorias | 1 |
| 19445 | olfateando | 1 |
| 19446 | olfatea | 1 |
| 19447 | óleos | 1 |
| 19448 | oleeé | 1 |
| 19449 | oleadas | 1 |
| 19450 | ojivas | 1 |
| 19451 | ojeriza | 1 |
| 19452 | ojeador | 1 |
| 19453 | ojeadas | 1 |
| 19454 | ojales | 1 |
| 19455 | ojalateros | 1 |
| 19456 | oírnos | 1 |
| 19457 | oírlos | 1 |
| 19458 | oírles | 1 |
| 19459 | oiría | 1 |
| 19460 | oiré | 1 |
| 19461 | oímos | 1 |
| 19462 | oigas | 1 |
| 19463 | oigan | 1 |
| 19464 | oídas | 1 |
| 19465 | oíanle | 1 |
| 19466 | oíamos | 1 |
| 19467 | oíales | 1 |
| 19468 | ofuscaras | 1 |
| 19469 | ofuscándose | 1 |
| 19470 | ofrecimiento | 1 |
| 19471 | ofreciéndoseles | 1 |
| 19472 | ofreciéndose | 1 |
| 19473 | ofreciéndolo | 1 |
| 19474 | ofreciéndoles | 1 |
| 19475 | ofrecíase | 1 |
| 19476 | ofrecían | 1 |
| 19477 | ofrecérselo | 1 |
| 19478 | ofrecerse | 1 |
| 19479 | ofrecerme | 1 |
| 19480 | ofrecerles | 1 |
| 19481 | ofrecerla | 1 |
| 19482 | ofrecerá | 1 |
| 19483 | ofrecen | 1 |
| 19484 | ofrécele | 1 |
| 19485 | oficiosos | 1 |
| 19486 | oficios | 1 |
| 19487 | oficinalis | 1 |
| 19488 | oficialmente | 1 |
| 19489 | oficiales | 1 |
| 19490 | ofícialas | 1 |
| 19491 | ofensor | 1 |
| 19492 | ofensiva | 1 |
| 19493 | ofendió | 1 |
| 19494 | ofendiera | 1 |
| 19495 | ofendiendo | 1 |
| 19496 | ofendía | 1 |
| 19497 | ofenderse | 1 |
| 19498 | odisea | 1 |
| 19499 | odiosos | 1 |
| 19500 | odié | 1 |
| 19501 | ocurrírsele | 1 |
| 19502 | ocurrirle | 1 |
| 19503 | ocurrirían | 1 |
| 19504 | ocurriome | 1 |
| 19505 | ocurriendo | 1 |
| 19506 | ocurridos | 1 |
| 19507 | ocurrente | 1 |
| 19508 | ocurrencias | 1 |
| 19509 | ocurran | 1 |
| 19510 | ocupes | 1 |
| 19511 | ocuparte | 1 |
| 19512 | ocuparían | 1 |
| 19513 | ocuparía | 1 |
| 19514 | ocupándose | 1 |
| 19515 | ocupándola | 1 |
| 19516 | ocupando | 1 |
| 19517 | ocupador | 1 |
| 19518 | ocupadas | 1 |
| 19519 | ocultis | 1 |
| 19520 | ocultes | 1 |
| 19521 | ocultas | 1 |
| 19522 | ocultarte | 1 |
| 19523 | ocultárselo | 1 |
| 19524 | ocultarse | 1 |
| 19525 | ocultáronse | 1 |
| 19526 | ocultarle | 1 |
| 19527 | ocultarían | 1 |
| 19528 | ocultara | 1 |
| 19529 | ocultamente | 1 |
| 19530 | ocular | 1 |
| 19531 | octavo | 1 |
| 19532 | octava | 1 |
| 19533 | ocre | 1 |
| 19534 | ochentines | 1 |
| 19535 | ochavos | 1 |
| 19536 | ochavito | 1 |
| 19537 | océano | 1 |
| 19538 | ocasionó | 1 |
| 19539 | ocasionan | 1 |
| 19540 | ocasional | 1 |
| 19541 | ocasionado | 1 |
| 19542 | ocasionaban | 1 |
| 19543 | ocasiona | 1 |
| 19544 | obtienen | 1 |
| 19545 | obteniendo | 1 |
| 19546 | obtenidas | 1 |
| 19547 | obstruían | 1 |
| 19548 | obstino | 1 |
| 19549 | obstinas | 1 |
| 19550 | obstinación | 1 |
| 19551 | obstinaba | 1 |
| 19552 | obstina | 1 |
| 19553 | obstetricia | 1 |
| 19554 | obstáculos | 1 |
| 19555 | observole | 1 |
| 19556 | observe | 1 |
| 19557 | observaste | 1 |
| 19558 | observas | 1 |
| 19559 | observarse | 1 |
| 19560 | observarla | 1 |
| 19561 | obsérvale | 1 |
| 19562 | observados | 1 |
| 19563 | observada | 1 |
| 19564 | observábale | 1 |
| 19565 | observábala | 1 |
| 19566 | obsequiosissimus | 1 |
| 19567 | obsequios | 1 |
| 19568 | obsequio | 1 |
| 19569 | obsequiadas | 1 |
| 19570 | obrero | 1 |
| 19571 | obre | 1 |
| 19572 | obrase | 1 |
| 19573 | obrando | 1 |
| 19574 | obran | 1 |
| 19575 | obrado | 1 |
| 19576 | obraba | 1 |
| 19577 | obligas | 1 |
| 19578 | obligaron | 1 |
| 19579 | obligaran | 1 |
| 19580 | obligar | 1 |
| 19581 | obligándole | 1 |
| 19582 | obligan | 1 |
| 19583 | oblicuidad | 1 |
| 19584 | oblicuas | 1 |
| 19585 | objetivos | 1 |
| 19586 | objetiva | 1 |
| 19587 | obeso | 1 |
| 19588 | obesidad | 1 |
| 19589 | obedientes | 1 |
| 19590 | obedezco | 1 |
| 19591 | obedecían | 1 |
| 19592 | obedecen | 1 |
| 19593 | ñoños | 1 |
| 19594 | nutría | 1 |
| 19595 | nuncio | 1 |
| 19596 | numismático | 1 |
| 19597 | numerosa | 1 |
| 19598 | numérico | 1 |
| 19599 | nulidad | 1 |
| 19600 | nula | 1 |
| 19601 | nuevecitas | 1 |
| 19602 | nueces | 1 |
| 19603 | nudoso | 1 |
| 19604 | nubló | 1 |
| 19605 | nublado | 1 |
| 19606 | nublaba | 1 |
| 19607 | novísimo | 1 |
| 19608 | novísima | 1 |
| 19609 | noviciado | 1 |
| 19610 | novias | 1 |
| 19611 | noveno | 1 |
| 19612 | novenas | 1 |
| 19613 | novelistas | 1 |
| 19614 | novelista | 1 |
| 19615 | novelesco | 1 |
| 19616 | novelador | 1 |
| 19617 | novel | 1 |
| 19618 | novecientos | 1 |
| 19619 | noticiero | 1 |
| 19620 | notarios | 1 |
| 19621 | notándose | 1 |
| 19622 | notabilísima | 1 |
| 19623 | notabilidades | 1 |
| 19624 | notábase | 1 |
| 19625 | notaban | 1 |
| 19626 | nostri | 1 |
| 19627 | nostalgia | 1 |
| 19628 | normalizar | 1 |
| 19629 | normales | 1 |
| 19630 | norma | 1 |
| 19631 | noramala | 1 |
| 19632 | non | 1 |
| 19633 | nominativas | 1 |
| 19634 | nominal | 1 |
| 19635 | nómina | 1 |
| 19636 | nomenclaturas | 1 |
| 19637 | nomenclátor | 1 |
| 19638 | nombrarla | 1 |
| 19639 | nombrara | 1 |
| 19640 | nombran | 1 |
| 19641 | nombramientos | 1 |
| 19642 | nombramiento | 1 |
| 19643 | nombrados | 1 |
| 19644 | nombrado | 1 |
| 19645 | nombrábase | 1 |
| 19646 | nombraban | 1 |
| 19647 | nombraba | 1 |
| 19648 | nombra | 1 |
| 19649 | nogal | 1 |
| 19650 | nocturnos | 1 |
| 19651 | nocturnas | 1 |
| 19652 | nociva | 1 |
| 19653 | nochecita | 1 |
| 19654 | nobilísimos | 1 |
| 19655 | nobilísima | 1 |
| 19656 | nobiliarias | 1 |
| 19657 | nizán | 1 |
| 19658 | nitro | 1 |
| 19659 | níquel | 1 |
| 19660 | nipis | 1 |
| 19661 | niñerías | 1 |
| 19662 | niñeras | 1 |
| 19663 | nimiedades | 1 |
| 19664 | nilo | 1 |
| 19665 | nieva | 1 |
| 19666 | nietecito | 1 |
| 19667 | niego | 1 |
| 19668 | niegas | 1 |
| 19669 | niebla | 1 |
| 19670 | newton | 1 |
| 19671 | neutralizado | 1 |
| 19672 | neto | 1 |
| 19673 | nerviosos | 1 |
| 19674 | nerviosísima | 1 |
| 19675 | nerviosas | 1 |
| 19676 | neptuno | 1 |
| 19677 | neos | 1 |
| 19678 | neo | 1 |
| 19679 | nenita | 1 |
| 19680 | negrura | 1 |
| 19681 | negrazo | 1 |
| 19682 | negociara | 1 |
| 19683 | negociar | 1 |
| 19684 | negligente | 1 |
| 19685 | negativos | 1 |
| 19686 | negativas | 1 |
| 19687 | negase | 1 |
| 19688 | negaron | 1 |
| 19689 | negaran | 1 |
| 19690 | negándose | 1 |
| 19691 | negación | 1 |
| 19692 | negábase | 1 |
| 19693 | nefandos | 1 |
| 19694 | nefandas | 1 |
| 19695 | necio | 1 |
| 19696 | necias | 1 |
| 19697 | necesitaré | 1 |
| 19698 | necesitará | 1 |
| 19699 | necesitar | 1 |
| 19700 | necesitando | 1 |
| 19701 | necesitados | 1 |
| 19702 | neas | 1 |
| 19703 | navío | 1 |
| 19704 | navidades | 1 |
| 19705 | naves | 1 |
| 19706 | navas | 1 |
| 19707 | navarra | 1 |
| 19708 | navajas | 1 |
| 19709 | navaja | 1 |
| 19710 | nauseabundo | 1 |
| 19711 | naufragios | 1 |
| 19712 | naufragio | 1 |
| 19713 | náufraga | 1 |
| 19714 | náu | 1 |
| 19715 | nato | 1 |
| 19716 | nasales | 1 |
| 19717 | narradora | 1 |
| 19718 | narración | 1 |
| 19719 | narra | 1 |
| 19720 | narina | 1 |
| 19721 | narigudos | 1 |
| 19722 | naricillas | 1 |
| 19723 | narcótico | 1 |
| 19724 | narcisus | 1 |
| 19725 | naranjo | 1 |
| 19726 | naranjeros | 1 |
| 19727 | naranjado | 1 |
| 19728 | napoleónicas | 1 |
| 19729 | nansouk | 1 |
| 19730 | najo | 1 |
| 19731 | najabao | 1 |
| 19732 | nadasen | 1 |
| 19733 | nadase | 1 |
| 19734 | nadamos | 1 |
| 19735 | nadaban | 1 |
| 19736 | naciones | 1 |
| 19737 | nacida | 1 |
| 19738 | nací | 1 |
| 19739 | nacerá | 1 |
| 19740 | mutuo | 1 |
| 19741 | mutuamente | 1 |
| 19742 | mutismo | 1 |
| 19743 | mutaciones | 1 |
| 19744 | mustio | 1 |
| 19745 | musotros | 1 |
| 19746 | muslito | 1 |
| 19747 | músicos | 1 |
| 19748 | musas | 1 |
| 19749 | murmurantes | 1 |
| 19750 | murmuración | 1 |
| 19751 | muriese | 1 |
| 19752 | murieras | 1 |
| 19753 | muriéndose | 1 |
| 19754 | muriéndome | 1 |
| 19755 | murgas | 1 |
| 19756 | murcia | 1 |
| 19757 | murallas | 1 |
| 19758 | muñón | 1 |
| 19759 | munificencia | 1 |
| 19760 | municipio | 1 |
| 19761 | mundanos | 1 |
| 19762 | mundana | 1 |
| 19763 | multitudes | 1 |
| 19764 | multiplica | 1 |
| 19765 | múltiples | 1 |
| 19766 | multas | 1 |
| 19767 | mulo | 1 |
| 19768 | muladares | 1 |
| 19769 | mula | 1 |
| 19770 | mujeriego | 1 |
| 19771 | mujercita | 1 |
| 19772 | mujeraza | 1 |
| 19773 | mugrientas | 1 |
| 19774 | mugir | 1 |
| 19775 | mueven | 1 |
| 19776 | mueva | 1 |
| 19777 | muestrarios | 1 |
| 19778 | muerde | 1 |
| 19779 | muerdas | 1 |
| 19780 | muerda | 1 |
| 19781 | muellemente | 1 |
| 19782 | mueca | 1 |
| 19783 | mudemos | 1 |
| 19784 | mudas | 1 |
| 19785 | mudaron | 1 |
| 19786 | mudara | 1 |
| 19787 | mudando | 1 |
| 19788 | mudan | 1 |
| 19789 | mucosa | 1 |
| 19790 | mucílago | 1 |
| 19791 | muchísimos | 1 |
| 19792 | muchísimas | 1 |
| 19793 | muchedumbres | 1 |
| 19794 | muchachuelas | 1 |
| 19795 | muchachones | 1 |
| 19796 | mozuela | 1 |
| 19797 | mozas | 1 |
| 19798 | mozart | 1 |
| 19799 | mozárabe | 1 |
| 19800 | mozalbetes | 1 |
| 19801 | moyano | 1 |
| 19802 | moviese | 1 |
| 19803 | moviera | 1 |
| 19804 | moviéndola | 1 |
| 19805 | movibles | 1 |
| 19806 | movible | 1 |
| 19807 | movíase | 1 |
| 19808 | movías | 1 |
| 19809 | motivaran | 1 |
| 19810 | motivados | 1 |
| 19811 | motivado | 1 |
| 19812 | motín | 1 |
| 19813 | motes | 1 |
| 19814 | motejaban | 1 |
| 19815 | moteja | 1 |
| 19816 | mostrose | 1 |
| 19817 | mostraron | 1 |
| 19818 | mostrarla | 1 |
| 19819 | mostrándoselos | 1 |
| 19820 | mostrándoselo | 1 |
| 19821 | mostrándolos | 1 |
| 19822 | mostrándolo | 1 |
| 19823 | mostrándola | 1 |
| 19824 | mostrado | 1 |
| 19825 | mosquitero | 1 |
| 19826 | mosquita | 1 |
| 19827 | moscones | 1 |
| 19828 | mortuorio | 1 |
| 19829 | mortifique | 1 |
| 19830 | mortificó | 1 |
| 19831 | mortificarla | 1 |
| 19832 | mortificara | 1 |
| 19833 | mortificando | 1 |
| 19834 | mortificaciones | 1 |
| 19835 | mortero | 1 |
| 19836 | mortecina | 1 |
| 19837 | mortalmente | 1 |
| 19838 | mortaja | 1 |
| 19839 | morrones | 1 |
| 19840 | morro | 1 |
| 19841 | morritos | 1 |
| 19842 | morris | 1 |
| 19843 | morralla | 1 |
| 19844 | morral | 1 |
| 19845 | morrada | 1 |
| 19846 | morosidades | 1 |
| 19847 | moró | 1 |
| 19848 | morisco | 1 |
| 19849 | morisca | 1 |
| 19850 | morírseme | 1 |
| 19851 | morirían | 1 |
| 19852 | moriríamos | 1 |
| 19853 | moriremos | 1 |
| 19854 | moribundo | 1 |
| 19855 | morían | 1 |
| 19856 | morí | 1 |
| 19857 | mordiscos | 1 |
| 19858 | mordiscar | 1 |
| 19859 | mordió | 1 |
| 19860 | mordiéndose | 1 |
| 19861 | mordiendo | 1 |
| 19862 | mordida | 1 |
| 19863 | mordía | 1 |
| 19864 | mordentes | 1 |
| 19865 | moras | 1 |
| 19866 | morar | 1 |
| 19867 | moralizar | 1 |
| 19868 | morados | 1 |
| 19869 | moquito | 1 |
| 19870 | moquillo | 1 |
| 19871 | moqueta | 1 |
| 19872 | moños | 1 |
| 19873 | moña | 1 |
| 19874 | monumento | 1 |
| 19875 | monumentalidad | 1 |
| 19876 | monumental | 1 |
| 19877 | montpensier | 1 |
| 19878 | montose | 1 |
| 19879 | montoncitos | 1 |
| 19880 | montesinos | 1 |
| 19881 | montesa | 1 |
| 19882 | montés | 1 |
| 19883 | montemuru | 1 |
| 19884 | monteleón | 1 |
| 19885 | montarse | 1 |
| 19886 | montarlo | 1 |
| 19887 | montar | 1 |
| 19888 | montañas | 1 |
| 19889 | montaba | 1 |
| 19890 | monstruosos | 1 |
| 19891 | monstruosa | 1 |
| 19892 | monstrua | 1 |
| 19893 | monotonía | 1 |
| 19894 | monopolizaron | 1 |
| 19895 | monopolizando | 1 |
| 19896 | monopolizaban | 1 |
| 19897 | monomaniacos | 1 |
| 19898 | monomaniaca | 1 |
| 19899 | monjes | 1 |
| 19900 | monísimos | 1 |
| 19901 | monísimas | 1 |
| 19902 | monises | 1 |
| 19903 | monín | 1 |
| 19904 | monilla | 1 |
| 19905 | monigote | 1 |
| 19906 | mongólico | 1 |
| 19907 | monetaria | 1 |
| 19908 | monea | 1 |
| 19909 | monde | 1 |
| 19910 | moncloa | 1 |
| 19911 | monasterio | 1 |
| 19912 | monarquías | 1 |
| 19913 | monamente | 1 |
| 19914 | mon | 1 |
| 19915 | momias | 1 |
| 19916 | momentitos | 1 |
| 19917 | momentico | 1 |
| 19918 | momentáneamente | 1 |
| 19919 | molusco | 1 |
| 19920 | molto | 1 |
| 19921 | mollera | 1 |
| 19922 | molleja | 1 |
| 19923 | molinillo | 1 |
| 19924 | molida | 1 |
| 19925 | molía | 1 |
| 19926 | molestó | 1 |
| 19927 | molestísimas | 1 |
| 19928 | molestísima | 1 |
| 19929 | molestase | 1 |
| 19930 | molestas | 1 |
| 19931 | molestarte | 1 |
| 19932 | molestarle | 1 |
| 19933 | molestaré | 1 |
| 19934 | molestará | 1 |
| 19935 | molestan | 1 |
| 19936 | molestábale | 1 |
| 19937 | moler | 1 |
| 19938 | moldearla | 1 |
| 19939 | mojó | 1 |
| 19940 | mojicón | 1 |
| 19941 | mojaría | 1 |
| 19942 | mojar | 1 |
| 19943 | mojándole | 1 |
| 19944 | mojamos | 1 |
| 19945 | mojama | 1 |
| 19946 | mojaba | 1 |
| 19947 | mohosos | 1 |
| 19948 | mohosas | 1 |
| 19949 | modulaciones | 1 |
| 19950 | modosita | 1 |
| 19951 | modorra | 1 |
| 19952 | moditos | 1 |
| 19953 | modistos | 1 |
| 19954 | modistillas | 1 |
| 19955 | modismos | 1 |
| 19956 | modificó | 1 |
| 19957 | modificado | 1 |
| 19958 | modificación | 1 |
| 19959 | modestísimo | 1 |
| 19960 | modestamente | 1 |
| 19961 | modernos | 1 |
| 19962 | modere | 1 |
| 19963 | moderarse | 1 |
| 19964 | moderantismo | 1 |
| 19965 | moderando | 1 |
| 19966 | moderaísmo | 1 |
| 19967 | moderación | 1 |
| 19968 | modelito | 1 |
| 19969 | modele | 1 |
| 19970 | modelaban | 1 |
| 19971 | mochuelo | 1 |
| 19972 | mochila | 1 |
| 19973 | mocetón | 1 |
| 19974 | mixtura | 1 |
| 19975 | mitras | 1 |
| 19976 | mitra | 1 |
| 19977 | mitos | 1 |
| 19978 | mitológico | 1 |
| 19979 | mitchell | 1 |
| 19980 | mistress | 1 |
| 19981 | mistos | 1 |
| 19982 | mistiquerías | 1 |
| 19983 | mística | 1 |
| 19984 | misteriosos | 1 |
| 19985 | mister | 1 |
| 19986 | misté | 1 |
| 19987 | mismísimo | 1 |
| 19988 | misitas | 1 |
| 19989 | misiones | 1 |
| 19990 | misericordias | 1 |
| 19991 | míseras | 1 |
| 19992 | míseramente | 1 |
| 19993 | misales | 1 |
| 19994 | mironas | 1 |
| 19995 | mirola | 1 |
| 19996 | mirlo | 1 |
| 19997 | miriñaque | 1 |
| 19998 | mírelo | 1 |
| 19999 | mirarme | 1 |
| 20000 | mirarlos | 1 |
| 20001 | mirarlas | 1 |
| 20002 | mirarían | 1 |
| 20003 | miraran | 1 |
| 20004 | míranse | 1 |
| 20005 | miranda | 1 |
| 20006 | miramos | 1 |
| 20007 | miramiento | 1 |
| 20008 | míralo | 1 |
| 20009 | mirados | 1 |
| 20010 | mirábase | 1 |
| 20011 | mirábanse | 1 |
| 20012 | mirábanla | 1 |
| 20013 | mirábamos | 1 |
| 20014 | mirábales | 1 |
| 20015 | mirábala | 1 |
| 20016 | miope | 1 |
| 20017 | minueto | 1 |
| 20018 | minuciosas | 1 |
| 20019 | ministerialismo | 1 |
| 20020 | minino | 1 |
| 20021 | miniaturita | 1 |
| 20022 | minas | 1 |
| 20023 | mina | 1 |
| 20024 | mimosidad | 1 |
| 20025 | mimosa | 1 |
| 20026 | mimitos | 1 |
| 20027 | mímicas | 1 |
| 20028 | mimarle | 1 |
| 20029 | mimadito | 1 |
| 20030 | mimadita | 1 |
| 20031 | mimada | 1 |
| 20032 | mimaban | 1 |
| 20033 | millonarios | 1 |
| 20034 | millón | 1 |
| 20035 | millas | 1 |
| 20036 | militante | 1 |
| 20037 | milicianos | 1 |
| 20038 | miliciano | 1 |
| 20039 | milaneses | 1 |
| 20040 | milagroso | 1 |
| 20041 | miiiii | 1 |
| 20042 | mies | 1 |
| 20043 | miércoles | 1 |
| 20044 | miente | 1 |
| 20045 | miembro | 1 |
| 20046 | mielero | 1 |
| 20047 | miedosa | 1 |
| 20048 | midiera | 1 |
| 20049 | midiendo | 1 |
| 20050 | miden | 1 |
| 20051 | micos | 1 |
| 20052 | micho | 1 |
| 20053 | miajitas | 1 |
| 20054 | miaja | 1 |
| 20055 | mezquita | 1 |
| 20056 | mezcló | 1 |
| 20057 | metz | 1 |
| 20058 | metros | 1 |
| 20059 | metrópoli | 1 |
| 20060 | métome | 1 |
| 20061 | metodizando | 1 |
| 20062 | metódicas | 1 |
| 20063 | metiole | 1 |
| 20064 | metiese | 1 |
| 20065 | metiéndola | 1 |
| 20066 | metidita | 1 |
| 20067 | metíase | 1 |
| 20068 | métete | 1 |
| 20069 | metes | 1 |
| 20070 | meterte | 1 |
| 20071 | metérselo | 1 |
| 20072 | meterlos | 1 |
| 20073 | meteré | 1 |
| 20074 | meterá | 1 |
| 20075 | meten | 1 |
| 20076 | metempsícosis | 1 |
| 20077 | metemos | 1 |
| 20078 | mételo | 1 |
| 20079 | mételes | 1 |
| 20080 | metas | 1 |
| 20081 | metan | 1 |
| 20082 | metamos | 1 |
| 20083 | metálicas | 1 |
| 20084 | metálicamente | 1 |
| 20085 | metales | 1 |
| 20086 | metáis | 1 |
| 20087 | metá | 1 |
| 20088 | mesonero | 1 |
| 20089 | mesón | 1 |
| 20090 | mesocrático | 1 |
| 20091 | mesita | 1 |
| 20092 | mesianitis | 1 |
| 20093 | meseta | 1 |
| 20094 | mescolanza | 1 |
| 20095 | mero | 1 |
| 20096 | mermó | 1 |
| 20097 | mermar | 1 |
| 20098 | mermados | 1 |
| 20099 | meriendas | 1 |
| 20100 | meriendan | 1 |
| 20101 | merezcas | 1 |
| 20102 | merengue | 1 |
| 20103 | merengada | 1 |
| 20104 | merenderos | 1 |
| 20105 | mereció | 1 |
| 20106 | merecimientos | 1 |
| 20107 | mereciesen | 1 |
| 20108 | mereciese | 1 |
| 20109 | merecían | 1 |
| 20110 | merecerlo | 1 |
| 20111 | merecería | 1 |
| 20112 | merecéis | 1 |
| 20113 | merecedor | 1 |
| 20114 | mercuriales | 1 |
| 20115 | mercurial | 1 |
| 20116 | mercenarias | 1 |
| 20117 | mercancías | 1 |
| 20118 | mercachifles | 1 |
| 20119 | menudos | 1 |
| 20120 | menudillo | 1 |
| 20121 | mentó | 1 |
| 20122 | mentís | 1 |
| 20123 | mentiroso | 1 |
| 20124 | mentirosas | 1 |
| 20125 | mentirosa | 1 |
| 20126 | mentirilla | 1 |
| 20127 | mentirijillas | 1 |
| 20128 | mentirijilla | 1 |
| 20129 | mentir | 1 |
| 20130 | mentarlo | 1 |
| 20131 | mentales | 1 |
| 20132 | mensajes | 1 |
| 20133 | menospreciar | 1 |
| 20134 | menoscabo | 1 |
| 20135 | menjurje | 1 |
| 20136 | menistro | 1 |
| 20137 | meningo | 1 |
| 20138 | menina | 1 |
| 20139 | mengue | 1 |
| 20140 | menguaban | 1 |
| 20141 | menestrales | 1 |
| 20142 | meneo | 1 |
| 20143 | menease | 1 |
| 20144 | menearse | 1 |
| 20145 | meneallo | 1 |
| 20146 | meneada | 1 |
| 20147 | menea | 1 |
| 20148 | mendiry | 1 |
| 20149 | mendigas | 1 |
| 20150 | mendicante | 1 |
| 20151 | méndez | 1 |
| 20152 | mencionar | 1 |
| 20153 | mencionados | 1 |
| 20154 | mencionada | 1 |
| 20155 | menaje | 1 |
| 20156 | memos | 1 |
| 20157 | memoriales | 1 |
| 20158 | memorial | 1 |
| 20159 | membrillo | 1 |
| 20160 | melón | 1 |
| 20161 | melómanos | 1 |
| 20162 | melómano | 1 |
| 20163 | melodramáticos | 1 |
| 20164 | melodramática | 1 |
| 20165 | melicianos | 1 |
| 20166 | melenudos | 1 |
| 20167 | melenuda | 1 |
| 20168 | melena | 1 |
| 20169 | melancólicamente | 1 |
| 20170 | melaera | 1 |
| 20171 | mela | 1 |
| 20172 | mejoras | 1 |
| 20173 | mejoraré | 1 |
| 20174 | mejoraba | 1 |
| 20175 | meetings | 1 |
| 20176 | medroso | 1 |
| 20177 | medrosica | 1 |
| 20178 | medrosa | 1 |
| 20179 | meditó | 1 |
| 20180 | meditado | 1 |
| 20181 | medirse | 1 |
| 20182 | medió | 1 |
| 20183 | medidor | 1 |
| 20184 | medicinales | 1 |
| 20185 | mediasen | 1 |
| 20186 | mediascañas | 1 |
| 20187 | mediaron | 1 |
| 20188 | medianero | 1 |
| 20189 | mediando | 1 |
| 20190 | medianas | 1 |
| 20191 | medíalas | 1 |
| 20192 | mediaban | 1 |
| 20193 | medía | 1 |
| 20194 | medallas | 1 |
| 20195 | meciéndose | 1 |
| 20196 | mechas | 1 |
| 20197 | mecha | 1 |
| 20198 | meces | 1 |
| 20199 | mécele | 1 |
| 20200 | mecánicos | 1 |
| 20201 | mazmorra | 1 |
| 20202 | maximiliana | 1 |
| 20203 | mauro | 1 |
| 20204 | maulas | 1 |
| 20205 | matuteros | 1 |
| 20206 | matronas | 1 |
| 20207 | matrona | 1 |
| 20208 | matriz | 1 |
| 20209 | matritense | 1 |
| 20210 | matrimoñesca | 1 |
| 20211 | matricularse | 1 |
| 20212 | matrices | 1 |
| 20213 | matorrales | 1 |
| 20214 | matiz | 1 |
| 20215 | matitas | 1 |
| 20216 | matices | 1 |
| 20217 | matías | 1 |
| 20218 | materialmente | 1 |
| 20219 | materialistas | 1 |
| 20220 | materialidades | 1 |
| 20221 | materialidad | 1 |
| 20222 | mateo | 1 |
| 20223 | matemos | 1 |
| 20224 | matemática | 1 |
| 20225 | mátate | 1 |
| 20226 | matase | 1 |
| 20227 | matarnos | 1 |
| 20228 | mataría | 1 |
| 20229 | mataremos | 1 |
| 20230 | matanza | 1 |
| 20231 | mátameles | 1 |
| 20232 | matadores | 1 |
| 20233 | matachines | 1 |
| 20234 | mataba | 1 |
| 20235 | masticarlos | 1 |
| 20236 | massarnau | 1 |
| 20237 | massanielo | 1 |
| 20238 | masque | 1 |
| 20239 | masónico | 1 |
| 20240 | masones | 1 |
| 20241 | mascullones | 1 |
| 20242 | mascullando | 1 |
| 20243 | mascota | 1 |
| 20244 | mascase | 1 |
| 20245 | masca | 1 |
| 20246 | masarnau | 1 |
| 20247 | martirizarle | 1 |
| 20248 | martirios | 1 |
| 20249 | martillos | 1 |
| 20250 | martillazo | 1 |
| 20251 | martillase | 1 |
| 20252 | martes | 1 |
| 20253 | marte | 1 |
| 20254 | marsella | 1 |
| 20255 | marrullería | 1 |
| 20256 | marranos | 1 |
| 20257 | marrano | 1 |
| 20258 | marranadas | 1 |
| 20259 | marranada | 1 |
| 20260 | marquilla | 1 |
| 20261 | marquesito | 1 |
| 20262 | marítimos | 1 |
| 20263 | marismas | 1 |
| 20264 | mariscos | 1 |
| 20265 | marisabidilla | 1 |
| 20266 | mariquita | 1 |
| 20267 | mariposa | 1 |
| 20268 | marinos | 1 |
| 20269 | marino | 1 |
| 20270 | marineros | 1 |
| 20271 | marinero | 1 |
| 20272 | marinas | 1 |
| 20273 | marimachos | 1 |
| 20274 | marica | 1 |
| 20275 | mariana | 1 |
| 20276 | margaritas | 1 |
| 20277 | mareo | 1 |
| 20278 | marearse | 1 |
| 20279 | marearla | 1 |
| 20280 | marearán | 1 |
| 20281 | mareante | 1 |
| 20282 | mareando | 1 |
| 20283 | mareado | 1 |
| 20284 | marcó | 1 |
| 20285 | marchose | 1 |
| 20286 | marcho | 1 |
| 20287 | marchito | 1 |
| 20288 | marchitas | 1 |
| 20289 | marchitarse | 1 |
| 20290 | marche | 1 |
| 20291 | márchate | 1 |
| 20292 | marchasen | 1 |
| 20293 | marcharan | 1 |
| 20294 | marchante | 1 |
| 20295 | marchándose | 1 |
| 20296 | marchando | 1 |
| 20297 | marchan | 1 |
| 20298 | marchádose | 1 |
| 20299 | marchaban | 1 |
| 20300 | marcas | 1 |
| 20301 | marcarles | 1 |
| 20302 | marcándolos | 1 |
| 20303 | marcan | 1 |
| 20304 | marcador | 1 |
| 20305 | marcadas | 1 |
| 20306 | marcadamente | 1 |
| 20307 | maravilloso | 1 |
| 20308 | maravillase | 1 |
| 20309 | maravillarse | 1 |
| 20310 | maravillaron | 1 |
| 20311 | maravillábase | 1 |
| 20312 | maravillaban | 1 |
| 20313 | maravillaba | 1 |
| 20314 | marañas | 1 |
| 20315 | maraña | 1 |
| 20316 | maragatos | 1 |
| 20317 | maragatería | 1 |
| 20318 | maquinales | 1 |
| 20319 | maquinaciones | 1 |
| 20320 | maquina | 1 |
| 20321 | mañoso | 1 |
| 20322 | mañosito | 1 |
| 20323 | mañosas | 1 |
| 20324 | manzanilla | 1 |
| 20325 | manzanas | 1 |
| 20326 | manueles | 1 |
| 20327 | mantuviera | 1 |
| 20328 | manteos | 1 |
| 20329 | manteo | 1 |
| 20330 | mantenido | 1 |
| 20331 | mantenía | 1 |
| 20332 | mantenga | 1 |
| 20333 | mantenerse | 1 |
| 20334 | mantenerla | 1 |
| 20335 | manteleta | 1 |
| 20336 | manteles | 1 |
| 20337 | mansión | 1 |
| 20338 | mansas | 1 |
| 20339 | mansa | 1 |
| 20340 | manoteaba | 1 |
| 20341 | manotazo | 1 |
| 20342 | manosear | 1 |
| 20343 | manoseándole | 1 |
| 20344 | manolos | 1 |
| 20345 | manolitos | 1 |
| 20346 | manolito | 1 |
| 20347 | manjares | 1 |
| 20348 | manjar | 1 |
| 20349 | maniobrar | 1 |
| 20350 | manifiesten | 1 |
| 20351 | manifieste | 1 |
| 20352 | manifestose | 1 |
| 20353 | manifestárselo | 1 |
| 20354 | manifestarle | 1 |
| 20355 | manifestara | 1 |
| 20356 | manifestado | 1 |
| 20357 | manifestaban | 1 |
| 20358 | maniático | 1 |
| 20359 | mangueros | 1 |
| 20360 | mangonee | 1 |
| 20361 | mangoneando | 1 |
| 20362 | mangonean | 1 |
| 20363 | mangoneado | 1 |
| 20364 | manglares | 1 |
| 20365 | manga | 1 |
| 20366 | manetizan | 1 |
| 20367 | manejos | 1 |
| 20368 | manejes | 1 |
| 20369 | manejarte | 1 |
| 20370 | manejándole | 1 |
| 20371 | manejada | 1 |
| 20372 | manejaban | 1 |
| 20373 | maneja | 1 |
| 20374 | manecita | 1 |
| 20375 | mane | 1 |
| 20376 | mandria | 1 |
| 20377 | mandole | 1 |
| 20378 | mandola | 1 |
| 20379 | mandingas | 1 |
| 20380 | mandíbulas | 1 |
| 20381 | mándelas | 1 |
| 20382 | mandéis | 1 |
| 20383 | mandato | 1 |
| 20384 | mandaste | 1 |
| 20385 | mandasen | 1 |
| 20386 | mandase | 1 |
| 20387 | mandas | 1 |
| 20388 | mandaron | 1 |
| 20389 | mandarme | 1 |
| 20390 | mandarles | 1 |
| 20391 | mandarín | 1 |
| 20392 | mandaría | 1 |
| 20393 | mandaremos | 1 |
| 20394 | mandare | 1 |
| 20395 | mandaran | 1 |
| 20396 | mandándole | 1 |
| 20397 | mandamientos | 1 |
| 20398 | mandamiento | 1 |
| 20399 | mándale | 1 |
| 20400 | mandados | 1 |
| 20401 | mandábala | 1 |
| 20402 | mancilla | 1 |
| 20403 | manchurrones | 1 |
| 20404 | manchego | 1 |
| 20405 | manchega | 1 |
| 20406 | mancharse | 1 |
| 20407 | mancháis | 1 |
| 20408 | manchadas | 1 |
| 20409 | manchaba | 1 |
| 20410 | manaza | 1 |
| 20411 | manadas | 1 |
| 20412 | manada | 1 |
| 20413 | mamotretos | 1 |
| 20414 | mamotreto | 1 |
| 20415 | mamen | 1 |
| 20416 | mameluco | 1 |
| 20417 | mamándose | 1 |
| 20418 | mamaíta | 1 |
| 20419 | mamaba | 1 |
| 20420 | malva | 1 |
| 20421 | maltrate | 1 |
| 20422 | maltratada | 1 |
| 20423 | maltrataba | 1 |
| 20424 | maltrajeao | 1 |
| 20425 | malsonante | 1 |
| 20426 | malsana | 1 |
| 20427 | malquerencia | 1 |
| 20428 | malogró | 1 |
| 20429 | maligno | 1 |
| 20430 | malicias | 1 |
| 20431 | malhumorado | 1 |
| 20432 | maleta | 1 |
| 20433 | maleficiar | 1 |
| 20434 | maledicencias | 1 |
| 20435 | maleada | 1 |
| 20436 | maldonadas | 1 |
| 20437 | malditamente | 1 |
| 20438 | maldicientes | 1 |
| 20439 | maldice | 1 |
| 20440 | maldecidos | 1 |
| 20441 | maldecida | 1 |
| 20442 | malchara | 1 |
| 20443 | malayas | 1 |
| 20444 | malaventurado | 1 |
| 20445 | malakoff | 1 |
| 20446 | malagueñas | 1 |
| 20447 | málaga | 1 |
| 20448 | majestuoso | 1 |
| 20449 | majestuosas | 1 |
| 20450 | majestuosa | 1 |
| 20451 | majagranzas | 1 |
| 20452 | majadera | 1 |
| 20453 | maíz | 1 |
| 20454 | mahones | 1 |
| 20455 | magullada | 1 |
| 20456 | mago | 1 |
| 20457 | magnitud | 1 |
| 20458 | magnética | 1 |
| 20459 | magnánimos | 1 |
| 20460 | magistratura | 1 |
| 20461 | magistrado | 1 |
| 20462 | magisterio | 1 |
| 20463 | mágica | 1 |
| 20464 | maestros | 1 |
| 20465 | maestrita | 1 |
| 20466 | maestría | 1 |
| 20467 | madurez | 1 |
| 20468 | madure | 1 |
| 20469 | madurando | 1 |
| 20470 | maduran | 1 |
| 20471 | madrugues | 1 |
| 20472 | madrugadores | 1 |
| 20473 | madrugador | 1 |
| 20474 | madruga | 1 |
| 20475 | madroños | 1 |
| 20476 | madroñaje | 1 |
| 20477 | madrileñas | 1 |
| 20478 | madrigueras | 1 |
| 20479 | madrigales | 1 |
| 20480 | madrastras | 1 |
| 20481 | madrás | 1 |
| 20482 | madoz | 1 |
| 20483 | madeja | 1 |
| 20484 | macuquinas | 1 |
| 20485 | macilenta | 1 |
| 20486 | machos | 1 |
| 20487 | machito | 1 |
| 20488 | machete | 1 |
| 20489 | machetazos | 1 |
| 20490 | machaqué | 1 |
| 20491 | machamartillo | 1 |
| 20492 | machacones | 1 |
| 20493 | machacona | 1 |
| 20494 | machacarla | 1 |
| 20495 | machacante | 1 |
| 20496 | machacado | 1 |
| 20497 | macetas | 1 |
| 20498 | m | 1 |
| 20499 | luteras | 1 |
| 20500 | luterano | 1 |
| 20501 | lustros | 1 |
| 20502 | lunar | 1 |
| 20503 | luminosas | 1 |
| 20504 | lugo | 1 |
| 20505 | lugarón | 1 |
| 20506 | luengos | 1 |
| 20507 | luenga | 1 |
| 20508 | lucrativo | 1 |
| 20509 | lucrativa | 1 |
| 20510 | lucirme | 1 |
| 20511 | luciría | 1 |
| 20512 | lucir | 1 |
| 20513 | lució | 1 |
| 20514 | lucio | 1 |
| 20515 | luciera | 1 |
| 20516 | luciendo | 1 |
| 20517 | lúcidos | 1 |
| 20518 | lucidez | 1 |
| 20519 | lucharían | 1 |
| 20520 | luchar | 1 |
| 20521 | luchana | 1 |
| 20522 | luchan | 1 |
| 20523 | luchaban | 1 |
| 20524 | lucecita | 1 |
| 20525 | luce | 1 |
| 20526 | lozanas | 1 |
| 20527 | lourdes | 1 |
| 20528 | lotero | 1 |
| 20529 | lotérica | 1 |
| 20530 | lorito | 1 |
| 20531 | lores | 1 |
| 20532 | lorenzo | 1 |
| 20533 | lorenzana | 1 |
| 20534 | loquito | 1 |
| 20535 | loquilla | 1 |
| 20536 | lontananzas | 1 |
| 20537 | lontananza | 1 |
| 20538 | lonjas | 1 |
| 20539 | lonja | 1 |
| 20540 | longaniza | 1 |
| 20541 | londonenses | 1 |
| 20542 | lombardas | 1 |
| 20543 | lombarda | 1 |
| 20544 | lola | 1 |
| 20545 | logras | 1 |
| 20546 | lograrlo | 1 |
| 20547 | lograría | 1 |
| 20548 | lograr | 1 |
| 20549 | logrando | 1 |
| 20550 | logradas | 1 |
| 20551 | lógicos | 1 |
| 20552 | lógicamente | 1 |
| 20553 | logia | 1 |
| 20554 | lodos | 1 |
| 20555 | locurilla | 1 |
| 20556 | locuaces | 1 |
| 20557 | locas | 1 |
| 20558 | locamente | 1 |
| 20559 | lóbulos | 1 |
| 20560 | lóbrego | 1 |
| 20561 | lóbregas | 1 |
| 20562 | lobos | 1 |
| 20563 | lobas | 1 |
| 20564 | lluvioso | 1 |
| 20565 | llueven | 1 |
| 20566 | llueve | 1 |
| 20567 | lloviendo | 1 |
| 20568 | lloverá | 1 |
| 20569 | llorosa | 1 |
| 20570 | lloros | 1 |
| 20571 | llorones | 1 |
| 20572 | llorona | 1 |
| 20573 | lloró | 1 |
| 20574 | lloriqueo | 1 |
| 20575 | lloriquear | 1 |
| 20576 | llores | 1 |
| 20577 | llorase | 1 |
| 20578 | llorarle | 1 |
| 20579 | llorándome | 1 |
| 20580 | lloradas | 1 |
| 20581 | llevose | 1 |
| 20582 | llevola | 1 |
| 20583 | lleves | 1 |
| 20584 | llevárselos | 1 |
| 20585 | llevársele | 1 |
| 20586 | lleváronle | 1 |
| 20587 | llevárnoslo | 1 |
| 20588 | llevárnosle | 1 |
| 20589 | llevármelo | 1 |
| 20590 | llevármele | 1 |
| 20591 | llevarlo | 1 |
| 20592 | llevarlas | 1 |
| 20593 | llevándoselas | 1 |
| 20594 | llevándolos | 1 |
| 20595 | llévalos | 1 |
| 20596 | llévalo | 1 |
| 20597 | llevados | 1 |
| 20598 | llevábase | 1 |
| 20599 | llevabas | 1 |
| 20600 | llenola | 1 |
| 20601 | llénese | 1 |
| 20602 | llenéis | 1 |
| 20603 | llenarles | 1 |
| 20604 | llenarla | 1 |
| 20605 | llenaran | 1 |
| 20606 | llenándose | 1 |
| 20607 | llenábase | 1 |
| 20608 | llegues | 1 |
| 20609 | lleguen | 1 |
| 20610 | lleguemos | 1 |
| 20611 | llegose | 1 |
| 20612 | llégate | 1 |
| 20613 | llegas | 1 |
| 20614 | llegarse | 1 |
| 20615 | llegarás | 1 |
| 20616 | llegándole | 1 |
| 20617 | llegados | 1 |
| 20618 | llegadas | 1 |
| 20619 | llaneza | 1 |
| 20620 | llana | 1 |
| 20621 | llamola | 1 |
| 20622 | llamen | 1 |
| 20623 | llamé | 1 |
| 20624 | llamasen | 1 |
| 20625 | llamársela | 1 |
| 20626 | llamáronle | 1 |
| 20627 | llamaríamos | 1 |
| 20628 | llamarás | 1 |
| 20629 | llamarán | 1 |
| 20630 | llamaradas | 1 |
| 20631 | llamarada | 1 |
| 20632 | llamara | 1 |
| 20633 | llámanse | 1 |
| 20634 | llamándome | 1 |
| 20635 | llámame | 1 |
| 20636 | llámalos | 1 |
| 20637 | llámalo | 1 |
| 20638 | llamadas | 1 |
| 20639 | llamabas | 1 |
| 20640 | llamábamos | 1 |
| 20641 | llagas | 1 |
| 20642 | llaga | 1 |
| 20643 | lla | 1 |
| 20644 | livianos | 1 |
| 20645 | liviandades | 1 |
| 20646 | liviandad | 1 |
| 20647 | liviana | 1 |
| 20648 | liverpool | 1 |
| 20649 | liturgia | 1 |
| 20650 | litros | 1 |
| 20651 | litro | 1 |
| 20652 | literarios | 1 |
| 20653 | listos | 1 |
| 20654 | listones | 1 |
| 20655 | lisonjeros | 1 |
| 20656 | lisonjero | 1 |
| 20657 | lisonjera | 1 |
| 20658 | lisonjear | 1 |
| 20659 | liso | 1 |
| 20660 | lisiados | 1 |
| 20661 | lirón | 1 |
| 20662 | liquidar | 1 |
| 20663 | liquidada | 1 |
| 20664 | líquenes | 1 |
| 20665 | lió | 1 |
| 20666 | linneo | 1 |
| 20667 | linfática | 1 |
| 20668 | lindísima | 1 |
| 20669 | lindezas | 1 |
| 20670 | linderos | 1 |
| 20671 | lindaba | 1 |
| 20672 | limpió | 1 |
| 20673 | limpié | 1 |
| 20674 | limpiasen | 1 |
| 20675 | limpias | 1 |
| 20676 | limpiarte | 1 |
| 20677 | limpiarse | 1 |
| 20678 | limpiaron | 1 |
| 20679 | limpiarlos | 1 |
| 20680 | limpiarlo | 1 |
| 20681 | limpiarle | 1 |
| 20682 | limpiara | 1 |
| 20683 | limpiados | 1 |
| 20684 | limpiaban | 1 |
| 20685 | limosnita | 1 |
| 20686 | limítrofes | 1 |
| 20687 | limitose | 1 |
| 20688 | limitó | 1 |
| 20689 | limitados | 1 |
| 20690 | limitada | 1 |
| 20691 | limitaban | 1 |
| 20692 | limbo | 1 |
| 20693 | lija | 1 |
| 20694 | ligeros | 1 |
| 20695 | ligar | 1 |
| 20696 | ligaduras | 1 |
| 20697 | ligaba | 1 |
| 20698 | lidiar | 1 |
| 20699 | licores | 1 |
| 20700 | lición | 1 |
| 20701 | licencioso | 1 |
| 20702 | licenciatura | 1 |
| 20703 | licenciarla | 1 |
| 20704 | licenciados | 1 |
| 20705 | licenciado | 1 |
| 20706 | librotes | 1 |
| 20707 | librote | 1 |
| 20708 | librillos | 1 |
| 20709 | libreta | 1 |
| 20710 | librerías | 1 |
| 20711 | librepensadores | 1 |
| 20712 | librecambista | 1 |
| 20713 | libré | 1 |
| 20714 | librarlas | 1 |
| 20715 | librara | 1 |
| 20716 | librándose | 1 |
| 20717 | líbrame | 1 |
| 20718 | librado | 1 |
| 20719 | libertinos | 1 |
| 20720 | liberticidas | 1 |
| 20721 | liberté | 1 |
| 20722 | liberó | 1 |
| 20723 | liberalescos | 1 |
| 20724 | liarte | 1 |
| 20725 | liar | 1 |
| 20726 | liándose | 1 |
| 20727 | liados | 1 |
| 20728 | leyeras | 1 |
| 20729 | leyeran | 1 |
| 20730 | leyéndolas | 1 |
| 20731 | leyendas | 1 |
| 20732 | levitín | 1 |
| 20733 | levantes | 1 |
| 20734 | levanten | 1 |
| 20735 | levanté | 1 |
| 20736 | levántate | 1 |
| 20737 | levantase | 1 |
| 20738 | levantarme | 1 |
| 20739 | levantarles | 1 |
| 20740 | levantarle | 1 |
| 20741 | levantarlas | 1 |
| 20742 | levantaré | 1 |
| 20743 | levantará | 1 |
| 20744 | levantándola | 1 |
| 20745 | levantamiento | 1 |
| 20746 | levantadas | 1 |
| 20747 | levantábase | 1 |
| 20748 | levantaban | 1 |
| 20749 | levadura | 1 |
| 20750 | letargos | 1 |
| 20751 | lesa | 1 |
| 20752 | lérida | 1 |
| 20753 | lepanto | 1 |
| 20754 | leopardo | 1 |
| 20755 | leoncillo | 1 |
| 20756 | leñera | 1 |
| 20757 | leñador | 1 |
| 20758 | lentejuelas | 1 |
| 20759 | lentejas | 1 |
| 20760 | lentas | 1 |
| 20761 | lengüetazo | 1 |
| 20762 | lengüetas | 1 |
| 20763 | lengüecita | 1 |
| 20764 | lenguaza | 1 |
| 20765 | lenguaraces | 1 |
| 20766 | lenguados | 1 |
| 20767 | lejanos | 1 |
| 20768 | lejanas | 1 |
| 20769 | leitoral | 1 |
| 20770 | leían | 1 |
| 20771 | leí | 1 |
| 20772 | legitimidades | 1 |
| 20773 | legía | 1 |
| 20774 | legalizado | 1 |
| 20775 | legación | 1 |
| 20776 | lees | 1 |
| 20777 | leerte | 1 |
| 20778 | leerle | 1 |
| 20779 | leerla | 1 |
| 20780 | leen | 1 |
| 20781 | leemos | 1 |
| 20782 | lechuzos | 1 |
| 20783 | lechuzas | 1 |
| 20784 | lechuga | 1 |
| 20785 | lean | 1 |
| 20786 | leales | 1 |
| 20787 | lazaretos | 1 |
| 20788 | lazareto | 1 |
| 20789 | lazadas | 1 |
| 20790 | lazada | 1 |
| 20791 | lavose | 1 |
| 20792 | lavemos | 1 |
| 20793 | lave | 1 |
| 20794 | lavatorio | 1 |
| 20795 | lavas | 1 |
| 20796 | lavarle | 1 |
| 20797 | lavaría | 1 |
| 20798 | lavaré | 1 |
| 20799 | lavándose | 1 |
| 20800 | lavando | 1 |
| 20801 | lavandera | 1 |
| 20802 | lavan | 1 |
| 20803 | lavaduras | 1 |
| 20804 | lavadero | 1 |
| 20805 | lavabo | 1 |
| 20806 | lavaban | 1 |
| 20807 | laura | 1 |
| 20808 | laudatorio | 1 |
| 20809 | laudable | 1 |
| 20810 | latro | 1 |
| 20811 | latonero | 1 |
| 20812 | latitudes | 1 |
| 20813 | latinos | 1 |
| 20814 | latinas | 1 |
| 20815 | latina | 1 |
| 20816 | latigazo | 1 |
| 20817 | latía | 1 |
| 20818 | latente | 1 |
| 20819 | lastre | 1 |
| 20820 | lastraba | 1 |
| 20821 | lastimosísimo | 1 |
| 20822 | lastimosísima | 1 |
| 20823 | lastimosa | 1 |
| 20824 | lastimó | 1 |
| 20825 | lastimero | 1 |
| 20826 | lastimera | 1 |
| 20827 | lástimas | 1 |
| 20828 | lastimar | 1 |
| 20829 | lastimándose | 1 |
| 20830 | lastimado | 1 |
| 20831 | lastimaba | 1 |
| 20832 | laringe | 1 |
| 20833 | larguísimas | 1 |
| 20834 | larguísima | 1 |
| 20835 | larguilucho | 1 |
| 20836 | largue | 1 |
| 20837 | largaran | 1 |
| 20838 | largara | 1 |
| 20839 | largar | 1 |
| 20840 | largamos | 1 |
| 20841 | largado | 1 |
| 20842 | lara | 1 |
| 20843 | lapso | 1 |
| 20844 | lápidas | 1 |
| 20845 | lápices | 1 |
| 20846 | lañador | 1 |
| 20847 | lanzará | 1 |
| 20848 | lanzara | 1 |
| 20849 | lanzaban | 1 |
| 20850 | lanuza | 1 |
| 20851 | lantigua | 1 |
| 20852 | langostino | 1 |
| 20853 | langosta | 1 |
| 20854 | landó | 1 |
| 20855 | lanceta | 1 |
| 20856 | lamparilla | 1 |
| 20857 | lámparas | 1 |
| 20858 | laminotas | 1 |
| 20859 | laminitas | 1 |
| 20860 | lamido | 1 |
| 20861 | lamía | 1 |
| 20862 | lamento | 1 |
| 20863 | lamentarse | 1 |
| 20864 | lamentándose | 1 |
| 20865 | lamentaciones | 1 |
| 20866 | lamentábase | 1 |
| 20867 | lamentaban | 1 |
| 20868 | lamen | 1 |
| 20869 | laica | 1 |
| 20870 | lagrimitas | 1 |
| 20871 | lagos | 1 |
| 20872 | lagartijo | 1 |
| 20873 | laganitos | 1 |
| 20874 | ladronicio | 1 |
| 20875 | ladró | 1 |
| 20876 | ladrillazo | 1 |
| 20877 | ladrándole | 1 |
| 20878 | ladra | 1 |
| 20879 | ladinamente | 1 |
| 20880 | ladeando | 1 |
| 20881 | lacto | 1 |
| 20882 | lactancia | 1 |
| 20883 | lacrimoso | 1 |
| 20884 | lacerias | 1 |
| 20885 | lacerante | 1 |
| 20886 | labrando | 1 |
| 20887 | labrados | 1 |
| 20888 | labradas | 1 |
| 20889 | laborioso | 1 |
| 20890 | laboriosa | 1 |
| 20891 | labiano | 1 |
| 20892 | juzgues | 1 |
| 20893 | juzguéis | 1 |
| 20894 | juzgo | 1 |
| 20895 | juzgándose | 1 |
| 20896 | juzgan | 1 |
| 20897 | juzgábase | 1 |
| 20898 | juzgaba | 1 |
| 20899 | juzga | 1 |
| 20900 | juveniles | 1 |
| 20901 | juvenil | 1 |
| 20902 | justificar | 1 |
| 20903 | justificadas | 1 |
| 20904 | justificación | 1 |
| 20905 | justicieras | 1 |
| 20906 | justiciera | 1 |
| 20907 | justiciada | 1 |
| 20908 | justamente | 1 |
| 20909 | justa | 1 |
| 20910 | juros | 1 |
| 20911 | jurídica | 1 |
| 20912 | juras | 1 |
| 20913 | jurarme | 1 |
| 20914 | jurarlo | 1 |
| 20915 | jurar | 1 |
| 20916 | jurando | 1 |
| 20917 | júramelo | 1 |
| 20918 | jurados | 1 |
| 20919 | jurado | 1 |
| 20920 | jura | 1 |
| 20921 | júpiter | 1 |
| 20922 | juntose | 1 |
| 20923 | juntó | 1 |
| 20924 | juntitos | 1 |
| 20925 | juntillas | 1 |
| 20926 | juntarse | 1 |
| 20927 | juntáronse | 1 |
| 20928 | juntan | 1 |
| 20929 | juntábanse | 1 |
| 20930 | juntaban | 1 |
| 20931 | juntaba | 1 |
| 20932 | jumeras | 1 |
| 20933 | jum | 1 |
| 20934 | juliana | 1 |
| 20935 | juiciosos | 1 |
| 20936 | juiciosísimo | 1 |
| 20937 | juiciosillo | 1 |
| 20938 | juiciosas | 1 |
| 20939 | jugué | 1 |
| 20940 | jugosos | 1 |
| 20941 | jugó | 1 |
| 20942 | jugo | 1 |
| 20943 | jugasen | 1 |
| 20944 | jugase | 1 |
| 20945 | jugarreta | 1 |
| 20946 | jugaron | 1 |
| 20947 | jugarle | 1 |
| 20948 | jugadores | 1 |
| 20949 | juergas | 1 |
| 20950 | juegas | 1 |
| 20951 | jueces | 1 |
| 20952 | júcar | 1 |
| 20953 | jubileo | 1 |
| 20954 | jubilarte | 1 |
| 20955 | jubilarse | 1 |
| 20956 | jubilación | 1 |
| 20957 | jovenzuelas | 1 |
| 20958 | jovenzuela | 1 |
| 20959 | jovencito | 1 |
| 20960 | jovellar | 1 |
| 20961 | jovellanos | 1 |
| 20962 | josés | 1 |
| 20963 | josef | 1 |
| 20964 | jorobándonos | 1 |
| 20965 | jorobados | 1 |
| 20966 | jorobadita | 1 |
| 20967 | jorobada | 1 |
| 20968 | jornada | 1 |
| 20969 | jormiguita | 1 |
| 20970 | jordán | 1 |
| 20971 | jonjabaron | 1 |
| 20972 | joloanas | 1 |
| 20973 | jollines | 1 |
| 20974 | jofaina | 1 |
| 20975 | joco | 1 |
| 20976 | job | 1 |
| 20977 | joaquina | 1 |
| 20978 | jipíos | 1 |
| 20979 | jinetes | 1 |
| 20980 | jiménez | 1 |
| 20981 | jilguero | 1 |
| 20982 | jierros | 1 |
| 20983 | jierro | 1 |
| 20984 | jícara | 1 |
| 20985 | jesuítico | 1 |
| 20986 | jesuíticamente | 1 |
| 20987 | jesuita | 1 |
| 20988 | jeroglíficos | 1 |
| 20989 | jeroglífico | 1 |
| 20990 | jericó | 1 |
| 20991 | jergones | 1 |
| 20992 | jerarquías | 1 |
| 20993 | jerarquía | 1 |
| 20994 | jena | 1 |
| 20995 | jefes | 1 |
| 20996 | jayanes | 1 |
| 20997 | jayán | 1 |
| 20998 | javanesas | 1 |
| 20999 | jaulones | 1 |
| 21000 | játiva | 1 |
| 21001 | jarrito | 1 |
| 21002 | jarretiera | 1 |
| 21003 | jardinillo | 1 |
| 21004 | jardinería | 1 |
| 21005 | jardineras | 1 |
| 21006 | jáquima | 1 |
| 21007 | jaquecoso | 1 |
| 21008 | jamona | 1 |
| 21009 | james | 1 |
| 21010 | jaleos | 1 |
| 21011 | jalapa | 1 |
| 21012 | jaez | 1 |
| 21013 | jadeantes | 1 |
| 21014 | jactancia | 1 |
| 21015 | jacquard | 1 |
| 21016 | jacometrenzo | 1 |
| 21017 | jacintillo | 1 |
| 21018 | jabonadura | 1 |
| 21019 | itinerario | 1 |
| 21020 | italiana | 1 |
| 21021 | istmo | 1 |
| 21022 | israelita | 1 |
| 21023 | isprisiones | 1 |
| 21024 | iscariote | 1 |
| 21025 | irujo | 1 |
| 21026 | irte | 1 |
| 21027 | irritó | 1 |
| 21028 | irrites | 1 |
| 21029 | irritarle | 1 |
| 21030 | irritado | 1 |
| 21031 | irritadas | 1 |
| 21032 | irritada | 1 |
| 21033 | irritabilidad | 1 |
| 21034 | irritábase | 1 |
| 21035 | irritaban | 1 |
| 21036 | irritaba | 1 |
| 21037 | irrevocable | 1 |
| 21038 | irreverentemente | 1 |
| 21039 | irreverente | 1 |
| 21040 | irreverencia | 1 |
| 21041 | irrespetuosas | 1 |
| 21042 | irreparables | 1 |
| 21043 | irreparable | 1 |
| 21044 | irremediables | 1 |
| 21045 | irregularidades | 1 |
| 21046 | ironías | 1 |
| 21047 | irlos | 1 |
| 21048 | irlas | 1 |
| 21049 | irlandas | 1 |
| 21050 | irla | 1 |
| 21051 | irisados | 1 |
| 21052 | irascibilidad | 1 |
| 21053 | iracundo | 1 |
| 21054 | iracunda | 1 |
| 21055 | ipso | 1 |
| 21056 | inza | 1 |
| 21057 | inyectados | 1 |
| 21058 | inyectaban | 1 |
| 21059 | invóqueles | 1 |
| 21060 | involuntarios | 1 |
| 21061 | involucremos | 1 |
| 21062 | involucre | 1 |
| 21063 | involución | 1 |
| 21064 | invocó | 1 |
| 21065 | invocaciones | 1 |
| 21066 | invocación | 1 |
| 21067 | invocaba | 1 |
| 21068 | invoca | 1 |
| 21069 | invitole | 1 |
| 21070 | inviten | 1 |
| 21071 | invite | 1 |
| 21072 | invitase | 1 |
| 21073 | invitaron | 1 |
| 21074 | invitará | 1 |
| 21075 | invitar | 1 |
| 21076 | invitando | 1 |
| 21077 | invitaciones | 1 |
| 21078 | invitaba | 1 |
| 21079 | investigó | 1 |
| 21080 | investigador | 1 |
| 21081 | investigación | 1 |
| 21082 | inverosímiles | 1 |
| 21083 | inventos | 1 |
| 21084 | inventor | 1 |
| 21085 | inventiva | 1 |
| 21086 | inventéis | 1 |
| 21087 | inventase | 1 |
| 21088 | inventarlo | 1 |
| 21089 | inventariar | 1 |
| 21090 | inventará | 1 |
| 21091 | inventando | 1 |
| 21092 | inventadas | 1 |
| 21093 | inventada | 1 |
| 21094 | inventa | 1 |
| 21095 | inválido | 1 |
| 21096 | invadió | 1 |
| 21097 | invadido | 1 |
| 21098 | invadían | 1 |
| 21099 | invaden | 1 |
| 21100 | inusitada | 1 |
| 21101 | inundose | 1 |
| 21102 | inundándola | 1 |
| 21103 | inundación | 1 |
| 21104 | inundaban | 1 |
| 21105 | intuitiva | 1 |
| 21106 | intrusa | 1 |
| 21107 | introdujo | 1 |
| 21108 | introdujese | 1 |
| 21109 | introductora | 1 |
| 21110 | introducirse | 1 |
| 21111 | introducirlo | 1 |
| 21112 | introduciendo | 1 |
| 21113 | introducido | 1 |
| 21114 | introducen | 1 |
| 21115 | intríngulis | 1 |
| 21116 | intrigüelas | 1 |
| 21117 | intrigante | 1 |
| 21118 | intrigantas | 1 |
| 21119 | intransitable | 1 |
| 21120 | intranquilizó | 1 |
| 21121 | intolerante | 1 |
| 21122 | intolerable | 1 |
| 21123 | intimó | 1 |
| 21124 | intimando | 1 |
| 21125 | intervino | 1 |
| 21126 | intervinieron | 1 |
| 21127 | intervenían | 1 |
| 21128 | intervalos | 1 |
| 21129 | intervalo | 1 |
| 21130 | interrupciones | 1 |
| 21131 | interrumpiera | 1 |
| 21132 | interrumpiéndole | 1 |
| 21133 | interrumpida | 1 |
| 21134 | interrumpas | 1 |
| 21135 | interrumpan | 1 |
| 21136 | interrogar | 1 |
| 21137 | interrogándose | 1 |
| 21138 | interrogándola | 1 |
| 21139 | interrogando | 1 |
| 21140 | interrogador | 1 |
| 21141 | interrogada | 1 |
| 21142 | interrogaciones | 1 |
| 21143 | interrogación | 1 |
| 21144 | intérprete | 1 |
| 21145 | interprete | 1 |
| 21146 | interpretar | 1 |
| 21147 | interpretándolos | 1 |
| 21148 | interpretándola | 1 |
| 21149 | interpretabas | 1 |
| 21150 | interponiéndose | 1 |
| 21151 | internos | 1 |
| 21152 | internaron | 1 |
| 21153 | interminables | 1 |
| 21154 | intermedia | 1 |
| 21155 | interlocutores | 1 |
| 21156 | interlocutor | 1 |
| 21157 | interjecciones | 1 |
| 21158 | interioridad | 1 |
| 21159 | interino | 1 |
| 21160 | interesar | 1 |
| 21161 | interesantísimo | 1 |
| 21162 | interesan | 1 |
| 21163 | interesado | 1 |
| 21164 | interesaban | 1 |
| 21165 | interceptaron | 1 |
| 21166 | interceptaban | 1 |
| 21167 | intercedí | 1 |
| 21168 | intercede | 1 |
| 21169 | interceda | 1 |
| 21170 | intentos | 1 |
| 21171 | intenté | 1 |
| 21172 | intentase | 1 |
| 21173 | intentaron | 1 |
| 21174 | intentarlo | 1 |
| 21175 | intentaría | 1 |
| 21176 | intentado | 1 |
| 21177 | intensos | 1 |
| 21178 | intensísimas | 1 |
| 21179 | intensidad | 1 |
| 21180 | intensa | 1 |
| 21181 | intendente | 1 |
| 21182 | intencionada | 1 |
| 21183 | intempestivas | 1 |
| 21184 | intemperie | 1 |
| 21185 | inteligible | 1 |
| 21186 | inteligentes | 1 |
| 21187 | intactas | 1 |
| 21188 | intachables | 1 |
| 21189 | insurreccionó | 1 |
| 21190 | insurrección | 1 |
| 21191 | insurgentes | 1 |
| 21192 | insurgente | 1 |
| 21193 | insultos | 1 |
| 21194 | insulté | 1 |
| 21195 | insultase | 1 |
| 21196 | insultarle | 1 |
| 21197 | insultar | 1 |
| 21198 | ínsulas | 1 |
| 21199 | ínsula | 1 |
| 21200 | insufribles | 1 |
| 21201 | insuficientes | 1 |
| 21202 | insubordina | 1 |
| 21203 | instruye | 1 |
| 21204 | instrumentos | 1 |
| 21205 | instruirte | 1 |
| 21206 | instruido | 1 |
| 21207 | instructiva | 1 |
| 21208 | instó | 1 |
| 21209 | instantáneo | 1 |
| 21210 | instancias | 1 |
| 21211 | instancia | 1 |
| 21212 | instalose | 1 |
| 21213 | instaló | 1 |
| 21214 | instalarse | 1 |
| 21215 | instalándose | 1 |
| 21216 | instalado | 1 |
| 21217 | instalaban | 1 |
| 21218 | instalaba | 1 |
| 21219 | instado | 1 |
| 21220 | instaban | 1 |
| 21221 | instaba | 1 |
| 21222 | inspirole | 1 |
| 21223 | inspirarse | 1 |
| 21224 | inspiraron | 1 |
| 21225 | inspirarle | 1 |
| 21226 | inspirar | 1 |
| 21227 | inspirándome | 1 |
| 21228 | inspirabas | 1 |
| 21229 | inspeccionando | 1 |
| 21230 | inspecciona | 1 |
| 21231 | insoportables | 1 |
| 21232 | insolvente | 1 |
| 21233 | insolvencias | 1 |
| 21234 | insolvencia | 1 |
| 21235 | insoluble | 1 |
| 21236 | insolentes | 1 |
| 21237 | insolencias | 1 |
| 21238 | insolencia | 1 |
| 21239 | insistiré | 1 |
| 21240 | insistir | 1 |
| 21241 | insistiese | 1 |
| 21242 | insistiendo | 1 |
| 21243 | insistido | 1 |
| 21244 | insistente | 1 |
| 21245 | insisten | 1 |
| 21246 | insiste | 1 |
| 21247 | insípido | 1 |
| 21248 | insinuarse | 1 |
| 21249 | insinuantes | 1 |
| 21250 | insinuándose | 1 |
| 21251 | insinuaciones | 1 |
| 21252 | insignia | 1 |
| 21253 | insepulto | 1 |
| 21254 | inseparable | 1 |
| 21255 | insensatez | 1 |
| 21256 | inseguros | 1 |
| 21257 | inseguras | 1 |
| 21258 | insectos | 1 |
| 21259 | insecto | 1 |
| 21260 | inquirir | 1 |
| 21261 | inquiriendo | 1 |
| 21262 | inquilino | 1 |
| 21263 | inquietas | 1 |
| 21264 | inquietamente | 1 |
| 21265 | inquietaban | 1 |
| 21266 | inquietaba | 1 |
| 21267 | inoportuno | 1 |
| 21268 | inopinadamente | 1 |
| 21269 | inocentadas | 1 |
| 21270 | inocentada | 1 |
| 21271 | innumerables | 1 |
| 21272 | innovador | 1 |
| 21273 | innobles | 1 |
| 21274 | innegable | 1 |
| 21275 | innatas | 1 |
| 21276 | inmutó | 1 |
| 21277 | inmutarse | 1 |
| 21278 | inmutada | 1 |
| 21279 | inmutables | 1 |
| 21280 | inmunidad | 1 |
| 21281 | inmundo | 1 |
| 21282 | inmundas | 1 |
| 21283 | inmunda | 1 |
| 21284 | inmueble | 1 |
| 21285 | inmovilidad | 1 |
| 21286 | inmóviles | 1 |
| 21287 | inmoralidad | 1 |
| 21288 | inmorales | 1 |
| 21289 | inmoral | 1 |
| 21290 | inmodestia | 1 |
| 21291 | inmensas | 1 |
| 21292 | inmensamente | 1 |
| 21293 | inmediaciones | 1 |
| 21294 | injustos | 1 |
| 21295 | injusto | 1 |
| 21296 | injuriosas | 1 |
| 21297 | injuria | 1 |
| 21298 | injertado | 1 |
| 21299 | ininteligible | 1 |
| 21300 | iniciose | 1 |
| 21301 | iniciarlo | 1 |
| 21302 | iniciar | 1 |
| 21303 | iniciándole | 1 |
| 21304 | inician | 1 |
| 21305 | iniciadoras | 1 |
| 21306 | iniciadora | 1 |
| 21307 | iniciación | 1 |
| 21308 | iniciábasele | 1 |
| 21309 | iniciábase | 1 |
| 21310 | iniciaba | 1 |
| 21311 | inhumanas | 1 |
| 21312 | inhabitables | 1 |
| 21313 | inhábiles | 1 |
| 21314 | inhábil | 1 |
| 21315 | ingreso | 1 |
| 21316 | ingresara | 1 |
| 21317 | ingresar | 1 |
| 21318 | ingratuelo | 1 |
| 21319 | inglesotes | 1 |
| 21320 | inglesote | 1 |
| 21321 | inglesones | 1 |
| 21322 | inglesona | 1 |
| 21323 | ingestión | 1 |
| 21324 | ingente | 1 |
| 21325 | ingénito | 1 |
| 21326 | ingeniosos | 1 |
| 21327 | ingeniosísimos | 1 |
| 21328 | ingenios | 1 |
| 21329 | infundirte | 1 |
| 21330 | infundirse | 1 |
| 21331 | infundiéndole | 1 |
| 21332 | infundíanle | 1 |
| 21333 | infundían | 1 |
| 21334 | infundíale | 1 |
| 21335 | infundes | 1 |
| 21336 | infunden | 1 |
| 21337 | infructuoso | 1 |
| 21338 | infranqueables | 1 |
| 21339 | infortunada | 1 |
| 21340 | informarse | 1 |
| 21341 | informarlo | 1 |
| 21342 | informándose | 1 |
| 21343 | informadora | 1 |
| 21344 | informado | 1 |
| 21345 | informada | 1 |
| 21346 | informaba | 1 |
| 21347 | informa | 1 |
| 21348 | influyese | 1 |
| 21349 | influyendo | 1 |
| 21350 | influye | 1 |
| 21351 | influjo | 1 |
| 21352 | influir | 1 |
| 21353 | infló | 1 |
| 21354 | infligir | 1 |
| 21355 | inflexibilidad | 1 |
| 21356 | inflándose | 1 |
| 21357 | inflamados | 1 |
| 21358 | inflamado | 1 |
| 21359 | inflamación | 1 |
| 21360 | inflamaba | 1 |
| 21361 | inflaban | 1 |
| 21362 | infinitivos | 1 |
| 21363 | infieles | 1 |
| 21364 | infestada | 1 |
| 21365 | infelizote | 1 |
| 21366 | infantería | 1 |
| 21367 | infante | 1 |
| 21368 | infamias | 1 |
| 21369 | infamar | 1 |
| 21370 | infalibilidad | 1 |
| 21371 | inexpugnable | 1 |
| 21372 | inexpresiva | 1 |
| 21373 | inexperto | 1 |
| 21374 | inexpertas | 1 |
| 21375 | inesperadas | 1 |
| 21376 | inesperada | 1 |
| 21377 | inervación | 1 |
| 21378 | inercia | 1 |
| 21379 | inequívoca | 1 |
| 21380 | ineptas | 1 |
| 21381 | inepta | 1 |
| 21382 | ineficaz | 1 |
| 21383 | ineducado | 1 |
| 21384 | ineducada | 1 |
| 21385 | industriosa | 1 |
| 21386 | industrias | 1 |
| 21387 | indultos | 1 |
| 21388 | indulto | 1 |
| 21389 | indújole | 1 |
| 21390 | indujo | 1 |
| 21391 | indujeran | 1 |
| 21392 | indudables | 1 |
| 21393 | induce | 1 |
| 21394 | indolente | 1 |
| 21395 | indivudua | 1 |
| 21396 | individualizar | 1 |
| 21397 | individualidades | 1 |
| 21398 | individuales | 1 |
| 21399 | indispuesta | 1 |
| 21400 | indisoluble | 1 |
| 21401 | indirecto | 1 |
| 21402 | indirectas | 1 |
| 21403 | indirectamente | 1 |
| 21404 | indinos | 1 |
| 21405 | indino | 1 |
| 21406 | indina | 1 |
| 21407 | indilugencia | 1 |
| 21408 | indignarse | 1 |
| 21409 | indignarían | 1 |
| 21410 | indignaban | 1 |
| 21411 | indigestos | 1 |
| 21412 | indigéstate | 1 |
| 21413 | indigestan | 1 |
| 21414 | indigestada | 1 |
| 21415 | indigestaba | 1 |
| 21416 | indigente | 1 |
| 21417 | índices | 1 |
| 21418 | indicáronle | 1 |
| 21419 | indicaron | 1 |
| 21420 | indicarle | 1 |
| 21421 | indicara | 1 |
| 21422 | indicado | 1 |
| 21423 | indias | 1 |
| 21424 | indiana | 1 |
| 21425 | india | 1 |
| 21426 | indeterminado | 1 |
| 21427 | indestructibles | 1 |
| 21428 | indemnizarse | 1 |
| 21429 | indemnizaba | 1 |
| 21430 | indefinido | 1 |
| 21431 | indefensos | 1 |
| 21432 | indecorosa | 1 |
| 21433 | indecibles | 1 |
| 21434 | indecentonas | 1 |
| 21435 | indecentísimos | 1 |
| 21436 | indagatorias | 1 |
| 21437 | indagando | 1 |
| 21438 | indagador | 1 |
| 21439 | indagación | 1 |
| 21440 | indagaba | 1 |
| 21441 | incurrir | 1 |
| 21442 | incumbía | 1 |
| 21443 | incumbencia | 1 |
| 21444 | incultura | 1 |
| 21445 | incultivados | 1 |
| 21446 | inculpabilidad | 1 |
| 21447 | incrustando | 1 |
| 21448 | increpar | 1 |
| 21449 | increpaba | 1 |
| 21450 | incorruptible | 1 |
| 21451 | incorrecta | 1 |
| 21452 | incorrección | 1 |
| 21453 | incorporan | 1 |
| 21454 | incorporábase | 1 |
| 21455 | incontrastables | 1 |
| 21456 | inconstancia | 1 |
| 21457 | inconsolables | 1 |
| 21458 | inconsecuencia | 1 |
| 21459 | inconmensurables | 1 |
| 21460 | inconmensurable | 1 |
| 21461 | inconcuso | 1 |
| 21462 | incomprensible | 1 |
| 21463 | incompletos | 1 |
| 21464 | incompletas | 1 |
| 21465 | incompatible | 1 |
| 21466 | incómodo | 1 |
| 21467 | incomodé | 1 |
| 21468 | incomodase | 1 |
| 21469 | incomodarme | 1 |
| 21470 | incomodara | 1 |
| 21471 | incomodar | 1 |
| 21472 | incomodándose | 1 |
| 21473 | incomodan | 1 |
| 21474 | incomodadísima | 1 |
| 21475 | incomodadas | 1 |
| 21476 | incomoda | 1 |
| 21477 | incoloras | 1 |
| 21478 | incluyeran | 1 |
| 21479 | inclusive | 1 |
| 21480 | inclusero | 1 |
| 21481 | incluido | 1 |
| 21482 | inclino | 1 |
| 21483 | inclinarse | 1 |
| 21484 | inclinábase | 1 |
| 21485 | incitó | 1 |
| 21486 | incitar | 1 |
| 21487 | incitantes | 1 |
| 21488 | incitada | 1 |
| 21489 | incipiente | 1 |
| 21490 | incienso | 1 |
| 21491 | incidentes | 1 |
| 21492 | incidente | 1 |
| 21493 | incidencia | 1 |
| 21494 | incertidumbres | 1 |
| 21495 | incentivo | 1 |
| 21496 | incensario | 1 |
| 21497 | incautos | 1 |
| 21498 | incautas | 1 |
| 21499 | incautado | 1 |
| 21500 | incautación | 1 |
| 21501 | incautaba | 1 |
| 21502 | incapacidad | 1 |
| 21503 | inauguró | 1 |
| 21504 | inarmónica | 1 |
| 21505 | inapetente | 1 |
| 21506 | inanición | 1 |
| 21507 | inamovible | 1 |
| 21508 | inalterada | 1 |
| 21509 | inalterable | 1 |
| 21510 | inaguantable | 1 |
| 21511 | inagotable | 1 |
| 21512 | inactivo | 1 |
| 21513 | inactividad | 1 |
| 21514 | inaccesible | 1 |
| 21515 | imputado | 1 |
| 21516 | impuro | 1 |
| 21517 | impurezas | 1 |
| 21518 | impulsión | 1 |
| 21519 | impulsan | 1 |
| 21520 | impulsado | 1 |
| 21521 | impulsábala | 1 |
| 21522 | impulsa | 1 |
| 21523 | impuesta | 1 |
| 21524 | impúber | 1 |
| 21525 | imprudentes | 1 |
| 21526 | improvisar | 1 |
| 21527 | improvisador | 1 |
| 21528 | improvisado | 1 |
| 21529 | improvisada | 1 |
| 21530 | improvisación | 1 |
| 21531 | impropios | 1 |
| 21532 | impropias | 1 |
| 21533 | improbable | 1 |
| 21534 | imprimir | 1 |
| 21535 | imprimían | 1 |
| 21536 | imprimía | 1 |
| 21537 | imprimen | 1 |
| 21538 | impresos | 1 |
| 21539 | impresionar | 1 |
| 21540 | impresionable | 1 |
| 21541 | impresionaba | 1 |
| 21542 | impresas | 1 |
| 21543 | impregnadas | 1 |
| 21544 | imprecación | 1 |
| 21545 | impotente | 1 |
| 21546 | imposiciones | 1 |
| 21547 | imposibilitándola | 1 |
| 21548 | importunarla | 1 |
| 21549 | importarán | 1 |
| 21550 | importadoras | 1 |
| 21551 | importador | 1 |
| 21552 | importación | 1 |
| 21553 | importaban | 1 |
| 21554 | imponiendo | 1 |
| 21555 | imponíale | 1 |
| 21556 | imponérsele | 1 |
| 21557 | imponer | 1 |
| 21558 | imponen | 1 |
| 21559 | implorar | 1 |
| 21560 | implorando | 1 |
| 21561 | implantado | 1 |
| 21562 | impiedad | 1 |
| 21563 | impido | 1 |
| 21564 | impidió | 1 |
| 21565 | impidiéndose | 1 |
| 21566 | impíamente | 1 |
| 21567 | ímpetus | 1 |
| 21568 | impetrando | 1 |
| 21569 | impersonal | 1 |
| 21570 | imperiosos | 1 |
| 21571 | imperfecciones | 1 |
| 21572 | imperativo | 1 |
| 21573 | imperaba | 1 |
| 21574 | impenetrabilidad | 1 |
| 21575 | impedirle | 1 |
| 21576 | impedirla | 1 |
| 21577 | impediré | 1 |
| 21578 | impávida | 1 |
| 21579 | impasible | 1 |
| 21580 | impares | 1 |
| 21581 | imparcialmente | 1 |
| 21582 | impalpable | 1 |
| 21583 | impacientes | 1 |
| 21584 | impacientarse | 1 |
| 21585 | impacienta | 1 |
| 21586 | imítela | 1 |
| 21587 | imitativa | 1 |
| 21588 | imitarlo | 1 |
| 21589 | imitarla | 1 |
| 21590 | imitado | 1 |
| 21591 | imitaciones | 1 |
| 21592 | imbuyen | 1 |
| 21593 | imbecilidad | 1 |
| 21594 | imbéciles | 1 |
| 21595 | imagínese | 1 |
| 21596 | imaginativos | 1 |
| 21597 | imagínate | 1 |
| 21598 | imaginársela | 1 |
| 21599 | imaginarla | 1 |
| 21600 | imaginario | 1 |
| 21601 | imaginando | 1 |
| 21602 | imaginan | 1 |
| 21603 | imaginamos | 1 |
| 21604 | imaginacioncilla | 1 |
| 21605 | ilustrísimo | 1 |
| 21606 | ilustres | 1 |
| 21607 | ilustrando | 1 |
| 21608 | ilustran | 1 |
| 21609 | ilustrada | 1 |
| 21610 | ilusorios | 1 |
| 21611 | ilusorio | 1 |
| 21612 | ilusionó | 1 |
| 21613 | ilusioncita | 1 |
| 21614 | ilusionarse | 1 |
| 21615 | ilusionándose | 1 |
| 21616 | ilusionan | 1 |
| 21617 | ilusionado | 1 |
| 21618 | ilusionaba | 1 |
| 21619 | iluminarme | 1 |
| 21620 | iluminará | 1 |
| 21621 | iluminación | 1 |
| 21622 | ilimitado | 1 |
| 21623 | ilegal | 1 |
| 21624 | iiii | 1 |
| 21625 | iguale | 1 |
| 21626 | igualarían | 1 |
| 21627 | igualara | 1 |
| 21628 | igualada | 1 |
| 21629 | igualaban | 1 |
| 21630 | ignore | 1 |
| 21631 | ignoras | 1 |
| 21632 | ignorar | 1 |
| 21633 | ignoran | 1 |
| 21634 | ignorada | 1 |
| 21635 | ignominioso | 1 |
| 21636 | ignominiosamente | 1 |
| 21637 | iglesita | 1 |
| 21638 | idos | 1 |
| 21639 | idolatrías | 1 |
| 21640 | idolatrar | 1 |
| 21641 | idólatra | 1 |
| 21642 | idolatra | 1 |
| 21643 | ideó | 1 |
| 21644 | idéntico | 1 |
| 21645 | idéntica | 1 |
| 21646 | ídem | 1 |
| 21647 | ideítas | 1 |
| 21648 | idease | 1 |
| 21649 | idear | 1 |
| 21650 | idealista | 1 |
| 21651 | idealismo | 1 |
| 21652 | ideada | 1 |
| 21653 | iconografía | 1 |
| 21654 | ibérica | 1 |
| 21655 | huyas | 1 |
| 21656 | hurón | 1 |
| 21657 | hurgado | 1 |
| 21658 | huracán | 1 |
| 21659 | hundirse | 1 |
| 21660 | hundiose | 1 |
| 21661 | hundiéronse | 1 |
| 21662 | hundidos | 1 |
| 21663 | hundían | 1 |
| 21664 | hundía | 1 |
| 21665 | húndete | 1 |
| 21666 | hunden | 1 |
| 21667 | hunde | 1 |
| 21668 | humos | 1 |
| 21669 | humorísticas | 1 |
| 21670 | humorística | 1 |
| 21671 | humorada | 1 |
| 21672 | humillen | 1 |
| 21673 | humillarles | 1 |
| 21674 | humillante | 1 |
| 21675 | humillaciones | 1 |
| 21676 | humildísimo | 1 |
| 21677 | húmedo | 1 |
| 21678 | humeante | 1 |
| 21679 | humanitario | 1 |
| 21680 | humanamente | 1 |
| 21681 | hules | 1 |
| 21682 | huían | 1 |
| 21683 | huía | 1 |
| 21684 | huevitos | 1 |
| 21685 | hueverito | 1 |
| 21686 | huevería | 1 |
| 21687 | hueveras | 1 |
| 21688 | huésped | 1 |
| 21689 | huérfano | 1 |
| 21690 | huelva | 1 |
| 21691 | huelgas | 1 |
| 21692 | huelga | 1 |
| 21693 | huecas | 1 |
| 21694 | hubiesen | 1 |
| 21695 | hubiérales | 1 |
| 21696 | hoz | 1 |
| 21697 | hoteles | 1 |
| 21698 | hostigó | 1 |
| 21699 | hostigándole | 1 |
| 21700 | hortalizas | 1 |
| 21701 | hortaliza | 1 |
| 21702 | horroroso | 1 |
| 21703 | horrorizadas | 1 |
| 21704 | horroriza | 1 |
| 21705 | horrorice | 1 |
| 21706 | horripilé | 1 |
| 21707 | horripiladas | 1 |
| 21708 | horripila | 1 |
| 21709 | horrenda | 1 |
| 21710 | horquillas | 1 |
| 21711 | hornito | 1 |
| 21712 | hormiguilla | 1 |
| 21713 | hormiguero | 1 |
| 21714 | horizontales | 1 |
| 21715 | horita | 1 |
| 21716 | hordas | 1 |
| 21717 | horcas | 1 |
| 21718 | horada | 1 |
| 21719 | honrarle | 1 |
| 21720 | honrar | 1 |
| 21721 | honrando | 1 |
| 21722 | honradote | 1 |
| 21723 | honradito | 1 |
| 21724 | honradísimo | 1 |
| 21725 | honradeces | 1 |
| 21726 | honorarios | 1 |
| 21727 | honorario | 1 |
| 21728 | honorabilidad | 1 |
| 21729 | honguito | 1 |
| 21730 | honestos | 1 |
| 21731 | honestidad | 1 |
| 21732 | hondísimos | 1 |
| 21733 | hondísimas | 1 |
| 21734 | hondero | 1 |
| 21735 | hondas | 1 |
| 21736 | homenaje | 1 |
| 21737 | hombrunas | 1 |
| 21738 | hombrón | 1 |
| 21739 | hombría | 1 |
| 21740 | hombrada | 1 |
| 21741 | hombrachón | 1 |
| 21742 | hollín | 1 |
| 21743 | holgazanote | 1 |
| 21744 | holgazanes | 1 |
| 21745 | holgazanería | 1 |
| 21746 | holgazana | 1 |
| 21747 | holgados | 1 |
| 21748 | holgadísimas | 1 |
| 21749 | holgadamente | 1 |
| 21750 | holandas | 1 |
| 21751 | hojuelas | 1 |
| 21752 | hojitas | 1 |
| 21753 | hojarasca | 1 |
| 21754 | hogares | 1 |
| 21755 | hociquitos | 1 |
| 21756 | hociquearemos | 1 |
| 21757 | hocicadas | 1 |
| 21758 | hocicada | 1 |
| 21759 | hízome | 1 |
| 21760 | hízola | 1 |
| 21761 | histrionismo | 1 |
| 21762 | histriónica | 1 |
| 21763 | historiador | 1 |
| 21764 | hispanófilo | 1 |
| 21765 | hispana | 1 |
| 21766 | hirviendo | 1 |
| 21767 | hirió | 1 |
| 21768 | hirieran | 1 |
| 21769 | hiriera | 1 |
| 21770 | hiriendo | 1 |
| 21771 | hipotéticamente | 1 |
| 21772 | hipótesis | 1 |
| 21773 | hipotecan | 1 |
| 21774 | hipotecado | 1 |
| 21775 | hipoquitropíticas | 1 |
| 21776 | hipódromo | 1 |
| 21777 | hipocritón | 1 |
| 21778 | hipocráticos | 1 |
| 21779 | hipocráticas | 1 |
| 21780 | hipócrates | 1 |
| 21781 | hipo | 1 |
| 21782 | hiperquinesia | 1 |
| 21783 | hiperbólicos | 1 |
| 21784 | hiperbólico | 1 |
| 21785 | hiperbólicamente | 1 |
| 21786 | hipérbole | 1 |
| 21787 | hindostán | 1 |
| 21788 | hincósele | 1 |
| 21789 | hinchar | 1 |
| 21790 | hinchándose | 1 |
| 21791 | hinchando | 1 |
| 21792 | hinchados | 1 |
| 21793 | hinchada | 1 |
| 21794 | hinchaba | 1 |
| 21795 | hincar | 1 |
| 21796 | hincaba | 1 |
| 21797 | himnos | 1 |
| 21798 | hilvanarlos | 1 |
| 21799 | hilito | 1 |
| 21800 | hilillos | 1 |
| 21801 | hileras | 1 |
| 21802 | hildebrando | 1 |
| 21803 | hilar | 1 |
| 21804 | hiladito | 1 |
| 21805 | hilaban | 1 |
| 21806 | hijastra | 1 |
| 21807 | higuí | 1 |
| 21808 | higo | 1 |
| 21809 | higiénicos | 1 |
| 21810 | higiene | 1 |
| 21811 | higa | 1 |
| 21812 | hierven | 1 |
| 21813 | hiero | 1 |
| 21814 | hiere | 1 |
| 21815 | hierba | 1 |
| 21816 | hidropesía | 1 |
| 21817 | hidrógeno | 1 |
| 21818 | hidra | 1 |
| 21819 | hide | 1 |
| 21820 | hicimos | 1 |
| 21821 | hiciéronle | 1 |
| 21822 | híceme | 1 |
| 21823 | heterogéneo | 1 |
| 21824 | heterodoxa | 1 |
| 21825 | hervores | 1 |
| 21826 | herreros | 1 |
| 21827 | herrería | 1 |
| 21828 | herrar | 1 |
| 21829 | herraje | 1 |
| 21830 | heroísmos | 1 |
| 21831 | hermosotes | 1 |
| 21832 | hermosismo | 1 |
| 21833 | hermosísimas | 1 |
| 21834 | hermosísima | 1 |
| 21835 | hermosamente | 1 |
| 21836 | hermanillo | 1 |
| 21837 | heridos | 1 |
| 21838 | hería | 1 |
| 21839 | herejotes | 1 |
| 21840 | herejote | 1 |
| 21841 | herejías | 1 |
| 21842 | herejía | 1 |
| 21843 | hereditario | 1 |
| 21844 | herederos | 1 |
| 21845 | herede | 1 |
| 21846 | heredáis | 1 |
| 21847 | heredadas | 1 |
| 21848 | hereda | 1 |
| 21849 | heráldica | 1 |
| 21850 | hepáticas | 1 |
| 21851 | hendiduras | 1 |
| 21852 | henchido | 1 |
| 21853 | hemorragia | 1 |
| 21854 | hemoptisis | 1 |
| 21855 | hemicráneo | 1 |
| 21856 | heló | 1 |
| 21857 | heliotropo | 1 |
| 21858 | heliogábalo | 1 |
| 21859 | helénica | 1 |
| 21860 | helena | 1 |
| 21861 | helechos | 1 |
| 21862 | helas | 1 |
| 21863 | helaron | 1 |
| 21864 | helar | 1 |
| 21865 | heine | 1 |
| 21866 | hediondo | 1 |
| 21867 | hechicero | 1 |
| 21868 | hebillas | 1 |
| 21869 | hazañas | 1 |
| 21870 | hazaña | 1 |
| 21871 | haymarket | 1 |
| 21872 | hatchiss | 1 |
| 21873 | hartaran | 1 |
| 21874 | hartándose | 1 |
| 21875 | hartan | 1 |
| 21876 | harpías | 1 |
| 21877 | harpía | 1 |
| 21878 | harina | 1 |
| 21879 | haragán | 1 |
| 21880 | hamlet | 1 |
| 21881 | hamburgo | 1 |
| 21882 | hallole | 1 |
| 21883 | hallo | 1 |
| 21884 | hallazgos | 1 |
| 21885 | hállase | 1 |
| 21886 | halláronse | 1 |
| 21887 | hallaron | 1 |
| 21888 | hallar | 1 |
| 21889 | hallamos | 1 |
| 21890 | hallado | 1 |
| 21891 | hálito | 1 |
| 21892 | halcón | 1 |
| 21893 | halagarle | 1 |
| 21894 | hágote | 1 |
| 21895 | hágolo | 1 |
| 21896 | háganme | 1 |
| 21897 | hagámonos | 1 |
| 21898 | haeckel | 1 |
| 21899 | hacinadas | 1 |
| 21900 | haciéndosele | 1 |
| 21901 | haciéndomelo | 1 |
| 21902 | haciéndome | 1 |
| 21903 | hacíanla | 1 |
| 21904 | hacíale | 1 |
| 21905 | haches | 1 |
| 21906 | hache | 1 |
| 21907 | hacérselos | 1 |
| 21908 | hacérsele | 1 |
| 21909 | hacerlas | 1 |
| 21910 | hacendosa | 1 |
| 21911 | hacendista | 1 |
| 21912 | haced | 1 |
| 21913 | habríase | 1 |
| 21914 | habríale | 1 |
| 21915 | habremos | 1 |
| 21916 | habrase | 1 |
| 21917 | hablen | 1 |
| 21918 | háblele | 1 |
| 21919 | hablarse | 1 |
| 21920 | hablarás | 1 |
| 21921 | hablaras | 1 |
| 21922 | hablarán | 1 |
| 21923 | háblame | 1 |
| 21924 | habladoras | 1 |
| 21925 | hablabas | 1 |
| 21926 | habitaba | 1 |
| 21927 | habita | 1 |
| 21928 | habilísimas | 1 |
| 21929 | habiéndote | 1 |
| 21930 | habiéndome | 1 |
| 21931 | habiéndolo | 1 |
| 21932 | habíales | 1 |
| 21933 | habíalas | 1 |
| 21934 | habíala | 1 |
| 21935 | habia | 1 |
| 21936 | habértelo | 1 |
| 21937 | haberlos | 1 |
| 21938 | habas | 1 |
| 21939 | guturales | 1 |
| 21940 | gutural | 1 |
| 21941 | guttenberg | 1 |
| 21942 | gutapercha | 1 |
| 21943 | gustosos | 1 |
| 21944 | gustoso | 1 |
| 21945 | gustosamente | 1 |
| 21946 | gustosa | 1 |
| 21947 | gustes | 1 |
| 21948 | gustas | 1 |
| 21949 | gustara | 1 |
| 21950 | gustable | 1 |
| 21951 | gusanera | 1 |
| 21952 | guras | 1 |
| 21953 | gurapas | 1 |
| 21954 | guitarrista | 1 |
| 21955 | guisotes | 1 |
| 21956 | guiso | 1 |
| 21957 | guisas | 1 |
| 21958 | guisadas | 1 |
| 21959 | guisaba | 1 |
| 21960 | guirnaldas | 1 |
| 21961 | guirigay | 1 |
| 21962 | guiños | 1 |
| 21963 | guiñó | 1 |
| 21964 | guiño | 1 |
| 21965 | guiñar | 1 |
| 21966 | guiñados | 1 |
| 21967 | guiñada | 1 |
| 21968 | guindilla | 1 |
| 21969 | guindalera | 1 |
| 21970 | guillotinadas | 1 |
| 21971 | guillermo | 1 |
| 21972 | guillado | 1 |
| 21973 | guijarro | 1 |
| 21974 | guiase | 1 |
| 21975 | guiarte | 1 |
| 21976 | guiarse | 1 |
| 21977 | guiar | 1 |
| 21978 | guiándolas | 1 |
| 21979 | guiando | 1 |
| 21980 | guiado | 1 |
| 21981 | guiaba | 1 |
| 21982 | guetaria | 1 |
| 21983 | guerrillero | 1 |
| 21984 | guerrera | 1 |
| 21985 | güeno | 1 |
| 21986 | güelvo | 1 |
| 21987 | güélvete | 1 |
| 21988 | guelbenzu | 1 |
| 21989 | guealés | 1 |
| 21990 | gubernativo | 1 |
| 21991 | gubernamentales | 1 |
| 21992 | gubernamental | 1 |
| 21993 | gubernación | 1 |
| 21994 | guasón | 1 |
| 21995 | guasee | 1 |
| 21996 | guarismo | 1 |
| 21997 | guaridas | 1 |
| 21998 | guarida | 1 |
| 21999 | guardesas | 1 |
| 22000 | guardes | 1 |
| 22001 | guarden | 1 |
| 22002 | guárdelo | 1 |
| 22003 | guárdate | 1 |
| 22004 | guardase | 1 |
| 22005 | guardárselo | 1 |
| 22006 | guardarlo | 1 |
| 22007 | guardarle | 1 |
| 22008 | guardarlas | 1 |
| 22009 | guardarla | 1 |
| 22010 | guardarían | 1 |
| 22011 | guardándolo | 1 |
| 22012 | guardamos | 1 |
| 22013 | guardamalletas | 1 |
| 22014 | guárdalo | 1 |
| 22015 | guárdala | 1 |
| 22016 | guardados | 1 |
| 22017 | guardadora | 1 |
| 22018 | guardadas | 1 |
| 22019 | guardacantón | 1 |
| 22020 | guardabrisas | 1 |
| 22021 | guardaban | 1 |
| 22022 | guardábalo | 1 |
| 22023 | guapos | 1 |
| 22024 | guapito | 1 |
| 22025 | guapines | 1 |
| 22026 | guapín | 1 |
| 22027 | guapillas | 1 |
| 22028 | guapezas | 1 |
| 22029 | guapeza | 1 |
| 22030 | guapetones | 1 |
| 22031 | guapamente | 1 |
| 22032 | guadalupe | 1 |
| 22033 | grupito | 1 |
| 22034 | gruesísima | 1 |
| 22035 | grúas | 1 |
| 22036 | groserías | 1 |
| 22037 | grosera | 1 |
| 22038 | gros | 1 |
| 22039 | grite | 1 |
| 22040 | grita | 1 |
| 22041 | grifos | 1 |
| 22042 | griego | 1 |
| 22043 | greña | 1 |
| 22044 | gremios | 1 |
| 22045 | gremio | 1 |
| 22046 | gravitó | 1 |
| 22047 | gravitativo | 1 |
| 22048 | gravísimas | 1 |
| 22049 | grasiento | 1 |
| 22050 | granuloso | 1 |
| 22051 | granulosa | 1 |
| 22052 | granulaciones | 1 |
| 22053 | granujita | 1 |
| 22054 | grandullón | 1 |
| 22055 | grandones | 1 |
| 22056 | grandezas | 1 |
| 22057 | grandemente | 1 |
| 22058 | grandecitos | 1 |
| 22059 | grandecitas | 1 |
| 22060 | grandecita | 1 |
| 22061 | granadinas | 1 |
| 22062 | gramos | 1 |
| 22063 | gramo | 1 |
| 22064 | gramaticales | 1 |
| 22065 | grajeas | 1 |
| 22066 | gráficamente | 1 |
| 22067 | graduación | 1 |
| 22068 | graduaba | 1 |
| 22069 | gradaciones | 1 |
| 22070 | graciosísima | 1 |
| 22071 | grabados | 1 |
| 22072 | grabadas | 1 |
| 22073 | grababan | 1 |
| 22074 | gozosas | 1 |
| 22075 | gozón | 1 |
| 22076 | goznes | 1 |
| 22077 | gozaremos | 1 |
| 22078 | gozaré | 1 |
| 22079 | gozan | 1 |
| 22080 | gotita | 1 |
| 22081 | gótico | 1 |
| 22082 | goterones | 1 |
| 22083 | gotear | 1 |
| 22084 | gorritas | 1 |
| 22085 | gorrita | 1 |
| 22086 | gorrinos | 1 |
| 22087 | gorrina | 1 |
| 22088 | gorjeo | 1 |
| 22089 | gordura | 1 |
| 22090 | gordito | 1 |
| 22091 | gordita | 1 |
| 22092 | gordísimo | 1 |
| 22093 | golviésemos | 1 |
| 22094 | golver | 1 |
| 22095 | golpecito | 1 |
| 22096 | golpeaba | 1 |
| 22097 | golpazos | 1 |
| 22098 | goloso | 1 |
| 22099 | golondrina | 1 |
| 22100 | gollerías | 1 |
| 22101 | goled | 1 |
| 22102 | gola | 1 |
| 22103 | goiri | 1 |
| 22104 | goëthe | 1 |
| 22105 | gocen | 1 |
| 22106 | gocemos | 1 |
| 22107 | gobernarte | 1 |
| 22108 | gobernarse | 1 |
| 22109 | gobernarlo | 1 |
| 22110 | gobernara | 1 |
| 22111 | gobernando | 1 |
| 22112 | gobernadora | 1 |
| 22113 | gobernable | 1 |
| 22114 | gobernábala | 1 |
| 22115 | gluten | 1 |
| 22116 | glotona | 1 |
| 22117 | gloriosos | 1 |
| 22118 | gloriosas | 1 |
| 22119 | glóbulos | 1 |
| 22120 | glóbulo | 1 |
| 22121 | globo | 1 |
| 22122 | gitano | 1 |
| 22123 | gitani | 1 |
| 22124 | gitanas | 1 |
| 22125 | gitana | 1 |
| 22126 | girones | 1 |
| 22127 | girasoles | 1 |
| 22128 | girase | 1 |
| 22129 | girar | 1 |
| 22130 | girando | 1 |
| 22131 | giraba | 1 |
| 22132 | gimnástica | 1 |
| 22133 | gimnasias | 1 |
| 22134 | gimió | 1 |
| 22135 | gimiendo | 1 |
| 22136 | gilís | 1 |
| 22137 | gigantones | 1 |
| 22138 | gigantescas | 1 |
| 22139 | gestión | 1 |
| 22140 | gesticulaba | 1 |
| 22141 | gestación | 1 |
| 22142 | germen | 1 |
| 22143 | germán | 1 |
| 22144 | genuino | 1 |
| 22145 | genuflexión | 1 |
| 22146 | gentualla | 1 |
| 22147 | gentileza | 1 |
| 22148 | gentil | 1 |
| 22149 | generosos | 1 |
| 22150 | generalización | 1 |
| 22151 | generadora | 1 |
| 22152 | generación | 1 |
| 22153 | genealógico | 1 |
| 22154 | gendarme | 1 |
| 22155 | gemelos | 1 |
| 22156 | gelsemina | 1 |
| 22157 | gaznate | 1 |
| 22158 | gaznápiro | 1 |
| 22159 | gazmoño | 1 |
| 22160 | gayola | 1 |
| 22161 | gatuno | 1 |
| 22162 | gatillo | 1 |
| 22163 | gaterías | 1 |
| 22164 | gatería | 1 |
| 22165 | gatera | 1 |
| 22166 | gasté | 1 |
| 22167 | gaste | 1 |
| 22168 | gastas | 1 |
| 22169 | gastarse | 1 |
| 22170 | gastarlo | 1 |
| 22171 | gastarían | 1 |
| 22172 | gastaré | 1 |
| 22173 | gastarás | 1 |
| 22174 | gastará | 1 |
| 22175 | gastándolo | 1 |
| 22176 | gastados | 1 |
| 22177 | gaseosa | 1 |
| 22178 | gasas | 1 |
| 22179 | gárrulo | 1 |
| 22180 | garrulería | 1 |
| 22181 | gárrula | 1 |
| 22182 | garrotazo | 1 |
| 22183 | garró | 1 |
| 22184 | garrapatos | 1 |
| 22185 | garrafas | 1 |
| 22186 | garlochín | 1 |
| 22187 | garita | 1 |
| 22188 | garfio | 1 |
| 22189 | garfiñé | 1 |
| 22190 | garfiñaran | 1 |
| 22191 | garbosa | 1 |
| 22192 | garantíceme | 1 |
| 22193 | garantías | 1 |
| 22194 | garantía | 1 |
| 22195 | garabito | 1 |
| 22196 | ganzúa | 1 |
| 22197 | ganso | 1 |
| 22198 | gangrenada | 1 |
| 22199 | gane | 1 |
| 22200 | gandía | 1 |
| 22201 | ganarle | 1 |
| 22202 | ganaremos | 1 |
| 22203 | ganarás | 1 |
| 22204 | ganará | 1 |
| 22205 | ganapán | 1 |
| 22206 | ganándose | 1 |
| 22207 | ganamos | 1 |
| 22208 | ganadas | 1 |
| 22209 | ganábalo | 1 |
| 22210 | galonado | 1 |
| 22211 | gallos | 1 |
| 22212 | gallinejera | 1 |
| 22213 | gallineja | 1 |
| 22214 | gallináceas | 1 |
| 22215 | galletas | 1 |
| 22216 | galleta | 1 |
| 22217 | gallego | 1 |
| 22218 | gallegas | 1 |
| 22219 | gallega | 1 |
| 22220 | gallardo | 1 |
| 22221 | gallardísimo | 1 |
| 22222 | gallardeaba | 1 |
| 22223 | galindo | 1 |
| 22224 | galimatías | 1 |
| 22225 | galileo | 1 |
| 22226 | galgo | 1 |
| 22227 | galerías | 1 |
| 22228 | galería | 1 |
| 22229 | galdós | 1 |
| 22230 | galas | 1 |
| 22231 | galantes | 1 |
| 22232 | gaeta | 1 |
| 22233 | gachas | 1 |
| 22234 | gacetilla | 1 |
| 22235 | gabinetes | 1 |
| 22236 | gabachos | 1 |
| 22237 | gabachas | 1 |
| 22238 | fustes | 1 |
| 22239 | fusileros | 1 |
| 22240 | fusilaron | 1 |
| 22241 | fusilar | 1 |
| 22242 | fusilaba | 1 |
| 22243 | furtivas | 1 |
| 22244 | furores | 1 |
| 22245 | furiosos | 1 |
| 22246 | furiosas | 1 |
| 22247 | furiosamente | 1 |
| 22248 | furibundos | 1 |
| 22249 | furibundas | 1 |
| 22250 | funestos | 1 |
| 22251 | funestas | 1 |
| 22252 | funerales | 1 |
| 22253 | funeral | 1 |
| 22254 | fundirnos | 1 |
| 22255 | fundiéndose | 1 |
| 22256 | fundarme | 1 |
| 22257 | fundándonos | 1 |
| 22258 | fundándome | 1 |
| 22259 | fundando | 1 |
| 22260 | fundamentales | 1 |
| 22261 | fundamenta | 1 |
| 22262 | fundados | 1 |
| 22263 | fundábase | 1 |
| 22264 | fundabas | 1 |
| 22265 | funda | 1 |
| 22266 | funcionario | 1 |
| 22267 | funcionara | 1 |
| 22268 | funcionar | 1 |
| 22269 | funcionante | 1 |
| 22270 | funcionando | 1 |
| 22271 | funcionaban | 1 |
| 22272 | funcionaba | 1 |
| 22273 | fumarse | 1 |
| 22274 | fumándose | 1 |
| 22275 | fumada | 1 |
| 22276 | fumaba | 1 |
| 22277 | fuma | 1 |
| 22278 | fulminó | 1 |
| 22279 | fulminantes | 1 |
| 22280 | fulgores | 1 |
| 22281 | fulastre | 1 |
| 22282 | fuisteis | 1 |
| 22283 | fuimos | 1 |
| 22284 | fugitivos | 1 |
| 22285 | fugitiva | 1 |
| 22286 | fugaces | 1 |
| 22287 | fuertecilla | 1 |
| 22288 | fueren | 1 |
| 22289 | fuentecillas | 1 |
| 22290 | fuencarral | 1 |
| 22291 | fu | 1 |
| 22292 | frustrar | 1 |
| 22293 | frustrado | 1 |
| 22294 | fruslerías | 1 |
| 22295 | fruncir | 1 |
| 22296 | fruncidos | 1 |
| 22297 | fruncida | 1 |
| 22298 | fruición | 1 |
| 22299 | frugalidad | 1 |
| 22300 | froten | 1 |
| 22301 | frote | 1 |
| 22302 | frotasen | 1 |
| 22303 | frotándole | 1 |
| 22304 | frotándola | 1 |
| 22305 | frotando | 1 |
| 22306 | frotábase | 1 |
| 22307 | frotaban | 1 |
| 22308 | frontiles | 1 |
| 22309 | frontil | 1 |
| 22310 | frontero | 1 |
| 22311 | fronteras | 1 |
| 22312 | frontales | 1 |
| 22313 | frontal | 1 |
| 22314 | frondoso | 1 |
| 22315 | frivolidad | 1 |
| 22316 | frívola | 1 |
| 22317 | fritas | 1 |
| 22318 | fritanga | 1 |
| 22319 | frisaba | 1 |
| 22320 | frigidísimo | 1 |
| 22321 | fríes | 1 |
| 22322 | frieron | 1 |
| 22323 | fríamente | 1 |
| 22324 | fresquecito | 1 |
| 22325 | fresquecita | 1 |
| 22326 | fresno | 1 |
| 22327 | frescuras | 1 |
| 22328 | frescachona | 1 |
| 22329 | frescachón | 1 |
| 22330 | frenopático | 1 |
| 22331 | frenética | 1 |
| 22332 | freír | 1 |
| 22333 | freidera | 1 |
| 22334 | fregoteo | 1 |
| 22335 | fregotee | 1 |
| 22336 | fregaré | 1 |
| 22337 | fregando | 1 |
| 22338 | fregaban | 1 |
| 22339 | fregaba | 1 |
| 22340 | freeeesero | 1 |
| 22341 | frecuentemente | 1 |
| 22342 | frecuentar | 1 |
| 22343 | frecuentando | 1 |
| 22344 | frecuentaban | 1 |
| 22345 | frecuenta | 1 |
| 22346 | freatas | 1 |
| 22347 | frasecilla | 1 |
| 22348 | frasear | 1 |
| 22349 | frascuelo | 1 |
| 22350 | franquezas | 1 |
| 22351 | franja | 1 |
| 22352 | franela | 1 |
| 22353 | francisca | 1 |
| 22354 | francesillas | 1 |
| 22355 | francesilla | 1 |
| 22356 | francesas | 1 |
| 22357 | francachelas | 1 |
| 22358 | fragmentos | 1 |
| 22359 | fragmento | 1 |
| 22360 | frágil | 1 |
| 22361 | fragatonas | 1 |
| 22362 | fragancias | 1 |
| 22363 | fouquier | 1 |
| 22364 | fotográfico | 1 |
| 22365 | fortunatita | 1 |
| 22366 | fortunatas | 1 |
| 22367 | fortunas | 1 |
| 22368 | fortunaaá | 1 |
| 22369 | fortifica | 1 |
| 22370 | fortalecimiento | 1 |
| 22371 | fortalecídose | 1 |
| 22372 | fortalecido | 1 |
| 22373 | fortalecen | 1 |
| 22374 | fortalece | 1 |
| 22375 | forros | 1 |
| 22376 | forraría | 1 |
| 22377 | foro | 1 |
| 22378 | formuló | 1 |
| 22379 | formularlo | 1 |
| 22380 | formular | 1 |
| 22381 | formose | 1 |
| 22382 | fórmico | 1 |
| 22383 | forme | 1 |
| 22384 | formarte | 1 |
| 22385 | formarle | 1 |
| 22386 | formarlas | 1 |
| 22387 | formaría | 1 |
| 22388 | forman | 1 |
| 22389 | formalmente | 1 |
| 22390 | formalito | 1 |
| 22391 | formalita | 1 |
| 22392 | formada | 1 |
| 22393 | formación | 1 |
| 22394 | forjarse | 1 |
| 22395 | forjar | 1 |
| 22396 | forcejear | 1 |
| 22397 | forcejeando | 1 |
| 22398 | forasteros | 1 |
| 22399 | forasteras | 1 |
| 22400 | forajido | 1 |
| 22401 | fontainebleau | 1 |
| 22402 | fomento | 1 |
| 22403 | fomentas | 1 |
| 22404 | folletos | 1 |
| 22405 | folletito | 1 |
| 22406 | fogosas | 1 |
| 22407 | fogón | 1 |
| 22408 | fofa | 1 |
| 22409 | fluidos | 1 |
| 22410 | fluido | 1 |
| 22411 | flote | 1 |
| 22412 | flotar | 1 |
| 22413 | florilogios | 1 |
| 22414 | floridas | 1 |
| 22415 | floreos | 1 |
| 22416 | florecer | 1 |
| 22417 | flojo | 1 |
| 22418 | flojita | 1 |
| 22419 | flexiones | 1 |
| 22420 | flexibilidad | 1 |
| 22421 | flema | 1 |
| 22422 | flecos | 1 |
| 22423 | flechazo | 1 |
| 22424 | flecharla | 1 |
| 22425 | flechadas | 1 |
| 22426 | flechaba | 1 |
| 22427 | flecha | 1 |
| 22428 | flatulento | 1 |
| 22429 | flatulenta | 1 |
| 22430 | flaquear | 1 |
| 22431 | flaqueaban | 1 |
| 22432 | flaqueaba | 1 |
| 22433 | flanco | 1 |
| 22434 | flamencos | 1 |
| 22435 | flamenco | 1 |
| 22436 | flameando | 1 |
| 22437 | flamante | 1 |
| 22438 | fláccidas | 1 |
| 22439 | fisonómico | 1 |
| 22440 | fisonomías | 1 |
| 22441 | fiscalizar | 1 |
| 22442 | firmísima | 1 |
| 22443 | firmando | 1 |
| 22444 | firmamento | 1 |
| 22445 | finito | 1 |
| 22446 | finitas | 1 |
| 22447 | finiquito | 1 |
| 22448 | fingió | 1 |
| 22449 | fingimientos | 1 |
| 22450 | fingidos | 1 |
| 22451 | fingidamente | 1 |
| 22452 | fingida | 1 |
| 22453 | financiero | 1 |
| 22454 | financiera | 1 |
| 22455 | finamente | 1 |
| 22456 | finalizar | 1 |
| 22457 | filtrar | 1 |
| 22458 | filipina | 1 |
| 22459 | filibustero | 1 |
| 22460 | filiación | 1 |
| 22461 | filete | 1 |
| 22462 | filantrópicos | 1 |
| 22463 | filantrópico | 1 |
| 22464 | filantrópicas | 1 |
| 22465 | filantrópica | 1 |
| 22466 | filantropía | 1 |
| 22467 | fije | 1 |
| 22468 | fijáronse | 1 |
| 22469 | fijarlas | 1 |
| 22470 | fijaría | 1 |
| 22471 | fijan | 1 |
| 22472 | fijados | 1 |
| 22473 | figurose | 1 |
| 22474 | figurones | 1 |
| 22475 | figuró | 1 |
| 22476 | figuritas | 1 |
| 22477 | figurita | 1 |
| 22478 | figúrenselo | 1 |
| 22479 | figúrense | 1 |
| 22480 | figuremos | 1 |
| 22481 | figurémonos | 1 |
| 22482 | figuré | 1 |
| 22483 | figure | 1 |
| 22484 | figurarme | 1 |
| 22485 | figuraran | 1 |
| 22486 | figuraciones | 1 |
| 22487 | figuerola | 1 |
| 22488 | fíese | 1 |
| 22489 | fíes | 1 |
| 22490 | fierro | 1 |
| 22491 | fieros | 1 |
| 22492 | fierezas | 1 |
| 22493 | fierecilla | 1 |
| 22494 | fielmente | 1 |
| 22495 | fidelidades | 1 |
| 22496 | fidedignas | 1 |
| 22497 | ficciones | 1 |
| 22498 | fibras | 1 |
| 22499 | fíate | 1 |
| 22500 | fiasco | 1 |
| 22501 | fiara | 1 |
| 22502 | fiambrera | 1 |
| 22503 | fiado | 1 |
| 22504 | fiaba | 1 |
| 22505 | feúcha | 1 |
| 22506 | fétido | 1 |
| 22507 | fétidas | 1 |
| 22508 | fetiches | 1 |
| 22509 | festoneados | 1 |
| 22510 | festiva | 1 |
| 22511 | fervorosa | 1 |
| 22512 | fervientes | 1 |
| 22513 | férula | 1 |
| 22514 | fértil | 1 |
| 22515 | ferruje | 1 |
| 22516 | ferrocarril | 1 |
| 22517 | ferretero | 1 |
| 22518 | ferretería | 1 |
| 22519 | ferretera | 1 |
| 22520 | ferocidades | 1 |
| 22521 | feroces | 1 |
| 22522 | fernán | 1 |
| 22523 | fermentaron | 1 |
| 22524 | fermentando | 1 |
| 22525 | fermentados | 1 |
| 22526 | fermenta | 1 |
| 22527 | feotes | 1 |
| 22528 | feona | 1 |
| 22529 | feón | 1 |
| 22530 | fénico | 1 |
| 22531 | fenicias | 1 |
| 22532 | femeninas | 1 |
| 22533 | femenina | 1 |
| 22534 | femenil | 1 |
| 22535 | felpudos | 1 |
| 22536 | felpilla | 1 |
| 22537 | felpa | 1 |
| 22538 | felicito | 1 |
| 22539 | felicíteme | 1 |
| 22540 | felicitaron | 1 |
| 22541 | felicitándose | 1 |
| 22542 | felicidades | 1 |
| 22543 | feíto | 1 |
| 22544 | feísimo | 1 |
| 22545 | fedro | 1 |
| 22546 | fecundísimo | 1 |
| 22547 | fecunda | 1 |
| 22548 | feculentos | 1 |
| 22549 | fechadura | 1 |
| 22550 | featón | 1 |
| 22551 | favoreciéndoles | 1 |
| 22552 | favoreciendo | 1 |
| 22553 | favorecidos | 1 |
| 22554 | favorecían | 1 |
| 22555 | favorecen | 1 |
| 22556 | favorablemente | 1 |
| 22557 | fauces | 1 |
| 22558 | fatuo | 1 |
| 22559 | fatua | 1 |
| 22560 | fatigas | 1 |
| 22561 | fatigándose | 1 |
| 22562 | fatigando | 1 |
| 22563 | fatigadísimo | 1 |
| 22564 | fatigaba | 1 |
| 22565 | fatídicas | 1 |
| 22566 | fatídica | 1 |
| 22567 | fatales | 1 |
| 22568 | fastidioso | 1 |
| 22569 | fastidiosa | 1 |
| 22570 | fastídiese | 1 |
| 22571 | fastidien | 1 |
| 22572 | fastidie | 1 |
| 22573 | fastidiar | 1 |
| 22574 | fascinador | 1 |
| 22575 | fascinaban | 1 |
| 22576 | fascinaba | 1 |
| 22577 | farsas | 1 |
| 22578 | farsantuelo | 1 |
| 22579 | farolona | 1 |
| 22580 | fariseos | 1 |
| 22581 | farfantonas | 1 |
| 22582 | farfantona | 1 |
| 22583 | fare | 1 |
| 22584 | fantásticas | 1 |
| 22585 | fantásticamente | 1 |
| 22586 | fantástica | 1 |
| 22587 | fantasmonas | 1 |
| 22588 | fantasmón | 1 |
| 22589 | fantasmas | 1 |
| 22590 | fantasmagórica | 1 |
| 22591 | fantasmagorías | 1 |
| 22592 | fantasiar | 1 |
| 22593 | fanfarronería | 1 |
| 22594 | fanegas | 1 |
| 22595 | fandangos | 1 |
| 22596 | fandango | 1 |
| 22597 | fanáticos | 1 |
| 22598 | fanático | 1 |
| 22599 | fanática | 1 |
| 22600 | famosas | 1 |
| 22601 | familiona | 1 |
| 22602 | familión | 1 |
| 22603 | familiarizarse | 1 |
| 22604 | familiarizaran | 1 |
| 22605 | familiarizara | 1 |
| 22606 | familiarizado | 1 |
| 22607 | familiarizadas | 1 |
| 22608 | familiaridades | 1 |
| 22609 | famélicas | 1 |
| 22610 | faltoncito | 1 |
| 22611 | faltón | 1 |
| 22612 | faltes | 1 |
| 22613 | faltase | 1 |
| 22614 | faltaron | 1 |
| 22615 | faltarnos | 1 |
| 22616 | faltaría | 1 |
| 22617 | faltarás | 1 |
| 22618 | faltan | 1 |
| 22619 | falsísimo | 1 |
| 22620 | falsificadas | 1 |
| 22621 | falsificada | 1 |
| 22622 | falsificación | 1 |
| 22623 | falsedad | 1 |
| 22624 | falseamiento | 1 |
| 22625 | falsarias | 1 |
| 22626 | fallecido | 1 |
| 22627 | falle | 1 |
| 22628 | falla | 1 |
| 22629 | faldón | 1 |
| 22630 | fajita | 1 |
| 22631 | fajas | 1 |
| 22632 | fajarlo | 1 |
| 22633 | fajado | 1 |
| 22634 | facto | 1 |
| 22635 | facilitaran | 1 |
| 22636 | facilitan | 1 |
| 22637 | facilita | 1 |
| 22638 | fachas | 1 |
| 22639 | fachadas | 1 |
| 22640 | faccioso | 1 |
| 22641 | fabulosos | 1 |
| 22642 | fabricar | 1 |
| 22643 | fabrican | 1 |
| 22644 | fa | 1 |
| 22645 | ezquerdo | 1 |
| 22646 | eylau | 1 |
| 22647 | exuberante | 1 |
| 22648 | extremando | 1 |
| 22649 | extremaba | 1 |
| 22650 | extrema | 1 |
| 22651 | extrayendo | 1 |
| 22652 | extraviarse | 1 |
| 22653 | extravían | 1 |
| 22654 | extraviadas | 1 |
| 22655 | extraordinarios | 1 |
| 22656 | extraordinarias | 1 |
| 22657 | extrañó | 1 |
| 22658 | extrañísima | 1 |
| 22659 | extrañe | 1 |
| 22660 | extrañase | 1 |
| 22661 | extrañará | 1 |
| 22662 | extrañando | 1 |
| 22663 | extranjis | 1 |
| 22664 | extranjerote | 1 |
| 22665 | extranjerizado | 1 |
| 22666 | extranjerismo | 1 |
| 22667 | extraído | 1 |
| 22668 | extraía | 1 |
| 22669 | extraerle | 1 |
| 22670 | extraer | 1 |
| 22671 | extractor | 1 |
| 22672 | extracción | 1 |
| 22673 | extra | 1 |
| 22674 | extirpación | 1 |
| 22675 | extinguirse | 1 |
| 22676 | extinguieran | 1 |
| 22677 | extinguido | 1 |
| 22678 | extinguía | 1 |
| 22679 | exterminios | 1 |
| 22680 | exterminio | 1 |
| 22681 | exteriorizarse | 1 |
| 22682 | exteriores | 1 |
| 22683 | extenuación | 1 |
| 22684 | extensiones | 1 |
| 22685 | extendiéndose | 1 |
| 22686 | extendían | 1 |
| 22687 | extenderlas | 1 |
| 22688 | extáticos | 1 |
| 22689 | exquisitas | 1 |
| 22690 | expusiera | 1 |
| 22691 | expurgación | 1 |
| 22692 | expulsarla | 1 |
| 22693 | expulsados | 1 |
| 22694 | expulsadas | 1 |
| 22695 | expugnador | 1 |
| 22696 | exprimidas | 1 |
| 22697 | express | 1 |
| 22698 | expreso | 1 |
| 22699 | expresivas | 1 |
| 22700 | expresase | 1 |
| 22701 | expresarlo | 1 |
| 22702 | expresarle | 1 |
| 22703 | expresarlas | 1 |
| 22704 | expresándole | 1 |
| 22705 | expresábase | 1 |
| 22706 | expresaban | 1 |
| 22707 | expositor | 1 |
| 22708 | exposiciones | 1 |
| 22709 | exposición | 1 |
| 22710 | exponían | 1 |
| 22711 | expondré | 1 |
| 22712 | explotarse | 1 |
| 22713 | explotados | 1 |
| 22714 | exploró | 1 |
| 22715 | explore | 1 |
| 22716 | exploraba | 1 |
| 22717 | explíquese | 1 |
| 22718 | expliquen | 1 |
| 22719 | explícito | 1 |
| 22720 | explícitamente | 1 |
| 22721 | explicas | 1 |
| 22722 | explicártelo | 1 |
| 22723 | explicaran | 1 |
| 22724 | explicado | 1 |
| 22725 | explaye | 1 |
| 22726 | explayándose | 1 |
| 22727 | explanó | 1 |
| 22728 | expiró | 1 |
| 22729 | expiraron | 1 |
| 22730 | expirar | 1 |
| 22731 | expirantes | 1 |
| 22732 | expiraban | 1 |
| 22733 | expiar | 1 |
| 22734 | expiad | 1 |
| 22735 | expertos | 1 |
| 22736 | expertísimo | 1 |
| 22737 | expertas | 1 |
| 22738 | experimentos | 1 |
| 22739 | experimentó | 1 |
| 22740 | experimento | 1 |
| 22741 | experimentando | 1 |
| 22742 | experimentales | 1 |
| 22743 | experimentada | 1 |
| 22744 | expensas | 1 |
| 22745 | expenden | 1 |
| 22746 | expediente | 1 |
| 22747 | expansivo | 1 |
| 22748 | expansión | 1 |
| 22749 | exóticas | 1 |
| 22750 | exordio | 1 |
| 22751 | exitazo | 1 |
| 22752 | existirá | 1 |
| 22753 | existieran | 1 |
| 22754 | existan | 1 |
| 22755 | exista | 1 |
| 22756 | eximios | 1 |
| 22757 | eximio | 1 |
| 22758 | exijo | 1 |
| 22759 | exigüidad | 1 |
| 22760 | exigirle | 1 |
| 22761 | exigían | 1 |
| 22762 | exigí | 1 |
| 22763 | exiges | 1 |
| 22764 | exigente | 1 |
| 22765 | exigen | 1 |
| 22766 | exhortaba | 1 |
| 22767 | exhibir | 1 |
| 22768 | exhibición | 1 |
| 22769 | exhibe | 1 |
| 22770 | exhausta | 1 |
| 22771 | exhalar | 1 |
| 22772 | exhalaba | 1 |
| 22773 | exenta | 1 |
| 22774 | execrables | 1 |
| 22775 | execrable | 1 |
| 22776 | excusó | 1 |
| 22777 | excusaba | 1 |
| 22778 | excluyó | 1 |
| 22779 | exclusivo | 1 |
| 22780 | exclusiva | 1 |
| 22781 | exclusión | 1 |
| 22782 | excluían | 1 |
| 22783 | exclaustrados | 1 |
| 22784 | exclaustrado | 1 |
| 22785 | excite | 1 |
| 22786 | excitase | 1 |
| 22787 | excitadísimo | 1 |
| 22788 | excitaban | 1 |
| 22789 | excesos | 1 |
| 22790 | excesivamente | 1 |
| 22791 | excepciones | 1 |
| 22792 | excepcionales | 1 |
| 22793 | excepcional | 1 |
| 22794 | excentricidades | 1 |
| 22795 | excéntricas | 1 |
| 22796 | excelsos | 1 |
| 22797 | excelso | 1 |
| 22798 | exasperaba | 1 |
| 22799 | examinemos | 1 |
| 22800 | examine | 1 |
| 22801 | examinase | 1 |
| 22802 | examinarlas | 1 |
| 22803 | examinarla | 1 |
| 22804 | examínalo | 1 |
| 22805 | examínale | 1 |
| 22806 | examinadas | 1 |
| 22807 | examina | 1 |
| 22808 | exaltarse | 1 |
| 22809 | exaltando | 1 |
| 22810 | exaltados | 1 |
| 22811 | exaltadas | 1 |
| 22812 | exaltaba | 1 |
| 22813 | exagerar | 1 |
| 22814 | exagerando | 1 |
| 22815 | exagerada | 1 |
| 22816 | exageraciones | 1 |
| 22817 | exabrupto | 1 |
| 22818 | evocó | 1 |
| 22819 | evocadas | 1 |
| 22820 | evocación | 1 |
| 22821 | eviten | 1 |
| 22822 | evitarlas | 1 |
| 22823 | evitaban | 1 |
| 22824 | eventuales | 1 |
| 22825 | evasivos | 1 |
| 22826 | evasiva | 1 |
| 22827 | evaporado | 1 |
| 22828 | evangelísticos | 1 |
| 22829 | evangelistas | 1 |
| 22830 | evangelios | 1 |
| 22831 | evangélicos | 1 |
| 22832 | evangélico | 1 |
| 22833 | evangélica | 1 |
| 22834 | europeos | 1 |
| 22835 | europeas | 1 |
| 22836 | eugenio | 1 |
| 22837 | éufrates | 1 |
| 22838 | eton | 1 |
| 22839 | etnográfico | 1 |
| 22840 | eternos | 1 |
| 22841 | eternamente | 1 |
| 22842 | etéreo | 1 |
| 22843 | etéreas | 1 |
| 22844 | etalaje | 1 |
| 22845 | estuvimos | 1 |
| 22846 | estuviesen | 1 |
| 22847 | estupores | 1 |
| 22848 | estupideces | 1 |
| 22849 | estupendos | 1 |
| 22850 | estupendo | 1 |
| 22851 | estudiosos | 1 |
| 22852 | estudias | 1 |
| 22853 | estudiarle | 1 |
| 22854 | estudiaré | 1 |
| 22855 | estudiantillo | 1 |
| 22856 | estudiantiles | 1 |
| 22857 | estudiándole | 1 |
| 22858 | estudia | 1 |
| 22859 | estuchitos | 1 |
| 22860 | estuches | 1 |
| 22861 | estucada | 1 |
| 22862 | estrujaron | 1 |
| 22863 | estrujarla | 1 |
| 22864 | estrujar | 1 |
| 22865 | estrujaba | 1 |
| 22866 | estropicio | 1 |
| 22867 | estropearon | 1 |
| 22868 | estropear | 1 |
| 22869 | estropeándose | 1 |
| 22870 | estropeado | 1 |
| 22871 | estropeadísima | 1 |
| 22872 | estropeada | 1 |
| 22873 | estropea | 1 |
| 22874 | estropajosas | 1 |
| 22875 | estropajosa | 1 |
| 22876 | estropajo | 1 |
| 22877 | estrofas | 1 |
| 22878 | estro | 1 |
| 22879 | estrictamente | 1 |
| 22880 | estricta | 1 |
| 22881 | estribación | 1 |
| 22882 | estrepitosa | 1 |
| 22883 | estrenó | 1 |
| 22884 | estrenaríamos | 1 |
| 22885 | estrenaré | 1 |
| 22886 | estrenara | 1 |
| 22887 | estrenado | 1 |
| 22888 | estrenaba | 1 |
| 22889 | estrena | 1 |
| 22890 | estremecerse | 1 |
| 22891 | estremece | 1 |
| 22892 | estrellitas | 1 |
| 22893 | estrellarla | 1 |
| 22894 | estrellándolas | 1 |
| 22895 | estrecharle | 1 |
| 22896 | estrechar | 1 |
| 22897 | estrechándola | 1 |
| 22898 | estrechando | 1 |
| 22899 | estrechaba | 1 |
| 22900 | estraza | 1 |
| 22901 | estratégico | 1 |
| 22902 | estrangulándola | 1 |
| 22903 | estrangulado | 1 |
| 22904 | estrambóticas | 1 |
| 22905 | estrambótica | 1 |
| 22906 | estragados | 1 |
| 22907 | estragado | 1 |
| 22908 | estrafalarios | 1 |
| 22909 | estrabismo | 1 |
| 22910 | estotra | 1 |
| 22911 | estornudos | 1 |
| 22912 | estornudo | 1 |
| 22913 | estorbe | 1 |
| 22914 | estorbarle | 1 |
| 22915 | estorbar | 1 |
| 22916 | estorbaban | 1 |
| 22917 | estómagos | 1 |
| 22918 | estólidos | 1 |
| 22919 | estolidez | 1 |
| 22920 | estoico | 1 |
| 22921 | estoicismo | 1 |
| 22922 | estoica | 1 |
| 22923 | estofados | 1 |
| 22924 | estofadas | 1 |
| 22925 | estofa | 1 |
| 22926 | estocadas | 1 |
| 22927 | estocada | 1 |
| 22928 | estirpes | 1 |
| 22929 | estirpe | 1 |
| 22930 | estirase | 1 |
| 22931 | estirarse | 1 |
| 22932 | estirarlo | 1 |
| 22933 | estiraran | 1 |
| 22934 | estirando | 1 |
| 22935 | estirados | 1 |
| 22936 | estirado | 1 |
| 22937 | estiradas | 1 |
| 22938 | estímulos | 1 |
| 22939 | estimuló | 1 |
| 22940 | estímulo | 1 |
| 22941 | estimulante | 1 |
| 22942 | estimulándole | 1 |
| 22943 | estimulando | 1 |
| 22944 | estimulada | 1 |
| 22945 | estimó | 1 |
| 22946 | estimaran | 1 |
| 22947 | estiman | 1 |
| 22948 | estimados | 1 |
| 22949 | estimada | 1 |
| 22950 | estimaban | 1 |
| 22951 | estilan | 1 |
| 22952 | estila | 1 |
| 22953 | estigma | 1 |
| 22954 | estéticas | 1 |
| 22955 | esternón | 1 |
| 22956 | esterlinas | 1 |
| 22957 | esteritas | 1 |
| 22958 | esterita | 1 |
| 22959 | esteras | 1 |
| 22960 | estera | 1 |
| 22961 | esteparios | 1 |
| 22962 | estepa | 1 |
| 22963 | estentórea | 1 |
| 22964 | estela | 1 |
| 22965 | estaturas | 1 |
| 22966 | estatuas | 1 |
| 22967 | estatuario | 1 |
| 22968 | estático | 1 |
| 22969 | estática | 1 |
| 22970 | estarte | 1 |
| 22971 | estaribel | 1 |
| 22972 | estarcidos | 1 |
| 22973 | estarcido | 1 |
| 22974 | estantigua | 1 |
| 22975 | estantería | 1 |
| 22976 | estanco | 1 |
| 22977 | estancias | 1 |
| 22978 | estampó | 1 |
| 22979 | estampitas | 1 |
| 22980 | estampido | 1 |
| 22981 | estámpelo | 1 |
| 22982 | estampar | 1 |
| 22983 | estampado | 1 |
| 22984 | estampadas | 1 |
| 22985 | estampaba | 1 |
| 22986 | estalló | 1 |
| 22987 | estallo | 1 |
| 22988 | estalle | 1 |
| 22989 | estallase | 1 |
| 22990 | estafetas | 1 |
| 22991 | estafase | 1 |
| 22992 | estafarles | 1 |
| 22993 | estafar | 1 |
| 22994 | estafamos | 1 |
| 22995 | estadística | 1 |
| 22996 | establezcamos | 1 |
| 22997 | estableciendo | 1 |
| 22998 | establecidos | 1 |
| 22999 | establecía | 1 |
| 23000 | establecerme | 1 |
| 23001 | establecen | 1 |
| 23002 | estable | 1 |
| 23003 | estábase | 1 |
| 23004 | estábanlo | 1 |
| 23005 | esquivaba | 1 |
| 23006 | esquinazo | 1 |
| 23007 | esquilón | 1 |
| 23008 | esquelitas | 1 |
| 23009 | esqueletos | 1 |
| 23010 | esquelas | 1 |
| 23011 | espumas | 1 |
| 23012 | espuerta | 1 |
| 23013 | espuelas | 1 |
| 23014 | esprit | 1 |
| 23015 | espotrique | 1 |
| 23016 | espotricarás | 1 |
| 23017 | espotrica | 1 |
| 23018 | esposas | 1 |
| 23019 | espontáneas | 1 |
| 23020 | espontanearse | 1 |
| 23021 | espontáneamente | 1 |
| 23022 | espolvoreada | 1 |
| 23023 | esplines | 1 |
| 23024 | esplinado | 1 |
| 23025 | esplendor | 1 |
| 23026 | esplendidez | 1 |
| 23027 | espléndidas | 1 |
| 23028 | espléndidamente | 1 |
| 23029 | espirituosa | 1 |
| 23030 | espiritualizar | 1 |
| 23031 | espiritualista | 1 |
| 23032 | espiritualidad | 1 |
| 23033 | espiritista | 1 |
| 23034 | espinoso | 1 |
| 23035 | espigadita | 1 |
| 23036 | espichamos | 1 |
| 23037 | espichaba | 1 |
| 23038 | espich | 1 |
| 23039 | espías | 1 |
| 23040 | espiaba | 1 |
| 23041 | espetó | 1 |
| 23042 | espetarle | 1 |
| 23043 | espetaría | 1 |
| 23044 | espetando | 1 |
| 23045 | espetaba | 1 |
| 23046 | espeta | 1 |
| 23047 | espesos | 1 |
| 23048 | espesas | 1 |
| 23049 | espérese | 1 |
| 23050 | esperes | 1 |
| 23051 | esperarme | 1 |
| 23052 | esperarían | 1 |
| 23053 | esperándole | 1 |
| 23054 | esperándola | 1 |
| 23055 | esperamos | 1 |
| 23056 | esperado | 1 |
| 23057 | esperabas | 1 |
| 23058 | espeluznante | 1 |
| 23059 | espejuelos | 1 |
| 23060 | especulativas | 1 |
| 23061 | especulación | 1 |
| 23062 | espectador | 1 |
| 23063 | específicos | 1 |
| 23064 | especies | 1 |
| 23065 | espátula | 1 |
| 23066 | espatarrados | 1 |
| 23067 | espasmos | 1 |
| 23068 | espasmo | 1 |
| 23069 | espárragos | 1 |
| 23070 | esparcimientos | 1 |
| 23071 | esparcidos | 1 |
| 23072 | españolizada | 1 |
| 23073 | españita | 1 |
| 23074 | espante | 1 |
| 23075 | espantas | 1 |
| 23076 | espantarlo | 1 |
| 23077 | espantara | 1 |
| 23078 | espantar | 1 |
| 23079 | espantan | 1 |
| 23080 | espantajos | 1 |
| 23081 | espantadas | 1 |
| 23082 | espaldilla | 1 |
| 23083 | espaldarazo | 1 |
| 23084 | espaciosísima | 1 |
| 23085 | espació | 1 |
| 23086 | espachurrar | 1 |
| 23087 | esmeró | 1 |
| 23088 | esmerándose | 1 |
| 23089 | esmeradísimos | 1 |
| 23090 | esmerada | 1 |
| 23091 | esmeraba | 1 |
| 23092 | esmaltadas | 1 |
| 23093 | eslabonaba | 1 |
| 23094 | esgrimió | 1 |
| 23095 | esgrimiéndola | 1 |
| 23096 | esforzarte | 1 |
| 23097 | esforzábase | 1 |
| 23098 | esferas | 1 |
| 23099 | esfera | 1 |
| 23100 | eserina | 1 |
| 23101 | esencialísimo | 1 |
| 23102 | escurro | 1 |
| 23103 | escurriendo | 1 |
| 23104 | escurridiza | 1 |
| 23105 | escurrían | 1 |
| 23106 | escurrí | 1 |
| 23107 | escurren | 1 |
| 23108 | escupiría | 1 |
| 23109 | escupiera | 1 |
| 23110 | escupidera | 1 |
| 23111 | escupe | 1 |
| 23112 | escultor | 1 |
| 23113 | esculapio | 1 |
| 23114 | escuezan | 1 |
| 23115 | escuetos | 1 |
| 23116 | escueta | 1 |
| 23117 | escuerzo | 1 |
| 23118 | escuecen | 1 |
| 23119 | escudriñar | 1 |
| 23120 | escudriñando | 1 |
| 23121 | escudriñadoras | 1 |
| 23122 | escudriñaba | 1 |
| 23123 | escudito | 1 |
| 23124 | escudilla | 1 |
| 23125 | escudero | 1 |
| 23126 | escuchó | 1 |
| 23127 | escuchara | 1 |
| 23128 | escuchado | 1 |
| 23129 | escualidez | 1 |
| 23130 | escuálida | 1 |
| 23131 | escuadrones | 1 |
| 23132 | escrutinios | 1 |
| 23133 | escrutinio | 1 |
| 23134 | escrutadora | 1 |
| 23135 | escrutador | 1 |
| 23136 | escrupulosa | 1 |
| 23137 | escritas | 1 |
| 23138 | escribirse | 1 |
| 23139 | escribiré | 1 |
| 23140 | escribirás | 1 |
| 23141 | escribiera | 1 |
| 23142 | escribiente | 1 |
| 23143 | escribiéndole | 1 |
| 23144 | escribidores | 1 |
| 23145 | escribida | 1 |
| 23146 | escriben | 1 |
| 23147 | escríbele | 1 |
| 23148 | escriba | 1 |
| 23149 | escozorcillo | 1 |
| 23150 | escorzos | 1 |
| 23151 | escoplos | 1 |
| 23152 | escopetilla | 1 |
| 23153 | escopeta | 1 |
| 23154 | escondo | 1 |
| 23155 | escondites | 1 |
| 23156 | escondidísimo | 1 |
| 23157 | escondían | 1 |
| 23158 | escondí | 1 |
| 23159 | esconderse | 1 |
| 23160 | esconderme | 1 |
| 23161 | escondería | 1 |
| 23162 | esconderé | 1 |
| 23163 | escóndelo | 1 |
| 23164 | escomienzo | 1 |
| 23165 | escoltaron | 1 |
| 23166 | escoltando | 1 |
| 23167 | escoltado | 1 |
| 23168 | escoltadas | 1 |
| 23169 | escoltada | 1 |
| 23170 | escollos | 1 |
| 23171 | escolásticos | 1 |
| 23172 | escolar | 1 |
| 23173 | escogidos | 1 |
| 23174 | escogido | 1 |
| 23175 | escogidas | 1 |
| 23176 | escogida | 1 |
| 23177 | escoge | 1 |
| 23178 | escocias | 1 |
| 23179 | escocía | 1 |
| 23180 | escocer | 1 |
| 23181 | escobones | 1 |
| 23182 | esclavos | 1 |
| 23183 | esclavizarles | 1 |
| 23184 | esclavizar | 1 |
| 23185 | esclavitudes | 1 |
| 23186 | esclarecerla | 1 |
| 23187 | escépticos | 1 |
| 23188 | escéptico | 1 |
| 23189 | escenita | 1 |
| 23190 | escénico | 1 |
| 23191 | escaseces | 1 |
| 23192 | escasean | 1 |
| 23193 | escaseaban | 1 |
| 23194 | escasas | 1 |
| 23195 | escarnecida | 1 |
| 23196 | escarnecía | 1 |
| 23197 | escarmientos | 1 |
| 23198 | escarmiente | 1 |
| 23199 | escarmentar | 1 |
| 23200 | escarmentada | 1 |
| 23201 | escarlatina | 1 |
| 23202 | escarbando | 1 |
| 23203 | escarbaba | 1 |
| 23204 | escaray | 1 |
| 23205 | escapose | 1 |
| 23206 | escapo | 1 |
| 23207 | escapes | 1 |
| 23208 | escapé | 1 |
| 23209 | escapase | 1 |
| 23210 | escaparte | 1 |
| 23211 | escapárseme | 1 |
| 23212 | escaparse | 1 |
| 23213 | escaparon | 1 |
| 23214 | escapadas | 1 |
| 23215 | escapada | 1 |
| 23216 | escaños | 1 |
| 23217 | escandalosas | 1 |
| 23218 | escandalizan | 1 |
| 23219 | escanciaba | 1 |
| 23220 | escamoteos | 1 |
| 23221 | escamotees | 1 |
| 23222 | escamoteadas | 1 |
| 23223 | escamosa | 1 |
| 23224 | escamonea | 1 |
| 23225 | escamón | 1 |
| 23226 | escamo | 1 |
| 23227 | escamas | 1 |
| 23228 | escamarse | 1 |
| 23229 | escamaba | 1 |
| 23230 | escalonada | 1 |
| 23231 | escalo | 1 |
| 23232 | escaldado | 1 |
| 23233 | escalas | 1 |
| 23234 | escalafón | 1 |
| 23235 | escabullo | 1 |
| 23236 | escabullirse | 1 |
| 23237 | escabecharnos | 1 |
| 23238 | escabecharla | 1 |
| 23239 | escabechadas | 1 |
| 23240 | esbozarse | 1 |
| 23241 | esbelto | 1 |
| 23242 | esbeltísimo | 1 |
| 23243 | esbeltas | 1 |
| 23244 | ésa | 1 |
| 23245 | eruditos | 1 |
| 23246 | erres | 1 |
| 23247 | eroísma | 1 |
| 23248 | erizado | 1 |
| 23249 | erizaba | 1 |
| 23250 | erigido | 1 |
| 23251 | erguía | 1 |
| 23252 | erección | 1 |
| 23253 | érase | 1 |
| 23254 | érales | 1 |
| 23255 | equivoqué | 1 |
| 23256 | equivoque | 1 |
| 23257 | equívocos | 1 |
| 23258 | equivocas | 1 |
| 23259 | equivocarme | 1 |
| 23260 | equivocaría | 1 |
| 23261 | equivocan | 1 |
| 23262 | equivocamos | 1 |
| 23263 | equivoca | 1 |
| 23264 | equipos | 1 |
| 23265 | equipo | 1 |
| 23266 | equipajes | 1 |
| 23267 | equilibrarás | 1 |
| 23268 | equilibradas | 1 |
| 23269 | equilibraban | 1 |
| 23270 | equi | 1 |
| 23271 | epopeyas | 1 |
| 23272 | epitafios | 1 |
| 23273 | episodios | 1 |
| 23274 | epilépticos | 1 |
| 23275 | epilépticas | 1 |
| 23276 | epígrafe | 1 |
| 23277 | epidérmicas | 1 |
| 23278 | epaminondas | 1 |
| 23279 | enzarzó | 1 |
| 23280 | enzarzaran | 1 |
| 23281 | enzarzados | 1 |
| 23282 | enzarzado | 1 |
| 23283 | enzarzaban | 1 |
| 23284 | envuelven | 1 |
| 23285 | envuelve | 1 |
| 23286 | envuelvas | 1 |
| 23287 | envueltitos | 1 |
| 23288 | envueltas | 1 |
| 23289 | envolvíase | 1 |
| 23290 | envolverlos | 1 |
| 23291 | enviudé | 1 |
| 23292 | enviudaste | 1 |
| 23293 | enviole | 1 |
| 23294 | envilecen | 1 |
| 23295 | envidioso | 1 |
| 23296 | envidiarían | 1 |
| 23297 | envidiado | 1 |
| 23298 | envidiada | 1 |
| 23299 | enviciados | 1 |
| 23300 | enviciadas | 1 |
| 23301 | enviarle | 1 |
| 23302 | enviaré | 1 |
| 23303 | enviar | 1 |
| 23304 | enviado | 1 |
| 23305 | envenene | 1 |
| 23306 | envenenas | 1 |
| 23307 | envenenarse | 1 |
| 23308 | envenenara | 1 |
| 23309 | envenenado | 1 |
| 23310 | envenenada | 1 |
| 23311 | envenena | 1 |
| 23312 | envejecidas | 1 |
| 23313 | envejecida | 1 |
| 23314 | envejecer | 1 |
| 23315 | envejece | 1 |
| 23316 | envalentonaban | 1 |
| 23317 | envainó | 1 |
| 23318 | entusiasmó | 1 |
| 23319 | entusiasmes | 1 |
| 23320 | entusiasmas | 1 |
| 23321 | entusiasmándose | 1 |
| 23322 | entusiasman | 1 |
| 23323 | entusiasmaban | 1 |
| 23324 | enturbiando | 1 |
| 23325 | entrometimiento | 1 |
| 23326 | entrometidos | 1 |
| 23327 | entrometidas | 1 |
| 23328 | entrometerse | 1 |
| 23329 | entristeciendo | 1 |
| 23330 | entristecían | 1 |
| 23331 | entristecía | 1 |
| 23332 | entreviendo | 1 |
| 23333 | entrevía | 1 |
| 23334 | entreverando | 1 |
| 23335 | entrevé | 1 |
| 23336 | entretenle | 1 |
| 23337 | entretenimiento | 1 |
| 23338 | entretenidos | 1 |
| 23339 | entretenga | 1 |
| 23340 | entretendría | 1 |
| 23341 | entresacando | 1 |
| 23342 | entremezcladas | 1 |
| 23343 | entremezclada | 1 |
| 23344 | entregues | 1 |
| 23345 | entregue | 1 |
| 23346 | entregárselos | 1 |
| 23347 | entregarme | 1 |
| 23348 | entregarle | 1 |
| 23349 | entregaría | 1 |
| 23350 | entregándoselo | 1 |
| 23351 | entregando | 1 |
| 23352 | entregados | 1 |
| 23353 | entregábase | 1 |
| 23354 | entregábalos | 1 |
| 23355 | entrega | 1 |
| 23356 | entrecortadas | 1 |
| 23357 | entrecortaba | 1 |
| 23358 | entrecanos | 1 |
| 23359 | entreabriendo | 1 |
| 23360 | entreabierta | 1 |
| 23361 | entrarme | 1 |
| 23362 | entrarían | 1 |
| 23363 | entraremos | 1 |
| 23364 | entrañable | 1 |
| 23365 | entrañaba | 1 |
| 23366 | éntranle | 1 |
| 23367 | entramos | 1 |
| 23368 | entrambas | 1 |
| 23369 | entramado | 1 |
| 23370 | entortolarse | 1 |
| 23371 | entorpecimiento | 1 |
| 23372 | entorpecían | 1 |
| 23373 | entorpecerle | 1 |
| 23374 | entorpecería | 1 |
| 23375 | entornados | 1 |
| 23376 | entornadas | 1 |
| 23377 | entornaba | 1 |
| 23378 | entonan | 1 |
| 23379 | entonaban | 1 |
| 23380 | entiesaba | 1 |
| 23381 | entienda | 1 |
| 23382 | entidades | 1 |
| 23383 | enterrasen | 1 |
| 23384 | enterrarle | 1 |
| 23385 | enterneció | 1 |
| 23386 | enternecimiento | 1 |
| 23387 | enterneciéndose | 1 |
| 23388 | enternecerían | 1 |
| 23389 | enterita | 1 |
| 23390 | entérese | 1 |
| 23391 | enteres | 1 |
| 23392 | enteremos | 1 |
| 23393 | enteraste | 1 |
| 23394 | enterasen | 1 |
| 23395 | enteraría | 1 |
| 23396 | enteraré | 1 |
| 23397 | entenebrecidos | 1 |
| 23398 | entendiesen | 1 |
| 23399 | entendieran | 1 |
| 23400 | entendían | 1 |
| 23401 | entendí | 1 |
| 23402 | entenderías | 1 |
| 23403 | entenderé | 1 |
| 23404 | entendedor | 1 |
| 23405 | entendederas | 1 |
| 23406 | entendedera | 1 |
| 23407 | entendamos | 1 |
| 23408 | entendámonos | 1 |
| 23409 | entenada | 1 |
| 23410 | entarimado | 1 |
| 23411 | entablose | 1 |
| 23412 | entablaba | 1 |
| 23413 | ensuciarlo | 1 |
| 23414 | ensuciaré | 1 |
| 23415 | ensucian | 1 |
| 23416 | ensuciados | 1 |
| 23417 | ensuciaba | 1 |
| 23418 | ensordecían | 1 |
| 23419 | ensordecedor | 1 |
| 23420 | ensordece | 1 |
| 23421 | ensoberbecido | 1 |
| 23422 | ensoberbecía | 1 |
| 23423 | ensimisme | 1 |
| 23424 | enseñoreando | 1 |
| 23425 | enseñen | 1 |
| 23426 | enséñemelo | 1 |
| 23427 | enseñé | 1 |
| 23428 | enseñe | 1 |
| 23429 | enseñas | 1 |
| 23430 | enseñarte | 1 |
| 23431 | enseñárselo | 1 |
| 23432 | enseñarme | 1 |
| 23433 | enseñarles | 1 |
| 23434 | enseñará | 1 |
| 23435 | enseñándosela | 1 |
| 23436 | enseñándome | 1 |
| 23437 | enseñándole | 1 |
| 23438 | enseñándola | 1 |
| 23439 | enséñame | 1 |
| 23440 | enséñale | 1 |
| 23441 | enseñabas | 1 |
| 23442 | enseñaban | 1 |
| 23443 | ensartadas | 1 |
| 23444 | ensarriá | 1 |
| 23445 | ensañas | 1 |
| 23446 | ensangrentados | 1 |
| 23447 | ensalzaron | 1 |
| 23448 | ensalza | 1 |
| 23449 | enroscado | 1 |
| 23450 | enroscada | 1 |
| 23451 | enroscaba | 1 |
| 23452 | enronquecido | 1 |
| 23453 | enrojecidos | 1 |
| 23454 | enrojecidas | 1 |
| 23455 | enriquecido | 1 |
| 23456 | enriquecer | 1 |
| 23457 | enrevesado | 1 |
| 23458 | enrevesadas | 1 |
| 23459 | enrevesada | 1 |
| 23460 | enrejados | 1 |
| 23461 | enrejado | 1 |
| 23462 | enrejadas | 1 |
| 23463 | enrejada | 1 |
| 23464 | enredarse | 1 |
| 23465 | enredarme | 1 |
| 23466 | enredadora | 1 |
| 23467 | enredado | 1 |
| 23468 | enredada | 1 |
| 23469 | enredaban | 1 |
| 23470 | enreda | 1 |
| 23471 | enranciaran | 1 |
| 23472 | enramada | 1 |
| 23473 | enramaban | 1 |
| 23474 | enojó | 1 |
| 23475 | enojado | 1 |
| 23476 | enojábanla | 1 |
| 23477 | enojaba | 1 |
| 23478 | ennobleciendo | 1 |
| 23479 | ennoblecerse | 1 |
| 23480 | ennegrecido | 1 |
| 23481 | enmudecía | 1 |
| 23482 | enmudecer | 1 |
| 23483 | enmohecidas | 1 |
| 23484 | enmiendes | 1 |
| 23485 | enmendarse | 1 |
| 23486 | enmendar | 1 |
| 23487 | enmendada | 1 |
| 23488 | enmascarando | 1 |
| 23489 | enluto | 1 |
| 23490 | enlutados | 1 |
| 23491 | enloquecía | 1 |
| 23492 | enloquecerme | 1 |
| 23493 | enloquecer | 1 |
| 23494 | enlazan | 1 |
| 23495 | enlazados | 1 |
| 23496 | enlazadas | 1 |
| 23497 | enjuto | 1 |
| 23498 | enjutísimas | 1 |
| 23499 | enjugando | 1 |
| 23500 | enjaretarle | 1 |
| 23501 | enjabonáronle | 1 |
| 23502 | enigmas | 1 |
| 23503 | engullir | 1 |
| 23504 | engrosando | 1 |
| 23505 | engrosaba | 1 |
| 23506 | engrasado | 1 |
| 23507 | engrandecerte | 1 |
| 23508 | engranaje | 1 |
| 23509 | engorden | 1 |
| 23510 | engordas | 1 |
| 23511 | engomado | 1 |
| 23512 | engolosinaron | 1 |
| 23513 | engolosina | 1 |
| 23514 | engolfó | 1 |
| 23515 | engolfada | 1 |
| 23516 | engendros | 1 |
| 23517 | engendrar | 1 |
| 23518 | engendra | 1 |
| 23519 | engatusas | 1 |
| 23520 | engatusar | 1 |
| 23521 | engatusando | 1 |
| 23522 | engatusa | 1 |
| 23523 | engastado | 1 |
| 23524 | engarzada | 1 |
| 23525 | engarza | 1 |
| 23526 | engarnos | 1 |
| 23527 | engarfiñaron | 1 |
| 23528 | engañosa | 1 |
| 23529 | engañen | 1 |
| 23530 | engañe | 1 |
| 23531 | engañase | 1 |
| 23532 | engañarse | 1 |
| 23533 | engañarás | 1 |
| 23534 | engañara | 1 |
| 23535 | engañamos | 1 |
| 23536 | engañadores | 1 |
| 23537 | engañábase | 1 |
| 23538 | enganchadas | 1 |
| 23539 | engancha | 1 |
| 23540 | engalanó | 1 |
| 23541 | engalanarse | 1 |
| 23542 | enfurruñas | 1 |
| 23543 | enfurruñados | 1 |
| 23544 | enfurruñado | 1 |
| 23545 | enfureció | 1 |
| 23546 | enfureciendo | 1 |
| 23547 | enfurecía | 1 |
| 23548 | enfriase | 1 |
| 23549 | enfriarás | 1 |
| 23550 | enfriaran | 1 |
| 23551 | enfriara | 1 |
| 23552 | enfriar | 1 |
| 23553 | enfrenada | 1 |
| 23554 | enfrenaba | 1 |
| 23555 | enfrascaron | 1 |
| 23556 | enflaquecido | 1 |
| 23557 | enfermó | 1 |
| 23558 | enfermizo | 1 |
| 23559 | enfermera | 1 |
| 23560 | enfermara | 1 |
| 23561 | enfáticos | 1 |
| 23562 | enfáticas | 1 |
| 23563 | enfadosas | 1 |
| 23564 | enfadé | 1 |
| 23565 | enfade | 1 |
| 23566 | enfadarías | 1 |
| 23567 | enfadaré | 1 |
| 23568 | enfadará | 1 |
| 23569 | enfadan | 1 |
| 23570 | enfadadito | 1 |
| 23571 | enérgicas | 1 |
| 23572 | enérgicamente | 1 |
| 23573 | enemistad | 1 |
| 23574 | endurecimiento | 1 |
| 23575 | endurecidos | 1 |
| 23576 | endurecida | 1 |
| 23577 | endurecía | 1 |
| 23578 | endulzó | 1 |
| 23579 | endulzara | 1 |
| 23580 | endividos | 1 |
| 23581 | endiñarles | 1 |
| 23582 | endilgarle | 1 |
| 23583 | endiablo | 1 |
| 23584 | endiablados | 1 |
| 23585 | endiablado | 1 |
| 23586 | enderezó | 1 |
| 23587 | enderezarse | 1 |
| 23588 | enderezarán | 1 |
| 23589 | enderezaran | 1 |
| 23590 | enderezado | 1 |
| 23591 | enderezaba | 1 |
| 23592 | endemoniados | 1 |
| 23593 | encuentros | 1 |
| 23594 | encubra | 1 |
| 23595 | encorvarse | 1 |
| 23596 | encopetadas | 1 |
| 23597 | encopetada | 1 |
| 23598 | encontronazos | 1 |
| 23599 | encontrolo | 1 |
| 23600 | encontrole | 1 |
| 23601 | encontrola | 1 |
| 23602 | encontrémela | 1 |
| 23603 | encontrarte | 1 |
| 23604 | encontrársele | 1 |
| 23605 | encontrarme | 1 |
| 23606 | encontrarlos | 1 |
| 23607 | encontrarlo | 1 |
| 23608 | encontrarían | 1 |
| 23609 | encontraremos | 1 |
| 23610 | encontraré | 1 |
| 23611 | encontrábase | 1 |
| 23612 | enconos | 1 |
| 23613 | encomienda | 1 |
| 23614 | encomiástico | 1 |
| 23615 | encomiando | 1 |
| 23616 | encomendole | 1 |
| 23617 | encomendarse | 1 |
| 23618 | encomendaba | 1 |
| 23619 | encolerizado | 1 |
| 23620 | encogimientos | 1 |
| 23621 | encogido | 1 |
| 23622 | encogida | 1 |
| 23623 | encogerlo | 1 |
| 23624 | enclenque | 1 |
| 23625 | encintado | 1 |
| 23626 | encinta | 1 |
| 23627 | encierran | 1 |
| 23628 | enciende | 1 |
| 23629 | encienda | 1 |
| 23630 | enciclopédica | 1 |
| 23631 | encía | 1 |
| 23632 | encharcadas | 1 |
| 23633 | encharcada | 1 |
| 23634 | encharcad | 1 |
| 23635 | encerrona | 1 |
| 23636 | encerró | 1 |
| 23637 | encerrarla | 1 |
| 23638 | encerrarán | 1 |
| 23639 | encerrándose | 1 |
| 23640 | encerrando | 1 |
| 23641 | encerraban | 1 |
| 23642 | encenegándose | 1 |
| 23643 | encendiera | 1 |
| 23644 | encendiéndolas | 1 |
| 23645 | encenderse | 1 |
| 23646 | encenderlas | 1 |
| 23647 | encendería | 1 |
| 23648 | encenágate | 1 |
| 23649 | encefálico | 1 |
| 23650 | encauzarlo | 1 |
| 23651 | encastilló | 1 |
| 23652 | encasquetarme | 1 |
| 23653 | encasquetan | 1 |
| 23654 | encasquetado | 1 |
| 23655 | encasquetada | 1 |
| 23656 | encasquetaba | 1 |
| 23657 | encarose | 1 |
| 23658 | encarnarse | 1 |
| 23659 | encarnándose | 1 |
| 23660 | encarna | 1 |
| 23661 | encariñarte | 1 |
| 23662 | encariñan | 1 |
| 23663 | encariñada | 1 |
| 23664 | encariñaba | 1 |
| 23665 | encargue | 1 |
| 23666 | encárgate | 1 |
| 23667 | encargase | 1 |
| 23668 | encargarte | 1 |
| 23669 | encargarse | 1 |
| 23670 | encargarle | 1 |
| 23671 | encargaría | 1 |
| 23672 | encargaremos | 1 |
| 23673 | encargaras | 1 |
| 23674 | encargara | 1 |
| 23675 | encargados | 1 |
| 23676 | encargadas | 1 |
| 23677 | encargada | 1 |
| 23678 | encargábase | 1 |
| 23679 | encargaban | 1 |
| 23680 | encareció | 1 |
| 23681 | encarecimientos | 1 |
| 23682 | encarecer | 1 |
| 23683 | encarcelada | 1 |
| 23684 | encaramando | 1 |
| 23685 | encaprichó | 1 |
| 23686 | encapricharte | 1 |
| 23687 | encantando | 1 |
| 23688 | encantan | 1 |
| 23689 | encantados | 1 |
| 23690 | encantadora | 1 |
| 23691 | encantador | 1 |
| 23692 | encanta | 1 |
| 23693 | encanijado | 1 |
| 23694 | encanijada | 1 |
| 23695 | encanecido | 1 |
| 23696 | encanallan | 1 |
| 23697 | encanallamiento | 1 |
| 23698 | encanallado | 1 |
| 23699 | encaminaron | 1 |
| 23700 | encaminarla | 1 |
| 23701 | encamarme | 1 |
| 23702 | encamada | 1 |
| 23703 | encalabrinada | 1 |
| 23704 | encajó | 1 |
| 23705 | encajería | 1 |
| 23706 | encajera | 1 |
| 23707 | encajan | 1 |
| 23708 | encajaba | 1 |
| 23709 | encadenando | 1 |
| 23710 | enardecía | 1 |
| 23711 | enano | 1 |
| 23712 | enanita | 1 |
| 23713 | enamorisca | 1 |
| 23714 | enamoraran | 1 |
| 23715 | enamoramiento | 1 |
| 23716 | enamoradito | 1 |
| 23717 | enamoradas | 1 |
| 23718 | enamora | 1 |
| 23719 | enaltecido | 1 |
| 23720 | enaltecerlo | 1 |
| 23721 | enaltecer | 1 |
| 23722 | enajenación | 1 |
| 23723 | emulsión | 1 |
| 23724 | empujones | 1 |
| 23725 | empujole | 1 |
| 23726 | empujola | 1 |
| 23727 | empujaran | 1 |
| 23728 | empujará | 1 |
| 23729 | empujándose | 1 |
| 23730 | empujando | 1 |
| 23731 | empuja | 1 |
| 23732 | empuerca | 1 |
| 23733 | empresario | 1 |
| 23734 | emprendiera | 1 |
| 23735 | emprendido | 1 |
| 23736 | emprendía | 1 |
| 23737 | emprenderla | 1 |
| 23738 | empozado | 1 |
| 23739 | empolvadas | 1 |
| 23740 | empolva | 1 |
| 23741 | empollar | 1 |
| 23742 | empollándola | 1 |
| 23743 | empobreciesen | 1 |
| 23744 | empobrecida | 1 |
| 23745 | emplomadas | 1 |
| 23746 | empleolo | 1 |
| 23747 | empleíto | 1 |
| 23748 | empleitas | 1 |
| 23749 | empleasen | 1 |
| 23750 | emplearse | 1 |
| 23751 | emplearla | 1 |
| 23752 | empleara | 1 |
| 23753 | empleábale | 1 |
| 23754 | empingorotó | 1 |
| 23755 | empingorotadas | 1 |
| 23756 | empingorotada | 1 |
| 23757 | empinándose | 1 |
| 23758 | empina | 1 |
| 23759 | empieces | 1 |
| 23760 | empezase | 1 |
| 23761 | empezaremos | 1 |
| 23762 | empezaré | 1 |
| 23763 | empezarás | 1 |
| 23764 | empezarán | 1 |
| 23765 | emperifollada | 1 |
| 23766 | emperejilarse | 1 |
| 23767 | emperejilado | 1 |
| 23768 | empequeñecido | 1 |
| 23769 | empeoró | 1 |
| 23770 | empeoraba | 1 |
| 23771 | empeñemos | 1 |
| 23772 | empeñáronse | 1 |
| 23773 | empeñaron | 1 |
| 23774 | empeñarme | 1 |
| 23775 | empeñarás | 1 |
| 23776 | empeñará | 1 |
| 23777 | empeñando | 1 |
| 23778 | empeñadamente | 1 |
| 23779 | empeñábase | 1 |
| 23780 | empenachados | 1 |
| 23781 | empedrados | 1 |
| 23782 | empedernido | 1 |
| 23783 | empedernidas | 1 |
| 23784 | empecemos | 1 |
| 23785 | emparrados | 1 |
| 23786 | emparentada | 1 |
| 23787 | emparejan | 1 |
| 23788 | empaquetados | 1 |
| 23789 | empapelar | 1 |
| 23790 | empapada | 1 |
| 23791 | empañado | 1 |
| 23792 | empalme | 1 |
| 23793 | empalmaste | 1 |
| 23794 | empalmaba | 1 |
| 23795 | empalagosos | 1 |
| 23796 | empalagoso | 1 |
| 23797 | empalagosa | 1 |
| 23798 | emolumentos | 1 |
| 23799 | emoliente | 1 |
| 23800 | emitir | 1 |
| 23801 | emitía | 1 |
| 23802 | emisión | 1 |
| 23803 | eminentemente | 1 |
| 23804 | eminente | 1 |
| 23805 | eminencias | 1 |
| 23806 | emilion | 1 |
| 23807 | emilio | 1 |
| 23808 | emigrar | 1 |
| 23809 | eméticos | 1 |
| 23810 | emético | 1 |
| 23811 | emersión | 1 |
| 23812 | embusteros | 1 |
| 23813 | embusteras | 1 |
| 23814 | embudo | 1 |
| 23815 | embruteció | 1 |
| 23816 | embrutecido | 1 |
| 23817 | embrutecida | 1 |
| 23818 | embrutecía | 1 |
| 23819 | embrutecerse | 1 |
| 23820 | embrionario | 1 |
| 23821 | embriagó | 1 |
| 23822 | embriago | 1 |
| 23823 | embriagarle | 1 |
| 23824 | embriagado | 1 |
| 23825 | embriagada | 1 |
| 23826 | embriagaba | 1 |
| 23827 | embozos | 1 |
| 23828 | embozándose | 1 |
| 23829 | embozadito | 1 |
| 23830 | embotarse | 1 |
| 23831 | emboscada | 1 |
| 23832 | emborrachen | 1 |
| 23833 | emborrachado | 1 |
| 23834 | emborrachaban | 1 |
| 23835 | emboce | 1 |
| 23836 | embobar | 1 |
| 23837 | embobado | 1 |
| 23838 | embiste | 1 |
| 23839 | embetunadas | 1 |
| 23840 | embestirla | 1 |
| 23841 | embestidas | 1 |
| 23842 | embestida | 1 |
| 23843 | embelleciéndose | 1 |
| 23844 | embellecían | 1 |
| 23845 | embellecer | 1 |
| 23846 | embelesarse | 1 |
| 23847 | embelesan | 1 |
| 23848 | embelesado | 1 |
| 23849 | embelesadas | 1 |
| 23850 | embelesada | 1 |
| 23851 | embebecimiento | 1 |
| 23852 | embebecida | 1 |
| 23853 | embebe | 1 |
| 23854 | embaulará | 1 |
| 23855 | embaucara | 1 |
| 23856 | embaucar | 1 |
| 23857 | embaucando | 1 |
| 23858 | embarulló | 1 |
| 23859 | embarullarse | 1 |
| 23860 | embarullar | 1 |
| 23861 | embarullaba | 1 |
| 23862 | embargué | 1 |
| 23863 | embargaron | 1 |
| 23864 | embargaría | 1 |
| 23865 | embargado | 1 |
| 23866 | embarcase | 1 |
| 23867 | embarcaciones | 1 |
| 23868 | embarcación | 1 |
| 23869 | embaldosados | 1 |
| 23870 | embalajes | 1 |
| 23871 | embajador | 1 |
| 23872 | embadurnadas | 1 |
| 23873 | embadurnada | 1 |
| 23874 | emancipaste | 1 |
| 23875 | emanciparse | 1 |
| 23876 | emanciparía | 1 |
| 23877 | emanada | 1 |
| 23878 | emanaciones | 1 |
| 23879 | emanaban | 1 |
| 23880 | eludir | 1 |
| 23881 | elogiaron | 1 |
| 23882 | elogiarle | 1 |
| 23883 | elogiando | 1 |
| 23884 | elogian | 1 |
| 23885 | elle | 1 |
| 23886 | elimine | 1 |
| 23887 | eliminar | 1 |
| 23888 | eliminación | 1 |
| 23889 | eliminaba | 1 |
| 23890 | eligió | 1 |
| 23891 | elige | 1 |
| 23892 | elevado | 1 |
| 23893 | elevación | 1 |
| 23894 | elevaban | 1 |
| 23895 | elevaba | 1 |
| 23896 | elegirte | 1 |
| 23897 | elegantona | 1 |
| 23898 | elegantísimo | 1 |
| 23899 | electriza | 1 |
| 23900 | elduayen | 1 |
| 23901 | elástico | 1 |
| 23902 | elasticidad | 1 |
| 23903 | elástica | 1 |
| 23904 | elaboradas | 1 |
| 23905 | elaboración | 1 |
| 23906 | elaboraba | 1 |
| 23907 | ejido | 1 |
| 23908 | ejerzo | 1 |
| 23909 | ejercitando | 1 |
| 23910 | ejercitaban | 1 |
| 23911 | ejercían | 1 |
| 23912 | ejerce | 1 |
| 23913 | ejecutarla | 1 |
| 23914 | ejecuta | 1 |
| 23915 | egipcios | 1 |
| 23916 | efusiones | 1 |
| 23917 | efeméride | 1 |
| 23918 | efectuó | 1 |
| 23919 | efectuase | 1 |
| 23920 | efectuarse | 1 |
| 23921 | efectivos | 1 |
| 23922 | efectividad | 1 |
| 23923 | eduqué | 1 |
| 23924 | educatrices | 1 |
| 23925 | educativa | 1 |
| 23926 | educarse | 1 |
| 23927 | educarle | 1 |
| 23928 | educarlas | 1 |
| 23929 | educaré | 1 |
| 23930 | educaran | 1 |
| 23931 | educan | 1 |
| 23932 | educados | 1 |
| 23933 | educadito | 1 |
| 23934 | educadas | 1 |
| 23935 | educaba | 1 |
| 23936 | educa | 1 |
| 23937 | edificó | 1 |
| 23938 | edificársenos | 1 |
| 23939 | edificarse | 1 |
| 23940 | edificara | 1 |
| 23941 | edificante | 1 |
| 23942 | edificado | 1 |
| 23943 | edificadas | 1 |
| 23944 | edificaba | 1 |
| 23945 | edecán | 1 |
| 23946 | ecuménico | 1 |
| 23947 | ecónomo | 1 |
| 23948 | economizar | 1 |
| 23949 | economistas | 1 |
| 23950 | economista | 1 |
| 23951 | eclipsó | 1 |
| 23952 | eclipses | 1 |
| 23953 | eclipse | 1 |
| 23954 | eclipsaban | 1 |
| 23955 | echole | 1 |
| 23956 | échenme | 1 |
| 23957 | échenle | 1 |
| 23958 | echen | 1 |
| 23959 | echemos | 1 |
| 23960 | echaste | 1 |
| 23961 | echase | 1 |
| 23962 | echártela | 1 |
| 23963 | echárnosla | 1 |
| 23964 | echarnos | 1 |
| 23965 | echarlos | 1 |
| 23966 | echarlo | 1 |
| 23967 | echarles | 1 |
| 23968 | echarían | 1 |
| 23969 | echaría | 1 |
| 23970 | echarás | 1 |
| 23971 | echará | 1 |
| 23972 | echándotelas | 1 |
| 23973 | echándotela | 1 |
| 23974 | échame | 1 |
| 23975 | echadito | 1 |
| 23976 | echabas | 1 |
| 23977 | echábamos | 1 |
| 23978 | echábalo | 1 |
| 23979 | echábalas | 1 |
| 23980 | ebro | 1 |
| 23981 | durmiese | 1 |
| 23982 | durmiéndola | 1 |
| 23983 | duritos | 1 |
| 23984 | durísima | 1 |
| 23985 | duretes | 1 |
| 23986 | durete | 1 |
| 23987 | duración | 1 |
| 23988 | duraban | 1 |
| 23989 | durábale | 1 |
| 23990 | duques | 1 |
| 23991 | duodécimo | 1 |
| 23992 | dulzuras | 1 |
| 23993 | dulzón | 1 |
| 23994 | dulcísimo | 1 |
| 23995 | dulcificó | 1 |
| 23996 | dulcificarla | 1 |
| 23997 | dulcificando | 1 |
| 23998 | duerman | 1 |
| 23999 | duelos | 1 |
| 24000 | duelo | 1 |
| 24001 | duelitos | 1 |
| 24002 | dudosa | 1 |
| 24003 | duden | 1 |
| 24004 | dude | 1 |
| 24005 | dudara | 1 |
| 24006 | dudan | 1 |
| 24007 | dubitativo | 1 |
| 24008 | dubarry | 1 |
| 24009 | dualismos | 1 |
| 24010 | dromedario | 1 |
| 24011 | droguista | 1 |
| 24012 | drástico | 1 |
| 24013 | dramón | 1 |
| 24014 | dramita | 1 |
| 24015 | dover | 1 |
| 24016 | dotrina | 1 |
| 24017 | dotarle | 1 |
| 24018 | dotada | 1 |
| 24019 | dormitar | 1 |
| 24020 | dormitaban | 1 |
| 24021 | dormitaba | 1 |
| 24022 | dormiste | 1 |
| 24023 | dormirte | 1 |
| 24024 | dormirnos | 1 |
| 24025 | dormirlas | 1 |
| 24026 | dormiría | 1 |
| 24027 | dormiremos | 1 |
| 24028 | dormiré | 1 |
| 24029 | dormilones | 1 |
| 24030 | dormilón | 1 |
| 24031 | dormías | 1 |
| 24032 | dorando | 1 |
| 24033 | dorados | 1 |
| 24034 | doraba | 1 |
| 24035 | donativo | 1 |
| 24036 | dominó | 1 |
| 24037 | domini | 1 |
| 24038 | domingueros | 1 |
| 24039 | domine | 1 |
| 24040 | dominarse | 1 |
| 24041 | dominantes | 1 |
| 24042 | dominan | 1 |
| 24043 | dominado | 1 |
| 24044 | domicilios | 1 |
| 24045 | domiciliarios | 1 |
| 24046 | domestiquen | 1 |
| 24047 | domesticidad | 1 |
| 24048 | domesticaremos | 1 |
| 24049 | domesticar | 1 |
| 24050 | domarle | 1 |
| 24051 | domaríamos | 1 |
| 24052 | domar | 1 |
| 24053 | domado | 1 |
| 24054 | dolorido | 1 |
| 24055 | doloridas | 1 |
| 24056 | doliesen | 1 |
| 24057 | doliese | 1 |
| 24058 | dolieron | 1 |
| 24059 | doliente | 1 |
| 24060 | dolían | 1 |
| 24061 | dolerle | 1 |
| 24062 | dolencia | 1 |
| 24063 | dogal | 1 |
| 24064 | doctrinarios | 1 |
| 24065 | doctrinario | 1 |
| 24066 | doctores | 1 |
| 24067 | doctoral | 1 |
| 24068 | doctora | 1 |
| 24069 | docilota | 1 |
| 24070 | doblones | 1 |
| 24071 | dobloncito | 1 |
| 24072 | dobló | 1 |
| 24073 | doblemos | 1 |
| 24074 | doblegarse | 1 |
| 24075 | doblase | 1 |
| 24076 | doblarlos | 1 |
| 24077 | doblarlo | 1 |
| 24078 | doblados | 1 |
| 24079 | dobladitos | 1 |
| 24080 | dobladillar | 1 |
| 24081 | dobladas | 1 |
| 24082 | dobla | 1 |
| 24083 | do | 1 |
| 24084 | divulgasen | 1 |
| 24085 | divisoria | 1 |
| 24086 | divisara | 1 |
| 24087 | divisar | 1 |
| 24088 | divisado | 1 |
| 24089 | divirtió | 1 |
| 24090 | divirtiera | 1 |
| 24091 | divierto | 1 |
| 24092 | diviertan | 1 |
| 24093 | dividió | 1 |
| 24094 | divididos | 1 |
| 24095 | divididas | 1 |
| 24096 | dividíanse | 1 |
| 24097 | dividendos | 1 |
| 24098 | dividendo | 1 |
| 24099 | dividen | 1 |
| 24100 | divertirte | 1 |
| 24101 | divertirme | 1 |
| 24102 | divertimientos | 1 |
| 24103 | divertidos | 1 |
| 24104 | divertíanla | 1 |
| 24105 | divertí | 1 |
| 24106 | diverso | 1 |
| 24107 | diversiones | 1 |
| 24108 | diversidad | 1 |
| 24109 | diversa | 1 |
| 24110 | diurna | 1 |
| 24111 | diuréticos | 1 |
| 24112 | disuélvase | 1 |
| 24113 | disuelto | 1 |
| 24114 | disuadirle | 1 |
| 24115 | disuadir | 1 |
| 24116 | distritos | 1 |
| 24117 | distribuyendo | 1 |
| 24118 | distribuirse | 1 |
| 24119 | distribuidos | 1 |
| 24120 | distribuido | 1 |
| 24121 | distrayendo | 1 |
| 24122 | distrajeron | 1 |
| 24123 | distrajera | 1 |
| 24124 | distraigo | 1 |
| 24125 | distráiganme | 1 |
| 24126 | distraidita | 1 |
| 24127 | distráete | 1 |
| 24128 | distraerle | 1 |
| 24129 | distraería | 1 |
| 24130 | distraedme | 1 |
| 24131 | distrae | 1 |
| 24132 | disto | 1 |
| 24133 | distinguirle | 1 |
| 24134 | distinguirla | 1 |
| 24135 | distinguieron | 1 |
| 24136 | distinguiéndose | 1 |
| 24137 | distinguí | 1 |
| 24138 | distingue | 1 |
| 24139 | distingos | 1 |
| 24140 | diste | 1 |
| 24141 | distante | 1 |
| 24142 | distaba | 1 |
| 24143 | disputó | 1 |
| 24144 | disputase | 1 |
| 24145 | disputárselo | 1 |
| 24146 | disputaron | 1 |
| 24147 | disputara | 1 |
| 24148 | disputando | 1 |
| 24149 | disputan | 1 |
| 24150 | disputábanse | 1 |
| 24151 | dispuestilla | 1 |
| 24152 | dispuestas | 1 |
| 24153 | disponibles | 1 |
| 24154 | dispersión | 1 |
| 24155 | dispersas | 1 |
| 24156 | dispersado | 1 |
| 24157 | dispersaban | 1 |
| 24158 | dispepsias | 1 |
| 24159 | dispepsia | 1 |
| 24160 | dispensó | 1 |
| 24161 | dispénseme | 1 |
| 24162 | dispensarme | 1 |
| 24163 | dispensará | 1 |
| 24164 | dispensadora | 1 |
| 24165 | disparos | 1 |
| 24166 | disparó | 1 |
| 24167 | disparatar | 1 |
| 24168 | disparatadamente | 1 |
| 24169 | dispararlos | 1 |
| 24170 | disparar | 1 |
| 24171 | disparándole | 1 |
| 24172 | disparan | 1 |
| 24173 | disparaba | 1 |
| 24174 | disolvían | 1 |
| 24175 | disolutos | 1 |
| 24176 | disoluto | 1 |
| 24177 | disoluta | 1 |
| 24178 | disolución | 1 |
| 24179 | disminuye | 1 |
| 24180 | disloquemos | 1 |
| 24181 | dislocará | 1 |
| 24182 | dislocado | 1 |
| 24183 | dislocada | 1 |
| 24184 | disiparan | 1 |
| 24185 | disipará | 1 |
| 24186 | disipar | 1 |
| 24187 | disipación | 1 |
| 24188 | disipaban | 1 |
| 24189 | disinificantes | 1 |
| 24190 | disimulas | 1 |
| 24191 | disimularse | 1 |
| 24192 | disimularlo | 1 |
| 24193 | disimulan | 1 |
| 24194 | disimuladamente | 1 |
| 24195 | disimulada | 1 |
| 24196 | disimula | 1 |
| 24197 | disimilo | 1 |
| 24198 | disgustarla | 1 |
| 24199 | disgustar | 1 |
| 24200 | disgustaban | 1 |
| 24201 | disfrute | 1 |
| 24202 | disfrutar | 1 |
| 24203 | disfruta | 1 |
| 24204 | disfrazaron | 1 |
| 24205 | disfrazan | 1 |
| 24206 | disfrazados | 1 |
| 24207 | disfrazada | 1 |
| 24208 | disertaron | 1 |
| 24209 | disertación | 1 |
| 24210 | diseño | 1 |
| 24211 | disentimiento | 1 |
| 24212 | disensiones | 1 |
| 24213 | diseminaban | 1 |
| 24214 | disección | 1 |
| 24215 | discutiremos | 1 |
| 24216 | discutiré | 1 |
| 24217 | discutirá | 1 |
| 24218 | discutiose | 1 |
| 24219 | discutió | 1 |
| 24220 | discutían | 1 |
| 24221 | discutíamos | 1 |
| 24222 | discute | 1 |
| 24223 | discursazo | 1 |
| 24224 | discurriera | 1 |
| 24225 | discurres | 1 |
| 24226 | discurre | 1 |
| 24227 | discurras | 1 |
| 24228 | disculpose | 1 |
| 24229 | disculparse | 1 |
| 24230 | disculpar | 1 |
| 24231 | disculpan | 1 |
| 24232 | disculpa | 1 |
| 24233 | discrepando | 1 |
| 24234 | discrepaban | 1 |
| 24235 | discípula | 1 |
| 24236 | disciplinarias | 1 |
| 24237 | disciplinaria | 1 |
| 24238 | discernir | 1 |
| 24239 | discernimiento | 1 |
| 24240 | dirigirá | 1 |
| 24241 | dirigieran | 1 |
| 24242 | dirigiera | 1 |
| 24243 | diríase | 1 |
| 24244 | dirías | 1 |
| 24245 | dirían | 1 |
| 24246 | diremos | 1 |
| 24247 | direcciones | 1 |
| 24248 | diranle | 1 |
| 24249 | diquiá | 1 |
| 24250 | diputados | 1 |
| 24251 | diputación | 1 |
| 24252 | dipósito | 1 |
| 24253 | diplomáticas | 1 |
| 24254 | diplomática | 1 |
| 24255 | diplomacias | 1 |
| 24256 | diploma | 1 |
| 24257 | diósela | 1 |
| 24258 | diosecito | 1 |
| 24259 | diose | 1 |
| 24260 | diosa | 1 |
| 24261 | díos | 1 |
| 24262 | diome | 1 |
| 24263 | dintel | 1 |
| 24264 | dinos | 1 |
| 24265 | dineral | 1 |
| 24266 | dinastía | 1 |
| 24267 | dinamita | 1 |
| 24268 | diminuto | 1 |
| 24269 | dimetria | 1 |
| 24270 | dimensiones | 1 |
| 24271 | dímelas | 1 |
| 24272 | dímela | 1 |
| 24273 | diluviaba | 1 |
| 24274 | dilucidemos | 1 |
| 24275 | diligentísima | 1 |
| 24276 | diligente | 1 |
| 24277 | dilatadas | 1 |
| 24278 | dilatada | 1 |
| 24279 | díjoles | 1 |
| 24280 | dijesen | 1 |
| 24281 | digresiones | 1 |
| 24282 | dígolo | 1 |
| 24283 | dignísimo | 1 |
| 24284 | dignamente | 1 |
| 24285 | dignado | 1 |
| 24286 | digitalina | 1 |
| 24287 | digital | 1 |
| 24288 | digiere | 1 |
| 24289 | digestivo | 1 |
| 24290 | digestión | 1 |
| 24291 | digerido | 1 |
| 24292 | digería | 1 |
| 24293 | dígamelo | 1 |
| 24294 | dígalo | 1 |
| 24295 | difuntos | 1 |
| 24296 | difundido | 1 |
| 24297 | dificultara | 1 |
| 24298 | dificultaba | 1 |
| 24299 | diferir | 1 |
| 24300 | diferiencia | 1 |
| 24301 | diferencian | 1 |
| 24302 | diferenciaban | 1 |
| 24303 | difamatorios | 1 |
| 24304 | diestros | 1 |
| 24305 | diesen | 1 |
| 24306 | diéronse | 1 |
| 24307 | diéranle | 1 |
| 24308 | diéramos | 1 |
| 24309 | dierais | 1 |
| 24310 | dientecillos | 1 |
| 24311 | diecinueve | 1 |
| 24312 | dido | 1 |
| 24313 | dictó | 1 |
| 24314 | dictar | 1 |
| 24315 | dictan | 1 |
| 24316 | dictador | 1 |
| 24317 | dictaba | 1 |
| 24318 | diciéndote | 1 |
| 24319 | diciéndolas | 1 |
| 24320 | dicharachos | 1 |
| 24321 | dicharachera | 1 |
| 24322 | diccionario | 1 |
| 24323 | dibujando | 1 |
| 24324 | dibujan | 1 |
| 24325 | dibujado | 1 |
| 24326 | díaz | 1 |
| 24327 | diátesis | 1 |
| 24328 | diarias | 1 |
| 24329 | diariamente | 1 |
| 24330 | diaria | 1 |
| 24331 | diaquilón | 1 |
| 24332 | diantres | 1 |
| 24333 | dianches | 1 |
| 24334 | diamantinos | 1 |
| 24335 | dialécticas | 1 |
| 24336 | diagnóstico | 1 |
| 24337 | diafanidad | 1 |
| 24338 | diáfana | 1 |
| 24339 | diabólicos | 1 |
| 24340 | diabólicas | 1 |
| 24341 | diablura | 1 |
| 24342 | diablillos | 1 |
| 24343 | diablesca | 1 |
| 24344 | dextrina | 1 |
| 24345 | devuelves | 1 |
| 24346 | devorarle | 1 |
| 24347 | devorarla | 1 |
| 24348 | devorar | 1 |
| 24349 | devorándola | 1 |
| 24350 | devorando | 1 |
| 24351 | devorado | 1 |
| 24352 | devoraban | 1 |
| 24353 | devolviéndoselo | 1 |
| 24354 | devolvérselos | 1 |
| 24355 | devolverle | 1 |
| 24356 | devolverlas | 1 |
| 24357 | devolvería | 1 |
| 24358 | devoluciones | 1 |
| 24359 | devocionarios | 1 |
| 24360 | devastadores | 1 |
| 24361 | devastaba | 1 |
| 24362 | devano | 1 |
| 24363 | devanarse | 1 |
| 24364 | devanar | 1 |
| 24365 | devanamos | 1 |
| 24366 | devanábamos | 1 |
| 24367 | deudora | 1 |
| 24368 | detuviera | 1 |
| 24369 | detiénese | 1 |
| 24370 | detestable | 1 |
| 24371 | determino | 1 |
| 24372 | determiné | 1 |
| 24373 | determinas | 1 |
| 24374 | determinarse | 1 |
| 24375 | determináronse | 1 |
| 24376 | determinaremos | 1 |
| 24377 | determinando | 1 |
| 24378 | determinan | 1 |
| 24379 | determinados | 1 |
| 24380 | determinadas | 1 |
| 24381 | determinada | 1 |
| 24382 | determina | 1 |
| 24383 | deteriorado | 1 |
| 24384 | detenimiento | 1 |
| 24385 | deteniéndola | 1 |
| 24386 | detenido | 1 |
| 24387 | detenida | 1 |
| 24388 | deteníase | 1 |
| 24389 | detenían | 1 |
| 24390 | detengas | 1 |
| 24391 | detenga | 1 |
| 24392 | detenernos | 1 |
| 24393 | detenerlo | 1 |
| 24394 | detenerle | 1 |
| 24395 | detallistas | 1 |
| 24396 | desviven | 1 |
| 24397 | desvió | 1 |
| 24398 | desviar | 1 |
| 24399 | desviado | 1 |
| 24400 | desvergonzó | 1 |
| 24401 | desvergonzada | 1 |
| 24402 | desventurados | 1 |
| 24403 | desventura | 1 |
| 24404 | desventajosa | 1 |
| 24405 | desventajas | 1 |
| 24406 | desventaja | 1 |
| 24407 | desvelo | 1 |
| 24408 | desvelados | 1 |
| 24409 | desvela | 1 |
| 24410 | desvariar | 1 |
| 24411 | desvariando | 1 |
| 24412 | desvanecieron | 1 |
| 24413 | desvaneciéndose | 1 |
| 24414 | desvanecidas | 1 |
| 24415 | desvanecerse | 1 |
| 24416 | desvanecen | 1 |
| 24417 | desván | 1 |
| 24418 | desvalidos | 1 |
| 24419 | desvalido | 1 |
| 24420 | destruyo | 1 |
| 24421 | destruyese | 1 |
| 24422 | destruirlos | 1 |
| 24423 | destruirlo | 1 |
| 24424 | destruido | 1 |
| 24425 | destruía | 1 |
| 24426 | destructoras | 1 |
| 24427 | destrución | 1 |
| 24428 | destrozará | 1 |
| 24429 | destinósele | 1 |
| 24430 | destinatario | 1 |
| 24431 | destinaba | 1 |
| 24432 | destilando | 1 |
| 24433 | destiladera | 1 |
| 24434 | destilaba | 1 |
| 24435 | destierro | 1 |
| 24436 | desterrarlo | 1 |
| 24437 | desterrando | 1 |
| 24438 | desterrados | 1 |
| 24439 | desternillaba | 1 |
| 24440 | destape | 1 |
| 24441 | destapas | 1 |
| 24442 | destapar | 1 |
| 24443 | destapaba | 1 |
| 24444 | destajo | 1 |
| 24445 | destacose | 1 |
| 24446 | destacó | 1 |
| 24447 | destacándose | 1 |
| 24448 | destacaban | 1 |
| 24449 | desquite | 1 |
| 24450 | desquicien | 1 |
| 24451 | desquiciaron | 1 |
| 24452 | desquiciamiento | 1 |
| 24453 | despuntaban | 1 |
| 24454 | despuntaba | 1 |
| 24455 | desprovista | 1 |
| 24456 | despropósito | 1 |
| 24457 | desproporcionadamente | 1 |
| 24458 | desprevenida | 1 |
| 24459 | desprestigiaría | 1 |
| 24460 | desprestigiar | 1 |
| 24461 | despreocupación | 1 |
| 24462 | desprendió | 1 |
| 24463 | desprendiese | 1 |
| 24464 | desprendiendo | 1 |
| 24465 | desprendido | 1 |
| 24466 | desprendía | 1 |
| 24467 | desprenderme | 1 |
| 24468 | despreció | 1 |
| 24469 | desprecian | 1 |
| 24470 | despreciado | 1 |
| 24471 | despreciadas | 1 |
| 24472 | despotricar | 1 |
| 24473 | despótico | 1 |
| 24474 | despóticamente | 1 |
| 24475 | despótica | 1 |
| 24476 | despojaron | 1 |
| 24477 | despojado | 1 |
| 24478 | desplumó | 1 |
| 24479 | desplumar | 1 |
| 24480 | desplumados | 1 |
| 24481 | desplumadoras | 1 |
| 24482 | desplumaban | 1 |
| 24483 | desplomose | 1 |
| 24484 | desplomado | 1 |
| 24485 | desplomada | 1 |
| 24486 | desplomaban | 1 |
| 24487 | desplegadas | 1 |
| 24488 | desplantes | 1 |
| 24489 | despinta | 1 |
| 24490 | despilfarros | 1 |
| 24491 | despilfarro | 1 |
| 24492 | despiertísima | 1 |
| 24493 | despido | 1 |
| 24494 | despidiéronla | 1 |
| 24495 | despidiera | 1 |
| 24496 | despídete | 1 |
| 24497 | despiden | 1 |
| 24498 | despídase | 1 |
| 24499 | despiadado | 1 |
| 24500 | desperté | 1 |
| 24501 | despertase | 1 |
| 24502 | despertáronse | 1 |
| 24503 | despertarla | 1 |
| 24504 | despertaré | 1 |
| 24505 | despertándose | 1 |
| 24506 | desperna | 1 |
| 24507 | desperezos | 1 |
| 24508 | desperezo | 1 |
| 24509 | desperezara | 1 |
| 24510 | desperdicio | 1 |
| 24511 | despercudir | 1 |
| 24512 | despercudida | 1 |
| 24513 | despepita | 1 |
| 24514 | despeñó | 1 |
| 24515 | despeñaperros | 1 |
| 24516 | despejaría | 1 |
| 24517 | despejará | 1 |
| 24518 | despejándole | 1 |
| 24519 | despejadísimo | 1 |
| 24520 | despejaban | 1 |
| 24521 | despedirles | 1 |
| 24522 | despedirlas | 1 |
| 24523 | despedir | 1 |
| 24524 | despedido | 1 |
| 24525 | despedazaría | 1 |
| 24526 | despedazados | 1 |
| 24527 | despechada | 1 |
| 24528 | despavorido | 1 |
| 24529 | despavoridas | 1 |
| 24530 | desparramados | 1 |
| 24531 | despachos | 1 |
| 24532 | despácheme | 1 |
| 24533 | despaché | 1 |
| 24534 | despache | 1 |
| 24535 | despachase | 1 |
| 24536 | despachara | 1 |
| 24537 | despachando | 1 |
| 24538 | despachados | 1 |
| 24539 | despacha | 1 |
| 24540 | despabile | 1 |
| 24541 | despabilarme | 1 |
| 24542 | desorientados | 1 |
| 24543 | desorientaba | 1 |
| 24544 | desorganización | 1 |
| 24545 | desordenadas | 1 |
| 24546 | desollaron | 1 |
| 24547 | desojaban | 1 |
| 24548 | desocuparme | 1 |
| 24549 | desocupado | 1 |
| 24550 | desobedientes | 1 |
| 24551 | desobediencia | 1 |
| 24552 | desobedecería | 1 |
| 24553 | desnudez | 1 |
| 24554 | desnudabas | 1 |
| 24555 | desmoralizados | 1 |
| 24556 | desmontó | 1 |
| 24557 | desmintieran | 1 |
| 24558 | desmintiendo | 1 |
| 24559 | desmiente | 1 |
| 24560 | desmerecía | 1 |
| 24561 | desmerecer | 1 |
| 24562 | desmerece | 1 |
| 24563 | desmenuzar | 1 |
| 24564 | desmenuzadas | 1 |
| 24565 | desmenuzaba | 1 |
| 24566 | desmentirá | 1 |
| 24567 | desmentidas | 1 |
| 24568 | desmemoriado | 1 |
| 24569 | desmejorarse | 1 |
| 24570 | desmejoramiento | 1 |
| 24571 | desmejoradillo | 1 |
| 24572 | desmedidamente | 1 |
| 24573 | desmedida | 1 |
| 24574 | desmayó | 1 |
| 24575 | desmayan | 1 |
| 24576 | desmayados | 1 |
| 24577 | desmayado | 1 |
| 24578 | desmayaba | 1 |
| 24579 | desmandase | 1 |
| 24580 | desmanda | 1 |
| 24581 | desmadejada | 1 |
| 24582 | deslumbrado | 1 |
| 24583 | deslumbraba | 1 |
| 24584 | deslucida | 1 |
| 24585 | deslomar | 1 |
| 24586 | deslizose | 1 |
| 24587 | deslizó | 1 |
| 24588 | deslizarse | 1 |
| 24589 | deslizar | 1 |
| 24590 | deslizando | 1 |
| 24591 | deslizado | 1 |
| 24592 | desligado | 1 |
| 24593 | desligada | 1 |
| 24594 | deslicen | 1 |
| 24595 | desliando | 1 |
| 24596 | desliaba | 1 |
| 24597 | deslealtades | 1 |
| 24598 | deslealtad | 1 |
| 24599 | desistió | 1 |
| 24600 | desinteresados | 1 |
| 24601 | desinteresada | 1 |
| 24602 | desilusiones | 1 |
| 24603 | desilusionada | 1 |
| 24604 | desilusión | 1 |
| 24605 | designaré | 1 |
| 24606 | designará | 1 |
| 24607 | designado | 1 |
| 24608 | designada | 1 |
| 24609 | desiderátum | 1 |
| 24610 | deshonró | 1 |
| 24611 | deshonras | 1 |
| 24612 | deshonrarme | 1 |
| 24613 | deshonrarán | 1 |
| 24614 | deshojar | 1 |
| 24615 | deshelaba | 1 |
| 24616 | deshecho | 1 |
| 24617 | deshechas | 1 |
| 24618 | deshaciéndose | 1 |
| 24619 | deshaciendo | 1 |
| 24620 | deshacían | 1 |
| 24621 | deshacía | 1 |
| 24622 | deshacen | 1 |
| 24623 | deshabitada | 1 |
| 24624 | desgranadas | 1 |
| 24625 | desgraciadas | 1 |
| 24626 | desgobernando | 1 |
| 24627 | desgaste | 1 |
| 24628 | desgastase | 1 |
| 24629 | desgastará | 1 |
| 24630 | desgarran | 1 |
| 24631 | desgarrado | 1 |
| 24632 | desgañitarse | 1 |
| 24633 | desganada | 1 |
| 24634 | desflorar | 1 |
| 24635 | desfile | 1 |
| 24636 | desfilaron | 1 |
| 24637 | desfilar | 1 |
| 24638 | desfigurarla | 1 |
| 24639 | desfigurados | 1 |
| 24640 | desfiguraba | 1 |
| 24641 | desfavorecido | 1 |
| 24642 | desfavorables | 1 |
| 24643 | desfavorablemente | 1 |
| 24644 | desfallecimientos | 1 |
| 24645 | desesperarse | 1 |
| 24646 | desesperaría | 1 |
| 24647 | desesperante | 1 |
| 24648 | desesperado | 1 |
| 24649 | desesperadamente | 1 |
| 24650 | desesperada | 1 |
| 24651 | desesperaba | 1 |
| 24652 | desertar | 1 |
| 24653 | deserción | 1 |
| 24654 | desequilibrio | 1 |
| 24655 | desequilibraba | 1 |
| 24656 | deseoso | 1 |
| 24657 | deseosas | 1 |
| 24658 | desenvuelve | 1 |
| 24659 | desenvuelta | 1 |
| 24660 | desenvolvía | 1 |
| 24661 | desenvolveros | 1 |
| 24662 | desenvolverme | 1 |
| 24663 | desenvolver | 1 |
| 24664 | desentumecían | 1 |
| 24665 | desentumecía | 1 |
| 24666 | desentrañar | 1 |
| 24667 | desentono | 1 |
| 24668 | desentonada | 1 |
| 24669 | desenroscarse | 1 |
| 24670 | desenrosca | 1 |
| 24671 | desenojaría | 1 |
| 24672 | desenojar | 1 |
| 24673 | desenlace | 1 |
| 24674 | desengonzado | 1 |
| 24675 | desengaños | 1 |
| 24676 | desengaño | 1 |
| 24677 | desengáñese | 1 |
| 24678 | desengañarle | 1 |
| 24679 | desengañaos | 1 |
| 24680 | desengañado | 1 |
| 24681 | desengañadas | 1 |
| 24682 | desenfundan | 1 |
| 24683 | desenfadada | 1 |
| 24684 | desencuadernarse | 1 |
| 24685 | desencarna | 1 |
| 24686 | desencajados | 1 |
| 24687 | desempeñes | 1 |
| 24688 | desempeñarlo | 1 |
| 24689 | desempeñarla | 1 |
| 24690 | desempeñan | 1 |
| 24691 | desempeñado | 1 |
| 24692 | desembuchas | 1 |
| 24693 | desembuchando | 1 |
| 24694 | desembocar | 1 |
| 24695 | desembarcos | 1 |
| 24696 | desembarcar | 1 |
| 24697 | desellando | 1 |
| 24698 | deseé | 1 |
| 24699 | desecho | 1 |
| 24700 | deseché | 1 |
| 24701 | desecharon | 1 |
| 24702 | desecharla | 1 |
| 24703 | desechar | 1 |
| 24704 | desechando | 1 |
| 24705 | desechados | 1 |
| 24706 | desechadas | 1 |
| 24707 | desearan | 1 |
| 24708 | deseándolo | 1 |
| 24709 | deseándole | 1 |
| 24710 | desean | 1 |
| 24711 | desdoro | 1 |
| 24712 | desdoblado | 1 |
| 24713 | desdoblaba | 1 |
| 24714 | desdijera | 1 |
| 24715 | desdiciéndose | 1 |
| 24716 | desdicha | 1 |
| 24717 | desdice | 1 |
| 24718 | desdeñosas | 1 |
| 24719 | desdeñosa | 1 |
| 24720 | desdeñado | 1 |
| 24721 | desdentado | 1 |
| 24722 | desdecirme | 1 |
| 24723 | descuidos | 1 |
| 24724 | descuidillos | 1 |
| 24725 | descuidero | 1 |
| 24726 | descuidera | 1 |
| 24727 | descuidar | 1 |
| 24728 | descuidadas | 1 |
| 24729 | descuidaban | 1 |
| 24730 | descuentos | 1 |
| 24731 | descuelgue | 1 |
| 24732 | descuelgas | 1 |
| 24733 | descuelga | 1 |
| 24734 | descubriremos | 1 |
| 24735 | descubriolo | 1 |
| 24736 | descubrimos | 1 |
| 24737 | descubrieran | 1 |
| 24738 | descubriera | 1 |
| 24739 | descubrí | 1 |
| 24740 | descubren | 1 |
| 24741 | descubras | 1 |
| 24742 | descuartizarla | 1 |
| 24743 | descuartizar | 1 |
| 24744 | descuartizada | 1 |
| 24745 | descuartice | 1 |
| 24746 | descrita | 1 |
| 24747 | descrismándose | 1 |
| 24748 | descriptivo | 1 |
| 24749 | describirse | 1 |
| 24750 | describía | 1 |
| 24751 | describe | 1 |
| 24752 | descorrían | 1 |
| 24753 | descorrer | 1 |
| 24754 | descorazonó | 1 |
| 24755 | descorazonamiento | 1 |
| 24756 | descorazonado | 1 |
| 24757 | descontentos | 1 |
| 24758 | descontenta | 1 |
| 24759 | descontándole | 1 |
| 24760 | descontadas | 1 |
| 24761 | desconsuelos | 1 |
| 24762 | desconsoladora | 1 |
| 24763 | desconsoladísima | 1 |
| 24764 | desconsolaba | 1 |
| 24765 | desconsideradamente | 1 |
| 24766 | desconozco | 1 |
| 24767 | desconociendo | 1 |
| 24768 | desconocidos | 1 |
| 24769 | desconfías | 1 |
| 24770 | desconfianzas | 1 |
| 24771 | desconfía | 1 |
| 24772 | desconcertados | 1 |
| 24773 | desconcertaba | 1 |
| 24774 | descompusiera | 1 |
| 24775 | descompostura | 1 |
| 24776 | descomposición | 1 |
| 24777 | descomponiéndole | 1 |
| 24778 | descomponían | 1 |
| 24779 | descomedida | 1 |
| 24780 | descolorido | 1 |
| 24781 | descoloridas | 1 |
| 24782 | descollaría | 1 |
| 24783 | descollar | 1 |
| 24784 | descolgarte | 1 |
| 24785 | descolgarlos | 1 |
| 24786 | descolgándose | 1 |
| 24787 | desclavar | 1 |
| 24788 | descifraba | 1 |
| 24789 | descendido | 1 |
| 24790 | descendían | 1 |
| 24791 | descastada | 1 |
| 24792 | descascaraba | 1 |
| 24793 | descartaba | 1 |
| 24794 | descarriado | 1 |
| 24795 | descarriadas | 1 |
| 24796 | descarnada | 1 |
| 24797 | descargos | 1 |
| 24798 | descargó | 1 |
| 24799 | descargo | 1 |
| 24800 | descargasen | 1 |
| 24801 | descargase | 1 |
| 24802 | descargándosela | 1 |
| 24803 | descargando | 1 |
| 24804 | descargados | 1 |
| 24805 | descargada | 1 |
| 24806 | descarado | 1 |
| 24807 | descansó | 1 |
| 24808 | descanses | 1 |
| 24809 | descansen | 1 |
| 24810 | descansaron | 1 |
| 24811 | descansando | 1 |
| 24812 | descansado | 1 |
| 24813 | descansada | 1 |
| 24814 | descansaba | 1 |
| 24815 | descamisado | 1 |
| 24816 | descalzarle | 1 |
| 24817 | descalcitos | 1 |
| 24818 | descalabré | 1 |
| 24819 | descalabrado | 1 |
| 24820 | descalabra | 1 |
| 24821 | descaecimiento | 1 |
| 24822 | descabezando | 1 |
| 24823 | descabezado | 1 |
| 24824 | descabezaban | 1 |
| 24825 | descabaladas | 1 |
| 24826 | desbravase | 1 |
| 24827 | desbordarse | 1 |
| 24828 | desbordamientos | 1 |
| 24829 | desbordamiento | 1 |
| 24830 | desbordaban | 1 |
| 24831 | desbastaron | 1 |
| 24832 | desbastar | 1 |
| 24833 | desbastándola | 1 |
| 24834 | desbarro | 1 |
| 24835 | desbarraba | 1 |
| 24836 | desbaratarse | 1 |
| 24837 | desbaratar | 1 |
| 24838 | desbaratando | 1 |
| 24839 | desbarataba | 1 |
| 24840 | desbarata | 1 |
| 24841 | desbandó | 1 |
| 24842 | desbandan | 1 |
| 24843 | desbandada | 1 |
| 24844 | desazonaba | 1 |
| 24845 | desayunarse | 1 |
| 24846 | desavío | 1 |
| 24847 | desavenidos | 1 |
| 24848 | desatinadas | 1 |
| 24849 | desate | 1 |
| 24850 | desatar | 1 |
| 24851 | desatado | 1 |
| 24852 | desatada | 1 |
| 24853 | desataban | 1 |
| 24854 | desastres | 1 |
| 24855 | desastre | 1 |
| 24856 | desasosegado | 1 |
| 24857 | desasosegada | 1 |
| 24858 | desasosegaba | 1 |
| 24859 | desaseo | 1 |
| 24860 | desaseado | 1 |
| 24861 | desarrollaron | 1 |
| 24862 | desarrollándosele | 1 |
| 24863 | desarrolladas | 1 |
| 24864 | desarrollaban | 1 |
| 24865 | desarregladas | 1 |
| 24866 | desarreglada | 1 |
| 24867 | desarraigar | 1 |
| 24868 | desarmarle | 1 |
| 24869 | desarmar | 1 |
| 24870 | desaprobar | 1 |
| 24871 | desapartaísos | 1 |
| 24872 | desapartada | 1 |
| 24873 | desapariciones | 1 |
| 24874 | desaparezca | 1 |
| 24875 | desapareciendo | 1 |
| 24876 | desaparecida | 1 |
| 24877 | desaparecía | 1 |
| 24878 | desanimarte | 1 |
| 24879 | desanimándose | 1 |
| 24880 | desanimados | 1 |
| 24881 | desamparado | 1 |
| 24882 | desamparadas | 1 |
| 24883 | desamparada | 1 |
| 24884 | desamortización | 1 |
| 24885 | desamor | 1 |
| 24886 | desalmado | 1 |
| 24887 | desalentaban | 1 |
| 24888 | desalada | 1 |
| 24889 | desairaban | 1 |
| 24890 | desahucios | 1 |
| 24891 | desahogos | 1 |
| 24892 | desahogó | 1 |
| 24893 | desahógate | 1 |
| 24894 | desahogaran | 1 |
| 24895 | desahogándola | 1 |
| 24896 | desahogan | 1 |
| 24897 | desahogadamente | 1 |
| 24898 | desahogada | 1 |
| 24899 | desagrado | 1 |
| 24900 | desagradaron | 1 |
| 24901 | desagradablemente | 1 |
| 24902 | desafueros | 1 |
| 24903 | desaforadamente | 1 |
| 24904 | desafíos | 1 |
| 24905 | desafinar | 1 |
| 24906 | desafinamos | 1 |
| 24907 | desafiaban | 1 |
| 24908 | desacredito | 1 |
| 24909 | desacreditar | 1 |
| 24910 | desacordes | 1 |
| 24911 | desacierto | 1 |
| 24912 | desabrocharon | 1 |
| 24913 | desabrigues | 1 |
| 24914 | desabrigo | 1 |
| 24915 | desabrigara | 1 |
| 24916 | desabrigado | 1 |
| 24917 | desabridísimo | 1 |
| 24918 | desabotonar | 1 |
| 24919 | desaborida | 1 |
| 24920 | derroteros | 1 |
| 24921 | derrotar | 1 |
| 24922 | derrotados | 1 |
| 24923 | derrochador | 1 |
| 24924 | derritieran | 1 |
| 24925 | derritiendo | 1 |
| 24926 | derribarle | 1 |
| 24927 | derribar | 1 |
| 24928 | derribando | 1 |
| 24929 | derribada | 1 |
| 24930 | derrengado | 1 |
| 24931 | derramó | 1 |
| 24932 | derramo | 1 |
| 24933 | derrames | 1 |
| 24934 | derrame | 1 |
| 24935 | derramarse | 1 |
| 24936 | derramamiento | 1 |
| 24937 | derramaba | 1 |
| 24938 | derrama | 1 |
| 24939 | derogando | 1 |
| 24940 | derogada | 1 |
| 24941 | derivado | 1 |
| 24942 | derivadas | 1 |
| 24943 | derivaciones | 1 |
| 24944 | derivaba | 1 |
| 24945 | deriva | 1 |
| 24946 | derechitos | 1 |
| 24947 | derechas | 1 |
| 24948 | derechamente | 1 |
| 24949 | depurar | 1 |
| 24950 | deprisa | 1 |
| 24951 | depravados | 1 |
| 24952 | depravado | 1 |
| 24953 | depravaciones | 1 |
| 24954 | depositó | 1 |
| 24955 | depositar | 1 |
| 24956 | depositaban | 1 |
| 24957 | deplorar | 1 |
| 24958 | dependiera | 1 |
| 24959 | dependía | 1 |
| 24960 | departió | 1 |
| 24961 | deparó | 1 |
| 24962 | depare | 1 |
| 24963 | deparándote | 1 |
| 24964 | denuncies | 1 |
| 24965 | denunciado | 1 |
| 24966 | denunciaban | 1 |
| 24967 | denuestos | 1 |
| 24968 | dentición | 1 |
| 24969 | dentelladas | 1 |
| 24970 | denso | 1 |
| 24971 | densísimo | 1 |
| 24972 | densa | 1 |
| 24973 | denotaban | 1 |
| 24974 | denominó | 1 |
| 24975 | denominaciones | 1 |
| 24976 | denominación | 1 |
| 24977 | denme | 1 |
| 24978 | denle | 1 |
| 24979 | dengues | 1 |
| 24980 | dengosas | 1 |
| 24981 | dengosa | 1 |
| 24982 | denegaciones | 1 |
| 24983 | demuestras | 1 |
| 24984 | demuestran | 1 |
| 24985 | demudó | 1 |
| 24986 | demudado | 1 |
| 24987 | demostrarlo | 1 |
| 24988 | demostraré | 1 |
| 24989 | demostrándolo | 1 |
| 24990 | demonche | 1 |
| 24991 | demolieron | 1 |
| 24992 | demolición | 1 |
| 24993 | democráticas | 1 |
| 24994 | democrática | 1 |
| 24995 | demócratas | 1 |
| 24996 | demi | 1 |
| 24997 | demetria | 1 |
| 24998 | demencias | 1 |
| 24999 | demasiadas | 1 |
| 25000 | demasiada | 1 |
| 25001 | demanda | 1 |
| 25002 | demagogo | 1 |
| 25003 | demagógica | 1 |
| 25004 | delta | 1 |
| 25005 | delos | 1 |
| 25006 | delirium | 1 |
| 25007 | delirios | 1 |
| 25008 | delirara | 1 |
| 25009 | delirar | 1 |
| 25010 | delira | 1 |
| 25011 | deliciosos | 1 |
| 25012 | delicioso | 1 |
| 25013 | delicias | 1 |
| 25014 | delicadito | 1 |
| 25015 | deliberadamente | 1 |
| 25016 | deliberada | 1 |
| 25017 | delgadas | 1 |
| 25018 | delfinito | 1 |
| 25019 | delfines | 1 |
| 25020 | deleznables | 1 |
| 25021 | deleitaba | 1 |
| 25022 | delegando | 1 |
| 25023 | delatarla | 1 |
| 25024 | delantito | 1 |
| 25025 | delación | 1 |
| 25026 | dejoso | 1 |
| 25027 | dejolo | 1 |
| 25028 | dejoles | 1 |
| 25029 | dejola | 1 |
| 25030 | dejémoslo | 1 |
| 25031 | déjemelo | 1 |
| 25032 | déjela | 1 |
| 25033 | déjase | 1 |
| 25034 | dejártela | 1 |
| 25035 | dejárselos | 1 |
| 25036 | dejarnos | 1 |
| 25037 | dejarlo | 1 |
| 25038 | dejarles | 1 |
| 25039 | dejaremos | 1 |
| 25040 | dejarás | 1 |
| 25041 | dejarán | 1 |
| 25042 | déjanos | 1 |
| 25043 | dejándotela | 1 |
| 25044 | dejándonos | 1 |
| 25045 | dejándome | 1 |
| 25046 | dejándolo | 1 |
| 25047 | déjamele | 1 |
| 25048 | déjalo | 1 |
| 25049 | déjales | 1 |
| 25050 | déjala | 1 |
| 25051 | dejáis | 1 |
| 25052 | dejadez | 1 |
| 25053 | dejadas | 1 |
| 25054 | dejábalos | 1 |
| 25055 | deicidas | 1 |
| 25056 | dehesa | 1 |
| 25057 | degüello | 1 |
| 25058 | degüellan | 1 |
| 25059 | degrada | 1 |
| 25060 | degollina | 1 |
| 25061 | degollada | 1 |
| 25062 | deglutaba | 1 |
| 25063 | degeneración | 1 |
| 25064 | defraudaciones | 1 |
| 25065 | definiendo | 1 |
| 25066 | defiendo | 1 |
| 25067 | defiéndete | 1 |
| 25068 | déficit | 1 |
| 25069 | deficiencias | 1 |
| 25070 | defensor | 1 |
| 25071 | defensivo | 1 |
| 25072 | defendiera | 1 |
| 25073 | defendiéndose | 1 |
| 25074 | defendiendo | 1 |
| 25075 | defendidos | 1 |
| 25076 | defendida | 1 |
| 25077 | defenderlo | 1 |
| 25078 | defenderlas | 1 |
| 25079 | defendemos | 1 |
| 25080 | defectuosísima | 1 |
| 25081 | deducirse | 1 |
| 25082 | deduciendo | 1 |
| 25083 | deducía | 1 |
| 25084 | deduce | 1 |
| 25085 | deditos | 1 |
| 25086 | dedico | 1 |
| 25087 | dedicas | 1 |
| 25088 | dedicaría | 1 |
| 25089 | dedicar | 1 |
| 25090 | dedicaban | 1 |
| 25091 | dédalos | 1 |
| 25092 | dedal | 1 |
| 25093 | decretó | 1 |
| 25094 | decreto | 1 |
| 25095 | decretado | 1 |
| 25096 | decoroso | 1 |
| 25097 | decorosas | 1 |
| 25098 | decoró | 1 |
| 25099 | decorativas | 1 |
| 25100 | decorativamente | 1 |
| 25101 | decorar | 1 |
| 25102 | decoran | 1 |
| 25103 | decoraciones | 1 |
| 25104 | decoraban | 1 |
| 25105 | decoraba | 1 |
| 25106 | decomisura | 1 |
| 25107 | declive | 1 |
| 25108 | declinación | 1 |
| 25109 | declare | 1 |
| 25110 | declarase | 1 |
| 25111 | declaras | 1 |
| 25112 | declararse | 1 |
| 25113 | declararlo | 1 |
| 25114 | declararía | 1 |
| 25115 | declarando | 1 |
| 25116 | declaran | 1 |
| 25117 | declarados | 1 |
| 25118 | declaraciones | 1 |
| 25119 | declamatorio | 1 |
| 25120 | declamaciones | 1 |
| 25121 | decisivas | 1 |
| 25122 | decírtelo | 1 |
| 25123 | decírselas | 1 |
| 25124 | deciros | 1 |
| 25125 | decirnos | 1 |
| 25126 | decirlas | 1 |
| 25127 | décimos | 1 |
| 25128 | decimos | 1 |
| 25129 | décimas | 1 |
| 25130 | decidor | 1 |
| 25131 | decidirían | 1 |
| 25132 | decidiría | 1 |
| 25133 | decidiose | 1 |
| 25134 | decidieron | 1 |
| 25135 | decidiera | 1 |
| 25136 | decididamente | 1 |
| 25137 | decidí | 1 |
| 25138 | decídete | 1 |
| 25139 | deciden | 1 |
| 25140 | decidáis | 1 |
| 25141 | decible | 1 |
| 25142 | decíase | 1 |
| 25143 | decíanle | 1 |
| 25144 | decíame | 1 |
| 25145 | decíalas | 1 |
| 25146 | decentísimo | 1 |
| 25147 | decayendo | 1 |
| 25148 | decaída | 1 |
| 25149 | decaía | 1 |
| 25150 | decaer | 1 |
| 25151 | decadente | 1 |
| 25152 | débitos | 1 |
| 25153 | débilmente | 1 |
| 25154 | debilitarse | 1 |
| 25155 | debilitado | 1 |
| 25156 | debilitada | 1 |
| 25157 | débiles | 1 |
| 25158 | debieras | 1 |
| 25159 | debiendo | 1 |
| 25160 | deberían | 1 |
| 25161 | deberíamos | 1 |
| 25162 | debería | 1 |
| 25163 | deberá | 1 |
| 25164 | deba | 1 |
| 25165 | deán | 1 |
| 25166 | davidson | 1 |
| 25167 | david | 1 |
| 25168 | dátil | 1 |
| 25169 | dáselo | 1 |
| 25170 | darwinista | 1 |
| 25171 | darwin | 1 |
| 25172 | dártelo | 1 |
| 25173 | dárselas | 1 |
| 25174 | daros | 1 |
| 25175 | dármelo | 1 |
| 25176 | dármelas | 1 |
| 25177 | darlo | 1 |
| 25178 | darías | 1 |
| 25179 | darán | 1 |
| 25180 | daños | 1 |
| 25181 | dañino | 1 |
| 25182 | dañan | 1 |
| 25183 | dañados | 1 |
| 25184 | dañado | 1 |
| 25185 | danzando | 1 |
| 25186 | dante | 1 |
| 25187 | danme | 1 |
| 25188 | daniel | 1 |
| 25189 | dandys | 1 |
| 25190 | dándosela | 1 |
| 25191 | dándolo | 1 |
| 25192 | dámelo | 1 |
| 25193 | damasquería | 1 |
| 25194 | daganzo | 1 |
| 25195 | dádselo | 1 |
| 25196 | dados | 1 |
| 25197 | dadivosos | 1 |
| 25198 | daca | 1 |
| 25199 | dabas | 1 |
| 25200 | dábanse | 1 |
| 25201 | dábalo | 1 |
| 25202 | cutíes | 1 |
| 25203 | custodiarla | 1 |
| 25204 | custodiaba | 1 |
| 25205 | curtidos | 1 |
| 25206 | curtido | 1 |
| 25207 | cursilerías | 1 |
| 25208 | cursilería | 1 |
| 25209 | cursaban | 1 |
| 25210 | curó | 1 |
| 25211 | curo | 1 |
| 25212 | curiosos | 1 |
| 25213 | curiosona | 1 |
| 25214 | curiosísimo | 1 |
| 25215 | curioseo | 1 |
| 25216 | curiosas | 1 |
| 25217 | curia | 1 |
| 25218 | curdela | 1 |
| 25219 | curda | 1 |
| 25220 | curárselas | 1 |
| 25221 | curarme | 1 |
| 25222 | curara | 1 |
| 25223 | curánganos | 1 |
| 25224 | curadas | 1 |
| 25225 | curaba | 1 |
| 25226 | cúpulas | 1 |
| 25227 | cupiesen | 1 |
| 25228 | cuotas | 1 |
| 25229 | cuota | 1 |
| 25230 | cuñas | 1 |
| 25231 | cuñados | 1 |
| 25232 | cuñadita | 1 |
| 25233 | cunitas | 1 |
| 25234 | cunita | 1 |
| 25235 | cuneta | 1 |
| 25236 | cundiendo | 1 |
| 25237 | cunas | 1 |
| 25238 | cumplirse | 1 |
| 25239 | cumplirlo | 1 |
| 25240 | cumplirla | 1 |
| 25241 | cumpliré | 1 |
| 25242 | cumplidísima | 1 |
| 25243 | cumplidamente | 1 |
| 25244 | cumplían | 1 |
| 25245 | cumples | 1 |
| 25246 | cúmplase | 1 |
| 25247 | cumplas | 1 |
| 25248 | cumplamos | 1 |
| 25249 | cultos | 1 |
| 25250 | cultivarlo | 1 |
| 25251 | cultivar | 1 |
| 25252 | cultivando | 1 |
| 25253 | culpables | 1 |
| 25254 | culpabilidad | 1 |
| 25255 | culminante | 1 |
| 25256 | culito | 1 |
| 25257 | culinaria | 1 |
| 25258 | cuitado | 1 |
| 25259 | cuiste | 1 |
| 25260 | cuides | 1 |
| 25261 | cuidarme | 1 |
| 25262 | cuidarlos | 1 |
| 25263 | cuidarla | 1 |
| 25264 | cuidaré | 1 |
| 25265 | cuidará | 1 |
| 25266 | cuidándole | 1 |
| 25267 | cuidándolas | 1 |
| 25268 | cuidadoso | 1 |
| 25269 | cueza | 1 |
| 25270 | cuevas | 1 |
| 25271 | cueva | 1 |
| 25272 | cuestionar | 1 |
| 25273 | cuestionando | 1 |
| 25274 | cuestionaban | 1 |
| 25275 | cuestan | 1 |
| 25276 | cuernos | 1 |
| 25277 | cuentera | 1 |
| 25278 | cuéntenme | 1 |
| 25279 | cuéntanos | 1 |
| 25280 | cuéntale | 1 |
| 25281 | cuéntala | 1 |
| 25282 | cuelguen | 1 |
| 25283 | cuélgueme | 1 |
| 25284 | cuelgo | 1 |
| 25285 | cuela | 1 |
| 25286 | cuco | 1 |
| 25287 | cuchillote | 1 |
| 25288 | cuchillito | 1 |
| 25289 | cuchilladas | 1 |
| 25290 | cuchicheó | 1 |
| 25291 | cuchicheando | 1 |
| 25292 | cuchicheaban | 1 |
| 25293 | cucharillas | 1 |
| 25294 | cucharetazos | 1 |
| 25295 | cucaracha | 1 |
| 25296 | cucamonas | 1 |
| 25297 | cubrirse | 1 |
| 25298 | cubriole | 1 |
| 25299 | cubriéronle | 1 |
| 25300 | cubrieron | 1 |
| 25301 | cubriendo | 1 |
| 25302 | cubrían | 1 |
| 25303 | cubría | 1 |
| 25304 | cúbrete | 1 |
| 25305 | cubres | 1 |
| 25306 | cúbrele | 1 |
| 25307 | cubiletes | 1 |
| 25308 | cubilete | 1 |
| 25309 | cúbicos | 1 |
| 25310 | cúbicas | 1 |
| 25311 | cúbica | 1 |
| 25312 | cuatros | 1 |
| 25313 | cuatrillones | 1 |
| 25314 | cuartillas | 1 |
| 25315 | cuartetos | 1 |
| 25316 | cuarterones | 1 |
| 25317 | cuartelesco | 1 |
| 25318 | cuaresma | 1 |
| 25319 | cuantiosas | 1 |
| 25320 | cuanti | 1 |
| 25321 | cuanta | 1 |
| 25322 | cualisquiera | 1 |
| 25323 | cuajo | 1 |
| 25324 | cuaje | 1 |
| 25325 | cuajarse | 1 |
| 25326 | cuadrumana | 1 |
| 25327 | cuadró | 1 |
| 25328 | cuadrilongo | 1 |
| 25329 | cuadrilla | 1 |
| 25330 | cuadril | 1 |
| 25331 | cuadratura | 1 |
| 25332 | cuadrase | 1 |
| 25333 | cuadrángano | 1 |
| 25334 | cuadraba | 1 |
| 25335 | cuadernos | 1 |
| 25336 | cruzáronse | 1 |
| 25337 | cruzarnos | 1 |
| 25338 | cruzar | 1 |
| 25339 | cruzándose | 1 |
| 25340 | cruzamiento | 1 |
| 25341 | cruzaban | 1 |
| 25342 | crujió | 1 |
| 25343 | crujieron | 1 |
| 25344 | crujidos | 1 |
| 25345 | crujida | 1 |
| 25346 | crujías | 1 |
| 25347 | cruelmente | 1 |
| 25348 | cruelísimas | 1 |
| 25349 | cruelísima | 1 |
| 25350 | crudísimo | 1 |
| 25351 | crudillo | 1 |
| 25352 | crudezas | 1 |
| 25353 | crudas | 1 |
| 25354 | crucis | 1 |
| 25355 | crucifique | 1 |
| 25356 | crucificando | 1 |
| 25357 | crucificados | 1 |
| 25358 | crucifica | 1 |
| 25359 | cruceta | 1 |
| 25360 | croto | 1 |
| 25361 | croquetita | 1 |
| 25362 | crónicas | 1 |
| 25363 | cromwell | 1 |
| 25364 | cromos | 1 |
| 25365 | crochet | 1 |
| 25366 | criticó | 1 |
| 25367 | criticar | 1 |
| 25368 | criticando | 1 |
| 25369 | criterios | 1 |
| 25370 | cristianamente | 1 |
| 25371 | cristalitos | 1 |
| 25372 | crispamientos | 1 |
| 25373 | crinolinas | 1 |
| 25374 | criminala | 1 |
| 25375 | criáronle | 1 |
| 25376 | criaron | 1 |
| 25377 | criarlos | 1 |
| 25378 | criarlo | 1 |
| 25379 | criaré | 1 |
| 25380 | criaban | 1 |
| 25381 | creyolo | 1 |
| 25382 | creyérase | 1 |
| 25383 | creyeran | 1 |
| 25384 | creyente | 1 |
| 25385 | creyéndose | 1 |
| 25386 | crespones | 1 |
| 25387 | crenchas | 1 |
| 25388 | creímos | 1 |
| 25389 | creíamos | 1 |
| 25390 | creételo | 1 |
| 25391 | creérmelo | 1 |
| 25392 | creerlas | 1 |
| 25393 | creerla | 1 |
| 25394 | credulidad | 1 |
| 25395 | credo | 1 |
| 25396 | créditos | 1 |
| 25397 | credencialeja | 1 |
| 25398 | crecieron | 1 |
| 25399 | crecidos | 1 |
| 25400 | crecidito | 1 |
| 25401 | creciditas | 1 |
| 25402 | crecidita | 1 |
| 25403 | creces | 1 |
| 25404 | crearía | 1 |
| 25405 | creánmelo | 1 |
| 25406 | créanlo | 1 |
| 25407 | creamos | 1 |
| 25408 | créamela | 1 |
| 25409 | creadoras | 1 |
| 25410 | creado | 1 |
| 25411 | creaciones | 1 |
| 25412 | creación | 1 |
| 25413 | crac | 1 |
| 25414 | coyunturas | 1 |
| 25415 | covacha | 1 |
| 25416 | courtray | 1 |
| 25417 | cotta | 1 |
| 25418 | cotorrear | 1 |
| 25419 | cotorreaban | 1 |
| 25420 | cotorras | 1 |
| 25421 | cotizaciones | 1 |
| 25422 | cotiza | 1 |
| 25423 | cotidiano | 1 |
| 25424 | costurones | 1 |
| 25425 | costuras | 1 |
| 25426 | costras | 1 |
| 25427 | costera | 1 |
| 25428 | costeo | 1 |
| 25429 | costear | 1 |
| 25430 | costeando | 1 |
| 25431 | costaría | 1 |
| 25432 | costará | 1 |
| 25433 | costar | 1 |
| 25434 | costanilla | 1 |
| 25435 | cósmico | 1 |
| 25436 | cosidos | 1 |
| 25437 | cosido | 1 |
| 25438 | cosidas | 1 |
| 25439 | cosida | 1 |
| 25440 | cosía | 1 |
| 25441 | cosedoras | 1 |
| 25442 | cosecheros | 1 |
| 25443 | coscorrón | 1 |
| 25444 | cortísimo | 1 |
| 25445 | cortinones | 1 |
| 25446 | cortinón | 1 |
| 25447 | cortinilla | 1 |
| 25448 | cortésmente | 1 |
| 25449 | cortesanas | 1 |
| 25450 | cortesana | 1 |
| 25451 | corten | 1 |
| 25452 | cortase | 1 |
| 25453 | cortarte | 1 |
| 25454 | cortarme | 1 |
| 25455 | cortarían | 1 |
| 25456 | cortaría | 1 |
| 25457 | cortará | 1 |
| 25458 | cortante | 1 |
| 25459 | cortándose | 1 |
| 25460 | cortan | 1 |
| 25461 | cortadito | 1 |
| 25462 | cortadísima | 1 |
| 25463 | cortadas | 1 |
| 25464 | corsés | 1 |
| 25465 | corsario | 1 |
| 25466 | corruptora | 1 |
| 25467 | corrompido | 1 |
| 25468 | corrompe | 1 |
| 25469 | corroboró | 1 |
| 25470 | corriole | 1 |
| 25471 | corrillos | 1 |
| 25472 | corrigiendo | 1 |
| 25473 | corrígete | 1 |
| 25474 | corrige | 1 |
| 25475 | corriéndola | 1 |
| 25476 | corriendito | 1 |
| 25477 | corridas | 1 |
| 25478 | corríase | 1 |
| 25479 | corríale | 1 |
| 25480 | corretear | 1 |
| 25481 | correteando | 1 |
| 25482 | correspondencias | 1 |
| 25483 | correrse | 1 |
| 25484 | correrla | 1 |
| 25485 | correrías | 1 |
| 25486 | correría | 1 |
| 25487 | corregirte | 1 |
| 25488 | corregirla | 1 |
| 25489 | corregían | 1 |
| 25490 | correderas | 1 |
| 25491 | corredera | 1 |
| 25492 | correctivos | 1 |
| 25493 | correctísima | 1 |
| 25494 | correa | 1 |
| 25495 | corras | 1 |
| 25496 | corral | 1 |
| 25497 | corpulenta | 1 |
| 25498 | corpulencia | 1 |
| 25499 | corpórea | 1 |
| 25500 | corporal | 1 |
| 25501 | corpachón | 1 |
| 25502 | coros | 1 |
| 25503 | coronen | 1 |
| 25504 | coronado | 1 |
| 25505 | coronadas | 1 |
| 25506 | coronada | 1 |
| 25507 | cornuda | 1 |
| 25508 | cornisas | 1 |
| 25509 | cornisa | 1 |
| 25510 | corneta | 1 |
| 25511 | corito | 1 |
| 25512 | corifeos | 1 |
| 25513 | coria | 1 |
| 25514 | cordones | 1 |
| 25515 | cordón | 1 |
| 25516 | cordilla | 1 |
| 25517 | cordialidad | 1 |
| 25518 | cordiales | 1 |
| 25519 | cordelero | 1 |
| 25520 | cordelería | 1 |
| 25521 | corchetes | 1 |
| 25522 | corbatín | 1 |
| 25523 | corazoncito | 1 |
| 25524 | coraza | 1 |
| 25525 | corambres | 1 |
| 25526 | coral | 1 |
| 25527 | coqueterías | 1 |
| 25528 | coqueteaba | 1 |
| 25529 | coquera | 1 |
| 25530 | copulativas | 1 |
| 25531 | copudo | 1 |
| 25532 | copos | 1 |
| 25533 | copón | 1 |
| 25534 | copo | 1 |
| 25535 | coplitas | 1 |
| 25536 | copiosamente | 1 |
| 25537 | copio | 1 |
| 25538 | copiadores | 1 |
| 25539 | copete | 1 |
| 25540 | convulsivo | 1 |
| 25541 | convocando | 1 |
| 25542 | convite | 1 |
| 25543 | convirtió | 1 |
| 25544 | convirtieran | 1 |
| 25545 | convirtiera | 1 |
| 25546 | convirtiéndose | 1 |
| 25547 | conviniera | 1 |
| 25548 | convierto | 1 |
| 25549 | convierta | 1 |
| 25550 | convienen | 1 |
| 25551 | convide | 1 |
| 25552 | convidara | 1 |
| 25553 | convidadas | 1 |
| 25554 | convidaban | 1 |
| 25555 | convidábale | 1 |
| 25556 | convida | 1 |
| 25557 | convexidad | 1 |
| 25558 | convertirse | 1 |
| 25559 | convertirlo | 1 |
| 25560 | convertirle | 1 |
| 25561 | convertirlas | 1 |
| 25562 | convertiría | 1 |
| 25563 | convertiré | 1 |
| 25564 | convertidas | 1 |
| 25565 | convertían | 1 |
| 25566 | convertía | 1 |
| 25567 | conversos | 1 |
| 25568 | conversión | 1 |
| 25569 | conversando | 1 |
| 25570 | convénzase | 1 |
| 25571 | convenio | 1 |
| 25572 | convenimos | 1 |
| 25573 | conveniencias | 1 |
| 25574 | convencionalismo | 1 |
| 25575 | convencían | 1 |
| 25576 | convences | 1 |
| 25577 | convencerías | 1 |
| 25578 | convencerá | 1 |
| 25579 | convéncele | 1 |
| 25580 | contuso | 1 |
| 25581 | contrista | 1 |
| 25582 | contrincantes | 1 |
| 25583 | contrincante | 1 |
| 25584 | contribuciones | 1 |
| 25585 | contreras | 1 |
| 25586 | contraviniendo | 1 |
| 25587 | contraventores | 1 |
| 25588 | contratos | 1 |
| 25589 | contratista | 1 |
| 25590 | contratiempo | 1 |
| 25591 | contratar | 1 |
| 25592 | contratantes | 1 |
| 25593 | contratación | 1 |
| 25594 | contrastar | 1 |
| 25595 | contrastando | 1 |
| 25596 | contrastaba | 1 |
| 25597 | contrariedades | 1 |
| 25598 | contrariaron | 1 |
| 25599 | contrariada | 1 |
| 25600 | contrariábala | 1 |
| 25601 | contraída | 1 |
| 25602 | contraía | 1 |
| 25603 | contrahechas | 1 |
| 25604 | contrafalda | 1 |
| 25605 | contraer | 1 |
| 25606 | contraen | 1 |
| 25607 | contrae | 1 |
| 25608 | contradijo | 1 |
| 25609 | contradictorias | 1 |
| 25610 | contradiciéndole | 1 |
| 25611 | contradice | 1 |
| 25612 | contradicciones | 1 |
| 25613 | contradecirla | 1 |
| 25614 | contradanzas | 1 |
| 25615 | contracciones | 1 |
| 25616 | contrabandistas | 1 |
| 25617 | contornos | 1 |
| 25618 | contonean | 1 |
| 25619 | contome | 1 |
| 25620 | continuase | 1 |
| 25621 | continuaremos | 1 |
| 25622 | continuara | 1 |
| 25623 | continúan | 1 |
| 25624 | continuadamente | 1 |
| 25625 | continuación | 1 |
| 25626 | continencia | 1 |
| 25627 | contigua | 1 |
| 25628 | contesto | 1 |
| 25629 | contestarse | 1 |
| 25630 | contestarles | 1 |
| 25631 | contéstame | 1 |
| 25632 | contestábale | 1 |
| 25633 | conteras | 1 |
| 25634 | contentísimo | 1 |
| 25635 | contenti | 1 |
| 25636 | conténtate | 1 |
| 25637 | contentaría | 1 |
| 25638 | contentarás | 1 |
| 25639 | contentado | 1 |
| 25640 | contentábase | 1 |
| 25641 | contentaban | 1 |
| 25642 | contentaba | 1 |
| 25643 | contenidas | 1 |
| 25644 | contenida | 1 |
| 25645 | contengo | 1 |
| 25646 | contenga | 1 |
| 25647 | contenerme | 1 |
| 25648 | contendientes | 1 |
| 25649 | contemporizador | 1 |
| 25650 | contemplo | 1 |
| 25651 | contemplarse | 1 |
| 25652 | contemplándole | 1 |
| 25653 | contemplándola | 1 |
| 25654 | contemplaciones | 1 |
| 25655 | conté | 1 |
| 25656 | contase | 1 |
| 25657 | contártelo | 1 |
| 25658 | contarte | 1 |
| 25659 | contárselo | 1 |
| 25660 | contármelo | 1 |
| 25661 | contarme | 1 |
| 25662 | contarlos | 1 |
| 25663 | contaría | 1 |
| 25664 | contaremos | 1 |
| 25665 | contarás | 1 |
| 25666 | contará | 1 |
| 25667 | contándote | 1 |
| 25668 | contándose | 1 |
| 25669 | contamos | 1 |
| 25670 | contagiosas | 1 |
| 25671 | contagiada | 1 |
| 25672 | contaduría | 1 |
| 25673 | contábale | 1 |
| 25674 | consunción | 1 |
| 25675 | consumirte | 1 |
| 25676 | consumidor | 1 |
| 25677 | consumido | 1 |
| 25678 | consumían | 1 |
| 25679 | consumía | 1 |
| 25680 | consumen | 1 |
| 25681 | consumaría | 1 |
| 25682 | consultó | 1 |
| 25683 | consultarme | 1 |
| 25684 | consultarlo | 1 |
| 25685 | consultaré | 1 |
| 25686 | consultándose | 1 |
| 25687 | consúltalo | 1 |
| 25688 | consultada | 1 |
| 25689 | cónsul | 1 |
| 25690 | consuetudinaria | 1 |
| 25691 | consuela | 1 |
| 25692 | construiré | 1 |
| 25693 | construidos | 1 |
| 25694 | construido | 1 |
| 25695 | construidas | 1 |
| 25696 | construían | 1 |
| 25697 | constructivo | 1 |
| 25698 | constructiva | 1 |
| 25699 | construcciones | 1 |
| 25700 | constituyo | 1 |
| 25701 | constituyesen | 1 |
| 25702 | constituyen | 1 |
| 25703 | constitutivo | 1 |
| 25704 | constitutiva | 1 |
| 25705 | constituirse | 1 |
| 25706 | constituida | 1 |
| 25707 | constituciones | 1 |
| 25708 | constipase | 1 |
| 25709 | constipado | 1 |
| 25710 | consternados | 1 |
| 25711 | constara | 1 |
| 25712 | constantino | 1 |
| 25713 | consta | 1 |
| 25714 | conspirar | 1 |
| 25715 | conspirando | 1 |
| 25716 | conspiran | 1 |
| 25717 | conspicuo | 1 |
| 25718 | conspicuas | 1 |
| 25719 | consonante | 1 |
| 25720 | consonancia | 1 |
| 25721 | consolemos | 1 |
| 25722 | consolé | 1 |
| 25723 | consolarte | 1 |
| 25724 | consolarse | 1 |
| 25725 | consolarnos | 1 |
| 25726 | consolarme | 1 |
| 25727 | consolarla | 1 |
| 25728 | consolaré | 1 |
| 25729 | consoladoras | 1 |
| 25730 | consolado | 1 |
| 25731 | consolaban | 1 |
| 25732 | consola | 1 |
| 25733 | consistió | 1 |
| 25734 | consistentes | 1 |
| 25735 | consista | 1 |
| 25736 | consiguió | 1 |
| 25737 | consiguiendo | 1 |
| 25738 | consiguen | 1 |
| 25739 | consigue | 1 |
| 25740 | consignar | 1 |
| 25741 | consignada | 1 |
| 25742 | consigna | 1 |
| 25743 | consienten | 1 |
| 25744 | consideré | 1 |
| 25745 | considerarte | 1 |
| 25746 | considerarse | 1 |
| 25747 | considerarle | 1 |
| 25748 | considerara | 1 |
| 25749 | considéralo | 1 |
| 25750 | considerada | 1 |
| 25751 | considerábase | 1 |
| 25752 | considerábanla | 1 |
| 25753 | consideraban | 1 |
| 25754 | conservas | 1 |
| 25755 | conservarla | 1 |
| 25756 | conservaré | 1 |
| 25757 | conservadora | 1 |
| 25758 | conservadas | 1 |
| 25759 | conservada | 1 |
| 25760 | consentirse | 1 |
| 25761 | consentimos | 1 |
| 25762 | consentían | 1 |
| 25763 | consecutivos | 1 |
| 25764 | consecuentes | 1 |
| 25765 | consciente | 1 |
| 25766 | consagraría | 1 |
| 25767 | consagraremos | 1 |
| 25768 | consagrado | 1 |
| 25769 | consagra | 1 |
| 25770 | conquistó | 1 |
| 25771 | conquistara | 1 |
| 25772 | conquistando | 1 |
| 25773 | conquistado | 1 |
| 25774 | conquistada | 1 |
| 25775 | conozcas | 1 |
| 25776 | conozcamos | 1 |
| 25777 | conociole | 1 |
| 25778 | conociéndola | 1 |
| 25779 | conocías | 1 |
| 25780 | conocerlo | 1 |
| 25781 | conocerla | 1 |
| 25782 | conocerían | 1 |
| 25783 | conoceremos | 1 |
| 25784 | conoceré | 1 |
| 25785 | conocerás | 1 |
| 25786 | conocerá | 1 |
| 25787 | conocedores | 1 |
| 25788 | conocedoras | 1 |
| 25789 | conocedora | 1 |
| 25790 | connivencia | 1 |
| 25791 | conmovió | 1 |
| 25792 | conmovidísima | 1 |
| 25793 | conmovedora | 1 |
| 25794 | conmovedor | 1 |
| 25795 | conminación | 1 |
| 25796 | conllevando | 1 |
| 25797 | conjuraban | 1 |
| 25798 | conjunciones | 1 |
| 25799 | conjeturas | 1 |
| 25800 | congrio | 1 |
| 25801 | congregarse | 1 |
| 25802 | congregados | 1 |
| 25803 | congratularse | 1 |
| 25804 | congojas | 1 |
| 25805 | congoja | 1 |
| 25806 | congestionaba | 1 |
| 25807 | congestión | 1 |
| 25808 | congenialidad | 1 |
| 25809 | confusas | 1 |
| 25810 | confusamente | 1 |
| 25811 | confundo | 1 |
| 25812 | confundirme | 1 |
| 25813 | confundieran | 1 |
| 25814 | confundiera | 1 |
| 25815 | confundido | 1 |
| 25816 | confundida | 1 |
| 25817 | confunden | 1 |
| 25818 | confundamos | 1 |
| 25819 | confrontar | 1 |
| 25820 | confrontándolas | 1 |
| 25821 | confortaron | 1 |
| 25822 | confortado | 1 |
| 25823 | conformó | 1 |
| 25824 | confórmese | 1 |
| 25825 | conformes | 1 |
| 25826 | conformaron | 1 |
| 25827 | conformarnos | 1 |
| 25828 | conformará | 1 |
| 25829 | conformándose | 1 |
| 25830 | conformado | 1 |
| 25831 | conflictos | 1 |
| 25832 | confitó | 1 |
| 25833 | confitería | 1 |
| 25834 | confirmo | 1 |
| 25835 | confirmase | 1 |
| 25836 | confirmaron | 1 |
| 25837 | confirmarlo | 1 |
| 25838 | confirmar | 1 |
| 25839 | confirmándose | 1 |
| 25840 | confirmaba | 1 |
| 25841 | confín | 1 |
| 25842 | confiéselo | 1 |
| 25843 | confiesas | 1 |
| 25844 | confiesan | 1 |
| 25845 | confiésame | 1 |
| 25846 | confíe | 1 |
| 25847 | confíate | 1 |
| 25848 | confiase | 1 |
| 25849 | confiarme | 1 |
| 25850 | confiadas | 1 |
| 25851 | confía | 1 |
| 25852 | confesiones | 1 |
| 25853 | confesionario | 1 |
| 25854 | confesaste | 1 |
| 25855 | confesarte | 1 |
| 25856 | confesaron | 1 |
| 25857 | confesarlo | 1 |
| 25858 | confesarían | 1 |
| 25859 | confesándose | 1 |
| 25860 | confesada | 1 |
| 25861 | confesaban | 1 |
| 25862 | conferencias | 1 |
| 25863 | confeccionar | 1 |
| 25864 | confeccionados | 1 |
| 25865 | confeccionada | 1 |
| 25866 | confeccionaba | 1 |
| 25867 | confabulado | 1 |
| 25868 | confabulada | 1 |
| 25869 | confabulación | 1 |
| 25870 | confabulaban | 1 |
| 25871 | condújola | 1 |
| 25872 | condujo | 1 |
| 25873 | conductos | 1 |
| 25874 | conductores | 1 |
| 25875 | conductor | 1 |
| 25876 | conducirse | 1 |
| 25877 | conducidos | 1 |
| 25878 | conducido | 1 |
| 25879 | conducidas | 1 |
| 25880 | conducida | 1 |
| 25881 | conduce | 1 |
| 25882 | condoliéndose | 1 |
| 25883 | condiscípulos | 1 |
| 25884 | condimento | 1 |
| 25885 | condimentado | 1 |
| 25886 | condicional | 1 |
| 25887 | condensarse | 1 |
| 25888 | condensándose | 1 |
| 25889 | condensaban | 1 |
| 25890 | condeno | 1 |
| 25891 | condenarse | 1 |
| 25892 | condenarás | 1 |
| 25893 | condenando | 1 |
| 25894 | condenación | 1 |
| 25895 | concurriendo | 1 |
| 25896 | concurridos | 1 |
| 25897 | concurrida | 1 |
| 25898 | concurrentes | 1 |
| 25899 | concurre | 1 |
| 25900 | conculcar | 1 |
| 25901 | concretándose | 1 |
| 25902 | concretan | 1 |
| 25903 | concretamente | 1 |
| 25904 | concordaban | 1 |
| 25905 | concordaba | 1 |
| 25906 | concluyese | 1 |
| 25907 | concluyeron | 1 |
| 25908 | concluyera | 1 |
| 25909 | concluyentes | 1 |
| 25910 | concluye | 1 |
| 25911 | conclusiones | 1 |
| 25912 | concluirla | 1 |
| 25913 | concluiría | 1 |
| 25914 | concluimos | 1 |
| 25915 | concluidas | 1 |
| 25916 | concisión | 1 |
| 25917 | concilio | 1 |
| 25918 | conciliasen | 1 |
| 25919 | conciliarse | 1 |
| 25920 | conciliaba | 1 |
| 25921 | concierne | 1 |
| 25922 | concibió | 1 |
| 25923 | concibiendo | 1 |
| 25924 | concibe | 1 |
| 25925 | conchas | 1 |
| 25926 | concesión | 1 |
| 25927 | concertados | 1 |
| 25928 | concertado | 1 |
| 25929 | concernientes | 1 |
| 25930 | conceptuándola | 1 |
| 25931 | concentrándose | 1 |
| 25932 | concentrado | 1 |
| 25933 | concentración | 1 |
| 25934 | concejales | 1 |
| 25935 | concediendo | 1 |
| 25936 | concedía | 1 |
| 25937 | conceder | 1 |
| 25938 | concede | 1 |
| 25939 | concebiría | 1 |
| 25940 | concebir | 1 |
| 25941 | concebido | 1 |
| 25942 | concebí | 1 |
| 25943 | cóncavos | 1 |
| 25944 | cóncavo | 1 |
| 25945 | concatenación | 1 |
| 25946 | conatos | 1 |
| 25947 | conato | 1 |
| 25948 | comunidades | 1 |
| 25949 | comunícase | 1 |
| 25950 | comunicase | 1 |
| 25951 | comunicar | 1 |
| 25952 | comunicándose | 1 |
| 25953 | comunicado | 1 |
| 25954 | comunicadas | 1 |
| 25955 | comunicada | 1 |
| 25956 | comulgas | 1 |
| 25957 | comulgaron | 1 |
| 25958 | compusiera | 1 |
| 25959 | compuestos | 1 |
| 25960 | compuertas | 1 |
| 25961 | comprometió | 1 |
| 25962 | comprometerle | 1 |
| 25963 | comprometen | 1 |
| 25964 | comprobarse | 1 |
| 25965 | comprobación | 1 |
| 25966 | compro | 1 |
| 25967 | comprimió | 1 |
| 25968 | comprimiéndose | 1 |
| 25969 | comprimidas | 1 |
| 25970 | compresión | 1 |
| 25971 | comprensible | 1 |
| 25972 | comprendiolo | 1 |
| 25973 | comprendiera | 1 |
| 25974 | comprendí | 1 |
| 25975 | comprenderlo | 1 |
| 25976 | comprenderías | 1 |
| 25977 | comprenderían | 1 |
| 25978 | comprenderás | 1 |
| 25979 | comprenden | 1 |
| 25980 | comprendemos | 1 |
| 25981 | comprendan | 1 |
| 25982 | compremos | 1 |
| 25983 | cómpreme | 1 |
| 25984 | compraste | 1 |
| 25985 | comprasen | 1 |
| 25986 | comprase | 1 |
| 25987 | comprárselo | 1 |
| 25988 | compraron | 1 |
| 25989 | comprarme | 1 |
| 25990 | comprarlo | 1 |
| 25991 | compraría | 1 |
| 25992 | compraremos | 1 |
| 25993 | compraran | 1 |
| 25994 | compráramos | 1 |
| 25995 | comprara | 1 |
| 25996 | comprando | 1 |
| 25997 | compran | 1 |
| 25998 | compramos | 1 |
| 25999 | comprados | 1 |
| 26000 | compradores | 1 |
| 26001 | compraban | 1 |
| 26002 | compotas | 1 |
| 26003 | compositores | 1 |
| 26004 | composicioncita | 1 |
| 26005 | componiéndose | 1 |
| 26006 | componíase | 1 |
| 26007 | compones | 1 |
| 26008 | componen | 1 |
| 26009 | compondría | 1 |
| 26010 | compondremos | 1 |
| 26011 | complicar | 1 |
| 26012 | complicado | 1 |
| 26013 | complicadas | 1 |
| 26014 | complicaciones | 1 |
| 26015 | completos | 1 |
| 26016 | completó | 1 |
| 26017 | completas | 1 |
| 26018 | completado | 1 |
| 26019 | complemento | 1 |
| 26020 | compleja | 1 |
| 26021 | complaciéndose | 1 |
| 26022 | complacido | 1 |
| 26023 | complacidísima | 1 |
| 26024 | complacida | 1 |
| 26025 | complacía | 1 |
| 26026 | complacerle | 1 |
| 26027 | complacerla | 1 |
| 26028 | complacer | 1 |
| 26029 | complacencias | 1 |
| 26030 | complace | 1 |
| 26031 | competir | 1 |
| 26032 | competidores | 1 |
| 26033 | competía | 1 |
| 26034 | compensó | 1 |
| 26035 | compensar | 1 |
| 26036 | compenetraron | 1 |
| 26037 | compenetrando | 1 |
| 26038 | compatibles | 1 |
| 26039 | compatibilidad | 1 |
| 26040 | compasivos | 1 |
| 26041 | compases | 1 |
| 26042 | comparsas | 1 |
| 26043 | comparsa | 1 |
| 26044 | compare | 1 |
| 26045 | comparativos | 1 |
| 26046 | comparativo | 1 |
| 26047 | compararlo | 1 |
| 26048 | comparar | 1 |
| 26049 | comparando | 1 |
| 26050 | comparan | 1 |
| 26051 | comparaba | 1 |
| 26052 | compara | 1 |
| 26053 | compañerismo | 1 |
| 26054 | compaña | 1 |
| 26055 | compagina | 1 |
| 26056 | compadre | 1 |
| 26057 | compadeció | 1 |
| 26058 | compadecida | 1 |
| 26059 | compadécete | 1 |
| 26060 | compadecerte | 1 |
| 26061 | compadecerse | 1 |
| 26062 | compadecerle | 1 |
| 26063 | compactas | 1 |
| 26064 | cómodo | 1 |
| 26065 | comodidades | 1 |
| 26066 | cómodas | 1 |
| 26067 | comitentes | 1 |
| 26068 | comiteles | 1 |
| 26069 | comisuras | 1 |
| 26070 | comistrajo | 1 |
| 26071 | comistraje | 1 |
| 26072 | comisionados | 1 |
| 26073 | comiquito | 1 |
| 26074 | cominos | 1 |
| 26075 | comino | 1 |
| 26076 | comilonas | 1 |
| 26077 | comiéndoselo | 1 |
| 26078 | comiéndosele | 1 |
| 26079 | comiéndolo | 1 |
| 26080 | cómicamente | 1 |
| 26081 | comí | 1 |
| 26082 | comezones | 1 |
| 26083 | cometió | 1 |
| 26084 | cometieron | 1 |
| 26085 | cometiendo | 1 |
| 26086 | cometidos | 1 |
| 26087 | cometí | 1 |
| 26088 | cometerlas | 1 |
| 26089 | cometas | 1 |
| 26090 | cometa | 1 |
| 26091 | comérsele | 1 |
| 26092 | comérselas | 1 |
| 26093 | comérsela | 1 |
| 26094 | comerlos | 1 |
| 26095 | comerla | 1 |
| 26096 | comeré | 1 |
| 26097 | comercian | 1 |
| 26098 | comerás | 1 |
| 26099 | comerán | 1 |
| 26100 | comenzar | 1 |
| 26101 | comenzando | 1 |
| 26102 | comentos | 1 |
| 26103 | comentase | 1 |
| 26104 | comentando | 1 |
| 26105 | comenencias | 1 |
| 26106 | comenencia | 1 |
| 26107 | comemos | 1 |
| 26108 | cómeme | 1 |
| 26109 | comedido | 1 |
| 26110 | comediante | 1 |
| 26111 | comedianta | 1 |
| 26112 | combustión | 1 |
| 26113 | combustible | 1 |
| 26114 | combinada | 1 |
| 26115 | combinaba | 1 |
| 26116 | combina | 1 |
| 26117 | combatiente | 1 |
| 26118 | combatían | 1 |
| 26119 | combate | 1 |
| 26120 | comático | 1 |
| 26121 | comanditaria | 1 |
| 26122 | comadre | 1 |
| 26123 | columnarias | 1 |
| 26124 | columbró | 1 |
| 26125 | columbrar | 1 |
| 26126 | colose | 1 |
| 26127 | colosales | 1 |
| 26128 | colorete | 1 |
| 26129 | colorao | 1 |
| 26130 | coloradas | 1 |
| 26131 | coloquios | 1 |
| 26132 | colóqueme | 1 |
| 26133 | coloqué | 1 |
| 26134 | colón | 1 |
| 26135 | colocártelos | 1 |
| 26136 | colocarme | 1 |
| 26137 | colocarlo | 1 |
| 26138 | colocarle | 1 |
| 26139 | colocarlas | 1 |
| 26140 | colocao | 1 |
| 26141 | colocándose | 1 |
| 26142 | colocan | 1 |
| 26143 | colocaciones | 1 |
| 26144 | colocaban | 1 |
| 26145 | colocaba | 1 |
| 26146 | coló | 1 |
| 26147 | colmillo | 1 |
| 26148 | colmado | 1 |
| 26149 | collarines | 1 |
| 26150 | colisión | 1 |
| 26151 | coliseo | 1 |
| 26152 | colinas | 1 |
| 26153 | colina | 1 |
| 26154 | coligió | 1 |
| 26155 | coligieron | 1 |
| 26156 | coliflor | 1 |
| 26157 | colguemos | 1 |
| 26158 | colgarle | 1 |
| 26159 | colgaría | 1 |
| 26160 | colgara | 1 |
| 26161 | colgándosele | 1 |
| 26162 | colgándome | 1 |
| 26163 | colgajo | 1 |
| 26164 | colgadura | 1 |
| 26165 | coletazos | 1 |
| 26166 | coléricas | 1 |
| 26167 | colegios | 1 |
| 26168 | colegiata | 1 |
| 26169 | colectiva | 1 |
| 26170 | colectas | 1 |
| 26171 | coleccionistas | 1 |
| 26172 | coleccionista | 1 |
| 26173 | colecciones | 1 |
| 26174 | coleccionarlos | 1 |
| 26175 | colé | 1 |
| 26176 | colchón | 1 |
| 26177 | colarse | 1 |
| 26178 | colaríamos | 1 |
| 26179 | colaría | 1 |
| 26180 | colapso | 1 |
| 26181 | colado | 1 |
| 26182 | colada | 1 |
| 26183 | colaban | 1 |
| 26184 | colaba | 1 |
| 26185 | cojines | 1 |
| 26186 | cojera | 1 |
| 26187 | cojearás | 1 |
| 26188 | cojeaban | 1 |
| 26189 | coincidencia | 1 |
| 26190 | cohonestarse | 1 |
| 26191 | cohonestar | 1 |
| 26192 | cohibido | 1 |
| 26193 | cohibían | 1 |
| 26194 | cohibía | 1 |
| 26195 | cohete | 1 |
| 26196 | cogiste | 1 |
| 26197 | cogiola | 1 |
| 26198 | cogiese | 1 |
| 26199 | cogiéronse | 1 |
| 26200 | cogieran | 1 |
| 26201 | cogiéndolo | 1 |
| 26202 | cogiéndolas | 1 |
| 26203 | cogiditos | 1 |
| 26204 | cogerme | 1 |
| 26205 | cogerá | 1 |
| 26206 | cógelo | 1 |
| 26207 | cogéis | 1 |
| 26208 | cofradía | 1 |
| 26209 | cofrades | 1 |
| 26210 | codornices | 1 |
| 26211 | codillo | 1 |
| 26212 | código | 1 |
| 26213 | codificación | 1 |
| 26214 | codiciosas | 1 |
| 26215 | codiciado | 1 |
| 26216 | codicia | 1 |
| 26217 | coclearia | 1 |
| 26218 | cocinero | 1 |
| 26219 | cocidas | 1 |
| 26220 | cochino | 1 |
| 26221 | cochinamente | 1 |
| 26222 | cochinadas | 1 |
| 26223 | cochecillo | 1 |
| 26224 | coca | 1 |
| 26225 | cobró | 1 |
| 26226 | cobrase | 1 |
| 26227 | cobras | 1 |
| 26228 | cobraron | 1 |
| 26229 | cobraría | 1 |
| 26230 | cobran | 1 |
| 26231 | cobradores | 1 |
| 26232 | cobrado | 1 |
| 26233 | cobrábale | 1 |
| 26234 | cobraba | 1 |
| 26235 | cobardía | 1 |
| 26236 | cobardes | 1 |
| 26237 | cobalto | 1 |
| 26238 | co | 1 |
| 26239 | clubs | 1 |
| 26240 | cloral | 1 |
| 26241 | clima | 1 |
| 26242 | clientela | 1 |
| 26243 | clerofobia | 1 |
| 26244 | clericales | 1 |
| 26245 | clavetee | 1 |
| 26246 | claveteara | 1 |
| 26247 | claveteando | 1 |
| 26248 | claveteados | 1 |
| 26249 | claves | 1 |
| 26250 | clavel | 1 |
| 26251 | clave | 1 |
| 26252 | clavazón | 1 |
| 26253 | clavase | 1 |
| 26254 | clavársele | 1 |
| 26255 | clavarles | 1 |
| 26256 | clavarle | 1 |
| 26257 | clavarla | 1 |
| 26258 | clavándose | 1 |
| 26259 | clavamos | 1 |
| 26260 | clavaban | 1 |
| 26261 | claudio | 1 |
| 26262 | clasificar | 1 |
| 26263 | clásico | 1 |
| 26264 | clarísima | 1 |
| 26265 | clarines | 1 |
| 26266 | clarificado | 1 |
| 26267 | claridades | 1 |
| 26268 | claréate | 1 |
| 26269 | clareando | 1 |
| 26270 | clarea | 1 |
| 26271 | clandestinos | 1 |
| 26272 | clamor | 1 |
| 26273 | clamas | 1 |
| 26274 | clamaron | 1 |
| 26275 | clamaba | 1 |
| 26276 | clabos | 1 |
| 26277 | clabar | 1 |
| 26278 | civilizo | 1 |
| 26279 | civilizados | 1 |
| 26280 | civilizado | 1 |
| 26281 | civilizada | 1 |
| 26282 | civilizaciones | 1 |
| 26283 | civiles | 1 |
| 26284 | citutina | 1 |
| 26285 | citó | 1 |
| 26286 | citita | 1 |
| 26287 | cite | 1 |
| 26288 | citados | 1 |
| 26289 | cisne | 1 |
| 26290 | ciscos | 1 |
| 26291 | cirugía | 1 |
| 26292 | ciruelas | 1 |
| 26293 | cirineo | 1 |
| 26294 | cirilo | 1 |
| 26295 | circunspecto | 1 |
| 26296 | circunspección | 1 |
| 26297 | circunscrita | 1 |
| 26298 | circunloquios | 1 |
| 26299 | circunferencias | 1 |
| 26300 | circundan | 1 |
| 26301 | circulito | 1 |
| 26302 | circulaban | 1 |
| 26303 | circo | 1 |
| 26304 | cinturón | 1 |
| 26305 | cinturas | 1 |
| 26306 | cintajos | 1 |
| 26307 | cincuentona | 1 |
| 26308 | cimbros | 1 |
| 26309 | cimarra | 1 |
| 26310 | cima | 1 |
| 26311 | cilindro | 1 |
| 26312 | cilicio | 1 |
| 26313 | cigüeña | 1 |
| 26314 | cigarrillos | 1 |
| 26315 | cierro | 1 |
| 26316 | cierre | 1 |
| 26317 | cierras | 1 |
| 26318 | cieno | 1 |
| 26319 | cienfuegos | 1 |
| 26320 | cielito | 1 |
| 26321 | cicutina | 1 |
| 26322 | ciclón | 1 |
| 26323 | cicerone | 1 |
| 26324 | cicerón | 1 |
| 26325 | cicatriz | 1 |
| 26326 | cicatrices | 1 |
| 26327 | cicateros | 1 |
| 26328 | cibeles | 1 |
| 26329 | cianuro | 1 |
| 26330 | chuzo | 1 |
| 26331 | chuscada | 1 |
| 26332 | chusca | 1 |
| 26333 | churruca | 1 |
| 26334 | chupe | 1 |
| 26335 | chupase | 1 |
| 26336 | chupas | 1 |
| 26337 | chuparse | 1 |
| 26338 | chuparla | 1 |
| 26339 | chupar | 1 |
| 26340 | chupan | 1 |
| 26341 | chupado | 1 |
| 26342 | chupada | 1 |
| 26343 | chulito | 1 |
| 26344 | chulesca | 1 |
| 26345 | chula | 1 |
| 26346 | chu | 1 |
| 26347 | christophorus | 1 |
| 26348 | chovelar | 1 |
| 26349 | chorreras | 1 |
| 26350 | chorrear | 1 |
| 26351 | chorreaba | 1 |
| 26352 | chorrea | 1 |
| 26353 | choquezuela | 1 |
| 26354 | chopos | 1 |
| 26355 | chocolatero | 1 |
| 26356 | chochos | 1 |
| 26357 | chocheemos | 1 |
| 26358 | chocarrera | 1 |
| 26359 | chocaron | 1 |
| 26360 | chocantes | 1 |
| 26361 | chocante | 1 |
| 26362 | chocaba | 1 |
| 26363 | choca | 1 |
| 26364 | chistosísima | 1 |
| 26365 | chisto | 1 |
| 26366 | chisteras | 1 |
| 26367 | chistasen | 1 |
| 26368 | chistaré | 1 |
| 26369 | chistara | 1 |
| 26370 | chispos | 1 |
| 26371 | chispazos | 1 |
| 26372 | chispa | 1 |
| 26373 | chismosos | 1 |
| 26374 | chismorreo | 1 |
| 26375 | chismorreando | 1 |
| 26376 | chismográfico | 1 |
| 26377 | chismajos | 1 |
| 26378 | chisgarabís | 1 |
| 26379 | chis | 1 |
| 26380 | chirrido | 1 |
| 26381 | chirlata | 1 |
| 26382 | chiripón | 1 |
| 26383 | chirimbolos | 1 |
| 26384 | chirigotas | 1 |
| 26385 | chiquitos | 1 |
| 26386 | chiquitito | 1 |
| 26387 | chiquitita | 1 |
| 26388 | chiquita | 1 |
| 26389 | chiquirrininas | 1 |
| 26390 | chiquillín | 1 |
| 26391 | chiquillería | 1 |
| 26392 | chinos | 1 |
| 26393 | chinescos | 1 |
| 26394 | chinescas | 1 |
| 26395 | chinesca | 1 |
| 26396 | chinchoso | 1 |
| 26397 | chinchón | 1 |
| 26398 | chinchillas | 1 |
| 26399 | chinas | 1 |
| 26400 | chillona | 1 |
| 26401 | chillón | 1 |
| 26402 | chille | 1 |
| 26403 | chifló | 1 |
| 26404 | chiflado | 1 |
| 26405 | chiflaba | 1 |
| 26406 | chicooo | 1 |
| 26407 | chichones | 1 |
| 26408 | chicha | 1 |
| 26409 | chavo | 1 |
| 26410 | chauvinisme | 1 |
| 26411 | chato | 1 |
| 26412 | chasquido | 1 |
| 26413 | chasqueado | 1 |
| 26414 | chasqueada | 1 |
| 26415 | charrán | 1 |
| 26416 | charoles | 1 |
| 26417 | charlatana | 1 |
| 26418 | charlatán | 1 |
| 26419 | charlaría | 1 |
| 26420 | charlaremos | 1 |
| 26421 | charlado | 1 |
| 26422 | charcos | 1 |
| 26423 | chaquetillas | 1 |
| 26424 | chapuzón | 1 |
| 26425 | chapuzarse | 1 |
| 26426 | chapuzaba | 1 |
| 26427 | chapurraba | 1 |
| 26428 | chapoteo | 1 |
| 26429 | chapoteaban | 1 |
| 26430 | chapapote | 1 |
| 26431 | chanfaina | 1 |
| 26432 | chancleta | 1 |
| 26433 | champignons | 1 |
| 26434 | chambritas | 1 |
| 26435 | chambra | 1 |
| 26436 | chambelán | 1 |
| 26437 | chalanescas | 1 |
| 26438 | chafé | 1 |
| 26439 | chafarrinones | 1 |
| 26440 | chafarle | 1 |
| 26441 | chachito | 1 |
| 26442 | chabacana | 1 |
| 26443 | cetro | 1 |
| 26444 | cetrería | 1 |
| 26445 | céspedes | 1 |
| 26446 | cesaran | 1 |
| 26447 | césar | 1 |
| 26448 | cesando | 1 |
| 26449 | cesa | 1 |
| 26450 | cerril | 1 |
| 26451 | cerrarse | 1 |
| 26452 | cerrarle | 1 |
| 26453 | cerraré | 1 |
| 26454 | cerrándose | 1 |
| 26455 | cerrándolos | 1 |
| 26456 | cerrándoles | 1 |
| 26457 | ceros | 1 |
| 26458 | cero | 1 |
| 26459 | cerezas | 1 |
| 26460 | ceremoniosas | 1 |
| 26461 | ceremoniosamente | 1 |
| 26462 | ceremoniosa | 1 |
| 26463 | cerebros | 1 |
| 26464 | cerdea | 1 |
| 26465 | cerda | 1 |
| 26466 | cercioró | 1 |
| 26467 | cercana | 1 |
| 26468 | cerámica | 1 |
| 26469 | cepillos | 1 |
| 26470 | cepillo | 1 |
| 26471 | cepa | 1 |
| 26472 | ceñuda | 1 |
| 26473 | ceñidas | 1 |
| 26474 | ceñía | 1 |
| 26475 | centuplicado | 1 |
| 26476 | centrípeto | 1 |
| 26477 | centrífuga | 1 |
| 26478 | centinelas | 1 |
| 26479 | centímetros | 1 |
| 26480 | centenes | 1 |
| 26481 | centenares | 1 |
| 26482 | centén | 1 |
| 26483 | centelleo | 1 |
| 26484 | cenó | 1 |
| 26485 | cenizas | 1 |
| 26486 | cenital | 1 |
| 26487 | cenefas | 1 |
| 26488 | cenas | 1 |
| 26489 | cenarían | 1 |
| 26490 | cenagosa | 1 |
| 26491 | cenado | 1 |
| 26492 | celitos | 1 |
| 26493 | célibe | 1 |
| 26494 | celibato | 1 |
| 26495 | celibatarios | 1 |
| 26496 | celestiales | 1 |
| 26497 | celeridad | 1 |
| 26498 | celemín | 1 |
| 26499 | celebro | 1 |
| 26500 | celebridades | 1 |
| 26501 | celebridad | 1 |
| 26502 | celebrarse | 1 |
| 26503 | celebrarlo | 1 |
| 26504 | celebrándose | 1 |
| 26505 | celebrado | 1 |
| 26506 | celebrada | 1 |
| 26507 | celebraban | 1 |
| 26508 | celdas | 1 |
| 26509 | celajes | 1 |
| 26510 | celaje | 1 |
| 26511 | celadas | 1 |
| 26512 | cejar | 1 |
| 26513 | ceguezuelo | 1 |
| 26514 | ceguera | 1 |
| 26515 | cegué | 1 |
| 26516 | cegarse | 1 |
| 26517 | cegarla | 1 |
| 26518 | cegado | 1 |
| 26519 | cefalálgicos | 1 |
| 26520 | cefalalgia | 1 |
| 26521 | cédula | 1 |
| 26522 | cede | 1 |
| 26523 | cedazo | 1 |
| 26524 | ceceoso | 1 |
| 26525 | ceceo | 1 |
| 26526 | cebón | 1 |
| 26527 | cebáronse | 1 |
| 26528 | cebados | 1 |
| 26529 | cebaba | 1 |
| 26530 | cazuelas | 1 |
| 26531 | cazó | 1 |
| 26532 | cazo | 1 |
| 26533 | cazarlo | 1 |
| 26534 | cazadores | 1 |
| 26535 | cazadas | 1 |
| 26536 | cazable | 1 |
| 26537 | cazaba | 1 |
| 26538 | cayose | 1 |
| 26539 | cayeron | 1 |
| 26540 | cayeran | 1 |
| 26541 | cavour | 1 |
| 26542 | caviles | 1 |
| 26543 | cavilando | 1 |
| 26544 | cavidades | 1 |
| 26545 | cavernoso | 1 |
| 26546 | cautivan | 1 |
| 26547 | cautivábale | 1 |
| 26548 | cauteloso | 1 |
| 26549 | causo | 1 |
| 26550 | causarle | 1 |
| 26551 | causaría | 1 |
| 26552 | causara | 1 |
| 26553 | causados | 1 |
| 26554 | causábale | 1 |
| 26555 | caudalito | 1 |
| 26556 | catre | 1 |
| 26557 | catoliquísima | 1 |
| 26558 | catolicismo | 1 |
| 26559 | católicamente | 1 |
| 26560 | cató | 1 |
| 26561 | catilinario | 1 |
| 26562 | caterva | 1 |
| 26563 | catequizas | 1 |
| 26564 | catequizador | 1 |
| 26565 | categórico | 1 |
| 26566 | categóricarnente | 1 |
| 26567 | categorías | 1 |
| 26568 | catedrática | 1 |
| 26569 | cátedras | 1 |
| 26570 | catecúmenos | 1 |
| 26571 | catecúmeno | 1 |
| 26572 | catecúmena | 1 |
| 26573 | caté | 1 |
| 26574 | catástrofes | 1 |
| 26575 | catarros | 1 |
| 26576 | catarral | 1 |
| 26577 | catarían | 1 |
| 26578 | catarata | 1 |
| 26579 | cataplasma | 1 |
| 26580 | cátalas | 1 |
| 26581 | catalanes | 1 |
| 26582 | catalanas | 1 |
| 26583 | catafalco | 1 |
| 26584 | cataduras | 1 |
| 26585 | catadura | 1 |
| 26586 | catador | 1 |
| 26587 | cataclismos | 1 |
| 26588 | cataba | 1 |
| 26589 | casullas | 1 |
| 26590 | casucha | 1 |
| 26591 | casualmente | 1 |
| 26592 | casualidades | 1 |
| 26593 | castro | 1 |
| 26594 | castrametación | 1 |
| 26595 | castiza | 1 |
| 26596 | castilla | 1 |
| 26597 | castigase | 1 |
| 26598 | castigas | 1 |
| 26599 | castigarles | 1 |
| 26600 | castigarle | 1 |
| 26601 | castigara | 1 |
| 26602 | castigando | 1 |
| 26603 | castigada | 1 |
| 26604 | castellana | 1 |
| 26605 | castas | 1 |
| 26606 | castañuelas | 1 |
| 26607 | castañeteo | 1 |
| 26608 | castañetazo | 1 |
| 26609 | castañas | 1 |
| 26610 | castamente | 1 |
| 26611 | casquillo | 1 |
| 26612 | casquería | 1 |
| 26613 | caspitina | 1 |
| 26614 | caspa | 1 |
| 26615 | casose | 1 |
| 26616 | casitas | 1 |
| 26617 | casinos | 1 |
| 26618 | casino | 1 |
| 26619 | casillas | 1 |
| 26620 | casilla | 1 |
| 26621 | casetas | 1 |
| 26622 | caserones | 1 |
| 26623 | caseras | 1 |
| 26624 | cascarones | 1 |
| 26625 | cascarla | 1 |
| 26626 | cascajo | 1 |
| 26627 | cascado | 1 |
| 26628 | cascadas | 1 |
| 26629 | casase | 1 |
| 26630 | casarle | 1 |
| 26631 | casarlas | 1 |
| 26632 | casarías | 1 |
| 26633 | casaré | 1 |
| 26634 | casaras | 1 |
| 26635 | casan | 1 |
| 26636 | casamientos | 1 |
| 26637 | cásale | 1 |
| 26638 | casaditas | 1 |
| 26639 | casadita | 1 |
| 26640 | cartuja | 1 |
| 26641 | cartuchos | 1 |
| 26642 | cartucho | 1 |
| 26643 | cartita | 1 |
| 26644 | carteros | 1 |
| 26645 | cartero | 1 |
| 26646 | cartelón | 1 |
| 26647 | cartel | 1 |
| 26648 | carteaba | 1 |
| 26649 | carruajes | 1 |
| 26650 | carrozas | 1 |
| 26651 | carrilleras | 1 |
| 26652 | carrillera | 1 |
| 26653 | carrilladas | 1 |
| 26654 | carretes | 1 |
| 26655 | carretero | 1 |
| 26656 | carretela | 1 |
| 26657 | carreras | 1 |
| 26658 | carraspeo | 1 |
| 26659 | carrascales | 1 |
| 26660 | carrasca | 1 |
| 26661 | carpinteros | 1 |
| 26662 | carpintero | 1 |
| 26663 | carpetazo | 1 |
| 26664 | carpetas | 1 |
| 26665 | carpeta | 1 |
| 26666 | carnicerías | 1 |
| 26667 | carnecitas | 1 |
| 26668 | carnavalesca | 1 |
| 26669 | carnavales | 1 |
| 26670 | carnaval | 1 |
| 26671 | carminoso | 1 |
| 26672 | carmesí | 1 |
| 26673 | cariñitos | 1 |
| 26674 | caricatura | 1 |
| 26675 | caribes | 1 |
| 26676 | caribe | 1 |
| 26677 | cariacontecido | 1 |
| 26678 | cargos | 1 |
| 26679 | cargas | 1 |
| 26680 | cargarse | 1 |
| 26681 | cargarlo | 1 |
| 26682 | cargarás | 1 |
| 26683 | cargara | 1 |
| 26684 | cargábanle | 1 |
| 26685 | caretas | 1 |
| 26686 | careciese | 1 |
| 26687 | careciendo | 1 |
| 26688 | cardos | 1 |
| 26689 | cardo | 1 |
| 26690 | cardiaca | 1 |
| 26691 | cardarle | 1 |
| 26692 | carcundas | 1 |
| 26693 | carcunda | 1 |
| 26694 | carcomida | 1 |
| 26695 | cárceles | 1 |
| 26696 | carceleros | 1 |
| 26697 | carcelero | 1 |
| 26698 | carcajadita | 1 |
| 26699 | carca | 1 |
| 26700 | caraiter | 1 |
| 26701 | caracterizar | 1 |
| 26702 | caracterizan | 1 |
| 26703 | característicos | 1 |
| 26704 | característica | 1 |
| 26705 | caracolitos | 1 |
| 26706 | carabanchel | 1 |
| 26707 | capuchoncitos | 1 |
| 26708 | captura | 1 |
| 26709 | caprichosos | 1 |
| 26710 | caprichoso | 1 |
| 26711 | caprichosa | 1 |
| 26712 | capote | 1 |
| 26713 | capotas | 1 |
| 26714 | capítulos | 1 |
| 26715 | capitanes | 1 |
| 26716 | capitaneadas | 1 |
| 26717 | capitán | 1 |
| 26718 | capitalizaba | 1 |
| 26719 | capitalazo | 1 |
| 26720 | capitación | 1 |
| 26721 | capita | 1 |
| 26722 | capillas | 1 |
| 26723 | capearlo | 1 |
| 26724 | capcioso | 1 |
| 26725 | capciosa | 1 |
| 26726 | caño | 1 |
| 26727 | cañí | 1 |
| 26728 | cañamoncito | 1 |
| 26729 | cañamazo | 1 |
| 26730 | canturriaba | 1 |
| 26731 | cantorrios | 1 |
| 26732 | cantor | 1 |
| 26733 | cantones | 1 |
| 26734 | cantonalismo | 1 |
| 26735 | cantó | 1 |
| 26736 | cantina | 1 |
| 26737 | canterac | 1 |
| 26738 | canten | 1 |
| 26739 | cantazo | 1 |
| 26740 | cantase | 1 |
| 26741 | cántaros | 1 |
| 26742 | cantarle | 1 |
| 26743 | cantaré | 1 |
| 26744 | cantará | 1 |
| 26745 | cantantes | 1 |
| 26746 | cantante | 1 |
| 26747 | cántale | 1 |
| 26748 | cantado | 1 |
| 26749 | cantadas | 1 |
| 26750 | cantábrico | 1 |
| 26751 | cantabile | 1 |
| 26752 | cantaban | 1 |
| 26753 | canses | 1 |
| 26754 | cansemos | 1 |
| 26755 | cansaron | 1 |
| 26756 | cansarme | 1 |
| 26757 | cansarás | 1 |
| 26758 | cansará | 1 |
| 26759 | cansando | 1 |
| 26760 | cansamos | 1 |
| 26761 | cansadita | 1 |
| 26762 | cansábase | 1 |
| 26763 | canonjías | 1 |
| 26764 | canonizarlas | 1 |
| 26765 | canonizaremos | 1 |
| 26766 | canonizar | 1 |
| 26767 | canonizada | 1 |
| 26768 | canonizable | 1 |
| 26769 | canonizaban | 1 |
| 26770 | canon | 1 |
| 26771 | canina | 1 |
| 26772 | canillas | 1 |
| 26773 | canijo | 1 |
| 26774 | caníbales | 1 |
| 26775 | candorosa | 1 |
| 26776 | candilones | 1 |
| 26777 | candil | 1 |
| 26778 | candidez | 1 |
| 26779 | candideces | 1 |
| 26780 | candidatura | 1 |
| 26781 | candidato | 1 |
| 26782 | cándidas | 1 |
| 26783 | candeleros | 1 |
| 26784 | candelero | 1 |
| 26785 | candelas | 1 |
| 26786 | candados | 1 |
| 26787 | canciones | 1 |
| 26788 | cancillerías | 1 |
| 26789 | canceles | 1 |
| 26790 | cancelación | 1 |
| 26791 | cancamurria | 1 |
| 26792 | canastos | 1 |
| 26793 | canasto | 1 |
| 26794 | canastas | 1 |
| 26795 | canarios | 1 |
| 26796 | canarias | 1 |
| 26797 | canapé | 1 |
| 26798 | canallas | 1 |
| 26799 | canallada | 1 |
| 26800 | canalejas | 1 |
| 26801 | camús | 1 |
| 26802 | camuesa | 1 |
| 26803 | camposanto | 1 |
| 26804 | campestre | 1 |
| 26805 | campesinos | 1 |
| 26806 | campaneo | 1 |
| 26807 | campanas | 1 |
| 26808 | campanarios | 1 |
| 26809 | camita | 1 |
| 26810 | camisolas | 1 |
| 26811 | camiones | 1 |
| 26812 | caminatas | 1 |
| 26813 | caminando | 1 |
| 26814 | camilla | 1 |
| 26815 | camellos | 1 |
| 26816 | cambias | 1 |
| 26817 | cambiarte | 1 |
| 26818 | cambiaran | 1 |
| 26819 | cambiándolos | 1 |
| 26820 | cambiándolo | 1 |
| 26821 | cambiada | 1 |
| 26822 | camarín | 1 |
| 26823 | camarilla | 1 |
| 26824 | camarero | 1 |
| 26825 | camarera | 1 |
| 26826 | camará | 1 |
| 26827 | camaleones | 1 |
| 26828 | calzoncillos | 1 |
| 26829 | calzarse | 1 |
| 26830 | calzará | 1 |
| 26831 | calzan | 1 |
| 26832 | calzaba | 1 |
| 26833 | calvo | 1 |
| 26834 | calvinista | 1 |
| 26835 | calumniaste | 1 |
| 26836 | calumniadora | 1 |
| 26837 | calumniador | 1 |
| 26838 | calorcillo | 1 |
| 26839 | calo | 1 |
| 26840 | calme | 1 |
| 26841 | cálmate | 1 |
| 26842 | calmándose | 1 |
| 26843 | calmando | 1 |
| 26844 | calman | 1 |
| 26845 | calmado | 1 |
| 26846 | callémonos | 1 |
| 26847 | callejero | 1 |
| 26848 | callejeras | 1 |
| 26849 | callejas | 1 |
| 26850 | callé | 1 |
| 26851 | cállatela | 1 |
| 26852 | callas | 1 |
| 26853 | callarte | 1 |
| 26854 | callaría | 1 |
| 26855 | callaré | 1 |
| 26856 | callara | 1 |
| 26857 | callao | 1 |
| 26858 | callan | 1 |
| 26859 | callaíto | 1 |
| 26860 | calladitos | 1 |
| 26861 | cáliz | 1 |
| 26862 | caligráficos | 1 |
| 26863 | caligrafía | 1 |
| 26864 | calificó | 1 |
| 26865 | calificar | 1 |
| 26866 | calificado | 1 |
| 26867 | calientes | 1 |
| 26868 | calienta | 1 |
| 26869 | calidades | 1 |
| 26870 | calidá | 1 |
| 26871 | calenturienta | 1 |
| 26872 | calenturas | 1 |
| 26873 | calentito | 1 |
| 26874 | calentitas | 1 |
| 26875 | calentita | 1 |
| 26876 | calenté | 1 |
| 26877 | calentaste | 1 |
| 26878 | calentarte | 1 |
| 26879 | calentármela | 1 |
| 26880 | calentarlo | 1 |
| 26881 | calentarle | 1 |
| 26882 | calentándome | 1 |
| 26883 | calentándolo | 1 |
| 26884 | calendario | 1 |
| 26885 | caldito | 1 |
| 26886 | calderón | 1 |
| 26887 | calderería | 1 |
| 26888 | caldeos | 1 |
| 26889 | caldeando | 1 |
| 26890 | caldeaba | 1 |
| 26891 | calculó | 1 |
| 26892 | calculé | 1 |
| 26893 | calculas | 1 |
| 26894 | calcular | 1 |
| 26895 | calculada | 1 |
| 26896 | calculaba | 1 |
| 26897 | calco | 1 |
| 26898 | calcetín | 1 |
| 26899 | calceta | 1 |
| 26900 | calcárea | 1 |
| 26901 | calaveras | 1 |
| 26902 | calatravas | 1 |
| 26903 | calatrava | 1 |
| 26904 | calandrias | 1 |
| 26905 | calandria | 1 |
| 26906 | calándoselos | 1 |
| 26907 | calándose | 1 |
| 26908 | calaínos | 1 |
| 26909 | calainos | 1 |
| 26910 | calabazas | 1 |
| 26911 | calábase | 1 |
| 26912 | calaba | 1 |
| 26913 | cajista | 1 |
| 26914 | cajetilla | 1 |
| 26915 | caíste | 1 |
| 26916 | caímos | 1 |
| 26917 | caíme | 1 |
| 26918 | caídos | 1 |
| 26919 | cafres | 1 |
| 26920 | cafre | 1 |
| 26921 | cafeteros | 1 |
| 26922 | caería | 1 |
| 26923 | caerán | 1 |
| 26924 | caenas | 1 |
| 26925 | caemos | 1 |
| 26926 | caduca | 1 |
| 26927 | cadmio | 1 |
| 26928 | cadera | 1 |
| 26929 | cadencioso | 1 |
| 26930 | cadencias | 1 |
| 26931 | cadenas | 1 |
| 26932 | cadavérica | 1 |
| 26933 | cadávere | 1 |
| 26934 | cacumen | 1 |
| 26935 | caciquismo | 1 |
| 26936 | cachucha | 1 |
| 26937 | cachorros | 1 |
| 26938 | cachorro | 1 |
| 26939 | cachete | 1 |
| 26940 | cacharrería | 1 |
| 26941 | cacerolas | 1 |
| 26942 | cacerola | 1 |
| 26943 | cacareo | 1 |
| 26944 | cacarearlo | 1 |
| 26945 | cacao | 1 |
| 26946 | cacahuetes | 1 |
| 26947 | cabrón | 1 |
| 26948 | cabritos | 1 |
| 26949 | cabriolas | 1 |
| 26950 | cable | 1 |
| 26951 | cabizbaja | 1 |
| 26952 | cabida | 1 |
| 26953 | cabestrillo | 1 |
| 26954 | caben | 1 |
| 26955 | cabellerías | 1 |
| 26956 | cabecilla | 1 |
| 26957 | cabañas | 1 |
| 26958 | caballista | 1 |
| 26959 | caballerizas | 1 |
| 26960 | caballerías | 1 |
| 26961 | caballerete | 1 |
| 26962 | caballeresca | 1 |
| 26963 | cabalitos | 1 |
| 26964 | ca | 1 |
| 26965 | bustos | 1 |
| 26966 | buscona | 1 |
| 26967 | buscón | 1 |
| 26968 | buscaste | 1 |
| 26969 | buscase | 1 |
| 26970 | buscarte | 1 |
| 26971 | buscaron | 1 |
| 26972 | buscármelo | 1 |
| 26973 | buscaríamos | 1 |
| 26974 | buscaremos | 1 |
| 26975 | buscaran | 1 |
| 26976 | buscándola | 1 |
| 26977 | buscada | 1 |
| 26978 | buscaban | 1 |
| 26979 | burris | 1 |
| 26980 | burra | 1 |
| 26981 | burocracia | 1 |
| 26982 | burlones | 1 |
| 26983 | burlón | 1 |
| 26984 | burlen | 1 |
| 26985 | búrlate | 1 |
| 26986 | burlasen | 1 |
| 26987 | burlándose | 1 |
| 26988 | burlando | 1 |
| 26989 | burlan | 1 |
| 26990 | burladores | 1 |
| 26991 | burlado | 1 |
| 26992 | burlaban | 1 |
| 26993 | burguesía | 1 |
| 26994 | burgués | 1 |
| 26995 | burbujeaba | 1 |
| 26996 | buque | 1 |
| 26997 | buñuelo | 1 |
| 26998 | bulliciosos | 1 |
| 26999 | bulliciosa | 1 |
| 27000 | bullangas | 1 |
| 27001 | bullanga | 1 |
| 27002 | buleros | 1 |
| 27003 | bulas | 1 |
| 27004 | bula | 1 |
| 27005 | bufón | 1 |
| 27006 | bufidos | 1 |
| 27007 | bufando | 1 |
| 27008 | bufandas | 1 |
| 27009 | bufaban | 1 |
| 27010 | bufaba | 1 |
| 27011 | budistas | 1 |
| 27012 | budista | 1 |
| 27013 | bucólica | 1 |
| 27014 | bruta | 1 |
| 27015 | bruscos | 1 |
| 27016 | brusco | 1 |
| 27017 | bruscas | 1 |
| 27018 | bruños | 1 |
| 27019 | bruñido | 1 |
| 27020 | bruñida | 1 |
| 27021 | brujerías | 1 |
| 27022 | brrrr | 1 |
| 27023 | brrr | 1 |
| 27024 | brr | 1 |
| 27025 | broza | 1 |
| 27026 | brotó | 1 |
| 27027 | brotes | 1 |
| 27028 | brotaran | 1 |
| 27029 | brotando | 1 |
| 27030 | brotan | 1 |
| 27031 | brotado | 1 |
| 27032 | brotaban | 1 |
| 27033 | broncíneos | 1 |
| 27034 | broncas | 1 |
| 27035 | bromista | 1 |
| 27036 | bromee | 1 |
| 27037 | bromeas | 1 |
| 27038 | bromeando | 1 |
| 27039 | brochazos | 1 |
| 27040 | brochase | 1 |
| 27041 | brocados | 1 |
| 27042 | brocado | 1 |
| 27043 | brisca | 1 |
| 27044 | brindarles | 1 |
| 27045 | brincando | 1 |
| 27046 | brillantísima | 1 |
| 27047 | brillantez | 1 |
| 27048 | brihuega | 1 |
| 27049 | bribones | 1 |
| 27050 | bribonada | 1 |
| 27051 | breviarios | 1 |
| 27052 | brevedad | 1 |
| 27053 | brevas | 1 |
| 27054 | bregué | 1 |
| 27055 | bregaron | 1 |
| 27056 | brega | 1 |
| 27057 | brebajes | 1 |
| 27058 | brazadas | 1 |
| 27059 | braveza | 1 |
| 27060 | braserón | 1 |
| 27061 | brasas | 1 |
| 27062 | branco | 1 |
| 27063 | bramante | 1 |
| 27064 | bramaba | 1 |
| 27065 | bracmánica | 1 |
| 27066 | bracitos | 1 |
| 27067 | bracete | 1 |
| 27068 | bracero | 1 |
| 27069 | braceaban | 1 |
| 27070 | bozal | 1 |
| 27071 | boya | 1 |
| 27072 | boxear | 1 |
| 27073 | box | 1 |
| 27074 | botoneras | 1 |
| 27075 | botita | 1 |
| 27076 | boticarito | 1 |
| 27077 | boticarios | 1 |
| 27078 | boticarín | 1 |
| 27079 | botes | 1 |
| 27080 | botellazo | 1 |
| 27081 | bote | 1 |
| 27082 | botaratadas | 1 |
| 27083 | botaratada | 1 |
| 27084 | botánica | 1 |
| 27085 | bostezo | 1 |
| 27086 | bostezando | 1 |
| 27087 | bosquejada | 1 |
| 27088 | borrosas | 1 |
| 27089 | borrosa | 1 |
| 27090 | borro | 1 |
| 27091 | borriqueros | 1 |
| 27092 | borricales | 1 |
| 27093 | borricada | 1 |
| 27094 | borre | 1 |
| 27095 | borrascosos | 1 |
| 27096 | borrarlas | 1 |
| 27097 | borrara | 1 |
| 27098 | borran | 1 |
| 27099 | borrachas | 1 |
| 27100 | borracha | 1 |
| 27101 | borraban | 1 |
| 27102 | borraba | 1 |
| 27103 | borlita | 1 |
| 27104 | borleo | 1 |
| 27105 | borgias | 1 |
| 27106 | bordo | 1 |
| 27107 | bordaron | 1 |
| 27108 | bordar | 1 |
| 27109 | bordan | 1 |
| 27110 | bordadores | 1 |
| 27111 | bordador | 1 |
| 27112 | bordaban | 1 |
| 27113 | borbotones | 1 |
| 27114 | borbones | 1 |
| 27115 | boqueás | 1 |
| 27116 | boqueadas | 1 |
| 27117 | boquea | 1 |
| 27118 | bonitísima | 1 |
| 27119 | bonitamente | 1 |
| 27120 | bonísimo | 1 |
| 27121 | bonísima | 1 |
| 27122 | bonillas | 1 |
| 27123 | bonibus | 1 |
| 27124 | bondadosamente | 1 |
| 27125 | bonancibles | 1 |
| 27126 | bolsas | 1 |
| 27127 | bolos | 1 |
| 27128 | bollos | 1 |
| 27129 | bollo | 1 |
| 27130 | bollero | 1 |
| 27131 | bollería | 1 |
| 27132 | bólido | 1 |
| 27133 | boletín | 1 |
| 27134 | bohardillón | 1 |
| 27135 | bohardillas | 1 |
| 27136 | bocona | 1 |
| 27137 | bochorno | 1 |
| 27138 | bocanadas | 1 |
| 27139 | bobones | 1 |
| 27140 | bobona | 1 |
| 27141 | bobón | 1 |
| 27142 | boberías | 1 |
| 27143 | bobería | 1 |
| 27144 | bobadas | 1 |
| 27145 | bloques | 1 |
| 27146 | blondas | 1 |
| 27147 | blinco | 1 |
| 27148 | blasonados | 1 |
| 27149 | blasfemo | 1 |
| 27150 | blasfemando | 1 |
| 27151 | blanquecina | 1 |
| 27152 | blanqueará | 1 |
| 27153 | blanquear | 1 |
| 27154 | blanquean | 1 |
| 27155 | blanqueado | 1 |
| 27156 | blandura | 1 |
| 27157 | blandamente | 1 |
| 27158 | bizmas | 1 |
| 27159 | bizma | 1 |
| 27160 | bizcochitos | 1 |
| 27161 | bizcochito | 1 |
| 27162 | bizco | 1 |
| 27163 | bizcas | 1 |
| 27164 | bizcando | 1 |
| 27165 | bizca | 1 |
| 27166 | bizantinas | 1 |
| 27167 | bisteques | 1 |
| 27168 | bisoño | 1 |
| 27169 | bismark | 1 |
| 27170 | bismarck | 1 |
| 27171 | birmingham | 1 |
| 27172 | birló | 1 |
| 27173 | birlado | 1 |
| 27174 | birla | 1 |
| 27175 | biricornio | 1 |
| 27176 | biombo | 1 |
| 27177 | billetito | 1 |
| 27178 | bilbao | 1 |
| 27179 | bigotito | 1 |
| 27180 | bigotes | 1 |
| 27181 | bigotera | 1 |
| 27182 | bifurcación | 1 |
| 27183 | biftec | 1 |
| 27184 | bienhechora | 1 |
| 27185 | bienaventuranza | 1 |
| 27186 | bienaventurado | 1 |
| 27187 | bienandanzas | 1 |
| 27188 | bienandanza | 1 |
| 27189 | bicoca | 1 |
| 27190 | bichos | 1 |
| 27191 | bichito | 1 |
| 27192 | bíblico | 1 |
| 27193 | betsabée | 1 |
| 27194 | besuqueó | 1 |
| 27195 | besuqueo | 1 |
| 27196 | besuqueándose | 1 |
| 27197 | besugos | 1 |
| 27198 | besárselos | 1 |
| 27199 | besaron | 1 |
| 27200 | besarla | 1 |
| 27201 | besándose | 1 |
| 27202 | besando | 1 |
| 27203 | besan | 1 |
| 27204 | besamanos | 1 |
| 27205 | besadlas | 1 |
| 27206 | besadera | 1 |
| 27207 | besaba | 1 |
| 27208 | besa | 1 |
| 27209 | berza | 1 |
| 27210 | berrugones | 1 |
| 27211 | berroqueñas | 1 |
| 27212 | berro | 1 |
| 27213 | berreando | 1 |
| 27214 | bermingán | 1 |
| 27215 | bergantes | 1 |
| 27216 | bergante | 1 |
| 27217 | bergantas | 1 |
| 27218 | berganta | 1 |
| 27219 | berdan | 1 |
| 27220 | benignita | 1 |
| 27221 | benignidad | 1 |
| 27222 | benévolos | 1 |
| 27223 | benévolo | 1 |
| 27224 | benevolencias | 1 |
| 27225 | benévolamente | 1 |
| 27226 | benéficos | 1 |
| 27227 | beneficios | 1 |
| 27228 | benéfica | 1 |
| 27229 | bendijo | 1 |
| 27230 | bendigo | 1 |
| 27231 | bendiciendo | 1 |
| 27232 | bendicen | 1 |
| 27233 | bendecirá | 1 |
| 27234 | bendecidas | 1 |
| 27235 | bemol | 1 |
| 27236 | bellotes | 1 |
| 27237 | bellotas | 1 |
| 27238 | bellota | 1 |
| 27239 | bello | 1 |
| 27240 | belladona | 1 |
| 27241 | belicosas | 1 |
| 27242 | belfort | 1 |
| 27243 | belencita | 1 |
| 27244 | beldad | 1 |
| 27245 | begonias | 1 |
| 27246 | befa | 1 |
| 27247 | becerradas | 1 |
| 27248 | bebimos | 1 |
| 27249 | bebiese | 1 |
| 27250 | bebieron | 1 |
| 27251 | bebiera | 1 |
| 27252 | bebiéndola | 1 |
| 27253 | bebiendo | 1 |
| 27254 | bebí | 1 |
| 27255 | beberse | 1 |
| 27256 | beberías | 1 |
| 27257 | bebería | 1 |
| 27258 | beberé | 1 |
| 27259 | beben | 1 |
| 27260 | bebedor | 1 |
| 27261 | bebé | 1 |
| 27262 | beba | 1 |
| 27263 | beatos | 1 |
| 27264 | beato | 1 |
| 27265 | beata | 1 |
| 27266 | baztán | 1 |
| 27267 | bazofias | 1 |
| 27268 | bazofia | 1 |
| 27269 | bautizos | 1 |
| 27270 | bautizaré | 1 |
| 27271 | bautizan | 1 |
| 27272 | batuta | 1 |
| 27273 | batón | 1 |
| 27274 | batlló | 1 |
| 27275 | batita | 1 |
| 27276 | batista | 1 |
| 27277 | batirse | 1 |
| 27278 | batirme | 1 |
| 27279 | batiéndose | 1 |
| 27280 | batiéndola | 1 |
| 27281 | batido | 1 |
| 27282 | batidas | 1 |
| 27283 | bate | 1 |
| 27284 | batallitas | 1 |
| 27285 | batahola | 1 |
| 27286 | batacazo | 1 |
| 27287 | bastó | 1 |
| 27288 | bastiones | 1 |
| 27289 | bastimentos | 1 |
| 27290 | bastiat | 1 |
| 27291 | baste | 1 |
| 27292 | bastaría | 1 |
| 27293 | bastardos | 1 |
| 27294 | bastar | 1 |
| 27295 | bastándoles | 1 |
| 27296 | bastándole | 1 |
| 27297 | basílica | 1 |
| 27298 | basilea | 1 |
| 27299 | báscula | 1 |
| 27300 | bascas | 1 |
| 27301 | basamento | 1 |
| 27302 | basadas | 1 |
| 27303 | bártulos | 1 |
| 27304 | barruntó | 1 |
| 27305 | barroquismo | 1 |
| 27306 | barrilitos | 1 |
| 27307 | barrigón | 1 |
| 27308 | barrieran | 1 |
| 27309 | barriendo | 1 |
| 27310 | barrido | 1 |
| 27311 | barrida | 1 |
| 27312 | barría | 1 |
| 27313 | barrerme | 1 |
| 27314 | barrerle | 1 |
| 27315 | barreremos | 1 |
| 27316 | barrenos | 1 |
| 27317 | barrendero | 1 |
| 27318 | barreduras | 1 |
| 27319 | barre | 1 |
| 27320 | barranco | 1 |
| 27321 | barrancas | 1 |
| 27322 | barrabasadas | 1 |
| 27323 | barrabasada | 1 |
| 27324 | barquitos | 1 |
| 27325 | barquito | 1 |
| 27326 | barquinazo | 1 |
| 27327 | baronesa | 1 |
| 27328 | barón | 1 |
| 27329 | barniz | 1 |
| 27330 | barnices | 1 |
| 27331 | bargueño | 1 |
| 27332 | bardales | 1 |
| 27333 | barcia | 1 |
| 27334 | barca | 1 |
| 27335 | barbilla | 1 |
| 27336 | barbianas | 1 |
| 27337 | barbería | 1 |
| 27338 | baratillos | 1 |
| 27339 | barástolis | 1 |
| 27340 | barajaban | 1 |
| 27341 | baraja | 1 |
| 27342 | bar | 1 |
| 27343 | baqueteados | 1 |
| 27344 | bañándose | 1 |
| 27345 | bañado | 1 |
| 27346 | banquetas | 1 |
| 27347 | banquero | 1 |
| 27348 | bandoleros | 1 |
| 27349 | banderita | 1 |
| 27350 | banderillero | 1 |
| 27351 | bandejas | 1 |
| 27352 | bandas | 1 |
| 27353 | bandadas | 1 |
| 27354 | bandada | 1 |
| 27355 | banastas | 1 |
| 27356 | banasta | 1 |
| 27357 | baluarte | 1 |
| 27358 | balsain | 1 |
| 27359 | balsa | 1 |
| 27360 | ballesta | 1 |
| 27361 | baldón | 1 |
| 27362 | baldío | 1 |
| 27363 | baldada | 1 |
| 27364 | balda | 1 |
| 27365 | balconcillo | 1 |
| 27366 | balbucir | 1 |
| 27367 | balbucientes | 1 |
| 27368 | balbuciendo | 1 |
| 27369 | balbucía | 1 |
| 27370 | balas | 1 |
| 27371 | balandranes | 1 |
| 27372 | balandrán | 1 |
| 27373 | balancines | 1 |
| 27374 | balancín | 1 |
| 27375 | balanceos | 1 |
| 27376 | balanceó | 1 |
| 27377 | balancearse | 1 |
| 27378 | balanceara | 1 |
| 27379 | balanceándose | 1 |
| 27380 | balanceaban | 1 |
| 27381 | balance | 1 |
| 27382 | baladronada | 1 |
| 27383 | bajoncito | 1 |
| 27384 | bajita | 1 |
| 27385 | bajísimos | 1 |
| 27386 | bajezas | 1 |
| 27387 | bajeza | 1 |
| 27388 | bajase | 1 |
| 27389 | bajarla | 1 |
| 27390 | bajarían | 1 |
| 27391 | bajaría | 1 |
| 27392 | bajarán | 1 |
| 27393 | bajándola | 1 |
| 27394 | bajáis | 1 |
| 27395 | bajada | 1 |
| 27396 | bajábala | 1 |
| 27397 | bailoteando | 1 |
| 27398 | bailo | 1 |
| 27399 | bailly | 1 |
| 27400 | baillière | 1 |
| 27401 | bailara | 1 |
| 27402 | bailadas | 1 |
| 27403 | bailaban | 1 |
| 27404 | bailaba | 1 |
| 27405 | baguetilla | 1 |
| 27406 | bagaje | 1 |
| 27407 | badila | 1 |
| 27408 | bachillería | 1 |
| 27409 | bachiller | 1 |
| 27410 | baches | 1 |
| 27411 | babosa | 1 |
| 27412 | babilonia | 1 |
| 27413 | babieca | 1 |
| 27414 | babel | 1 |
| 27415 | b | 1 |
| 27416 | azuzándole | 1 |
| 27417 | azuzan | 1 |
| 27418 | azuzáis | 1 |
| 27419 | azuzado | 1 |
| 27420 | azulejos | 1 |
| 27421 | azulado | 1 |
| 27422 | azufre | 1 |
| 27423 | azucarillo | 1 |
| 27424 | azotando | 1 |
| 27425 | azotaina | 1 |
| 27426 | azotaban | 1 |
| 27427 | azota | 1 |
| 27428 | azares | 1 |
| 27429 | azalea | 1 |
| 27430 | azada | 1 |
| 27431 | aza | 1 |
| 27432 | ayunar | 1 |
| 27433 | ayunaba | 1 |
| 27434 | ayuna | 1 |
| 27435 | ayudemos | 1 |
| 27436 | ayúdeme | 1 |
| 27437 | ayudéis | 1 |
| 27438 | ayude | 1 |
| 27439 | ayudase | 1 |
| 27440 | ayudarte | 1 |
| 27441 | ayudáronla | 1 |
| 27442 | ayudarnos | 1 |
| 27443 | ayudarles | 1 |
| 27444 | ayudarle | 1 |
| 27445 | ayudarla | 1 |
| 27446 | ayudaría | 1 |
| 27447 | ayudaré | 1 |
| 27448 | ayudados | 1 |
| 27449 | avivar | 1 |
| 27450 | avispados | 1 |
| 27451 | avispado | 1 |
| 27452 | avispada | 1 |
| 27453 | avisó | 1 |
| 27454 | avisasteis | 1 |
| 27455 | avisaste | 1 |
| 27456 | avisaron | 1 |
| 27457 | avisaremos | 1 |
| 27458 | avisarás | 1 |
| 27459 | avisando | 1 |
| 27460 | avisado | 1 |
| 27461 | avisada | 1 |
| 27462 | avíos | 1 |
| 27463 | avine | 1 |
| 27464 | aviesa | 1 |
| 27465 | aviene | 1 |
| 27466 | avidez | 1 |
| 27467 | ávidas | 1 |
| 27468 | aviarme | 1 |
| 27469 | aviarla | 1 |
| 27470 | aviar | 1 |
| 27471 | averígüelo | 1 |
| 27472 | averiguase | 1 |
| 27473 | averiguarle | 1 |
| 27474 | averiguaría | 1 |
| 27475 | averiguaré | 1 |
| 27476 | averiguadores | 1 |
| 27477 | averiguador | 1 |
| 27478 | averiguaciones | 1 |
| 27479 | averiguación | 1 |
| 27480 | avergüenzo | 1 |
| 27481 | avergonzose | 1 |
| 27482 | avergonzó | 1 |
| 27483 | avergonzados | 1 |
| 27484 | aventurillas | 1 |
| 27485 | aventuremos | 1 |
| 27486 | aventurar | 1 |
| 27487 | aventurándose | 1 |
| 27488 | aventurábase | 1 |
| 27489 | aventajada | 1 |
| 27490 | aventaja | 1 |
| 27491 | avenida | 1 |
| 27492 | avenía | 1 |
| 27493 | avenencia | 1 |
| 27494 | avellana | 1 |
| 27495 | avasallador | 1 |
| 27496 | avaro | 1 |
| 27497 | avariciosa | 1 |
| 27498 | avanzadas | 1 |
| 27499 | avanzada | 1 |
| 27500 | auxiliase | 1 |
| 27501 | auxiliarse | 1 |
| 27502 | auxiliarla | 1 |
| 27503 | auxiliado | 1 |
| 27504 | autorizarme | 1 |
| 27505 | autorizan | 1 |
| 27506 | autorizado | 1 |
| 27507 | autorizada | 1 |
| 27508 | autoriza | 1 |
| 27509 | autoritarios | 1 |
| 27510 | autoritarias | 1 |
| 27511 | autoritariamente | 1 |
| 27512 | autorice | 1 |
| 27513 | autocrático | 1 |
| 27514 | autocrática | 1 |
| 27515 | autenticidad | 1 |
| 27516 | auténtica | 1 |
| 27517 | austerlitz | 1 |
| 27518 | austeridad | 1 |
| 27519 | auspicios | 1 |
| 27520 | ausento | 1 |
| 27521 | ausente | 1 |
| 27522 | ausentarme | 1 |
| 27523 | ausentándose | 1 |
| 27524 | ausculte | 1 |
| 27525 | auscultarle | 1 |
| 27526 | aurorita | 1 |
| 27527 | auroras | 1 |
| 27528 | aumentos | 1 |
| 27529 | aumente | 1 |
| 27530 | aumentase | 1 |
| 27531 | aumentaron | 1 |
| 27532 | aumentarlas | 1 |
| 27533 | aumentando | 1 |
| 27534 | auméntame | 1 |
| 27535 | aumentada | 1 |
| 27536 | augurios | 1 |
| 27537 | audición | 1 |
| 27538 | audacias | 1 |
| 27539 | atusó | 1 |
| 27540 | atusarte | 1 |
| 27541 | atusada | 1 |
| 27542 | aturullo | 1 |
| 27543 | aturullada | 1 |
| 27544 | aturdió | 1 |
| 27545 | aturdidísima | 1 |
| 27546 | atufo | 1 |
| 27547 | atropellos | 1 |
| 27548 | atropelló | 1 |
| 27549 | atropello | 1 |
| 27550 | atropellando | 1 |
| 27551 | atropellada | 1 |
| 27552 | atronaban | 1 |
| 27553 | atril | 1 |
| 27554 | atribuyeron | 1 |
| 27555 | atribuyéndole | 1 |
| 27556 | atrevidilla | 1 |
| 27557 | atreví | 1 |
| 27558 | atreverías | 1 |
| 27559 | atraviesa | 1 |
| 27560 | atravesósele | 1 |
| 27561 | atravesole | 1 |
| 27562 | atravesase | 1 |
| 27563 | atravesaron | 1 |
| 27564 | atravesándolo | 1 |
| 27565 | atravesándole | 1 |
| 27566 | atravesados | 1 |
| 27567 | atravesado | 1 |
| 27568 | atraso | 1 |
| 27569 | atrasados | 1 |
| 27570 | atrasaditos | 1 |
| 27571 | atrasa | 1 |
| 27572 | atrapo | 1 |
| 27573 | atrapado | 1 |
| 27574 | atrajo | 1 |
| 27575 | atraídos | 1 |
| 27576 | atraído | 1 |
| 27577 | atraída | 1 |
| 27578 | atraía | 1 |
| 27579 | atragantaban | 1 |
| 27580 | atracón | 1 |
| 27581 | atracciones | 1 |
| 27582 | atrácate | 1 |
| 27583 | atracaba | 1 |
| 27584 | atosigaba | 1 |
| 27585 | atormentó | 1 |
| 27586 | atormentarme | 1 |
| 27587 | atormentarle | 1 |
| 27588 | atormentarla | 1 |
| 27589 | atormentándole | 1 |
| 27590 | atormentada | 1 |
| 27591 | atormenta | 1 |
| 27592 | atontarse | 1 |
| 27593 | atónitos | 1 |
| 27594 | atonía | 1 |
| 27595 | atmosférico | 1 |
| 27596 | atletas | 1 |
| 27597 | atlas | 1 |
| 27598 | atizé | 1 |
| 27599 | atizándose | 1 |
| 27600 | atizado | 1 |
| 27601 | atisbos | 1 |
| 27602 | atisbando | 1 |
| 27603 | atisbadora | 1 |
| 27604 | atinado | 1 |
| 27605 | atinadas | 1 |
| 27606 | atildado | 1 |
| 27607 | atildada | 1 |
| 27608 | atiende | 1 |
| 27609 | atice | 1 |
| 27610 | atestiguó | 1 |
| 27611 | atestiguaban | 1 |
| 27612 | atestados | 1 |
| 27613 | aterrorizarla | 1 |
| 27614 | aterrorizada | 1 |
| 27615 | aterró | 1 |
| 27616 | aterrados | 1 |
| 27617 | aterradoras | 1 |
| 27618 | ateos | 1 |
| 27619 | atenuase | 1 |
| 27620 | atenuada | 1 |
| 27621 | atenuaciones | 1 |
| 27622 | atenuación | 1 |
| 27623 | atenuaba | 1 |
| 27624 | atenúa | 1 |
| 27625 | atentísimamente | 1 |
| 27626 | atentar | 1 |
| 27627 | ateneo | 1 |
| 27628 | atendió | 1 |
| 27629 | atendido | 1 |
| 27630 | atendidas | 1 |
| 27631 | atenazó | 1 |
| 27632 | atenazado | 1 |
| 27633 | atenazaba | 1 |
| 27634 | ateísmo | 1 |
| 27635 | ateas | 1 |
| 27636 | atavismo | 1 |
| 27637 | atavíen | 1 |
| 27638 | ataviarse | 1 |
| 27639 | atascó | 1 |
| 27640 | atascaban | 1 |
| 27641 | atarugándolo | 1 |
| 27642 | atarugaba | 1 |
| 27643 | ataros | 1 |
| 27644 | ataron | 1 |
| 27645 | atarme | 1 |
| 27646 | atarles | 1 |
| 27647 | atarla | 1 |
| 27648 | atarés | 1 |
| 27649 | atareado | 1 |
| 27650 | atañen | 1 |
| 27651 | atan | 1 |
| 27652 | atajarle | 1 |
| 27653 | atajar | 1 |
| 27654 | atajan | 1 |
| 27655 | atáis | 1 |
| 27656 | atadijo | 1 |
| 27657 | atacó | 1 |
| 27658 | atacar | 1 |
| 27659 | atacados | 1 |
| 27660 | atacada | 1 |
| 27661 | atacaba | 1 |
| 27662 | ata | 1 |
| 27663 | asustose | 1 |
| 27664 | asusté | 1 |
| 27665 | asustas | 1 |
| 27666 | asustarme | 1 |
| 27667 | asustaré | 1 |
| 27668 | asustaran | 1 |
| 27669 | asustando | 1 |
| 27670 | asustadísima | 1 |
| 27671 | asustadas | 1 |
| 27672 | asustábase | 1 |
| 27673 | asustaban | 1 |
| 27674 | asturias | 1 |
| 27675 | astucias | 1 |
| 27676 | astucia | 1 |
| 27677 | astros | 1 |
| 27678 | astronomía | 1 |
| 27679 | astro | 1 |
| 27680 | astilla | 1 |
| 27681 | asté | 1 |
| 27682 | asqueroso | 1 |
| 27683 | asquerosísimas | 1 |
| 27684 | asquerosidades | 1 |
| 27685 | aspires | 1 |
| 27686 | aspiradores | 1 |
| 27687 | aspiración | 1 |
| 27688 | aspiraban | 1 |
| 27689 | aspira | 1 |
| 27690 | ásperas | 1 |
| 27691 | aspaviento | 1 |
| 27692 | aspasia | 1 |
| 27693 | asomos | 1 |
| 27694 | asomo | 1 |
| 27695 | asomes | 1 |
| 27696 | asombrosa | 1 |
| 27697 | asombró | 1 |
| 27698 | asómbrese | 1 |
| 27699 | asombréis | 1 |
| 27700 | asombre | 1 |
| 27701 | asombráronse | 1 |
| 27702 | asombrarías | 1 |
| 27703 | asombrarás | 1 |
| 27704 | asombrándose | 1 |
| 27705 | asombrado | 1 |
| 27706 | asombraba | 1 |
| 27707 | asomase | 1 |
| 27708 | asomaron | 1 |
| 27709 | asomara | 1 |
| 27710 | asoma | 1 |
| 27711 | asoleado | 1 |
| 27712 | asociándolos | 1 |
| 27713 | asociadas | 1 |
| 27714 | asociada | 1 |
| 27715 | asociación | 1 |
| 27716 | asmático | 1 |
| 27717 | asistirle | 1 |
| 27718 | asistirla | 1 |
| 27719 | asistiría | 1 |
| 27720 | asistiendo | 1 |
| 27721 | asistido | 1 |
| 27722 | asistían | 1 |
| 27723 | asistente | 1 |
| 27724 | asín | 1 |
| 27725 | asimilan | 1 |
| 27726 | asimiladas | 1 |
| 27727 | asilados | 1 |
| 27728 | asignarle | 1 |
| 27729 | asignara | 1 |
| 27730 | asienta | 1 |
| 27731 | asiduos | 1 |
| 27732 | asiduo | 1 |
| 27733 | asida | 1 |
| 27734 | asiática | 1 |
| 27735 | asia | 1 |
| 27736 | aseveró | 1 |
| 27737 | asesinó | 1 |
| 27738 | asesinatos | 1 |
| 27739 | asesinando | 1 |
| 27740 | asesinado | 1 |
| 27741 | asesina | 1 |
| 27742 | aserrar | 1 |
| 27743 | aseñorado | 1 |
| 27744 | asentir | 1 |
| 27745 | asentía | 1 |
| 27746 | asensio | 1 |
| 27747 | asemejaban | 1 |
| 27748 | asemeja | 1 |
| 27749 | aseguremos | 1 |
| 27750 | asegure | 1 |
| 27751 | aseguraron | 1 |
| 27752 | asegurarla | 1 |
| 27753 | aseguraría | 1 |
| 27754 | aseguraran | 1 |
| 27755 | asegurándole | 1 |
| 27756 | asegúrame | 1 |
| 27757 | asegurado | 1 |
| 27758 | aseguradas | 1 |
| 27759 | aseadísima | 1 |
| 27760 | aseada | 1 |
| 27761 | ascua | 1 |
| 27762 | ascetismo | 1 |
| 27763 | ascensión | 1 |
| 27764 | ascendió | 1 |
| 27765 | ascendido | 1 |
| 27766 | asar | 1 |
| 27767 | asamblea | 1 |
| 27768 | asaltó | 1 |
| 27769 | asaltáronle | 1 |
| 27770 | asaltar | 1 |
| 27771 | asalta | 1 |
| 27772 | asadura | 1 |
| 27773 | asador | 1 |
| 27774 | asacristanado | 1 |
| 27775 | asaban | 1 |
| 27776 | asa | 1 |
| 27777 | artimañas | 1 |
| 27778 | artilleros | 1 |
| 27779 | artillería | 1 |
| 27780 | artificioso | 1 |
| 27781 | artificios | 1 |
| 27782 | artificiales | 1 |
| 27783 | articuló | 1 |
| 27784 | articulazo | 1 |
| 27785 | articularse | 1 |
| 27786 | articulando | 1 |
| 27787 | articulaciones | 1 |
| 27788 | articulación | 1 |
| 27789 | artesianos | 1 |
| 27790 | artesas | 1 |
| 27791 | artesano | 1 |
| 27792 | arsenioso | 1 |
| 27793 | arrumacos | 1 |
| 27794 | arrullo | 1 |
| 27795 | arrullas | 1 |
| 27796 | arrullándose | 1 |
| 27797 | arrullando | 1 |
| 27798 | arrullan | 1 |
| 27799 | arrullado | 1 |
| 27800 | arrullaban | 1 |
| 27801 | arrulla | 1 |
| 27802 | arruinen | 1 |
| 27803 | arruinaron | 1 |
| 27804 | arruinar | 1 |
| 27805 | arruinando | 1 |
| 27806 | arrugarse | 1 |
| 27807 | arrollado | 1 |
| 27808 | arrolla | 1 |
| 27809 | arrojo | 1 |
| 27810 | arroje | 1 |
| 27811 | arrojas | 1 |
| 27812 | arrojaron | 1 |
| 27813 | arrojarle | 1 |
| 27814 | arrojarla | 1 |
| 27815 | arrojándole | 1 |
| 27816 | arrojadas | 1 |
| 27817 | arrogantillo | 1 |
| 27818 | arrodillose | 1 |
| 27819 | arrodillaste | 1 |
| 27820 | arrodilladas | 1 |
| 27821 | arrobo | 1 |
| 27822 | arrobamientos | 1 |
| 27823 | arrobamiento | 1 |
| 27824 | arrimó | 1 |
| 27825 | arrimo | 1 |
| 27826 | arrimarse | 1 |
| 27827 | arrimándose | 1 |
| 27828 | arrimado | 1 |
| 27829 | arrimaban | 1 |
| 27830 | arriesgáronse | 1 |
| 27831 | arriesgados | 1 |
| 27832 | arrieros | 1 |
| 27833 | arriero | 1 |
| 27834 | arrepintiose | 1 |
| 27835 | arrepintiera | 1 |
| 27836 | arrepintiendo | 1 |
| 27837 | arrepiento | 1 |
| 27838 | arrepientes | 1 |
| 27839 | arrepienten | 1 |
| 27840 | arrepentirte | 1 |
| 27841 | arrepentimientos | 1 |
| 27842 | arreos | 1 |
| 27843 | arreo | 1 |
| 27844 | arrendaba | 1 |
| 27845 | arremangó | 1 |
| 27846 | arremangados | 1 |
| 27847 | arreglole | 1 |
| 27848 | arreglito | 1 |
| 27849 | arreglen | 1 |
| 27850 | arregléis | 1 |
| 27851 | arréglatelas | 1 |
| 27852 | arreglase | 1 |
| 27853 | arreglándose | 1 |
| 27854 | arréglame | 1 |
| 27855 | arreglados | 1 |
| 27856 | arregladitas | 1 |
| 27857 | arregladita | 1 |
| 27858 | arredraba | 1 |
| 27859 | arrecogidas | 1 |
| 27860 | arreciar | 1 |
| 27861 | arrechuchos | 1 |
| 27862 | arrebolada | 1 |
| 27863 | arrebatándole | 1 |
| 27864 | arreaba | 1 |
| 27865 | arrastró | 1 |
| 27866 | arrastrarse | 1 |
| 27867 | arrastraron | 1 |
| 27868 | arrastrarán | 1 |
| 27869 | arrastrándote | 1 |
| 27870 | arrastrándose | 1 |
| 27871 | arrastran | 1 |
| 27872 | arrastra | 1 |
| 27873 | arrasado | 1 |
| 27874 | arranqué | 1 |
| 27875 | arrancaron | 1 |
| 27876 | arrancarles | 1 |
| 27877 | arrancarla | 1 |
| 27878 | arrancándose | 1 |
| 27879 | arrancándolos | 1 |
| 27880 | arrancan | 1 |
| 27881 | arramblaron | 1 |
| 27882 | arramblaban | 1 |
| 27883 | arraigados | 1 |
| 27884 | arraigado | 1 |
| 27885 | arraigada | 1 |
| 27886 | arrabales | 1 |
| 27887 | arquitectónico | 1 |
| 27888 | arquitectónica | 1 |
| 27889 | arquitecto | 1 |
| 27890 | arqueos | 1 |
| 27891 | arqueólogo | 1 |
| 27892 | arqueológica | 1 |
| 27893 | arqueología | 1 |
| 27894 | arqueo | 1 |
| 27895 | arqueadas | 1 |
| 27896 | aros | 1 |
| 27897 | aroma | 1 |
| 27898 | arneses | 1 |
| 27899 | armose | 1 |
| 27900 | armonizar | 1 |
| 27901 | armonizando | 1 |
| 27902 | armonizadas | 1 |
| 27903 | armonizaba | 1 |
| 27904 | armoniosas | 1 |
| 27905 | armoniosa | 1 |
| 27906 | armónico | 1 |
| 27907 | armole | 1 |
| 27908 | armo | 1 |
| 27909 | armiño | 1 |
| 27910 | armería | 1 |
| 27911 | armejas | 1 |
| 27912 | armasen | 1 |
| 27913 | armase | 1 |
| 27914 | armaron | 1 |
| 27915 | armarme | 1 |
| 27916 | armarías | 1 |
| 27917 | armándose | 1 |
| 27918 | armándole | 1 |
| 27919 | armadores | 1 |
| 27920 | armadas | 1 |
| 27921 | aritméticos | 1 |
| 27922 | aritméticas | 1 |
| 27923 | aristocráticas | 1 |
| 27924 | aristarco | 1 |
| 27925 | arisca | 1 |
| 27926 | arias | 1 |
| 27927 | arguyéndose | 1 |
| 27928 | argumentar | 1 |
| 27929 | argumentando | 1 |
| 27930 | argüía | 1 |
| 27931 | argucias | 1 |
| 27932 | argollitas | 1 |
| 27933 | argollas | 1 |
| 27934 | argentino | 1 |
| 27935 | argentina | 1 |
| 27936 | arganda | 1 |
| 27937 | argamasillesca | 1 |
| 27938 | arenilla | 1 |
| 27939 | arengando | 1 |
| 27940 | arengaba | 1 |
| 27941 | arenales | 1 |
| 27942 | ardorosos | 1 |
| 27943 | ardió | 1 |
| 27944 | ardides | 1 |
| 27945 | ardid | 1 |
| 27946 | ardería | 1 |
| 27947 | ardentísimo | 1 |
| 27948 | arden | 1 |
| 27949 | arda | 1 |
| 27950 | arcola | 1 |
| 27951 | archivo | 1 |
| 27952 | archipámpano | 1 |
| 27953 | arcanos | 1 |
| 27954 | arcadas | 1 |
| 27955 | arbusto | 1 |
| 27956 | arboledas | 1 |
| 27957 | árbitro | 1 |
| 27958 | arbitrios | 1 |
| 27959 | arbitrio | 1 |
| 27960 | arbitrando | 1 |
| 27961 | árbitra | 1 |
| 27962 | aravaca | 1 |
| 27963 | arañó | 1 |
| 27964 | arañé | 1 |
| 27965 | arañazos | 1 |
| 27966 | arañas | 1 |
| 27967 | arañarle | 1 |
| 27968 | arañar | 1 |
| 27969 | arañando | 1 |
| 27970 | arañada | 1 |
| 27971 | arañaban | 1 |
| 27972 | arango | 1 |
| 27973 | aranceles | 1 |
| 27974 | arancelarios | 1 |
| 27975 | arancelarias | 1 |
| 27976 | arancelaria | 1 |
| 27977 | arancel | 1 |
| 27978 | aragonés | 1 |
| 27979 | arábiga | 1 |
| 27980 | arabesco | 1 |
| 27981 | apurillos | 1 |
| 27982 | apuren | 1 |
| 27983 | apuran | 1 |
| 27984 | apuradísima | 1 |
| 27985 | apura | 1 |
| 27986 | apuntárselas | 1 |
| 27987 | apuntarle | 1 |
| 27988 | apuntaré | 1 |
| 27989 | apuntándole | 1 |
| 27990 | apuntando | 1 |
| 27991 | apuntadas | 1 |
| 27992 | apuntaban | 1 |
| 27993 | apuestan | 1 |
| 27994 | aproximaría | 1 |
| 27995 | aproximar | 1 |
| 27996 | aproximada | 1 |
| 27997 | aproximaban | 1 |
| 27998 | aproxima | 1 |
| 27999 | aprovecharnos | 1 |
| 28000 | aprovechará | 1 |
| 28001 | aprovechara | 1 |
| 28002 | aprovechan | 1 |
| 28003 | aprovechamiento | 1 |
| 28004 | aprovecháis | 1 |
| 28005 | aprovechadas | 1 |
| 28006 | aprovechaban | 1 |
| 28007 | apropiado | 1 |
| 28008 | apropiada | 1 |
| 28009 | apropiación | 1 |
| 28010 | aprobase | 1 |
| 28011 | aprobadas | 1 |
| 28012 | aprobada | 1 |
| 28013 | aprobación | 1 |
| 28014 | aprobaban | 1 |
| 28015 | aprisionar | 1 |
| 28016 | aprisionados | 1 |
| 28017 | aprietes | 1 |
| 28018 | aprietas | 1 |
| 28019 | aprietan | 1 |
| 28020 | apretura | 1 |
| 28021 | apretársele | 1 |
| 28022 | apretándoselo | 1 |
| 28023 | apretándola | 1 |
| 28024 | apresuré | 1 |
| 28025 | apresúrate | 1 |
| 28026 | apresurase | 1 |
| 28027 | apresuraron | 1 |
| 28028 | apresurar | 1 |
| 28029 | apresuradamente | 1 |
| 28030 | apresurada | 1 |
| 28031 | apresuraba | 1 |
| 28032 | aprensivo | 1 |
| 28033 | aprensiva | 1 |
| 28034 | aprendo | 1 |
| 28035 | aprendizaje | 1 |
| 28036 | aprendiz | 1 |
| 28037 | aprendieron | 1 |
| 28038 | aprendiera | 1 |
| 28039 | aprendidas | 1 |
| 28040 | aprendían | 1 |
| 28041 | apréndetelo | 1 |
| 28042 | apréndete | 1 |
| 28043 | aprendes | 1 |
| 28044 | aprenderán | 1 |
| 28045 | aprendemos | 1 |
| 28046 | aprended | 1 |
| 28047 | aprendan | 1 |
| 28048 | apremiaron | 1 |
| 28049 | apremiarla | 1 |
| 28050 | apremiantes | 1 |
| 28051 | apremiante | 1 |
| 28052 | apremiado | 1 |
| 28053 | apremiaban | 1 |
| 28054 | apremiaba | 1 |
| 28055 | apreciarlas | 1 |
| 28056 | apreciarán | 1 |
| 28057 | apreciados | 1 |
| 28058 | apreciado | 1 |
| 28059 | apreciadas | 1 |
| 28060 | apreciables | 1 |
| 28061 | apreciabilísimo | 1 |
| 28062 | apreciabilísima | 1 |
| 28063 | apoye | 1 |
| 28064 | apoyaturas | 1 |
| 28065 | apóyate | 1 |
| 28066 | apoyaban | 1 |
| 28067 | apoyaba | 1 |
| 28068 | apoya | 1 |
| 28069 | apoteosis | 1 |
| 28070 | apóstrofe | 1 |
| 28071 | apostólicos | 1 |
| 28072 | apostaría | 1 |
| 28073 | apostado | 1 |
| 28074 | aposentados | 1 |
| 28075 | aportaste | 1 |
| 28076 | aportar | 1 |
| 28077 | aportaban | 1 |
| 28078 | aportaba | 1 |
| 28079 | aporreo | 1 |
| 28080 | aporreando | 1 |
| 28081 | aporrean | 1 |
| 28082 | aporreada | 1 |
| 28083 | aporrea | 1 |
| 28084 | apología | 1 |
| 28085 | apoderó | 1 |
| 28086 | apoderaron | 1 |
| 28087 | apoderada | 1 |
| 28088 | apoderaban | 1 |
| 28089 | apócrifo | 1 |
| 28090 | apocamiento | 1 |
| 28091 | apocado | 1 |
| 28092 | apliquen | 1 |
| 28093 | aplícate | 1 |
| 28094 | aplicarse | 1 |
| 28095 | aplicarlo | 1 |
| 28096 | aplicándose | 1 |
| 28097 | aplicados | 1 |
| 28098 | aplicado | 1 |
| 28099 | aplicaditos | 1 |
| 28100 | aplicadísimo | 1 |
| 28101 | aplicadísima | 1 |
| 28102 | aplicaciones | 1 |
| 28103 | aplica | 1 |
| 28104 | aplazó | 1 |
| 28105 | aplazarlo | 1 |
| 28106 | aplausos | 1 |
| 28107 | aplaudirse | 1 |
| 28108 | aplaudir | 1 |
| 28109 | aplaudiesen | 1 |
| 28110 | aplaudieron | 1 |
| 28111 | aplaudiéndose | 1 |
| 28112 | aplaudía | 1 |
| 28113 | aplaude | 1 |
| 28114 | aplasto | 1 |
| 28115 | aplastando | 1 |
| 28116 | aplastado | 1 |
| 28117 | aplanado | 1 |
| 28118 | aplanada | 1 |
| 28119 | aplacó | 1 |
| 28120 | aplacaría | 1 |
| 28121 | aplacará | 1 |
| 28122 | aplacando | 1 |
| 28123 | aplacada | 1 |
| 28124 | aplacaba | 1 |
| 28125 | aplaca | 1 |
| 28126 | apio | 1 |
| 28127 | apilaba | 1 |
| 28128 | apetitoso | 1 |
| 28129 | apetezca | 1 |
| 28130 | apeteciendo | 1 |
| 28131 | apetecido | 1 |
| 28132 | apetecían | 1 |
| 28133 | apestando | 1 |
| 28134 | aperreada | 1 |
| 28135 | apergaminaba | 1 |
| 28136 | apercibiendo | 1 |
| 28137 | apeose | 1 |
| 28138 | apéndice | 1 |
| 28139 | apencó | 1 |
| 28140 | apenado | 1 |
| 28141 | apelo | 1 |
| 28142 | apelmazándose | 1 |
| 28143 | apelmazaban | 1 |
| 28144 | apechuguemos | 1 |
| 28145 | apechugue | 1 |
| 28146 | apechugó | 1 |
| 28147 | apearme | 1 |
| 28148 | apáticamente | 1 |
| 28149 | apasionada | 1 |
| 28150 | apartola | 1 |
| 28151 | aparto | 1 |
| 28152 | aparté | 1 |
| 28153 | apartase | 1 |
| 28154 | apartas | 1 |
| 28155 | apartarte | 1 |
| 28156 | apartarlo | 1 |
| 28157 | apartarle | 1 |
| 28158 | apartarla | 1 |
| 28159 | apartándolas | 1 |
| 28160 | apartan | 1 |
| 28161 | apartamientos | 1 |
| 28162 | apartamiento | 1 |
| 28163 | apártame | 1 |
| 28164 | apartaban | 1 |
| 28165 | aparezco | 1 |
| 28166 | aparezca | 1 |
| 28167 | aparentemente | 1 |
| 28168 | aparentase | 1 |
| 28169 | aparentarla | 1 |
| 28170 | aparejos | 1 |
| 28171 | aparejo | 1 |
| 28172 | aparejados | 1 |
| 28173 | apareciese | 1 |
| 28174 | apareciera | 1 |
| 28175 | aparecerán | 1 |
| 28176 | aparecerá | 1 |
| 28177 | aparatosa | 1 |
| 28178 | aparatos | 1 |
| 28179 | apañados | 1 |
| 28180 | apañado | 1 |
| 28181 | apañaditos | 1 |
| 28182 | apañadita | 1 |
| 28183 | apaña | 1 |
| 28184 | apandando | 1 |
| 28185 | apalearle | 1 |
| 28186 | apalean | 1 |
| 28187 | apaleaban | 1 |
| 28188 | apalabrado | 1 |
| 28189 | apalabradas | 1 |
| 28190 | apaisada | 1 |
| 28191 | apagolo | 1 |
| 28192 | apagó | 1 |
| 28193 | apagaste | 1 |
| 28194 | apagarse | 1 |
| 28195 | apagarlas | 1 |
| 28196 | apagarla | 1 |
| 28197 | apagaría | 1 |
| 28198 | apagaran | 1 |
| 28199 | apagábase | 1 |
| 28200 | apagaban | 1 |
| 28201 | apaga | 1 |
| 28202 | apacentaba | 1 |
| 28203 | apabullar | 1 |
| 28204 | aorta | 1 |
| 28205 | añadirse | 1 |
| 28206 | añadiéndole | 1 |
| 28207 | añadido | 1 |
| 28208 | añada | 1 |
| 28209 | anuncios | 1 |
| 28210 | anuncié | 1 |
| 28211 | anunciarte | 1 |
| 28212 | anunciarse | 1 |
| 28213 | anunciarme | 1 |
| 28214 | anunciarle | 1 |
| 28215 | anunciará | 1 |
| 28216 | anunciara | 1 |
| 28217 | anunciándose | 1 |
| 28218 | anunciado | 1 |
| 28219 | anunciadas | 1 |
| 28220 | anunciaban | 1 |
| 28221 | anularse | 1 |
| 28222 | anular | 1 |
| 28223 | anulando | 1 |
| 28224 | anula | 1 |
| 28225 | anudado | 1 |
| 28226 | anualmente | 1 |
| 28227 | antorchas | 1 |
| 28228 | antoñita | 1 |
| 28229 | antonieta | 1 |
| 28230 | antojitos | 1 |
| 28231 | antojito | 1 |
| 28232 | antojaría | 1 |
| 28233 | antojaba | 1 |
| 28234 | antiquísimos | 1 |
| 28235 | antípodas | 1 |
| 28236 | antipatriótico | 1 |
| 28237 | antipáticas | 1 |
| 28238 | antioquía | 1 |
| 28239 | antigüedad | 1 |
| 28240 | antiguamente | 1 |
| 28241 | antigualla | 1 |
| 28242 | antiespasmódico | 1 |
| 28243 | antieconómico | 1 |
| 28244 | antidinásticas | 1 |
| 28245 | anticuados | 1 |
| 28246 | anticuado | 1 |
| 28247 | anticonstitucional | 1 |
| 28248 | anticipos | 1 |
| 28249 | anticipó | 1 |
| 28250 | anticiparse | 1 |
| 28251 | anticipándome | 1 |
| 28252 | anticipado | 1 |
| 28253 | anticipada | 1 |
| 28254 | anticipaban | 1 |
| 28255 | antequera | 1 |
| 28256 | anteponen | 1 |
| 28257 | antepechos | 1 |
| 28258 | antepecho | 1 |
| 28259 | anteojo | 1 |
| 28260 | anteojazo | 1 |
| 28261 | antediluvianos | 1 |
| 28262 | antediluviana | 1 |
| 28263 | antecesores | 1 |
| 28264 | antecesor | 1 |
| 28265 | antaño | 1 |
| 28266 | antagonista | 1 |
| 28267 | antagonismos | 1 |
| 28268 | ansiosos | 1 |
| 28269 | ansiedades | 1 |
| 28270 | ansiados | 1 |
| 28271 | anotaciones | 1 |
| 28272 | anormal | 1 |
| 28273 | anonadar | 1 |
| 28274 | anonadando | 1 |
| 28275 | anonadado | 1 |
| 28276 | anonadaba | 1 |
| 28277 | anomalías | 1 |
| 28278 | anómala | 1 |
| 28279 | anochecía | 1 |
| 28280 | aniversario | 1 |
| 28281 | anís | 1 |
| 28282 | aniquilar | 1 |
| 28283 | aniquilan | 1 |
| 28284 | aniquilamiento | 1 |
| 28285 | animose | 1 |
| 28286 | anímese | 1 |
| 28287 | animarse | 1 |
| 28288 | animarle | 1 |
| 28289 | animarla | 1 |
| 28290 | animándole | 1 |
| 28291 | animalitos | 1 |
| 28292 | animadísimo | 1 |
| 28293 | animadas | 1 |
| 28294 | animábale | 1 |
| 28295 | anillos | 1 |
| 28296 | anillo | 1 |
| 28297 | anillas | 1 |
| 28298 | anidara | 1 |
| 28299 | anida | 1 |
| 28300 | anhela | 1 |
| 28301 | angustiada | 1 |
| 28302 | angulosas | 1 |
| 28303 | angulosa | 1 |
| 28304 | ángulos | 1 |
| 28305 | angulema | 1 |
| 28306 | anguila | 1 |
| 28307 | angosturas | 1 |
| 28308 | angostas | 1 |
| 28309 | anglómano | 1 |
| 28310 | anglicanizados | 1 |
| 28311 | angelita | 1 |
| 28312 | angelicales | 1 |
| 28313 | anfitriones | 1 |
| 28314 | anestésico | 1 |
| 28315 | anegar | 1 |
| 28316 | anegándose | 1 |
| 28317 | anega | 1 |
| 28318 | anduvieron | 1 |
| 28319 | anduviera | 1 |
| 28320 | anduve | 1 |
| 28321 | andurriales | 1 |
| 28322 | andrajosas | 1 |
| 28323 | andrajosa | 1 |
| 28324 | andrajo | 1 |
| 28325 | ando | 1 |
| 28326 | anden | 1 |
| 28327 | andarse | 1 |
| 28328 | andarían | 1 |
| 28329 | andaríamos | 1 |
| 28330 | andarás | 1 |
| 28331 | andamio | 1 |
| 28332 | andamiajes | 1 |
| 28333 | andamiaje | 1 |
| 28334 | andaluza | 1 |
| 28335 | andábanle | 1 |
| 28336 | ancladas | 1 |
| 28337 | ancianas | 1 |
| 28338 | anchura | 1 |
| 28339 | anchoas | 1 |
| 28340 | anatomías | 1 |
| 28341 | anatomía | 1 |
| 28342 | anascotes | 1 |
| 28343 | análogos | 1 |
| 28344 | analizó | 1 |
| 28345 | analizara | 1 |
| 28346 | analizar | 1 |
| 28347 | anafres | 1 |
| 28348 | anacronismo | 1 |
| 28349 | anacletus | 1 |
| 28350 | anacleto | 1 |
| 28351 | anabaptista | 1 |
| 28352 | amueblados | 1 |
| 28353 | amuebladas | 1 |
| 28354 | amputación | 1 |
| 28355 | ampolla | 1 |
| 28356 | amplísima | 1 |
| 28357 | amplia | 1 |
| 28358 | ampare | 1 |
| 28359 | ampararse | 1 |
| 28360 | ampararles | 1 |
| 28361 | ampararán | 1 |
| 28362 | amparaba | 1 |
| 28363 | ampara | 1 |
| 28364 | amotinó | 1 |
| 28365 | amoscose | 1 |
| 28366 | amortajó | 1 |
| 28367 | amortajaron | 1 |
| 28368 | amorraba | 1 |
| 28369 | amorosamente | 1 |
| 28370 | amorosa | 1 |
| 28371 | amoríos | 1 |
| 28372 | amorcito | 1 |
| 28373 | amoratados | 1 |
| 28374 | amontones | 1 |
| 28375 | amontone | 1 |
| 28376 | amontonaron | 1 |
| 28377 | amoniaco | 1 |
| 28378 | amonestó | 1 |
| 28379 | amoldarlas | 1 |
| 28380 | amoldara | 1 |
| 28381 | amoldada | 1 |
| 28382 | amodorrado | 1 |
| 28383 | amito | 1 |
| 28384 | amistoso | 1 |
| 28385 | amistosamente | 1 |
| 28386 | amilanarse | 1 |
| 28387 | amilana | 1 |
| 28388 | amiguito | 1 |
| 28389 | amigotes | 1 |
| 28390 | amigota | 1 |
| 28391 | amigablemente | 1 |
| 28392 | americano | 1 |
| 28393 | amenizó | 1 |
| 28394 | ameniza | 1 |
| 28395 | amenguársele | 1 |
| 28396 | amenguar | 1 |
| 28397 | amenazar | 1 |
| 28398 | amenazándolos | 1 |
| 28399 | amenazándola | 1 |
| 28400 | amenazadores | 1 |
| 28401 | amenazador | 1 |
| 28402 | amenazada | 1 |
| 28403 | amenazaban | 1 |
| 28404 | amenas | 1 |
| 28405 | ame | 1 |
| 28406 | ambulante | 1 |
| 28407 | ambicionar | 1 |
| 28408 | ámbar | 1 |
| 28409 | amazónica | 1 |
| 28410 | amazonas | 1 |
| 28411 | amazona | 1 |
| 28412 | amasara | 1 |
| 28413 | amasábanlo | 1 |
| 28414 | amasábalo | 1 |
| 28415 | amartelamiento | 1 |
| 28416 | amarre | 1 |
| 28417 | amarrara | 1 |
| 28418 | amarrar | 1 |
| 28419 | amarrada | 1 |
| 28420 | amarillentas | 1 |
| 28421 | amargos | 1 |
| 28422 | amargor | 1 |
| 28423 | amargarán | 1 |
| 28424 | amargan | 1 |
| 28425 | amargaban | 1 |
| 28426 | amargaba | 1 |
| 28427 | amaremos | 1 |
| 28428 | amaranto | 1 |
| 28429 | amara | 1 |
| 28430 | amañada | 1 |
| 28431 | amantísima | 1 |
| 28432 | amanse | 1 |
| 28433 | amansarla | 1 |
| 28434 | amansará | 1 |
| 28435 | amansaban | 1 |
| 28436 | amansa | 1 |
| 28437 | amanezco | 1 |
| 28438 | amanezca | 1 |
| 28439 | amaneramientos | 1 |
| 28440 | amanerado | 1 |
| 28441 | amanecía | 1 |
| 28442 | amándola | 1 |
| 28443 | amando | 1 |
| 28444 | amancebada | 1 |
| 28445 | aman | 1 |
| 28446 | amalgama | 1 |
| 28447 | amago | 1 |
| 28448 | amagado | 1 |
| 28449 | amaestrados | 1 |
| 28450 | amables | 1 |
| 28451 | amábale | 1 |
| 28452 | alzarse | 1 |
| 28453 | alzándolos | 1 |
| 28454 | alzándole | 1 |
| 28455 | alzamiento | 1 |
| 28456 | alzada | 1 |
| 28457 | alumbré | 1 |
| 28458 | alumbrar | 1 |
| 28459 | alumbrándose | 1 |
| 28460 | alumbrando | 1 |
| 28461 | alumbramientos | 1 |
| 28462 | alumbrado | 1 |
| 28463 | alumbra | 1 |
| 28464 | aluego | 1 |
| 28465 | aludir | 1 |
| 28466 | aludiendo | 1 |
| 28467 | aludidos | 1 |
| 28468 | alucinado | 1 |
| 28469 | alucinada | 1 |
| 28470 | alucinaciones | 1 |
| 28471 | altozanos | 1 |
| 28472 | altona | 1 |
| 28473 | altivez | 1 |
| 28474 | altísima | 1 |
| 28475 | alteza | 1 |
| 28476 | alternativamente | 1 |
| 28477 | alternativa | 1 |
| 28478 | alternando | 1 |
| 28479 | alternadamente | 1 |
| 28480 | alternaban | 1 |
| 28481 | alterna | 1 |
| 28482 | alteres | 1 |
| 28483 | alterando | 1 |
| 28484 | alterada | 1 |
| 28485 | altarucho | 1 |
| 28486 | altanería | 1 |
| 28487 | altaneramente | 1 |
| 28488 | alsacia | 1 |
| 28489 | alquilan | 1 |
| 28490 | alquilado | 1 |
| 28491 | alquila | 1 |
| 28492 | alpargatitas | 1 |
| 28493 | alones | 1 |
| 28494 | alojamiento | 1 |
| 28495 | alojaba | 1 |
| 28496 | almuerzas | 1 |
| 28497 | almuerza | 1 |
| 28498 | almorzó | 1 |
| 28499 | almorzaron | 1 |
| 28500 | almorzaría | 1 |
| 28501 | almorzaré | 1 |
| 28502 | almorzarás | 1 |
| 28503 | almorzaran | 1 |
| 28504 | almorzará | 1 |
| 28505 | almorzaban | 1 |
| 28506 | almorcemos | 1 |
| 28507 | almonedas | 1 |
| 28508 | almohadón | 1 |
| 28509 | almireces | 1 |
| 28510 | almidón | 1 |
| 28511 | almería | 1 |
| 28512 | almendrita | 1 |
| 28513 | almendrado | 1 |
| 28514 | almansa | 1 |
| 28515 | almanaques | 1 |
| 28516 | almagre | 1 |
| 28517 | almacenista | 1 |
| 28518 | aller | 1 |
| 28519 | allegro | 1 |
| 28520 | allego | 1 |
| 28521 | allegadizo | 1 |
| 28522 | allanamiento | 1 |
| 28523 | alivió | 1 |
| 28524 | aliviarle | 1 |
| 28525 | alivian | 1 |
| 28526 | aliviado | 1 |
| 28527 | aliviaba | 1 |
| 28528 | alivia | 1 |
| 28529 | aliñada | 1 |
| 28530 | alinearon | 1 |
| 28531 | alineadas | 1 |
| 28532 | alimentarse | 1 |
| 28533 | alimentarlo | 1 |
| 28534 | alimentados | 1 |
| 28535 | alimentada | 1 |
| 28536 | alimentaba | 1 |
| 28537 | alilao | 1 |
| 28538 | aligerándole | 1 |
| 28539 | aligeraba | 1 |
| 28540 | aligera | 1 |
| 28541 | alifonso | 1 |
| 28542 | alicante | 1 |
| 28543 | aliar | 1 |
| 28544 | alianza | 1 |
| 28545 | alhambra | 1 |
| 28546 | alhajita | 1 |
| 28547 | álgido | 1 |
| 28548 | algeciras | 1 |
| 28549 | algarroba | 1 |
| 28550 | alfonsina | 1 |
| 28551 | alfombrita | 1 |
| 28552 | alfombras | 1 |
| 28553 | alfombrado | 1 |
| 28554 | alfombrada | 1 |
| 28555 | alfilerazo | 1 |
| 28556 | alfargías | 1 |
| 28557 | alevosa | 1 |
| 28558 | aletargarse | 1 |
| 28559 | alentó | 1 |
| 28560 | alentarme | 1 |
| 28561 | alentara | 1 |
| 28562 | alentar | 1 |
| 28563 | alentado | 1 |
| 28564 | alentada | 1 |
| 28565 | alentaba | 1 |
| 28566 | aleluya | 1 |
| 28567 | alelí | 1 |
| 28568 | alejaron | 1 |
| 28569 | alejándole | 1 |
| 28570 | alegrones | 1 |
| 28571 | alegremente | 1 |
| 28572 | alegrase | 1 |
| 28573 | alegras | 1 |
| 28574 | alegrarte | 1 |
| 28575 | alegrarla | 1 |
| 28576 | alegraríamos | 1 |
| 28577 | alegraran | 1 |
| 28578 | alegrado | 1 |
| 28579 | alegrábanse | 1 |
| 28580 | alegra | 1 |
| 28581 | alegórica | 1 |
| 28582 | alegoría | 1 |
| 28583 | alegar | 1 |
| 28584 | alegando | 1 |
| 28585 | aldeota | 1 |
| 28586 | aldeas | 1 |
| 28587 | aldeanos | 1 |
| 28588 | alcorcón | 1 |
| 28589 | alcoholismo | 1 |
| 28590 | alcohólico | 1 |
| 28591 | alcohólicas | 1 |
| 28592 | alcoholatos | 1 |
| 28593 | alcira | 1 |
| 28594 | alcé | 1 |
| 28595 | alcarria | 1 |
| 28596 | alcarreño | 1 |
| 28597 | alcaraz | 1 |
| 28598 | alcanzas | 1 |
| 28599 | alcanzarla | 1 |
| 28600 | alcanzaría | 1 |
| 28601 | alcanzamos | 1 |
| 28602 | alcanzaban | 1 |
| 28603 | alcantarillas | 1 |
| 28604 | alcanfor | 1 |
| 28605 | alcánceme | 1 |
| 28606 | alcaloide | 1 |
| 28607 | alcaldía | 1 |
| 28608 | alcahuetas | 1 |
| 28609 | alcachofas | 1 |
| 28610 | alborozada | 1 |
| 28611 | alborotos | 1 |
| 28612 | alborotes | 1 |
| 28613 | alborotemos | 1 |
| 28614 | alboroté | 1 |
| 28615 | alborotaron | 1 |
| 28616 | alborotan | 1 |
| 28617 | alborotadamente | 1 |
| 28618 | albis | 1 |
| 28619 | albillo | 1 |
| 28620 | albergarse | 1 |
| 28621 | albergar | 1 |
| 28622 | albergaban | 1 |
| 28623 | albedrío | 1 |
| 28624 | albaricoque | 1 |
| 28625 | albardería | 1 |
| 28626 | albaicín | 1 |
| 28627 | albahaca | 1 |
| 28628 | alarmas | 1 |
| 28629 | alarmarse | 1 |
| 28630 | alarmaron | 1 |
| 28631 | alarmar | 1 |
| 28632 | alarmándose | 1 |
| 28633 | alarmando | 1 |
| 28634 | alarmados | 1 |
| 28635 | alarmado | 1 |
| 28636 | alaridos | 1 |
| 28637 | alarido | 1 |
| 28638 | alargué | 1 |
| 28639 | alargaron | 1 |
| 28640 | alargarle | 1 |
| 28641 | alargar | 1 |
| 28642 | alargándosela | 1 |
| 28643 | alargamiento | 1 |
| 28644 | alargábalo | 1 |
| 28645 | alardeando | 1 |
| 28646 | alardeaba | 1 |
| 28647 | alardea | 1 |
| 28648 | alamedas | 1 |
| 28649 | alambicados | 1 |
| 28650 | alados | 1 |
| 28651 | alabó | 1 |
| 28652 | alabarderos | 1 |
| 28653 | alabar | 1 |
| 28654 | alabanzas | 1 |
| 28655 | alaban | 1 |
| 28656 | alababan | 1 |
| 28657 | akos | 1 |
| 28658 | ajusticiar | 1 |
| 28659 | ajusticiados | 1 |
| 28660 | ajustaré | 1 |
| 28661 | ajustarán | 1 |
| 28662 | ajustar | 1 |
| 28663 | ajustándolos | 1 |
| 28664 | ajustados | 1 |
| 28665 | ajustaba | 1 |
| 28666 | ajuntaron | 1 |
| 28667 | ajumarse | 1 |
| 28668 | ajumaíto | 1 |
| 28669 | ajuares | 1 |
| 28670 | ajos | 1 |
| 28671 | ajito | 1 |
| 28672 | ajenjos | 1 |
| 28673 | ajardinados | 1 |
| 28674 | ajan | 1 |
| 28675 | aislados | 1 |
| 28676 | aislado | 1 |
| 28677 | airote | 1 |
| 28678 | airear | 1 |
| 28679 | airado | 1 |
| 28680 | airadas | 1 |
| 28681 | ahuyentase | 1 |
| 28682 | ahuyentar | 1 |
| 28683 | ahuyentan | 1 |
| 28684 | ahuma | 1 |
| 28685 | ahuecar | 1 |
| 28686 | ahuecados | 1 |
| 28687 | ahuecadas | 1 |
| 28688 | ahueca | 1 |
| 28689 | ahorrarse | 1 |
| 28690 | ahorrar | 1 |
| 28691 | ahorcarme | 1 |
| 28692 | ahorcado | 1 |
| 28693 | ahondando | 1 |
| 28694 | ahola | 1 |
| 28695 | ahoguillo | 1 |
| 28696 | ahogos | 1 |
| 28697 | ahogarte | 1 |
| 28698 | ahogarse | 1 |
| 28699 | ahogarle | 1 |
| 28700 | ahogaría | 1 |
| 28701 | ahogaran | 1 |
| 28702 | ahogándose | 1 |
| 28703 | ahogándola | 1 |
| 28704 | ahogando | 1 |
| 28705 | ahogado | 1 |
| 28706 | ahogadas | 1 |
| 28707 | ahoga | 1 |
| 28708 | ahíto | 1 |
| 28709 | ahilado | 1 |
| 28710 | ahijado | 1 |
| 28711 | ahijada | 1 |
| 28712 | aguzadores | 1 |
| 28713 | aguzado | 1 |
| 28714 | aguzaban | 1 |
| 28715 | agujeritos | 1 |
| 28716 | agujereados | 1 |
| 28717 | aguirre | 1 |
| 28718 | aguinaldo | 1 |
| 28719 | aguileña | 1 |
| 28720 | águilas | 1 |
| 28721 | agudos | 1 |
| 28722 | agudísimos | 1 |
| 28723 | agudísima | 1 |
| 28724 | agudezas | 1 |
| 28725 | aguaron | 1 |
| 28726 | aguardo | 1 |
| 28727 | aguardientito | 1 |
| 28728 | aguardientazo | 1 |
| 28729 | aguárdense | 1 |
| 28730 | aguardaron | 1 |
| 28731 | aguardaba | 1 |
| 28732 | aguantó | 1 |
| 28733 | aguanten | 1 |
| 28734 | aguánteme | 1 |
| 28735 | aguante | 1 |
| 28736 | aguantas | 1 |
| 28737 | aguantarme | 1 |
| 28738 | aguantarle | 1 |
| 28739 | aguantaría | 1 |
| 28740 | aguantamos | 1 |
| 28741 | aguadores | 1 |
| 28742 | aguacero | 1 |
| 28743 | agrupar | 1 |
| 28744 | agricultura | 1 |
| 28745 | agrias | 1 |
| 28746 | agriado | 1 |
| 28747 | agriaba | 1 |
| 28748 | agresor | 1 |
| 28749 | agregarse | 1 |
| 28750 | agregando | 1 |
| 28751 | agregábansele | 1 |
| 28752 | agregaba | 1 |
| 28753 | agredida | 1 |
| 28754 | agravio | 1 |
| 28755 | agraviadas | 1 |
| 28756 | agravación | 1 |
| 28757 | agrandando | 1 |
| 28758 | agrandado | 1 |
| 28759 | agrandada | 1 |
| 28760 | agradó | 1 |
| 28761 | agradezcáis | 1 |
| 28762 | agradecimientos | 1 |
| 28763 | agradeces | 1 |
| 28764 | agradecerle | 1 |
| 28765 | agradecerían | 1 |
| 28766 | agradeceremos | 1 |
| 28767 | agradéceme | 1 |
| 28768 | agradece | 1 |
| 28769 | agradaron | 1 |
| 28770 | agradarle | 1 |
| 28771 | agradan | 1 |
| 28772 | agradablemente | 1 |
| 28773 | agradabilísimo | 1 |
| 28774 | agradábanle | 1 |
| 28775 | agració | 1 |
| 28776 | agraciadas | 1 |
| 28777 | agotarse | 1 |
| 28778 | agostaba | 1 |
| 28779 | agonizada | 1 |
| 28780 | agobia | 1 |
| 28781 | agitato | 1 |
| 28782 | agitara | 1 |
| 28783 | agitante | 1 |
| 28784 | agitanada | 1 |
| 28785 | agitadas | 1 |
| 28786 | ágiles | 1 |
| 28787 | agenciado | 1 |
| 28788 | agasajarle | 1 |
| 28789 | agasajar | 1 |
| 28790 | agasajando | 1 |
| 28791 | agasajan | 1 |
| 28792 | agasajada | 1 |
| 28793 | agarrotes | 1 |
| 28794 | agarrose | 1 |
| 28795 | agarré | 1 |
| 28796 | agarre | 1 |
| 28797 | agarrase | 1 |
| 28798 | agarras | 1 |
| 28799 | agarraron | 1 |
| 28800 | agarrarlo | 1 |
| 28801 | agarrándole | 1 |
| 28802 | agarrados | 1 |
| 28803 | agarrado | 1 |
| 28804 | agarradas | 1 |
| 28805 | agarraba | 1 |
| 28806 | agarra | 1 |
| 28807 | agallas | 1 |
| 28808 | agachaban | 1 |
| 28809 | agacha | 1 |
| 28810 | afrontando | 1 |
| 28811 | africana | 1 |
| 28812 | afrento | 1 |
| 28813 | afrentas | 1 |
| 28814 | afrentar | 1 |
| 28815 | afortunado | 1 |
| 28816 | aforismos | 1 |
| 28817 | afluía | 1 |
| 28818 | aflojé | 1 |
| 28819 | afloje | 1 |
| 28820 | aflojarse | 1 |
| 28821 | aflojarle | 1 |
| 28822 | aflojar | 1 |
| 28823 | aflijas | 1 |
| 28824 | afligidos | 1 |
| 28825 | afligidísimo | 1 |
| 28826 | aflige | 1 |
| 28827 | aflictivo | 1 |
| 28828 | aflictiva | 1 |
| 28829 | aflicciones | 1 |
| 28830 | aflamencado | 1 |
| 28831 | afirme | 1 |
| 28832 | afirmativos | 1 |
| 28833 | afirmativa | 1 |
| 28834 | afirmase | 1 |
| 28835 | afirmarse | 1 |
| 28836 | afinó | 1 |
| 28837 | afinidades | 1 |
| 28838 | afines | 1 |
| 28839 | afinado | 1 |
| 28840 | afinadas | 1 |
| 28841 | afinaba | 1 |
| 28842 | afiló | 1 |
| 28843 | afiliarse | 1 |
| 28844 | afilándolas | 1 |
| 28845 | afilados | 1 |
| 28846 | afiladas | 1 |
| 28847 | afilaban | 1 |
| 28848 | afianzando | 1 |
| 28849 | afianzaba | 1 |
| 28850 | aferradas | 1 |
| 28851 | aferrada | 1 |
| 28852 | aferraba | 1 |
| 28853 | afeiten | 1 |
| 28854 | afeite | 1 |
| 28855 | afeitadito | 1 |
| 28856 | afeitada | 1 |
| 28857 | afectuosos | 1 |
| 28858 | afectase | 1 |
| 28859 | afectarte | 1 |
| 28860 | afectaron | 1 |
| 28861 | afectadísimo | 1 |
| 28862 | afección | 1 |
| 28863 | afeaban | 1 |
| 28864 | afanándose | 1 |
| 28865 | afanados | 1 |
| 28866 | afanadora | 1 |
| 28867 | afanada | 1 |
| 28868 | advirtieron | 1 |
| 28869 | advirtiera | 1 |
| 28870 | advirtiéndole | 1 |
| 28871 | adviniese | 1 |
| 28872 | adviértele | 1 |
| 28873 | advierte | 1 |
| 28874 | adviertas | 1 |
| 28875 | adviértale | 1 |
| 28876 | advertirle | 1 |
| 28877 | advertido | 1 |
| 28878 | advertida | 1 |
| 28879 | advertían | 1 |
| 28880 | advertencia | 1 |
| 28881 | adversidad | 1 |
| 28882 | adventicia | 1 |
| 28883 | adustez | 1 |
| 28884 | adustas | 1 |
| 28885 | adúltero | 1 |
| 28886 | adultero | 1 |
| 28887 | adulterios | 1 |
| 28888 | adulteraba | 1 |
| 28889 | adulona | 1 |
| 28890 | adulando | 1 |
| 28891 | adulaban | 1 |
| 28892 | adquiriría | 1 |
| 28893 | adquiriré | 1 |
| 28894 | adquirida | 1 |
| 28895 | adquieren | 1 |
| 28896 | adquieran | 1 |
| 28897 | adquiera | 1 |
| 28898 | adornó | 1 |
| 28899 | adornarse | 1 |
| 28900 | adornar | 1 |
| 28901 | adornados | 1 |
| 28902 | adormilado | 1 |
| 28903 | adormidera | 1 |
| 28904 | adormeciera | 1 |
| 28905 | adormecido | 1 |
| 28906 | adormecida | 1 |
| 28907 | adormecía | 1 |
| 28908 | adormecerse | 1 |
| 28909 | adoren | 1 |
| 28910 | adore | 1 |
| 28911 | adorarte | 1 |
| 28912 | adorarse | 1 |
| 28913 | adoraron | 1 |
| 28914 | adorarme | 1 |
| 28915 | adoraría | 1 |
| 28916 | adoraré | 1 |
| 28917 | adoraran | 1 |
| 28918 | adorara | 1 |
| 28919 | adorando | 1 |
| 28920 | adoramos | 1 |
| 28921 | adorabas | 1 |
| 28922 | adoquinando | 1 |
| 28923 | adoquinadas | 1 |
| 28924 | adoptó | 1 |
| 28925 | adopte | 1 |
| 28926 | adoptarlo | 1 |
| 28927 | adoptarla | 1 |
| 28928 | adoptaría | 1 |
| 28929 | adoptado | 1 |
| 28930 | adonis | 1 |
| 28931 | adonde | 1 |
| 28932 | adolecieran | 1 |
| 28933 | adobado | 1 |
| 28934 | admitirlo | 1 |
| 28935 | admitirle | 1 |
| 28936 | admitió | 1 |
| 28937 | admitiesen | 1 |
| 28938 | admitiera | 1 |
| 28939 | admitiendo | 1 |
| 28940 | admitidas | 1 |
| 28941 | admitida | 1 |
| 28942 | admitamos | 1 |
| 28943 | admisión | 1 |
| 28944 | admirose | 1 |
| 28945 | admirase | 1 |
| 28946 | admiras | 1 |
| 28947 | admiraron | 1 |
| 28948 | admiraría | 1 |
| 28949 | admiran | 1 |
| 28950 | admiramos | 1 |
| 28951 | admiradas | 1 |
| 28952 | admirábala | 1 |
| 28953 | admira | 1 |
| 28954 | administre | 1 |
| 28955 | administrativo | 1 |
| 28956 | administrativas | 1 |
| 28957 | administrado | 1 |
| 28958 | administraba | 1 |
| 28959 | administra | 1 |
| 28960 | adjudicó | 1 |
| 28961 | adjudicado | 1 |
| 28962 | adjetivo | 1 |
| 28963 | adiviné | 1 |
| 28964 | adivinarlo | 1 |
| 28965 | adivinarle | 1 |
| 28966 | adivinar | 1 |
| 28967 | adivinanza | 1 |
| 28968 | adivinándole | 1 |
| 28969 | adivinando | 1 |
| 28970 | adivinado | 1 |
| 28971 | adivinaciones | 1 |
| 28972 | adivinabas | 1 |
| 28973 | adicto | 1 |
| 28974 | adiciones | 1 |
| 28975 | adhiriéndose | 1 |
| 28976 | adhiere | 1 |
| 28977 | adheridos | 1 |
| 28978 | adeudaba | 1 |
| 28979 | aderezo | 1 |
| 28980 | aderezado | 1 |
| 28981 | aderezada | 1 |
| 28982 | adepto | 1 |
| 28983 | adentros | 1 |
| 28984 | adelgazadas | 1 |
| 28985 | adelgazada | 1 |
| 28986 | adelanto | 1 |
| 28987 | adelantarse | 1 |
| 28988 | adelantarían | 1 |
| 28989 | adelantar | 1 |
| 28990 | adelantan | 1 |
| 28991 | adelantamos | 1 |
| 28992 | adela | 1 |
| 28993 | adecentase | 1 |
| 28994 | adecentarse | 1 |
| 28995 | adecentaras | 1 |
| 28996 | adecentar | 1 |
| 28997 | adecentado | 1 |
| 28998 | adaptando | 1 |
| 28999 | adaptada | 1 |
| 29000 | adaptaban | 1 |
| 29001 | adán | 1 |
| 29002 | adamado | 1 |
| 29003 | adagio | 1 |
| 29004 | acuse | 1 |
| 29005 | acusarse | 1 |
| 29006 | acusaré | 1 |
| 29007 | acusándose | 1 |
| 29008 | acusándoles | 1 |
| 29009 | acusádose | 1 |
| 29010 | acusadora | 1 |
| 29011 | acusaban | 1 |
| 29012 | acurrucó | 1 |
| 29013 | acurrucada | 1 |
| 29014 | acuñar | 1 |
| 29015 | acueste | 1 |
| 29016 | acuesta | 1 |
| 29017 | acuerdos | 1 |
| 29018 | acuérdese | 1 |
| 29019 | acuerden | 1 |
| 29020 | acuerdan | 1 |
| 29021 | acueducto | 1 |
| 29022 | acudo | 1 |
| 29023 | acudiremos | 1 |
| 29024 | acudiré | 1 |
| 29025 | acudimos | 1 |
| 29026 | acudiera | 1 |
| 29027 | acudía | 1 |
| 29028 | acuden | 1 |
| 29029 | acudas | 1 |
| 29030 | acubilla | 1 |
| 29031 | actuar | 1 |
| 29032 | actuando | 1 |
| 29033 | actualmente | 1 |
| 29034 | actrices | 1 |
| 29035 | activamente | 1 |
| 29036 | activaba | 1 |
| 29037 | actitudes | 1 |
| 29038 | acta | 1 |
| 29039 | acrisolada | 1 |
| 29040 | acribilló | 1 |
| 29041 | acribillarlas | 1 |
| 29042 | acredite | 1 |
| 29043 | acreditadísimo | 1 |
| 29044 | acreditada | 1 |
| 29045 | acrecía | 1 |
| 29046 | acostumbres | 1 |
| 29047 | acostumbré | 1 |
| 29048 | acostumbrarse | 1 |
| 29049 | acostumbraran | 1 |
| 29050 | acostumbrados | 1 |
| 29051 | acostumbradas | 1 |
| 29052 | acostumbra | 1 |
| 29053 | acosté | 1 |
| 29054 | acostáronle | 1 |
| 29055 | acostaron | 1 |
| 29056 | acostarme | 1 |
| 29057 | acostaría | 1 |
| 29058 | acostaremos | 1 |
| 29059 | acostara | 1 |
| 29060 | acostando | 1 |
| 29061 | acosen | 1 |
| 29062 | acosándoles | 1 |
| 29063 | acosando | 1 |
| 29064 | acosados | 1 |
| 29065 | acorte | 1 |
| 29066 | acortarse | 1 |
| 29067 | acortar | 1 |
| 29068 | acortando | 1 |
| 29069 | acortaba | 1 |
| 29070 | acorralan | 1 |
| 29071 | acordes | 1 |
| 29072 | acorde | 1 |
| 29073 | acordase | 1 |
| 29074 | acordarme | 1 |
| 29075 | acordaría | 1 |
| 29076 | acordaré | 1 |
| 29077 | acordará | 1 |
| 29078 | acordándome | 1 |
| 29079 | acordado | 1 |
| 29080 | acordada | 1 |
| 29081 | acordabas | 1 |
| 29082 | acordaban | 1 |
| 29083 | acorazó | 1 |
| 29084 | acopio | 1 |
| 29085 | acopiando | 1 |
| 29086 | acopiada | 1 |
| 29087 | acontecimientos | 1 |
| 29088 | aconteciendo | 1 |
| 29089 | acontece | 1 |
| 29090 | aconsejo | 1 |
| 29091 | aconséjele | 1 |
| 29092 | aconséjate | 1 |
| 29093 | aconsejas | 1 |
| 29094 | aconsejarte | 1 |
| 29095 | aconsejármelas | 1 |
| 29096 | aconsejaría | 1 |
| 29097 | aconseja | 1 |
| 29098 | acónito | 1 |
| 29099 | acompañolas | 1 |
| 29100 | acompañes | 1 |
| 29101 | acompañaron | 1 |
| 29102 | acompañara | 1 |
| 29103 | acompañantes | 1 |
| 29104 | acompañante | 1 |
| 29105 | acompañándola | 1 |
| 29106 | acompañan | 1 |
| 29107 | acompañamos | 1 |
| 29108 | acompañábanle | 1 |
| 29109 | acompañábanla | 1 |
| 29110 | acomodó | 1 |
| 29111 | acomodo | 1 |
| 29112 | acomodaticios | 1 |
| 29113 | acomodarse | 1 |
| 29114 | acomodar | 1 |
| 29115 | acomodándose | 1 |
| 29116 | acomodando | 1 |
| 29117 | acomodado | 1 |
| 29118 | acomodada | 1 |
| 29119 | acomoda | 1 |
| 29120 | acometía | 1 |
| 29121 | acometerla | 1 |
| 29122 | acometería | 1 |
| 29123 | acoja | 1 |
| 29124 | acogió | 1 |
| 29125 | acogida | 1 |
| 29126 | acobardes | 1 |
| 29127 | acobardarse | 1 |
| 29128 | acobardaron | 1 |
| 29129 | acobardarme | 1 |
| 29130 | acobardará | 1 |
| 29131 | acobardado | 1 |
| 29132 | aclimatación | 1 |
| 29133 | aclaró | 1 |
| 29134 | aclare | 1 |
| 29135 | aclaran | 1 |
| 29136 | aclaración | 1 |
| 29137 | aclaraba | 1 |
| 29138 | aclara | 1 |
| 29139 | aclamaciones | 1 |
| 29140 | aciertas | 1 |
| 29141 | aciertan | 1 |
| 29142 | acídula | 1 |
| 29143 | acidez | 1 |
| 29144 | acicaló | 1 |
| 29145 | aciaga | 1 |
| 29146 | achuchones | 1 |
| 29147 | achicharrados | 1 |
| 29148 | achicarte | 1 |
| 29149 | achantado | 1 |
| 29150 | achantada | 1 |
| 29151 | achacaban | 1 |
| 29152 | achacaba | 1 |
| 29153 | acetato | 1 |
| 29154 | acertijos | 1 |
| 29155 | acertaré | 1 |
| 29156 | acertados | 1 |
| 29157 | acertadas | 1 |
| 29158 | acertada | 1 |
| 29159 | acertaban | 1 |
| 29160 | acerqueme | 1 |
| 29161 | acerico | 1 |
| 29162 | acercósele | 1 |
| 29163 | acercase | 1 |
| 29164 | acercara | 1 |
| 29165 | acercan | 1 |
| 29166 | acerbísimo | 1 |
| 29167 | acerbísimas | 1 |
| 29168 | acerados | 1 |
| 29169 | acéptelo | 1 |
| 29170 | acepté | 1 |
| 29171 | acéptalo | 1 |
| 29172 | aceptación | 1 |
| 29173 | acentuole | 1 |
| 29174 | acentuar | 1 |
| 29175 | acentúan | 1 |
| 29176 | acentuación | 1 |
| 29177 | acémilas | 1 |
| 29178 | aceleró | 1 |
| 29179 | aceleradas | 1 |
| 29180 | aceitosa | 1 |
| 29181 | acechas | 1 |
| 29182 | acecharlas | 1 |
| 29183 | acecharan | 1 |
| 29184 | acechar | 1 |
| 29185 | acechándola | 1 |
| 29186 | acechador | 1 |
| 29187 | acechaban | 1 |
| 29188 | acechaba | 1 |
| 29189 | acebuche | 1 |
| 29190 | accionistas | 1 |
| 29191 | accidentados | 1 |
| 29192 | accidentada | 1 |
| 29193 | accedieron | 1 |
| 29194 | acaudalada | 1 |
| 29195 | acatemos | 1 |
| 29196 | acatarrado | 1 |
| 29197 | acatar | 1 |
| 29198 | acataba | 1 |
| 29199 | acarició | 1 |
| 29200 | acariciarlo | 1 |
| 29201 | acariciarle | 1 |
| 29202 | acariciándoselo | 1 |
| 29203 | acariciándolas | 1 |
| 29204 | acariciaba | 1 |
| 29205 | acaparamientos | 1 |
| 29206 | acantonar | 1 |
| 29207 | acampan | 1 |
| 29208 | acalores | 1 |
| 29209 | acalorándose | 1 |
| 29210 | acalorándole | 1 |
| 29211 | acaloran | 1 |
| 29212 | acaloradamente | 1 |
| 29213 | acallar | 1 |
| 29214 | acallaban | 1 |
| 29215 | acaeció | 1 |
| 29216 | académicos | 1 |
| 29217 | académico | 1 |
| 29218 | académica | 1 |
| 29219 | acacias | 1 |
| 29220 | acabas | 1 |
| 29221 | acabarás | 1 |
| 29222 | acabarán | 1 |
| 29223 | acabáramos | 1 |
| 29224 | abuso | 1 |
| 29225 | abusas | 1 |
| 29226 | abusar | 1 |
| 29227 | aburriste | 1 |
| 29228 | aburrirle | 1 |
| 29229 | aburrir | 1 |
| 29230 | aburrió | 1 |
| 29231 | aburriera | 1 |
| 29232 | aburriéndose | 1 |
| 29233 | aburridos | 1 |
| 29234 | aburridísima | 1 |
| 29235 | aburridas | 1 |
| 29236 | aburrida | 1 |
| 29237 | aburrían | 1 |
| 29238 | aburríale | 1 |
| 29239 | aburres | 1 |
| 29240 | aburra | 1 |
| 29241 | abundan | 1 |
| 29242 | abunda | 1 |
| 29243 | abulte | 1 |
| 29244 | abuelos | 1 |
| 29245 | absuelta | 1 |
| 29246 | abstrusas | 1 |
| 29247 | abstraerse | 1 |
| 29248 | abstracciones | 1 |
| 29249 | abstinencia | 1 |
| 29250 | absteniéndose | 1 |
| 29251 | absorción | 1 |
| 29252 | absorbió | 1 |
| 29253 | absorbía | 1 |
| 29254 | absorbederos | 1 |
| 29255 | absolverás | 1 |
| 29256 | absolutista | 1 |
| 29257 | absolución | 1 |
| 29258 | abrumara | 1 |
| 29259 | abrumadoras | 1 |
| 29260 | abrumadora | 1 |
| 29261 | abruma | 1 |
| 29262 | abroñigal | 1 |
| 29263 | abrocharte | 1 |
| 29264 | abrochándose | 1 |
| 29265 | abrirlos | 1 |
| 29266 | abrirla | 1 |
| 29267 | abriría | 1 |
| 29268 | abriremos | 1 |
| 29269 | abrirá | 1 |
| 29270 | abriolo | 1 |
| 29271 | abriole | 1 |
| 29272 | abrigos | 1 |
| 29273 | abrigase | 1 |
| 29274 | abrigas | 1 |
| 29275 | abrigarte | 1 |
| 29276 | abrigarse | 1 |
| 29277 | abrigara | 1 |
| 29278 | abrigar | 1 |
| 29279 | abrigándose | 1 |
| 29280 | abrigándole | 1 |
| 29281 | abrigados | 1 |
| 29282 | abrigaditos | 1 |
| 29283 | abrigaditas | 1 |
| 29284 | abrigábamos | 1 |
| 29285 | abriera | 1 |
| 29286 | abriéndolos | 1 |
| 29287 | abriéndole | 1 |
| 29288 | abriéndolas | 1 |
| 29289 | abriéndola | 1 |
| 29290 | abrí | 1 |
| 29291 | abreviemos | 1 |
| 29292 | abrevie | 1 |
| 29293 | abreviaturas | 1 |
| 29294 | abreviarlos | 1 |
| 29295 | abreviarlo | 1 |
| 29296 | ábrete | 1 |
| 29297 | abrazola | 1 |
| 29298 | abrazara | 1 |
| 29299 | abrazándose | 1 |
| 29300 | abrazándole | 1 |
| 29301 | abrazados | 1 |
| 29302 | abrazaba | 1 |
| 29303 | abrasado | 1 |
| 29304 | abras | 1 |
| 29305 | abran | 1 |
| 29306 | abracitos | 1 |
| 29307 | abovedada | 1 |
| 29308 | abotonándose | 1 |
| 29309 | aborregado | 1 |
| 29310 | aborrecimiento | 1 |
| 29311 | aborreciera | 1 |
| 29312 | aborrecido | 1 |
| 29313 | aborrecidas | 1 |
| 29314 | aborrecida | 1 |
| 29315 | aborrecerlo | 1 |
| 29316 | aborrecerle | 1 |
| 29317 | aboque | 1 |
| 29318 | abonos | 1 |
| 29319 | abono | 1 |
| 29320 | abonados | 1 |
| 29321 | abonado | 1 |
| 29322 | abona | 1 |
| 29323 | abominando | 1 |
| 29324 | abolladuras | 1 |
| 29325 | abollados | 1 |
| 29326 | abolieron | 1 |
| 29327 | abolida | 1 |
| 29328 | abogaba | 1 |
| 29329 | abocose | 1 |
| 29330 | aboco | 1 |
| 29331 | abochornada | 1 |
| 29332 | aboca | 1 |
| 29333 | abnegaciones | 1 |
| 29334 | ablande | 1 |
| 29335 | ablandaría | 1 |
| 29336 | ablanda | 1 |
| 29337 | abigarrado | 1 |
| 29338 | abigarradas | 1 |
| 29339 | abiertamente | 1 |
| 29340 | aberración | 1 |
| 29341 | abejorro | 1 |
| 29342 | abejón | 1 |
| 29343 | abejas | 1 |
| 29344 | abdicar | 1 |
| 29345 | abcesos | 1 |
| 29346 | abatiendo | 1 |
| 29347 | abatidísimo | 1 |
| 29348 | abatida | 1 |
| 29349 | abarcado | 1 |
| 29350 | abarcaban | 1 |
| 29351 | abarca | 1 |
| 29352 | abanicón | 1 |
| 29353 | abanicarse | 1 |
| 29354 | abandonaros | 1 |
| 29355 | abandonaron | 1 |
| 29356 | abandonarlo | 1 |
| 29357 | abandonaría | 1 |
| 29358 | abandonaremos | 1 |
| 29359 | abandonalo | 1 |
| 29360 | abandonados | 1 |
| 29361 | abandonadas | 1 |
| 29362 | abandonaba | 1 |
| 29363 | abalorio | 1 |
| 29364 | abalanzándose | 1 |
| 29365 | abalanzado | 1 |
| 29366 | abajito | 1 |
| 29367 | abadesa | 1 |
|
| Rank | Palabra | Frec |
|---|
| 1 | el | 31365 |
| 2 | de | 20458 |
| 3 | que | 15596 |
| 4 | y | 13273 |
| 5 | lo | 12622 |
| 6 | a | 11998 |
| 7 | se | 8317 |
| 8 | no | 7621 |
| 9 | en | 7593 |
| 10 | un | 6609 |
| 11 | ser | 5091 |
| 12 | su | 5028 |
| 13 | con | 4631 |
| 14 | haber | 4571 |
| 15 | me | 3613 |
| 16 | por | 3599 |
| 17 | decir | 2850 |
| 18 | tener | 2726 |
| 19 | estar | 2658 |
| 20 | más | 2309 |
| 21 | para | 2266 |
| 22 | como | 2162 |
| 23 | pero | 2096 |
| 24 | si | 2030 |
| 25 | hacer | 1936 |
| 26 | ver | 1932 |
| 27 | todo | 1905 |
| 28 | te | 1792 |
| 29 | qué | 1791 |
| 30 | yo | 1697 |
| 31 | aquel | 1674 |
| 32 | usted | 1584 |
| 33 | dar | 1551 |
| 34 | ir | 1528 |
| 35 | este | 1454 |
| 36 | otro | 1374 |
| 37 | querer | 1334 |
| 38 | poder | 1276 |
| 39 | muy | 1215 |
| 40 | éste | 1195 |
| 41 | ya | 1175 |
| 42 | porque | 1094 |
| 43 | cuando | 1083 |
| 44 | ella | 1046 |
| 45 | tan | 1028 |
| 46 | saber | 999 |
| 47 | o | 986 |
| 48 | poner | 954 |
| 49 | pues | 903 |
| 50 | mi | 903 |
| 51 | casa | 884 |
| 52 | bien | 874 |
| 53 | fortunata | 869 |
| 54 | sin | 862 |
| 55 | mucho | 831 |
| 56 | parecer | 829 |
| 57 | él | 796 |
| 58 | día | 759 |
| 59 | la | 754 |
| 60 | ni | 735 |
| 61 | cosa | 735 |
| 62 | sí | 730 |
| 63 | doña | 714 |
| 64 | volver | 681 |
| 65 | bueno | 670 |
| 66 | mujer | 658 |
| 67 | dos | 652 |
| 68 | nada | 642 |
| 69 | mirar | 637 |
| 70 | después | 620 |
| 71 | ese | 613 |
| 72 | poco | 609 |
| 73 | mismo | 603 |
| 74 | salir | 593 |
| 75 | algún | 576 |
| 76 | jacinta | 571 |
| 77 | entrar | 562 |
| 78 | pasar | 561 |
| 79 | tú | 560 |
| 80 | hombre | 558 |
| 81 | hablar | 553 |
| 82 | venir | 552 |
| 83 | grande | 547 |
| 84 | señora | 533 |
| 85 | tanto | 526 |
| 86 | lupe | 520 |
| 87 | aquí | 512 |
| 88 | dios | 508 |
| 89 | llevar | 506 |
| 90 | vez | 504 |
| 91 | mano | 494 |
| 92 | sobre | 489 |
| 93 | dejar | 485 |
| 94 | amigo | 484 |
| 95 | tomar | 483 |
| 96 | hijo | 479 |
| 97 | mí | 475 |
| 98 | ahora | 471 |
| 99 | era | 463 |
| 100 | también | 453 |
| 101 | echar | 446 |
| 102 | algo | 444 |
| 103 | idea | 441 |
| 104 | hasta | 441 |
| 105 | cabeza | 438 |
| 106 | calle | 430 |
| 107 | noche | 426 |
| 108 | oír | 421 |
| 109 | tal | 413 |
| 110 | siempre | 412 |
| 111 | ése | 411 |
| 112 | fin | 409 |
| 113 | tiempo | 406 |
| 114 | vida | 402 |
| 115 | es | 402 |
| 116 | d | 401 |
| 117 | así | 400 |
| 118 | pensar | 397 |
| 119 | llegar | 384 |
| 120 | nos | 380 |
| 121 | comer | 371 |
| 122 | sentir | 361 |
| 123 | allí | 358 |
| 124 | ojo | 356 |
| 125 | quien | 355 |
| 126 | creer | 351 |
| 127 | cómo | 351 |
| 128 | deber | 350 |
| 129 | llamar | 348 |
| 130 | quedar | 340 |
| 131 | tío | 336 |
| 132 | palabra | 336 |
| 133 | cara | 334 |
| 134 | sacar | 332 |
| 135 | malo | 331 |
| 136 | entre | 322 |
| 137 | guillermina | 320 |
| 138 | coger | 319 |
| 139 | persona | 315 |
| 140 | chico | 315 |
| 141 | traer | 314 |
| 142 | cierto | 314 |
| 143 | rubín | 313 |
| 144 | vivir | 311 |
| 145 | alma | 310 |
| 146 | juan | 309 |
| 147 | marido | 308 |
| 148 | maxi | 304 |
| 149 | puerta | 302 |
| 150 | mejor | 298 |
| 151 | cual | 298 |
| 152 | maximiliano | 294 |
| 153 | mal | 294 |
| 154 | tu | 289 |
| 155 | verdad | 284 |
| 156 | contar | 284 |
| 157 | caer | 284 |
| 158 | señor | 277 |
| 159 | mundo | 276 |
| 160 | aunque | 276 |
| 161 | mañana | 275 |
| 162 | cruz | 273 |
| 163 | uno | 267 |
| 164 | empezar | 267 |
| 165 | santa | 266 |
| 166 | pobre | 266 |
| 167 | menos | 266 |
| 168 | desde | 264 |
| 169 | conocer | 263 |
| 170 | encontrar | 259 |
| 171 | seguir | 253 |
| 172 | hecho | 252 |
| 173 | año | 251 |
| 174 | meter | 250 |
| 175 | quitar | 244 |
| 176 | al | 242 |
| 177 | pronto | 238 |
| 178 | luego | 230 |
| 179 | casar | 230 |
| 180 | voz | 228 |
| 181 | reír | 228 |
| 182 | tres | 227 |
| 183 | sino | 227 |
| 184 | hora | 227 |
| 185 | fuera | 224 |
| 186 | ningún | 221 |
| 187 | nunca | 220 |
| 188 | parte | 219 |
| 189 | hermano | 219 |
| 190 | allá | 219 |
| 191 | antes | 217 |
| 192 | donde | 216 |
| 193 | caso | 212 |
| 194 | solo | 211 |
| 195 | mío | 211 |
| 196 | sólo | 202 |
| 197 | cada | 201 |
| 198 | los | 199 |
| 199 | boca | 199 |
| 200 | niño | 198 |
| 201 | morir | 198 |
| 202 | vaya | 196 |
| 203 | tratar | 196 |
| 204 | santo | 195 |
| 205 | faltar | 195 |
| 206 | sentar | 194 |
| 207 | gustar | 194 |
| 208 | pedir | 190 |
| 209 | mauricia | 190 |
| 210 | barbarita | 190 |
| 211 | abrir | 190 |
| 212 | propio | 189 |
| 213 | familia | 189 |
| 214 | perder | 188 |
| 215 | medio | 187 |
| 216 | dormir | 187 |
| 217 | modo | 183 |
| 218 | paso | 182 |
| 219 | ay | 182 |
| 220 | ah | 182 |
| 221 | tarde | 181 |
| 222 | cuarto | 181 |
| 223 | brazo | 180 |
| 224 | mayor | 179 |
| 225 | dijo | 178 |
| 226 | quién | 177 |
| 227 | joven | 177 |
| 228 | corazón | 177 |
| 229 | rato | 176 |
| 230 | hacia | 176 |
| 231 | mandar | 175 |
| 232 | hoy | 173 |
| 233 | una | 170 |
| 234 | madre | 170 |
| 235 | andar | 170 |
| 236 | amor | 166 |
| 237 | ti | 164 |
| 238 | subir | 164 |
| 239 | dónde | 164 |
| 240 | tocar | 163 |
| 241 | nuevo | 161 |
| 242 | izquierdo | 161 |
| 243 | entonces | 161 |
| 244 | cuanto | 161 |
| 245 | preguntar | 160 |
| 246 | levantar | 160 |
| 247 | moreno | 158 |
| 248 | manera | 158 |
| 249 | dentro | 158 |
| 250 | mesa | 157 |
| 251 | ocurrir | 156 |
| 252 | mil | 155 |
| 253 | buscar | 155 |
| 254 | nadie | 154 |
| 255 | lado | 154 |
| 256 | esperar | 154 |
| 257 | cuerpo | 151 |
| 258 | sé | 150 |
| 259 | madrid | 149 |
| 260 | correr | 149 |
| 261 | sobrino | 148 |
| 262 | momento | 146 |
| 263 | punto | 144 |
| 264 | puesto | 144 |
| 265 | pablo | 144 |
| 266 | eso | 143 |
| 267 | dinero | 142 |
| 268 | acabar | 141 |
| 269 | vamos | 140 |
| 270 | delante | 140 |
| 271 | cuatro | 140 |
| 272 | entender | 139 |
| 273 | bajar | 139 |
| 274 | café | 138 |
| 275 | último | 136 |
| 276 | razón | 134 |
| 277 | comprar | 134 |
| 278 | ballester | 134 |
| 279 | gracia | 133 |
| 280 | suyo | 132 |
| 281 | mientras | 132 |
| 282 | gente | 132 |
| 283 | ellos | 132 |
| 284 | contra | 132 |
| 285 | casi | 130 |
| 286 | aquél | 130 |
| 287 | tirar | 129 |
| 288 | negro | 127 |
| 289 | ganar | 127 |
| 290 | pensamiento | 126 |
| 291 | matar | 126 |
| 292 | vuelta | 125 |
| 293 | duda | 124 |
| 294 | mira | 123 |
| 295 | estupiñá | 123 |
| 296 | claro | 123 |
| 297 | aún | 123 |
| 298 | vestir | 122 |
| 299 | padre | 122 |
| 300 | tonto | 121 |
| 301 | ropa | 121 |
| 302 | junto | 121 |
| 303 | ahí | 120 |
| 304 | acordar | 120 |
| 305 | pegar | 119 |
| 306 | miedo | 119 |
| 307 | feijoo | 119 |
| 308 | baldomero | 119 |
| 309 | pasado | 118 |
| 310 | dado | 118 |
| 311 | recibir | 117 |
| 312 | agua | 117 |
| 313 | soltar | 116 |
| 314 | instante | 116 |
| 315 | expresar | 115 |
| 316 | desear | 115 |
| 317 | callar | 115 |
| 318 | bonito | 115 |
| 319 | tienda | 114 |
| 320 | papitos | 114 |
| 321 | cualquier | 114 |
| 322 | sala | 113 |
| 323 | nicolás | 112 |
| 324 | las | 112 |
| 325 | san | 111 |
| 326 | obra | 111 |
| 327 | fuerte | 111 |
| 328 | comprender | 111 |
| 329 | gusto | 110 |
| 330 | valer | 109 |
| 331 | primero | 109 |
| 332 | pie | 109 |
| 333 | trabajo | 108 |
| 334 | servir | 108 |
| 335 | verdadero | 107 |
| 336 | plácido | 107 |
| 337 | luz | 107 |
| 338 | guardar | 107 |
| 339 | mirada | 106 |
| 340 | real | 105 |
| 341 | nuestro | 105 |
| 342 | cuenta | 105 |
| 343 | cama | 105 |
| 344 | trabajar | 104 |
| 345 | cuyo | 104 |
| 346 | aire | 103 |
| 347 | mamá | 102 |
| 348 | evaristo | 102 |
| 349 | ante | 102 |
| 350 | primera | 101 |
| 351 | mes | 101 |
| 352 | siguiente | 100 |
| 353 | papel | 100 |
| 354 | necesitar | 100 |
| 355 | leer | 100 |
| 356 | le | 100 |
| 357 | cielo | 100 |
| 358 | aun | 100 |
| 359 | llenar | 99 |
| 360 | espíritu | 99 |
| 361 | conversación | 99 |
| 362 | salar | 98 |
| 363 | conciencia | 98 |
| 364 | fuerza | 97 |
| 365 | ellas | 97 |
| 366 | diez | 97 |
| 367 | alcoba | 97 |
| 368 | mostrar | 96 |
| 369 | loco | 96 |
| 370 | escalera | 96 |
| 371 | enterar | 96 |
| 372 | único | 95 |
| 373 | vengar | 94 |
| 374 | todavía | 94 |
| 375 | romper | 94 |
| 376 | observar | 94 |
| 377 | juanito | 94 |
| 378 | sentimiento | 93 |
| 379 | segundo | 93 |
| 380 | llorar | 93 |
| 381 | enfermo | 93 |
| 382 | bajo | 93 |
| 383 | pueblo | 92 |
| 384 | delfín | 92 |
| 385 | chiquillo | 92 |
| 386 | presentar | 91 |
| 387 | infeliz | 91 |
| 388 | demás | 91 |
| 389 | retirar | 90 |
| 390 | importar | 90 |
| 391 | gana | 90 |
| 392 | esposo | 90 |
| 393 | nombre | 89 |
| 394 | bastante | 89 |
| 395 | ofrecer | 88 |
| 396 | largo | 88 |
| 397 | humano | 88 |
| 398 | figurar | 88 |
| 399 | permitir | 87 |
| 400 | tono | 86 |
| 401 | suelo | 86 |
| 402 | convenir | 86 |
| 403 | sueño | 85 |
| 404 | responder | 85 |
| 405 | remedio | 85 |
| 406 | precisar | 85 |
| 407 | pañuelo | 85 |
| 408 | josé | 85 |
| 409 | duro | 85 |
| 410 | visita | 84 |
| 411 | rico | 84 |
| 412 | posible | 84 |
| 413 | mover | 84 |
| 414 | dedo | 84 |
| 415 | recoger | 83 |
| 416 | puro | 83 |
| 417 | olvidar | 83 |
| 418 | dama | 83 |
| 419 | cuidar | 83 |
| 420 | tampoco | 82 |
| 421 | lástima | 82 |
| 422 | arreglar | 82 |
| 423 | son | 81 |
| 424 | soler | 81 |
| 425 | quizás | 81 |
| 426 | ido | 81 |
| 427 | enseñar | 81 |
| 428 | despertar | 81 |
| 429 | deseo | 81 |
| 430 | criar | 81 |
| 431 | contestar | 81 |
| 432 | cinco | 81 |
| 433 | perdonar | 80 |
| 434 | muerte | 80 |
| 435 | historia | 80 |
| 436 | engañar | 80 |
| 437 | disponer | 80 |
| 438 | ángel | 80 |
| 439 | silla | 79 |
| 440 | notar | 79 |
| 441 | mente | 79 |
| 442 | conmigo | 79 |
| 443 | cargar | 79 |
| 444 | camino | 79 |
| 445 | atrever | 79 |
| 446 | sostener | 78 |
| 447 | repetir | 78 |
| 448 | peor | 78 |
| 449 | merecer | 78 |
| 450 | expresión | 78 |
| 451 | ello | 78 |
| 452 | carne | 78 |
| 453 | blanco | 78 |
| 454 | armar | 78 |
| 455 | tras | 77 |
| 456 | cumplir | 77 |
| 457 | aurora | 77 |
| 458 | pelo | 76 |
| 459 | media | 76 |
| 460 | jáuregui | 76 |
| 461 | frente | 76 |
| 462 | estado | 76 |
| 463 | aparecer | 76 |
| 464 | abajo | 76 |
| 465 | semejante | 75 |
| 466 | ley | 75 |
| 467 | iglesia | 75 |
| 468 | don | 75 |
| 469 | cortar | 75 |
| 470 | viuda | 74 |
| 471 | pesar | 74 |
| 472 | pagar | 74 |
| 473 | orden | 74 |
| 474 | moral | 74 |
| 475 | escribir | 74 |
| 476 | cuánto | 74 |
| 477 | cariño | 74 |
| 478 | amar | 74 |
| 479 | villalonga | 73 |
| 480 | severiana | 73 |
| 481 | probar | 73 |
| 482 | labio | 73 |
| 483 | durante | 73 |
| 484 | cocina | 73 |
| 485 | acercar | 73 |
| 486 | ustedes | 72 |
| 487 | coser | 72 |
| 488 | aprender | 72 |
| 489 | acompañar | 72 |
| 490 | señorita | 71 |
| 491 | marchar | 71 |
| 492 | concluir | 71 |
| 493 | color | 71 |
| 494 | tontería | 70 |
| 495 | situación | 70 |
| 496 | segunda | 70 |
| 497 | samaniego | 70 |
| 498 | nacer | 70 |
| 499 | frío | 70 |
| 500 | derecho | 70 |
| 501 | curiosidad | 70 |
| 502 | cerrar | 70 |
| 503 | casta | 70 |
| 504 | broma | 70 |
| 505 | seguro | 69 |
| 506 | pasa | 69 |
| 507 | nariz | 69 |
| 508 | exclamó | 69 |
| 509 | descubrir | 69 |
| 510 | balcón | 69 |
| 511 | ayudar | 69 |
| 512 | atención | 69 |
| 513 | alto | 69 |
| 514 | fijar | 68 |
| 515 | cura | 68 |
| 516 | coche | 68 |
| 517 | apenas | 68 |
| 518 | acostar | 68 |
| 519 | sonreír | 67 |
| 520 | risa | 67 |
| 521 | público | 67 |
| 522 | pecho | 67 |
| 523 | falta | 67 |
| 524 | clase | 67 |
| 525 | arriba | 67 |
| 526 | veces | 66 |
| 527 | unir | 66 |
| 528 | plaza | 66 |
| 529 | partir | 66 |
| 530 | honrar | 66 |
| 531 | arrojar | 66 |
| 532 | arnaiz | 66 |
| 533 | apartar | 66 |
| 534 | temer | 65 |
| 535 | sangre | 65 |
| 536 | recordar | 65 |
| 537 | ocasión | 65 |
| 538 | e | 65 |
| 539 | próximo | 64 |
| 540 | pieza | 64 |
| 541 | pena | 64 |
| 542 | paseo | 64 |
| 543 | parar | 64 |
| 544 | monja | 64 |
| 545 | hermoso | 64 |
| 546 | asegurar | 64 |
| 547 | ambos | 64 |
| 548 | alegría | 64 |
| 549 | alegrar | 64 |
| 550 | sor | 63 |
| 551 | según | 63 |
| 552 | preparar | 63 |
| 553 | ocupar | 63 |
| 554 | misa | 63 |
| 555 | memoria | 63 |
| 556 | juicio | 63 |
| 557 | formar | 63 |
| 558 | despedir | 63 |
| 559 | cuidado | 63 |
| 560 | sonar | 62 |
| 561 | sociedad | 62 |
| 562 | primer | 62 |
| 563 | efecto | 62 |
| 564 | repente | 61 |
| 565 | conseguir | 61 |
| 566 | usar | 60 |
| 567 | triste | 60 |
| 568 | tranquilo | 60 |
| 569 | siquiera | 60 |
| 570 | oh | 60 |
| 571 | naturaleza | 60 |
| 572 | jugar | 60 |
| 573 | hija | 60 |
| 574 | del | 60 |
| 575 | clavar | 60 |
| 576 | cerca | 60 |
| 577 | ayer | 60 |
| 578 | apretar | 60 |
| 579 | acá | 60 |
| 580 | virgen | 59 |
| 581 | saltar | 59 |
| 582 | producir | 59 |
| 583 | limpiar | 59 |
| 584 | golpe | 59 |
| 585 | encender | 59 |
| 586 | dolor | 59 |
| 587 | detener | 59 |
| 588 | costumbre | 59 |
| 589 | corredor | 59 |
| 590 | viejo | 58 |
| 591 | sr | 58 |
| 592 | ruido | 58 |
| 593 | mentira | 58 |
| 594 | gordo | 58 |
| 595 | contener | 58 |
| 596 | tristeza | 57 |
| 597 | reconocer | 57 |
| 598 | hombro | 57 |
| 599 | encima | 57 |
| 600 | carácter | 57 |
| 601 | anoche | 57 |
| 602 | vecino | 56 |
| 603 | tus | 56 |
| 604 | sabes | 56 |
| 605 | resultar | 56 |
| 606 | político | 56 |
| 607 | ii | 56 |
| 608 | diferente | 56 |
| 609 | detrás | 56 |
| 610 | asunto | 56 |
| 611 | arte | 56 |
| 612 | vista | 55 |
| 613 | principio | 55 |
| 614 | médico | 55 |
| 615 | maldito | 55 |
| 616 | dudar | 55 |
| 617 | tardar | 54 |
| 618 | tales | 54 |
| 619 | sombrero | 54 |
| 620 | sol | 54 |
| 621 | noticia | 54 |
| 622 | negar | 54 |
| 623 | natural | 54 |
| 624 | frase | 54 |
| 625 | culpa | 54 |
| 626 | asustar | 54 |
| 627 | vivo | 53 |
| 628 | proponer | 53 |
| 629 | padecer | 53 |
| 630 | forma | 53 |
| 631 | difícil | 53 |
| 632 | demonio | 53 |
| 633 | cerebro | 53 |
| 634 | caballero | 53 |
| 635 | botica | 53 |
| 636 | arrancar | 53 |
| 637 | talento | 52 |
| 638 | soñar | 52 |
| 639 | serio | 52 |
| 640 | principal | 52 |
| 641 | pasión | 52 |
| 642 | paciencia | 52 |
| 643 | lengua | 52 |
| 644 | interés | 52 |
| 645 | feo | 52 |
| 646 | feliz | 52 |
| 647 | explicar | 52 |
| 648 | español | 52 |
| 649 | encargar | 52 |
| 650 | emplear | 52 |
| 651 | doce | 52 |
| 652 | confianza | 52 |
| 653 | ánimo | 52 |
| 654 | amo | 52 |
| 655 | alzar | 52 |
| 656 | además | 52 |
| 657 | acción | 52 |
| 658 | sofá | 51 |
| 659 | sitio | 51 |
| 660 | pasillo | 51 |
| 661 | particular | 51 |
| 662 | lógica | 51 |
| 663 | llave | 51 |
| 664 | libro | 51 |
| 665 | habitación | 51 |
| 666 | existir | 51 |
| 667 | disparate | 51 |
| 668 | basilio | 51 |
| 669 | acto | 51 |
| 670 | sentido | 50 |
| 671 | realidad | 50 |
| 672 | pecar | 50 |
| 673 | paz | 50 |
| 674 | pared | 50 |
| 675 | os | 50 |
| 676 | lejos | 50 |
| 677 | i | 50 |
| 678 | horrible | 50 |
| 679 | gabinete | 50 |
| 680 | escapar | 50 |
| 681 | contrario | 50 |
| 682 | compañero | 50 |
| 683 | calor | 50 |
| 684 | atrás | 50 |
| 685 | rostro | 49 |
| 686 | respeto | 49 |
| 687 | honor | 49 |
| 688 | gastar | 49 |
| 689 | fundador | 49 |
| 690 | fe | 49 |
| 691 | defender | 49 |
| 692 | decidir | 49 |
| 693 | cuales | 49 |
| 694 | cantar | 49 |
| 695 | valor | 48 |
| 696 | pintar | 48 |
| 697 | novio | 48 |
| 698 | movimiento | 48 |
| 699 | interior | 48 |
| 700 | ilusión | 48 |
| 701 | hallar | 48 |
| 702 | edad | 48 |
| 703 | convento | 48 |
| 704 | continuar | 48 |
| 705 | causa | 48 |
| 706 | vino | 47 |
| 707 | revolver | 47 |
| 708 | lavar | 47 |
| 709 | inspirar | 47 |
| 710 | gozar | 47 |
| 711 | examinar | 47 |
| 712 | durar | 47 |
| 713 | curar | 47 |
| 714 | considerar | 47 |
| 715 | ambas | 47 |
| 716 | abandonar | 47 |
| 717 | torquemada | 46 |
| 718 | social | 46 |
| 719 | par | 46 |
| 720 | maría | 46 |
| 721 | envolver | 46 |
| 722 | beber | 46 |
| 723 | antiguo | 46 |
| 724 | vergüenza | 45 |
| 725 | ventana | 45 |
| 726 | tierra | 45 |
| 727 | salvar | 45 |
| 728 | religioso | 45 |
| 729 | negocio | 45 |
| 730 | matrimonio | 45 |
| 731 | mantón | 45 |
| 732 | guapo | 45 |
| 733 | esto | 45 |
| 734 | diente | 45 |
| 735 | cristo | 45 |
| 736 | contigo | 45 |
| 737 | visitar | 44 |
| 738 | siete | 44 |
| 739 | rezar | 44 |
| 740 | replicó | 44 |
| 741 | religión | 44 |
| 742 | piedra | 44 |
| 743 | patio | 44 |
| 744 | necesidad | 44 |
| 745 | mar | 44 |
| 746 | lanzar | 44 |
| 747 | impresión | 44 |
| 748 | fondo | 44 |
| 749 | fácil | 44 |
| 750 | divertir | 44 |
| 751 | carta | 44 |
| 752 | bastar | 44 |
| 753 | apoyar | 44 |
| 754 | señorito | 43 |
| 755 | segismundo | 43 |
| 756 | música | 43 |
| 757 | muerto | 43 |
| 758 | jurar | 43 |
| 759 | inclinar | 43 |
| 760 | empeñar | 43 |
| 761 | derecha | 43 |
| 762 | debajo | 43 |
| 763 | comedor | 43 |
| 764 | cambiar | 43 |
| 765 | bota | 43 |
| 766 | bárbara | 43 |
| 767 | aparisi | 43 |
| 768 | víctima | 42 |
| 769 | suerte | 42 |
| 770 | silencio | 42 |
| 771 | seis | 42 |
| 772 | revelar | 42 |
| 773 | portar | 42 |
| 774 | portal | 42 |
| 775 | pan | 42 |
| 776 | objeto | 42 |
| 777 | mona | 42 |
| 778 | micaelas | 42 |
| 779 | jaqueca | 42 |
| 780 | género | 42 |
| 781 | fresco | 42 |
| 782 | establecimiento | 42 |
| 783 | discurrir | 42 |
| 784 | decente | 42 |
| 785 | confesar | 42 |
| 786 | beso | 42 |
| 787 | banco | 42 |
| 788 | apreciar | 42 |
| 789 | anunciar | 42 |
| 790 | adelantar | 42 |
| 791 | tremendo | 41 |
| 792 | temblar | 41 |
| 793 | relación | 41 |
| 794 | perdón | 41 |
| 795 | pedazo | 41 |
| 796 | opinión | 41 |
| 797 | mitad | 41 |
| 798 | lleno | 41 |
| 799 | lenguaje | 41 |
| 800 | lección | 41 |
| 801 | lágrima | 41 |
| 802 | justicia | 41 |
| 803 | ja | 41 |
| 804 | imagen | 41 |
| 805 | esconder | 41 |
| 806 | entregar | 41 |
| 807 | dueño | 41 |
| 808 | disimular | 41 |
| 809 | conservar | 41 |
| 810 | cansar | 41 |
| 811 | azul | 41 |
| 812 | alguien | 41 |
| 813 | agradecer | 41 |
| 814 | absolutamente | 41 |
| 815 | tema | 40 |
| 816 | profundo | 40 |
| 817 | número | 40 |
| 818 | muchacho | 40 |
| 819 | leche | 40 |
| 820 | imposible | 40 |
| 821 | imaginar | 40 |
| 822 | fino | 40 |
| 823 | dirigir | 40 |
| 824 | cuento | 40 |
| 825 | convencer | 40 |
| 826 | contemplar | 40 |
| 827 | colocar | 40 |
| 828 | caña | 40 |
| 829 | averiguar | 40 |
| 830 | asomar | 40 |
| 831 | apetito | 40 |
| 832 | almorzar | 40 |
| 833 | alborotar | 40 |
| 834 | voluntad | 39 |
| 835 | virtud | 39 |
| 836 | temor | 39 |
| 837 | suponer | 39 |
| 838 | simpático | 39 |
| 839 | secreto | 39 |
| 840 | robar | 39 |
| 841 | resistir | 39 |
| 842 | punta | 39 |
| 843 | papá | 39 |
| 844 | muñoz | 39 |
| 845 | mire | 39 |
| 846 | marqués | 39 |
| 847 | igual | 39 |
| 848 | figura | 39 |
| 849 | favor | 39 |
| 850 | esposar | 39 |
| 851 | entretener | 39 |
| 852 | enteramente | 39 |
| 853 | disposición | 39 |
| 854 | criatura | 39 |
| 855 | costar | 39 |
| 856 | contento | 39 |
| 857 | colgar | 39 |
| 858 | capa | 39 |
| 859 | cantidad | 39 |
| 860 | adquirir | 39 |
| 861 | verde | 38 |
| 862 | pico | 38 |
| 863 | pequeño | 38 |
| 864 | pepe | 38 |
| 865 | pasear | 38 |
| 866 | nervioso | 38 |
| 867 | nene | 38 |
| 868 | libertad | 38 |
| 869 | ira | 38 |
| 870 | grito | 38 |
| 871 | flor | 38 |
| 872 | extrañar | 38 |
| 873 | enfadar | 38 |
| 874 | ejemplo | 38 |
| 875 | dulce | 38 |
| 876 | declarar | 38 |
| 877 | completo | 38 |
| 878 | vender | 37 |
| 879 | saludar | 37 |
| 880 | salida | 37 |
| 881 | quevedo | 37 |
| 882 | prestar | 37 |
| 883 | plantar | 37 |
| 884 | oído | 37 |
| 885 | nosotros | 37 |
| 886 | manifestar | 37 |
| 887 | jamás | 37 |
| 888 | disparatar | 37 |
| 889 | determinar | 37 |
| 890 | bendito | 37 |
| 891 | amistad | 37 |
| 892 | aguantar | 37 |
| 893 | acudir | 37 |
| 894 | tragar | 36 |
| 895 | suspiro | 36 |
| 896 | salvaje | 36 |
| 897 | raro | 36 |
| 898 | práctico | 36 |
| 899 | polvo | 36 |
| 900 | plato | 36 |
| 901 | piso | 36 |
| 902 | pasmar | 36 |
| 903 | miseria | 36 |
| 904 | manía | 36 |
| 905 | juanín | 36 |
| 906 | inglés | 36 |
| 907 | iii | 36 |
| 908 | estudiar | 36 |
| 909 | doler | 36 |
| 910 | demasiado | 36 |
| 911 | cuál | 36 |
| 912 | crecer | 36 |
| 913 | convertir | 36 |
| 914 | comunicar | 36 |
| 915 | causar | 36 |
| 916 | campo | 36 |
| 917 | barrio | 36 |
| 918 | amante | 36 |
| 919 | advertir | 36 |
| 920 | admirable | 36 |
| 921 | superior | 35 |
| 922 | suceso | 35 |
| 923 | sospechar | 35 |
| 924 | secar | 35 |
| 925 | pronunciar | 35 |
| 926 | preguntó | 35 |
| 927 | picar | 35 |
| 928 | país | 35 |
| 929 | motivo | 35 |
| 930 | molestar | 35 |
| 931 | lugar | 35 |
| 932 | genio | 35 |
| 933 | falda | 35 |
| 934 | espiritual | 35 |
| 935 | enemigo | 35 |
| 936 | distinto | 35 |
| 937 | chocolate | 35 |
| 938 | ves | 34 |
| 939 | vencer | 34 |
| 940 | separar | 34 |
| 941 | ruiz | 34 |
| 942 | rojo | 34 |
| 943 | querido | 34 |
| 944 | prometer | 34 |
| 945 | pregunta | 34 |
| 946 | plan | 34 |
| 947 | letra | 34 |
| 948 | largar | 34 |
| 949 | ji | 34 |
| 950 | inmenso | 34 |
| 951 | hierro | 34 |
| 952 | gritar | 34 |
| 953 | gracioso | 34 |
| 954 | gobierno | 34 |
| 955 | fuego | 34 |
| 956 | farmacéutico | 34 |
| 957 | delicado | 34 |
| 958 | crear | 34 |
| 959 | consejo | 34 |
| 960 | cesar | 34 |
| 961 | caridad | 34 |
| 962 | cabo | 34 |
| 963 | caber | 34 |
| 964 | bolsillo | 34 |
| 965 | atar | 34 |
| 966 | aceptar | 34 |
| 967 | veras | 33 |
| 968 | velar | 33 |
| 969 | treinta | 33 |
| 970 | teatro | 33 |
| 971 | sonrisa | 33 |
| 972 | señal | 33 |
| 973 | salud | 33 |
| 974 | sacudir | 33 |
| 975 | respecto | 33 |
| 976 | primeros | 33 |
| 977 | poquito | 33 |
| 978 | perro | 33 |
| 979 | pareja | 33 |
| 980 | palo | 33 |
| 981 | olmedo | 33 |
| 982 | ocultar | 33 |
| 983 | intentar | 33 |
| 984 | inocente | 33 |
| 985 | gracias | 33 |
| 986 | gato | 33 |
| 987 | francamente | 33 |
| 988 | extender | 33 |
| 989 | estómago | 33 |
| 990 | escena | 33 |
| 991 | equivocar | 33 |
| 992 | domingo | 33 |
| 993 | distinguir | 33 |
| 994 | dignidad | 33 |
| 995 | cuello | 33 |
| 996 | comercio | 33 |
| 997 | cambio | 33 |
| 998 | caja | 33 |
| 999 | ave | 33 |
| 1000 | aumentar | 33 |
| 1001 | apurar | 33 |
| 1002 | veinte | 32 |
| 1003 | tuyo | 32 |
| 1004 | trato | 32 |
| 1005 | tapar | 32 |
| 1006 | reventar | 32 |
| 1007 | respuesta | 32 |
| 1008 | ratito | 32 |
| 1009 | prisa | 32 |
| 1010 | prenda | 32 |
| 1011 | oscuro | 32 |
| 1012 | oro | 32 |
| 1013 | nueve | 32 |
| 1014 | libre | 32 |
| 1015 | hermosura | 32 |
| 1016 | existencia | 32 |
| 1017 | estilo | 32 |
| 1018 | esta | 32 |
| 1019 | educación | 32 |
| 1020 | dichoso | 32 |
| 1021 | desgraciar | 32 |
| 1022 | desgracia | 32 |
| 1023 | delfina | 32 |
| 1024 | cuestión | 32 |
| 1025 | consolar | 32 |
| 1026 | consentir | 32 |
| 1027 | concepto | 32 |
| 1028 | completamente | 32 |
| 1029 | compañía | 32 |
| 1030 | charlar | 32 |
| 1031 | barbaridad | 32 |
| 1032 | asilo | 32 |
| 1033 | arrastrar | 32 |
| 1034 | añadir | 32 |
| 1035 | alargar | 32 |
| 1036 | actitud | 32 |
| 1037 | versar | 31 |
| 1038 | tertuliar | 31 |
| 1039 | término | 31 |
| 1040 | tela | 31 |
| 1041 | superiora | 31 |
| 1042 | sucio | 31 |
| 1043 | suceder | 31 |
| 1044 | semana | 31 |
| 1045 | rodear | 31 |
| 1046 | rey | 31 |
| 1047 | reloj | 31 |
| 1048 | recomendar | 31 |
| 1049 | preciso | 31 |
| 1050 | oye | 31 |
| 1051 | mueble | 31 |
| 1052 | grave | 31 |
| 1053 | general | 31 |
| 1054 | esfuerzo | 31 |
| 1055 | enfermedad | 31 |
| 1056 | encerrar | 31 |
| 1057 | elegante | 31 |
| 1058 | descomponer | 31 |
| 1059 | cómodo | 31 |
| 1060 | cava | 31 |
| 1061 | breve | 31 |
| 1062 | billete | 31 |
| 1063 | belén | 31 |
| 1064 | autoridad | 31 |
| 1065 | adorar | 31 |
| 1066 | vicio | 30 |
| 1067 | toledo | 30 |
| 1068 | terror | 30 |
| 1069 | terreno | 30 |
| 1070 | sombra | 30 |
| 1071 | rincón | 30 |
| 1072 | representar | 30 |
| 1073 | referir | 30 |
| 1074 | poseer | 30 |
| 1075 | pez | 30 |
| 1076 | penetrar | 30 |
| 1077 | mía | 30 |
| 1078 | librar | 30 |
| 1079 | ladrillo | 30 |
| 1080 | isla | 30 |
| 1081 | impulso | 30 |
| 1082 | imaginación | 30 |
| 1083 | hucha | 30 |
| 1084 | honradez | 30 |
| 1085 | grupo | 30 |
| 1086 | finar | 30 |
| 1087 | fatigar | 30 |
| 1088 | excelente | 30 |
| 1089 | evitar | 30 |
| 1090 | dura | 30 |
| 1091 | desaparecer | 30 |
| 1092 | clérigo | 30 |
| 1093 | ciego | 30 |
| 1094 | cariñoso | 30 |
| 1095 | acento | 30 |
| 1096 | viento | 29 |
| 1097 | trasto | 29 |
| 1098 | tiro | 29 |
| 1099 | techo | 29 |
| 1100 | sujetar | 29 |
| 1101 | siglo | 29 |
| 1102 | servicio | 29 |
| 1103 | respirar | 29 |
| 1104 | resolver | 29 |
| 1105 | quejar | 29 |
| 1106 | puesta | 29 |
| 1107 | proteger | 29 |
| 1108 | periódico | 29 |
| 1109 | pecado | 29 |
| 1110 | nadar | 29 |
| 1111 | menudo | 29 |
| 1112 | ladrón | 29 |
| 1113 | inventar | 29 |
| 1114 | individuo | 29 |
| 1115 | fijo | 29 |
| 1116 | feliciana | 29 |
| 1117 | espejo | 29 |
| 1118 | españa | 29 |
| 1119 | dominar | 29 |
| 1120 | destino | 29 |
| 1121 | cubrir | 29 |
| 1122 | bestia | 29 |
| 1123 | benigna | 29 |
| 1124 | argumento | 29 |
| 1125 | anterior | 29 |
| 1126 | altar | 29 |
| 1127 | volar | 28 |
| 1128 | vacilar | 28 |
| 1129 | tren | 28 |
| 1130 | tender | 28 |
| 1131 | sustancia | 28 |
| 1132 | prueba | 28 |
| 1133 | problema | 28 |
| 1134 | pecador | 28 |
| 1135 | pariente | 28 |
| 1136 | ocho | 28 |
| 1137 | obligar | 28 |
| 1138 | obedecer | 28 |
| 1139 | moda | 28 |
| 1140 | máquina | 28 |
| 1141 | juego | 28 |
| 1142 | iv | 28 |
| 1143 | hoja | 28 |
| 1144 | fundar | 28 |
| 1145 | extremo | 28 |
| 1146 | estúpido | 28 |
| 1147 | esquina | 28 |
| 1148 | época | 28 |
| 1149 | edificio | 28 |
| 1150 | dirección | 28 |
| 1151 | conque | 28 |
| 1152 | componer | 28 |
| 1153 | claridad | 28 |
| 1154 | circunstancia | 28 |
| 1155 | capellán | 28 |
| 1156 | capaz | 28 |
| 1157 | besar | 28 |
| 1158 | atender | 28 |
| 1159 | apuntar | 28 |
| 1160 | aplicar | 28 |
| 1161 | anda | 28 |
| 1162 | acertar | 28 |
| 1163 | vecindad | 27 |
| 1164 | varias | 27 |
| 1165 | valiente | 27 |
| 1166 | v | 27 |
| 1167 | trastornar | 27 |
| 1168 | traje | 27 |
| 1169 | timidez | 27 |
| 1170 | seso | 27 |
| 1171 | serenidad | 27 |
| 1172 | semblante | 27 |
| 1173 | seguramente | 27 |
| 1174 | reñir | 27 |
| 1175 | rabia | 27 |
| 1176 | propósito | 27 |
| 1177 | prójima | 27 |
| 1178 | primo | 27 |
| 1179 | pertenecer | 27 |
| 1180 | parir | 27 |
| 1181 | obligación | 27 |
| 1182 | noble | 27 |
| 1183 | mozo | 27 |
| 1184 | minuto | 27 |
| 1185 | mérito | 27 |
| 1186 | medicina | 27 |
| 1187 | león | 27 |
| 1188 | iluminar | 27 |
| 1189 | huevo | 27 |
| 1190 | guerra | 27 |
| 1191 | falso | 27 |
| 1192 | extranjero | 27 |
| 1193 | encarnación | 27 |
| 1194 | dicho | 27 |
| 1195 | convicción | 27 |
| 1196 | conformar | 27 |
| 1197 | cobrar | 27 |
| 1198 | ciencia | 27 |
| 1199 | celo | 27 |
| 1200 | carrera | 27 |
| 1201 | árbol | 27 |
| 1202 | agarrar | 27 |
| 1203 | admirar | 27 |
| 1204 | adiós | 27 |
| 1205 | aburrir | 27 |
| 1206 | viaje | 26 |
| 1207 | vela | 26 |
| 1208 | variar | 26 |
| 1209 | trapo | 26 |
| 1210 | tranquilizar | 26 |
| 1211 | total | 26 |
| 1212 | tertulia | 26 |
| 1213 | satisfacer | 26 |
| 1214 | satisfacción | 26 |
| 1215 | sabe | 26 |
| 1216 | ratos | 26 |
| 1217 | plata | 26 |
| 1218 | permanecer | 26 |
| 1219 | perfecto | 26 |
| 1220 | parroquiano | 26 |
| 1221 | oreja | 26 |
| 1222 | oler | 26 |
| 1223 | oficio | 26 |
| 1224 | obtener | 26 |
| 1225 | observación | 26 |
| 1226 | mosca | 26 |
| 1227 | madera | 26 |
| 1228 | lucir | 26 |
| 1229 | lecho | 26 |
| 1230 | interesar | 26 |
| 1231 | indecente | 26 |
| 1232 | increíble | 26 |
| 1233 | imponer | 26 |
| 1234 | humor | 26 |
| 1235 | hueco | 26 |
| 1236 | gesto | 26 |
| 1237 | filosofía | 26 |
| 1238 | excitar | 26 |
| 1239 | estudio | 26 |
| 1240 | entusiasmar | 26 |
| 1241 | entendimiento | 26 |
| 1242 | diferencia | 26 |
| 1243 | cuerda | 26 |
| 1244 | cuándo | 26 |
| 1245 | corriente | 26 |
| 1246 | contentar | 26 |
| 1247 | condenar | 26 |
| 1248 | compra | 26 |
| 1249 | comida | 26 |
| 1250 | caballo | 26 |
| 1251 | boda | 26 |
| 1252 | atravesar | 26 |
| 1253 | asiento | 26 |
| 1254 | absoluto | 26 |
| 1255 | villuendas | 25 |
| 1256 | vaso | 25 |
| 1257 | tiene | 25 |
| 1258 | sorprender | 25 |
| 1259 | soledad | 25 |
| 1260 | significar | 25 |
| 1261 | seno | 25 |
| 1262 | rodilla | 25 |
| 1263 | retrato | 25 |
| 1264 | recado | 25 |
| 1265 | ramo | 25 |
| 1266 | piedad | 25 |
| 1267 | perfectamente | 25 |
| 1268 | parís | 25 |
| 1269 | olor | 25 |
| 1270 | novedad | 25 |
| 1271 | nicanora | 25 |
| 1272 | menor | 25 |
| 1273 | mantener | 25 |
| 1274 | limosna | 25 |
| 1275 | lectura | 25 |
| 1276 | intención | 25 |
| 1277 | incomodar | 25 |
| 1278 | hostia | 25 |
| 1279 | haz | 25 |
| 1280 | hartar | 25 |
| 1281 | hambre | 25 |
| 1282 | físico | 25 |
| 1283 | farmacia | 25 |
| 1284 | entusiasmo | 25 |
| 1285 | doblar | 25 |
| 1286 | cruzar | 25 |
| 1287 | criada | 25 |
| 1288 | convidar | 25 |
| 1289 | condición | 25 |
| 1290 | cincuenta | 25 |
| 1291 | calmar | 25 |
| 1292 | arrepentir | 25 |
| 1293 | acostumbrar | 25 |
| 1294 | terrible | 24 |
| 1295 | sufrir | 24 |
| 1296 | suegro | 24 |
| 1297 | sorpresa | 24 |
| 1298 | sofocar | 24 |
| 1299 | síntoma | 24 |
| 1300 | señalar | 24 |
| 1301 | seda | 24 |
| 1302 | santidad | 24 |
| 1303 | resultado | 24 |
| 1304 | recobrar | 24 |
| 1305 | rafaela | 24 |
| 1306 | quiere | 24 |
| 1307 | puño | 24 |
| 1308 | presencia | 24 |
| 1309 | personal | 24 |
| 1310 | peinar | 24 |
| 1311 | pálido | 24 |
| 1312 | pájaro | 24 |
| 1313 | pacheco | 24 |
| 1314 | muchísimo | 24 |
| 1315 | misterioso | 24 |
| 1316 | manta | 24 |
| 1317 | maestro | 24 |
| 1318 | lujo | 24 |
| 1319 | juntar | 24 |
| 1320 | indicar | 24 |
| 1321 | impedir | 24 |
| 1322 | hueso | 24 |
| 1323 | herencia | 24 |
| 1324 | grado | 24 |
| 1325 | gloria | 24 |
| 1326 | furioso | 24 |
| 1327 | extraordinario | 24 |
| 1328 | espalda | 24 |
| 1329 | escuela | 24 |
| 1330 | desconocer | 24 |
| 1331 | descansar | 24 |
| 1332 | demostrar | 24 |
| 1333 | decía | 24 |
| 1334 | debilidad | 24 |
| 1335 | corto | 24 |
| 1336 | compasión | 24 |
| 1337 | comedia | 24 |
| 1338 | círculo | 24 |
| 1339 | anciano | 24 |
| 1340 | alcanzar | 24 |
| 1341 | ahogar | 24 |
| 1342 | agradar | 24 |
| 1343 | adoración | 24 |
| 1344 | uso | 23 |
| 1345 | toda | 23 |
| 1346 | tipo | 23 |
| 1347 | temeroso | 23 |
| 1348 | sosegar | 23 |
| 1349 | severidad | 23 |
| 1350 | sabio | 23 |
| 1351 | respetar | 23 |
| 1352 | reparar | 23 |
| 1353 | remediar | 23 |
| 1354 | rápidamente | 23 |
| 1355 | rama | 23 |
| 1356 | procurar | 23 |
| 1357 | podrir | 23 |
| 1358 | pícaro | 23 |
| 1359 | periodo | 23 |
| 1360 | pata | 23 |
| 1361 | orgullo | 23 |
| 1362 | ordinario | 23 |
| 1363 | oponer | 23 |
| 1364 | olimpia | 23 |
| 1365 | nombrar | 23 |
| 1366 | mudar | 23 |
| 1367 | moneda | 23 |
| 1368 | marcela | 23 |
| 1369 | marcar | 23 |
| 1370 | manto | 23 |
| 1371 | ligero | 23 |
| 1372 | jesús | 23 |
| 1373 | isabel | 23 |
| 1374 | infame | 23 |
| 1375 | humanidad | 23 |
| 1376 | huir | 23 |
| 1377 | honrado | 23 |
| 1378 | hábito | 23 |
| 1379 | gobernar | 23 |
| 1380 | facultad | 23 |
| 1381 | energía | 23 |
| 1382 | enamorar | 23 |
| 1383 | difunto | 23 |
| 1384 | cristiano | 23 |
| 1385 | cometer | 23 |
| 1386 | bruto | 23 |
| 1387 | avanzar | 23 |
| 1388 | artículo | 23 |
| 1389 | animar | 23 |
| 1390 | amarillo | 23 |
| 1391 | ajeno | 23 |
| 1392 | abrazar | 23 |
| 1393 | aborrecer | 23 |
| 1394 | vi | 22 |
| 1395 | temprano | 22 |
| 1396 | sinceridad | 22 |
| 1397 | serenar | 22 |
| 1398 | seguridad | 22 |
| 1399 | santísimo | 22 |
| 1400 | sano | 22 |
| 1401 | salón | 22 |
| 1402 | sacerdote | 22 |
| 1403 | rodar | 22 |
| 1404 | río | 22 |
| 1405 | recorrer | 22 |
| 1406 | realizar | 22 |
| 1407 | rabiar | 22 |
| 1408 | quedose | 22 |
| 1409 | peso | 22 |
| 1410 | peseta | 22 |
| 1411 | peligro | 22 |
| 1412 | paquete | 22 |
| 1413 | paño | 22 |
| 1414 | nosotras | 22 |
| 1415 | norte | 22 |
| 1416 | miserable | 22 |
| 1417 | manuel | 22 |
| 1418 | línea | 22 |
| 1419 | inquietud | 22 |
| 1420 | importancia | 22 |
| 1421 | hay | 22 |
| 1422 | fortuna | 22 |
| 1423 | formalidad | 22 |
| 1424 | fingir | 22 |
| 1425 | felicidad | 22 |
| 1426 | estás | 22 |
| 1427 | escándalo | 22 |
| 1428 | empujar | 22 |
| 1429 | emoción | 22 |
| 1430 | eh | 22 |
| 1431 | echado | 22 |
| 1432 | doméstico | 22 |
| 1433 | distraer | 22 |
| 1434 | dificultad | 22 |
| 1435 | dedicar | 22 |
| 1436 | cuadro | 22 |
| 1437 | cristal | 22 |
| 1438 | copa | 22 |
| 1439 | consultar | 22 |
| 1440 | consecuencia | 22 |
| 1441 | cintura | 22 |
| 1442 | célebre | 22 |
| 1443 | ceja | 22 |
| 1444 | castigar | 22 |
| 1445 | cargo | 22 |
| 1446 | capital | 22 |
| 1447 | camisa | 22 |
| 1448 | calma | 22 |
| 1449 | buen | 22 |
| 1450 | barba | 22 |
| 1451 | bailar | 22 |
| 1452 | asombrar | 22 |
| 1453 | apariencia | 22 |
| 1454 | alejar | 22 |
| 1455 | agujero | 22 |
| 1456 | afectar | 22 |
| 1457 | acometer | 22 |
| 1458 | acera | 22 |
| 1459 | verdaderamente | 21 |
| 1460 | tranquilidad | 21 |
| 1461 | trampa | 21 |
| 1462 | sujeto | 21 |
| 1463 | suelto | 21 |
| 1464 | simpatía | 21 |
| 1465 | sillón | 21 |
| 1466 | santísima | 21 |
| 1467 | risueño | 21 |
| 1468 | repartir | 21 |
| 1469 | quieres | 21 |
| 1470 | querida | 21 |
| 1471 | presente | 21 |
| 1472 | plazuela | 21 |
| 1473 | partido | 21 |
| 1474 | oscuridad | 21 |
| 1475 | ordenar | 21 |
| 1476 | ofender | 21 |
| 1477 | nones | 21 |
| 1478 | nacimiento | 21 |
| 1479 | montón | 21 |
| 1480 | meditar | 21 |
| 1481 | mas | 21 |
| 1482 | local | 21 |
| 1483 | limpio | 21 |
| 1484 | judío | 21 |
| 1485 | íntimo | 21 |
| 1486 | inteligencia | 21 |
| 1487 | inmediato | 21 |
| 1488 | idear | 21 |
| 1489 | horror | 21 |
| 1490 | ha | 21 |
| 1491 | gravar | 21 |
| 1492 | explicación | 21 |
| 1493 | está | 21 |
| 1494 | entero | 21 |
| 1495 | enorme | 21 |
| 1496 | distancia | 21 |
| 1497 | disgusto | 21 |
| 1498 | discutir | 21 |
| 1499 | discreto | 21 |
| 1500 | desdén | 21 |
| 1501 | cordero | 21 |
| 1502 | consistir | 21 |
| 1503 | conocimiento | 21 |
| 1504 | confundir | 21 |
| 1505 | cajón | 21 |
| 1506 | bribón | 21 |
| 1507 | bola | 21 |
| 1508 | bofetada | 21 |
| 1509 | asco | 21 |
| 1510 | antonio | 21 |
| 1511 | animal | 21 |
| 1512 | admiración | 21 |
| 1513 | ademán | 21 |
| 1514 | adelante | 21 |
| 1515 | acerca | 21 |
| 1516 | acentuar | 21 |
| 1517 | zalamero | 20 |
| 1518 | vera | 20 |
| 1519 | varios | 20 |
| 1520 | vanidad | 20 |
| 1521 | tunante | 20 |
| 1522 | tropa | 20 |
| 1523 | tía | 20 |
| 1524 | tarascar | 20 |
| 1525 | socorro | 20 |
| 1526 | sistema | 20 |
| 1527 | seco | 20 |
| 1528 | sagrario | 20 |
| 1529 | sagrado | 20 |
| 1530 | sábana | 20 |
| 1531 | resto | 20 |
| 1532 | reservar | 20 |
| 1533 | referente | 20 |
| 1534 | quieto | 20 |
| 1535 | quemar | 20 |
| 1536 | pretender | 20 |
| 1537 | pintado | 20 |
| 1538 | pesado | 20 |
| 1539 | patricia | 20 |
| 1540 | pase | 20 |
| 1541 | orar | 20 |
| 1542 | naturalmente | 20 |
| 1543 | modelo | 20 |
| 1544 | magnífico | 20 |
| 1545 | maestra | 20 |
| 1546 | jueves | 20 |
| 1547 | insignificante | 20 |
| 1548 | huerta | 20 |
| 1549 | gozoso | 20 |
| 1550 | ginés | 20 |
| 1551 | función | 20 |
| 1552 | franqueza | 20 |
| 1553 | francisco | 20 |
| 1554 | firmar | 20 |
| 1555 | fiera | 20 |
| 1556 | fiel | 20 |
| 1557 | fenómeno | 20 |
| 1558 | establecer | 20 |
| 1559 | esperanza | 20 |
| 1560 | espacio | 20 |
| 1561 | embargo | 20 |
| 1562 | económico | 20 |
| 1563 | divino | 20 |
| 1564 | desplegar | 20 |
| 1565 | despachar | 20 |
| 1566 | deshacer | 20 |
| 1567 | desempeñar | 20 |
| 1568 | dependiente | 20 |
| 1569 | dato | 20 |
| 1570 | consuelo | 20 |
| 1571 | confusión | 20 |
| 1572 | conducta | 20 |
| 1573 | combinar | 20 |
| 1574 | capilla | 20 |
| 1575 | campanilla | 20 |
| 1576 | buena | 20 |
| 1577 | bobo | 20 |
| 1578 | bah | 20 |
| 1579 | avisar | 20 |
| 1580 | aspecto | 20 |
| 1581 | aproximar | 20 |
| 1582 | amenazar | 20 |
| 1583 | admitir | 20 |
| 1584 | abrigo | 20 |
| 1585 | vestido | 19 |
| 1586 | venga | 19 |
| 1587 | solar | 19 |
| 1588 | simple | 19 |
| 1589 | seriedad | 19 |
| 1590 | seguida | 19 |
| 1591 | ridículo | 19 |
| 1592 | revólver | 19 |
| 1593 | rendir | 19 |
| 1594 | rencor | 19 |
| 1595 | reja | 19 |
| 1596 | rápido | 19 |
| 1597 | prudente | 19 |
| 1598 | protección | 19 |
| 1599 | proceder | 19 |
| 1600 | pretexto | 19 |
| 1601 | presunción | 19 |
| 1602 | préstamo | 19 |
| 1603 | pozo | 19 |
| 1604 | personar | 19 |
| 1605 | nube | 19 |
| 1606 | novela | 19 |
| 1607 | nota | 19 |
| 1608 | natividad | 19 |
| 1609 | murmuró | 19 |
| 1610 | medida | 19 |
| 1611 | limpieza | 19 |
| 1612 | instinto | 19 |
| 1613 | infierno | 19 |
| 1614 | importante | 19 |
| 1615 | hacienda | 19 |
| 1616 | gumersindo | 19 |
| 1617 | fórmula | 19 |
| 1618 | facha | 19 |
| 1619 | extraño | 19 |
| 1620 | estirar | 19 |
| 1621 | estación | 19 |
| 1622 | especie | 19 |
| 1623 | espantar | 19 |
| 1624 | escalón | 19 |
| 1625 | encargo | 19 |
| 1626 | educar | 19 |
| 1627 | duque | 19 |
| 1628 | despacho | 19 |
| 1629 | deshonrar | 19 |
| 1630 | cuerdo | 19 |
| 1631 | crimen | 19 |
| 1632 | comparar | 19 |
| 1633 | celebrar | 19 |
| 1634 | busca | 19 |
| 1635 | botón | 19 |
| 1636 | borrar | 19 |
| 1637 | bondad | 19 |
| 1638 | belleza | 19 |
| 1639 | bastón | 19 |
| 1640 | artista | 19 |
| 1641 | aplacar | 19 |
| 1642 | antipático | 19 |
| 1643 | alta | 19 |
| 1644 | almuerzo | 19 |
| 1645 | afecto | 19 |
| 1646 | adentrar | 19 |
| 1647 | acaso | 19 |
| 1648 | vulgar | 18 |
| 1649 | veinticinco | 18 |
| 1650 | vale | 18 |
| 1651 | turbar | 18 |
| 1652 | trujillo | 18 |
| 1653 | tropezar | 18 |
| 1654 | tercera | 18 |
| 1655 | suavemente | 18 |
| 1656 | socorrer | 18 |
| 1657 | sermón | 18 |
| 1658 | sencillo | 18 |
| 1659 | satisfecho | 18 |
| 1660 | repitió | 18 |
| 1661 | regular | 18 |
| 1662 | profesor | 18 |
| 1663 | primeras | 18 |
| 1664 | precisamente | 18 |
| 1665 | partida | 18 |
| 1666 | pantalón | 18 |
| 1667 | once | 18 |
| 1668 | noticiar | 18 |
| 1669 | misterio | 18 |
| 1670 | militar | 18 |
| 1671 | mental | 18 |
| 1672 | mejilla | 18 |
| 1673 | marcha | 18 |
| 1674 | lograr | 18 |
| 1675 | locura | 18 |
| 1676 | lance | 18 |
| 1677 | juzgar | 18 |
| 1678 | inútil | 18 |
| 1679 | infantil | 18 |
| 1680 | indicó | 18 |
| 1681 | improvisar | 18 |
| 1682 | hilo | 18 |
| 1683 | herir | 18 |
| 1684 | hablador | 18 |
| 1685 | guardia | 18 |
| 1686 | guante | 18 |
| 1687 | gritó | 18 |
| 1688 | furor | 18 |
| 1689 | frotar | 18 |
| 1690 | fenelón | 18 |
| 1691 | federico | 18 |
| 1692 | eterno | 18 |
| 1693 | estremecer | 18 |
| 1694 | estrellar | 18 |
| 1695 | entierro | 18 |
| 1696 | ejercicio | 18 |
| 1697 | disputar | 18 |
| 1698 | dignar | 18 |
| 1699 | devoción | 18 |
| 1700 | desorden | 18 |
| 1701 | delirio | 18 |
| 1702 | corte | 18 |
| 1703 | conveniente | 18 |
| 1704 | consideración | 18 |
| 1705 | conforme | 18 |
| 1706 | confiar | 18 |
| 1707 | común | 18 |
| 1708 | claramente | 18 |
| 1709 | chillido | 18 |
| 1710 | centro | 18 |
| 1711 | ceder | 18 |
| 1712 | carcajada | 18 |
| 1713 | burlar | 18 |
| 1714 | arreglo | 18 |
| 1715 | arma | 18 |
| 1716 | apresurar | 18 |
| 1717 | aparentar | 18 |
| 1718 | amiguito | 18 |
| 1719 | aguardar | 18 |
| 1720 | adivinar | 18 |
| 1721 | vii | 17 |
| 1722 | vigilar | 17 |
| 1723 | vara | 17 |
| 1724 | trocar | 17 |
| 1725 | trance | 17 |
| 1726 | toma | 17 |
| 1727 | tocayo | 17 |
| 1728 | tierno | 17 |
| 1729 | tantísimo | 17 |
| 1730 | tamaño | 17 |
| 1731 | taller | 17 |
| 1732 | soy | 17 |
| 1733 | sobrar | 17 |
| 1734 | sea | 17 |
| 1735 | retiro | 17 |
| 1736 | reducir | 17 |
| 1737 | ramón | 17 |
| 1738 | provincia | 17 |
| 1739 | providencia | 17 |
| 1740 | preferir | 17 |
| 1741 | precioso | 17 |
| 1742 | pongo | 17 |
| 1743 | pluma | 17 |
| 1744 | píldora | 17 |
| 1745 | pescar | 17 |
| 1746 | perdido | 17 |
| 1747 | patria | 17 |
| 1748 | parecido | 17 |
| 1749 | parece | 17 |
| 1750 | pardo | 17 |
| 1751 | necesario | 17 |
| 1752 | montes | 17 |
| 1753 | modal | 17 |
| 1754 | masa | 17 |
| 1755 | marear | 17 |
| 1756 | manolo | 17 |
| 1757 | maldad | 17 |
| 1758 | liberal | 17 |
| 1759 | invitar | 17 |
| 1760 | infundir | 17 |
| 1761 | indignar | 17 |
| 1762 | impertinente | 17 |
| 1763 | humo | 17 |
| 1764 | heredar | 17 |
| 1765 | grueso | 17 |
| 1766 | grandísimo | 17 |
| 1767 | francia | 17 |
| 1768 | finísimo | 17 |
| 1769 | febril | 17 |
| 1770 | fábrica | 17 |
| 1771 | extraordinariamente | 17 |
| 1772 | estudiante | 17 |
| 1773 | entrada | 17 |
| 1774 | ea | 17 |
| 1775 | diverso | 17 |
| 1776 | devolver | 17 |
| 1777 | despreciar | 17 |
| 1778 | desarrollar | 17 |
| 1779 | defensa | 17 |
| 1780 | decoro | 17 |
| 1781 | débil | 17 |
| 1782 | cristianar | 17 |
| 1783 | corresponder | 17 |
| 1784 | comentario | 17 |
| 1785 | codo | 17 |
| 1786 | ciento | 17 |
| 1787 | cien | 17 |
| 1788 | chupar | 17 |
| 1789 | cegar | 17 |
| 1790 | carro | 17 |
| 1791 | cárcel | 17 |
| 1792 | calentar | 17 |
| 1793 | cálculo | 17 |
| 1794 | cabello | 17 |
| 1795 | bulto | 17 |
| 1796 | bruscamente | 17 |
| 1797 | botella | 17 |
| 1798 | baúl | 17 |
| 1799 | azúcar | 17 |
| 1800 | autor | 17 |
| 1801 | asombro | 17 |
| 1802 | ardor | 17 |
| 1803 | aprovechar | 17 |
| 1804 | apagar | 17 |
| 1805 | alumno | 17 |
| 1806 | aguja | 17 |
| 1807 | afán | 17 |
| 1808 | acariciar | 17 |
| 1809 | vetar | 16 |
| 1810 | verano | 16 |
| 1811 | verá | 16 |
| 1812 | toro | 16 |
| 1813 | tendero | 16 |
| 1814 | será | 16 |
| 1815 | sensación | 16 |
| 1816 | sanar | 16 |
| 1817 | salita | 16 |
| 1818 | rumor | 16 |
| 1819 | reunir | 16 |
| 1820 | refugio | 16 |
| 1821 | quince | 16 |
| 1822 | principiar | 16 |
| 1823 | pillo | 16 |
| 1824 | pierna | 16 |
| 1825 | perseguir | 16 |
| 1826 | pensó | 16 |
| 1827 | pedro | 16 |
| 1828 | parentesco | 16 |
| 1829 | nuera | 16 |
| 1830 | monte | 16 |
| 1831 | ministro | 16 |
| 1832 | machacar | 16 |
| 1833 | lotería | 16 |
| 1834 | lío | 16 |
| 1835 | lejano | 16 |
| 1836 | inspiración | 16 |
| 1837 | insistir | 16 |
| 1838 | inferior | 16 |
| 1839 | histórico | 16 |
| 1840 | he | 16 |
| 1841 | gota | 16 |
| 1842 | gas | 16 |
| 1843 | fisonomía | 16 |
| 1844 | fiebre | 16 |
| 1845 | fecha | 16 |
| 1846 | favorecer | 16 |
| 1847 | facción | 16 |
| 1848 | extensión | 16 |
| 1849 | exponer | 16 |
| 1850 | escoger | 16 |
| 1851 | error | 16 |
| 1852 | envidiar | 16 |
| 1853 | enfrente | 16 |
| 1854 | domicilio | 16 |
| 1855 | doctrina | 16 |
| 1856 | diablo | 16 |
| 1857 | descargar | 16 |
| 1858 | desagradable | 16 |
| 1859 | deje | 16 |
| 1860 | cuarenta | 16 |
| 1861 | crítico | 16 |
| 1862 | crisis | 16 |
| 1863 | cortesía | 16 |
| 1864 | constituir | 16 |
| 1865 | conferencia | 16 |
| 1866 | conducir | 16 |
| 1867 | completar | 16 |
| 1868 | chillar | 16 |
| 1869 | catar | 16 |
| 1870 | castelar | 16 |
| 1871 | casamiento | 16 |
| 1872 | caro | 16 |
| 1873 | ataque | 16 |
| 1874 | asistir | 16 |
| 1875 | arroz | 16 |
| 1876 | ardiente | 16 |
| 1877 | ansiedad | 16 |
| 1878 | almohada | 16 |
| 1879 | actividad | 16 |
| 1880 | abrigar | 16 |
| 1881 | abierto | 16 |
| 1882 | vicioso | 15 |
| 1883 | vía | 15 |
| 1884 | velo | 15 |
| 1885 | uña | 15 |
| 1886 | turbación | 15 |
| 1887 | tesoro | 15 |
| 1888 | té | 15 |
| 1889 | suspender | 15 |
| 1890 | seguido | 15 |
| 1891 | seductor | 15 |
| 1892 | salto | 15 |
| 1893 | salido | 15 |
| 1894 | rubio | 15 |
| 1895 | rosario | 15 |
| 1896 | rigor | 15 |
| 1897 | replicar | 15 |
| 1898 | relacionar | 15 |
| 1899 | redondo | 15 |
| 1900 | rebajar | 15 |
| 1901 | proyecto | 15 |
| 1902 | pontejos | 15 |
| 1903 | poeta | 15 |
| 1904 | pintura | 15 |
| 1905 | piel | 15 |
| 1906 | pensaba | 15 |
| 1907 | peldaño | 15 |
| 1908 | párpado | 15 |
| 1909 | papa | 15 |
| 1910 | paloma | 15 |
| 1911 | paca | 15 |
| 1912 | oscuras | 15 |
| 1913 | orgulloso | 15 |
| 1914 | operación | 15 |
| 1915 | oiga | 15 |
| 1916 | niñez | 15 |
| 1917 | nervio | 15 |
| 1918 | morenos | 15 |
| 1919 | montar | 15 |
| 1920 | ministerio | 15 |
| 1921 | mejorar | 15 |
| 1922 | meditación | 15 |
| 1923 | maña | 15 |
| 1924 | levita | 15 |
| 1925 | lentamente | 15 |
| 1926 | insigne | 15 |
| 1927 | ideal | 15 |
| 1928 | goce | 15 |
| 1929 | fresca | 15 |
| 1930 | final | 15 |
| 1931 | fiar | 15 |
| 1932 | favorable | 15 |
| 1933 | éxito | 15 |
| 1934 | exigir | 15 |
| 1935 | estoy | 15 |
| 1936 | espectáculo | 15 |
| 1937 | esparcir | 15 |
| 1938 | esforzar | 15 |
| 1939 | distracción | 15 |
| 1940 | deuda | 15 |
| 1941 | desvanecer | 15 |
| 1942 | descuidar | 15 |
| 1943 | cuchillo | 15 |
| 1944 | cruel | 15 |
| 1945 | crees | 15 |
| 1946 | constar | 15 |
| 1947 | consagrar | 15 |
| 1948 | comprometer | 15 |
| 1949 | clavo | 15 |
| 1950 | cigarro | 15 |
| 1951 | chuleta | 15 |
| 1952 | chistar | 15 |
| 1953 | chamberí | 15 |
| 1954 | cerebral | 15 |
| 1955 | cavilación | 15 |
| 1956 | casualidad | 15 |
| 1957 | candelaria | 15 |
| 1958 | calcular | 15 |
| 1959 | buenas | 15 |
| 1960 | brillar | 15 |
| 1961 | atormentar | 15 |
| 1962 | aterrar | 15 |
| 1963 | aspirar | 15 |
| 1964 | aplicación | 15 |
| 1965 | angelical | 15 |
| 1966 | acechar | 15 |
| 1967 | venganza | 14 |
| 1968 | valencia | 14 |
| 1969 | vago | 14 |
| 1970 | vagar | 14 |
| 1971 | trastorno | 14 |
| 1972 | toquilla | 14 |
| 1973 | susto | 14 |
| 1974 | solución | 14 |
| 1975 | soberbio | 14 |
| 1976 | silvia | 14 |
| 1977 | sal | 14 |
| 1978 | riqueza | 14 |
| 1979 | reproducir | 14 |
| 1980 | relativo | 14 |
| 1981 | reinar | 14 |
| 1982 | regalo | 14 |
| 1983 | recogida | 14 |
| 1984 | razonable | 14 |
| 1985 | rayo | 14 |
| 1986 | quia | 14 |
| 1987 | protestante | 14 |
| 1988 | profundamente | 14 |
| 1989 | procesión | 14 |
| 1990 | pretensión | 14 |
| 1991 | porvenir | 14 |
| 1992 | popular | 14 |
| 1993 | pobreza | 14 |
| 1994 | pensativo | 14 |
| 1995 | penoso | 14 |
| 1996 | peine | 14 |
| 1997 | mortificar | 14 |
| 1998 | monstruo | 14 |
| 1999 | modestia | 14 |
| 2000 | milagro | 14 |
| 2001 | metal | 14 |
| 2002 | menester | 14 |
| 2003 | marzo | 14 |
| 2004 | londres | 14 |
| 2005 | jefe | 14 |
| 2006 | introducir | 14 |
| 2007 | inteligente | 14 |
| 2008 | inquietar | 14 |
| 2009 | iniciar | 14 |
| 2010 | infalible | 14 |
| 2011 | inexplicable | 14 |
| 2012 | inconveniente | 14 |
| 2013 | grosero | 14 |
| 2014 | gorro | 14 |
| 2015 | gloriar | 14 |
| 2016 | garganta | 14 |
| 2017 | gallo | 14 |
| 2018 | finca | 14 |
| 2019 | fácilmente | 14 |
| 2020 | extravagancia | 14 |
| 2021 | examen | 14 |
| 2022 | estancia | 14 |
| 2023 | enredar | 14 |
| 2024 | encendido | 14 |
| 2025 | disgustar | 14 |
| 2026 | discurso | 14 |
| 2027 | dice | 14 |
| 2028 | determinación | 14 |
| 2029 | despacio | 14 |
| 2030 | desazón | 14 |
| 2031 | derramar | 14 |
| 2032 | déjame | 14 |
| 2033 | defecto | 14 |
| 2034 | crudo | 14 |
| 2035 | criminal | 14 |
| 2036 | corregir | 14 |
| 2037 | condenado | 14 |
| 2038 | compromiso | 14 |
| 2039 | comercial | 14 |
| 2040 | comandanta | 14 |
| 2041 | cólera | 14 |
| 2042 | cerrado | 14 |
| 2043 | cementerio | 14 |
| 2044 | caricia | 14 |
| 2045 | borde | 14 |
| 2046 | aventura | 14 |
| 2047 | ausencia | 14 |
| 2048 | atraer | 14 |
| 2049 | arrullar | 14 |
| 2050 | aprobar | 14 |
| 2051 | antojar | 14 |
| 2052 | alegre | 14 |
| 2053 | afirmar | 14 |
| 2054 | aconsejar | 14 |
| 2055 | absurdo | 14 |
| 2056 | vivísimo | 13 |
| 2057 | villa | 13 |
| 2058 | ventaja | 13 |
| 2059 | varón | 13 |
| 2060 | vacío | 13 |
| 2061 | trazar | 13 |
| 2062 | torcer | 13 |
| 2063 | tocante | 13 |
| 2064 | terminar | 13 |
| 2065 | temporada | 13 |
| 2066 | tarea | 13 |
| 2067 | taberna | 13 |
| 2068 | surgir | 13 |
| 2069 | sudar | 13 |
| 2070 | súbito | 13 |
| 2071 | someter | 13 |
| 2072 | solitario | 13 |
| 2073 | seña | 13 |
| 2074 | rotar | 13 |
| 2075 | rosa | 13 |
| 2076 | respiración | 13 |
| 2077 | respetable | 13 |
| 2078 | república | 13 |
| 2079 | renegar | 13 |
| 2080 | remoto | 13 |
| 2081 | regla | 13 |
| 2082 | registro | 13 |
| 2083 | regalar | 13 |
| 2084 | raza | 13 |
| 2085 | rascar | 13 |
| 2086 | puramente | 13 |
| 2087 | proposición | 13 |
| 2088 | promesa | 13 |
| 2089 | príncipe | 13 |
| 2090 | primitivo | 13 |
| 2091 | pollo | 13 |
| 2092 | placero | 13 |
| 2093 | pescuezo | 13 |
| 2094 | pedernero | 13 |
| 2095 | pausa | 13 |
| 2096 | patata | 13 |
| 2097 | paja | 13 |
| 2098 | otra | 13 |
| 2099 | oprimir | 13 |
| 2100 | ochoa | 13 |
| 2101 | obrar | 13 |
| 2102 | nieto | 13 |
| 2103 | nacional | 13 |
| 2104 | músculo | 13 |
| 2105 | murmurar | 13 |
| 2106 | multitud | 13 |
| 2107 | muestra | 13 |
| 2108 | motivar | 13 |
| 2109 | mostrador | 13 |
| 2110 | morder | 13 |
| 2111 | molestia | 13 |
| 2112 | moderno | 13 |
| 2113 | mimar | 13 |
| 2114 | mesías | 13 |
| 2115 | medir | 13 |
| 2116 | marrar | 13 |
| 2117 | manolita | 13 |
| 2118 | manejar | 13 |
| 2119 | manchar | 13 |
| 2120 | majestad | 13 |
| 2121 | madrugada | 13 |
| 2122 | lumbre | 13 |
| 2123 | lista | 13 |
| 2124 | liar | 13 |
| 2125 | legua | 13 |
| 2126 | justo | 13 |
| 2127 | juicioso | 13 |
| 2128 | juez | 13 |
| 2129 | intervenir | 13 |
| 2130 | infinito | 13 |
| 2131 | infancia | 13 |
| 2132 | indulgencia | 13 |
| 2133 | indecible | 13 |
| 2134 | impresionar | 13 |
| 2135 | imitar | 13 |
| 2136 | humildad | 13 |
| 2137 | hogar | 13 |
| 2138 | hembra | 13 |
| 2139 | grosería | 13 |
| 2140 | gratitud | 13 |
| 2141 | gorra | 13 |
| 2142 | garbanzo | 13 |
| 2143 | fruncir | 13 |
| 2144 | frialdad | 13 |
| 2145 | frescura | 13 |
| 2146 | franco | 13 |
| 2147 | francés | 13 |
| 2148 | formal | 13 |
| 2149 | florar | 13 |
| 2150 | filosófico | 13 |
| 2151 | facunda | 13 |
| 2152 | exaltar | 13 |
| 2153 | estorbar | 13 |
| 2154 | espantoso | 13 |
| 2155 | escuchar | 13 |
| 2156 | envidia | 13 |
| 2157 | enfermar | 13 |
| 2158 | enderezar | 13 |
| 2159 | emprender | 13 |
| 2160 | ejercer | 13 |
| 2161 | director | 13 |
| 2162 | desnudar | 13 |
| 2163 | deslizar | 13 |
| 2164 | desenvolver | 13 |
| 2165 | desdémona | 13 |
| 2166 | desconsuelo | 13 |
| 2167 | desconocido | 13 |
| 2168 | desconcertar | 13 |
| 2169 | descender | 13 |
| 2170 | delantal | 13 |
| 2171 | dañar | 13 |
| 2172 | creerás | 13 |
| 2173 | corrección | 13 |
| 2174 | coronel | 13 |
| 2175 | concepción | 13 |
| 2176 | compadecer | 13 |
| 2177 | comerciante | 13 |
| 2178 | colegio | 13 |
| 2179 | chasco | 13 |
| 2180 | cavilar | 13 |
| 2181 | católico | 13 |
| 2182 | benevolencia | 13 |
| 2183 | bendición | 13 |
| 2184 | bárbaro | 13 |
| 2185 | atroz | 13 |
| 2186 | arder | 13 |
| 2187 | añadió | 13 |
| 2188 | alarmar | 13 |
| 2189 | agitar | 13 |
| 2190 | admirablemente | 13 |
| 2191 | zapato | 12 |
| 2192 | vuestro | 12 |
| 2193 | viii | 12 |
| 2194 | verificar | 12 |
| 2195 | varonil | 12 |
| 2196 | únicamente | 12 |
| 2197 | trincar | 12 |
| 2198 | transigir | 12 |
| 2199 | tiesto | 12 |
| 2200 | tienes | 12 |
| 2201 | terciopelo | 12 |
| 2202 | talle | 12 |
| 2203 | talar | 12 |
| 2204 | sublimar | 12 |
| 2205 | sospecha | 12 |
| 2206 | sordo | 12 |
| 2207 | soltero | 12 |
| 2208 | solas | 12 |
| 2209 | sesenta | 12 |
| 2210 | sencillez | 12 |
| 2211 | sazón | 12 |
| 2212 | sacristán | 12 |
| 2213 | sacrificio | 12 |
| 2214 | sacrificar | 12 |
| 2215 | sabroso | 12 |
| 2216 | rudo | 12 |
| 2217 | revolucionario | 12 |
| 2218 | resolución | 12 |
| 2219 | reserva | 12 |
| 2220 | región | 12 |
| 2221 | recibimiento | 12 |
| 2222 | raya | 12 |
| 2223 | ratón | 12 |
| 2224 | púsose | 12 |
| 2225 | provenir | 12 |
| 2226 | protector | 12 |
| 2227 | propiedad | 12 |
| 2228 | progreso | 12 |
| 2229 | principalmente | 12 |
| 2230 | presteza | 12 |
| 2231 | presenciar | 12 |
| 2232 | postura | 12 |
| 2233 | posición | 12 |
| 2234 | pormenor | 12 |
| 2235 | policía | 12 |
| 2236 | pobrecito | 12 |
| 2237 | planta | 12 |
| 2238 | pisar | 12 |
| 2239 | pillar | 12 |
| 2240 | personalidad | 12 |
| 2241 | perfil | 12 |
| 2242 | penar | 12 |
| 2243 | pavos | 12 |
| 2244 | pavo | 12 |
| 2245 | patada | 12 |
| 2246 | pandereta | 12 |
| 2247 | palillo | 12 |
| 2248 | onda | 12 |
| 2249 | oficina | 12 |
| 2250 | odio | 12 |
| 2251 | obstante | 12 |
| 2252 | observó | 12 |
| 2253 | municipal | 12 |
| 2254 | moza | 12 |
| 2255 | miguel | 12 |
| 2256 | miel | 12 |
| 2257 | mezclar | 12 |
| 2258 | mercado | 12 |
| 2259 | máscara | 12 |
| 2260 | manila | 12 |
| 2261 | mando | 12 |
| 2262 | maldita | 12 |
| 2263 | lindo | 12 |
| 2264 | levantose | 12 |
| 2265 | letrero | 12 |
| 2266 | leopoldo | 12 |
| 2267 | legítimo | 12 |
| 2268 | leal | 12 |
| 2269 | labor | 12 |
| 2270 | joaquín | 12 |
| 2271 | jerónima | 12 |
| 2272 | ix | 12 |
| 2273 | interrumpir | 12 |
| 2274 | interesante | 12 |
| 2275 | inglaterra | 12 |
| 2276 | ingenioso | 12 |
| 2277 | indulgente | 12 |
| 2278 | incorporar | 12 |
| 2279 | ilustre | 12 |
| 2280 | hundir | 12 |
| 2281 | humilde | 12 |
| 2282 | humanar | 12 |
| 2283 | hortera | 12 |
| 2284 | horizonte | 12 |
| 2285 | herida | 12 |
| 2286 | hace | 12 |
| 2287 | gravedad | 12 |
| 2288 | gobernador | 12 |
| 2289 | gobernación | 12 |
| 2290 | gasto | 12 |
| 2291 | futuro | 12 |
| 2292 | forzoso | 12 |
| 2293 | firme | 12 |
| 2294 | finura | 12 |
| 2295 | fila | 12 |
| 2296 | fiesta | 12 |
| 2297 | farsa | 12 |
| 2298 | famoso | 12 |
| 2299 | etcétera | 12 |
| 2300 | estrenar | 12 |
| 2301 | estrella | 12 |
| 2302 | espléndido | 12 |
| 2303 | escupir | 12 |
| 2304 | escritorio | 12 |
| 2305 | escoba | 12 |
| 2306 | entró | 12 |
| 2307 | entraña | 12 |
| 2308 | empresa | 12 |
| 2309 | efectivo | 12 |
| 2310 | doctor | 12 |
| 2311 | dispuesto | 12 |
| 2312 | disparar | 12 |
| 2313 | digno | 12 |
| 2314 | diabla | 12 |
| 2315 | destruir | 12 |
| 2316 | destinar | 12 |
| 2317 | desprender | 12 |
| 2318 | despabilar | 12 |
| 2319 | desgraciado | 12 |
| 2320 | dejo | 12 |
| 2321 | cuñado | 12 |
| 2322 | cuba | 12 |
| 2323 | cuarta | 12 |
| 2324 | crítica | 12 |
| 2325 | criterio | 12 |
| 2326 | criado | 12 |
| 2327 | creeríase | 12 |
| 2328 | costura | 12 |
| 2329 | cortina | 12 |
| 2330 | colmo | 12 |
| 2331 | colcha | 12 |
| 2332 | cochero | 12 |
| 2333 | civilización | 12 |
| 2334 | ciudad | 12 |
| 2335 | cesta | 12 |
| 2336 | carlos | 12 |
| 2337 | capricho | 12 |
| 2338 | canto | 12 |
| 2339 | cállate | 12 |
| 2340 | brotar | 12 |
| 2341 | batir | 12 |
| 2342 | barrer | 12 |
| 2343 | atacar | 12 |
| 2344 | asir | 12 |
| 2345 | ansia | 12 |
| 2346 | anochecer | 12 |
| 2347 | amoroso | 12 |
| 2348 | altura | 12 |
| 2349 | alrededor | 12 |
| 2350 | almacén | 12 |
| 2351 | ajustar | 12 |
| 2352 | aguardiente | 12 |
| 2353 | abur | 12 |
| 2354 | yema | 11 |
| 2355 | vuelo | 11 |
| 2356 | vocablo | 11 |
| 2357 | vivienda | 11 |
| 2358 | viva | 11 |
| 2359 | viudo | 11 |
| 2360 | vergonzoso | 11 |
| 2361 | vástago | 11 |
| 2362 | tuno | 11 |
| 2363 | tronco | 11 |
| 2364 | traspasar | 11 |
| 2365 | transformar | 11 |
| 2366 | tercero | 11 |
| 2367 | teñir | 11 |
| 2368 | tenía | 11 |
| 2369 | tengo | 11 |
| 2370 | tambor | 11 |
| 2371 | suspirar | 11 |
| 2372 | sucesión | 11 |
| 2373 | sublime | 11 |
| 2374 | solemne | 11 |
| 2375 | soberbia | 11 |
| 2376 | silenciar | 11 |
| 2377 | sílaba | 11 |
| 2378 | signo | 11 |
| 2379 | sexo | 11 |
| 2380 | sereno | 11 |
| 2381 | sabiduría | 11 |
| 2382 | rossini | 11 |
| 2383 | rondar | 11 |
| 2384 | rogar | 11 |
| 2385 | revolución | 11 |
| 2386 | revés | 11 |
| 2387 | revelación | 11 |
| 2388 | retener | 11 |
| 2389 | restauración | 11 |
| 2390 | responsabilidad | 11 |
| 2391 | respectivo | 11 |
| 2392 | resistencia | 11 |
| 2393 | relucir | 11 |
| 2394 | refrescar | 11 |
| 2395 | recto | 11 |
| 2396 | reclamar | 11 |
| 2397 | realmente | 11 |
| 2398 | rastro | 11 |
| 2399 | rasgo | 11 |
| 2400 | quite | 11 |
| 2401 | quita | 11 |
| 2402 | pueril | 11 |
| 2403 | provecho | 11 |
| 2404 | prohibir | 11 |
| 2405 | presumir | 11 |
| 2406 | precio | 11 |
| 2407 | preceder | 11 |
| 2408 | practicar | 11 |
| 2409 | portero | 11 |
| 2410 | personaje | 11 |
| 2411 | perdición | 11 |
| 2412 | penitente | 11 |
| 2413 | pelota | 11 |
| 2414 | origen | 11 |
| 2415 | oportuno | 11 |
| 2416 | ojos | 11 |
| 2417 | ocupación | 11 |
| 2418 | observador | 11 |
| 2419 | obrador | 11 |
| 2420 | notable | 11 |
| 2421 | mono | 11 |
| 2422 | millón | 11 |
| 2423 | medicinar | 11 |
| 2424 | materno | 11 |
| 2425 | maternidad | 11 |
| 2426 | materia | 11 |
| 2427 | marfil | 11 |
| 2428 | luna | 11 |
| 2429 | lúgubre | 11 |
| 2430 | llover | 11 |
| 2431 | llanto | 11 |
| 2432 | liberación | 11 |
| 2433 | latín | 11 |
| 2434 | joya | 11 |
| 2435 | inundar | 11 |
| 2436 | insolente | 11 |
| 2437 | insensato | 11 |
| 2438 | inscripción | 11 |
| 2439 | insano | 11 |
| 2440 | inquilino | 11 |
| 2441 | inquieto | 11 |
| 2442 | infidelidad | 11 |
| 2443 | infernal | 11 |
| 2444 | independencia | 11 |
| 2445 | incredulidad | 11 |
| 2446 | impulsar | 11 |
| 2447 | impropio | 11 |
| 2448 | impacientar | 11 |
| 2449 | ignominia | 11 |
| 2450 | horriblemente | 11 |
| 2451 | hondo | 11 |
| 2452 | hebra | 11 |
| 2453 | guitarra | 11 |
| 2454 | generoso | 11 |
| 2455 | furia | 11 |
| 2456 | freír | 11 |
| 2457 | forzar | 11 |
| 2458 | filósofo | 11 |
| 2459 | filipinas | 11 |
| 2460 | figúrate | 11 |
| 2461 | familiar | 11 |
| 2462 | fama | 11 |
| 2463 | extravagante | 11 |
| 2464 | éxtasis | 11 |
| 2465 | exclamar | 11 |
| 2466 | exclamación | 11 |
| 2467 | excitación | 11 |
| 2468 | exaltación | 11 |
| 2469 | estrechar | 11 |
| 2470 | estimar | 11 |
| 2471 | espanto | 11 |
| 2472 | espada | 11 |
| 2473 | esencial | 11 |
| 2474 | entrever | 11 |
| 2475 | enmendar | 11 |
| 2476 | engaño | 11 |
| 2477 | encimar | 11 |
| 2478 | empleado | 11 |
| 2479 | ejército | 11 |
| 2480 | efusión | 11 |
| 2481 | dormitorio | 11 |
| 2482 | donaire | 11 |
| 2483 | dime | 11 |
| 2484 | detalle | 11 |
| 2485 | desventurado | 11 |
| 2486 | desvarío | 11 |
| 2487 | desprecio | 11 |
| 2488 | describir | 11 |
| 2489 | descanso | 11 |
| 2490 | depósito | 11 |
| 2491 | custodiar | 11 |
| 2492 | cursi | 11 |
| 2493 | cultivar | 11 |
| 2494 | cuartel | 11 |
| 2495 | crédito | 11 |
| 2496 | corbata | 11 |
| 2497 | contradecir | 11 |
| 2498 | contestación | 11 |
| 2499 | confuso | 11 |
| 2500 | combinación | 11 |
| 2501 | chiflar | 11 |
| 2502 | cera | 11 |
| 2503 | cenar | 11 |
| 2504 | celoso | 11 |
| 2505 | celestial | 11 |
| 2506 | castigo | 11 |
| 2507 | casado | 11 |
| 2508 | caminos | 11 |
| 2509 | calzar | 11 |
| 2510 | cabra | 11 |
| 2511 | burro | 11 |
| 2512 | bonifacio | 11 |
| 2513 | blando | 11 |
| 2514 | basta | 11 |
| 2515 | barcelona | 11 |
| 2516 | auxilio | 11 |
| 2517 | asesino | 11 |
| 2518 | arribar | 11 |
| 2519 | arrepentimiento | 11 |
| 2520 | aptitud | 11 |
| 2521 | apetecer | 11 |
| 2522 | amargar | 11 |
| 2523 | alterar | 11 |
| 2524 | alhajar | 11 |
| 2525 | algodón | 11 |
| 2526 | alentar | 11 |
| 2527 | afligir | 11 |
| 2528 | acostumbrado | 11 |
| 2529 | acomodar | 11 |
| 2530 | aceite | 11 |
| 2531 | aburrimiento | 11 |
| 2532 | abrazo | 11 |
| 2533 | zaragoza | 10 |
| 2534 | viveza | 10 |
| 2535 | visto | 10 |
| 2536 | visión | 10 |
| 2537 | verídico | 10 |
| 2538 | verbo | 10 |
| 2539 | verás | 10 |
| 2540 | ve | 10 |
| 2541 | variedad | 10 |
| 2542 | vaciar | 10 |
| 2543 | turrón | 10 |
| 2544 | triunfo | 10 |
| 2545 | triunfar | 10 |
| 2546 | través | 10 |
| 2547 | transeúnte | 10 |
| 2548 | tornar | 10 |
| 2549 | tolerancia | 10 |
| 2550 | tieso | 10 |
| 2551 | tesar | 10 |
| 2552 | ternura | 10 |
| 2553 | tentar | 10 |
| 2554 | tenedor | 10 |
| 2555 | tembloroso | 10 |
| 2556 | teatral | 10 |
| 2557 | sus | 10 |
| 2558 | sur | 10 |
| 2559 | sudor | 10 |
| 2560 | sopa | 10 |
| 2561 | severo | 10 |
| 2562 | seriar | 10 |
| 2563 | salvación | 10 |
| 2564 | sacramento | 10 |
| 2565 | rutina | 10 |
| 2566 | rótulo | 10 |
| 2567 | ronda | 10 |
| 2568 | roncar | 10 |
| 2569 | repugnar | 10 |
| 2570 | reposo | 10 |
| 2571 | reino | 10 |
| 2572 | regresar | 10 |
| 2573 | registrar | 10 |
| 2574 | recrear | 10 |
| 2575 | recortar | 10 |
| 2576 | realar | 10 |
| 2577 | quizá | 10 |
| 2578 | purificar | 10 |
| 2579 | puñal | 10 |
| 2580 | pulso | 10 |
| 2581 | puchero | 10 |
| 2582 | prodigio | 10 |
| 2583 | probable | 10 |
| 2584 | primogénito | 10 |
| 2585 | premio | 10 |
| 2586 | precipitar | 10 |
| 2587 | práctica | 10 |
| 2588 | posar | 10 |
| 2589 | placer | 10 |
| 2590 | pillín | 10 |
| 2591 | pesadilla | 10 |
| 2592 | perverso | 10 |
| 2593 | permiso | 10 |
| 2594 | perfección | 10 |
| 2595 | paternal | 10 |
| 2596 | patear | 10 |
| 2597 | pastor | 10 |
| 2598 | pascual | 10 |
| 2599 | participar | 10 |
| 2600 | parroquia | 10 |
| 2601 | párrafo | 10 |
| 2602 | parado | 10 |
| 2603 | palacio | 10 |
| 2604 | pago | 10 |
| 2605 | padilla | 10 |
| 2606 | pacífico | 10 |
| 2607 | ópera | 10 |
| 2608 | ola | 10 |
| 2609 | obrero | 10 |
| 2610 | nobleza | 10 |
| 2611 | navidad | 10 |
| 2612 | naranja | 10 |
| 2613 | muñeca | 10 |
| 2614 | mundano | 10 |
| 2615 | morar | 10 |
| 2616 | misión | 10 |
| 2617 | mesilla | 10 |
| 2618 | menear | 10 |
| 2619 | mayo | 10 |
| 2620 | martirio | 10 |
| 2621 | mármol | 10 |
| 2622 | maravillar | 10 |
| 2623 | mantilla | 10 |
| 2624 | manicomio | 10 |
| 2625 | mamar | 10 |
| 2626 | madrileño | 10 |
| 2627 | luminoso | 10 |
| 2628 | luchar | 10 |
| 2629 | lobo | 10 |
| 2630 | juventud | 10 |
| 2631 | jarabe | 10 |
| 2632 | isidro | 10 |
| 2633 | interrogar | 10 |
| 2634 | inocencia | 10 |
| 2635 | ingrato | 10 |
| 2636 | ingenio | 10 |
| 2637 | influenciar | 10 |
| 2638 | imperio | 10 |
| 2639 | ilustrar | 10 |
| 2640 | ignorar | 10 |
| 2641 | hule | 10 |
| 2642 | huésped | 10 |
| 2643 | heredero | 10 |
| 2644 | has | 10 |
| 2645 | habrá | 10 |
| 2646 | golosina | 10 |
| 2647 | fuertemente | 10 |
| 2648 | frenesí | 10 |
| 2649 | fregar | 10 |
| 2650 | fraternal | 10 |
| 2651 | flaco | 10 |
| 2652 | exterior | 10 |
| 2653 | expresivo | 10 |
| 2654 | experiencia | 10 |
| 2655 | eulalia | 10 |
| 2656 | estatura | 10 |
| 2657 | espectro | 10 |
| 2658 | escrúpulo | 10 |
| 2659 | envenenar | 10 |
| 2660 | enojar | 10 |
| 2661 | enérgico | 10 |
| 2662 | encarnar | 10 |
| 2663 | encantar | 10 |
| 2664 | empleo | 10 |
| 2665 | elogiar | 10 |
| 2666 | elegancia | 10 |
| 2667 | efectivamente | 10 |
| 2668 | edificar | 10 |
| 2669 | doloroso | 10 |
| 2670 | docena | 10 |
| 2671 | divertido | 10 |
| 2672 | disimulo | 10 |
| 2673 | discusión | 10 |
| 2674 | disco | 10 |
| 2675 | dictar | 10 |
| 2676 | diario | 10 |
| 2677 | desmentir | 10 |
| 2678 | desdichado | 10 |
| 2679 | deogracias | 10 |
| 2680 | demencia | 10 |
| 2681 | custodia | 10 |
| 2682 | cuchichear | 10 |
| 2683 | cree | 10 |
| 2684 | corro | 10 |
| 2685 | corrida | 10 |
| 2686 | coro | 10 |
| 2687 | construir | 10 |
| 2688 | conmover | 10 |
| 2689 | conjunto | 10 |
| 2690 | confirmar | 10 |
| 2691 | comunicación | 10 |
| 2692 | colar | 10 |
| 2693 | cola | 10 |
| 2694 | clara | 10 |
| 2695 | cinta | 10 |
| 2696 | chaleco | 10 |
| 2697 | cerrojo | 10 |
| 2698 | ceremonia | 10 |
| 2699 | cena | 10 |
| 2700 | celda | 10 |
| 2701 | castillo | 10 |
| 2702 | carlista | 10 |
| 2703 | carecer | 10 |
| 2704 | calzado | 10 |
| 2705 | burla | 10 |
| 2706 | bordar | 10 |
| 2707 | bondadoso | 10 |
| 2708 | blas | 10 |
| 2709 | bebida | 10 |
| 2710 | baba | 10 |
| 2711 | atrevimiento | 10 |
| 2712 | atónito | 10 |
| 2713 | ascua | 10 |
| 2714 | asaltar | 10 |
| 2715 | arranque | 10 |
| 2716 | armonía | 10 |
| 2717 | apuro | 10 |
| 2718 | antonia | 10 |
| 2719 | antipatía | 10 |
| 2720 | animación | 10 |
| 2721 | andrés | 10 |
| 2722 | ancho | 10 |
| 2723 | amanecer | 10 |
| 2724 | amable | 10 |
| 2725 | alumbrar | 10 |
| 2726 | aliento | 10 |
| 2727 | ala | 10 |
| 2728 | agudo | 10 |
| 2729 | aforar | 10 |
| 2730 | afición | 10 |
| 2731 | administrador | 10 |
| 2732 | administración | 10 |
| 2733 | acuerdo | 10 |
| 2734 | acecho | 10 |
| 2735 | zancudo | 9 |
| 2736 | yeso | 9 |
| 2737 | voto | 9 |
| 2738 | vivamente | 9 |
| 2739 | virtuoso | 9 |
| 2740 | violencia | 9 |
| 2741 | vieja | 9 |
| 2742 | viático | 9 |
| 2743 | verdugo | 9 |
| 2744 | veneno | 9 |
| 2745 | vallejo | 9 |
| 2746 | u | 9 |
| 2747 | tubo | 9 |
| 2748 | tronar | 9 |
| 2749 | transmitir | 9 |
| 2750 | trágico | 9 |
| 2751 | toser | 9 |
| 2752 | torre | 9 |
| 2753 | torpe | 9 |
| 2754 | tom | 9 |
| 2755 | templar | 9 |
| 2756 | tabla | 9 |
| 2757 | sutil | 9 |
| 2758 | suplicio | 9 |
| 2759 | sumergir | 9 |
| 2760 | sonido | 9 |
| 2761 | sólido | 9 |
| 2762 | sofocado | 9 |
| 2763 | sobrevenir | 9 |
| 2764 | so | 9 |
| 2765 | singular | 9 |
| 2766 | sincero | 9 |
| 2767 | setiembre | 9 |
| 2768 | rueda | 9 |
| 2769 | roto | 9 |
| 2770 | riquísimo | 9 |
| 2771 | resplandor | 9 |
| 2772 | repugnancia | 9 |
| 2773 | reprender | 9 |
| 2774 | renunciar | 9 |
| 2775 | renta | 9 |
| 2776 | renovar | 9 |
| 2777 | renglón | 9 |
| 2778 | remordimiento | 9 |
| 2779 | reflexionar | 9 |
| 2780 | redentor | 9 |
| 2781 | reconciliación | 9 |
| 2782 | recién | 9 |
| 2783 | re | 9 |
| 2784 | ráfaga | 9 |
| 2785 | quiero | 9 |
| 2786 | quedo | 9 |
| 2787 | puñalada | 9 |
| 2788 | pulmón | 9 |
| 2789 | prosiguió | 9 |
| 2790 | propiamente | 9 |
| 2791 | prolongar | 9 |
| 2792 | prim | 9 |
| 2793 | prever | 9 |
| 2794 | presuroso | 9 |
| 2795 | preso | 9 |
| 2796 | presentimiento | 9 |
| 2797 | portería | 9 |
| 2798 | porrazo | 9 |
| 2799 | porquería | 9 |
| 2800 | ponce | 9 |
| 2801 | pólvora | 9 |
| 2802 | poderoso | 9 |
| 2803 | plantón | 9 |
| 2804 | planchar | 9 |
| 2805 | pintor | 9 |
| 2806 | picardía | 9 |
| 2807 | piar | 9 |
| 2808 | pendiente | 9 |
| 2809 | peineta | 9 |
| 2810 | pastelero | 9 |
| 2811 | pasaje | 9 |
| 2812 | paraíso | 9 |
| 2813 | papeleta | 9 |
| 2814 | palmar | 9 |
| 2815 | pájara | 9 |
| 2816 | pagaré | 9 |
| 2817 | olvido | 9 |
| 2818 | oficiar | 9 |
| 2819 | oficial | 9 |
| 2820 | obispo | 9 |
| 2821 | nación | 9 |
| 2822 | molina | 9 |
| 2823 | moderar | 9 |
| 2824 | mimo | 9 |
| 2825 | metálico | 9 |
| 2826 | merluza | 9 |
| 2827 | merino | 9 |
| 2828 | menudencia | 9 |
| 2829 | melancolía | 9 |
| 2830 | medicamento | 9 |
| 2831 | materialismo | 9 |
| 2832 | material | 9 |
| 2833 | mancha | 9 |
| 2834 | magdalena | 9 |
| 2835 | listo | 9 |
| 2836 | lienzo | 9 |
| 2837 | libra | 9 |
| 2838 | lana | 9 |
| 2839 | lámpara | 9 |
| 2840 | jota | 9 |
| 2841 | jaula | 9 |
| 2842 | jacinto | 9 |
| 2843 | jabón | 9 |
| 2844 | irresistible | 9 |
| 2845 | intensísimo | 9 |
| 2846 | insoportable | 9 |
| 2847 | inmóvil | 9 |
| 2848 | infamar | 9 |
| 2849 | inefable | 9 |
| 2850 | industria | 9 |
| 2851 | indudablemente | 9 |
| 2852 | indignación | 9 |
| 2853 | indiferencia | 9 |
| 2854 | incluso | 9 |
| 2855 | inclusa | 9 |
| 2856 | implacable | 9 |
| 2857 | impaciencia | 9 |
| 2858 | ídolo | 9 |
| 2859 | idolatrar | 9 |
| 2860 | horrorizar | 9 |
| 2861 | horacio | 9 |
| 2862 | hola | 9 |
| 2863 | hipócrita | 9 |
| 2864 | héroe | 9 |
| 2865 | helar | 9 |
| 2866 | hallábase | 9 |
| 2867 | guiñar | 9 |
| 2868 | gris | 9 |
| 2869 | grato | 9 |
| 2870 | gozo | 9 |
| 2871 | goloso | 9 |
| 2872 | ganancia | 9 |
| 2873 | gallina | 9 |
| 2874 | gala | 9 |
| 2875 | furibundo | 9 |
| 2876 | funcionar | 9 |
| 2877 | fuensanta | 9 |
| 2878 | freno | 9 |
| 2879 | frecuentar | 9 |
| 2880 | frasco | 9 |
| 2881 | fíjate | 9 |
| 2882 | fiereza | 9 |
| 2883 | febrero | 9 |
| 2884 | faena | 9 |
| 2885 | externo | 9 |
| 2886 | exquisito | 9 |
| 2887 | exhalar | 9 |
| 2888 | exclusivamente | 9 |
| 2889 | exaltado | 9 |
| 2890 | ex | 9 |
| 2891 | evangelio | 9 |
| 2892 | estrépito | 9 |
| 2893 | estampar | 9 |
| 2894 | estallido | 9 |
| 2895 | escurrir | 9 |
| 2896 | escondite | 9 |
| 2897 | escape | 9 |
| 2898 | escaparate | 9 |
| 2899 | equivocación | 9 |
| 2900 | engracia | 9 |
| 2901 | encuentro | 9 |
| 2902 | embargar | 9 |
| 2903 | elevar | 9 |
| 2904 | elegir | 9 |
| 2905 | eléctrico | 9 |
| 2906 | eclesiástico | 9 |
| 2907 | dramático | 9 |
| 2908 | drama | 9 |
| 2909 | dosis | 9 |
| 2910 | disputa | 9 |
| 2911 | dispensar | 9 |
| 2912 | diciembre | 9 |
| 2913 | devorar | 9 |
| 2914 | devanar | 9 |
| 2915 | desesperación | 9 |
| 2916 | descuido | 9 |
| 2917 | desairar | 9 |
| 2918 | desahogar | 9 |
| 2919 | delito | 9 |
| 2920 | delincuente | 9 |
| 2921 | delicioso | 9 |
| 2922 | delicadeza | 9 |
| 2923 | declaración | 9 |
| 2924 | decencia | 9 |
| 2925 | curva | 9 |
| 2926 | curioso | 9 |
| 2927 | culto | 9 |
| 2928 | culebra | 9 |
| 2929 | cuchara | 9 |
| 2930 | continuo | 9 |
| 2931 | consumar | 9 |
| 2932 | consigo | 9 |
| 2933 | conocido | 9 |
| 2934 | conflicto | 9 |
| 2935 | confidencia | 9 |
| 2936 | conceder | 9 |
| 2937 | comisión | 9 |
| 2938 | colocación | 9 |
| 2939 | clarear | 9 |
| 2940 | citar | 9 |
| 2941 | ciertamente | 9 |
| 2942 | chorrear | 9 |
| 2943 | chocar | 9 |
| 2944 | charla | 9 |
| 2945 | centinela | 9 |
| 2946 | cazar | 9 |
| 2947 | casco | 9 |
| 2948 | carmen | 9 |
| 2949 | característico | 9 |
| 2950 | cansancio | 9 |
| 2951 | cana | 9 |
| 2952 | cállese | 9 |
| 2953 | calamidad | 9 |
| 2954 | cádiz | 9 |
| 2955 | butaca | 9 |
| 2956 | bulla | 9 |
| 2957 | brusco | 9 |
| 2958 | bronce | 9 |
| 2959 | borracho | 9 |
| 2960 | bolsa | 9 |
| 2961 | bocado | 9 |
| 2962 | bigote | 9 |
| 2963 | beneficencia | 9 |
| 2964 | bata | 9 |
| 2965 | barricada | 9 |
| 2966 | banca | 9 |
| 2967 | aventurar | 9 |
| 2968 | auxiliar | 9 |
| 2969 | aturdir | 9 |
| 2970 | atmósfera | 9 |
| 2971 | atizar | 9 |
| 2972 | atentar | 9 |
| 2973 | arena | 9 |
| 2974 | apretón | 9 |
| 2975 | apreciación | 9 |
| 2976 | apostar | 9 |
| 2977 | aposento | 9 |
| 2978 | apoderar | 9 |
| 2979 | aparato | 9 |
| 2980 | anticipar | 9 |
| 2981 | anhelo | 9 |
| 2982 | angustia | 9 |
| 2983 | ángulo | 9 |
| 2984 | angelito | 9 |
| 2985 | ambiente | 9 |
| 2986 | alquilar | 9 |
| 2987 | almirez | 9 |
| 2988 | algazara | 9 |
| 2989 | alfonso | 9 |
| 2990 | alcalde | 9 |
| 2991 | ahorro | 9 |
| 2992 | agasajar | 9 |
| 2993 | aflojar | 9 |
| 2994 | afable | 9 |
| 2995 | aclarar | 9 |
| 2996 | abnegación | 9 |
| 2997 | abismo | 9 |
| 2998 | abanico | 9 |
| 2999 | zapatilla | 8 |
| 3000 | zapatería | 8 |
| 3001 | zalamería | 8 |
| 3002 | x | 8 |
| 3003 | vistazo | 8 |
| 3004 | victoria | 8 |
| 3005 | vibración | 8 |
| 3006 | va | 8 |
| 3007 | unión | 8 |
| 3008 | ultrajar | 8 |
| 3009 | trujillos | 8 |
| 3010 | tristísimo | 8 |
| 3011 | tribunal | 8 |
| 3012 | trastada | 8 |
| 3013 | transformación | 8 |
| 3014 | traidor | 8 |
| 3015 | tormento | 8 |
| 3016 | toque | 8 |
| 3017 | tolerar | 8 |
| 3018 | tirón | 8 |
| 3019 | tino | 8 |
| 3020 | testigo | 8 |
| 3021 | tercer | 8 |
| 3022 | tallar | 8 |
| 3023 | sumisión | 8 |
| 3024 | subida | 8 |
| 3025 | sotana | 8 |
| 3026 | soplar | 8 |
| 3027 | sombrío | 8 |
| 3028 | soldar | 8 |
| 3029 | sobreponer | 8 |
| 3030 | sobra | 8 |
| 3031 | sinvergüenza | 8 |
| 3032 | simpleza | 8 |
| 3033 | señorío | 8 |
| 3034 | semejanza | 8 |
| 3035 | seducir | 8 |
| 3036 | saludo | 8 |
| 3037 | salmerón | 8 |
| 3038 | romántico | 8 |
| 3039 | rodillas | 8 |
| 3040 | robusto | 8 |
| 3041 | rezo | 8 |
| 3042 | revestir | 8 |
| 3043 | retorcer | 8 |
| 3044 | resplandecer | 8 |
| 3045 | réspice | 8 |
| 3046 | resoplido | 8 |
| 3047 | resignar | 8 |
| 3048 | repugnante | 8 |
| 3049 | reparación | 8 |
| 3050 | relimpio | 8 |
| 3051 | relato | 8 |
| 3052 | reina | 8 |
| 3053 | regocijar | 8 |
| 3054 | regente | 8 |
| 3055 | refunfuñar | 8 |
| 3056 | redención | 8 |
| 3057 | red | 8 |
| 3058 | rectitud | 8 |
| 3059 | recomendación | 8 |
| 3060 | recelo | 8 |
| 3061 | recaer | 8 |
| 3062 | rara | 8 |
| 3063 | rapidez | 8 |
| 3064 | rabo | 8 |
| 3065 | pulmonía | 8 |
| 3066 | prurito | 8 |
| 3067 | progresista | 8 |
| 3068 | profesar | 8 |
| 3069 | procedimiento | 8 |
| 3070 | probablemente | 8 |
| 3071 | prevenir | 8 |
| 3072 | presupuesto | 8 |
| 3073 | portamonedas | 8 |
| 3074 | poesía | 8 |
| 3075 | plenitud | 8 |
| 3076 | pleito | 8 |
| 3077 | platillo | 8 |
| 3078 | pintoresco | 8 |
| 3079 | pies | 8 |
| 3080 | picaresco | 8 |
| 3081 | picante | 8 |
| 3082 | piano | 8 |
| 3083 | pi | 8 |
| 3084 | perrería | 8 |
| 3085 | patético | 8 |
| 3086 | paseíto | 8 |
| 3087 | paréceme | 8 |
| 3088 | pantalla | 8 |
| 3089 | paisaje | 8 |
| 3090 | padrino | 8 |
| 3091 | oyose | 8 |
| 3092 | oriente | 8 |
| 3093 | oración | 8 |
| 3094 | ojalá | 8 |
| 3095 | odiar | 8 |
| 3096 | nido | 8 |
| 3097 | mortal | 8 |
| 3098 | moño | 8 |
| 3099 | molino | 8 |
| 3100 | moler | 8 |
| 3101 | místico | 8 |
| 3102 | misántropo | 8 |
| 3103 | metido | 8 |
| 3104 | mentar | 8 |
| 3105 | mediano | 8 |
| 3106 | mayormente | 8 |
| 3107 | matrimonial | 8 |
| 3108 | maternal | 8 |
| 3109 | mascar | 8 |
| 3110 | marco | 8 |
| 3111 | maravilloso | 8 |
| 3112 | manifestó | 8 |
| 3113 | malicia | 8 |
| 3114 | maldición | 8 |
| 3115 | lucha | 8 |
| 3116 | literario | 8 |
| 3117 | lazo | 8 |
| 3118 | lastimoso | 8 |
| 3119 | lámina | 8 |
| 3120 | lamentar | 8 |
| 3121 | judía | 8 |
| 3122 | joaquinito | 8 |
| 3123 | jardín | 8 |
| 3124 | izquierda | 8 |
| 3125 | irritar | 8 |
| 3126 | invisible | 8 |
| 3127 | invadir | 8 |
| 3128 | intranquilo | 8 |
| 3129 | interno | 8 |
| 3130 | instrucción | 8 |
| 3131 | institución | 8 |
| 3132 | instalar | 8 |
| 3133 | iniciativa | 8 |
| 3134 | informar | 8 |
| 3135 | infamia | 8 |
| 3136 | indudable | 8 |
| 3137 | indispensable | 8 |
| 3138 | imperial | 8 |
| 3139 | igualar | 8 |
| 3140 | humillar | 8 |
| 3141 | húmedo | 8 |
| 3142 | hospital | 8 |
| 3143 | honra | 8 |
| 3144 | hiel | 8 |
| 3145 | guiar | 8 |
| 3146 | gritos | 8 |
| 3147 | grandioso | 8 |
| 3148 | glacial | 8 |
| 3149 | gemir | 8 |
| 3150 | gemido | 8 |
| 3151 | fugaz | 8 |
| 3152 | fuente | 8 |
| 3153 | forrar | 8 |
| 3154 | flaqueza | 8 |
| 3155 | fiscal | 8 |
| 3156 | fiero | 8 |
| 3157 | fidelidad | 8 |
| 3158 | felisa | 8 |
| 3159 | farol | 8 |
| 3160 | faldón | 8 |
| 3161 | extremar | 8 |
| 3162 | exigencia | 8 |
| 3163 | exactamente | 8 |
| 3164 | estrecho | 8 |
| 3165 | estimular | 8 |
| 3166 | estimación | 8 |
| 3167 | estatua | 8 |
| 3168 | estampa | 8 |
| 3169 | escocer | 8 |
| 3170 | esclavo | 8 |
| 3171 | esclavitud | 8 |
| 3172 | escaso | 8 |
| 3173 | eres | 8 |
| 3174 | epiléptico | 8 |
| 3175 | entrecejo | 8 |
| 3176 | entereza | 8 |
| 3177 | enseñanza | 8 |
| 3178 | enojo | 8 |
| 3179 | encarar | 8 |
| 3180 | encajar | 8 |
| 3181 | embustero | 8 |
| 3182 | elemental | 8 |
| 3183 | egoísmo | 8 |
| 3184 | dulzura | 8 |
| 3185 | doscientos | 8 |
| 3186 | dorar | 8 |
| 3187 | doncella | 8 |
| 3188 | dolorido | 8 |
| 3189 | divinidad | 8 |
| 3190 | distraído | 8 |
| 3191 | disminuir | 8 |
| 3192 | disfrutar | 8 |
| 3193 | discreción | 8 |
| 3194 | dígame | 8 |
| 3195 | diálogo | 8 |
| 3196 | despejar | 8 |
| 3197 | despedida | 8 |
| 3198 | desechar | 8 |
| 3199 | descollar | 8 |
| 3200 | descolgar | 8 |
| 3201 | desbordar | 8 |
| 3202 | desatino | 8 |
| 3203 | dentadura | 8 |
| 3204 | delirante | 8 |
| 3205 | decorar | 8 |
| 3206 | declaró | 8 |
| 3207 | dátil | 8 |
| 3208 | datar | 8 |
| 3209 | curso | 8 |
| 3210 | culpable | 8 |
| 3211 | cuidadosamente | 8 |
| 3212 | cuero | 8 |
| 3213 | cuadrar | 8 |
| 3214 | crianza | 8 |
| 3215 | cráneo | 8 |
| 3216 | corrillo | 8 |
| 3217 | correspondiente | 8 |
| 3218 | cordura | 8 |
| 3219 | convulsivo | 8 |
| 3220 | contrariedad | 8 |
| 3221 | contrabando | 8 |
| 3222 | contacto | 8 |
| 3223 | construcción | 8 |
| 3224 | constante | 8 |
| 3225 | considerablemente | 8 |
| 3226 | conquistar | 8 |
| 3227 | confesión | 8 |
| 3228 | concurrir | 8 |
| 3229 | concienciar | 8 |
| 3230 | comunidad | 8 |
| 3231 | competencia | 8 |
| 3232 | compasivo | 8 |
| 3233 | combatir | 8 |
| 3234 | colorado | 8 |
| 3235 | cobre | 8 |
| 3236 | cobrador | 8 |
| 3237 | civil | 8 |
| 3238 | cirila | 8 |
| 3239 | chuchería | 8 |
| 3240 | chispa | 8 |
| 3241 | chillón | 8 |
| 3242 | chica | 8 |
| 3243 | cesto | 8 |
| 3244 | cesante | 8 |
| 3245 | cercar | 8 |
| 3246 | ceño | 8 |
| 3247 | cautivar | 8 |
| 3248 | casorio | 8 |
| 3249 | carita | 8 |
| 3250 | caramelo | 8 |
| 3251 | cañón | 8 |
| 3252 | cantón | 8 |
| 3253 | cansado | 8 |
| 3254 | calumniar | 8 |
| 3255 | cajita | 8 |
| 3256 | busto | 8 |
| 3257 | brío | 8 |
| 3258 | brillante | 8 |
| 3259 | bregar | 8 |
| 3260 | bravo | 8 |
| 3261 | botín | 8 |
| 3262 | boticario | 8 |
| 3263 | bomba | 8 |
| 3264 | base | 8 |
| 3265 | barro | 8 |
| 3266 | azotar | 8 |
| 3267 | avivar | 8 |
| 3268 | avergonzar | 8 |
| 3269 | autoritario | 8 |
| 3270 | atrevido | 8 |
| 3271 | atenuar | 8 |
| 3272 | atentamente | 8 |
| 3273 | aspaviento | 8 |
| 3274 | asesinar | 8 |
| 3275 | aseo | 8 |
| 3276 | arrogante | 8 |
| 3277 | arrimar | 8 |
| 3278 | arco | 8 |
| 3279 | aragón | 8 |
| 3280 | apretado | 8 |
| 3281 | apostamos | 8 |
| 3282 | aplaudir | 8 |
| 3283 | aparición | 8 |
| 3284 | anonadar | 8 |
| 3285 | amparar | 8 |
| 3286 | altercar | 8 |
| 3287 | alimento | 8 |
| 3288 | alcance | 8 |
| 3289 | albañil | 8 |
| 3290 | airoso | 8 |
| 3291 | agraciar | 8 |
| 3292 | agitación | 8 |
| 3293 | afligido | 8 |
| 3294 | afirmativo | 8 |
| 3295 | adornar | 8 |
| 3296 | adoptar | 8 |
| 3297 | acontecer | 8 |
| 3298 | acero | 8 |
| 3299 | acceso | 8 |
| 3300 | abuelito | 8 |
| 3301 | abatir | 8 |
| 3302 | yerba | 7 |
| 3303 | votar | 7 |
| 3304 | volvió | 7 |
| 3305 | volcar | 7 |
| 3306 | vigilancia | 7 |
| 3307 | viernes | 7 |
| 3308 | ventanilla | 7 |
| 3309 | vagamente | 7 |
| 3310 | vagabundo | 7 |
| 3311 | usurero | 7 |
| 3312 | tutear | 7 |
| 3313 | tripa | 7 |
| 3314 | tratamiento | 7 |
| 3315 | traspaso | 7 |
| 3316 | tranvía | 7 |
| 3317 | trago | 7 |
| 3318 | trabar | 7 |
| 3319 | tos | 7 |
| 3320 | torpeza | 7 |
| 3321 | torno | 7 |
| 3322 | tirria | 7 |
| 3323 | tiritar | 7 |
| 3324 | tinta | 7 |
| 3325 | texto | 7 |
| 3326 | teta | 7 |
| 3327 | testamento | 7 |
| 3328 | ternera | 7 |
| 3329 | teniente | 7 |
| 3330 | tejado | 7 |
| 3331 | supuesto | 7 |
| 3332 | suavidad | 7 |
| 3333 | soso | 7 |
| 3334 | soñador | 7 |
| 3335 | solicitar | 7 |
| 3336 | solemnidad | 7 |
| 3337 | socio | 7 |
| 3338 | sobresaltar | 7 |
| 3339 | simplemente | 7 |
| 3340 | símbolo | 7 |
| 3341 | sillar | 7 |
| 3342 | siéntese | 7 |
| 3343 | servidor | 7 |
| 3344 | sequedad | 7 |
| 3345 | sentose | 7 |
| 3346 | semejar | 7 |
| 3347 | sed | 7 |
| 3348 | secretear | 7 |
| 3349 | samaniegas | 7 |
| 3350 | salado | 7 |
| 3351 | sagunto | 7 |
| 3352 | sacristía | 7 |
| 3353 | sábado | 7 |
| 3354 | ruina | 7 |
| 3355 | rosita | 7 |
| 3356 | roer | 7 |
| 3357 | rival | 7 |
| 3358 | ricamente | 7 |
| 3359 | retumbar | 7 |
| 3360 | retratar | 7 |
| 3361 | resma | 7 |
| 3362 | reputación | 7 |
| 3363 | representación | 7 |
| 3364 | reponer | 7 |
| 3365 | repasar | 7 |
| 3366 | rehacer | 7 |
| 3367 | regentar | 7 |
| 3368 | reforma | 7 |
| 3369 | rédito | 7 |
| 3370 | recurso | 7 |
| 3371 | reconocimiento | 7 |
| 3372 | reconciliar | 7 |
| 3373 | recluso | 7 |
| 3374 | recíprocamente | 7 |
| 3375 | rechazar | 7 |
| 3376 | rebosar | 7 |
| 3377 | rasar | 7 |
| 3378 | queja | 7 |
| 3379 | purísima | 7 |
| 3380 | pulga | 7 |
| 3381 | proximidad | 7 |
| 3382 | proporcionar | 7 |
| 3383 | programa | 7 |
| 3384 | privar | 7 |
| 3385 | prensa | 7 |
| 3386 | predicar | 7 |
| 3387 | preciosidad | 7 |
| 3388 | postas | 7 |
| 3389 | poseedor | 7 |
| 3390 | portera | 7 |
| 3391 | ponderar | 7 |
| 3392 | polla | 7 |
| 3393 | poético | 7 |
| 3394 | pliegue | 7 |
| 3395 | plantear | 7 |
| 3396 | piadoso | 7 |
| 3397 | peste | 7 |
| 3398 | persecución | 7 |
| 3399 | perra | 7 |
| 3400 | perla | 7 |
| 3401 | peripecia | 7 |
| 3402 | percibir | 7 |
| 3403 | percha | 7 |
| 3404 | pensión | 7 |
| 3405 | penitenciar | 7 |
| 3406 | peligroso | 7 |
| 3407 | pechar | 7 |
| 3408 | paterno | 7 |
| 3409 | palique | 7 |
| 3410 | palco | 7 |
| 3411 | opinar | 7 |
| 3412 | odioso | 7 |
| 3413 | ocioso | 7 |
| 3414 | ocasionar | 7 |
| 3415 | obediencia | 7 |
| 3416 | nieves | 7 |
| 3417 | negativo | 7 |
| 3418 | narrador | 7 |
| 3419 | napoleón | 7 |
| 3420 | muro | 7 |
| 3421 | muñeco | 7 |
| 3422 | muleta | 7 |
| 3423 | mugido | 7 |
| 3424 | muelle | 7 |
| 3425 | mudanza | 7 |
| 3426 | muchas | 7 |
| 3427 | mota | 7 |
| 3428 | molde | 7 |
| 3429 | mojar | 7 |
| 3430 | modesto | 7 |
| 3431 | mimoso | 7 |
| 3432 | milicia | 7 |
| 3433 | mercantil | 7 |
| 3434 | mequetrefe | 7 |
| 3435 | mediodía | 7 |
| 3436 | mediar | 7 |
| 3437 | mechón | 7 |
| 3438 | mártir | 7 |
| 3439 | manotada | 7 |
| 3440 | manifestación | 7 |
| 3441 | maniático | 7 |
| 3442 | mangonear | 7 |
| 3443 | malvina | 7 |
| 3444 | maltratar | 7 |
| 3445 | malicioso | 7 |
| 3446 | majo | 7 |
| 3447 | majadero | 7 |
| 3448 | magín | 7 |
| 3449 | maduro | 7 |
| 3450 | lustre | 7 |
| 3451 | lozoya | 7 |
| 3452 | lógico | 7 |
| 3453 | lívido | 7 |
| 3454 | levitar | 7 |
| 3455 | letargo | 7 |
| 3456 | lealtad | 7 |
| 3457 | lastimar | 7 |
| 3458 | ladrar | 7 |
| 3459 | labrar | 7 |
| 3460 | juguete | 7 |
| 3461 | júbilo | 7 |
| 3462 | jarro | 7 |
| 3463 | invocar | 7 |
| 3464 | invierno | 7 |
| 3465 | intimidad | 7 |
| 3466 | inmensidad | 7 |
| 3467 | inmediatamente | 7 |
| 3468 | índole | 7 |
| 3469 | indeciso | 7 |
| 3470 | inclinación | 7 |
| 3471 | ignorancia | 7 |
| 3472 | ida | 7 |
| 3473 | huérfano | 7 |
| 3474 | honesto | 7 |
| 3475 | hocico | 7 |
| 3476 | hereje | 7 |
| 3477 | habla | 7 |
| 3478 | habilidad | 7 |
| 3479 | guisar | 7 |
| 3480 | guasa | 7 |
| 3481 | guapetón | 7 |
| 3482 | gran | 7 |
| 3483 | gonzález | 7 |
| 3484 | girar | 7 |
| 3485 | gatito | 7 |
| 3486 | ganga | 7 |
| 3487 | gafa | 7 |
| 3488 | fusil | 7 |
| 3489 | fúnebre | 7 |
| 3490 | fumar | 7 |
| 3491 | fresa | 7 |
| 3492 | ferrocarril | 7 |
| 3493 | felicitar | 7 |
| 3494 | fatal | 7 |
| 3495 | fantástico | 7 |
| 3496 | explotar | 7 |
| 3497 | excursión | 7 |
| 3498 | exagerar | 7 |
| 3499 | estupendo | 7 |
| 3500 | estaba | 7 |
| 3501 | espérate | 7 |
| 3502 | especialidad | 7 |
| 3503 | esa | 7 |
| 3504 | enzarzar | 7 |
| 3505 | ensimismar | 7 |
| 3506 | enfriar | 7 |
| 3507 | encanto | 7 |
| 3508 | encaminar | 7 |
| 3509 | empuje | 7 |
| 3510 | elección | 7 |
| 3511 | ejercitar | 7 |
| 3512 | economía | 7 |
| 3513 | dureza | 7 |
| 3514 | dote | 7 |
| 3515 | dómine | 7 |
| 3516 | dividir | 7 |
| 3517 | discípulo | 7 |
| 3518 | diligencia | 7 |
| 3519 | digo | 7 |
| 3520 | di | 7 |
| 3521 | desusado | 7 |
| 3522 | desterrar | 7 |
| 3523 | desplomar | 7 |
| 3524 | despecho | 7 |
| 3525 | desmayar | 7 |
| 3526 | desigual | 7 |
| 3527 | deseoso | 7 |
| 3528 | desdecir | 7 |
| 3529 | desconsolado | 7 |
| 3530 | desatinar | 7 |
| 3531 | desatar | 7 |
| 3532 | depender | 7 |
| 3533 | departamento | 7 |
| 3534 | demonios | 7 |
| 3535 | deleite | 7 |
| 3536 | déjeme | 7 |
| 3537 | déjate | 7 |
| 3538 | dejado | 7 |
| 3539 | debido | 7 |
| 3540 | debe | 7 |
| 3541 | cumplimiento | 7 |
| 3542 | coyuntura | 7 |
| 3543 | cortedad | 7 |
| 3544 | conquista | 7 |
| 3545 | conformidad | 7 |
| 3546 | confesor | 7 |
| 3547 | concejal | 7 |
| 3548 | comulgar | 7 |
| 3549 | complacer | 7 |
| 3550 | cómico | 7 |
| 3551 | colorar | 7 |
| 3552 | cohibir | 7 |
| 3553 | cocinero | 7 |
| 3554 | cláusula | 7 |
| 3555 | chimenea | 7 |
| 3556 | céntimo | 7 |
| 3557 | ceniza | 7 |
| 3558 | catorce | 7 |
| 3559 | catedral | 7 |
| 3560 | catarro | 7 |
| 3561 | cascote | 7 |
| 3562 | cartilla | 7 |
| 3563 | carbón | 7 |
| 3564 | caramba | 7 |
| 3565 | canonjía | 7 |
| 3566 | campaña | 7 |
| 3567 | calzón | 7 |
| 3568 | callado | 7 |
| 3569 | calentura | 7 |
| 3570 | calar | 7 |
| 3571 | caído | 7 |
| 3572 | cadáver | 7 |
| 3573 | cacharro | 7 |
| 3574 | cabezada | 7 |
| 3575 | cabecero | 7 |
| 3576 | burlesco | 7 |
| 3577 | bromuro | 7 |
| 3578 | brinco | 7 |
| 3579 | bendecir | 7 |
| 3580 | bayeta | 7 |
| 3581 | barriga | 7 |
| 3582 | baño | 7 |
| 3583 | banqueta | 7 |
| 3584 | baile | 7 |
| 3585 | bacalao | 7 |
| 3586 | atrocidad | 7 |
| 3587 | atractivo | 7 |
| 3588 | atocha | 7 |
| 3589 | asqueroso | 7 |
| 3590 | asociar | 7 |
| 3591 | asentimiento | 7 |
| 3592 | artístico | 7 |
| 3593 | articular | 7 |
| 3594 | aristocracia | 7 |
| 3595 | arañar | 7 |
| 3596 | apelar | 7 |
| 3597 | aparte | 7 |
| 3598 | anteojo | 7 |
| 3599 | anegar | 7 |
| 3600 | anarquista | 7 |
| 3601 | anarquía | 7 |
| 3602 | amparo | 7 |
| 3603 | americana | 7 |
| 3604 | ameno | 7 |
| 3605 | alternativa | 7 |
| 3606 | alimentar | 7 |
| 3607 | alhaja | 7 |
| 3608 | alfiler | 7 |
| 3609 | alburquerque | 7 |
| 3610 | alambre | 7 |
| 3611 | agregó | 7 |
| 3612 | agradecido | 7 |
| 3613 | agradable | 7 |
| 3614 | ágil | 7 |
| 3615 | aflicción | 7 |
| 3616 | afanar | 7 |
| 3617 | adoptivo | 7 |
| 3618 | adefesio | 7 |
| 3619 | acreedor | 7 |
| 3620 | acordose | 7 |
| 3621 | acobardar | 7 |
| 3622 | achuchón | 7 |
| 3623 | accionar | 7 |
| 3624 | accidente | 7 |
| 3625 | acalorar | 7 |
| 3626 | abusar | 7 |
| 3627 | abuelo | 7 |
| 3628 | abrasar | 7 |
| 3629 | zaragata | 6 |
| 3630 | xi | 6 |
| 3631 | vulgo | 6 |
| 3632 | vulgaridad | 6 |
| 3633 | voy | 6 |
| 3634 | votación | 6 |
| 3635 | vosotros | 6 |
| 3636 | visible | 6 |
| 3637 | violentar | 6 |
| 3638 | viciar | 6 |
| 3639 | viajar | 6 |
| 3640 | viajante | 6 |
| 3641 | vendedor | 6 |
| 3642 | ven | 6 |
| 3643 | veleta | 6 |
| 3644 | váyase | 6 |
| 3645 | vacilación | 6 |
| 3646 | urbanidad | 6 |
| 3647 | universal | 6 |
| 3648 | últimamente | 6 |
| 3649 | turno | 6 |
| 3650 | turco | 6 |
| 3651 | tumulto | 6 |
| 3652 | trozo | 6 |
| 3653 | tropiezo | 6 |
| 3654 | trompetilla | 6 |
| 3655 | triquiñuela | 6 |
| 3656 | trémulo | 6 |
| 3657 | travieso | 6 |
| 3658 | trasladar | 6 |
| 3659 | tránsito | 6 |
| 3660 | transición | 6 |
| 3661 | traición | 6 |
| 3662 | trabajador | 6 |
| 3663 | torcido | 6 |
| 3664 | tonillo | 6 |
| 3665 | tomás | 6 |
| 3666 | título | 6 |
| 3667 | tintoreros | 6 |
| 3668 | tiniebla | 6 |
| 3669 | timo | 6 |
| 3670 | tigre | 6 |
| 3671 | tez | 6 |
| 3672 | terminante | 6 |
| 3673 | tentación | 6 |
| 3674 | temperamento | 6 |
| 3675 | temerario | 6 |
| 3676 | tellería | 6 |
| 3677 | tardanza | 6 |
| 3678 | tablero | 6 |
| 3679 | suprimir | 6 |
| 3680 | superioridad | 6 |
| 3681 | sumamente | 6 |
| 3682 | suma | 6 |
| 3683 | sugerir | 6 |
| 3684 | suelos | 6 |
| 3685 | sueldo | 6 |
| 3686 | suela | 6 |
| 3687 | sucesor | 6 |
| 3688 | sublevar | 6 |
| 3689 | súbitamente | 6 |
| 3690 | suave | 6 |
| 3691 | sopetón | 6 |
| 3692 | sonrosar | 6 |
| 3693 | somnolencia | 6 |
| 3694 | sollozo | 6 |
| 3695 | silencioso | 6 |
| 3696 | signar | 6 |
| 3697 | sietemesino | 6 |
| 3698 | sien | 6 |
| 3699 | sevilla | 6 |
| 3700 | servidumbre | 6 |
| 3701 | serie | 6 |
| 3702 | separación | 6 |
| 3703 | sentimental | 6 |
| 3704 | sensato | 6 |
| 3705 | sayo | 6 |
| 3706 | samaritano | 6 |
| 3707 | salvo | 6 |
| 3708 | salió | 6 |
| 3709 | saladero | 6 |
| 3710 | sacudida | 6 |
| 3711 | saborear | 6 |
| 3712 | ruidoso | 6 |
| 3713 | rudeza | 6 |
| 3714 | rosquilla | 6 |
| 3715 | revolcar | 6 |
| 3716 | responsable | 6 |
| 3717 | respaldo | 6 |
| 3718 | resonar | 6 |
| 3719 | reproducción | 6 |
| 3720 | remontar | 6 |
| 3721 | relativamente | 6 |
| 3722 | relamer | 6 |
| 3723 | regreso | 6 |
| 3724 | regocijo | 6 |
| 3725 | reflexión | 6 |
| 3726 | recuerdo | 6 |
| 3727 | reciente | 6 |
| 3728 | recetar | 6 |
| 3729 | receta | 6 |
| 3730 | recelar | 6 |
| 3731 | rebelde | 6 |
| 3732 | reacción | 6 |
| 3733 | razonar | 6 |
| 3734 | razonamiento | 6 |
| 3735 | raimundo | 6 |
| 3736 | rabioso | 6 |
| 3737 | quinqué | 6 |
| 3738 | quijada | 6 |
| 3739 | queda | 6 |
| 3740 | pureza | 6 |
| 3741 | puntillas | 6 |
| 3742 | púlpito | 6 |
| 3743 | puede | 6 |
| 3744 | publicar | 6 |
| 3745 | puar | 6 |
| 3746 | provisión | 6 |
| 3747 | protestar | 6 |
| 3748 | proseguir | 6 |
| 3749 | proporción | 6 |
| 3750 | propietario | 6 |
| 3751 | propaganda | 6 |
| 3752 | privado | 6 |
| 3753 | prisión | 6 |
| 3754 | prestamista | 6 |
| 3755 | presentir | 6 |
| 3756 | precursor | 6 |
| 3757 | positivo | 6 |
| 3758 | pobrecilla | 6 |
| 3759 | pliego | 6 |
| 3760 | pleno | 6 |
| 3761 | plazo | 6 |
| 3762 | pito | 6 |
| 3763 | pisto | 6 |
| 3764 | pino | 6 |
| 3765 | pillete | 6 |
| 3766 | picador | 6 |
| 3767 | pianista | 6 |
| 3768 | petróleo | 6 |
| 3769 | pescador | 6 |
| 3770 | perversidad | 6 |
| 3771 | perturbar | 6 |
| 3772 | perdulario | 6 |
| 3773 | percal | 6 |
| 3774 | pelear | 6 |
| 3775 | pasta | 6 |
| 3776 | paréntesis | 6 |
| 3777 | papelito | 6 |
| 3778 | palpar | 6 |
| 3779 | página | 6 |
| 3780 | original | 6 |
| 3781 | oía | 6 |
| 3782 | oficiosidad | 6 |
| 3783 | ofensa | 6 |
| 3784 | nudo | 6 |
| 3785 | noria | 6 |
| 3786 | narciso | 6 |
| 3787 | napoleónico | 6 |
| 3788 | murria | 6 |
| 3789 | murmullo | 6 |
| 3790 | mula | 6 |
| 3791 | mugre | 6 |
| 3792 | muchedumbre | 6 |
| 3793 | motor | 6 |
| 3794 | mote | 6 |
| 3795 | mosquito | 6 |
| 3796 | monosílabo | 6 |
| 3797 | monarquía | 6 |
| 3798 | modelar | 6 |
| 3799 | miga | 6 |
| 3800 | mezcla | 6 |
| 3801 | memorable | 6 |
| 3802 | melancólico | 6 |
| 3803 | meditabundo | 6 |
| 3804 | mecánico | 6 |
| 3805 | mazapán | 6 |
| 3806 | mayoría | 6 |
| 3807 | maridar | 6 |
| 3808 | marca | 6 |
| 3809 | maravilla | 6 |
| 3810 | manos | 6 |
| 3811 | manguito | 6 |
| 3812 | mango | 6 |
| 3813 | manga | 6 |
| 3814 | luto | 6 |
| 3815 | lulio | 6 |
| 3816 | llavín | 6 |
| 3817 | líquido | 6 |
| 3818 | linaje | 6 |
| 3819 | limpia | 6 |
| 3820 | ligeramente | 6 |
| 3821 | leña | 6 |
| 3822 | lento | 6 |
| 3823 | leganés | 6 |
| 3824 | junta | 6 |
| 3825 | junio | 6 |
| 3826 | junco | 6 |
| 3827 | julio | 6 |
| 3828 | jovial | 6 |
| 3829 | jerez | 6 |
| 3830 | jarana | 6 |
| 3831 | ironía | 6 |
| 3832 | interlocutor | 6 |
| 3833 | intento | 6 |
| 3834 | insultar | 6 |
| 3835 | inseguro | 6 |
| 3836 | ingenuidad | 6 |
| 3837 | infaliblemente | 6 |
| 3838 | índice | 6 |
| 3839 | indicación | 6 |
| 3840 | incapaz | 6 |
| 3841 | impreso | 6 |
| 3842 | imperioso | 6 |
| 3843 | humorístico | 6 |
| 3844 | humorado | 6 |
| 3845 | hongo | 6 |
| 3846 | hito | 6 |
| 3847 | hinchar | 6 |
| 3848 | higo | 6 |
| 3849 | hermosísimo | 6 |
| 3850 | hechura | 6 |
| 3851 | habitante | 6 |
| 3852 | hábil | 6 |
| 3853 | gruñir | 6 |
| 3854 | gruñido | 6 |
| 3855 | gravelinas | 6 |
| 3856 | grata | 6 |
| 3857 | granuja | 6 |
| 3858 | grandeza | 6 |
| 3859 | glorioso | 6 |
| 3860 | gilimón | 6 |
| 3861 | generosidad | 6 |
| 3862 | gatillo | 6 |
| 3863 | gallego | 6 |
| 3864 | galán | 6 |
| 3865 | gabán | 6 |
| 3866 | fusilar | 6 |
| 3867 | frito | 6 |
| 3868 | fósforo | 6 |
| 3869 | formidable | 6 |
| 3870 | forastero | 6 |
| 3871 | fonda | 6 |
| 3872 | firma | 6 |
| 3873 | finalmente | 6 |
| 3874 | figurábase | 6 |
| 3875 | festivo | 6 |
| 3876 | feroz | 6 |
| 3877 | felipe | 6 |
| 3878 | faz | 6 |
| 3879 | fárrago | 6 |
| 3880 | facilidad | 6 |
| 3881 | extraviar | 6 |
| 3882 | extinguir | 6 |
| 3883 | expirar | 6 |
| 3884 | experimentar | 6 |
| 3885 | excepción | 6 |
| 3886 | exactitud | 6 |
| 3887 | etiqueta | 6 |
| 3888 | estropear | 6 |
| 3889 | estrechez | 6 |
| 3890 | estos | 6 |
| 3891 | estirón | 6 |
| 3892 | estallar | 6 |
| 3893 | espinazo | 6 |
| 3894 | espetar | 6 |
| 3895 | escritura | 6 |
| 3896 | escarola | 6 |
| 3897 | escandalizar | 6 |
| 3898 | escalofrío | 6 |
| 3899 | esas | 6 |
| 3900 | equivaler | 6 |
| 3901 | equilibrio | 6 |
| 3902 | enviar | 6 |
| 3903 | envalentonar | 6 |
| 3904 | entrole | 6 |
| 3905 | entresuelo | 6 |
| 3906 | entornar | 6 |
| 3907 | enredo | 6 |
| 3908 | enhorabuena | 6 |
| 3909 | engatusar | 6 |
| 3910 | enero | 6 |
| 3911 | encogimiento | 6 |
| 3912 | encarnado | 6 |
| 3913 | enamorado | 6 |
| 3914 | empalagoso | 6 |
| 3915 | emigración | 6 |
| 3916 | embriagar | 6 |
| 3917 | ejemplar | 6 |
| 3918 | ejecución | 6 |
| 3919 | eco | 6 |
| 3920 | echose | 6 |
| 3921 | duquesa | 6 |
| 3922 | dulcemente | 6 |
| 3923 | dudoso | 6 |
| 3924 | ducha | 6 |
| 3925 | droguería | 6 |
| 3926 | droga | 6 |
| 3927 | dominio | 6 |
| 3928 | dominante | 6 |
| 3929 | domar | 6 |
| 3930 | diván | 6 |
| 3931 | distribuir | 6 |
| 3932 | distribución | 6 |
| 3933 | disipar | 6 |
| 3934 | díjole | 6 |
| 3935 | digerir | 6 |
| 3936 | dígale | 6 |
| 3937 | dices | 6 |
| 3938 | dibujo | 6 |
| 3939 | dialéctico | 6 |
| 3940 | diablura | 6 |
| 3941 | devaneo | 6 |
| 3942 | deudor | 6 |
| 3943 | determinado | 6 |
| 3944 | destrozar | 6 |
| 3945 | destacar | 6 |
| 3946 | despejado | 6 |
| 3947 | desnudo | 6 |
| 3948 | desfilar | 6 |
| 3949 | desdeñoso | 6 |
| 3950 | desconsolar | 6 |
| 3951 | descompuesto | 6 |
| 3952 | descalzar | 6 |
| 3953 | derribar | 6 |
| 3954 | derivar | 6 |
| 3955 | demostración | 6 |
| 3956 | delirar | 6 |
| 3957 | delgado | 6 |
| 3958 | daño | 6 |
| 3959 | dale | 6 |
| 3960 | curiosear | 6 |
| 3961 | cuña | 6 |
| 3962 | cuentas | 6 |
| 3963 | cucharada | 6 |
| 3964 | cuartito | 6 |
| 3965 | cretona | 6 |
| 3966 | creo | 6 |
| 3967 | créetelo | 6 |
| 3968 | credencial | 6 |
| 3969 | cotorra | 6 |
| 3970 | cosquillar | 6 |
| 3971 | cortado | 6 |
| 3972 | corsé | 6 |
| 3973 | correo | 6 |
| 3974 | copar | 6 |
| 3975 | contrabandista | 6 |
| 3976 | consumir | 6 |
| 3977 | constantemente | 6 |
| 3978 | consorte | 6 |
| 3979 | conocedor | 6 |
| 3980 | concebir | 6 |
| 3981 | compostura | 6 |
| 3982 | comparación | 6 |
| 3983 | comandante | 6 |
| 3984 | coco | 6 |
| 3985 | cocido | 6 |
| 3986 | cocer | 6 |
| 3987 | cobarde | 6 |
| 3988 | clavetear | 6 |
| 3989 | citado | 6 |
| 3990 | cifra | 6 |
| 3991 | chocho | 6 |
| 3992 | chiquito | 6 |
| 3993 | chiquitín | 6 |
| 3994 | chafar | 6 |
| 3995 | cerilla | 6 |
| 3996 | cerebrar | 6 |
| 3997 | cerdo | 6 |
| 3998 | central | 6 |
| 3999 | cazador | 6 |
| 4000 | caza | 6 |
| 4001 | cavidad | 6 |
| 4002 | caudal | 6 |
| 4003 | caserío | 6 |
| 4004 | cascarón | 6 |
| 4005 | cartagena | 6 |
| 4006 | caritativo | 6 |
| 4007 | capirote | 6 |
| 4008 | canutar | 6 |
| 4009 | cantero | 6 |
| 4010 | canónigo | 6 |
| 4011 | canela | 6 |
| 4012 | cándido | 6 |
| 4013 | campanada | 6 |
| 4014 | caliente | 6 |
| 4015 | caldear | 6 |
| 4016 | calaverada | 6 |
| 4017 | cabellera | 6 |
| 4018 | caballería | 6 |
| 4019 | bullicio | 6 |
| 4020 | buenos | 6 |
| 4021 | brutal | 6 |
| 4022 | botar | 6 |
| 4023 | bonita | 6 |
| 4024 | bonilla | 6 |
| 4025 | bloque | 6 |
| 4026 | berrido | 6 |
| 4027 | benéfico | 6 |
| 4028 | bello | 6 |
| 4029 | bayona | 6 |
| 4030 | bautizo | 6 |
| 4031 | basura | 6 |
| 4032 | barullo | 6 |
| 4033 | barco | 6 |
| 4034 | barato | 6 |
| 4035 | bandera | 6 |
| 4036 | bandeja | 6 |
| 4037 | babero | 6 |
| 4038 | ayún | 6 |
| 4039 | ayuda | 6 |
| 4040 | atropellar | 6 |
| 4041 | atrasar | 6 |
| 4042 | atracción | 6 |
| 4043 | atontar | 6 |
| 4044 | aterrador | 6 |
| 4045 | ateo | 6 |
| 4046 | aspereza | 6 |
| 4047 | artesa | 6 |
| 4048 | arruinar | 6 |
| 4049 | arrugar | 6 |
| 4050 | arroyo | 6 |
| 4051 | arquitectura | 6 |
| 4052 | arca | 6 |
| 4053 | apunte | 6 |
| 4054 | aprensión | 6 |
| 4055 | apreciable | 6 |
| 4056 | apartado | 6 |
| 4057 | ansioso | 6 |
| 4058 | amarrar | 6 |
| 4059 | amantar | 6 |
| 4060 | amalia | 6 |
| 4061 | amado | 6 |
| 4062 | alivio | 6 |
| 4063 | aliviar | 6 |
| 4064 | aletargar | 6 |
| 4065 | alboroto | 6 |
| 4066 | albert | 6 |
| 4067 | alarmado | 6 |
| 4068 | alarde | 6 |
| 4069 | alabar | 6 |
| 4070 | ajar | 6 |
| 4071 | airar | 6 |
| 4072 | agudeza | 6 |
| 4073 | aguar | 6 |
| 4074 | agrandar | 6 |
| 4075 | agente | 6 |
| 4076 | afinar | 6 |
| 4077 | afilar | 6 |
| 4078 | adúltero | 6 |
| 4079 | adormecer | 6 |
| 4080 | administrativo | 6 |
| 4081 | administrar | 6 |
| 4082 | acusar | 6 |
| 4083 | acosar | 6 |
| 4084 | abundar | 6 |
| 4085 | abundante | 6 |
| 4086 | abatimiento | 6 |
| 4087 | abandono | 6 |
| 4088 | zozobra | 5 |
| 4089 | zona | 5 |
| 4090 | zarzuela | 5 |
| 4091 | vosotras | 5 |
| 4092 | visitación | 5 |
| 4093 | visaje | 5 |
| 4094 | viruela | 5 |
| 4095 | violín | 5 |
| 4096 | violentamente | 5 |
| 4097 | villaamil | 5 |
| 4098 | viga | 5 |
| 4099 | vientre | 5 |
| 4100 | vidrio | 5 |
| 4101 | vicario | 5 |
| 4102 | víbora | 5 |
| 4103 | venta | 5 |
| 4104 | vengo | 5 |
| 4105 | venerable | 5 |
| 4106 | vena | 5 |
| 4107 | vecindario | 5 |
| 4108 | variedades | 5 |
| 4109 | vapor | 5 |
| 4110 | vano | 5 |
| 4111 | valía | 5 |
| 4112 | valeroso | 5 |
| 4113 | vaca | 5 |
| 4114 | útil | 5 |
| 4115 | uniforme | 5 |
| 4116 | turquesa | 5 |
| 4117 | trompeta | 5 |
| 4118 | trivial | 5 |
| 4119 | trinar | 5 |
| 4120 | trecho | 5 |
| 4121 | trayecto | 5 |
| 4122 | travesura | 5 |
| 4123 | transparentar | 5 |
| 4124 | transfigurar | 5 |
| 4125 | transcurrir | 5 |
| 4126 | transacción | 5 |
| 4127 | tramo | 5 |
| 4128 | traicionero | 5 |
| 4129 | tragedia | 5 |
| 4130 | tradición | 5 |
| 4131 | tostar | 5 |
| 4132 | torero | 5 |
| 4133 | tontaina | 5 |
| 4134 | todos | 5 |
| 4135 | toalla | 5 |
| 4136 | tintero | 5 |
| 4137 | tímidamente | 5 |
| 4138 | tilín | 5 |
| 4139 | tientas | 5 |
| 4140 | tétrico | 5 |
| 4141 | testimonio | 5 |
| 4142 | terrón | 5 |
| 4143 | tendré | 5 |
| 4144 | tenaza | 5 |
| 4145 | templo | 5 |
| 4146 | telégrafo | 5 |
| 4147 | tecla | 5 |
| 4148 | taza | 5 |
| 4149 | tapujo | 5 |
| 4150 | tapiar | 5 |
| 4151 | tamañito | 5 |
| 4152 | tacón | 5 |
| 4153 | tabernillas | 5 |
| 4154 | surtir | 5 |
| 4155 | suplicar | 5 |
| 4156 | supersticioso | 5 |
| 4157 | suizo | 5 |
| 4158 | suicidio | 5 |
| 4159 | suficiencia | 5 |
| 4160 | sucesivo | 5 |
| 4161 | sospechoso | 5 |
| 4162 | soportar | 5 |
| 4163 | sopor | 5 |
| 4164 | solutamente | 5 |
| 4165 | solito | 5 |
| 4166 | soliloquio | 5 |
| 4167 | soldado | 5 |
| 4168 | sobrenatural | 5 |
| 4169 | sobrante | 5 |
| 4170 | siniestro | 5 |
| 4171 | sinceramente | 5 |
| 4172 | silbar | 5 |
| 4173 | serrano | 5 |
| 4174 | sería | 5 |
| 4175 | serafín | 5 |
| 4176 | sentíase | 5 |
| 4177 | sensible | 5 |
| 4178 | senquá | 5 |
| 4179 | sembrar | 5 |
| 4180 | sedación | 5 |
| 4181 | secta | 5 |
| 4182 | satánico | 5 |
| 4183 | sarcasmo | 5 |
| 4184 | saliva | 5 |
| 4185 | salamanca | 5 |
| 4186 | saco | 5 |
| 4187 | sablazo | 5 |
| 4188 | rutinario | 5 |
| 4189 | rumbo | 5 |
| 4190 | rufinita | 5 |
| 4191 | rúbrica | 5 |
| 4192 | ronquido | 5 |
| 4193 | rompimiento | 5 |
| 4194 | romano | 5 |
| 4195 | robustez | 5 |
| 4196 | revivir | 5 |
| 4197 | revisar | 5 |
| 4198 | reverdecer | 5 |
| 4199 | reunión | 5 |
| 4200 | retroceder | 5 |
| 4201 | reticencia | 5 |
| 4202 | restregar | 5 |
| 4203 | resbalar | 5 |
| 4204 | resabio | 5 |
| 4205 | requemar | 5 |
| 4206 | repóblica | 5 |
| 4207 | repetición | 5 |
| 4208 | reparador | 5 |
| 4209 | remiendo | 5 |
| 4210 | remedar | 5 |
| 4211 | relatar | 5 |
| 4212 | reinado | 5 |
| 4213 | refajo | 5 |
| 4214 | reducido | 5 |
| 4215 | reclinar | 5 |
| 4216 | rechinar | 5 |
| 4217 | receloso | 5 |
| 4218 | recatar | 5 |
| 4219 | rayar | 5 |
| 4220 | rasguear | 5 |
| 4221 | raquítico | 5 |
| 4222 | ramsés | 5 |
| 4223 | racimo | 5 |
| 4224 | quítate | 5 |
| 4225 | quintos | 5 |
| 4226 | quinto | 5 |
| 4227 | quinientos | 5 |
| 4228 | quietud | 5 |
| 4229 | quicio | 5 |
| 4230 | quejumbroso | 5 |
| 4231 | quebrantar | 5 |
| 4232 | puñado | 5 |
| 4233 | pum | 5 |
| 4234 | proyectar | 5 |
| 4235 | provocar | 5 |
| 4236 | prosperidad | 5 |
| 4237 | prójimo | 5 |
| 4238 | prodigar | 5 |
| 4239 | procedencia | 5 |
| 4240 | privación | 5 |
| 4241 | prisionero | 5 |
| 4242 | primor | 5 |
| 4243 | primar | 5 |
| 4244 | prevención | 5 |
| 4245 | prevalecer | 5 |
| 4246 | presidio | 5 |
| 4247 | preocupar | 5 |
| 4248 | preocupación | 5 |
| 4249 | prender | 5 |
| 4250 | prendar | 5 |
| 4251 | pregonar | 5 |
| 4252 | pregón | 5 |
| 4253 | preciosísimo | 5 |
| 4254 | preciar | 5 |
| 4255 | precaución | 5 |
| 4256 | postre | 5 |
| 4257 | posesión | 5 |
| 4258 | portillo | 5 |
| 4259 | poquillo | 5 |
| 4260 | poníase | 5 |
| 4261 | podrido | 5 |
| 4262 | población | 5 |
| 4263 | plomo | 5 |
| 4264 | pizcar | 5 |
| 4265 | pizca | 5 |
| 4266 | pisotear | 5 |
| 4267 | pirrar | 5 |
| 4268 | pinchar | 5 |
| 4269 | pillería | 5 |
| 4270 | piensa | 5 |
| 4271 | picor | 5 |
| 4272 | pesadumbre | 5 |
| 4273 | perteneciente | 5 |
| 4274 | persistir | 5 |
| 4275 | perezoso | 5 |
| 4276 | peregrinar | 5 |
| 4277 | perdone | 5 |
| 4278 | pelotera | 5 |
| 4279 | pellizco | 5 |
| 4280 | pellejo | 5 |
| 4281 | pelagatos | 5 |
| 4282 | pegado | 5 |
| 4283 | pedernal | 5 |
| 4284 | pavero | 5 |
| 4285 | patrocinio | 5 |
| 4286 | pastilla | 5 |
| 4287 | pasmado | 5 |
| 4288 | pascua | 5 |
| 4289 | pasajero | 5 |
| 4290 | particularmente | 5 |
| 4291 | particularidad | 5 |
| 4292 | paquetito | 5 |
| 4293 | pánico | 5 |
| 4294 | panadería | 5 |
| 4295 | pana | 5 |
| 4296 | palotada | 5 |
| 4297 | palmito | 5 |
| 4298 | palidez | 5 |
| 4299 | paleto | 5 |
| 4300 | oveja | 5 |
| 4301 | ostentar | 5 |
| 4302 | opulento | 5 |
| 4303 | oposición | 5 |
| 4304 | onza | 5 |
| 4305 | olivo | 5 |
| 4306 | olfato | 5 |
| 4307 | ofrecimiento | 5 |
| 4308 | nueva | 5 |
| 4309 | novelar | 5 |
| 4310 | noción | 5 |
| 4311 | ninguna | 5 |
| 4312 | nieve | 5 |
| 4313 | neto | 5 |
| 4314 | nefando | 5 |
| 4315 | nave | 5 |
| 4316 | na | 5 |
| 4317 | músico | 5 |
| 4318 | muestrario | 5 |
| 4319 | mudo | 5 |
| 4320 | móvil | 5 |
| 4321 | mortuorio | 5 |
| 4322 | moro | 5 |
| 4323 | moña | 5 |
| 4324 | montera | 5 |
| 4325 | mitón | 5 |
| 4326 | mismamente | 5 |
| 4327 | misericordia | 5 |
| 4328 | miren | 5 |
| 4329 | mirador | 5 |
| 4330 | miquis | 5 |
| 4331 | mico | 5 |
| 4332 | metro | 5 |
| 4333 | metamorfosis | 5 |
| 4334 | mesar | 5 |
| 4335 | menudillos | 5 |
| 4336 | mendigo | 5 |
| 4337 | memo | 5 |
| 4338 | melitona | 5 |
| 4339 | mecanismo | 5 |
| 4340 | mecánica | 5 |
| 4341 | materialista | 5 |
| 4342 | mata | 5 |
| 4343 | martillo | 5 |
| 4344 | mantillo | 5 |
| 4345 | manifiesto | 5 |
| 4346 | mama | 5 |
| 4347 | malito | 5 |
| 4348 | madurar | 5 |
| 4349 | lunes | 5 |
| 4350 | luis | 5 |
| 4351 | lozanía | 5 |
| 4352 | lomo | 5 |
| 4353 | llegada | 5 |
| 4354 | lisonjero | 5 |
| 4355 | límite | 5 |
| 4356 | limitar | 5 |
| 4357 | licor | 5 |
| 4358 | licencia | 5 |
| 4359 | leve | 5 |
| 4360 | leñar | 5 |
| 4361 | legal | 5 |
| 4362 | lata | 5 |
| 4363 | largamente | 5 |
| 4364 | lápiz | 5 |
| 4365 | lápida | 5 |
| 4366 | lanilla | 5 |
| 4367 | laboratorio | 5 |
| 4368 | labia | 5 |
| 4369 | jorobar | 5 |
| 4370 | jeta | 5 |
| 4371 | jesucristo | 5 |
| 4372 | japonés | 5 |
| 4373 | inverosímil | 5 |
| 4374 | invención | 5 |
| 4375 | interpretar | 5 |
| 4376 | intermitente | 5 |
| 4377 | instrumento | 5 |
| 4378 | instruir | 5 |
| 4379 | inspección | 5 |
| 4380 | insensible | 5 |
| 4381 | injuria | 5 |
| 4382 | ínfula | 5 |
| 4383 | industrial | 5 |
| 4384 | individual | 5 |
| 4385 | indiferente | 5 |
| 4386 | indicio | 5 |
| 4387 | incrédulo | 5 |
| 4388 | inconstante | 5 |
| 4389 | incierto | 5 |
| 4390 | inaudito | 5 |
| 4391 | imprimir | 5 |
| 4392 | imitación | 5 |
| 4393 | ilustrado | 5 |
| 4394 | ilusionar | 5 |
| 4395 | idiota | 5 |
| 4396 | humedad | 5 |
| 4397 | hospicio | 5 |
| 4398 | horripilar | 5 |
| 4399 | hormiga | 5 |
| 4400 | honrada | 5 |
| 4401 | hipotecar | 5 |
| 4402 | himno | 5 |
| 4403 | hígado | 5 |
| 4404 | hervir | 5 |
| 4405 | herrero | 5 |
| 4406 | hastío | 5 |
| 4407 | hambriento | 5 |
| 4408 | había | 5 |
| 4409 | greña | 5 |
| 4410 | gravemente | 5 |
| 4411 | gratis | 5 |
| 4412 | grano | 5 |
| 4413 | gradualmente | 5 |
| 4414 | gentío | 5 |
| 4415 | gata | 5 |
| 4416 | garra | 5 |
| 4417 | garabato | 5 |
| 4418 | gallardamente | 5 |
| 4419 | galera | 5 |
| 4420 | futura | 5 |
| 4421 | funesto | 5 |
| 4422 | fulgor | 5 |
| 4423 | fuero | 5 |
| 4424 | fruto | 5 |
| 4425 | fruta | 5 |
| 4426 | friolera | 5 |
| 4427 | frenético | 5 |
| 4428 | frecuencia | 5 |
| 4429 | fragancia | 5 |
| 4430 | fortaleza | 5 |
| 4431 | formular | 5 |
| 4432 | follaje | 5 |
| 4433 | flojo | 5 |
| 4434 | fineza | 5 |
| 4435 | financiero | 5 |
| 4436 | fijamente | 5 |
| 4437 | figurín | 5 |
| 4438 | ferocidad | 5 |
| 4439 | feria | 5 |
| 4440 | femenino | 5 |
| 4441 | fascinación | 5 |
| 4442 | fardo | 5 |
| 4443 | fango | 5 |
| 4444 | familiarizar | 5 |
| 4445 | familiaridad | 5 |
| 4446 | fajar | 5 |
| 4447 | facilitar | 5 |
| 4448 | fabricar | 5 |
| 4449 | extrañeza | 5 |
| 4450 | extraer | 5 |
| 4451 | expulsar | 5 |
| 4452 | expectación | 5 |
| 4453 | exacto | 5 |
| 4454 | evocar | 5 |
| 4455 | estupefacción | 5 |
| 4456 | estribillo | 5 |
| 4457 | estas | 5 |
| 4458 | esqueleto | 5 |
| 4459 | espiritista | 5 |
| 4460 | esperanzar | 5 |
| 4461 | espera | 5 |
| 4462 | espaldas | 5 |
| 4463 | esmerar | 5 |
| 4464 | escorial | 5 |
| 4465 | escoltar | 5 |
| 4466 | erudición | 5 |
| 4467 | equipaje | 5 |
| 4468 | envoltorio | 5 |
| 4469 | envejecer | 5 |
| 4470 | entusiasta | 5 |
| 4471 | entristecer | 5 |
| 4472 | entrevista | 5 |
| 4473 | entrañar | 5 |
| 4474 | entonar | 5 |
| 4475 | entidad | 5 |
| 4476 | entablar | 5 |
| 4477 | ensalada | 5 |
| 4478 | enroscar | 5 |
| 4479 | enredadera | 5 |
| 4480 | ennoblecer | 5 |
| 4481 | enfurruñar | 5 |
| 4482 | enfrentar | 5 |
| 4483 | enfático | 5 |
| 4484 | énfasis | 5 |
| 4485 | endeble | 5 |
| 4486 | encierro | 5 |
| 4487 | encasquetar | 5 |
| 4488 | embuste | 5 |
| 4489 | embrutecer | 5 |
| 4490 | embozar | 5 |
| 4491 | emborrachar | 5 |
| 4492 | embebecer | 5 |
| 4493 | emanar | 5 |
| 4494 | elogio | 5 |
| 4495 | elocuente | 5 |
| 4496 | elemento | 5 |
| 4497 | eje | 5 |
| 4498 | eficaz | 5 |
| 4499 | eclipsar | 5 |
| 4500 | dorado | 5 |
| 4501 | donativo | 5 |
| 4502 | divina | 5 |
| 4503 | displicente | 5 |
| 4504 | disolver | 5 |
| 4505 | disculpar | 5 |
| 4506 | directamente | 5 |
| 4507 | diplomático | 5 |
| 4508 | diligenciar | 5 |
| 4509 | dicha | 5 |
| 4510 | diamante | 5 |
| 4511 | desvelar | 5 |
| 4512 | despidiose | 5 |
| 4513 | despensa | 5 |
| 4514 | desmayado | 5 |
| 4515 | desigualdad | 5 |
| 4516 | desierto | 5 |
| 4517 | deshonra | 5 |
| 4518 | desesperar | 5 |
| 4519 | descuidado | 5 |
| 4520 | descalzo | 5 |
| 4521 | descabezar | 5 |
| 4522 | desbaratar | 5 |
| 4523 | desayuno | 5 |
| 4524 | desasosiego | 5 |
| 4525 | desagradar | 5 |
| 4526 | desabrido | 5 |
| 4527 | depositar | 5 |
| 4528 | denunciar | 5 |
| 4529 | delantera | 5 |
| 4530 | definitivo | 5 |
| 4531 | dedillo | 5 |
| 4532 | decoración | 5 |
| 4533 | décimo | 5 |
| 4534 | decidido | 5 |
| 4535 | dame | 5 |
| 4536 | cuna | 5 |
| 4537 | cuerno | 5 |
| 4538 | cucharilla | 5 |
| 4539 | cubil | 5 |
| 4540 | cúbico | 5 |
| 4541 | cualidad | 5 |
| 4542 | cuajar | 5 |
| 4543 | cruzado | 5 |
| 4544 | crujir | 5 |
| 4545 | cristóbal | 5 |
| 4546 | cría | 5 |
| 4547 | crespón | 5 |
| 4548 | creencia | 5 |
| 4549 | costra | 5 |
| 4550 | costear | 5 |
| 4551 | cosquillas | 5 |
| 4552 | coscorrón | 5 |
| 4553 | cortés | 5 |
| 4554 | cortes | 5 |
| 4555 | correspondencia | 5 |
| 4556 | coronar | 5 |
| 4557 | corona | 5 |
| 4558 | coraje | 5 |
| 4559 | convencimiento | 5 |
| 4560 | contraste | 5 |
| 4561 | contraer | 5 |
| 4562 | contestó | 5 |
| 4563 | contenido | 5 |
| 4564 | constitución | 5 |
| 4565 | constancia | 5 |
| 4566 | consiguiente | 5 |
| 4567 | considerable | 5 |
| 4568 | congreso | 5 |
| 4569 | conducto | 5 |
| 4570 | condensar | 5 |
| 4571 | concordia | 5 |
| 4572 | concertar | 5 |
| 4573 | concerniente | 5 |
| 4574 | compinche | 5 |
| 4575 | compás | 5 |
| 4576 | comodidad | 5 |
| 4577 | comezón | 5 |
| 4578 | comerciar | 5 |
| 4579 | columna | 5 |
| 4580 | colega | 5 |
| 4581 | colchón | 5 |
| 4582 | cofre | 5 |
| 4583 | clerical | 5 |
| 4584 | cita | 5 |
| 4585 | circunstante | 5 |
| 4586 | cimiento | 5 |
| 4587 | cigarrillo | 5 |
| 4588 | cifrar | 5 |
| 4589 | chorro | 5 |
| 4590 | choque | 5 |
| 4591 | chiste | 5 |
| 4592 | chino | 5 |
| 4593 | china | 5 |
| 4594 | chapa | 5 |
| 4595 | chalán | 5 |
| 4596 | cerveza | 5 |
| 4597 | cayetano | 5 |
| 4598 | categoría | 5 |
| 4599 | catástrofe | 5 |
| 4600 | casita | 5 |
| 4601 | casera | 5 |
| 4602 | cáscara | 5 |
| 4603 | carnicería | 5 |
| 4604 | cariñosamente | 5 |
| 4605 | careta | 5 |
| 4606 | carcelero | 5 |
| 4607 | cánovas | 5 |
| 4608 | canción | 5 |
| 4609 | canario | 5 |
| 4610 | cambiazo | 5 |
| 4611 | calva | 5 |
| 4612 | callejón | 5 |
| 4613 | caletre | 5 |
| 4614 | burlón | 5 |
| 4615 | burgos | 5 |
| 4616 | bufanda | 5 |
| 4617 | brujo | 5 |
| 4618 | bronco | 5 |
| 4619 | bromear | 5 |
| 4620 | bodegón | 5 |
| 4621 | bicerra | 5 |
| 4622 | betún | 5 |
| 4623 | benigno | 5 |
| 4624 | benévolo | 5 |
| 4625 | bazar | 5 |
| 4626 | batalla | 5 |
| 4627 | bastero | 5 |
| 4628 | barrendero | 5 |
| 4629 | barra | 5 |
| 4630 | balbució | 5 |
| 4631 | balancear | 5 |
| 4632 | bajón | 5 |
| 4633 | baja | 5 |
| 4634 | azuzar | 5 |
| 4635 | azorar | 5 |
| 4636 | ayuntamiento | 5 |
| 4637 | aviar | 5 |
| 4638 | avenir | 5 |
| 4639 | autorizar | 5 |
| 4640 | ausentar | 5 |
| 4641 | aula | 5 |
| 4642 | atufar | 5 |
| 4643 | atributo | 5 |
| 4644 | atrasado | 5 |
| 4645 | atajar | 5 |
| 4646 | áspero | 5 |
| 4647 | asno | 5 |
| 4648 | asimilar | 5 |
| 4649 | asilar | 5 |
| 4650 | asiático | 5 |
| 4651 | ascender | 5 |
| 4652 | arsénico | 5 |
| 4653 | arrodillar | 5 |
| 4654 | arroba | 5 |
| 4655 | arrebatado | 5 |
| 4656 | armario | 5 |
| 4657 | aritmético | 5 |
| 4658 | aristocrático | 5 |
| 4659 | aprisa | 5 |
| 4660 | apremiar | 5 |
| 4661 | aprecio | 5 |
| 4662 | apóstol | 5 |
| 4663 | aplastar | 5 |
| 4664 | apestar | 5 |
| 4665 | apenar | 5 |
| 4666 | apechugar | 5 |
| 4667 | antiespasmódica | 5 |
| 4668 | anhelar | 5 |
| 4669 | angustioso | 5 |
| 4670 | andaluz | 5 |
| 4671 | amasar | 5 |
| 4672 | amargura | 5 |
| 4673 | amargo | 5 |
| 4674 | amabilidad | 5 |
| 4675 | alternar | 5 |
| 4676 | alquiler | 5 |
| 4677 | almo | 5 |
| 4678 | alfombrar | 5 |
| 4679 | alcalá | 5 |
| 4680 | alborotado | 5 |
| 4681 | alarmante | 5 |
| 4682 | agregar | 5 |
| 4683 | agradecimiento | 5 |
| 4684 | agotar | 5 |
| 4685 | agonía | 5 |
| 4686 | agachar | 5 |
| 4687 | afrenta | 5 |
| 4688 | afirmativamente | 5 |
| 4689 | afirmación | 5 |
| 4690 | aficionar | 5 |
| 4691 | aficionado | 5 |
| 4692 | afeitar | 5 |
| 4693 | afectuoso | 5 |
| 4694 | adecentar | 5 |
| 4695 | acusación | 5 |
| 4696 | acumular | 5 |
| 4697 | actriz | 5 |
| 4698 | activar | 5 |
| 4699 | acortar | 5 |
| 4700 | acertado | 5 |
| 4701 | acentuado | 5 |
| 4702 | aburrido | 5 |
| 4703 | abultar | 5 |
| 4704 | abstracción | 5 |
| 4705 | abreviar | 5 |
| 4706 | zarandear | 4 |
| 4707 | zapatero | 4 |
| 4708 | yerto | 4 |
| 4709 | xii | 4 |
| 4710 | vómito | 4 |
| 4711 | volcán | 4 |
| 4712 | viviente | 4 |
| 4713 | vistoso | 4 |
| 4714 | visionario | 4 |
| 4715 | visionar | 4 |
| 4716 | violento | 4 |
| 4717 | violar | 4 |
| 4718 | viña | 4 |
| 4719 | vil | 4 |
| 4720 | viene | 4 |
| 4721 | viéndole | 4 |
| 4722 | vete | 4 |
| 4723 | vestíbulo | 4 |
| 4724 | verter | 4 |
| 4725 | veremos | 4 |
| 4726 | venus | 4 |
| 4727 | venturoso | 4 |
| 4728 | ventura | 4 |
| 4729 | ventanillo | 4 |
| 4730 | veneración | 4 |
| 4731 | vencedor | 4 |
| 4732 | velocidad | 4 |
| 4733 | velador | 4 |
| 4734 | vejez | 4 |
| 4735 | vehemente | 4 |
| 4736 | vaticinar | 4 |
| 4737 | vastísimo | 4 |
| 4738 | van | 4 |
| 4739 | valle | 4 |
| 4740 | vaguedad | 4 |
| 4741 | uva | 4 |
| 4742 | urna | 4 |
| 4743 | uniformar | 4 |
| 4744 | unción | 4 |
| 4745 | ultramar | 4 |
| 4746 | tute | 4 |
| 4747 | túnel | 4 |
| 4748 | tufo | 4 |
| 4749 | trombón | 4 |
| 4750 | triunfante | 4 |
| 4751 | tristemente | 4 |
| 4752 | trenza | 4 |
| 4753 | traza | 4 |
| 4754 | trastamara | 4 |
| 4755 | trapito | 4 |
| 4756 | trapisonda | 4 |
| 4757 | trajín | 4 |
| 4758 | tradicional | 4 |
| 4759 | tosco | 4 |
| 4760 | tortuoso | 4 |
| 4761 | todas | 4 |
| 4762 | tocata | 4 |
| 4763 | toca | 4 |
| 4764 | tirano | 4 |
| 4765 | tímido | 4 |
| 4766 | timar | 4 |
| 4767 | tesón | 4 |
| 4768 | terso | 4 |
| 4769 | terneza | 4 |
| 4770 | términos | 4 |
| 4771 | terminantemente | 4 |
| 4772 | terciar | 4 |
| 4773 | teoría | 4 |
| 4774 | tenue | 4 |
| 4775 | tentativa | 4 |
| 4776 | tenemos | 4 |
| 4777 | tendencia | 4 |
| 4778 | tenaz | 4 |
| 4779 | temple | 4 |
| 4780 | tempestad | 4 |
| 4781 | temblor | 4 |
| 4782 | telón | 4 |
| 4783 | tarjeta | 4 |
| 4784 | tararí | 4 |
| 4785 | tapia | 4 |
| 4786 | talonario | 4 |
| 4787 | tagarote | 4 |
| 4788 | tacto | 4 |
| 4789 | tabique | 4 |
| 4790 | susurro | 4 |
| 4791 | sustraer | 4 |
| 4792 | suspicaz | 4 |
| 4793 | superficie | 4 |
| 4794 | superar | 4 |
| 4795 | sumo | 4 |
| 4796 | sufrimiento | 4 |
| 4797 | subsecretario | 4 |
| 4798 | sosegado | 4 |
| 4799 | sortear | 4 |
| 4800 | sorber | 4 |
| 4801 | sonoro | 4 |
| 4802 | soltura | 4 |
| 4803 | solterón | 4 |
| 4804 | solfa | 4 |
| 4805 | sofía | 4 |
| 4806 | sodio | 4 |
| 4807 | sócrates | 4 |
| 4808 | sobremesa | 4 |
| 4809 | sobón | 4 |
| 4810 | soberano | 4 |
| 4811 | situar | 4 |
| 4812 | sirviente | 4 |
| 4813 | singularísimo | 4 |
| 4814 | sincerar | 4 |
| 4815 | simpatizar | 4 |
| 4816 | sigue | 4 |
| 4817 | significación | 4 |
| 4818 | sierra | 4 |
| 4819 | severamente | 4 |
| 4820 | setenta | 4 |
| 4821 | sesión | 4 |
| 4822 | servilleta | 4 |
| 4823 | sermonear | 4 |
| 4824 | seriamente | 4 |
| 4825 | sepulcro | 4 |
| 4826 | sendero | 4 |
| 4827 | sello | 4 |
| 4828 | sedar | 4 |
| 4829 | secretario | 4 |
| 4830 | secretar | 4 |
| 4831 | sebastián | 4 |
| 4832 | satanás | 4 |
| 4833 | sastre | 4 |
| 4834 | sardina | 4 |
| 4835 | sangrar | 4 |
| 4836 | samaniegos | 4 |
| 4837 | salivar | 4 |
| 4838 | sahumar | 4 |
| 4839 | sagaz | 4 |
| 4840 | sacrílego | 4 |
| 4841 | sabedor | 4 |
| 4842 | ronco | 4 |
| 4843 | romanticismo | 4 |
| 4844 | rodeo | 4 |
| 4845 | rito | 4 |
| 4846 | riñón | 4 |
| 4847 | rinconada | 4 |
| 4848 | rígido | 4 |
| 4849 | ridiculez | 4 |
| 4850 | ribete | 4 |
| 4851 | reyerta | 4 |
| 4852 | revuelta | 4 |
| 4853 | retroceso | 4 |
| 4854 | retozar | 4 |
| 4855 | retintín | 4 |
| 4856 | resumidas | 4 |
| 4857 | resucitar | 4 |
| 4858 | respetabilidad | 4 |
| 4859 | residir | 4 |
| 4860 | resentimiento | 4 |
| 4861 | reposado | 4 |
| 4862 | repentino | 4 |
| 4863 | renovación | 4 |
| 4864 | rematar | 4 |
| 4865 | religiosamente | 4 |
| 4866 | relámpago | 4 |
| 4867 | relajación | 4 |
| 4868 | rehuir | 4 |
| 4869 | regularidad | 4 |
| 4870 | refrenar | 4 |
| 4871 | refregar | 4 |
| 4872 | reformar | 4 |
| 4873 | reflejar | 4 |
| 4874 | redonda | 4 |
| 4875 | redimir | 4 |
| 4876 | redacción | 4 |
| 4877 | recurrir | 4 |
| 4878 | rectificar | 4 |
| 4879 | recóndito | 4 |
| 4880 | reclamo | 4 |
| 4881 | rechazo | 4 |
| 4882 | rebaño | 4 |
| 4883 | reaparecer | 4 |
| 4884 | raudal | 4 |
| 4885 | rasguñar | 4 |
| 4886 | ras | 4 |
| 4887 | rancio | 4 |
| 4888 | radiante | 4 |
| 4889 | raciocinio | 4 |
| 4890 | quitose | 4 |
| 4891 | querencia | 4 |
| 4892 | quejido | 4 |
| 4893 | quehacer | 4 |
| 4894 | purísimo | 4 |
| 4895 | purificación | 4 |
| 4896 | puntualidad | 4 |
| 4897 | puntual | 4 |
| 4898 | puntilla | 4 |
| 4899 | pulgas | 4 |
| 4900 | publicación | 4 |
| 4901 | prudencia | 4 |
| 4902 | prorrumpir | 4 |
| 4903 | propuso | 4 |
| 4904 | pronunciación | 4 |
| 4905 | prontitud | 4 |
| 4906 | prontamente | 4 |
| 4907 | profesión | 4 |
| 4908 | profecía | 4 |
| 4909 | producto | 4 |
| 4910 | prodigioso | 4 |
| 4911 | previo | 4 |
| 4912 | pretendiente | 4 |
| 4913 | presbítero | 4 |
| 4914 | preparativo | 4 |
| 4915 | predilecto | 4 |
| 4916 | precoz | 4 |
| 4917 | prado | 4 |
| 4918 | practicante | 4 |
| 4919 | prácticamente | 4 |
| 4920 | plencia | 4 |
| 4921 | plegar | 4 |
| 4922 | platicar | 4 |
| 4923 | plática | 4 |
| 4924 | plancha | 4 |
| 4925 | placidez | 4 |
| 4926 | placentero | 4 |
| 4927 | pláceme | 4 |
| 4928 | pisada | 4 |
| 4929 | pirámide | 4 |
| 4930 | pintada | 4 |
| 4931 | pingo | 4 |
| 4932 | pingajo | 4 |
| 4933 | pila | 4 |
| 4934 | pienso | 4 |
| 4935 | picotear | 4 |
| 4936 | picarón | 4 |
| 4937 | petitorio | 4 |
| 4938 | pestañear | 4 |
| 4939 | pesimismo | 4 |
| 4940 | pescado | 4 |
| 4941 | perspicaz | 4 |
| 4942 | perros | 4 |
| 4943 | perplejidad | 4 |
| 4944 | permanente | 4 |
| 4945 | perecer | 4 |
| 4946 | perdiz | 4 |
| 4947 | pérdida | 4 |
| 4948 | pepito | 4 |
| 4949 | pepa | 4 |
| 4950 | peña | 4 |
| 4951 | penitencia | 4 |
| 4952 | penetrante | 4 |
| 4953 | peludo | 4 |
| 4954 | pellizcar | 4 |
| 4955 | pelar | 4 |
| 4956 | peinador | 4 |
| 4957 | pedrada | 4 |
| 4958 | pedido | 4 |
| 4959 | patriotismo | 4 |
| 4960 | patricio | 4 |
| 4961 | patraña | 4 |
| 4962 | patita | 4 |
| 4963 | patilla | 4 |
| 4964 | patíbulo | 4 |
| 4965 | patas | 4 |
| 4966 | pasmoso | 4 |
| 4967 | pasada | 4 |
| 4968 | partidario | 4 |
| 4969 | participación | 4 |
| 4970 | papelera | 4 |
| 4971 | palpitar | 4 |
| 4972 | palpitación | 4 |
| 4973 | palmo | 4 |
| 4974 | palmetazo | 4 |
| 4975 | palma | 4 |
| 4976 | palidecer | 4 |
| 4977 | paco | 4 |
| 4978 | pachorra | 4 |
| 4979 | otros | 4 |
| 4980 | otorgar | 4 |
| 4981 | osar | 4 |
| 4982 | orillo | 4 |
| 4983 | orilla | 4 |
| 4984 | órgano | 4 |
| 4985 | organizar | 4 |
| 4986 | orador | 4 |
| 4987 | opresión | 4 |
| 4988 | omitir | 4 |
| 4989 | óleo | 4 |
| 4990 | olé | 4 |
| 4991 | ojuelos | 4 |
| 4992 | oíase | 4 |
| 4993 | ofuscar | 4 |
| 4994 | ofendido | 4 |
| 4995 | octubre | 4 |
| 4996 | obstinar | 4 |
| 4997 | obstáculo | 4 |
| 4998 | obsequiar | 4 |
| 4999 | nuez | 4 |
| 5000 | nuevamente | 4 |
| 5001 | normal | 4 |
| 5002 | nodriza | 4 |
| 5003 | niñería | 4 |
| 5004 | niebla | 4 |
| 5005 | neófito | 4 |
| 5006 | negra | 4 |
| 5007 | náusea | 4 |
| 5008 | naturalidad | 4 |
| 5009 | nardo | 4 |
| 5010 | musical | 4 |
| 5011 | muscular | 4 |
| 5012 | mus | 4 |
| 5013 | muletilla | 4 |
| 5014 | mugriento | 4 |
| 5015 | muela | 4 |
| 5016 | mueca | 4 |
| 5017 | mudéjar | 4 |
| 5018 | mu | 4 |
| 5019 | mortificación | 4 |
| 5020 | moribundo | 4 |
| 5021 | moralmente | 4 |
| 5022 | moralidad | 4 |
| 5023 | montaña | 4 |
| 5024 | molinillo | 4 |
| 5025 | mohín | 4 |
| 5026 | mocoso | 4 |
| 5027 | mísero | 4 |
| 5028 | miles | 4 |
| 5029 | miembro | 4 |
| 5030 | mezquino | 4 |
| 5031 | metiose | 4 |
| 5032 | meta | 4 |
| 5033 | merced | 4 |
| 5034 | mentalmente | 4 |
| 5035 | mensual | 4 |
| 5036 | mejoría | 4 |
| 5037 | medias | 4 |
| 5038 | matute | 4 |
| 5039 | masticar | 4 |
| 5040 | marrullería | 4 |
| 5041 | marimorena | 4 |
| 5042 | marea | 4 |
| 5043 | maquinalmente | 4 |
| 5044 | maquinal | 4 |
| 5045 | mañoso | 4 |
| 5046 | mañanita | 4 |
| 5047 | manzana | 4 |
| 5048 | mangar | 4 |
| 5049 | maná | 4 |
| 5050 | mampara | 4 |
| 5051 | maliciar | 4 |
| 5052 | madrugar | 4 |
| 5053 | madero | 4 |
| 5054 | lustroso | 4 |
| 5055 | lucido | 4 |
| 5056 | loza | 4 |
| 5057 | lodo | 4 |
| 5058 | lóbrego | 4 |
| 5059 | llorente | 4 |
| 5060 | llano | 4 |
| 5061 | llamada | 4 |
| 5062 | llamábase | 4 |
| 5063 | liviano | 4 |
| 5064 | libremente | 4 |
| 5065 | liberar | 4 |
| 5066 | les | 4 |
| 5067 | lente | 4 |
| 5068 | lengüetazo | 4 |
| 5069 | legítima | 4 |
| 5070 | lector | 4 |
| 5071 | lechar | 4 |
| 5072 | lavapiés | 4 |
| 5073 | lastimero | 4 |
| 5074 | larga | 4 |
| 5075 | lago | 4 |
| 5076 | juntamente | 4 |
| 5077 | juárez | 4 |
| 5078 | jinete | 4 |
| 5079 | invencible | 4 |
| 5080 | intriga | 4 |
| 5081 | intimar | 4 |
| 5082 | interponer | 4 |
| 5083 | interiormente | 4 |
| 5084 | intenso | 4 |
| 5085 | instar | 4 |
| 5086 | instantáneo | 4 |
| 5087 | insistencia | 4 |
| 5088 | inofensivo | 4 |
| 5089 | ingratitud | 4 |
| 5090 | ingenuo | 4 |
| 5091 | influir | 4 |
| 5092 | inflexión | 4 |
| 5093 | inflar | 4 |
| 5094 | infiel | 4 |
| 5095 | inexperto | 4 |
| 5096 | inerte | 4 |
| 5097 | indigestar | 4 |
| 5098 | independiente | 4 |
| 5099 | indecoroso | 4 |
| 5100 | indagar | 4 |
| 5101 | inconsolable | 4 |
| 5102 | inciso | 4 |
| 5103 | incertidumbre | 4 |
| 5104 | inauguración | 4 |
| 5105 | imperturbable | 4 |
| 5106 | impertinencia | 4 |
| 5107 | imparcialidad | 4 |
| 5108 | igualmente | 4 |
| 5109 | humedecer | 4 |
| 5110 | hortaleza | 4 |
| 5111 | horizontal | 4 |
| 5112 | honradamente | 4 |
| 5113 | homicidio | 4 |
| 5114 | hoguera | 4 |
| 5115 | hipocresía | 4 |
| 5116 | hilaridad | 4 |
| 5117 | hilar | 4 |
| 5118 | hielo | 4 |
| 5119 | hez | 4 |
| 5120 | hermanito | 4 |
| 5121 | hazte | 4 |
| 5122 | hazme | 4 |
| 5123 | haya | 4 |
| 5124 | harto | 4 |
| 5125 | hallazgo | 4 |
| 5126 | halar | 4 |
| 5127 | hágame | 4 |
| 5128 | habíale | 4 |
| 5129 | gusanillo | 4 |
| 5130 | guindilla | 4 |
| 5131 | guardias | 4 |
| 5132 | guardarropa | 4 |
| 5133 | guarda | 4 |
| 5134 | gresca | 4 |
| 5135 | grecia | 4 |
| 5136 | grasa | 4 |
| 5137 | gradar | 4 |
| 5138 | golpear | 4 |
| 5139 | giro | 4 |
| 5140 | gimnasia | 4 |
| 5141 | gesticular | 4 |
| 5142 | gatas | 4 |
| 5143 | garfio | 4 |
| 5144 | ganas | 4 |
| 5145 | galón | 4 |
| 5146 | gallardo | 4 |
| 5147 | galante | 4 |
| 5148 | fugitivo | 4 |
| 5149 | fue | 4 |
| 5150 | frontera | 4 |
| 5151 | fritanga | 4 |
| 5152 | frecuente | 4 |
| 5153 | fraternidad | 4 |
| 5154 | franquear | 4 |
| 5155 | fraile | 4 |
| 5156 | frágil | 4 |
| 5157 | fracaso | 4 |
| 5158 | forro | 4 |
| 5159 | fleco | 4 |
| 5160 | flandes | 4 |
| 5161 | filo | 4 |
| 5162 | fideo | 4 |
| 5163 | ficción | 4 |
| 5164 | fibra | 4 |
| 5165 | fétido | 4 |
| 5166 | ferrolana | 4 |
| 5167 | fernando | 4 |
| 5168 | fermentar | 4 |
| 5169 | felpudo | 4 |
| 5170 | fealdad | 4 |
| 5171 | fatigoso | 4 |
| 5172 | fatiga | 4 |
| 5173 | fatalidad | 4 |
| 5174 | fastidiar | 4 |
| 5175 | fase | 4 |
| 5176 | fantasmón | 4 |
| 5177 | famélico | 4 |
| 5178 | fábula | 4 |
| 5179 | extravío | 4 |
| 5180 | extracto | 4 |
| 5181 | explosión | 4 |
| 5182 | explanar | 4 |
| 5183 | exhalación | 4 |
| 5184 | excusar | 4 |
| 5185 | excluir | 4 |
| 5186 | excelso | 4 |
| 5187 | evidente | 4 |
| 5188 | europeo | 4 |
| 5189 | etapa | 4 |
| 5190 | estrujar | 4 |
| 5191 | estruendo | 4 |
| 5192 | estrepitoso | 4 |
| 5193 | estremecimiento | 4 |
| 5194 | estrafalario | 4 |
| 5195 | estético | 4 |
| 5196 | estanque | 4 |
| 5197 | estamos | 4 |
| 5198 | estafar | 4 |
| 5199 | espontaneidad | 4 |
| 5200 | espeso | 4 |
| 5201 | espesar | 4 |
| 5202 | específico | 4 |
| 5203 | especial | 4 |
| 5204 | espasmódico | 4 |
| 5205 | espartero | 4 |
| 5206 | espacioso | 4 |
| 5207 | esmero | 4 |
| 5208 | esgrimir | 4 |
| 5209 | escultura | 4 |
| 5210 | escrupuloso | 4 |
| 5211 | escritor | 4 |
| 5212 | escondrijo | 4 |
| 5213 | escéptico | 4 |
| 5214 | escarnecer | 4 |
| 5215 | escandaloso | 4 |
| 5216 | escalonar | 4 |
| 5217 | escala | 4 |
| 5218 | escabullir | 4 |
| 5219 | equilibrar | 4 |
| 5220 | entretenimiento | 4 |
| 5221 | entretenido | 4 |
| 5222 | entretanto | 4 |
| 5223 | entremezclar | 4 |
| 5224 | entrega | 4 |
| 5225 | entrecano | 4 |
| 5226 | enternecer | 4 |
| 5227 | ensuciar | 4 |
| 5228 | ensayo | 4 |
| 5229 | enojoso | 4 |
| 5230 | enmienda | 4 |
| 5231 | enlazar | 4 |
| 5232 | engranar | 4 |
| 5233 | engordar | 4 |
| 5234 | engolosinar | 4 |
| 5235 | enfrenar | 4 |
| 5236 | endiablado | 4 |
| 5237 | encubridor | 4 |
| 5238 | encariñar | 4 |
| 5239 | encaje | 4 |
| 5240 | enano | 4 |
| 5241 | empuñar | 4 |
| 5242 | emperador | 4 |
| 5243 | empeñado | 4 |
| 5244 | embriaguez | 4 |
| 5245 | embozo | 4 |
| 5246 | embestir | 4 |
| 5247 | embarullar | 4 |
| 5248 | embarazar | 4 |
| 5249 | durmiente | 4 |
| 5250 | dotar | 4 |
| 5251 | dorotea | 4 |
| 5252 | donnell | 4 |
| 5253 | documento | 4 |
| 5254 | doctrinar | 4 |
| 5255 | doble | 4 |
| 5256 | divorcio | 4 |
| 5257 | diversión | 4 |
| 5258 | distante | 4 |
| 5259 | displicencia | 4 |
| 5260 | disfrazar | 4 |
| 5261 | discretamente | 4 |
| 5262 | disciplinar | 4 |
| 5263 | directo | 4 |
| 5264 | diplomacia | 4 |
| 5265 | diligente | 4 |
| 5266 | dicen | 4 |
| 5267 | dialéctica | 4 |
| 5268 | diabólico | 4 |
| 5269 | detúvose | 4 |
| 5270 | desvelado | 4 |
| 5271 | destapar | 4 |
| 5272 | despropósito | 4 |
| 5273 | desplumar | 4 |
| 5274 | despierto | 4 |
| 5275 | despechar | 4 |
| 5276 | despavorir | 4 |
| 5277 | desordenado | 4 |
| 5278 | desmejorar | 4 |
| 5279 | desmedrar | 4 |
| 5280 | desmedido | 4 |
| 5281 | desmandar | 4 |
| 5282 | designar | 4 |
| 5283 | deshora | 4 |
| 5284 | deshilachar | 4 |
| 5285 | desgraciadamente | 4 |
| 5286 | desgarrar | 4 |
| 5287 | desembuchar | 4 |
| 5288 | desdicha | 4 |
| 5289 | descuide | 4 |
| 5290 | descuartizar | 4 |
| 5291 | descontentar | 4 |
| 5292 | desconfiar | 4 |
| 5293 | desconfianza | 4 |
| 5294 | desconcierto | 4 |
| 5295 | descarriar | 4 |
| 5296 | descarado | 4 |
| 5297 | desarrollo | 4 |
| 5298 | desarmar | 4 |
| 5299 | desanimar | 4 |
| 5300 | desalentar | 4 |
| 5301 | desairado | 4 |
| 5302 | derivativo | 4 |
| 5303 | dengoso | 4 |
| 5304 | demente | 4 |
| 5305 | dementar | 4 |
| 5306 | dejose | 4 |
| 5307 | dejarla | 4 |
| 5308 | deducir | 4 |
| 5309 | decoroso | 4 |
| 5310 | decaer | 4 |
| 5311 | debate | 4 |
| 5312 | danzante | 4 |
| 5313 | dámaso | 4 |
| 5314 | dábale | 4 |
| 5315 | curita | 4 |
| 5316 | cuestionar | 4 |
| 5317 | cuchufleta | 4 |
| 5318 | cuchilleros | 4 |
| 5319 | cuchicheo | 4 |
| 5320 | cuadrito | 4 |
| 5321 | crueldad | 4 |
| 5322 | crucificar | 4 |
| 5323 | crónico | 4 |
| 5324 | crin | 4 |
| 5325 | cotorrear | 4 |
| 5326 | costado | 4 |
| 5327 | costa | 4 |
| 5328 | corteza | 4 |
| 5329 | corrido | 4 |
| 5330 | correos | 4 |
| 5331 | corpus | 4 |
| 5332 | corazonada | 4 |
| 5333 | copla | 4 |
| 5334 | coñac | 4 |
| 5335 | conyugal | 4 |
| 5336 | contundente | 4 |
| 5337 | contratar | 4 |
| 5338 | contrastar | 4 |
| 5339 | contrariar | 4 |
| 5340 | contracción | 4 |
| 5341 | contemplación | 4 |
| 5342 | contante | 4 |
| 5343 | contado | 4 |
| 5344 | consumado | 4 |
| 5345 | consternar | 4 |
| 5346 | consternación | 4 |
| 5347 | consolidar | 4 |
| 5348 | consejero | 4 |
| 5349 | consecuente | 4 |
| 5350 | conjunción | 4 |
| 5351 | confianzudo | 4 |
| 5352 | confeccionar | 4 |
| 5353 | conejo | 4 |
| 5354 | conclusión | 4 |
| 5355 | concierto | 4 |
| 5356 | complicado | 4 |
| 5357 | compensar | 4 |
| 5358 | compaginar | 4 |
| 5359 | comestible | 4 |
| 5360 | comensal | 4 |
| 5361 | coma | 4 |
| 5362 | colosal | 4 |
| 5363 | coloquio | 4 |
| 5364 | colonia | 4 |
| 5365 | coleta | 4 |
| 5366 | col | 4 |
| 5367 | cojín | 4 |
| 5368 | cochinada | 4 |
| 5369 | cobranza | 4 |
| 5370 | clero | 4 |
| 5371 | clamar | 4 |
| 5372 | chistera | 4 |
| 5373 | chisme | 4 |
| 5374 | chiquillada | 4 |
| 5375 | chiquilla | 4 |
| 5376 | chinita | 4 |
| 5377 | chicos | 4 |
| 5378 | charco | 4 |
| 5379 | chal | 4 |
| 5380 | chacota | 4 |
| 5381 | cerrada | 4 |
| 5382 | cerciorar | 4 |
| 5383 | cercano | 4 |
| 5384 | cejar | 4 |
| 5385 | cebada | 4 |
| 5386 | cavernoso | 4 |
| 5387 | caverna | 4 |
| 5388 | cautela | 4 |
| 5389 | cátedra | 4 |
| 5390 | catecismo | 4 |
| 5391 | catalán | 4 |
| 5392 | casero | 4 |
| 5393 | cascar | 4 |
| 5394 | casarse | 4 |
| 5395 | casarredonda | 4 |
| 5396 | carretilla | 4 |
| 5397 | carnero | 4 |
| 5398 | carga | 4 |
| 5399 | carbonero | 4 |
| 5400 | caracol | 4 |
| 5401 | capcioso | 4 |
| 5402 | cañizares | 4 |
| 5403 | cantor | 4 |
| 5404 | cantinela | 4 |
| 5405 | cantería | 4 |
| 5406 | cantera | 4 |
| 5407 | canonizar | 4 |
| 5408 | candoroso | 4 |
| 5409 | canalla | 4 |
| 5410 | campechano | 4 |
| 5411 | camorra | 4 |
| 5412 | caminar | 4 |
| 5413 | callosar | 4 |
| 5414 | callejero | 4 |
| 5415 | calixta | 4 |
| 5416 | calavera | 4 |
| 5417 | cal | 4 |
| 5418 | cadena | 4 |
| 5419 | burrada | 4 |
| 5420 | bromazo | 4 |
| 5421 | bringas | 4 |
| 5422 | botonar | 4 |
| 5423 | botijo | 4 |
| 5424 | bostezo | 4 |
| 5425 | borroso | 4 |
| 5426 | bolsín | 4 |
| 5427 | blanquear | 4 |
| 5428 | bizcar | 4 |
| 5429 | bilis | 4 |
| 5430 | bicho | 4 |
| 5431 | biberón | 4 |
| 5432 | biarritz | 4 |
| 5433 | besugo | 4 |
| 5434 | bazo | 4 |
| 5435 | bautismo | 4 |
| 5436 | barreño | 4 |
| 5437 | baratija | 4 |
| 5438 | banda | 4 |
| 5439 | azahar | 4 |
| 5440 | ayunas | 4 |
| 5441 | ayunar | 4 |
| 5442 | aviado | 4 |
| 5443 | aversión | 4 |
| 5444 | avaricia | 4 |
| 5445 | austria | 4 |
| 5446 | augusto | 4 |
| 5447 | auditorio | 4 |
| 5448 | audacia | 4 |
| 5449 | aturdido | 4 |
| 5450 | atrozmente | 4 |
| 5451 | atavío | 4 |
| 5452 | ataúd | 4 |
| 5453 | aspiración | 4 |
| 5454 | asimilación | 4 |
| 5455 | asentir | 4 |
| 5456 | ascendiente | 4 |
| 5457 | artificial | 4 |
| 5458 | arrepentido | 4 |
| 5459 | arrechucho | 4 |
| 5460 | arrebato | 4 |
| 5461 | arrebatar | 4 |
| 5462 | arrastrado | 4 |
| 5463 | armonizar | 4 |
| 5464 | argumentar | 4 |
| 5465 | argumentación | 4 |
| 5466 | arenal | 4 |
| 5467 | apurado | 4 |
| 5468 | apuntó | 4 |
| 5469 | aproximación | 4 |
| 5470 | apropiar | 4 |
| 5471 | apoyo | 4 |
| 5472 | apostolado | 4 |
| 5473 | aportar | 4 |
| 5474 | aporrear | 4 |
| 5475 | apatía | 4 |
| 5476 | apacible | 4 |
| 5477 | añadidura | 4 |
| 5478 | anuncio | 4 |
| 5479 | anular | 4 |
| 5480 | antón | 4 |
| 5481 | angustiar | 4 |
| 5482 | angostar | 4 |
| 5483 | anécdota | 4 |
| 5484 | andrajo | 4 |
| 5485 | anchas | 4 |
| 5486 | anatema | 4 |
| 5487 | anaquelería | 4 |
| 5488 | amplitud | 4 |
| 5489 | amonestación | 4 |
| 5490 | americano | 4 |
| 5491 | ambulante | 4 |
| 5492 | ambición | 4 |
| 5493 | amansar | 4 |
| 5494 | amaneramiento | 4 |
| 5495 | amadeo | 4 |
| 5496 | alucinación | 4 |
| 5497 | almendra | 4 |
| 5498 | alabardero | 4 |
| 5499 | ajustado | 4 |
| 5500 | ajuar | 4 |
| 5501 | ajo | 4 |
| 5502 | ajetreo | 4 |
| 5503 | ahumar | 4 |
| 5504 | ahuecar | 4 |
| 5505 | ahorrar | 4 |
| 5506 | ahínco | 4 |
| 5507 | aguzar | 4 |
| 5508 | agujerito | 4 |
| 5509 | aguador | 4 |
| 5510 | agravio | 4 |
| 5511 | afrentar | 4 |
| 5512 | afirmó | 4 |
| 5513 | afabilidad | 4 |
| 5514 | adusto | 4 |
| 5515 | adulterar | 4 |
| 5516 | aduana | 4 |
| 5517 | adrede | 4 |
| 5518 | adorno | 4 |
| 5519 | actor | 4 |
| 5520 | activo | 4 |
| 5521 | aciago | 4 |
| 5522 | acantonar | 4 |
| 5523 | acalorado | 4 |
| 5524 | acallar | 4 |
| 5525 | absorto | 4 |
| 5526 | absorber | 4 |
| 5527 | abrumador | 4 |
| 5528 | abril | 4 |
| 5529 | abandonado | 4 |
| 5530 | abalanzar | 4 |
| 5531 | zarpa | 3 |
| 5532 | zapatón | 3 |
| 5533 | zángano | 3 |
| 5534 | zanca | 3 |
| 5535 | vulgarmente | 3 |
| 5536 | vuestra | 3 |
| 5537 | volviose | 3 |
| 5538 | volveré | 3 |
| 5539 | volumen | 3 |
| 5540 | vive | 3 |
| 5541 | vivaracho | 3 |
| 5542 | vitoria | 3 |
| 5543 | víspera | 3 |
| 5544 | viso | 3 |
| 5545 | visiblemente | 3 |
| 5546 | vio | 3 |
| 5547 | vínculo | 3 |
| 5548 | vinagre | 3 |
| 5549 | vigoroso | 3 |
| 5550 | vigorizar | 3 |
| 5551 | vigor | 3 |
| 5552 | vibrar | 3 |
| 5553 | viajero | 3 |
| 5554 | veterano | 3 |
| 5555 | vestigio | 3 |
| 5556 | verla | 3 |
| 5557 | verídicamente | 3 |
| 5558 | vereda | 3 |
| 5559 | vente | 3 |
| 5560 | ventar | 3 |
| 5561 | venida | 3 |
| 5562 | venerar | 3 |
| 5563 | vencido | 3 |
| 5564 | velón | 3 |
| 5565 | vello | 3 |
| 5566 | veis | 3 |
| 5567 | veintitrés | 3 |
| 5568 | veintisiete | 3 |
| 5569 | veinticuatro | 3 |
| 5570 | vehículo | 3 |
| 5571 | vehemencia | 3 |
| 5572 | véase | 3 |
| 5573 | vea | 3 |
| 5574 | varar | 3 |
| 5575 | valioso | 3 |
| 5576 | valientes | 3 |
| 5577 | valeriano | 3 |
| 5578 | vagón | 3 |
| 5579 | vacante | 3 |
| 5580 | uy | 3 |
| 5581 | usual | 3 |
| 5582 | usado | 3 |
| 5583 | universo | 3 |
| 5584 | universidad | 3 |
| 5585 | tumbar | 3 |
| 5586 | tufillo | 3 |
| 5587 | trote | 3 |
| 5588 | trono | 3 |
| 5589 | trofeo | 3 |
| 5590 | triunfal | 3 |
| 5591 | trinidad | 3 |
| 5592 | trimestre | 3 |
| 5593 | tributar | 3 |
| 5594 | tribulación | 3 |
| 5595 | tresillo | 3 |
| 5596 | trepidación | 3 |
| 5597 | tratante | 3 |
| 5598 | trastornado | 3 |
| 5599 | trastienda | 3 |
| 5600 | trastear | 3 |
| 5601 | trapisondista | 3 |
| 5602 | transparencia | 3 |
| 5603 | trámite | 3 |
| 5604 | tramar | 3 |
| 5605 | tragaderas | 3 |
| 5606 | tráfico | 3 |
| 5607 | tráete | 3 |
| 5608 | traducir | 3 |
| 5609 | trabajillo | 3 |
| 5610 | tortilla | 3 |
| 5611 | toros | 3 |
| 5612 | tome | 3 |
| 5613 | tomate | 3 |
| 5614 | toledano | 3 |
| 5615 | tiznar | 3 |
| 5616 | tisis | 3 |
| 5617 | tinte | 3 |
| 5618 | timbre | 3 |
| 5619 | tila | 3 |
| 5620 | tijera | 3 |
| 5621 | tifus | 3 |
| 5622 | tie | 3 |
| 5623 | tetuán | 3 |
| 5624 | tesis | 3 |
| 5625 | terrorífico | 3 |
| 5626 | terquedad | 3 |
| 5627 | terno | 3 |
| 5628 | terco | 3 |
| 5629 | tenducho | 3 |
| 5630 | tenacidad | 3 |
| 5631 | ten | 3 |
| 5632 | temporal | 3 |
| 5633 | tempestuoso | 3 |
| 5634 | telegrafiar | 3 |
| 5635 | tejido | 3 |
| 5636 | teja | 3 |
| 5637 | teclear | 3 |
| 5638 | tasar | 3 |
| 5639 | tasa | 3 |
| 5640 | tartán | 3 |
| 5641 | tantear | 3 |
| 5642 | talco | 3 |
| 5643 | talante | 3 |
| 5644 | tácito | 3 |
| 5645 | tabaco | 3 |
| 5646 | t | 3 |
| 5647 | susurrar | 3 |
| 5648 | sustituir | 3 |
| 5649 | suspenso | 3 |
| 5650 | supremo | 3 |
| 5651 | suposición | 3 |
| 5652 | suficiente | 3 |
| 5653 | suéltame | 3 |
| 5654 | subsistir | 3 |
| 5655 | subordinación | 3 |
| 5656 | subasta | 3 |
| 5657 | subalterno | 3 |
| 5658 | sótano | 3 |
| 5659 | sosiego | 3 |
| 5660 | sosiégate | 3 |
| 5661 | sortija | 3 |
| 5662 | soportal | 3 |
| 5663 | soplo | 3 |
| 5664 | sopar | 3 |
| 5665 | soñoliento | 3 |
| 5666 | sonrosado | 3 |
| 5667 | sondear | 3 |
| 5668 | sonda | 3 |
| 5669 | soltera | 3 |
| 5670 | solomillo | 3 |
| 5671 | sollozar | 3 |
| 5672 | solitaria | 3 |
| 5673 | soga | 3 |
| 5674 | sofisma | 3 |
| 5675 | socorrido | 3 |
| 5676 | socarrón | 3 |
| 5677 | sobriedad | 3 |
| 5678 | sobresalto | 3 |
| 5679 | sobar | 3 |
| 5680 | sintético | 3 |
| 5681 | singularmente | 3 |
| 5682 | singapore | 3 |
| 5683 | sigüenza | 3 |
| 5684 | sesudo | 3 |
| 5685 | serpiente | 3 |
| 5686 | sepultura | 3 |
| 5687 | septiembre | 3 |
| 5688 | señores | 3 |
| 5689 | señá | 3 |
| 5690 | sentencia | 3 |
| 5691 | sellar | 3 |
| 5692 | selecto | 3 |
| 5693 | seguimiento | 3 |
| 5694 | segar | 3 |
| 5695 | seducción | 3 |
| 5696 | secuestrador | 3 |
| 5697 | savia | 3 |
| 5698 | sartén | 3 |
| 5699 | sarcástico | 3 |
| 5700 | sarao | 3 |
| 5701 | sarampión | 3 |
| 5702 | saña | 3 |
| 5703 | sandez | 3 |
| 5704 | sándalo | 3 |
| 5705 | sánchez | 3 |
| 5706 | samaniega | 3 |
| 5707 | salvador | 3 |
| 5708 | saludable | 3 |
| 5709 | salpicar | 3 |
| 5710 | saldar | 3 |
| 5711 | saeta | 3 |
| 5712 | sacramentos | 3 |
| 5713 | saben | 3 |
| 5714 | rústico | 3 |
| 5715 | rusia | 3 |
| 5716 | rugir | 3 |
| 5717 | ruda | 3 |
| 5718 | rozar | 3 |
| 5719 | roñoso | 3 |
| 5720 | ron | 3 |
| 5721 | romero | 3 |
| 5722 | roma | 3 |
| 5723 | roca | 3 |
| 5724 | rizar | 3 |
| 5725 | rivalidad | 3 |
| 5726 | ritmo | 3 |
| 5727 | riguroso | 3 |
| 5728 | rifar | 3 |
| 5729 | riego | 3 |
| 5730 | ridiculizar | 3 |
| 5731 | rezongar | 3 |
| 5732 | revolotear | 3 |
| 5733 | rever | 3 |
| 5734 | reventón | 3 |
| 5735 | revancha | 3 |
| 5736 | reuma | 3 |
| 5737 | retórica | 3 |
| 5738 | retirado | 3 |
| 5739 | resurrección | 3 |
| 5740 | resueltamente | 3 |
| 5741 | restaurar | 3 |
| 5742 | resquicio | 3 |
| 5743 | respondía | 3 |
| 5744 | resplandeciente | 3 |
| 5745 | respiro | 3 |
| 5746 | resollar | 3 |
| 5747 | resobar | 3 |
| 5748 | resignación | 3 |
| 5749 | resguardar | 3 |
| 5750 | reputar | 3 |
| 5751 | reprimenda | 3 |
| 5752 | reposar | 3 |
| 5753 | repito | 3 |
| 5754 | repicar | 3 |
| 5755 | repetido | 3 |
| 5756 | reoyos | 3 |
| 5757 | remover | 3 |
| 5758 | remojo | 3 |
| 5759 | remitir | 3 |
| 5760 | remilgo | 3 |
| 5761 | remate | 3 |
| 5762 | relieve | 3 |
| 5763 | rejilla | 3 |
| 5764 | reiterar | 3 |
| 5765 | rehusar | 3 |
| 5766 | regularmente | 3 |
| 5767 | reglar | 3 |
| 5768 | reglamento | 3 |
| 5769 | regimiento | 3 |
| 5770 | regeneración | 3 |
| 5771 | regar | 3 |
| 5772 | regañón | 3 |
| 5773 | regaliz | 3 |
| 5774 | refrán | 3 |
| 5775 | refinar | 3 |
| 5776 | redoblar | 3 |
| 5777 | recreo | 3 |
| 5778 | reconcentrar | 3 |
| 5779 | recogimiento | 3 |
| 5780 | recinto | 3 |
| 5781 | recato | 3 |
| 5782 | rebuscar | 3 |
| 5783 | rebotica | 3 |
| 5784 | rebelar | 3 |
| 5785 | reanudar | 3 |
| 5786 | rata | 3 |
| 5787 | raso | 3 |
| 5788 | rareza | 3 |
| 5789 | rapar | 3 |
| 5790 | ramoncita | 3 |
| 5791 | ramaje | 3 |
| 5792 | ralo | 3 |
| 5793 | racionar | 3 |
| 5794 | racional | 3 |
| 5795 | ración | 3 |
| 5796 | quítese | 3 |
| 5797 | quintal | 3 |
| 5798 | quinta | 3 |
| 5799 | quijote | 3 |
| 5800 | quiebro | 3 |
| 5801 | queso | 3 |
| 5802 | quelo | 3 |
| 5803 | quédate | 3 |
| 5804 | quedamos | 3 |
| 5805 | quedábase | 3 |
| 5806 | pupila | 3 |
| 5807 | puñetazo | 3 |
| 5808 | puñados | 3 |
| 5809 | puntualmente | 3 |
| 5810 | puntapié | 3 |
| 5811 | pulverizar | 3 |
| 5812 | pulsar | 3 |
| 5813 | pulir | 3 |
| 5814 | pulcritud | 3 |
| 5815 | puerco | 3 |
| 5816 | puente | 3 |
| 5817 | pudor | 3 |
| 5818 | púa | 3 |
| 5819 | prusiano | 3 |
| 5820 | proyectil | 3 |
| 5821 | provisto | 3 |
| 5822 | proveer | 3 |
| 5823 | prórroga | 3 |
| 5824 | propagandista | 3 |
| 5825 | pronunciamiento | 3 |
| 5826 | profetizar | 3 |
| 5827 | proceso | 3 |
| 5828 | probabilidad | 3 |
| 5829 | pringar | 3 |
| 5830 | principios | 3 |
| 5831 | primoroso | 3 |
| 5832 | previsión | 3 |
| 5833 | pretextar | 3 |
| 5834 | presumido | 3 |
| 5835 | presidir | 3 |
| 5836 | presentose | 3 |
| 5837 | preferencia | 3 |
| 5838 | precipitadamente | 3 |
| 5839 | postración | 3 |
| 5840 | postizo | 3 |
| 5841 | posibilidad | 3 |
| 5842 | posesionar | 3 |
| 5843 | portezuela | 3 |
| 5844 | poro | 3 |
| 5845 | porción | 3 |
| 5846 | ponte | 3 |
| 5847 | polvoriento | 3 |
| 5848 | polémica | 3 |
| 5849 | podría | 3 |
| 5850 | podrá | 3 |
| 5851 | podar | 3 |
| 5852 | pobrecillo | 3 |
| 5853 | platerías | 3 |
| 5854 | plañidero | 3 |
| 5855 | pitar | 3 |
| 5856 | pistola | 3 |
| 5857 | pío | 3 |
| 5858 | pesimista | 3 |
| 5859 | pervertir | 3 |
| 5860 | persuasión | 3 |
| 5861 | perspicacia | 3 |
| 5862 | persignar | 3 |
| 5863 | perrito | 3 |
| 5864 | perrera | 3 |
| 5865 | perpetuo | 3 |
| 5866 | perjuicio | 3 |
| 5867 | periodista | 3 |
| 5868 | perfume | 3 |
| 5869 | pérfido | 3 |
| 5870 | perfeccionar | 3 |
| 5871 | peregrino | 3 |
| 5872 | perdónala | 3 |
| 5873 | perdona | 3 |
| 5874 | pera | 3 |
| 5875 | pentecostés | 3 |
| 5876 | penitenciario | 3 |
| 5877 | penales | 3 |
| 5878 | peluquería | 3 |
| 5879 | peluca | 3 |
| 5880 | pelmazo | 3 |
| 5881 | peligrar | 3 |
| 5882 | peines | 3 |
| 5883 | peinado | 3 |
| 5884 | pegote | 3 |
| 5885 | pegadizo | 3 |
| 5886 | pechuga | 3 |
| 5887 | pavía | 3 |
| 5888 | pausar | 3 |
| 5889 | pausadamente | 3 |
| 5890 | patrona | 3 |
| 5891 | patrón | 3 |
| 5892 | patochada | 3 |
| 5893 | pataleo | 3 |
| 5894 | patalear | 3 |
| 5895 | pastel | 3 |
| 5896 | pastar | 3 |
| 5897 | pasmarote | 3 |
| 5898 | pascuas | 3 |
| 5899 | pasaba | 3 |
| 5900 | parto | 3 |
| 5901 | parisiense | 3 |
| 5902 | parentela | 3 |
| 5903 | pareciole | 3 |
| 5904 | paralela | 3 |
| 5905 | paraguas | 3 |
| 5906 | paradójico | 3 |
| 5907 | papelista | 3 |
| 5908 | palmotear | 3 |
| 5909 | palmada | 3 |
| 5910 | palanca | 3 |
| 5911 | paladar | 3 |
| 5912 | ovillo | 3 |
| 5913 | ostra | 3 |
| 5914 | ostentación | 3 |
| 5915 | oscurecer | 3 |
| 5916 | orquesta | 3 |
| 5917 | oriundo | 3 |
| 5918 | orgía | 3 |
| 5919 | organización | 3 |
| 5920 | orgánico | 3 |
| 5921 | optimismo | 3 |
| 5922 | oloroso | 3 |
| 5923 | olorcillo | 3 |
| 5924 | olfatorio | 3 |
| 5925 | ojeroso | 3 |
| 5926 | ojera | 3 |
| 5927 | ojal | 3 |
| 5928 | oficioso | 3 |
| 5929 | oferta | 3 |
| 5930 | ocurriósele | 3 |
| 5931 | ocurriole | 3 |
| 5932 | ociosidad | 3 |
| 5933 | ochavo | 3 |
| 5934 | obstrucción | 3 |
| 5935 | objetar | 3 |
| 5936 | nudillo | 3 |
| 5937 | nubes | 3 |
| 5938 | noviembre | 3 |
| 5939 | novena | 3 |
| 5940 | novelesco | 3 |
| 5941 | novelda | 3 |
| 5942 | notorio | 3 |
| 5943 | non | 3 |
| 5944 | nocturno | 3 |
| 5945 | niña | 3 |
| 5946 | nicolasa | 3 |
| 5947 | neurosis | 3 |
| 5948 | negrito | 3 |
| 5949 | negociar | 3 |
| 5950 | negociante | 3 |
| 5951 | necio | 3 |
| 5952 | náufrago | 3 |
| 5953 | naturalista | 3 |
| 5954 | nativo | 3 |
| 5955 | nasal | 3 |
| 5956 | narrar | 3 |
| 5957 | naranjo | 3 |
| 5958 | nacido | 3 |
| 5959 | mutuo | 3 |
| 5960 | muslo | 3 |
| 5961 | musgo | 3 |
| 5962 | museo | 3 |
| 5963 | murillo | 3 |
| 5964 | multiplicar | 3 |
| 5965 | muladar | 3 |
| 5966 | movida | 3 |
| 5967 | morros | 3 |
| 5968 | morro | 3 |
| 5969 | morrión | 3 |
| 5970 | moros | 3 |
| 5971 | morisqueta | 3 |
| 5972 | moriones | 3 |
| 5973 | morejón | 3 |
| 5974 | morado | 3 |
| 5975 | morada | 3 |
| 5976 | monstruosidad | 3 |
| 5977 | monserga | 3 |
| 5978 | monopolizar | 3 |
| 5979 | momia | 3 |
| 5980 | momentito | 3 |
| 5981 | molido | 3 |
| 5982 | mocedad | 3 |
| 5983 | misterios | 3 |
| 5984 | mismísimo | 3 |
| 5985 | mis | 3 |
| 5986 | miramiento | 3 |
| 5987 | mírame | 3 |
| 5988 | minutar | 3 |
| 5989 | minucioso | 3 |
| 5990 | minuciosamente | 3 |
| 5991 | miente | 3 |
| 5992 | método | 3 |
| 5993 | metódico | 3 |
| 5994 | metida | 3 |
| 5995 | mermar | 3 |
| 5996 | mercurio | 3 |
| 5997 | mercachifle | 3 |
| 5998 | menudear | 3 |
| 5999 | mentiroso | 3 |
| 6000 | mensaje | 3 |
| 6001 | menestral | 3 |
| 6002 | meneo | 3 |
| 6003 | mendicidad | 3 |
| 6004 | melindre | 3 |
| 6005 | melchor | 3 |
| 6006 | médicis | 3 |
| 6007 | mediante | 3 |
| 6008 | mechero | 3 |
| 6009 | mazar | 3 |
| 6010 | matritense | 3 |
| 6011 | matorral | 3 |
| 6012 | matadero | 3 |
| 6013 | masón | 3 |
| 6014 | martirizar | 3 |
| 6015 | martín | 3 |
| 6016 | marianas | 3 |
| 6017 | mareo | 3 |
| 6018 | mareado | 3 |
| 6019 | marcial | 3 |
| 6020 | marcado | 3 |
| 6021 | manzanares | 3 |
| 6022 | manubrio | 3 |
| 6023 | manteca | 3 |
| 6024 | mansedumbre | 3 |
| 6025 | manotear | 3 |
| 6026 | manotazo | 3 |
| 6027 | maniquí | 3 |
| 6028 | mandil | 3 |
| 6029 | mandarín | 3 |
| 6030 | mancebo | 3 |
| 6031 | manceba | 3 |
| 6032 | malsano | 3 |
| 6033 | malograr | 3 |
| 6034 | malísimo | 3 |
| 6035 | maligno | 3 |
| 6036 | maleza | 3 |
| 6037 | majestuoso | 3 |
| 6038 | maja | 3 |
| 6039 | magra | 3 |
| 6040 | mágico | 3 |
| 6041 | madriz | 3 |
| 6042 | madriguera | 3 |
| 6043 | madeja | 3 |
| 6044 | macho | 3 |
| 6045 | lujoso | 3 |
| 6046 | locuaz | 3 |
| 6047 | lluvia | 3 |
| 6048 | lloro | 3 |
| 6049 | lloriquear | 3 |
| 6050 | llegó | 3 |
| 6051 | llamole | 3 |
| 6052 | literatura | 3 |
| 6053 | listar | 3 |
| 6054 | lisonja | 3 |
| 6055 | lindar | 3 |
| 6056 | ligereza | 3 |
| 6057 | ligar | 3 |
| 6058 | librería | 3 |
| 6059 | libertino | 3 |
| 6060 | libertar | 3 |
| 6061 | leyenda | 3 |
| 6062 | leopardi | 3 |
| 6063 | legalidad | 3 |
| 6064 | lazar | 3 |
| 6065 | láudano | 3 |
| 6066 | latitud | 3 |
| 6067 | latir | 3 |
| 6068 | lárgate | 3 |
| 6069 | lamento | 3 |
| 6070 | lacayo | 3 |
| 6071 | labrado | 3 |
| 6072 | jurisdicción | 3 |
| 6073 | juramento | 3 |
| 6074 | jugador | 3 |
| 6075 | judas | 3 |
| 6076 | jubilar | 3 |
| 6077 | juana | 3 |
| 6078 | jovialidad | 3 |
| 6079 | jergón | 3 |
| 6080 | jarras | 3 |
| 6081 | jamón | 3 |
| 6082 | jaime | 3 |
| 6083 | jadeante | 3 |
| 6084 | jacintilla | 3 |
| 6085 | italiano | 3 |
| 6086 | isabelita | 3 |
| 6087 | irritación | 3 |
| 6088 | irregularidad | 3 |
| 6089 | irregular | 3 |
| 6090 | iré | 3 |
| 6091 | invitación | 3 |
| 6092 | inválido | 3 |
| 6093 | intranquilidad | 3 |
| 6094 | íntimamente | 3 |
| 6095 | interrupción | 3 |
| 6096 | interminable | 3 |
| 6097 | interesantísimo | 3 |
| 6098 | interceder | 3 |
| 6099 | intelectual | 3 |
| 6100 | intacto | 3 |
| 6101 | intachable | 3 |
| 6102 | insufrible | 3 |
| 6103 | insubordinar | 3 |
| 6104 | instructivo | 3 |
| 6105 | institutriz | 3 |
| 6106 | instituto | 3 |
| 6107 | instintivamente | 3 |
| 6108 | insomnio | 3 |
| 6109 | insignia | 3 |
| 6110 | insensiblemente | 3 |
| 6111 | inocentón | 3 |
| 6112 | innato | 3 |
| 6113 | inmutar | 3 |
| 6114 | inmundo | 3 |
| 6115 | inmundicia | 3 |
| 6116 | inmueble | 3 |
| 6117 | inmemorial | 3 |
| 6118 | injusticia | 3 |
| 6119 | injuriar | 3 |
| 6120 | ininteligible | 3 |
| 6121 | ingeniero | 3 |
| 6122 | infracción | 3 |
| 6123 | infortunado | 3 |
| 6124 | informe | 3 |
| 6125 | influencia | 3 |
| 6126 | inflexible | 3 |
| 6127 | inflamar | 3 |
| 6128 | infinitamente | 3 |
| 6129 | inferioridad | 3 |
| 6130 | inevitable | 3 |
| 6131 | inesperadamente | 3 |
| 6132 | inequívoco | 3 |
| 6133 | inducir | 3 |
| 6134 | indolencia | 3 |
| 6135 | indino | 3 |
| 6136 | indefinible | 3 |
| 6137 | incurrir | 3 |
| 6138 | incumbencia | 3 |
| 6139 | incorporose | 3 |
| 6140 | incomprensible | 3 |
| 6141 | incomparable | 3 |
| 6142 | inclinose | 3 |
| 6143 | incitar | 3 |
| 6144 | incautar | 3 |
| 6145 | inapreciable | 3 |
| 6146 | imprudente | 3 |
| 6147 | impotente | 3 |
| 6148 | imposibilitar | 3 |
| 6149 | imposibilidad | 3 |
| 6150 | impetuoso | 3 |
| 6151 | imperdible | 3 |
| 6152 | imbécil | 3 |
| 6153 | iluminado | 3 |
| 6154 | ildefonso | 3 |
| 6155 | ignorante | 3 |
| 6156 | iglesias | 3 |
| 6157 | idolatría | 3 |
| 6158 | idioma | 3 |
| 6159 | iba | 3 |
| 6160 | humillación | 3 |
| 6161 | huella | 3 |
| 6162 | horrendo | 3 |
| 6163 | honda | 3 |
| 6164 | hombruno | 3 |
| 6165 | hízolo | 3 |
| 6166 | hinchazón | 3 |
| 6167 | hijos | 3 |
| 6168 | hijas | 3 |
| 6169 | herramienta | 3 |
| 6170 | heroísmo | 3 |
| 6171 | herido | 3 |
| 6172 | helada | 3 |
| 6173 | hebilla | 3 |
| 6174 | hato | 3 |
| 6175 | hastiar | 3 |
| 6176 | haragán | 3 |
| 6177 | hágase | 3 |
| 6178 | habría | 3 |
| 6179 | habló | 3 |
| 6180 | hablando | 3 |
| 6181 | habladuría | 3 |
| 6182 | habitual | 3 |
| 6183 | habana | 3 |
| 6184 | gustoso | 3 |
| 6185 | gustavito | 3 |
| 6186 | guisante | 3 |
| 6187 | guijarro | 3 |
| 6188 | guedeja | 3 |
| 6189 | gritería | 3 |
| 6190 | grillete | 3 |
| 6191 | grifo | 3 |
| 6192 | granito | 3 |
| 6193 | grandón | 3 |
| 6194 | granar | 3 |
| 6195 | grabar | 3 |
| 6196 | gotita | 3 |
| 6197 | golpecito | 3 |
| 6198 | globo | 3 |
| 6199 | geografía | 3 |
| 6200 | generalmente | 3 |
| 6201 | generala | 3 |
| 6202 | generación | 3 |
| 6203 | gatera | 3 |
| 6204 | garrotillo | 3 |
| 6205 | gargarismo | 3 |
| 6206 | garcía | 3 |
| 6207 | fundamento | 3 |
| 6208 | fundamental | 3 |
| 6209 | funciones | 3 |
| 6210 | fulano | 3 |
| 6211 | fuga | 3 |
| 6212 | frutar | 3 |
| 6213 | fruncido | 3 |
| 6214 | frugal | 3 |
| 6215 | fraude | 3 |
| 6216 | fragua | 3 |
| 6217 | fraga | 3 |
| 6218 | fotografía | 3 |
| 6219 | forzado | 3 |
| 6220 | fogoso | 3 |
| 6221 | flexible | 3 |
| 6222 | flechar | 3 |
| 6223 | flecha | 3 |
| 6224 | flaquear | 3 |
| 6225 | flamante | 3 |
| 6226 | físicamente | 3 |
| 6227 | firmeza | 3 |
| 6228 | fingido | 3 |
| 6229 | filtrar | 3 |
| 6230 | filípica | 3 |
| 6231 | filantrópico | 3 |
| 6232 | figuración | 3 |
| 6233 | figueras | 3 |
| 6234 | fervor | 3 |
| 6235 | felizmente | 3 |
| 6236 | fecundo | 3 |
| 6237 | fatuidad | 3 |
| 6238 | fastidio | 3 |
| 6239 | farsante | 3 |
| 6240 | fantasía | 3 |
| 6241 | fanático | 3 |
| 6242 | falsete | 3 |
| 6243 | fallecer | 3 |
| 6244 | facundia | 3 |
| 6245 | fachada | 3 |
| 6246 | fabricante | 3 |
| 6247 | extremidad | 3 |
| 6248 | expresó | 3 |
| 6249 | explosivo | 3 |
| 6250 | explorar | 3 |
| 6251 | expectativa | 3 |
| 6252 | expectante | 3 |
| 6253 | expansivo | 3 |
| 6254 | expansión | 3 |
| 6255 | excitante | 3 |
| 6256 | exceso | 3 |
| 6257 | excesivo | 3 |
| 6258 | exageración | 3 |
| 6259 | evolución | 3 |
| 6260 | evasivamente | 3 |
| 6261 | evasiva | 3 |
| 6262 | evasión | 3 |
| 6263 | evangélico | 3 |
| 6264 | europa | 3 |
| 6265 | eternidad | 3 |
| 6266 | estupor | 3 |
| 6267 | estupidez | 3 |
| 6268 | estudiado | 3 |
| 6269 | estuche | 3 |
| 6270 | estucar | 3 |
| 6271 | estrujón | 3 |
| 6272 | estrofa | 3 |
| 6273 | estridente | 3 |
| 6274 | estrechamente | 3 |
| 6275 | estipendio | 3 |
| 6276 | estilar | 3 |
| 6277 | estaría | 3 |
| 6278 | espumar | 3 |
| 6279 | espuma | 3 |
| 6280 | esperpento | 3 |
| 6281 | esparto | 3 |
| 6282 | esparcimiento | 3 |
| 6283 | espantajo | 3 |
| 6284 | espantada | 3 |
| 6285 | esfinge | 3 |
| 6286 | esencia | 3 |
| 6287 | escudriñar | 3 |
| 6288 | escudo | 3 |
| 6289 | escocés | 3 |
| 6290 | escobillón | 3 |
| 6291 | escarmiento | 3 |
| 6292 | escarmentar | 3 |
| 6293 | escapatoria | 3 |
| 6294 | escanciar | 3 |
| 6295 | escalerilla | 3 |
| 6296 | escabeche | 3 |
| 6297 | errante | 3 |
| 6298 | erizar | 3 |
| 6299 | erguir | 3 |
| 6300 | equívoco | 3 |
| 6301 | equivocado | 3 |
| 6302 | episodio | 3 |
| 6303 | enviudar | 3 |
| 6304 | envidioso | 3 |
| 6305 | envenenamiento | 3 |
| 6306 | entrometido | 3 |
| 6307 | entrometer | 3 |
| 6308 | entrañablemente | 3 |
| 6309 | entorpecer | 3 |
| 6310 | entornado | 3 |
| 6311 | enterose | 3 |
| 6312 | enterado | 3 |
| 6313 | enrevesado | 3 |
| 6314 | enrejar | 3 |
| 6315 | enloquecer | 3 |
| 6316 | enlace | 3 |
| 6317 | enjuto | 3 |
| 6318 | enigma | 3 |
| 6319 | enfurecer | 3 |
| 6320 | enfermizo | 3 |
| 6321 | endilgar | 3 |
| 6322 | encorvar | 3 |
| 6323 | encontronazo | 3 |
| 6324 | encoger | 3 |
| 6325 | encinas | 3 |
| 6326 | encerrarme | 3 |
| 6327 | encargado | 3 |
| 6328 | encaramar | 3 |
| 6329 | encantado | 3 |
| 6330 | encalabrinar | 3 |
| 6331 | enaltecer | 3 |
| 6332 | enagua | 3 |
| 6333 | emulación | 3 |
| 6334 | empolvar | 3 |
| 6335 | empinar | 3 |
| 6336 | empezó | 3 |
| 6337 | empeño | 3 |
| 6338 | empaquetar | 3 |
| 6339 | empaque | 3 |
| 6340 | empapar | 3 |
| 6341 | empañado | 3 |
| 6342 | eminencia | 3 |
| 6343 | emblema | 3 |
| 6344 | embellecer | 3 |
| 6345 | embelesar | 3 |
| 6346 | embaucar | 3 |
| 6347 | emancipar | 3 |
| 6348 | emanación | 3 |
| 6349 | elocuencia | 3 |
| 6350 | eliminar | 3 |
| 6351 | electrizar | 3 |
| 6352 | egipcio | 3 |
| 6353 | efectuar | 3 |
| 6354 | educativo | 3 |
| 6355 | edificación | 3 |
| 6356 | durmiose | 3 |
| 6357 | dulzón | 3 |
| 6358 | dulcificar | 3 |
| 6359 | dragón | 3 |
| 6360 | dormitar | 3 |
| 6361 | dominguero | 3 |
| 6362 | domiciliario | 3 |
| 6363 | dolores | 3 |
| 6364 | dogma | 3 |
| 6365 | divisar | 3 |
| 6366 | distrito | 3 |
| 6367 | distinguido | 3 |
| 6368 | distar | 3 |
| 6369 | dispensa | 3 |
| 6370 | disolvente | 3 |
| 6371 | disoluto | 3 |
| 6372 | dislocar | 3 |
| 6373 | disimulado | 3 |
| 6374 | disciplina | 3 |
| 6375 | diputar | 3 |
| 6376 | diole | 3 |
| 6377 | dímelo | 3 |
| 6378 | dilo | 3 |
| 6379 | dile | 3 |
| 6380 | dilatar | 3 |
| 6381 | dígase | 3 |
| 6382 | dificultar | 3 |
| 6383 | difícilmente | 3 |
| 6384 | diferenciar | 3 |
| 6385 | dieciocho | 3 |
| 6386 | dictamen | 3 |
| 6387 | dichosos | 3 |
| 6388 | dibujar | 3 |
| 6389 | devoto | 3 |
| 6390 | devolución | 3 |
| 6391 | desviar | 3 |
| 6392 | desvelo | 3 |
| 6393 | desvariar | 3 |
| 6394 | desvanecimiento | 3 |
| 6395 | destrozado | 3 |
| 6396 | desproporción | 3 |
| 6397 | desprendimiento | 3 |
| 6398 | despotismo | 3 |
| 6399 | despojo | 3 |
| 6400 | despintar | 3 |
| 6401 | despacito | 3 |
| 6402 | despabilado | 3 |
| 6403 | desolado | 3 |
| 6404 | desmerecer | 3 |
| 6405 | desmenuzar | 3 |
| 6406 | desmejorado | 3 |
| 6407 | desilusionar | 3 |
| 6408 | deshilachado | 3 |
| 6409 | desflorar | 3 |
| 6410 | desfigurar | 3 |
| 6411 | desfavorable | 3 |
| 6412 | desesperado | 3 |
| 6413 | desengañar | 3 |
| 6414 | desenfado | 3 |
| 6415 | descuida | 3 |
| 6416 | descubrimiento | 3 |
| 6417 | descifrar | 3 |
| 6418 | descarar | 3 |
| 6419 | descalabrar | 3 |
| 6420 | desbastar | 3 |
| 6421 | desasosegar | 3 |
| 6422 | desasir | 3 |
| 6423 | desaparición | 3 |
| 6424 | desaliento | 3 |
| 6425 | desalar | 3 |
| 6426 | desaire | 3 |
| 6427 | desahogo | 3 |
| 6428 | desabrigar | 3 |
| 6429 | derroche | 3 |
| 6430 | depravación | 3 |
| 6431 | deplorable | 3 |
| 6432 | deparar | 3 |
| 6433 | demonche | 3 |
| 6434 | democrático | 3 |
| 6435 | delicia | 3 |
| 6436 | déjese | 3 |
| 6437 | definir | 3 |
| 6438 | decisión | 3 |
| 6439 | decíale | 3 |
| 6440 | debo | 3 |
| 6441 | debilitar | 3 |
| 6442 | damasco | 3 |
| 6443 | cúpula | 3 |
| 6444 | cundir | 3 |
| 6445 | culpar | 3 |
| 6446 | cuita | 3 |
| 6447 | cuestas | 3 |
| 6448 | cuesta | 3 |
| 6449 | cuchitril | 3 |
| 6450 | cuatrocientos | 3 |
| 6451 | cuarterón | 3 |
| 6452 | cuántos | 3 |
| 6453 | cuántas | 3 |
| 6454 | crujía | 3 |
| 6455 | crucifijo | 3 |
| 6456 | cromo | 3 |
| 6457 | criticar | 3 |
| 6458 | cristiandad | 3 |
| 6459 | crío | 3 |
| 6460 | crepúsculo | 3 |
| 6461 | créete | 3 |
| 6462 | créelo | 3 |
| 6463 | crecimiento | 3 |
| 6464 | créame | 3 |
| 6465 | creador | 3 |
| 6466 | coz | 3 |
| 6467 | cosas | 3 |
| 6468 | corruptor | 3 |
| 6469 | corromper | 3 |
| 6470 | corroborar | 3 |
| 6471 | corretaje | 3 |
| 6472 | correcto | 3 |
| 6473 | coronilla | 3 |
| 6474 | corneta | 3 |
| 6475 | corista | 3 |
| 6476 | corinto | 3 |
| 6477 | cordial | 3 |
| 6478 | coral | 3 |
| 6479 | coquetería | 3 |
| 6480 | copiar | 3 |
| 6481 | conveniencia | 3 |
| 6482 | convencional | 3 |
| 6483 | contrato | 3 |
| 6484 | contratiempo | 3 |
| 6485 | continuidad | 3 |
| 6486 | contingencia | 3 |
| 6487 | continente | 3 |
| 6488 | contemporizar | 3 |
| 6489 | contemporáneo | 3 |
| 6490 | consumo | 3 |
| 6491 | consternado | 3 |
| 6492 | conspirar | 3 |
| 6493 | conspirador | 3 |
| 6494 | consolador | 3 |
| 6495 | consignar | 3 |
| 6496 | conservación | 3 |
| 6497 | consabido | 3 |
| 6498 | confín | 3 |
| 6499 | confabular | 3 |
| 6500 | conde | 3 |
| 6501 | concurso | 3 |
| 6502 | concurrencia | 3 |
| 6503 | conciliar | 3 |
| 6504 | conciliador | 3 |
| 6505 | concha | 3 |
| 6506 | conceptuar | 3 |
| 6507 | comúnmente | 3 |
| 6508 | comunión | 3 |
| 6509 | comunicativo | 3 |
| 6510 | comprendo | 3 |
| 6511 | comprador | 3 |
| 6512 | compota | 3 |
| 6513 | composición | 3 |
| 6514 | comportamiento | 3 |
| 6515 | cómplice | 3 |
| 6516 | complicación | 3 |
| 6517 | complexión | 3 |
| 6518 | complacencia | 3 |
| 6519 | comitiva | 3 |
| 6520 | comediar | 3 |
| 6521 | combatiente | 3 |
| 6522 | colorín | 3 |
| 6523 | coloquiar | 3 |
| 6524 | colmena | 3 |
| 6525 | colérico | 3 |
| 6526 | colegial | 3 |
| 6527 | colección | 3 |
| 6528 | colación | 3 |
| 6529 | codos | 3 |
| 6530 | club | 3 |
| 6531 | clavado | 3 |
| 6532 | claustro | 3 |
| 6533 | ciudadano | 3 |
| 6534 | cisco | 3 |
| 6535 | circular | 3 |
| 6536 | circulación | 3 |
| 6537 | ciprés | 3 |
| 6538 | cierta | 3 |
| 6539 | cicatero | 3 |
| 6540 | chusco | 3 |
| 6541 | chuscada | 3 |
| 6542 | chulo | 3 |
| 6543 | chulita | 3 |
| 6544 | chula | 3 |
| 6545 | chinesco | 3 |
| 6546 | chí | 3 |
| 6547 | chaveta | 3 |
| 6548 | chato | 3 |
| 6549 | chaqueta | 3 |
| 6550 | chanza | 3 |
| 6551 | chambra | 3 |
| 6552 | ceñudo | 3 |
| 6553 | ceñir | 3 |
| 6554 | celar | 3 |
| 6555 | cebolla | 3 |
| 6556 | cebar | 3 |
| 6557 | cautiverio | 3 |
| 6558 | cauteloso | 3 |
| 6559 | cautelosamente | 3 |
| 6560 | categórico | 3 |
| 6561 | catedrático | 3 |
| 6562 | catecúmeno | 3 |
| 6563 | cataclismo | 3 |
| 6564 | castrense | 3 |
| 6565 | castita | 3 |
| 6566 | castañetazo | 3 |
| 6567 | castaña | 3 |
| 6568 | caserón | 3 |
| 6569 | casaca | 3 |
| 6570 | cartón | 3 |
| 6571 | cartel | 3 |
| 6572 | cartear | 3 |
| 6573 | carruaje | 3 |
| 6574 | carretero | 3 |
| 6575 | carnicero | 3 |
| 6576 | carmín | 3 |
| 6577 | carca | 3 |
| 6578 | carbonería | 3 |
| 6579 | carambita | 3 |
| 6580 | capotar | 3 |
| 6581 | capota | 3 |
| 6582 | capítulo | 3 |
| 6583 | capar | 3 |
| 6584 | cáñamo | 3 |
| 6585 | cántaro | 3 |
| 6586 | canastilla | 3 |
| 6587 | camps | 3 |
| 6588 | campanario | 3 |
| 6589 | campana | 3 |
| 6590 | camello | 3 |
| 6591 | camastro | 3 |
| 6592 | cámara | 3 |
| 6593 | calvo | 3 |
| 6594 | calmo | 3 |
| 6595 | callejuela | 3 |
| 6596 | calla | 3 |
| 6597 | calidad | 3 |
| 6598 | calentito | 3 |
| 6599 | calderilla | 3 |
| 6600 | calabaza | 3 |
| 6601 | caimán | 3 |
| 6602 | cafetero | 3 |
| 6603 | cadera | 3 |
| 6604 | cachivache | 3 |
| 6605 | cachete | 3 |
| 6606 | caca | 3 |
| 6607 | cabizbajo | 3 |
| 6608 | cabellar | 3 |
| 6609 | burra | 3 |
| 6610 | burdeos | 3 |
| 6611 | bufar | 3 |
| 6612 | buenazo | 3 |
| 6613 | brujería | 3 |
| 6614 | bruces | 3 |
| 6615 | brocha | 3 |
| 6616 | brindar | 3 |
| 6617 | breva | 3 |
| 6618 | brea | 3 |
| 6619 | brasero | 3 |
| 6620 | bramido | 3 |
| 6621 | bóveda | 3 |
| 6622 | bostezar | 3 |
| 6623 | borrasca | 3 |
| 6624 | bonaparte | 3 |
| 6625 | blandura | 3 |
| 6626 | blancura | 3 |
| 6627 | birlar | 3 |
| 6628 | biblioteca | 3 |
| 6629 | biblia | 3 |
| 6630 | besuqueo | 3 |
| 6631 | berrear | 3 |
| 6632 | beneficio | 3 |
| 6633 | belga | 3 |
| 6634 | beata | 3 |
| 6635 | baza | 3 |
| 6636 | bautizar | 3 |
| 6637 | batista | 3 |
| 6638 | barruntar | 3 |
| 6639 | barril | 3 |
| 6640 | barbar | 3 |
| 6641 | baratura | 3 |
| 6642 | baratar | 3 |
| 6643 | barandal | 3 |
| 6644 | barajar | 3 |
| 6645 | baqueta | 3 |
| 6646 | banquete | 3 |
| 6647 | bálsamo | 3 |
| 6648 | baldomerito | 3 |
| 6649 | balbucir | 3 |
| 6650 | balance | 3 |
| 6651 | bala | 3 |
| 6652 | baboso | 3 |
| 6653 | azoramiento | 3 |
| 6654 | avispado | 3 |
| 6655 | aviso | 3 |
| 6656 | autócrata | 3 |
| 6657 | auténtico | 3 |
| 6658 | aureola | 3 |
| 6659 | aullido | 3 |
| 6660 | audiencia | 3 |
| 6661 | atusar | 3 |
| 6662 | atropelladamente | 3 |
| 6663 | atracón | 3 |
| 6664 | atontado | 3 |
| 6665 | aterrada | 3 |
| 6666 | atenazar | 3 |
| 6667 | asunción | 3 |
| 6668 | astuto | 3 |
| 6669 | asociación | 3 |
| 6670 | asistencia | 3 |
| 6671 | asimismo | 3 |
| 6672 | asfixia | 3 |
| 6673 | asesinato | 3 |
| 6674 | asado | 3 |
| 6675 | artesón | 3 |
| 6676 | arsenal | 3 |
| 6677 | arrogancia | 3 |
| 6678 | arrendar | 3 |
| 6679 | arraigar | 3 |
| 6680 | arrabal | 3 |
| 6681 | arquear | 3 |
| 6682 | aro | 3 |
| 6683 | árnica | 3 |
| 6684 | aritmética | 3 |
| 6685 | arenar | 3 |
| 6686 | ardientemente | 3 |
| 6687 | arcano | 3 |
| 6688 | arbusto | 3 |
| 6689 | arancelario | 3 |
| 6690 | apóstrofe | 3 |
| 6691 | apellido | 3 |
| 6692 | apellidar | 3 |
| 6693 | apático | 3 |
| 6694 | apasionado | 3 |
| 6695 | aparente | 3 |
| 6696 | apañar | 3 |
| 6697 | apañadito | 3 |
| 6698 | apalear | 3 |
| 6699 | anulación | 3 |
| 6700 | antemano | 3 |
| 6701 | antagonismo | 3 |
| 6702 | animado | 3 |
| 6703 | angosto | 3 |
| 6704 | andalucía | 3 |
| 6705 | andadas | 3 |
| 6706 | analizar | 3 |
| 6707 | amoratar | 3 |
| 6708 | amontonar | 3 |
| 6709 | amonestar | 3 |
| 6710 | amoldar | 3 |
| 6711 | amigote | 3 |
| 6712 | amiga | 3 |
| 6713 | amenaza | 3 |
| 6714 | alusión | 3 |
| 6715 | alucinar | 3 |
| 6716 | altísimo | 3 |
| 6717 | alpiste | 3 |
| 6718 | almacenista | 3 |
| 6719 | aligerar | 3 |
| 6720 | alfonsino | 3 |
| 6721 | alevoso | 3 |
| 6722 | aldea | 3 |
| 6723 | alcohol | 3 |
| 6724 | albergar | 3 |
| 6725 | alba | 3 |
| 6726 | alardear | 3 |
| 6727 | alambique | 3 |
| 6728 | alabado | 3 |
| 6729 | ajedrez | 3 |
| 6730 | ahuyentar | 3 |
| 6731 | ahogo | 3 |
| 6732 | ahilar | 3 |
| 6733 | agujereado | 3 |
| 6734 | agrio | 3 |
| 6735 | agresor | 3 |
| 6736 | agradecidísimo | 3 |
| 6737 | agilidad | 3 |
| 6738 | afrontar | 3 |
| 6739 | afinidad | 3 |
| 6740 | aferrar | 3 |
| 6741 | afear | 3 |
| 6742 | advertencia | 3 |
| 6743 | adulterio | 3 |
| 6744 | adquisición | 3 |
| 6745 | adoquín | 3 |
| 6746 | adónde | 3 |
| 6747 | adivinación | 3 |
| 6748 | adentro | 3 |
| 6749 | adarme | 3 |
| 6750 | adaptar | 3 |
| 6751 | acusón | 3 |
| 6752 | acusador | 3 |
| 6753 | acuéstate | 3 |
| 6754 | actual | 3 |
| 6755 | acritud | 3 |
| 6756 | acreditado | 3 |
| 6757 | acordábase | 3 |
| 6758 | acopiar | 3 |
| 6759 | acompañamiento | 3 |
| 6760 | acoger | 3 |
| 6761 | ácido | 3 |
| 6762 | achaque | 3 |
| 6763 | achacar | 3 |
| 6764 | acercose | 3 |
| 6765 | aceituna | 3 |
| 6766 | aceitoso | 3 |
| 6767 | accesible | 3 |
| 6768 | acceder | 3 |
| 6769 | académico | 3 |
| 6770 | acabado | 3 |
| 6771 | abundancia | 3 |
| 6772 | absolutismo | 3 |
| 6773 | abrumar | 3 |
| 6774 | abonar | 3 |
| 6775 | abollar | 3 |
| 6776 | abocar | 3 |
| 6777 | ablandar | 3 |
| 6778 | abarcar | 3 |
| 6779 | zurrón | 2 |
| 6780 | zurita | 2 |
| 6781 | zurcir | 2 |
| 6782 | zumbido | 2 |
| 6783 | zorro | 2 |
| 6784 | zócalo | 2 |
| 6785 | zipizape | 2 |
| 6786 | zarpar | 2 |
| 6787 | zampar | 2 |
| 6788 | zambullir | 2 |
| 6789 | zalea | 2 |
| 6790 | zafio | 2 |
| 6791 | yacer | 2 |
| 6792 | yacente | 2 |
| 6793 | xvi | 2 |
| 6794 | wagner | 2 |
| 6795 | voraz | 2 |
| 6796 | voracidad | 2 |
| 6797 | vomitar | 2 |
| 6798 | volviéndose | 2 |
| 6799 | voluminoso | 2 |
| 6800 | voltereta | 2 |
| 6801 | voltear | 2 |
| 6802 | volcado | 2 |
| 6803 | vocación | 2 |
| 6804 | vizcaíno | 2 |
| 6805 | víveres | 2 |
| 6806 | vivacidad | 2 |
| 6807 | vivaaaa | 2 |
| 6808 | vislumbrar | 2 |
| 6809 | visera | 2 |
| 6810 | virar | 2 |
| 6811 | violado | 2 |
| 6812 | vilo | 2 |
| 6813 | vigilante | 2 |
| 6814 | vienes | 2 |
| 6815 | viena | 2 |
| 6816 | vidrioso | 2 |
| 6817 | vicente | 2 |
| 6818 | viaducto | 2 |
| 6819 | vértigo | 2 |
| 6820 | verso | 2 |
| 6821 | verdura | 2 |
| 6822 | verdulera | 2 |
| 6823 | verdoso | 2 |
| 6824 | verbigracia | 2 |
| 6825 | veo | 2 |
| 6826 | ventilar | 2 |
| 6827 | ventilación | 2 |
| 6828 | vengan | 2 |
| 6829 | venenoso | 2 |
| 6830 | venecia | 2 |
| 6831 | vellón | 2 |
| 6832 | veintiséis | 2 |
| 6833 | vega | 2 |
| 6834 | ved | 2 |
| 6835 | vean | 2 |
| 6836 | veamos | 2 |
| 6837 | vasto | 2 |
| 6838 | vascular | 2 |
| 6839 | varita | 2 |
| 6840 | variadísimo | 2 |
| 6841 | vanidoso | 2 |
| 6842 | vanagloriar | 2 |
| 6843 | vámonos | 2 |
| 6844 | valenciano | 2 |
| 6845 | vajilla | 2 |
| 6846 | vaciado | 2 |
| 6847 | utilidad | 2 |
| 6848 | usurpar | 2 |
| 6849 | usurario | 2 |
| 6850 | usura | 2 |
| 6851 | urgente | 2 |
| 6852 | uñir | 2 |
| 6853 | untar | 2 |
| 6854 | unánimemente | 2 |
| 6855 | tutelar | 2 |
| 6856 | turulato | 2 |
| 6857 | turbio | 2 |
| 6858 | tumor | 2 |
| 6859 | tul | 2 |
| 6860 | truncar | 2 |
| 6861 | tropical | 2 |
| 6862 | tropel | 2 |
| 6863 | triquitraque | 2 |
| 6864 | trinquetada | 2 |
| 6865 | trino | 2 |
| 6866 | trigo | 2 |
| 6867 | trifulca | 2 |
| 6868 | triangular | 2 |
| 6869 | tremolina | 2 |
| 6870 | tremenda | 2 |
| 6871 | tregua | 2 |
| 6872 | trechos | 2 |
| 6873 | trece | 2 |
| 6874 | tratado | 2 |
| 6875 | traspié | 2 |
| 6876 | trasero | 2 |
| 6877 | trapicheo | 2 |
| 6878 | transmigrar | 2 |
| 6879 | tranquilízate | 2 |
| 6880 | tranquilizador | 2 |
| 6881 | tranco | 2 |
| 6882 | tramposo | 2 |
| 6883 | trajear | 2 |
| 6884 | tráiganme | 2 |
| 6885 | tráigame | 2 |
| 6886 | tragaluz | 2 |
| 6887 | tragaldabas | 2 |
| 6888 | tráfago | 2 |
| 6889 | tradicionalista | 2 |
| 6890 | totalidad | 2 |
| 6891 | toscamente | 2 |
| 6892 | torvo | 2 |
| 6893 | tórtola | 2 |
| 6894 | torta | 2 |
| 6895 | torpemente | 2 |
| 6896 | tornillo | 2 |
| 6897 | tornear | 2 |
| 6898 | tormenta | 2 |
| 6899 | torear | 2 |
| 6900 | torbellino | 2 |
| 6901 | topete | 2 |
| 6902 | tontear | 2 |
| 6903 | tontamente | 2 |
| 6904 | tonta | 2 |
| 6905 | tonadilla | 2 |
| 6906 | tole | 2 |
| 6907 | toldo | 2 |
| 6908 | tocino | 2 |
| 6909 | tocador | 2 |
| 6910 | tizne | 2 |
| 6911 | titular | 2 |
| 6912 | titubear | 2 |
| 6913 | tisú | 2 |
| 6914 | tirotear | 2 |
| 6915 | tirante | 2 |
| 6916 | tiranía | 2 |
| 6917 | tirador | 2 |
| 6918 | tira | 2 |
| 6919 | tiñoso | 2 |
| 6920 | tinglado | 2 |
| 6921 | timbrar | 2 |
| 6922 | tiita | 2 |
| 6923 | tibio | 2 |
| 6924 | testero | 2 |
| 6925 | ternero | 2 |
| 6926 | terapéutico | 2 |
| 6927 | teólogo | 2 |
| 6928 | teología | 2 |
| 6929 | tenuemente | 2 |
| 6930 | tenlo | 2 |
| 6931 | tenebroso | 2 |
| 6932 | tendido | 2 |
| 6933 | templado | 2 |
| 6934 | telegráfico | 2 |
| 6935 | telaraña | 2 |
| 6936 | tejer | 2 |
| 6937 | tedioso | 2 |
| 6938 | techumbre | 2 |
| 6939 | tate | 2 |
| 6940 | tarumba | 2 |
| 6941 | tartamudear | 2 |
| 6942 | tarro | 2 |
| 6943 | tarambana | 2 |
| 6944 | tapizar | 2 |
| 6945 | tapiz | 2 |
| 6946 | tapa | 2 |
| 6947 | tañer | 2 |
| 6948 | tanda | 2 |
| 6949 | talón | 2 |
| 6950 | talludito | 2 |
| 6951 | tallo | 2 |
| 6952 | talla | 2 |
| 6953 | tálamo | 2 |
| 6954 | tajada | 2 |
| 6955 | taimado | 2 |
| 6956 | táctico | 2 |
| 6957 | taciturno | 2 |
| 6958 | tácitamente | 2 |
| 6959 | tablear | 2 |
| 6960 | tabicar | 2 |
| 6961 | sutilizar | 2 |
| 6962 | sutileza | 2 |
| 6963 | sustitución | 2 |
| 6964 | sustentar | 2 |
| 6965 | sustancioso | 2 |
| 6966 | suspensión | 2 |
| 6967 | susceptible | 2 |
| 6968 | susceptibilidad | 2 |
| 6969 | susana | 2 |
| 6970 | surco | 2 |
| 6971 | surcar | 2 |
| 6972 | supremacía | 2 |
| 6973 | suplicante | 2 |
| 6974 | superstición | 2 |
| 6975 | superficial | 2 |
| 6976 | superchería | 2 |
| 6977 | sulfato | 2 |
| 6978 | sujeción | 2 |
| 6979 | suiza | 2 |
| 6980 | suicidar | 2 |
| 6981 | suicida | 2 |
| 6982 | sugestivo | 2 |
| 6983 | sugestión | 2 |
| 6984 | suficientemente | 2 |
| 6985 | suez | 2 |
| 6986 | suculento | 2 |
| 6987 | suciedad | 2 |
| 6988 | sucesivamente | 2 |
| 6989 | subyugar | 2 |
| 6990 | subterráneo | 2 |
| 6991 | subterfugio | 2 |
| 6992 | sublimemente | 2 |
| 6993 | subió | 2 |
| 6994 | suavizar | 2 |
| 6995 | soslayar | 2 |
| 6996 | sorprendente | 2 |
| 6997 | sordera | 2 |
| 6998 | soporífero | 2 |
| 6999 | sonsonete | 2 |
| 7000 | sonsacar | 2 |
| 7001 | sonrojo | 2 |
| 7002 | sonriente | 2 |
| 7003 | sonata | 2 |
| 7004 | somos | 2 |
| 7005 | sombrilla | 2 |
| 7006 | solidificar | 2 |
| 7007 | solidaridad | 2 |
| 7008 | solicitud | 2 |
| 7009 | solemnemente | 2 |
| 7010 | solapar | 2 |
| 7011 | sola | 2 |
| 7012 | sofocante | 2 |
| 7013 | socialista | 2 |
| 7014 | socialismo | 2 |
| 7015 | sobresalir | 2 |
| 7016 | sobrecoger | 2 |
| 7017 | soberanamente | 2 |
| 7018 | sinrazón | 2 |
| 7019 | sinfonía | 2 |
| 7020 | simetría | 2 |
| 7021 | simbolizar | 2 |
| 7022 | sillero | 2 |
| 7023 | sillería | 2 |
| 7024 | silenciosamente | 2 |
| 7025 | silbido | 2 |
| 7026 | siguió | 2 |
| 7027 | sigilo | 2 |
| 7028 | siesta | 2 |
| 7029 | siéntate | 2 |
| 7030 | shakespeare | 2 |
| 7031 | serrana | 2 |
| 7032 | seré | 2 |
| 7033 | sepultar | 2 |
| 7034 | sepulcral | 2 |
| 7035 | sepa | 2 |
| 7036 | señorón | 2 |
| 7037 | señoras | 2 |
| 7038 | señas | 2 |
| 7039 | señalado | 2 |
| 7040 | sentía | 2 |
| 7041 | sentado | 2 |
| 7042 | sensatez | 2 |
| 7043 | seminario | 2 |
| 7044 | semestre | 2 |
| 7045 | segovia | 2 |
| 7046 | sediento | 2 |
| 7047 | secular | 2 |
| 7048 | secretaría | 2 |
| 7049 | sección | 2 |
| 7050 | secadero | 2 |
| 7051 | seamos | 2 |
| 7052 | sazonar | 2 |
| 7053 | satén | 2 |
| 7054 | sarta | 2 |
| 7055 | sargento | 2 |
| 7056 | saquito | 2 |
| 7057 | sáqueme | 2 |
| 7058 | santurrón | 2 |
| 7059 | santiago | 2 |
| 7060 | santamente | 2 |
| 7061 | sanidad | 2 |
| 7062 | sangriento | 2 |
| 7063 | samaritana | 2 |
| 7064 | salvajismo | 2 |
| 7065 | salmón | 2 |
| 7066 | salivazo | 2 |
| 7067 | salero | 2 |
| 7068 | saldo | 2 |
| 7069 | sagasta | 2 |
| 7070 | sacrilegio | 2 |
| 7071 | saciar | 2 |
| 7072 | sacerdotal | 2 |
| 7073 | sabiendo | 2 |
| 7074 | ruptura | 2 |
| 7075 | rumiar | 2 |
| 7076 | ruinoso | 2 |
| 7077 | rugido | 2 |
| 7078 | rufina | 2 |
| 7079 | royan | 2 |
| 7080 | rosado | 2 |
| 7081 | rondón | 2 |
| 7082 | rondas | 2 |
| 7083 | rollo | 2 |
| 7084 | rojizo | 2 |
| 7085 | rodrigo | 2 |
| 7086 | rodillera | 2 |
| 7087 | roce | 2 |
| 7088 | robo | 2 |
| 7089 | roble | 2 |
| 7090 | rivero | 2 |
| 7091 | risilla | 2 |
| 7092 | risible | 2 |
| 7093 | riñonada | 2 |
| 7094 | ríete | 2 |
| 7095 | rienda | 2 |
| 7096 | rezonas | 2 |
| 7097 | rezagar | 2 |
| 7098 | reyes | 2 |
| 7099 | revuelto | 2 |
| 7100 | revolucionar | 2 |
| 7101 | revoltijo | 2 |
| 7102 | reverencia | 2 |
| 7103 | retrospectivo | 2 |
| 7104 | retrasar | 2 |
| 7105 | retrasado | 2 |
| 7106 | retozón | 2 |
| 7107 | retírate | 2 |
| 7108 | retiráronse | 2 |
| 7109 | retar | 2 |
| 7110 | retahíla | 2 |
| 7111 | restar | 2 |
| 7112 | restallido | 2 |
| 7113 | restablecer | 2 |
| 7114 | respingado | 2 |
| 7115 | resolviose | 2 |
| 7116 | residente | 2 |
| 7117 | residencia | 2 |
| 7118 | reservado | 2 |
| 7119 | requetefinos | 2 |
| 7120 | requerir | 2 |
| 7121 | repuso | 2 |
| 7122 | repuesto | 2 |
| 7123 | republicano | 2 |
| 7124 | representante | 2 |
| 7125 | réplica | 2 |
| 7126 | repletar | 2 |
| 7127 | repique | 2 |
| 7128 | repetía | 2 |
| 7129 | repelón | 2 |
| 7130 | repecho | 2 |
| 7131 | repaso | 2 |
| 7132 | reparo | 2 |
| 7133 | reo | 2 |
| 7134 | reñido | 2 |
| 7135 | renquear | 2 |
| 7136 | renovado | 2 |
| 7137 | rendido | 2 |
| 7138 | rencoroso | 2 |
| 7139 | remesa | 2 |
| 7140 | remendar | 2 |
| 7141 | rematado | 2 |
| 7142 | relumbrón | 2 |
| 7143 | relumbrar | 2 |
| 7144 | relumbrante | 2 |
| 7145 | religiosidad | 2 |
| 7146 | relevar | 2 |
| 7147 | relatores | 2 |
| 7148 | reintegro | 2 |
| 7149 | regurgitación | 2 |
| 7150 | reguapo | 2 |
| 7151 | régimen | 2 |
| 7152 | regenerar | 2 |
| 7153 | regazo | 2 |
| 7154 | regatear | 2 |
| 7155 | regaño | 2 |
| 7156 | regañar | 2 |
| 7157 | refundir | 2 |
| 7158 | refugiose | 2 |
| 7159 | refugiar | 2 |
| 7160 | reflexivo | 2 |
| 7161 | reflejo | 2 |
| 7162 | referido | 2 |
| 7163 | referencia | 2 |
| 7164 | redondear | 2 |
| 7165 | redactar | 2 |
| 7166 | recta | 2 |
| 7167 | recostar | 2 |
| 7168 | reclusión | 2 |
| 7169 | reclamación | 2 |
| 7170 | recio | 2 |
| 7171 | recientemente | 2 |
| 7172 | recibo | 2 |
| 7173 | recibido | 2 |
| 7174 | receptividad | 2 |
| 7175 | recepción | 2 |
| 7176 | rebullir | 2 |
| 7177 | rebasar | 2 |
| 7178 | rebañar | 2 |
| 7179 | ratero | 2 |
| 7180 | rastras | 2 |
| 7181 | raspar | 2 |
| 7182 | rasguño | 2 |
| 7183 | rarísimo | 2 |
| 7184 | rapaza | 2 |
| 7185 | rapaz | 2 |
| 7186 | randa | 2 |
| 7187 | ramos | 2 |
| 7188 | raíz | 2 |
| 7189 | raigón | 2 |
| 7190 | rábano | 2 |
| 7191 | ra | 2 |
| 7192 | quitarvos | 2 |
| 7193 | quiso | 2 |
| 7194 | quisiera | 2 |
| 7195 | quintar | 2 |
| 7196 | química | 2 |
| 7197 | quimera | 2 |
| 7198 | querindango | 2 |
| 7199 | quercus | 2 |
| 7200 | quédese | 2 |
| 7201 | quedamente | 2 |
| 7202 | quebradero | 2 |
| 7203 | puso | 2 |
| 7204 | purgatorio | 2 |
| 7205 | pupitre | 2 |
| 7206 | punzar | 2 |
| 7207 | puntería | 2 |
| 7208 | puntear | 2 |
| 7209 | puntal | 2 |
| 7210 | puntada | 2 |
| 7211 | pulsación | 2 |
| 7212 | pulgar | 2 |
| 7213 | puerto | 2 |
| 7214 | puedo | 2 |
| 7215 | puedes | 2 |
| 7216 | pudiente | 2 |
| 7217 | publicidad | 2 |
| 7218 | pública | 2 |
| 7219 | próximamente | 2 |
| 7220 | provisionar | 2 |
| 7221 | provisional | 2 |
| 7222 | provechoso | 2 |
| 7223 | protegida | 2 |
| 7224 | prostitución | 2 |
| 7225 | propuesta | 2 |
| 7226 | propinar | 2 |
| 7227 | propicio | 2 |
| 7228 | propenso | 2 |
| 7229 | propagar | 2 |
| 7230 | promulgar | 2 |
| 7231 | prométeme | 2 |
| 7232 | prolongación | 2 |
| 7233 | prohibición | 2 |
| 7234 | profanar | 2 |
| 7235 | profanación | 2 |
| 7236 | probado | 2 |
| 7237 | princesa | 2 |
| 7238 | primitiva | 2 |
| 7239 | previsor | 2 |
| 7240 | presión | 2 |
| 7241 | presidiario | 2 |
| 7242 | presidente | 2 |
| 7243 | presentable | 2 |
| 7244 | presentábase | 2 |
| 7245 | presagio | 2 |
| 7246 | preparémonos | 2 |
| 7247 | preparación | 2 |
| 7248 | preocupado | 2 |
| 7249 | premiar | 2 |
| 7250 | premeditación | 2 |
| 7251 | prehistórico | 2 |
| 7252 | pregúntaselo | 2 |
| 7253 | pregúntale | 2 |
| 7254 | predominio | 2 |
| 7255 | predecesor | 2 |
| 7256 | precoces | 2 |
| 7257 | precipitación | 2 |
| 7258 | preciados | 2 |
| 7259 | potro | 2 |
| 7260 | potingue | 2 |
| 7261 | potencia | 2 |
| 7262 | potaje | 2 |
| 7263 | posterior | 2 |
| 7264 | pórtico | 2 |
| 7265 | portazo | 2 |
| 7266 | portante | 2 |
| 7267 | porfiar | 2 |
| 7268 | porcelana | 2 |
| 7269 | poquísimo | 2 |
| 7270 | póngase | 2 |
| 7271 | ponferrada | 2 |
| 7272 | ponerse | 2 |
| 7273 | pompadour | 2 |
| 7274 | pompa | 2 |
| 7275 | poética | 2 |
| 7276 | pobretín | 2 |
| 7277 | pobretería | 2 |
| 7278 | pobrecita | 2 |
| 7279 | pluralidad | 2 |
| 7280 | plumaje | 2 |
| 7281 | plebeyo | 2 |
| 7282 | plebe | 2 |
| 7283 | plazoleta | 2 |
| 7284 | playa | 2 |
| 7285 | platón | 2 |
| 7286 | platito | 2 |
| 7287 | platería | 2 |
| 7288 | platear | 2 |
| 7289 | plasencia | 2 |
| 7290 | plano | 2 |
| 7291 | plancheta | 2 |
| 7292 | pla | 2 |
| 7293 | pizarra | 2 |
| 7294 | pivote | 2 |
| 7295 | pistoletazo | 2 |
| 7296 | pisotón | 2 |
| 7297 | piñón | 2 |
| 7298 | pinturero | 2 |
| 7299 | pinchazo | 2 |
| 7300 | pincel | 2 |
| 7301 | piltrafa | 2 |
| 7302 | pildorita | 2 |
| 7303 | pilar | 2 |
| 7304 | pignorar | 2 |
| 7305 | pifiar | 2 |
| 7306 | piénselo | 2 |
| 7307 | piensas | 2 |
| 7308 | picos | 2 |
| 7309 | picado | 2 |
| 7310 | pezón | 2 |
| 7311 | petrolero | 2 |
| 7312 | petra | 2 |
| 7313 | petaca | 2 |
| 7314 | pestaña | 2 |
| 7315 | pescadero | 2 |
| 7316 | pesadez | 2 |
| 7317 | pesadamente | 2 |
| 7318 | perversión | 2 |
| 7319 | pertinente | 2 |
| 7320 | persuasiva | 2 |
| 7321 | persuadir | 2 |
| 7322 | personificar | 2 |
| 7323 | personalmente | 2 |
| 7324 | personalizar | 2 |
| 7325 | perseverancia | 2 |
| 7326 | perrillo | 2 |
| 7327 | perrada | 2 |
| 7328 | perpetuar | 2 |
| 7329 | perorata | 2 |
| 7330 | perol | 2 |
| 7331 | periodismo | 2 |
| 7332 | periódicamente | 2 |
| 7333 | perilla | 2 |
| 7334 | perfumar | 2 |
| 7335 | perfilar | 2 |
| 7336 | pereza | 2 |
| 7337 | perdurable | 2 |
| 7338 | perdóneme | 2 |
| 7339 | perdóname | 2 |
| 7340 | perchero | 2 |
| 7341 | pequeñez | 2 |
| 7342 | pepita | 2 |
| 7343 | penumbra | 2 |
| 7344 | penique | 2 |
| 7345 | península | 2 |
| 7346 | peneque | 2 |
| 7347 | pelotazo | 2 |
| 7348 | pella | 2 |
| 7349 | peletería | 2 |
| 7350 | pelayo | 2 |
| 7351 | peces | 2 |
| 7352 | pavoroso | 2 |
| 7353 | pavor | 2 |
| 7354 | pava | 2 |
| 7355 | paul | 2 |
| 7356 | patriótico | 2 |
| 7357 | patrio | 2 |
| 7358 | patriarcal | 2 |
| 7359 | patológico | 2 |
| 7360 | pataleta | 2 |
| 7361 | pastoral | 2 |
| 7362 | pastora | 2 |
| 7363 | pastelería | 2 |
| 7364 | pasos | 2 |
| 7365 | pasó | 2 |
| 7366 | pasivo | 2 |
| 7367 | pasamanos | 2 |
| 7368 | partícipe | 2 |
| 7369 | partición | 2 |
| 7370 | partes | 2 |
| 7371 | parson | 2 |
| 7372 | parrilla | 2 |
| 7373 | parral | 2 |
| 7374 | parque | 2 |
| 7375 | parose | 2 |
| 7376 | parlamento | 2 |
| 7377 | parejo | 2 |
| 7378 | parecíame | 2 |
| 7379 | parecía | 2 |
| 7380 | pardos | 2 |
| 7381 | pararrayos | 2 |
| 7382 | paralizar | 2 |
| 7383 | paralítico | 2 |
| 7384 | paradoja | 2 |
| 7385 | paradero | 2 |
| 7386 | parábola | 2 |
| 7387 | parabién | 2 |
| 7388 | paparrucha | 2 |
| 7389 | papamoscas | 2 |
| 7390 | pañolón | 2 |
| 7391 | pañería | 2 |
| 7392 | panza | 2 |
| 7393 | panorama | 2 |
| 7394 | panecillo | 2 |
| 7395 | pamplina | 2 |
| 7396 | pamema | 2 |
| 7397 | palote | 2 |
| 7398 | palmita | 2 |
| 7399 | palmatoria | 2 |
| 7400 | palmario | 2 |
| 7401 | paliza | 2 |
| 7402 | palio | 2 |
| 7403 | paletada | 2 |
| 7404 | palabrería | 2 |
| 7405 | pala | 2 |
| 7406 | pajel | 2 |
| 7407 | pajarito | 2 |
| 7408 | pajarita | 2 |
| 7409 | pajarete | 2 |
| 7410 | paisano | 2 |
| 7411 | paices | 2 |
| 7412 | pae | 2 |
| 7413 | padillita | 2 |
| 7414 | paciente | 2 |
| 7415 | pacer | 2 |
| 7416 | pa | 2 |
| 7417 | oyéronse | 2 |
| 7418 | oyente | 2 |
| 7419 | osuna | 2 |
| 7420 | oscilar | 2 |
| 7421 | osadía | 2 |
| 7422 | ortografía | 2 |
| 7423 | ortiz | 2 |
| 7424 | originalidad | 2 |
| 7425 | oriental | 2 |
| 7426 | organismo | 2 |
| 7427 | orfila | 2 |
| 7428 | orejita | 2 |
| 7429 | orear | 2 |
| 7430 | ordinariamente | 2 |
| 7431 | ordenanza | 2 |
| 7432 | ordenada | 2 |
| 7433 | órdago | 2 |
| 7434 | oratorio | 2 |
| 7435 | oratoria | 2 |
| 7436 | orán | 2 |
| 7437 | opuesto | 2 |
| 7438 | optimista | 2 |
| 7439 | oportunidad | 2 |
| 7440 | opaco | 2 |
| 7441 | olfatear | 2 |
| 7442 | ojival | 2 |
| 7443 | ojazos | 2 |
| 7444 | oída | 2 |
| 7445 | oíanse | 2 |
| 7446 | oí | 2 |
| 7447 | ochocientos | 2 |
| 7448 | occidente | 2 |
| 7449 | occidental | 2 |
| 7450 | obstruccionar | 2 |
| 7451 | observancia | 2 |
| 7452 | objetivo | 2 |
| 7453 | nupcial | 2 |
| 7454 | núñez | 2 |
| 7455 | numerar | 2 |
| 7456 | numen | 2 |
| 7457 | nuestra | 2 |
| 7458 | nuca | 2 |
| 7459 | nublar | 2 |
| 7460 | novísimo | 2 |
| 7461 | novillo | 2 |
| 7462 | noviazgo | 2 |
| 7463 | noventa | 2 |
| 7464 | novelista | 2 |
| 7465 | novelero | 2 |
| 7466 | novar | 2 |
| 7467 | normalmente | 2 |
| 7468 | nombramiento | 2 |
| 7469 | noé | 2 |
| 7470 | noches | 2 |
| 7471 | niñera | 2 |
| 7472 | ninguno | 2 |
| 7473 | nicho | 2 |
| 7474 | nicarona | 2 |
| 7475 | neri | 2 |
| 7476 | nena | 2 |
| 7477 | negose | 2 |
| 7478 | necesariamente | 2 |
| 7479 | nebulosa | 2 |
| 7480 | nazareno | 2 |
| 7481 | navegar | 2 |
| 7482 | navaja | 2 |
| 7483 | naufragio | 2 |
| 7484 | naturalismo | 2 |
| 7485 | narices | 2 |
| 7486 | nápoles | 2 |
| 7487 | nalga | 2 |
| 7488 | naciente | 2 |
| 7489 | nabucodonosor | 2 |
| 7490 | mujerzuela | 2 |
| 7491 | mujeril | 2 |
| 7492 | mugir | 2 |
| 7493 | muerta | 2 |
| 7494 | muda | 2 |
| 7495 | movilidad | 2 |
| 7496 | movible | 2 |
| 7497 | motejar | 2 |
| 7498 | mostaza | 2 |
| 7499 | morriña | 2 |
| 7500 | morrazo | 2 |
| 7501 | mormón | 2 |
| 7502 | morisco | 2 |
| 7503 | morfina | 2 |
| 7504 | morcilla | 2 |
| 7505 | morboso | 2 |
| 7506 | moralista | 2 |
| 7507 | moraleja | 2 |
| 7508 | monstruoso | 2 |
| 7509 | monomaniaco | 2 |
| 7510 | monólogo | 2 |
| 7511 | monjil | 2 |
| 7512 | monería | 2 |
| 7513 | mondongo | 2 |
| 7514 | monaguillo | 2 |
| 7515 | molinete | 2 |
| 7516 | mojado | 2 |
| 7517 | mohoso | 2 |
| 7518 | modoso | 2 |
| 7519 | modificar | 2 |
| 7520 | moco | 2 |
| 7521 | mitra | 2 |
| 7522 | mitología | 2 |
| 7523 | misericordioso | 2 |
| 7524 | misantropía | 2 |
| 7525 | mirolo | 2 |
| 7526 | mírela | 2 |
| 7527 | míralos | 2 |
| 7528 | mírala | 2 |
| 7529 | mirado | 2 |
| 7530 | mirábale | 2 |
| 7531 | mirábalas | 2 |
| 7532 | minio | 2 |
| 7533 | mínimo | 2 |
| 7534 | mineral | 2 |
| 7535 | mímica | 2 |
| 7536 | mimbre | 2 |
| 7537 | miliciano | 2 |
| 7538 | mías | 2 |
| 7539 | mia | 2 |
| 7540 | metafísico | 2 |
| 7541 | metafísica | 2 |
| 7542 | merienda | 2 |
| 7543 | merengar | 2 |
| 7544 | merendar | 2 |
| 7545 | merecido | 2 |
| 7546 | mercurial | 2 |
| 7547 | mercader | 2 |
| 7548 | meñique | 2 |
| 7549 | mentirijilla | 2 |
| 7550 | mensajero | 2 |
| 7551 | menosprecio | 2 |
| 7552 | menestra | 2 |
| 7553 | menesteroso | 2 |
| 7554 | mendizábal | 2 |
| 7555 | mendigar | 2 |
| 7556 | mencionar | 2 |
| 7557 | mención | 2 |
| 7558 | mena | 2 |
| 7559 | memorial | 2 |
| 7560 | melómano | 2 |
| 7561 | melodramático | 2 |
| 7562 | melodrama | 2 |
| 7563 | melenudo | 2 |
| 7564 | mejorcito | 2 |
| 7565 | médula | 2 |
| 7566 | medroso | 2 |
| 7567 | mediterráneo | 2 |
| 7568 | medianamente | 2 |
| 7569 | mediados | 2 |
| 7570 | mediación | 2 |
| 7571 | mecha | 2 |
| 7572 | mecer | 2 |
| 7573 | meca | 2 |
| 7574 | maza | 2 |
| 7575 | mausoleo | 2 |
| 7576 | matrona | 2 |
| 7577 | matriz | 2 |
| 7578 | matiz | 2 |
| 7579 | matinal | 2 |
| 7580 | matilde | 2 |
| 7581 | materialidad | 2 |
| 7582 | matemático | 2 |
| 7583 | matarme | 2 |
| 7584 | mastín | 2 |
| 7585 | masticación | 2 |
| 7586 | masónico | 2 |
| 7587 | martos | 2 |
| 7588 | martínez | 2 |
| 7589 | martillar | 2 |
| 7590 | marrano | 2 |
| 7591 | marranada | 2 |
| 7592 | marino | 2 |
| 7593 | marinero | 2 |
| 7594 | marina | 2 |
| 7595 | marchitar | 2 |
| 7596 | márchese | 2 |
| 7597 | maravillosamente | 2 |
| 7598 | maraña | 2 |
| 7599 | maquinaria | 2 |
| 7600 | maño | 2 |
| 7601 | manteo | 2 |
| 7602 | mantelería | 2 |
| 7603 | manso | 2 |
| 7604 | manosear | 2 |
| 7605 | manojo | 2 |
| 7606 | manjavacas | 2 |
| 7607 | manjar | 2 |
| 7608 | manirroto | 2 |
| 7609 | manir | 2 |
| 7610 | maneras | 2 |
| 7611 | manejo | 2 |
| 7612 | mandamiento | 2 |
| 7613 | manda | 2 |
| 7614 | manchego | 2 |
| 7615 | manaza | 2 |
| 7616 | manada | 2 |
| 7617 | mamotreto | 2 |
| 7618 | mamón | 2 |
| 7619 | maltrecho | 2 |
| 7620 | maltratado | 2 |
| 7621 | malla | 2 |
| 7622 | malestar | 2 |
| 7623 | maleante | 2 |
| 7624 | maldecir | 2 |
| 7625 | majadería | 2 |
| 7626 | magistral | 2 |
| 7627 | magia | 2 |
| 7628 | madrugón | 2 |
| 7629 | madrugador | 2 |
| 7630 | madrina | 2 |
| 7631 | mácula | 2 |
| 7632 | machacón | 2 |
| 7633 | luterano | 2 |
| 7634 | lunático | 2 |
| 7635 | luengo | 2 |
| 7636 | lucrativo | 2 |
| 7637 | lucimiento | 2 |
| 7638 | lucero | 2 |
| 7639 | lote | 2 |
| 7640 | lópez | 2 |
| 7641 | lontananza | 2 |
| 7642 | lonja | 2 |
| 7643 | lombarda | 2 |
| 7644 | locomotora | 2 |
| 7645 | llorón | 2 |
| 7646 | llevándose | 2 |
| 7647 | llevadero | 2 |
| 7648 | llegaría | 2 |
| 7649 | llamarme | 2 |
| 7650 | llamarada | 2 |
| 7651 | llamador | 2 |
| 7652 | llamábanla | 2 |
| 7653 | llama | 2 |
| 7654 | llaga | 2 |
| 7655 | liviandad | 2 |
| 7656 | litro | 2 |
| 7657 | liquidar | 2 |
| 7658 | liquidación | 2 |
| 7659 | linterna | 2 |
| 7660 | lince | 2 |
| 7661 | limpión | 2 |
| 7662 | limón | 2 |
| 7663 | liebre | 2 |
| 7664 | licenciar | 2 |
| 7665 | librote | 2 |
| 7666 | lía | 2 |
| 7667 | levemente | 2 |
| 7668 | levar | 2 |
| 7669 | levante | 2 |
| 7670 | letras | 2 |
| 7671 | leonés | 2 |
| 7672 | lentitud | 2 |
| 7673 | lema | 2 |
| 7674 | lebrel | 2 |
| 7675 | lazareto | 2 |
| 7676 | lava | 2 |
| 7677 | lastrar | 2 |
| 7678 | larguísimo | 2 |
| 7679 | laredo | 2 |
| 7680 | lamer | 2 |
| 7681 | lamentable | 2 |
| 7682 | lagarto | 2 |
| 7683 | lagarta | 2 |
| 7684 | ladino | 2 |
| 7685 | laciar | 2 |
| 7686 | labrador | 2 |
| 7687 | laborioso | 2 |
| 7688 | laberinto | 2 |
| 7689 | laberíntico | 2 |
| 7690 | kock | 2 |
| 7691 | king | 2 |
| 7692 | juvenil | 2 |
| 7693 | justificar | 2 |
| 7694 | justiciero | 2 |
| 7695 | juramentar | 2 |
| 7696 | jura | 2 |
| 7697 | judicial | 2 |
| 7698 | jornal | 2 |
| 7699 | jicarazo | 2 |
| 7700 | jeroglífico | 2 |
| 7701 | jerarquía | 2 |
| 7702 | jayán | 2 |
| 7703 | javiera | 2 |
| 7704 | jaleo | 2 |
| 7705 | jactar | 2 |
| 7706 | jactábase | 2 |
| 7707 | italia | 2 |
| 7708 | irún | 2 |
| 7709 | irresponsable | 2 |
| 7710 | irreparable | 2 |
| 7711 | irradiación | 2 |
| 7712 | irónico | 2 |
| 7713 | iremos | 2 |
| 7714 | inyectar | 2 |
| 7715 | invocación | 2 |
| 7716 | invento | 2 |
| 7717 | inventario | 2 |
| 7718 | invasión | 2 |
| 7719 | invariablemente | 2 |
| 7720 | invariable | 2 |
| 7721 | inútilmente | 2 |
| 7722 | inutilidad | 2 |
| 7723 | intervalo | 2 |
| 7724 | interrogación | 2 |
| 7725 | interpretación | 2 |
| 7726 | intermediario | 2 |
| 7727 | interceptar | 2 |
| 7728 | intelectualmente | 2 |
| 7729 | insustancial | 2 |
| 7730 | insurgente | 2 |
| 7731 | ínsula | 2 |
| 7732 | instintivo | 2 |
| 7733 | instantáneamente | 2 |
| 7734 | instaláronse | 2 |
| 7735 | instalación | 2 |
| 7736 | inspector | 2 |
| 7737 | inspeccionar | 2 |
| 7738 | insolvencia | 2 |
| 7739 | insolencia | 2 |
| 7740 | insinuar | 2 |
| 7741 | inservible | 2 |
| 7742 | inseguridad | 2 |
| 7743 | inquisición | 2 |
| 7744 | inquirir | 2 |
| 7745 | inquina | 2 |
| 7746 | inmortalidad | 2 |
| 7747 | inmortal | 2 |
| 7748 | inmoral | 2 |
| 7749 | injusto | 2 |
| 7750 | inicial | 2 |
| 7751 | iniciador | 2 |
| 7752 | inhábil | 2 |
| 7753 | ingresar | 2 |
| 7754 | ingrediente | 2 |
| 7755 | ingenuamente | 2 |
| 7756 | infernar | 2 |
| 7757 | infausto | 2 |
| 7758 | infatigable | 2 |
| 7759 | infamante | 2 |
| 7760 | inestimable | 2 |
| 7761 | inesperado | 2 |
| 7762 | inepto | 2 |
| 7763 | ineficacia | 2 |
| 7764 | ineducado | 2 |
| 7765 | indulto | 2 |
| 7766 | indiscutible | 2 |
| 7767 | indiscreto | 2 |
| 7768 | indiscreción | 2 |
| 7769 | indirecto | 2 |
| 7770 | indirecta | 2 |
| 7771 | indicado | 2 |
| 7772 | indemnizar | 2 |
| 7773 | indemnización | 2 |
| 7774 | indefinidamente | 2 |
| 7775 | indecencia | 2 |
| 7776 | inculto | 2 |
| 7777 | increpar | 2 |
| 7778 | inconscientemente | 2 |
| 7779 | inconmensurable | 2 |
| 7780 | incompleto | 2 |
| 7781 | incoherente | 2 |
| 7782 | incluir | 2 |
| 7783 | incidente | 2 |
| 7784 | incendiar | 2 |
| 7785 | incansable | 2 |
| 7786 | inapetencia | 2 |
| 7787 | inacabable | 2 |
| 7788 | improvisado | 2 |
| 7789 | impresionable | 2 |
| 7790 | imprentar | 2 |
| 7791 | imprenta | 2 |
| 7792 | importador | 2 |
| 7793 | imponente | 2 |
| 7794 | implorar | 2 |
| 7795 | imperceptible | 2 |
| 7796 | impavidez | 2 |
| 7797 | ilusorio | 2 |
| 7798 | igualdad | 2 |
| 7799 | idilio | 2 |
| 7800 | idéntico | 2 |
| 7801 | ideación | 2 |
| 7802 | hurtadillas | 2 |
| 7803 | huraño | 2 |
| 7804 | hundido | 2 |
| 7805 | humildemente | 2 |
| 7806 | húmera | 2 |
| 7807 | huéspeda | 2 |
| 7808 | hubiérase | 2 |
| 7809 | hubiera | 2 |
| 7810 | hostilidad | 2 |
| 7811 | hostil | 2 |
| 7812 | hostigar | 2 |
| 7813 | hortaliza | 2 |
| 7814 | horroroso | 2 |
| 7815 | hornillo | 2 |
| 7816 | hormigueo | 2 |
| 7817 | horchata | 2 |
| 7818 | horcar | 2 |
| 7819 | honroso | 2 |
| 7820 | hondura | 2 |
| 7821 | hondamente | 2 |
| 7822 | homicida | 2 |
| 7823 | holgura | 2 |
| 7824 | holgazán | 2 |
| 7825 | hocicudo | 2 |
| 7826 | hocicar | 2 |
| 7827 | hízose | 2 |
| 7828 | hízole | 2 |
| 7829 | historiar | 2 |
| 7830 | hipoteca | 2 |
| 7831 | hipocrático | 2 |
| 7832 | hiperbólico | 2 |
| 7833 | hincar | 2 |
| 7834 | hincapié | 2 |
| 7835 | hilada | 2 |
| 7836 | hidalguía | 2 |
| 7837 | hidalgo | 2 |
| 7838 | heterogeneidad | 2 |
| 7839 | hervidero | 2 |
| 7840 | heroína | 2 |
| 7841 | heroico | 2 |
| 7842 | hernán | 2 |
| 7843 | herméticamente | 2 |
| 7844 | herejía | 2 |
| 7845 | hemos | 2 |
| 7846 | hazaña | 2 |
| 7847 | haré | 2 |
| 7848 | han | 2 |
| 7849 | hallábanse | 2 |
| 7850 | hacha | 2 |
| 7851 | hablose | 2 |
| 7852 | hablilla | 2 |
| 7853 | habitar | 2 |
| 7854 | habilidoso | 2 |
| 7855 | habíase | 2 |
| 7856 | habéis | 2 |
| 7857 | gutural | 2 |
| 7858 | gustábale | 2 |
| 7859 | gusano | 2 |
| 7860 | guitarrear | 2 |
| 7861 | guisa | 2 |
| 7862 | guiño | 2 |
| 7863 | guillotinar | 2 |
| 7864 | gubernamental | 2 |
| 7865 | guarida | 2 |
| 7866 | guapeza | 2 |
| 7867 | groseramente | 2 |
| 7868 | gro | 2 |
| 7869 | gritaba | 2 |
| 7870 | grillera | 2 |
| 7871 | greda | 2 |
| 7872 | granuloso | 2 |
| 7873 | granujería | 2 |
| 7874 | grandes | 2 |
| 7875 | granada | 2 |
| 7876 | grana | 2 |
| 7877 | gramo | 2 |
| 7878 | gramática | 2 |
| 7879 | gradual | 2 |
| 7880 | goma | 2 |
| 7881 | glóbulo | 2 |
| 7882 | gitano | 2 |
| 7883 | gitanesco | 2 |
| 7884 | gibraltar | 2 |
| 7885 | getafe | 2 |
| 7886 | gestar | 2 |
| 7887 | genial | 2 |
| 7888 | gelatinoso | 2 |
| 7889 | gaveta | 2 |
| 7890 | gatuperio | 2 |
| 7891 | gatería | 2 |
| 7892 | gárrulo | 2 |
| 7893 | garrote | 2 |
| 7894 | garrafal | 2 |
| 7895 | garbo | 2 |
| 7896 | garantía | 2 |
| 7897 | gancho | 2 |
| 7898 | ganado | 2 |
| 7899 | gama | 2 |
| 7900 | gallardía | 2 |
| 7901 | galápago | 2 |
| 7902 | galantería | 2 |
| 7903 | gaita | 2 |
| 7904 | gabacho | 2 |
| 7905 | funeral | 2 |
| 7906 | fundir | 2 |
| 7907 | fundamentar | 2 |
| 7908 | fundación | 2 |
| 7909 | fugar | 2 |
| 7910 | fuertecillo | 2 |
| 7911 | fuer | 2 |
| 7912 | fuelle | 2 |
| 7913 | frustrar | 2 |
| 7914 | fruncimiento | 2 |
| 7915 | frontal | 2 |
| 7916 | friega | 2 |
| 7917 | frescachón | 2 |
| 7918 | fresar | 2 |
| 7919 | fray | 2 |
| 7920 | francesilla | 2 |
| 7921 | frac | 2 |
| 7922 | fotografiar | 2 |
| 7923 | fosfato | 2 |
| 7924 | forzosamente | 2 |
| 7925 | fortísimo | 2 |
| 7926 | forraje | 2 |
| 7927 | fornos | 2 |
| 7928 | fornido | 2 |
| 7929 | formalito | 2 |
| 7930 | forjar | 2 |
| 7931 | forcejear | 2 |
| 7932 | foco | 2 |
| 7933 | fluir | 2 |
| 7934 | fluctuar | 2 |
| 7935 | flotante | 2 |
| 7936 | florín | 2 |
| 7937 | florear | 2 |
| 7938 | flojilla | 2 |
| 7939 | flequillo | 2 |
| 7940 | flamenco | 2 |
| 7941 | fisiológico | 2 |
| 7942 | física | 2 |
| 7943 | fisgón | 2 |
| 7944 | firmemente | 2 |
| 7945 | finito | 2 |
| 7946 | filigrana | 2 |
| 7947 | filar | 2 |
| 7948 | fijose | 2 |
| 7949 | fijeza | 2 |
| 7950 | figurita | 2 |
| 7951 | figúrese | 2 |
| 7952 | fieltro | 2 |
| 7953 | feudal | 2 |
| 7954 | festín | 2 |
| 7955 | ferretero | 2 |
| 7956 | felicitación | 2 |
| 7957 | felicísimo | 2 |
| 7958 | fecundidad | 2 |
| 7959 | favorecido | 2 |
| 7960 | fatuo | 2 |
| 7961 | fatídico | 2 |
| 7962 | fastidioso | 2 |
| 7963 | fascinar | 2 |
| 7964 | faro | 2 |
| 7965 | fanfarronada | 2 |
| 7966 | fandango | 2 |
| 7967 | familiarmente | 2 |
| 7968 | faltábale | 2 |
| 7969 | fallir | 2 |
| 7970 | faja | 2 |
| 7971 | facturar | 2 |
| 7972 | faceta | 2 |
| 7973 | fabulista | 2 |
| 7974 | fabricación | 2 |
| 7975 | extremeño | 2 |
| 7976 | extremado | 2 |
| 7977 | extraviado | 2 |
| 7978 | extinguido | 2 |
| 7979 | exterminio | 2 |
| 7980 | extenso | 2 |
| 7981 | expulsión | 2 |
| 7982 | exposición | 2 |
| 7983 | explotación | 2 |
| 7984 | explayar | 2 |
| 7985 | expiar | 2 |
| 7986 | experto | 2 |
| 7987 | experimento | 2 |
| 7988 | expeditivo | 2 |
| 7989 | expedir | 2 |
| 7990 | expedición | 2 |
| 7991 | eximio | 2 |
| 7992 | exhortación | 2 |
| 7993 | exhibir | 2 |
| 7994 | execrable | 2 |
| 7995 | excusa | 2 |
| 7996 | excursionar | 2 |
| 7997 | exclamaba | 2 |
| 7998 | excepcional | 2 |
| 7999 | excelencia | 2 |
| 8000 | eucaristía | 2 |
| 8001 | etiquetar | 2 |
| 8002 | etéreo | 2 |
| 8003 | estúpidamente | 2 |
| 8004 | estropajoso | 2 |
| 8005 | estricnina | 2 |
| 8006 | estribo | 2 |
| 8007 | estrangular | 2 |
| 8008 | estrago | 2 |
| 8009 | estragado | 2 |
| 8010 | estornudo | 2 |
| 8011 | estoico | 2 |
| 8012 | estocada | 2 |
| 8013 | estirpe | 2 |
| 8014 | estirado | 2 |
| 8015 | estímulo | 2 |
| 8016 | estima | 2 |
| 8017 | estiércol | 2 |
| 8018 | estertor | 2 |
| 8019 | estéril | 2 |
| 8020 | estático | 2 |
| 8021 | estate | 2 |
| 8022 | estarcido | 2 |
| 8023 | estarás | 2 |
| 8024 | estará | 2 |
| 8025 | estafa | 2 |
| 8026 | estacionar | 2 |
| 8027 | espumarajo | 2 |
| 8028 | espliego | 2 |
| 8029 | espiritualmente | 2 |
| 8030 | espiral | 2 |
| 8031 | espionaje | 2 |
| 8032 | espina | 2 |
| 8033 | espichar | 2 |
| 8034 | esperaré | 2 |
| 8035 | espasmo | 2 |
| 8036 | esparteros | 2 |
| 8037 | espantable | 2 |
| 8038 | eslabón | 2 |
| 8039 | esférico | 2 |
| 8040 | esfera | 2 |
| 8041 | esencialmente | 2 |
| 8042 | escueto | 2 |
| 8043 | escudar | 2 |
| 8044 | escrutinio | 2 |
| 8045 | escrutador | 2 |
| 8046 | escondidos | 2 |
| 8047 | escombro | 2 |
| 8048 | escolta | 2 |
| 8049 | esclavizar | 2 |
| 8050 | esclavina | 2 |
| 8051 | escepticismo | 2 |
| 8052 | escenario | 2 |
| 8053 | escayola | 2 |
| 8054 | escasear | 2 |
| 8055 | escarbar | 2 |
| 8056 | escapada | 2 |
| 8057 | escandalosa | 2 |
| 8058 | escamotear | 2 |
| 8059 | escamar | 2 |
| 8060 | escabechar | 2 |
| 8061 | esbelto | 2 |
| 8062 | erizado | 2 |
| 8063 | eran | 2 |
| 8064 | equipo | 2 |
| 8065 | equidad | 2 |
| 8066 | epístola | 2 |
| 8067 | epidermis | 2 |
| 8068 | enviciar | 2 |
| 8069 | entrecortar | 2 |
| 8070 | entráronle | 2 |
| 8071 | entrabar | 2 |
| 8072 | entonación | 2 |
| 8073 | ensueño | 2 |
| 8074 | ensordecer | 2 |
| 8075 | ensoberbecer | 2 |
| 8076 | ensayar | 2 |
| 8077 | ensalzar | 2 |
| 8078 | ensalmo | 2 |
| 8079 | ensaladera | 2 |
| 8080 | enrojecer | 2 |
| 8081 | enriquecer | 2 |
| 8082 | enorgullecer | 2 |
| 8083 | enojado | 2 |
| 8084 | enmudecer | 2 |
| 8085 | enlutar | 2 |
| 8086 | enjambre | 2 |
| 8087 | enhebrar | 2 |
| 8088 | engrudo | 2 |
| 8089 | engrosar | 2 |
| 8090 | engolfar | 2 |
| 8091 | engendrar | 2 |
| 8092 | enganchar | 2 |
| 8093 | engalanar | 2 |
| 8094 | enfado | 2 |
| 8095 | enea | 2 |
| 8096 | endurecido | 2 |
| 8097 | endulzar | 2 |
| 8098 | endemoniar | 2 |
| 8099 | encopetado | 2 |
| 8100 | encontradizo | 2 |
| 8101 | encomendar | 2 |
| 8102 | encogido | 2 |
| 8103 | encharcar | 2 |
| 8104 | encerrose | 2 |
| 8105 | encarecer | 2 |
| 8106 | encaprichar | 2 |
| 8107 | encantador | 2 |
| 8108 | encanijar | 2 |
| 8109 | encanallar | 2 |
| 8110 | encamar | 2 |
| 8111 | encadenamiento | 2 |
| 8112 | empujón | 2 |
| 8113 | empréstito | 2 |
| 8114 | emprendedor | 2 |
| 8115 | empobrecer | 2 |
| 8116 | emplastar | 2 |
| 8117 | emperejilar | 2 |
| 8118 | empeorar | 2 |
| 8119 | empedrar | 2 |
| 8120 | empedrado | 2 |
| 8121 | empedernir | 2 |
| 8122 | empalmar | 2 |
| 8123 | emitir | 2 |
| 8124 | emético | 2 |
| 8125 | embrutecimiento | 2 |
| 8126 | embrujar | 2 |
| 8127 | embocar | 2 |
| 8128 | embobar | 2 |
| 8129 | embestida | 2 |
| 8130 | embeleso | 2 |
| 8131 | embelesado | 2 |
| 8132 | embarcación | 2 |
| 8133 | embajada | 2 |
| 8134 | embadurnar | 2 |
| 8135 | elevado | 2 |
| 8136 | electoral | 2 |
| 8137 | elástico | 2 |
| 8138 | elaborar | 2 |
| 8139 | ejemplaridad | 2 |
| 8140 | ejecutivo | 2 |
| 8141 | ejecutar | 2 |
| 8142 | egoistón | 2 |
| 8143 | egoísta | 2 |
| 8144 | egipto | 2 |
| 8145 | efigie | 2 |
| 8146 | eficacia | 2 |
| 8147 | edredón | 2 |
| 8148 | editor | 2 |
| 8149 | economista | 2 |
| 8150 | echábaselas | 2 |
| 8151 | duramente | 2 |
| 8152 | duérmete | 2 |
| 8153 | duchar | 2 |
| 8154 | doscientas | 2 |
| 8155 | dorregaray | 2 |
| 8156 | dormilón | 2 |
| 8157 | domesticar | 2 |
| 8158 | docto | 2 |
| 8159 | docilidad | 2 |
| 8160 | dócil | 2 |
| 8161 | doceno | 2 |
| 8162 | doblez | 2 |
| 8163 | divorciar | 2 |
| 8164 | dividendo | 2 |
| 8165 | disuadir | 2 |
| 8166 | distintivo | 2 |
| 8167 | dispersar | 2 |
| 8168 | dispepsia | 2 |
| 8169 | disparidad | 2 |
| 8170 | disparado | 2 |
| 8171 | disparadero | 2 |
| 8172 | disfavor | 2 |
| 8173 | discrepar | 2 |
| 8174 | disciplinario | 2 |
| 8175 | diríale | 2 |
| 8176 | diretes | 2 |
| 8177 | dirá | 2 |
| 8178 | dimisión | 2 |
| 8179 | diminutivo | 2 |
| 8180 | dimes | 2 |
| 8181 | dilema | 2 |
| 8182 | díjome | 2 |
| 8183 | dígole | 2 |
| 8184 | difuso | 2 |
| 8185 | diego | 2 |
| 8186 | diciéndolo | 2 |
| 8187 | diapasón | 2 |
| 8188 | deudo | 2 |
| 8189 | detuviéronse | 2 |
| 8190 | detenidamente | 2 |
| 8191 | detallar | 2 |
| 8192 | desvergonzar | 2 |
| 8193 | desventaja | 2 |
| 8194 | desvalido | 2 |
| 8195 | destreza | 2 |
| 8196 | destilar | 2 |
| 8197 | desquiciar | 2 |
| 8198 | despuntar | 2 |
| 8199 | desprestigiar | 2 |
| 8200 | despreciable | 2 |
| 8201 | despótico | 2 |
| 8202 | déspota | 2 |
| 8203 | desposar | 2 |
| 8204 | despojar | 2 |
| 8205 | despidiéronse | 2 |
| 8206 | desperezar | 2 |
| 8207 | desperdicio | 2 |
| 8208 | despejo | 2 |
| 8209 | despeinado | 2 |
| 8210 | despego | 2 |
| 8211 | despegar | 2 |
| 8212 | despedazar | 2 |
| 8213 | desparpajar | 2 |
| 8214 | desorientar | 2 |
| 8215 | desolación | 2 |
| 8216 | desocupar | 2 |
| 8217 | desmañado | 2 |
| 8218 | deslumbrar | 2 |
| 8219 | deslomar | 2 |
| 8220 | desligar | 2 |
| 8221 | desliar | 2 |
| 8222 | desleír | 2 |
| 8223 | deslealtad | 2 |
| 8224 | desinteresado | 2 |
| 8225 | desilusión | 2 |
| 8226 | deshonroso | 2 |
| 8227 | desgastar | 2 |
| 8228 | desgarrado | 2 |
| 8229 | desgarbado | 2 |
| 8230 | desgajar | 2 |
| 8231 | desgaire | 2 |
| 8232 | desentumecer | 2 |
| 8233 | desenroscar | 2 |
| 8234 | desenojar | 2 |
| 8235 | desengaño | 2 |
| 8236 | desecho | 2 |
| 8237 | desdoblar | 2 |
| 8238 | descrédito | 2 |
| 8239 | descortés | 2 |
| 8240 | descorrer | 2 |
| 8241 | descorazonar | 2 |
| 8242 | descontar | 2 |
| 8243 | desconcertado | 2 |
| 8244 | descomunal | 2 |
| 8245 | descolorido | 2 |
| 8246 | descendiente | 2 |
| 8247 | descendencia | 2 |
| 8248 | descaro | 2 |
| 8249 | descarga | 2 |
| 8250 | descaradamente | 2 |
| 8251 | desbordamiento | 2 |
| 8252 | desbarrar | 2 |
| 8253 | desbandar | 2 |
| 8254 | desavenencia | 2 |
| 8255 | desastroso | 2 |
| 8256 | desastre | 2 |
| 8257 | desasosegado | 2 |
| 8258 | desarreglar | 2 |
| 8259 | desamparado | 2 |
| 8260 | desafinar | 2 |
| 8261 | desacreditar | 2 |
| 8262 | derrumbar | 2 |
| 8263 | derrotar | 2 |
| 8264 | derrota | 2 |
| 8265 | derribo | 2 |
| 8266 | derretir | 2 |
| 8267 | derredor | 2 |
| 8268 | derogar | 2 |
| 8269 | depresión | 2 |
| 8270 | depreciación | 2 |
| 8271 | deplorar | 2 |
| 8272 | denuncia | 2 |
| 8273 | denso | 2 |
| 8274 | denominación | 2 |
| 8275 | demudar | 2 |
| 8276 | deme | 2 |
| 8277 | demagogia | 2 |
| 8278 | delineante | 2 |
| 8279 | delicadísimo | 2 |
| 8280 | dejándose | 2 |
| 8281 | déjale | 2 |
| 8282 | degradación | 2 |
| 8283 | degollar | 2 |
| 8284 | deformar | 2 |
| 8285 | definitivamente | 2 |
| 8286 | definición | 2 |
| 8287 | decretar | 2 |
| 8288 | dechado | 2 |
| 8289 | decálogo | 2 |
| 8290 | decaimiento | 2 |
| 8291 | decadencia | 2 |
| 8292 | debió | 2 |
| 8293 | debí | 2 |
| 8294 | dardo | 2 |
| 8295 | dañado | 2 |
| 8296 | danzar | 2 |
| 8297 | danza | 2 |
| 8298 | dámele | 2 |
| 8299 | dádiva | 2 |
| 8300 | da | 2 |
| 8301 | cutis | 2 |
| 8302 | curtis | 2 |
| 8303 | curtido | 2 |
| 8304 | cuota | 2 |
| 8305 | cúmulo | 2 |
| 8306 | cultura | 2 |
| 8307 | cuervo | 2 |
| 8308 | cuéntame | 2 |
| 8309 | cucurucho | 2 |
| 8310 | cubo | 2 |
| 8311 | cubilete | 2 |
| 8312 | cubierta | 2 |
| 8313 | cuarentena | 2 |
| 8314 | cuánta | 2 |
| 8315 | cuajarón | 2 |
| 8316 | cuadrilátero | 2 |
| 8317 | cuadernillo | 2 |
| 8318 | cruzada | 2 |
| 8319 | crucero | 2 |
| 8320 | cristina | 2 |
| 8321 | creyó | 2 |
| 8322 | créeme | 2 |
| 8323 | creciente | 2 |
| 8324 | créalo | 2 |
| 8325 | creación | 2 |
| 8326 | crea | 2 |
| 8327 | craso | 2 |
| 8328 | cotarro | 2 |
| 8329 | costurero | 2 |
| 8330 | corvo | 2 |
| 8331 | cortadillo | 2 |
| 8332 | corrupción | 2 |
| 8333 | corretear | 2 |
| 8334 | corredera | 2 |
| 8335 | correctamente | 2 |
| 8336 | correccional | 2 |
| 8337 | corporación | 2 |
| 8338 | corpacho | 2 |
| 8339 | cornisa | 2 |
| 8340 | cornezuelo | 2 |
| 8341 | cordón | 2 |
| 8342 | córdoba | 2 |
| 8343 | cordel | 2 |
| 8344 | corcho | 2 |
| 8345 | copita | 2 |
| 8346 | copioso | 2 |
| 8347 | cónyuge | 2 |
| 8348 | conviene | 2 |
| 8349 | conveníale | 2 |
| 8350 | convencido | 2 |
| 8351 | convaleciente | 2 |
| 8352 | convalecencia | 2 |
| 8353 | contusionar | 2 |
| 8354 | contusión | 2 |
| 8355 | controversia | 2 |
| 8356 | contrincante | 2 |
| 8357 | contrición | 2 |
| 8358 | contribuir | 2 |
| 8359 | contrata | 2 |
| 8360 | contrasentido | 2 |
| 8361 | contorsionar | 2 |
| 8362 | contorsión | 2 |
| 8363 | contole | 2 |
| 8364 | contemplativo | 2 |
| 8365 | contagio | 2 |
| 8366 | contador | 2 |
| 8367 | contabilidad | 2 |
| 8368 | consulta | 2 |
| 8369 | constructivo | 2 |
| 8370 | constitutivo | 2 |
| 8371 | constipar | 2 |
| 8372 | conspiración | 2 |
| 8373 | conservatorio | 2 |
| 8374 | conservarse | 2 |
| 8375 | consagración | 2 |
| 8376 | conozco | 2 |
| 8377 | conmovedor | 2 |
| 8378 | conmoción | 2 |
| 8379 | conmiseración | 2 |
| 8380 | conllevar | 2 |
| 8381 | congregar | 2 |
| 8382 | congojar | 2 |
| 8383 | confrontar | 2 |
| 8384 | confortar | 2 |
| 8385 | configuración | 2 |
| 8386 | confidente | 2 |
| 8387 | conductor | 2 |
| 8388 | condiciones | 2 |
| 8389 | condescendencia | 2 |
| 8390 | concubinato | 2 |
| 8391 | concreto | 2 |
| 8392 | concretar | 2 |
| 8393 | concordar | 2 |
| 8394 | conciliación | 2 |
| 8395 | concentrar | 2 |
| 8396 | cóncavo | 2 |
| 8397 | concavidad | 2 |
| 8398 | conato | 2 |
| 8399 | compungir | 2 |
| 8400 | comprimir | 2 |
| 8401 | componenda | 2 |
| 8402 | complicidad | 2 |
| 8403 | complaciente | 2 |
| 8404 | compinchar | 2 |
| 8405 | compenetrar | 2 |
| 8406 | comparsa | 2 |
| 8407 | comparativo | 2 |
| 8408 | cómoda | 2 |
| 8409 | comisionar | 2 |
| 8410 | comienzo | 2 |
| 8411 | cometido | 2 |
| 8412 | cometa | 2 |
| 8413 | comenzar | 2 |
| 8414 | comentar | 2 |
| 8415 | comediante | 2 |
| 8416 | comedero | 2 |
| 8417 | columbrar | 2 |
| 8418 | colorista | 2 |
| 8419 | colina | 2 |
| 8420 | colgado | 2 |
| 8421 | coleto | 2 |
| 8422 | colegir | 2 |
| 8423 | cojo | 2 |
| 8424 | cojita | 2 |
| 8425 | cojear | 2 |
| 8426 | coincidir | 2 |
| 8427 | cohonestar | 2 |
| 8428 | cohibido | 2 |
| 8429 | codear | 2 |
| 8430 | cocinilla | 2 |
| 8431 | cochino | 2 |
| 8432 | clínica | 2 |
| 8433 | claustral | 2 |
| 8434 | claraboya | 2 |
| 8435 | clamó | 2 |
| 8436 | civilizar | 2 |
| 8437 | civilizado | 2 |
| 8438 | cisterna | 2 |
| 8439 | cirio | 2 |
| 8440 | cinismo | 2 |
| 8441 | cielos | 2 |
| 8442 | ciegamente | 2 |
| 8443 | chusma | 2 |
| 8444 | chumbo | 2 |
| 8445 | chufa | 2 |
| 8446 | chubasco | 2 |
| 8447 | chocolatera | 2 |
| 8448 | chocante | 2 |
| 8449 | chispita | 2 |
| 8450 | chispeante | 2 |
| 8451 | chinito | 2 |
| 8452 | chilló | 2 |
| 8453 | chillería | 2 |
| 8454 | chiflado | 2 |
| 8455 | chi | 2 |
| 8456 | cheong | 2 |
| 8457 | chasquear | 2 |
| 8458 | charol | 2 |
| 8459 | charlatán | 2 |
| 8460 | charca | 2 |
| 8461 | chaqué | 2 |
| 8462 | chapuzar | 2 |
| 8463 | chanchullo | 2 |
| 8464 | chamusquina | 2 |
| 8465 | chalana | 2 |
| 8466 | cháchara | 2 |
| 8467 | cevil | 2 |
| 8468 | ceuta | 2 |
| 8469 | cesantía | 2 |
| 8470 | cervantes | 2 |
| 8471 | certidumbre | 2 |
| 8472 | certeza | 2 |
| 8473 | cerradura | 2 |
| 8474 | cerrados | 2 |
| 8475 | ceremonioso | 2 |
| 8476 | cerco | 2 |
| 8477 | cepillo | 2 |
| 8478 | centigramo | 2 |
| 8479 | centeno | 2 |
| 8480 | cencerrada | 2 |
| 8481 | celeste | 2 |
| 8482 | celebridad | 2 |
| 8483 | celaje | 2 |
| 8484 | celador | 2 |
| 8485 | cejijunto | 2 |
| 8486 | ceca | 2 |
| 8487 | caviloso | 2 |
| 8488 | cavador | 2 |
| 8489 | cautelar | 2 |
| 8490 | causante | 2 |
| 8491 | caudillo | 2 |
| 8492 | caudaloso | 2 |
| 8493 | categóricamente | 2 |
| 8494 | catarroso | 2 |
| 8495 | catálogo | 2 |
| 8496 | catadura | 2 |
| 8497 | castidad | 2 |
| 8498 | castellano | 2 |
| 8499 | castaño | 2 |
| 8500 | casino | 2 |
| 8501 | casillero | 2 |
| 8502 | casilla | 2 |
| 8503 | cascabel | 2 |
| 8504 | casarme | 2 |
| 8505 | casada | 2 |
| 8506 | cartucho | 2 |
| 8507 | cartero | 2 |
| 8508 | carros | 2 |
| 8509 | carretas | 2 |
| 8510 | carpintero | 2 |
| 8511 | carpeta | 2 |
| 8512 | carpanta | 2 |
| 8513 | carlismo | 2 |
| 8514 | cariz | 2 |
| 8515 | caricaturar | 2 |
| 8516 | caribe | 2 |
| 8517 | cargante | 2 |
| 8518 | cargamento | 2 |
| 8519 | cardo | 2 |
| 8520 | cárdenas | 2 |
| 8521 | cardenal | 2 |
| 8522 | carbonera | 2 |
| 8523 | carátula | 2 |
| 8524 | carantoña | 2 |
| 8525 | caracterizar | 2 |
| 8526 | cápsula | 2 |
| 8527 | caprichoso | 2 |
| 8528 | capón | 2 |
| 8529 | capitana | 2 |
| 8530 | capitán | 2 |
| 8531 | capitalista | 2 |
| 8532 | capacidad | 2 |
| 8533 | caoba | 2 |
| 8534 | cañamón | 2 |
| 8535 | cantante | 2 |
| 8536 | candorosamente | 2 |
| 8537 | candidez | 2 |
| 8538 | candelero | 2 |
| 8539 | candelabro | 2 |
| 8540 | canciller | 2 |
| 8541 | canal | 2 |
| 8542 | campar | 2 |
| 8543 | campante | 2 |
| 8544 | campanillazo | 2 |
| 8545 | camisería | 2 |
| 8546 | camelia | 2 |
| 8547 | cambiante | 2 |
| 8548 | camarero | 2 |
| 8549 | camarada | 2 |
| 8550 | calzonazos | 2 |
| 8551 | calza | 2 |
| 8552 | calvario | 2 |
| 8553 | caluroso | 2 |
| 8554 | calumniador | 2 |
| 8555 | calumnia | 2 |
| 8556 | callosa | 2 |
| 8557 | calificar | 2 |
| 8558 | calandria | 2 |
| 8559 | calambre | 2 |
| 8560 | calabozo | 2 |
| 8561 | caín | 2 |
| 8562 | cafre | 2 |
| 8563 | cachorro | 2 |
| 8564 | cacerola | 2 |
| 8565 | cacarear | 2 |
| 8566 | cabildo | 2 |
| 8567 | caballete | 2 |
| 8568 | caballerosidad | 2 |
| 8569 | cabal | 2 |
| 8570 | buscón | 2 |
| 8571 | burocrático | 2 |
| 8572 | burdo | 2 |
| 8573 | bullicioso | 2 |
| 8574 | bullanga | 2 |
| 8575 | bular | 2 |
| 8576 | bujía | 2 |
| 8577 | buey | 2 |
| 8578 | buenavista | 2 |
| 8579 | budista | 2 |
| 8580 | buche | 2 |
| 8581 | búcaro | 2 |
| 8582 | brutalidad | 2 |
| 8583 | bronca | 2 |
| 8584 | brocal | 2 |
| 8585 | brocado | 2 |
| 8586 | brindis | 2 |
| 8587 | brincar | 2 |
| 8588 | brígida | 2 |
| 8589 | bribona | 2 |
| 8590 | brevemente | 2 |
| 8591 | brazos | 2 |
| 8592 | bravura | 2 |
| 8593 | bozo | 2 |
| 8594 | botonadura | 2 |
| 8595 | botarate | 2 |
| 8596 | botaratada | 2 |
| 8597 | borrego | 2 |
| 8598 | borrachera | 2 |
| 8599 | borla | 2 |
| 8600 | bordado | 2 |
| 8601 | boquete | 2 |
| 8602 | boquear | 2 |
| 8603 | bono | 2 |
| 8604 | bonísimo | 2 |
| 8605 | bombo | 2 |
| 8606 | bolsista | 2 |
| 8607 | bollo | 2 |
| 8608 | bojío | 2 |
| 8609 | bofe | 2 |
| 8610 | bocaza | 2 |
| 8611 | bobería | 2 |
| 8612 | bobalicón | 2 |
| 8613 | bizma | 2 |
| 8614 | bizcocho | 2 |
| 8615 | biografía | 2 |
| 8616 | billar | 2 |
| 8617 | bierzo | 2 |
| 8618 | bienestar | 2 |
| 8619 | bienaventurado | 2 |
| 8620 | bienandanza | 2 |
| 8621 | besuquear | 2 |
| 8622 | berrinche | 2 |
| 8623 | bernardino | 2 |
| 8624 | bermellón | 2 |
| 8625 | bermejo | 2 |
| 8626 | berlina | 2 |
| 8627 | bellota | 2 |
| 8628 | bellísimo | 2 |
| 8629 | béjar | 2 |
| 8630 | beethoven | 2 |
| 8631 | bedmar | 2 |
| 8632 | beatriz | 2 |
| 8633 | beato | 2 |
| 8634 | bazofia | 2 |
| 8635 | batidor | 2 |
| 8636 | batería | 2 |
| 8637 | batallar | 2 |
| 8638 | basurero | 2 |
| 8639 | bastidor | 2 |
| 8640 | basilisco | 2 |
| 8641 | basar | 2 |
| 8642 | barrionuevo | 2 |
| 8643 | barrabás | 2 |
| 8644 | barbarie | 2 |
| 8645 | bando | 2 |
| 8646 | banderilla | 2 |
| 8647 | bandada | 2 |
| 8648 | banasta | 2 |
| 8649 | baldosa | 2 |
| 8650 | baldar | 2 |
| 8651 | balbuciente | 2 |
| 8652 | balar | 2 |
| 8653 | balanza | 2 |
| 8654 | balandrán | 2 |
| 8655 | balancín | 2 |
| 8656 | bajó | 2 |
| 8657 | bajeza | 2 |
| 8658 | badulaque | 2 |
| 8659 | babilla | 2 |
| 8660 | azulear | 2 |
| 8661 | azular | 2 |
| 8662 | azucarado | 2 |
| 8663 | azorado | 2 |
| 8664 | ayudante | 2 |
| 8665 | ayúdame | 2 |
| 8666 | avisado | 2 |
| 8667 | avío | 2 |
| 8668 | ávido | 2 |
| 8669 | averiguador | 2 |
| 8670 | averiguación | 2 |
| 8671 | avergonzado | 2 |
| 8672 | aventurero | 2 |
| 8673 | aventajar | 2 |
| 8674 | autocrático | 2 |
| 8675 | auscultar | 2 |
| 8676 | aumento | 2 |
| 8677 | aturdimiento | 2 |
| 8678 | atropello | 2 |
| 8679 | atropellado | 2 |
| 8680 | atrio | 2 |
| 8681 | atribuir | 2 |
| 8682 | atrapar | 2 |
| 8683 | atracar | 2 |
| 8684 | atolladero | 2 |
| 8685 | atinado | 2 |
| 8686 | atildar | 2 |
| 8687 | atestiguar | 2 |
| 8688 | aterrorizar | 2 |
| 8689 | atenuación | 2 |
| 8690 | atento | 2 |
| 8691 | atentado | 2 |
| 8692 | atemperar | 2 |
| 8693 | ataviar | 2 |
| 8694 | atascar | 2 |
| 8695 | atarugar | 2 |
| 8696 | atarear | 2 |
| 8697 | atadero | 2 |
| 8698 | asturiano | 2 |
| 8699 | astucia | 2 |
| 8700 | astro | 2 |
| 8701 | astorga | 2 |
| 8702 | aspar | 2 |
| 8703 | asomo | 2 |
| 8704 | asomáronse | 2 |
| 8705 | asignar | 2 |
| 8706 | asiduo | 2 |
| 8707 | aseveración | 2 |
| 8708 | asentador | 2 |
| 8709 | asemejar | 2 |
| 8710 | asechanza | 2 |
| 8711 | ascenso | 2 |
| 8712 | asar | 2 |
| 8713 | articulación | 2 |
| 8714 | arruga | 2 |
| 8715 | arrope | 2 |
| 8716 | arropar | 2 |
| 8717 | arrollar | 2 |
| 8718 | arrobamiento | 2 |
| 8719 | arriero | 2 |
| 8720 | arrepiéntete | 2 |
| 8721 | arreo | 2 |
| 8722 | arreglador | 2 |
| 8723 | arreglado | 2 |
| 8724 | arramblar | 2 |
| 8725 | arquitectónico | 2 |
| 8726 | arqueo | 2 |
| 8727 | armonioso | 2 |
| 8728 | armatoste | 2 |
| 8729 | armadura | 2 |
| 8730 | armado | 2 |
| 8731 | armada | 2 |
| 8732 | aristócrata | 2 |
| 8733 | argentino | 2 |
| 8734 | arganzuela | 2 |
| 8735 | arengar | 2 |
| 8736 | ardid | 2 |
| 8737 | arcón | 2 |
| 8738 | árbitro | 2 |
| 8739 | arbitrio | 2 |
| 8740 | ara | 2 |
| 8741 | aquiescencia | 2 |
| 8742 | aquello | 2 |
| 8743 | aquella | 2 |
| 8744 | apuntalar | 2 |
| 8745 | apuesta | 2 |
| 8746 | aprisita | 2 |
| 8747 | aprisionar | 2 |
| 8748 | aprensivo | 2 |
| 8749 | apodo | 2 |
| 8750 | aplomo | 2 |
| 8751 | aplomar | 2 |
| 8752 | aplazar | 2 |
| 8753 | aplanar | 2 |
| 8754 | apilado | 2 |
| 8755 | apelmazar | 2 |
| 8756 | apear | 2 |
| 8757 | apasionar | 2 |
| 8758 | apartamiento | 2 |
| 8759 | aparejo | 2 |
| 8760 | aparador | 2 |
| 8761 | apagado | 2 |
| 8762 | añejo | 2 |
| 8763 | anzuelo | 2 |
| 8764 | anticuado | 2 |
| 8765 | anticipado | 2 |
| 8766 | antepecho | 2 |
| 8767 | antecesor | 2 |
| 8768 | antecedente | 2 |
| 8769 | anteayer | 2 |
| 8770 | ansiar | 2 |
| 8771 | anís | 2 |
| 8772 | aniquilar | 2 |
| 8773 | ánima | 2 |
| 8774 | anillo | 2 |
| 8775 | anidar | 2 |
| 8776 | anhelante | 2 |
| 8777 | angustias | 2 |
| 8778 | anguloso | 2 |
| 8779 | angelote | 2 |
| 8780 | angelón | 2 |
| 8781 | anémico | 2 |
| 8782 | andrómina | 2 |
| 8783 | andrea | 2 |
| 8784 | andrajoso | 2 |
| 8785 | ande | 2 |
| 8786 | andanada | 2 |
| 8787 | andana | 2 |
| 8788 | andamiaje | 2 |
| 8789 | andado | 2 |
| 8790 | anatomía | 2 |
| 8791 | anacoreta | 2 |
| 8792 | amueblar | 2 |
| 8793 | ampliación | 2 |
| 8794 | amortajar | 2 |
| 8795 | amilanar | 2 |
| 8796 | amiguita | 2 |
| 8797 | américa | 2 |
| 8798 | amenizar | 2 |
| 8799 | amenguar | 2 |
| 8800 | ambicioso | 2 |
| 8801 | amazona | 2 |
| 8802 | amancebamiento | 2 |
| 8803 | aludir | 2 |
| 8804 | alpargata | 2 |
| 8805 | almendrar | 2 |
| 8806 | almacenes | 2 |
| 8807 | alinear | 2 |
| 8808 | alimaña | 2 |
| 8809 | algunas | 2 |
| 8810 | alguna | 2 |
| 8811 | algarrobo | 2 |
| 8812 | alfombra | 2 |
| 8813 | aletargado | 2 |
| 8814 | alero | 2 |
| 8815 | alejandro | 2 |
| 8816 | alegar | 2 |
| 8817 | alcoy | 2 |
| 8818 | alcázar | 2 |
| 8819 | alcantarilla | 2 |
| 8820 | albricias | 2 |
| 8821 | alborozo | 2 |
| 8822 | albo | 2 |
| 8823 | albergue | 2 |
| 8824 | alarma | 2 |
| 8825 | alarido | 2 |
| 8826 | ajusticiar | 2 |
| 8827 | ajajá | 2 |
| 8828 | aislar | 2 |
| 8829 | aislamiento | 2 |
| 8830 | airado | 2 |
| 8831 | ahorita | 2 |
| 8832 | ahorcar | 2 |
| 8833 | águila | 2 |
| 8834 | aguas | 2 |
| 8835 | agrícola | 2 |
| 8836 | agriar | 2 |
| 8837 | agresión | 2 |
| 8838 | agradábale | 2 |
| 8839 | agosto | 2 |
| 8840 | agonizante | 2 |
| 8841 | agitado | 2 |
| 8842 | afueras | 2 |
| 8843 | afortunadamente | 2 |
| 8844 | aflictivo | 2 |
| 8845 | afianzar | 2 |
| 8846 | afeitado | 2 |
| 8847 | afectado | 2 |
| 8848 | afectación | 2 |
| 8849 | adular | 2 |
| 8850 | adoquinar | 2 |
| 8851 | adjudicar | 2 |
| 8852 | adherir | 2 |
| 8853 | adelgazar | 2 |
| 8854 | adelanto | 2 |
| 8855 | adecuar | 2 |
| 8856 | adecuado | 2 |
| 8857 | acusado | 2 |
| 8858 | acurrucar | 2 |
| 8859 | acuarela | 2 |
| 8860 | actuar | 2 |
| 8861 | acribillar | 2 |
| 8862 | acostose | 2 |
| 8863 | acostáronse | 2 |
| 8864 | acorralar | 2 |
| 8865 | acordeón | 2 |
| 8866 | acorde | 2 |
| 8867 | acoquinar | 2 |
| 8868 | acompañante | 2 |
| 8869 | acólito | 2 |
| 8870 | acogotar | 2 |
| 8871 | acierto | 2 |
| 8872 | acíbar | 2 |
| 8873 | achantar | 2 |
| 8874 | acerté | 2 |
| 8875 | acercábase | 2 |
| 8876 | aceptable | 2 |
| 8877 | accidental | 2 |
| 8878 | accidentado | 2 |
| 8879 | acatar | 2 |
| 8880 | academia | 2 |
| 8881 | acabamiento | 2 |
| 8882 | abyección | 2 |
| 8883 | abuso | 2 |
| 8884 | abundamiento | 2 |
| 8885 | abstraído | 2 |
| 8886 | absolver | 2 |
| 8887 | abrochar | 2 |
| 8888 | abriose | 2 |
| 8889 | abrígate | 2 |
| 8890 | abra | 2 |
| 8891 | abordar | 2 |
| 8892 | abolir | 2 |
| 8893 | abolición | 2 |
| 8894 | abogado | 2 |
| 8895 | zurriago | 1 |
| 8896 | zurcido | 1 |
| 8897 | zumo | 1 |
| 8898 | zumbón | 1 |
| 8899 | zumbar | 1 |
| 8900 | zozobrar | 1 |
| 8901 | zote | 1 |
| 8902 | zoquetes | 1 |
| 8903 | zoquete | 1 |
| 8904 | zopenco | 1 |
| 8905 | zascandil | 1 |
| 8906 | zarzal | 1 |
| 8907 | zarandaja | 1 |
| 8908 | zapateado | 1 |
| 8909 | zapata | 1 |
| 8910 | zancadilla | 1 |
| 8911 | zanahoria | 1 |
| 8912 | zampa | 1 |
| 8913 | zamorano | 1 |
| 8914 | zambullida | 1 |
| 8915 | zambombazo | 1 |
| 8916 | zamarra | 1 |
| 8917 | zahorí | 1 |
| 8918 | zagalón | 1 |
| 8919 | zafar | 1 |
| 8920 | zacarías | 1 |
| 8921 | yesería | 1 |
| 8922 | yerno | 1 |
| 8923 | yermar | 1 |
| 8924 | xv | 1 |
| 8925 | xix | 1 |
| 8926 | xiv | 1 |
| 8927 | xiii | 1 |
| 8928 | wellington | 1 |
| 8929 | wamba | 1 |
| 8930 | vusté | 1 |
| 8931 | vuelvo | 1 |
| 8932 | vuélvete | 1 |
| 8933 | vuelve | 1 |
| 8934 | vuelva | 1 |
| 8935 | vuelco | 1 |
| 8936 | votante | 1 |
| 8937 | vomitivo | 1 |
| 8938 | volvía | 1 |
| 8939 | volvería | 1 |
| 8940 | volvemos | 1 |
| 8941 | volvámonos | 1 |
| 8942 | voluntarioso | 1 |
| 8943 | voluntario | 1 |
| 8944 | voluble | 1 |
| 8945 | volatín | 1 |
| 8946 | volátil | 1 |
| 8947 | volador | 1 |
| 8948 | vocear | 1 |
| 8949 | vocal | 1 |
| 8950 | vocabulario | 1 |
| 8951 | vivito | 1 |
| 8952 | vivirá | 1 |
| 8953 | vivía | 1 |
| 8954 | viveros | 1 |
| 8955 | vivaaa | 1 |
| 8956 | vitrina | 1 |
| 8957 | vitalicio | 1 |
| 8958 | visual | 1 |
| 8959 | vistiose | 1 |
| 8960 | vistillas | 1 |
| 8961 | viste | 1 |
| 8962 | vísperas | 1 |
| 8963 | visitante | 1 |
| 8964 | visiones | 1 |
| 8965 | visillo | 1 |
| 8966 | virus | 1 |
| 8967 | virtuosa | 1 |
| 8968 | virtudes | 1 |
| 8969 | viril | 1 |
| 8970 | vírgenes | 1 |
| 8971 | vira | 1 |
| 8972 | viose | 1 |
| 8973 | viole | 1 |
| 8974 | vinoso | 1 |
| 8975 | vinazo | 1 |
| 8976 | vinatero | 1 |
| 8977 | villaviciosa | 1 |
| 8978 | villarreal | 1 |
| 8979 | villanía | 1 |
| 8980 | villancico | 1 |
| 8981 | villahermosa | 1 |
| 8982 | vigorización | 1 |
| 8983 | vigilia | 1 |
| 8984 | vigía | 1 |
| 8985 | vigente | 1 |
| 8986 | viéronle | 1 |
| 8987 | vientos | 1 |
| 8988 | viéndote | 1 |
| 8989 | viéndome | 1 |
| 8990 | viéndola | 1 |
| 8991 | viendo | 1 |
| 8992 | victorioso | 1 |
| 8993 | vicisitud | 1 |
| 8994 | viciado | 1 |
| 8995 | vicaría | 1 |
| 8996 | vibratorio | 1 |
| 8997 | vibrante | 1 |
| 8998 | viana | 1 |
| 8999 | viabilidad | 1 |
| 9000 | vetusto | 1 |
| 9001 | vestuario | 1 |
| 9002 | vestimenta | 1 |
| 9003 | vertiente | 1 |
| 9004 | vértice | 1 |
| 9005 | vertical | 1 |
| 9006 | versionar | 1 |
| 9007 | versión | 1 |
| 9008 | verosímil | 1 |
| 9009 | vernet | 1 |
| 9010 | verle | 1 |
| 9011 | verja | 1 |
| 9012 | verificábase | 1 |
| 9013 | vericueto | 1 |
| 9014 | vergonzante | 1 |
| 9015 | verdor | 1 |
| 9016 | verdades | 1 |
| 9017 | verbal | 1 |
| 9018 | verba | 1 |
| 9019 | veraz | 1 |
| 9020 | veranear | 1 |
| 9021 | verán | 1 |
| 9022 | veracidad | 1 |
| 9023 | ventosa | 1 |
| 9024 | ventorrillo | 1 |
| 9025 | ventajoso | 1 |
| 9026 | venidero | 1 |
| 9027 | venialmente | 1 |
| 9028 | venia | 1 |
| 9029 | vengativo | 1 |
| 9030 | vengarse | 1 |
| 9031 | venerando | 1 |
| 9032 | vendrás | 1 |
| 9033 | vendrá | 1 |
| 9034 | vendiendo | 1 |
| 9035 | vendida | 1 |
| 9036 | vencimiento | 1 |
| 9037 | velas | 1 |
| 9038 | vejiga | 1 |
| 9039 | veintiuno | 1 |
| 9040 | veintiocho | 1 |
| 9041 | veíase | 1 |
| 9042 | veíanse | 1 |
| 9043 | vegetativo | 1 |
| 9044 | vegetal | 1 |
| 9045 | vegetación | 1 |
| 9046 | vedar | 1 |
| 9047 | vecinas | 1 |
| 9048 | veámoslo | 1 |
| 9049 | véalo | 1 |
| 9050 | váyanse | 1 |
| 9051 | vayan | 1 |
| 9052 | vaticinio | 1 |
| 9053 | vasija | 1 |
| 9054 | vascongadas | 1 |
| 9055 | vasco | 1 |
| 9056 | vas | 1 |
| 9057 | varilla | 1 |
| 9058 | variante | 1 |
| 9059 | variado | 1 |
| 9060 | variación | 1 |
| 9061 | varear | 1 |
| 9062 | varas | 1 |
| 9063 | vaqueta | 1 |
| 9064 | vapulear | 1 |
| 9065 | vampiro | 1 |
| 9066 | valoraciones | 1 |
| 9067 | vallehermoso | 1 |
| 9068 | valledor | 1 |
| 9069 | vallecas | 1 |
| 9070 | valimiento | 1 |
| 9071 | valiéndose | 1 |
| 9072 | válido | 1 |
| 9073 | válganos | 1 |
| 9074 | valentía | 1 |
| 9075 | vaivén | 1 |
| 9076 | vais | 1 |
| 9077 | vaho | 1 |
| 9078 | vagancia | 1 |
| 9079 | vacuno | 1 |
| 9080 | vacía | 1 |
| 9081 | vacar | 1 |
| 9082 | vacación | 1 |
| 9083 | utilitario | 1 |
| 9084 | utilísimo | 1 |
| 9085 | usurpación | 1 |
| 9086 | usufructuario | 1 |
| 9087 | usufructo | 1 |
| 9088 | ustés | 1 |
| 9089 | usté | 1 |
| 9090 | uribe | 1 |
| 9091 | urgir | 1 |
| 9092 | urgencia | 1 |
| 9093 | urdir | 1 |
| 9094 | urdimbre | 1 |
| 9095 | urbano | 1 |
| 9096 | unos | 1 |
| 9097 | universitario | 1 |
| 9098 | uniformidad | 1 |
| 9099 | unidos | 1 |
| 9100 | unicornio | 1 |
| 9101 | ungüento | 1 |
| 9102 | ungir | 1 |
| 9103 | unanimidad | 1 |
| 9104 | unánime | 1 |
| 9105 | umbral | 1 |
| 9106 | ultratumba | 1 |
| 9107 | ultramarino | 1 |
| 9108 | ultraje | 1 |
| 9109 | úlcera | 1 |
| 9110 | ubre | 1 |
| 9111 | tuvo | 1 |
| 9112 | tuviéronla | 1 |
| 9113 | tuve | 1 |
| 9114 | tutora | 1 |
| 9115 | tutor | 1 |
| 9116 | tutela | 1 |
| 9117 | turgente | 1 |
| 9118 | turégano | 1 |
| 9119 | turbulento | 1 |
| 9120 | turbose | 1 |
| 9121 | turbante | 1 |
| 9122 | turbado | 1 |
| 9123 | turbábala | 1 |
| 9124 | tupé | 1 |
| 9125 | túnica | 1 |
| 9126 | tundir | 1 |
| 9127 | tunantería | 1 |
| 9128 | tunantas | 1 |
| 9129 | tun | 1 |
| 9130 | tumultuoso | 1 |
| 9131 | tugurio | 1 |
| 9132 | tuétano | 1 |
| 9133 | tubería | 1 |
| 9134 | tuberculosis | 1 |
| 9135 | trujillas | 1 |
| 9136 | truhán | 1 |
| 9137 | trufar | 1 |
| 9138 | trueno | 1 |
| 9139 | truchimán | 1 |
| 9140 | trovador | 1 |
| 9141 | tropezones | 1 |
| 9142 | tropezón | 1 |
| 9143 | tronado | 1 |
| 9144 | trompo | 1 |
| 9145 | trompicones | 1 |
| 9146 | trompicón | 1 |
| 9147 | trompada | 1 |
| 9148 | trizar | 1 |
| 9149 | triturar | 1 |
| 9150 | tris | 1 |
| 9151 | tripudo | 1 |
| 9152 | trípode | 1 |
| 9153 | triple | 1 |
| 9154 | trinca | 1 |
| 9155 | tributo | 1 |
| 9156 | tribuna | 1 |
| 9157 | triana | 1 |
| 9158 | treta | 1 |
| 9159 | trescientos | 1 |
| 9160 | trescientas | 1 |
| 9161 | trepar | 1 |
| 9162 | trepador | 1 |
| 9163 | trencilla | 1 |
| 9164 | trebejos | 1 |
| 9165 | trazado | 1 |
| 9166 | travesía | 1 |
| 9167 | traté | 1 |
| 9168 | tratadista | 1 |
| 9169 | tratábase | 1 |
| 9170 | trasunto | 1 |
| 9171 | trasuntar | 1 |
| 9172 | trastocar | 1 |
| 9173 | trastazo | 1 |
| 9174 | trasquilar | 1 |
| 9175 | trasnochar | 1 |
| 9176 | trasnochador | 1 |
| 9177 | trasmitir | 1 |
| 9178 | trasluz | 1 |
| 9179 | traslucir | 1 |
| 9180 | traslación | 1 |
| 9181 | trasegar | 1 |
| 9182 | trascender | 1 |
| 9183 | trascendencia | 1 |
| 9184 | traqueteo | 1 |
| 9185 | traquetear | 1 |
| 9186 | trapillo | 1 |
| 9187 | trap | 1 |
| 9188 | transporte | 1 |
| 9189 | transportar | 1 |
| 9190 | transparente | 1 |
| 9191 | transformismo | 1 |
| 9192 | transfiguración | 1 |
| 9193 | transferencia | 1 |
| 9194 | transcurso | 1 |
| 9195 | tranquilamente | 1 |
| 9196 | trancazo | 1 |
| 9197 | trancar | 1 |
| 9198 | tramposa | 1 |
| 9199 | tráiganos | 1 |
| 9200 | traían | 1 |
| 9201 | traía | 1 |
| 9202 | tragón | 1 |
| 9203 | tragicómico | 1 |
| 9204 | tragadero | 1 |
| 9205 | traficante | 1 |
| 9206 | trafalgar | 1 |
| 9207 | traería | 1 |
| 9208 | tráeme | 1 |
| 9209 | trae | 1 |
| 9210 | tradújose | 1 |
| 9211 | traducción | 1 |
| 9212 | trabucar | 1 |
| 9213 | trabilla | 1 |
| 9214 | trabajosamente | 1 |
| 9215 | tóxico | 1 |
| 9216 | totalmente | 1 |
| 9217 | tosquedad | 1 |
| 9218 | torzal | 1 |
| 9219 | torvamente | 1 |
| 9220 | tortuga | 1 |
| 9221 | tórtolo | 1 |
| 9222 | tortoleo | 1 |
| 9223 | tortillita | 1 |
| 9224 | torrero | 1 |
| 9225 | torreón | 1 |
| 9226 | torrellas | 1 |
| 9227 | torniquete | 1 |
| 9228 | torneo | 1 |
| 9229 | torneado | 1 |
| 9230 | tornasol | 1 |
| 9231 | torna | 1 |
| 9232 | toril | 1 |
| 9233 | torcedura | 1 |
| 9234 | tórax | 1 |
| 9235 | torácico | 1 |
| 9236 | tópico | 1 |
| 9237 | topetazo | 1 |
| 9238 | topar | 1 |
| 9239 | topacio | 1 |
| 9240 | tontín | 1 |
| 9241 | tontada | 1 |
| 9242 | tonsurar | 1 |
| 9243 | tónico | 1 |
| 9244 | tónica | 1 |
| 9245 | tonel | 1 |
| 9246 | tomola | 1 |
| 9247 | tomó | 1 |
| 9248 | tomo | 1 |
| 9249 | tomarla | 1 |
| 9250 | tomaremos | 1 |
| 9251 | tomándole | 1 |
| 9252 | tomad | 1 |
| 9253 | tomaba | 1 |
| 9254 | tolú | 1 |
| 9255 | tollina | 1 |
| 9256 | tolerable | 1 |
| 9257 | tocaya | 1 |
| 9258 | tocándole | 1 |
| 9259 | tocado | 1 |
| 9260 | titubeaba | 1 |
| 9261 | tísico | 1 |
| 9262 | tirantez | 1 |
| 9263 | tiránico | 1 |
| 9264 | tirabuzón | 1 |
| 9265 | tiorras | 1 |
| 9266 | tiologías | 1 |
| 9267 | tinturar | 1 |
| 9268 | tinto | 1 |
| 9269 | tinieblas | 1 |
| 9270 | tinaja | 1 |
| 9271 | tina | 1 |
| 9272 | tímpano | 1 |
| 9273 | timonear | 1 |
| 9274 | timbal | 1 |
| 9275 | timador | 1 |
| 9276 | tijeretazo | 1 |
| 9277 | tijeretas | 1 |
| 9278 | tijereta | 1 |
| 9279 | tiento | 1 |
| 9280 | tiembla | 1 |
| 9281 | tic | 1 |
| 9282 | tiburón | 1 |
| 9283 | tibidabo | 1 |
| 9284 | tibia | 1 |
| 9285 | thinville | 1 |
| 9286 | textualmente | 1 |
| 9287 | tetera | 1 |
| 9288 | testuz | 1 |
| 9289 | testimoniar | 1 |
| 9290 | testera | 1 |
| 9291 | testar | 1 |
| 9292 | tesorería | 1 |
| 9293 | teruel | 1 |
| 9294 | terruño | 1 |
| 9295 | territorio | 1 |
| 9296 | terrestre | 1 |
| 9297 | terrenal | 1 |
| 9298 | terraza | 1 |
| 9299 | terráqueo | 1 |
| 9300 | terranova | 1 |
| 9301 | ternerito | 1 |
| 9302 | terne | 1 |
| 9303 | tercio | 1 |
| 9304 | teórico | 1 |
| 9305 | teológico | 1 |
| 9306 | tenuidad | 1 |
| 9307 | tentativo | 1 |
| 9308 | tentador | 1 |
| 9309 | tenla | 1 |
| 9310 | teníase | 1 |
| 9311 | teníanle | 1 |
| 9312 | teníale | 1 |
| 9313 | tengamos | 1 |
| 9314 | téngalo | 1 |
| 9315 | tened | 1 |
| 9316 | tendrías | 1 |
| 9317 | tendría | 1 |
| 9318 | tendremos | 1 |
| 9319 | tendrán | 1 |
| 9320 | tendralos | 1 |
| 9321 | tendrá | 1 |
| 9322 | tendón | 1 |
| 9323 | tenderete | 1 |
| 9324 | tenacilla | 1 |
| 9325 | temperatura | 1 |
| 9326 | temible | 1 |
| 9327 | temía | 1 |
| 9328 | teméis | 1 |
| 9329 | teme | 1 |
| 9330 | telar | 1 |
| 9331 | tejavana | 1 |
| 9332 | tejar | 1 |
| 9333 | tedio | 1 |
| 9334 | tea | 1 |
| 9335 | tazón | 1 |
| 9336 | tauromaquia | 1 |
| 9337 | taurómaco | 1 |
| 9338 | tartana | 1 |
| 9339 | tarima | 1 |
| 9340 | tardío | 1 |
| 9341 | tardecillo | 1 |
| 9342 | tarancón | 1 |
| 9343 | tarabilla | 1 |
| 9344 | tapón | 1 |
| 9345 | tapete | 1 |
| 9346 | tapadera | 1 |
| 9347 | tangible | 1 |
| 9348 | tangente | 1 |
| 9349 | tamizar | 1 |
| 9350 | tamiz | 1 |
| 9351 | tamboril | 1 |
| 9352 | talud | 1 |
| 9353 | tallado | 1 |
| 9354 | talega | 1 |
| 9355 | talavera | 1 |
| 9356 | taladrar | 1 |
| 9357 | tahona | 1 |
| 9358 | tafetán | 1 |
| 9359 | táctica | 1 |
| 9360 | tacita | 1 |
| 9361 | tachuela | 1 |
| 9362 | tacaño | 1 |
| 9363 | tabernero | 1 |
| 9364 | tabacos | 1 |
| 9365 | ta | 1 |
| 9366 | sutilísimo | 1 |
| 9367 | sustancial | 1 |
| 9368 | suspiraba | 1 |
| 9369 | suspicacia | 1 |
| 9370 | susodicho | 1 |
| 9371 | suscripción | 1 |
| 9372 | suscribir | 1 |
| 9373 | suscitar | 1 |
| 9374 | surtidor | 1 |
| 9375 | súpose | 1 |
| 9376 | suponiendo | 1 |
| 9377 | suponíales | 1 |
| 9378 | suponía | 1 |
| 9379 | supongo | 1 |
| 9380 | supongamos | 1 |
| 9381 | suplir | 1 |
| 9382 | súplica | 1 |
| 9383 | suplemento | 1 |
| 9384 | suplementario | 1 |
| 9385 | súpito | 1 |
| 9386 | supe | 1 |
| 9387 | sumiso | 1 |
| 9388 | sumir | 1 |
| 9389 | suministrar | 1 |
| 9390 | sulfurar | 1 |
| 9391 | sujetose | 1 |
| 9392 | sufragio | 1 |
| 9393 | sueños | 1 |
| 9394 | suéltese | 1 |
| 9395 | suéltela | 1 |
| 9396 | sucumbir | 1 |
| 9397 | subteniente | 1 |
| 9398 | subsistencia | 1 |
| 9399 | subsiguiente | 1 |
| 9400 | subsidio | 1 |
| 9401 | subrepticiamente | 1 |
| 9402 | sublimidad | 1 |
| 9403 | subiría | 1 |
| 9404 | subiré | 1 |
| 9405 | subiéronle | 1 |
| 9406 | subiéndose | 1 |
| 9407 | subido | 1 |
| 9408 | súbdito | 1 |
| 9409 | suba | 1 |
| 9410 | suárez | 1 |
| 9411 | sotabanco | 1 |
| 9412 | sostenimiento | 1 |
| 9413 | sostenía | 1 |
| 9414 | sosería | 1 |
| 9415 | sosegadamente | 1 |
| 9416 | sosamente | 1 |
| 9417 | sortilegio | 1 |
| 9418 | sorpresita | 1 |
| 9419 | sorna | 1 |
| 9420 | sordina | 1 |
| 9421 | sordidez | 1 |
| 9422 | sordamente | 1 |
| 9423 | sorbo | 1 |
| 9424 | sopesar | 1 |
| 9425 | sopero | 1 |
| 9426 | sopera | 1 |
| 9427 | sonreía | 1 |
| 9428 | sonoridad | 1 |
| 9429 | sonámbulo | 1 |
| 9430 | somero | 1 |
| 9431 | sombrerero | 1 |
| 9432 | sombrear | 1 |
| 9433 | soltería | 1 |
| 9434 | solos | 1 |
| 9435 | solidificación | 1 |
| 9436 | solidez | 1 |
| 9437 | sólidamente | 1 |
| 9438 | solfeo | 1 |
| 9439 | soleta | 1 |
| 9440 | solecismo | 1 |
| 9441 | soldevilla | 1 |
| 9442 | soldados | 1 |
| 9443 | soldadito | 1 |
| 9444 | solaz | 1 |
| 9445 | solapa | 1 |
| 9446 | solana | 1 |
| 9447 | solamente | 1 |
| 9448 | sojuzgar | 1 |
| 9449 | sofocón | 1 |
| 9450 | sofoco | 1 |
| 9451 | sofistería | 1 |
| 9452 | soez | 1 |
| 9453 | socorriome | 1 |
| 9454 | socórrale | 1 |
| 9455 | sociedades | 1 |
| 9456 | socavar | 1 |
| 9457 | sobrio | 1 |
| 9458 | sobrevivir | 1 |
| 9459 | sobrestante | 1 |
| 9460 | sobresaliente | 1 |
| 9461 | sobrepujar | 1 |
| 9462 | sobreparto | 1 |
| 9463 | sobredorar | 1 |
| 9464 | sobado | 1 |
| 9465 | sobaco | 1 |
| 9466 | sito | 1 |
| 9467 | sistematizar | 1 |
| 9468 | sirven | 1 |
| 9469 | sinvergüenzonas | 1 |
| 9470 | síntomas | 1 |
| 9471 | sintiole | 1 |
| 9472 | sinónimo | 1 |
| 9473 | singularidad | 1 |
| 9474 | singer | 1 |
| 9475 | síncope | 1 |
| 9476 | síncopa | 1 |
| 9477 | simultáneo | 1 |
| 9478 | simultáneamente | 1 |
| 9479 | simular | 1 |
| 9480 | simulacro | 1 |
| 9481 | simpson | 1 |
| 9482 | simplón | 1 |
| 9483 | simón | 1 |
| 9484 | similar | 1 |
| 9485 | símil | 1 |
| 9486 | simiente | 1 |
| 9487 | simbolismo | 1 |
| 9488 | silueta | 1 |
| 9489 | silogismo | 1 |
| 9490 | silleta | 1 |
| 9491 | sílfide | 1 |
| 9492 | silabeo | 1 |
| 9493 | sigunda | 1 |
| 9494 | siguiole | 1 |
| 9495 | siguiéndoles | 1 |
| 9496 | significativo | 1 |
| 9497 | significado | 1 |
| 9498 | sicilianas | 1 |
| 9499 | sicario | 1 |
| 9500 | sibila | 1 |
| 9501 | sibarita | 1 |
| 9502 | shangai | 1 |
| 9503 | sexto | 1 |
| 9504 | sexta | 1 |
| 9505 | severísimamente | 1 |
| 9506 | severiano | 1 |
| 9507 | seto | 1 |
| 9508 | setecientas | 1 |
| 9509 | sesera | 1 |
| 9510 | servil | 1 |
| 9511 | servíale | 1 |
| 9512 | sert | 1 |
| 9513 | seroso | 1 |
| 9514 | serón | 1 |
| 9515 | serénate | 1 |
| 9516 | seráfico | 1 |
| 9517 | séquito | 1 |
| 9518 | séptimo | 1 |
| 9519 | separáronse | 1 |
| 9520 | separado | 1 |
| 9521 | seo | 1 |
| 9522 | sentina | 1 |
| 9523 | sentíala | 1 |
| 9524 | sentenciar | 1 |
| 9525 | sentáronse | 1 |
| 9526 | sentándose | 1 |
| 9527 | sentada | 1 |
| 9528 | sensiblemente | 1 |
| 9529 | senil | 1 |
| 9530 | senador | 1 |
| 9531 | semioscura | 1 |
| 9532 | semilla | 1 |
| 9533 | seiscientos | 1 |
| 9534 | segura | 1 |
| 9535 | segundón | 1 |
| 9536 | seguíales | 1 |
| 9537 | segoviano | 1 |
| 9538 | seglar | 1 |
| 9539 | sedimentar | 1 |
| 9540 | sedeño | 1 |
| 9541 | sede | 1 |
| 9542 | sedante | 1 |
| 9543 | sedanes | 1 |
| 9544 | sedán | 1 |
| 9545 | secuestrar | 1 |
| 9546 | seccionar | 1 |
| 9547 | seboso | 1 |
| 9548 | schiller | 1 |
| 9549 | sazonado | 1 |
| 9550 | sayón | 1 |
| 9551 | saya | 1 |
| 9552 | saturar | 1 |
| 9553 | satisfactorio | 1 |
| 9554 | satírico | 1 |
| 9555 | sastrería | 1 |
| 9556 | sastra | 1 |
| 9557 | sarna | 1 |
| 9558 | saquear | 1 |
| 9559 | sapo | 1 |
| 9560 | sañudamente | 1 |
| 9561 | santuario | 1 |
| 9562 | santificar | 1 |
| 9563 | santificación | 1 |
| 9564 | santander | 1 |
| 9565 | sanguinolento | 1 |
| 9566 | sanguíneo | 1 |
| 9567 | sanguinario | 1 |
| 9568 | sangría | 1 |
| 9569 | sandía | 1 |
| 9570 | sancho | 1 |
| 9571 | salvedad | 1 |
| 9572 | salvamento | 1 |
| 9573 | salvajada | 1 |
| 9574 | salva | 1 |
| 9575 | saludáronse | 1 |
| 9576 | saludador | 1 |
| 9577 | saltó | 1 |
| 9578 | saltimbanqui | 1 |
| 9579 | saltear | 1 |
| 9580 | salteado | 1 |
| 9581 | saltamontes | 1 |
| 9582 | salta | 1 |
| 9583 | salsa | 1 |
| 9584 | salomón | 1 |
| 9585 | salobre | 1 |
| 9586 | salmuera | 1 |
| 9587 | salí | 1 |
| 9588 | salgo | 1 |
| 9589 | salesas | 1 |
| 9590 | sales | 1 |
| 9591 | sajón | 1 |
| 9592 | saint | 1 |
| 9593 | sahumerio | 1 |
| 9594 | sagrados | 1 |
| 9595 | sagrada | 1 |
| 9596 | sagra | 1 |
| 9597 | sagacidad | 1 |
| 9598 | sacudido | 1 |
| 9599 | sacramentar | 1 |
| 9600 | sacramentado | 1 |
| 9601 | sacola | 1 |
| 9602 | sacó | 1 |
| 9603 | saciedad | 1 |
| 9604 | sacáronla | 1 |
| 9605 | sácalos | 1 |
| 9606 | sabusté | 1 |
| 9607 | sabor | 1 |
| 9608 | sable | 1 |
| 9609 | sabiéndolas | 1 |
| 9610 | sabéis | 1 |
| 9611 | sabañón | 1 |
| 9612 | s | 1 |
| 9613 | ruso | 1 |
| 9614 | rupertito | 1 |
| 9615 | rumboso | 1 |
| 9616 | rumbar | 1 |
| 9617 | ruin | 1 |
| 9618 | ruego | 1 |
| 9619 | ruedo | 1 |
| 9620 | rudimentario | 1 |
| 9621 | ruborizar | 1 |
| 9622 | ruborizado | 1 |
| 9623 | rubor | 1 |
| 9624 | rubines | 1 |
| 9625 | rubia | 1 |
| 9626 | rozamiento | 1 |
| 9627 | rozadura | 1 |
| 9628 | rotura | 1 |
| 9629 | rothschild | 1 |
| 9630 | rostchild | 1 |
| 9631 | rosicler | 1 |
| 9632 | rosca | 1 |
| 9633 | roque | 1 |
| 9634 | ropaje | 1 |
| 9635 | roña | 1 |
| 9636 | ronca | 1 |
| 9637 | rompí | 1 |
| 9638 | rompelanzas | 1 |
| 9639 | romo | 1 |
| 9640 | romería | 1 |
| 9641 | rombo | 1 |
| 9642 | romanza | 1 |
| 9643 | romanos | 1 |
| 9644 | románico | 1 |
| 9645 | romadizo | 1 |
| 9646 | roger | 1 |
| 9647 | roedor | 1 |
| 9648 | rodríguez | 1 |
| 9649 | rodil | 1 |
| 9650 | rocío | 1 |
| 9651 | rociada | 1 |
| 9652 | robustecer | 1 |
| 9653 | robledo | 1 |
| 9654 | rizado | 1 |
| 9655 | ritual | 1 |
| 9656 | rítmico | 1 |
| 9657 | rita | 1 |
| 9658 | risas | 1 |
| 9659 | ripio | 1 |
| 9660 | riose | 1 |
| 9661 | rioja | 1 |
| 9662 | ringorrango | 1 |
| 9663 | rimero | 1 |
| 9664 | rimar | 1 |
| 9665 | rija | 1 |
| 9666 | rigorista | 1 |
| 9667 | rígidamente | 1 |
| 9668 | rifle | 1 |
| 9669 | riesgo | 1 |
| 9670 | ridículamente | 1 |
| 9671 | ricardo | 1 |
| 9672 | ricacho | 1 |
| 9673 | rica | 1 |
| 9674 | ribetear | 1 |
| 9675 | ribera | 1 |
| 9676 | ríase | 1 |
| 9677 | rezumos | 1 |
| 9678 | rezumar | 1 |
| 9679 | rezongó | 1 |
| 9680 | revuelco | 1 |
| 9681 | revolvió | 1 |
| 9682 | revoltoso | 1 |
| 9683 | revolcose | 1 |
| 9684 | revoco | 1 |
| 9685 | revocar | 1 |
| 9686 | revista | 1 |
| 9687 | revisión | 1 |
| 9688 | revirar | 1 |
| 9689 | revertir | 1 |
| 9690 | reversión | 1 |
| 9691 | reverente | 1 |
| 9692 | reverbero | 1 |
| 9693 | reverberar | 1 |
| 9694 | reventa | 1 |
| 9695 | revenir | 1 |
| 9696 | revelarte | 1 |
| 9697 | revelado | 1 |
| 9698 | reumático | 1 |
| 9699 | retumbante | 1 |
| 9700 | retraimiento | 1 |
| 9701 | retraer | 1 |
| 9702 | retortero | 1 |
| 9703 | retorta | 1 |
| 9704 | retórico | 1 |
| 9705 | retorcido | 1 |
| 9706 | retorcedura | 1 |
| 9707 | retoñar | 1 |
| 9708 | retocar | 1 |
| 9709 | retirose | 1 |
| 9710 | retiradamente | 1 |
| 9711 | retirábase | 1 |
| 9712 | retina | 1 |
| 9713 | reteniéndole | 1 |
| 9714 | retención | 1 |
| 9715 | retemblar | 1 |
| 9716 | retazo | 1 |
| 9717 | retardar | 1 |
| 9718 | resurgir | 1 |
| 9719 | resumir | 1 |
| 9720 | resumen | 1 |
| 9721 | resultas | 1 |
| 9722 | resulta | 1 |
| 9723 | resuelto | 1 |
| 9724 | resuello | 1 |
| 9725 | restañar | 1 |
| 9726 | restante | 1 |
| 9727 | restallar | 1 |
| 9728 | restablecimiento | 1 |
| 9729 | resquebrajar | 1 |
| 9730 | responso | 1 |
| 9731 | respondón | 1 |
| 9732 | respondió | 1 |
| 9733 | responderme | 1 |
| 9734 | respóndeme | 1 |
| 9735 | respóndame | 1 |
| 9736 | respiradero | 1 |
| 9737 | respirable | 1 |
| 9738 | respingar | 1 |
| 9739 | respetuoso | 1 |
| 9740 | respetuosamente | 1 |
| 9741 | resorte | 1 |
| 9742 | resonante | 1 |
| 9743 | resolvió | 1 |
| 9744 | resolvíase | 1 |
| 9745 | resistente | 1 |
| 9746 | resina | 1 |
| 9747 | resguardo | 1 |
| 9748 | resentir | 1 |
| 9749 | resellar | 1 |
| 9750 | resecar | 1 |
| 9751 | rescoldo | 1 |
| 9752 | resbalón | 1 |
| 9753 | resbaladizo | 1 |
| 9754 | resaltar | 1 |
| 9755 | res | 1 |
| 9756 | requisito | 1 |
| 9757 | requetefinas | 1 |
| 9758 | requemado | 1 |
| 9759 | requejo | 1 |
| 9760 | reputado | 1 |
| 9761 | repuntar | 1 |
| 9762 | repulsión | 1 |
| 9763 | repulgo | 1 |
| 9764 | repulgar | 1 |
| 9765 | republicanismo | 1 |
| 9766 | reprobación | 1 |
| 9767 | reprobable | 1 |
| 9768 | reprimir | 1 |
| 9769 | reprensión | 1 |
| 9770 | repreciosa | 1 |
| 9771 | repostero | 1 |
| 9772 | repoblicanos | 1 |
| 9773 | repliegue | 1 |
| 9774 | replegar | 1 |
| 9775 | repartió | 1 |
| 9776 | reparón | 1 |
| 9777 | repantigar | 1 |
| 9778 | renacimiento | 1 |
| 9779 | renacer | 1 |
| 9780 | remotamente | 1 |
| 9781 | remorder | 1 |
| 9782 | remolque | 1 |
| 9783 | remolcar | 1 |
| 9784 | remojar | 1 |
| 9785 | remo | 1 |
| 9786 | remite | 1 |
| 9787 | reminiscencia | 1 |
| 9788 | remilgar | 1 |
| 9789 | remilgado | 1 |
| 9790 | remesar | 1 |
| 9791 | remedo | 1 |
| 9792 | remala | 1 |
| 9793 | remadera | 1 |
| 9794 | remachar | 1 |
| 9795 | relojero | 1 |
| 9796 | relojería | 1 |
| 9797 | reliquia | 1 |
| 9798 | relamido | 1 |
| 9799 | relajado | 1 |
| 9800 | relacionado | 1 |
| 9801 | rejuvenecer | 1 |
| 9802 | reírme | 1 |
| 9803 | reintegrar | 1 |
| 9804 | reincidir | 1 |
| 9805 | reincidente | 1 |
| 9806 | reguapa | 1 |
| 9807 | regrande | 1 |
| 9808 | regordete | 1 |
| 9809 | regocijado | 1 |
| 9810 | reglamentario | 1 |
| 9811 | regio | 1 |
| 9812 | regenerado | 1 |
| 9813 | regalón | 1 |
| 9814 | regadera | 1 |
| 9815 | refutar | 1 |
| 9816 | refunfuñó | 1 |
| 9817 | refunfuño | 1 |
| 9818 | refulgente | 1 |
| 9819 | refuerzo | 1 |
| 9820 | refregón | 1 |
| 9821 | refractario | 1 |
| 9822 | refinamiento | 1 |
| 9823 | refiérome | 1 |
| 9824 | refiere | 1 |
| 9825 | referirle | 1 |
| 9826 | refeos | 1 |
| 9827 | refectorio | 1 |
| 9828 | reducto | 1 |
| 9829 | redondel | 1 |
| 9830 | redaño | 1 |
| 9831 | recuento | 1 |
| 9832 | rectilíneo | 1 |
| 9833 | rectificó | 1 |
| 9834 | recrudecimiento | 1 |
| 9835 | recreábase | 1 |
| 9836 | recortándolo | 1 |
| 9837 | recortado | 1 |
| 9838 | recorrido | 1 |
| 9839 | reconstruir | 1 |
| 9840 | reconstituyente | 1 |
| 9841 | reconozco | 1 |
| 9842 | reconociendo | 1 |
| 9843 | reconocido | 1 |
| 9844 | reconocería | 1 |
| 9845 | recondenada | 1 |
| 9846 | recomponer | 1 |
| 9847 | recompensar | 1 |
| 9848 | recompensa | 1 |
| 9849 | recomendado | 1 |
| 9850 | recomendable | 1 |
| 9851 | recoletos | 1 |
| 9852 | recógete | 1 |
| 9853 | recoba | 1 |
| 9854 | reclinatorio | 1 |
| 9855 | recibiome | 1 |
| 9856 | recibió | 1 |
| 9857 | rechupete | 1 |
| 9858 | rechupado | 1 |
| 9859 | rechacemos | 1 |
| 9860 | recaudar | 1 |
| 9861 | recaudador | 1 |
| 9862 | recaudación | 1 |
| 9863 | recargar | 1 |
| 9864 | recapacitar | 1 |
| 9865 | recalentar | 1 |
| 9866 | recalcar | 1 |
| 9867 | recaída | 1 |
| 9868 | rebuznó | 1 |
| 9869 | rebuznar | 1 |
| 9870 | rebuscado | 1 |
| 9871 | rebullicio | 1 |
| 9872 | reblandecimiento | 1 |
| 9873 | reblandecer | 1 |
| 9874 | rebeca | 1 |
| 9875 | rebanada | 1 |
| 9876 | rebaja | 1 |
| 9877 | reapertura | 1 |
| 9878 | reanimar | 1 |
| 9879 | realización | 1 |
| 9880 | realista | 1 |
| 9881 | reales | 1 |
| 9882 | rayuela | 1 |
| 9883 | rayano | 1 |
| 9884 | rayado | 1 |
| 9885 | raudo | 1 |
| 9886 | ratificar | 1 |
| 9887 | ratera | 1 |
| 9888 | rastrear | 1 |
| 9889 | rasgueo | 1 |
| 9890 | rasgos | 1 |
| 9891 | rasgar | 1 |
| 9892 | raquitismo | 1 |
| 9893 | rapé | 1 |
| 9894 | rapacidad | 1 |
| 9895 | ranero | 1 |
| 9896 | rana | 1 |
| 9897 | ramplón | 1 |
| 9898 | rampa | 1 |
| 9899 | ramona | 1 |
| 9900 | ramojo | 1 |
| 9901 | ramillete | 1 |
| 9902 | rameaditas | 1 |
| 9903 | ramalazo | 1 |
| 9904 | rallar | 1 |
| 9905 | ralea | 1 |
| 9906 | rajar | 1 |
| 9907 | raja | 1 |
| 9908 | raído | 1 |
| 9909 | radio | 1 |
| 9910 | radicar | 1 |
| 9911 | radicalmente | 1 |
| 9912 | radical | 1 |
| 9913 | racionalista | 1 |
| 9914 | rachir | 1 |
| 9915 | racha | 1 |
| 9916 | rabillo | 1 |
| 9917 | rabadilla | 1 |
| 9918 | r | 1 |
| 9919 | quitole | 1 |
| 9920 | quitándose | 1 |
| 9921 | quítale | 1 |
| 9922 | quisto | 1 |
| 9923 | quisquilloso | 1 |
| 9924 | quirúrgicamente | 1 |
| 9925 | quintín | 1 |
| 9926 | quintilla | 1 |
| 9927 | quintero | 1 |
| 9928 | quinina | 1 |
| 9929 | quinientas | 1 |
| 9930 | quinceno | 1 |
| 9931 | quincena | 1 |
| 9932 | quincalla | 1 |
| 9933 | quina | 1 |
| 9934 | químico | 1 |
| 9935 | quilo | 1 |
| 9936 | quijotesco | 1 |
| 9937 | quiéreme | 1 |
| 9938 | quiera | 1 |
| 9939 | quiénes | 1 |
| 9940 | quiebra | 1 |
| 9941 | quid | 1 |
| 9942 | quevedos | 1 |
| 9943 | quesada | 1 |
| 9944 | queriéndome | 1 |
| 9945 | quería | 1 |
| 9946 | quererte | 1 |
| 9947 | quemado | 1 |
| 9948 | quedeme | 1 |
| 9949 | quedarse | 1 |
| 9950 | quedábanse | 1 |
| 9951 | quebrar | 1 |
| 9952 | putrefacción | 1 |
| 9953 | putona | 1 |
| 9954 | putativo | 1 |
| 9955 | pusiéronle | 1 |
| 9956 | púseme | 1 |
| 9957 | purgar | 1 |
| 9958 | puré | 1 |
| 9959 | pura | 1 |
| 9960 | punzón | 1 |
| 9961 | punzante | 1 |
| 9962 | punzada | 1 |
| 9963 | puntilloso | 1 |
| 9964 | puntiagudo | 1 |
| 9965 | puntero | 1 |
| 9966 | puntera | 1 |
| 9967 | pundonoroso | 1 |
| 9968 | pulsera | 1 |
| 9969 | pulpejo | 1 |
| 9970 | pulpa | 1 |
| 9971 | pulimentar | 1 |
| 9972 | pulgada | 1 |
| 9973 | pulcro | 1 |
| 9974 | pujanza | 1 |
| 9975 | pujante | 1 |
| 9976 | pugilato | 1 |
| 9977 | puertas | 1 |
| 9978 | puerilidad | 1 |
| 9979 | puerca | 1 |
| 9980 | pueden | 1 |
| 9981 | pueblecito | 1 |
| 9982 | pudrir | 1 |
| 9983 | pucheta | 1 |
| 9984 | publicista | 1 |
| 9985 | pseudo | 1 |
| 9986 | psch | 1 |
| 9987 | pruuun | 1 |
| 9988 | pruebe | 1 |
| 9989 | prudencial | 1 |
| 9990 | proyección | 1 |
| 9991 | provincias | 1 |
| 9992 | provinciano | 1 |
| 9993 | provincial | 1 |
| 9994 | protesta | 1 |
| 9995 | proteccionista | 1 |
| 9996 | prostituir | 1 |
| 9997 | prosternar | 1 |
| 9998 | prosperar | 1 |
| 9999 | prospecto | 1 |
| 10000 | prosélito | 1 |
| 10001 | proscenio | 1 |
| 10002 | prosa | 1 |
| 10003 | proporcional | 1 |
| 10004 | proporcionadamente | 1 |
| 10005 | proporcionábale | 1 |
| 10006 | propónense | 1 |
| 10007 | propina | 1 |
| 10008 | propender | 1 |
| 10009 | propalar | 1 |
| 10010 | pronóstico | 1 |
| 10011 | pronosticar | 1 |
| 10012 | promontorio | 1 |
| 10013 | prominente | 1 |
| 10014 | prometida | 1 |
| 10015 | prometíaselas | 1 |
| 10016 | prolijidad | 1 |
| 10017 | prolijamente | 1 |
| 10018 | prolífico | 1 |
| 10019 | prohijar | 1 |
| 10020 | progresivo | 1 |
| 10021 | progresar | 1 |
| 10022 | progenie | 1 |
| 10023 | profundísimamente | 1 |
| 10024 | profundísima | 1 |
| 10025 | profundidad | 1 |
| 10026 | profético | 1 |
| 10027 | profeta | 1 |
| 10028 | profesional | 1 |
| 10029 | profano | 1 |
| 10030 | proeza | 1 |
| 10031 | productor | 1 |
| 10032 | pródigo | 1 |
| 10033 | procurarle | 1 |
| 10034 | procura | 1 |
| 10035 | proclamar | 1 |
| 10036 | prócida | 1 |
| 10037 | procesionalmente | 1 |
| 10038 | proceroso | 1 |
| 10039 | procedente | 1 |
| 10040 | procaz | 1 |
| 10041 | procacidad | 1 |
| 10042 | probrecilla | 1 |
| 10043 | probes | 1 |
| 10044 | probe | 1 |
| 10045 | pro | 1 |
| 10046 | prismático | 1 |
| 10047 | prisma | 1 |
| 10048 | pringue | 1 |
| 10049 | primordial | 1 |
| 10050 | primeramente | 1 |
| 10051 | primario | 1 |
| 10052 | primaria | 1 |
| 10053 | prima | 1 |
| 10054 | price | 1 |
| 10055 | preventivo | 1 |
| 10056 | prevaricar | 1 |
| 10057 | pretextos | 1 |
| 10058 | pretérito | 1 |
| 10059 | presunto | 1 |
| 10060 | presumida | 1 |
| 10061 | prestigio | 1 |
| 10062 | prestidigitador | 1 |
| 10063 | prestidigitación | 1 |
| 10064 | presidencial | 1 |
| 10065 | presidencia | 1 |
| 10066 | preservativo | 1 |
| 10067 | preséntate | 1 |
| 10068 | prescribir | 1 |
| 10069 | prescindir | 1 |
| 10070 | presbiterio | 1 |
| 10071 | presagiar | 1 |
| 10072 | prepárese | 1 |
| 10073 | preparatorio | 1 |
| 10074 | prepárate | 1 |
| 10075 | preparando | 1 |
| 10076 | preparado | 1 |
| 10077 | preparábase | 1 |
| 10078 | premiado | 1 |
| 10079 | preliminar | 1 |
| 10080 | prejuicio | 1 |
| 10081 | preguntón | 1 |
| 10082 | preguntome | 1 |
| 10083 | preguntole | 1 |
| 10084 | prefieres | 1 |
| 10085 | preferiremos | 1 |
| 10086 | preferible | 1 |
| 10087 | prefería | 1 |
| 10088 | predisposición | 1 |
| 10089 | predicador | 1 |
| 10090 | predestinar | 1 |
| 10091 | precozmente | 1 |
| 10092 | precocidad | 1 |
| 10093 | precisión | 1 |
| 10094 | precipicio | 1 |
| 10095 | precepto | 1 |
| 10096 | precedente | 1 |
| 10097 | práxedes | 1 |
| 10098 | pragmático | 1 |
| 10099 | pragmática | 1 |
| 10100 | praga | 1 |
| 10101 | pradoluengo | 1 |
| 10102 | pradera | 1 |
| 10103 | practicable | 1 |
| 10104 | pozos | 1 |
| 10105 | potestad | 1 |
| 10106 | potente | 1 |
| 10107 | pote | 1 |
| 10108 | potasio | 1 |
| 10109 | póstumo | 1 |
| 10110 | postrimerías | 1 |
| 10111 | postrado | 1 |
| 10112 | poste | 1 |
| 10113 | postal | 1 |
| 10114 | posta | 1 |
| 10115 | positivar | 1 |
| 10116 | positivamente | 1 |
| 10117 | posada | 1 |
| 10118 | portugal | 1 |
| 10119 | portento | 1 |
| 10120 | portear | 1 |
| 10121 | porra | 1 |
| 10122 | pordiosero | 1 |
| 10123 | pordiosear | 1 |
| 10124 | popularidad | 1 |
| 10125 | ponzoñoso | 1 |
| 10126 | pontevedra | 1 |
| 10127 | ponlo | 1 |
| 10128 | ponle | 1 |
| 10129 | ponía | 1 |
| 10130 | pongámosle | 1 |
| 10131 | pongamos | 1 |
| 10132 | ponderación | 1 |
| 10133 | poncio | 1 |
| 10134 | pollino | 1 |
| 10135 | política | 1 |
| 10136 | polinesia | 1 |
| 10137 | policíaco | 1 |
| 10138 | policiaco | 1 |
| 10139 | polichinela | 1 |
| 10140 | polemista | 1 |
| 10141 | poema | 1 |
| 10142 | podrías | 1 |
| 10143 | podredumbre | 1 |
| 10144 | podrás | 1 |
| 10145 | podías | 1 |
| 10146 | pócima | 1 |
| 10147 | pocillo | 1 |
| 10148 | pocilga | 1 |
| 10149 | pobrete | 1 |
| 10150 | pobres | 1 |
| 10151 | poblar | 1 |
| 10152 | plomizo | 1 |
| 10153 | pléyade | 1 |
| 10154 | plenipotenciario | 1 |
| 10155 | plazos | 1 |
| 10156 | platero | 1 |
| 10157 | plateado | 1 |
| 10158 | plataforma | 1 |
| 10159 | plasta | 1 |
| 10160 | plantose | 1 |
| 10161 | plantilla | 1 |
| 10162 | plantificar | 1 |
| 10163 | planicie | 1 |
| 10164 | planeta | 1 |
| 10165 | plana | 1 |
| 10166 | plagar | 1 |
| 10167 | placita | 1 |
| 10168 | placidito | 1 |
| 10169 | placar | 1 |
| 10170 | pituitario | 1 |
| 10171 | pitón | 1 |
| 10172 | pitita | 1 |
| 10173 | pitillo | 1 |
| 10174 | pitido | 1 |
| 10175 | pitágoras | 1 |
| 10176 | piscicultura | 1 |
| 10177 | pirineo | 1 |
| 10178 | piratería | 1 |
| 10179 | pirata | 1 |
| 10180 | pirar | 1 |
| 10181 | piojoso | 1 |
| 10182 | pinto | 1 |
| 10183 | pintiparar | 1 |
| 10184 | pinitos | 1 |
| 10185 | pingüe | 1 |
| 10186 | pindonga | 1 |
| 10187 | pincelada | 1 |
| 10188 | pinar | 1 |
| 10189 | pináculo | 1 |
| 10190 | pin | 1 |
| 10191 | pimpollo | 1 |
| 10192 | pimiento | 1 |
| 10193 | piloso | 1 |
| 10194 | pilluelo | 1 |
| 10195 | pillinadas | 1 |
| 10196 | pillastre | 1 |
| 10197 | pilatos | 1 |
| 10198 | pidiole | 1 |
| 10199 | pidiéronle | 1 |
| 10200 | pídeselo | 1 |
| 10201 | pidámosle | 1 |
| 10202 | pichón | 1 |
| 10203 | picazón | 1 |
| 10204 | picaresca | 1 |
| 10205 | picardías | 1 |
| 10206 | picaporte | 1 |
| 10207 | picapedrero | 1 |
| 10208 | picadura | 1 |
| 10209 | picadilly | 1 |
| 10210 | picadillo | 1 |
| 10211 | picada | 1 |
| 10212 | pica | 1 |
| 10213 | pía | 1 |
| 10214 | petrificado | 1 |
| 10215 | petrarca | 1 |
| 10216 | petimetre | 1 |
| 10217 | pestilencia | 1 |
| 10218 | pestífero | 1 |
| 10219 | pestañar | 1 |
| 10220 | pesquisa | 1 |
| 10221 | pesebre | 1 |
| 10222 | pescadilla | 1 |
| 10223 | pesca | 1 |
| 10224 | pesares | 1 |
| 10225 | pesa | 1 |
| 10226 | perturbación | 1 |
| 10227 | pertinencia | 1 |
| 10228 | persuasivo | 1 |
| 10229 | perspectiva | 1 |
| 10230 | personas | 1 |
| 10231 | persistente | 1 |
| 10232 | perseverar | 1 |
| 10233 | persépolis | 1 |
| 10234 | perseguidor | 1 |
| 10235 | persecutorio | 1 |
| 10236 | persecuciones | 1 |
| 10237 | persa | 1 |
| 10238 | perruna | 1 |
| 10239 | perplejo | 1 |
| 10240 | perpiñá | 1 |
| 10241 | perpetuidad | 1 |
| 10242 | pernoctar | 1 |
| 10243 | perneta | 1 |
| 10244 | permuta | 1 |
| 10245 | perjudicial | 1 |
| 10246 | periquito | 1 |
| 10247 | periquillo | 1 |
| 10248 | perifollo | 1 |
| 10249 | perico | 1 |
| 10250 | pericial | 1 |
| 10251 | peri | 1 |
| 10252 | pergeñar | 1 |
| 10253 | pergenio | 1 |
| 10254 | pergamino | 1 |
| 10255 | perfumado | 1 |
| 10256 | perfec | 1 |
| 10257 | pérez | 1 |
| 10258 | perenne | 1 |
| 10259 | perendengue | 1 |
| 10260 | perejil | 1 |
| 10261 | perdidamente | 1 |
| 10262 | perdida | 1 |
| 10263 | percusión | 1 |
| 10264 | perchel | 1 |
| 10265 | peptona | 1 |
| 10266 | pepes | 1 |
| 10267 | peón | 1 |
| 10268 | peñuelas | 1 |
| 10269 | peñascal | 1 |
| 10270 | pentagrama | 1 |
| 10271 | pensionar | 1 |
| 10272 | pensaste | 1 |
| 10273 | pensará | 1 |
| 10274 | pensando | 1 |
| 10275 | pensador | 1 |
| 10276 | pensad | 1 |
| 10277 | penosamente | 1 |
| 10278 | penetración | 1 |
| 10279 | péndulo | 1 |
| 10280 | pendolista | 1 |
| 10281 | pender | 1 |
| 10282 | penca | 1 |
| 10283 | penalidad | 1 |
| 10284 | penal | 1 |
| 10285 | pelusa | 1 |
| 10286 | pelotón | 1 |
| 10287 | pelotilla | 1 |
| 10288 | pelliza | 1 |
| 10289 | pelleja | 1 |
| 10290 | pelinegro | 1 |
| 10291 | peligros | 1 |
| 10292 | pelea | 1 |
| 10293 | pelaje | 1 |
| 10294 | pelafustán | 1 |
| 10295 | peladilla | 1 |
| 10296 | peinada | 1 |
| 10297 | pégueme | 1 |
| 10298 | pégame | 1 |
| 10299 | pegajoso | 1 |
| 10300 | pegada | 1 |
| 10301 | pedrisco | 1 |
| 10302 | pedirme | 1 |
| 10303 | pedigüeño | 1 |
| 10304 | pedantería | 1 |
| 10305 | pedal | 1 |
| 10306 | pecoso | 1 |
| 10307 | pechugón | 1 |
| 10308 | pechera | 1 |
| 10309 | pececillos | 1 |
| 10310 | pecaminoso | 1 |
| 10311 | pe | 1 |
| 10312 | payo | 1 |
| 10313 | payaso | 1 |
| 10314 | payar | 1 |
| 10315 | pavimento | 1 |
| 10316 | paúl | 1 |
| 10317 | patulea | 1 |
| 10318 | patriota | 1 |
| 10319 | patrimonial | 1 |
| 10320 | patriarca | 1 |
| 10321 | patoso | 1 |
| 10322 | pato | 1 |
| 10323 | patito | 1 |
| 10324 | patitas | 1 |
| 10325 | patinar | 1 |
| 10326 | patinador | 1 |
| 10327 | pátina | 1 |
| 10328 | pateta | 1 |
| 10329 | paternidad | 1 |
| 10330 | paternalmente | 1 |
| 10331 | patentar | 1 |
| 10332 | patena | 1 |
| 10333 | pastorear | 1 |
| 10334 | pastelón | 1 |
| 10335 | pasmo | 1 |
| 10336 | pásmense | 1 |
| 10337 | pasmábase | 1 |
| 10338 | pasividad | 1 |
| 10339 | pasivas | 1 |
| 10340 | pasen | 1 |
| 10341 | paseante | 1 |
| 10342 | pasáronle | 1 |
| 10343 | pasaría | 1 |
| 10344 | pasaporte | 1 |
| 10345 | pasábanse | 1 |
| 10346 | partirle | 1 |
| 10347 | parra | 1 |
| 10348 | parola | 1 |
| 10349 | parlanchín | 1 |
| 10350 | parlamentar | 1 |
| 10351 | parienta | 1 |
| 10352 | parido | 1 |
| 10353 | parida | 1 |
| 10354 | paria | 1 |
| 10355 | párese | 1 |
| 10356 | pareciéronle | 1 |
| 10357 | parecían | 1 |
| 10358 | pardillo | 1 |
| 10359 | parche | 1 |
| 10360 | parca | 1 |
| 10361 | párate | 1 |
| 10362 | parásito | 1 |
| 10363 | parasitario | 1 |
| 10364 | pararse | 1 |
| 10365 | parándose | 1 |
| 10366 | paramento | 1 |
| 10367 | parálisis | 1 |
| 10368 | paralelamente | 1 |
| 10369 | parada | 1 |
| 10370 | paquito | 1 |
| 10371 | paquita | 1 |
| 10372 | pápiro | 1 |
| 10373 | papelillo | 1 |
| 10374 | papal | 1 |
| 10375 | papagayo | 1 |
| 10376 | paños | 1 |
| 10377 | pañero | 1 |
| 10378 | pantufla | 1 |
| 10379 | panteísta | 1 |
| 10380 | pantaleón | 1 |
| 10381 | pánfilo | 1 |
| 10382 | panegírico | 1 |
| 10383 | pandilla | 1 |
| 10384 | pancorvo | 1 |
| 10385 | panadero | 1 |
| 10386 | panacea | 1 |
| 10387 | pamplinas | 1 |
| 10388 | pámpano | 1 |
| 10389 | paludismo | 1 |
| 10390 | palpitante | 1 |
| 10391 | palpable | 1 |
| 10392 | palomar | 1 |
| 10393 | palmera | 1 |
| 10394 | palmado | 1 |
| 10395 | palmadita | 1 |
| 10396 | paliativo | 1 |
| 10397 | paletilla | 1 |
| 10398 | palatino | 1 |
| 10399 | palabrota | 1 |
| 10400 | palabrero | 1 |
| 10401 | palabreja | 1 |
| 10402 | pajita | 1 |
| 10403 | paje | 1 |
| 10404 | pajarraco | 1 |
| 10405 | pájaros | 1 |
| 10406 | pajarero | 1 |
| 10407 | paisajista | 1 |
| 10408 | paicen | 1 |
| 10409 | pagarle | 1 |
| 10410 | pagano | 1 |
| 10411 | paganismo | 1 |
| 10412 | paella | 1 |
| 10413 | padrenuestros | 1 |
| 10414 | padecimiento | 1 |
| 10415 | padecía | 1 |
| 10416 | pacto | 1 |
| 10417 | pacificar | 1 |
| 10418 | pacíficamente | 1 |
| 10419 | pacificador | 1 |
| 10420 | pabellón | 1 |
| 10421 | p | 1 |
| 10422 | oyoles | 1 |
| 10423 | oyola | 1 |
| 10424 | oyó | 1 |
| 10425 | oyen | 1 |
| 10426 | óvalo | 1 |
| 10427 | otras | 1 |
| 10428 | otero | 1 |
| 10429 | otelo | 1 |
| 10430 | oso | 1 |
| 10431 | orza | 1 |
| 10432 | oropel | 1 |
| 10433 | ornitológico | 1 |
| 10434 | ornato | 1 |
| 10435 | orlar | 1 |
| 10436 | orinar | 1 |
| 10437 | orillas | 1 |
| 10438 | orihuela | 1 |
| 10439 | orígenes | 1 |
| 10440 | orientar | 1 |
| 10441 | orgullosamente | 1 |
| 10442 | organizador | 1 |
| 10443 | organillo | 1 |
| 10444 | orfandad | 1 |
| 10445 | ordinariez | 1 |
| 10446 | ordenó | 1 |
| 10447 | ordenanzas | 1 |
| 10448 | ordenador | 1 |
| 10449 | ordenación | 1 |
| 10450 | orbe | 1 |
| 10451 | orate | 1 |
| 10452 | orangután | 1 |
| 10453 | oráculo | 1 |
| 10454 | opusiéronse | 1 |
| 10455 | opulencia | 1 |
| 10456 | optar | 1 |
| 10457 | oportunista | 1 |
| 10458 | opóngase | 1 |
| 10459 | opio | 1 |
| 10460 | opinó | 1 |
| 10461 | opiáceo | 1 |
| 10462 | ópalo | 1 |
| 10463 | opacidad | 1 |
| 10464 | ooooh | 1 |
| 10465 | onofre | 1 |
| 10466 | ondular | 1 |
| 10467 | ondear | 1 |
| 10468 | onde | 1 |
| 10469 | omoplato | 1 |
| 10470 | omnipotente | 1 |
| 10471 | omnipotencia | 1 |
| 10472 | omnímodo | 1 |
| 10473 | ómnibus | 1 |
| 10474 | omisión | 1 |
| 10475 | ombligo | 1 |
| 10476 | olvídate | 1 |
| 10477 | olvidadizo | 1 |
| 10478 | olózaga | 1 |
| 10479 | olmos | 1 |
| 10480 | olla | 1 |
| 10481 | olivares | 1 |
| 10482 | olivar | 1 |
| 10483 | oliva | 1 |
| 10484 | olimpa | 1 |
| 10485 | oleada | 1 |
| 10486 | ojiva | 1 |
| 10487 | ojeriza | 1 |
| 10488 | ojeador | 1 |
| 10489 | ojeada | 1 |
| 10490 | oímos | 1 |
| 10491 | óigame | 1 |
| 10492 | oíale | 1 |
| 10493 | ofreció | 1 |
| 10494 | ofrecíase | 1 |
| 10495 | oficialmente | 1 |
| 10496 | ofensor | 1 |
| 10497 | ofensivo | 1 |
| 10498 | ocurrírseme | 1 |
| 10499 | ocurrirle | 1 |
| 10500 | ocurrente | 1 |
| 10501 | ocurrencia | 1 |
| 10502 | ocupado | 1 |
| 10503 | oculto | 1 |
| 10504 | ocultáronse | 1 |
| 10505 | ocultamente | 1 |
| 10506 | ocular | 1 |
| 10507 | octava | 1 |
| 10508 | ocre | 1 |
| 10509 | océano | 1 |
| 10510 | ocasional | 1 |
| 10511 | obstruir | 1 |
| 10512 | obstinación | 1 |
| 10513 | obstetricia | 1 |
| 10514 | observo | 1 |
| 10515 | observándola | 1 |
| 10516 | obsérvale | 1 |
| 10517 | observábale | 1 |
| 10518 | observábala | 1 |
| 10519 | observa | 1 |
| 10520 | obsequio | 1 |
| 10521 | obligada | 1 |
| 10522 | oblicuidad | 1 |
| 10523 | oblicuar | 1 |
| 10524 | obeso | 1 |
| 10525 | obesidad | 1 |
| 10526 | obediente | 1 |
| 10527 | ñoño | 1 |
| 10528 | nutrir | 1 |
| 10529 | nuncio | 1 |
| 10530 | numismático | 1 |
| 10531 | numeroso | 1 |
| 10532 | numérico | 1 |
| 10533 | nulo | 1 |
| 10534 | nulidad | 1 |
| 10535 | nuevecito | 1 |
| 10536 | nuevas | 1 |
| 10537 | nudoso | 1 |
| 10538 | nublado | 1 |
| 10539 | noviciado | 1 |
| 10540 | novel | 1 |
| 10541 | novecientos | 1 |
| 10542 | noticiero | 1 |
| 10543 | notario | 1 |
| 10544 | notabilísimo | 1 |
| 10545 | notabilidad | 1 |
| 10546 | notábase | 1 |
| 10547 | nostri | 1 |
| 10548 | nostalgia | 1 |
| 10549 | normalizar | 1 |
| 10550 | norma | 1 |
| 10551 | nominativo | 1 |
| 10552 | nominal | 1 |
| 10553 | nómina | 1 |
| 10554 | nomenclatura | 1 |
| 10555 | nomenclátor | 1 |
| 10556 | nombrábase | 1 |
| 10557 | nogal | 1 |
| 10558 | nocivo | 1 |
| 10559 | nochecita | 1 |
| 10560 | nobiliario | 1 |
| 10561 | nizán | 1 |
| 10562 | nitro | 1 |
| 10563 | níquel | 1 |
| 10564 | niños | 1 |
| 10565 | niñero | 1 |
| 10566 | niñas | 1 |
| 10567 | nimiedad | 1 |
| 10568 | nilo | 1 |
| 10569 | nieva | 1 |
| 10570 | newton | 1 |
| 10571 | nevar | 1 |
| 10572 | nevado | 1 |
| 10573 | nevada | 1 |
| 10574 | neutralizar | 1 |
| 10575 | neptuno | 1 |
| 10576 | negrura | 1 |
| 10577 | negligente | 1 |
| 10578 | negativa | 1 |
| 10579 | negarle | 1 |
| 10580 | negación | 1 |
| 10581 | necios | 1 |
| 10582 | necesito | 1 |
| 10583 | necesitas | 1 |
| 10584 | necesitaré | 1 |
| 10585 | navío | 1 |
| 10586 | navidades | 1 |
| 10587 | navarra | 1 |
| 10588 | nauseabundo | 1 |
| 10589 | nato | 1 |
| 10590 | narración | 1 |
| 10591 | narigudo | 1 |
| 10592 | narcótico | 1 |
| 10593 | narcisus | 1 |
| 10594 | naranjeros | 1 |
| 10595 | naranjado | 1 |
| 10596 | najar | 1 |
| 10597 | nació | 1 |
| 10598 | mutuamente | 1 |
| 10599 | mutismo | 1 |
| 10600 | mutación | 1 |
| 10601 | mustiar | 1 |
| 10602 | musotros | 1 |
| 10603 | musas | 1 |
| 10604 | murmuración | 1 |
| 10605 | murga | 1 |
| 10606 | muralla | 1 |
| 10607 | muñón | 1 |
| 10608 | munificencia | 1 |
| 10609 | municipio | 1 |
| 10610 | múltiple | 1 |
| 10611 | multar | 1 |
| 10612 | mulo | 1 |
| 10613 | mujeriego | 1 |
| 10614 | mujeres | 1 |
| 10615 | mujercita | 1 |
| 10616 | mujeraza | 1 |
| 10617 | muellemente | 1 |
| 10618 | mudos | 1 |
| 10619 | mucosa | 1 |
| 10620 | mucílago | 1 |
| 10621 | muchísimas | 1 |
| 10622 | mozuela | 1 |
| 10623 | mozart | 1 |
| 10624 | mozárabe | 1 |
| 10625 | mozalbete | 1 |
| 10626 | moyano | 1 |
| 10627 | motín | 1 |
| 10628 | mostrándose | 1 |
| 10629 | mosquitero | 1 |
| 10630 | mosquita | 1 |
| 10631 | moscón | 1 |
| 10632 | mortecino | 1 |
| 10633 | mortalmente | 1 |
| 10634 | mortaja | 1 |
| 10635 | morrón | 1 |
| 10636 | morris | 1 |
| 10637 | morralla | 1 |
| 10638 | morral | 1 |
| 10639 | morosidad | 1 |
| 10640 | morirme | 1 |
| 10641 | morenito | 1 |
| 10642 | mordisco | 1 |
| 10643 | mordiscar | 1 |
| 10644 | moralizar | 1 |
| 10645 | mora | 1 |
| 10646 | moquillo | 1 |
| 10647 | moqueta | 1 |
| 10648 | moñuca | 1 |
| 10649 | monumento | 1 |
| 10650 | monumentalidad | 1 |
| 10651 | monumental | 1 |
| 10652 | montpensier | 1 |
| 10653 | montesinos | 1 |
| 10654 | montesa | 1 |
| 10655 | montés | 1 |
| 10656 | montemuru | 1 |
| 10657 | monteleón | 1 |
| 10658 | monotonía | 1 |
| 10659 | monje | 1 |
| 10660 | monigote | 1 |
| 10661 | mongólico | 1 |
| 10662 | monetario | 1 |
| 10663 | monear | 1 |
| 10664 | moncloa | 1 |
| 10665 | monasterio | 1 |
| 10666 | monamente | 1 |
| 10667 | mon | 1 |
| 10668 | momentáneamente | 1 |
| 10669 | molusco | 1 |
| 10670 | mollera | 1 |
| 10671 | molleja | 1 |
| 10672 | molesto | 1 |
| 10673 | molestábale | 1 |
| 10674 | mole | 1 |
| 10675 | moldear | 1 |
| 10676 | molar | 1 |
| 10677 | mojicón | 1 |
| 10678 | mojama | 1 |
| 10679 | modulación | 1 |
| 10680 | modos | 1 |
| 10681 | modorra | 1 |
| 10682 | modisto | 1 |
| 10683 | modistilla | 1 |
| 10684 | modismo | 1 |
| 10685 | modificación | 1 |
| 10686 | modestamente | 1 |
| 10687 | moderado | 1 |
| 10688 | moderación | 1 |
| 10689 | mochuelo | 1 |
| 10690 | mochila | 1 |
| 10691 | mocetón | 1 |
| 10692 | mixtura | 1 |
| 10693 | mitológico | 1 |
| 10694 | mito | 1 |
| 10695 | mitchell | 1 |
| 10696 | míseramente | 1 |
| 10697 | misal | 1 |
| 10698 | mirosté | 1 |
| 10699 | mirón | 1 |
| 10700 | mirola | 1 |
| 10701 | miró | 1 |
| 10702 | mirlo | 1 |
| 10703 | miriñaque | 1 |
| 10704 | mírenlo | 1 |
| 10705 | míreme | 1 |
| 10706 | mírelos | 1 |
| 10707 | mírele | 1 |
| 10708 | miráronla | 1 |
| 10709 | miraron | 1 |
| 10710 | miraría | 1 |
| 10711 | miraré | 1 |
| 10712 | míranse | 1 |
| 10713 | miranda | 1 |
| 10714 | mirad | 1 |
| 10715 | mirábase | 1 |
| 10716 | mirábales | 1 |
| 10717 | miope | 1 |
| 10718 | minino | 1 |
| 10719 | minas | 1 |
| 10720 | mina | 1 |
| 10721 | mímico | 1 |
| 10722 | mimado | 1 |
| 10723 | millonario | 1 |
| 10724 | milla | 1 |
| 10725 | militante | 1 |
| 10726 | milaneses | 1 |
| 10727 | milagroso | 1 |
| 10728 | migar | 1 |
| 10729 | mies | 1 |
| 10730 | miércoles | 1 |
| 10731 | miedoso | 1 |
| 10732 | miaja | 1 |
| 10733 | mezquita | 1 |
| 10734 | mezquinar | 1 |
| 10735 | mezclado | 1 |
| 10736 | metz | 1 |
| 10737 | metrópoli | 1 |
| 10738 | metodizar | 1 |
| 10739 | mételes | 1 |
| 10740 | mete | 1 |
| 10741 | metálicamente | 1 |
| 10742 | mesonero | 1 |
| 10743 | mesón | 1 |
| 10744 | meseta | 1 |
| 10745 | mero | 1 |
| 10746 | merendero | 1 |
| 10747 | merecimiento | 1 |
| 10748 | merecedor | 1 |
| 10749 | mercenario | 1 |
| 10750 | mercancía | 1 |
| 10751 | mentís | 1 |
| 10752 | mentirilla | 1 |
| 10753 | mentir | 1 |
| 10754 | menospreciar | 1 |
| 10755 | menoscabo | 1 |
| 10756 | mengue | 1 |
| 10757 | menguar | 1 |
| 10758 | mendiry | 1 |
| 10759 | mendicante | 1 |
| 10760 | méndez | 1 |
| 10761 | mencionado | 1 |
| 10762 | menaje | 1 |
| 10763 | membrillo | 1 |
| 10764 | melón | 1 |
| 10765 | melena | 1 |
| 10766 | melancólicamente | 1 |
| 10767 | mela | 1 |
| 10768 | mejores | 1 |
| 10769 | mejora | 1 |
| 10770 | meditemos | 1 |
| 10771 | medidor | 1 |
| 10772 | medicinal | 1 |
| 10773 | medianero | 1 |
| 10774 | mediana | 1 |
| 10775 | medalla | 1 |
| 10776 | mécele | 1 |
| 10777 | mazmorra | 1 |
| 10778 | maximiliana | 1 |
| 10779 | mauro | 1 |
| 10780 | maula | 1 |
| 10781 | matrimoniar | 1 |
| 10782 | matricular | 1 |
| 10783 | matías | 1 |
| 10784 | materialmente | 1 |
| 10785 | mateo | 1 |
| 10786 | mate | 1 |
| 10787 | mátate | 1 |
| 10788 | matarle | 1 |
| 10789 | matanza | 1 |
| 10790 | mátameles | 1 |
| 10791 | matador | 1 |
| 10792 | matachín | 1 |
| 10793 | massarnau | 1 |
| 10794 | massanielo | 1 |
| 10795 | mascullar | 1 |
| 10796 | masarnau | 1 |
| 10797 | masar | 1 |
| 10798 | martillazo | 1 |
| 10799 | martes | 1 |
| 10800 | marte | 1 |
| 10801 | marsella | 1 |
| 10802 | marítimo | 1 |
| 10803 | marisma | 1 |
| 10804 | marisabidilla | 1 |
| 10805 | mariquita | 1 |
| 10806 | mariposa | 1 |
| 10807 | marinar | 1 |
| 10808 | marica | 1 |
| 10809 | mariana | 1 |
| 10810 | margarita | 1 |
| 10811 | marcos | 1 |
| 10812 | marchose | 1 |
| 10813 | marchito | 1 |
| 10814 | márchate | 1 |
| 10815 | marcharse | 1 |
| 10816 | marchante | 1 |
| 10817 | marcador | 1 |
| 10818 | marcadamente | 1 |
| 10819 | maravillas | 1 |
| 10820 | maravillábase | 1 |
| 10821 | marar | 1 |
| 10822 | maquinar | 1 |
| 10823 | maquinación | 1 |
| 10824 | manzanilla | 1 |
| 10825 | manueles | 1 |
| 10826 | mantillas | 1 |
| 10827 | mantel | 1 |
| 10828 | mantecada | 1 |
| 10829 | mansión | 1 |
| 10830 | manolitos | 1 |
| 10831 | manolito | 1 |
| 10832 | maniobrar | 1 |
| 10833 | manglar | 1 |
| 10834 | mandria | 1 |
| 10835 | mandola | 1 |
| 10836 | mandó | 1 |
| 10837 | mandinga | 1 |
| 10838 | mandíbula | 1 |
| 10839 | mándeme | 1 |
| 10840 | mandato | 1 |
| 10841 | mándale | 1 |
| 10842 | mandado | 1 |
| 10843 | mancillar | 1 |
| 10844 | manchado | 1 |
| 10845 | mameluco | 1 |
| 10846 | malva | 1 |
| 10847 | malsonante | 1 |
| 10848 | malquerencia | 1 |
| 10849 | malhumorado | 1 |
| 10850 | maleta | 1 |
| 10851 | maleficiar | 1 |
| 10852 | maledicencia | 1 |
| 10853 | maleado | 1 |
| 10854 | maldonadas | 1 |
| 10855 | malditos | 1 |
| 10856 | malditamente | 1 |
| 10857 | maldiciente | 1 |
| 10858 | malayo | 1 |
| 10859 | malaventurado | 1 |
| 10860 | malagueño | 1 |
| 10861 | málaga | 1 |
| 10862 | mala | 1 |
| 10863 | majagranzas | 1 |
| 10864 | maíz | 1 |
| 10865 | magullar | 1 |
| 10866 | mago | 1 |
| 10867 | magnitud | 1 |
| 10868 | magnético | 1 |
| 10869 | magnánimo | 1 |
| 10870 | magistratura | 1 |
| 10871 | magistrado | 1 |
| 10872 | magisterio | 1 |
| 10873 | maestría | 1 |
| 10874 | madurez | 1 |
| 10875 | madroño | 1 |
| 10876 | madrigal | 1 |
| 10877 | madrastra | 1 |
| 10878 | madrás | 1 |
| 10879 | madoz | 1 |
| 10880 | macilento | 1 |
| 10881 | machito | 1 |
| 10882 | machete | 1 |
| 10883 | machetazo | 1 |
| 10884 | machamartillo | 1 |
| 10885 | machacárselo | 1 |
| 10886 | machacante | 1 |
| 10887 | maceta | 1 |
| 10888 | m | 1 |
| 10889 | lustro | 1 |
| 10890 | lustrar | 1 |
| 10891 | lunar | 1 |
| 10892 | lúgubremente | 1 |
| 10893 | lucio | 1 |
| 10894 | lúcido | 1 |
| 10895 | lucidez | 1 |
| 10896 | lucida | 1 |
| 10897 | luchana | 1 |
| 10898 | lozano | 1 |
| 10899 | lourdes | 1 |
| 10900 | lotero | 1 |
| 10901 | loterías | 1 |
| 10902 | losa | 1 |
| 10903 | lorito | 1 |
| 10904 | lorenzo | 1 |
| 10905 | lorenzana | 1 |
| 10906 | loquito | 1 |
| 10907 | longaniza | 1 |
| 10908 | lola | 1 |
| 10909 | lógicamente | 1 |
| 10910 | logia | 1 |
| 10911 | locamente | 1 |
| 10912 | lóbulo | 1 |
| 10913 | lluvioso | 1 |
| 10914 | llovido | 1 |
| 10915 | lloroso | 1 |
| 10916 | lloriqueo | 1 |
| 10917 | llevose | 1 |
| 10918 | llevola | 1 |
| 10919 | lléveselo | 1 |
| 10920 | llévate | 1 |
| 10921 | llevándola | 1 |
| 10922 | llévalos | 1 |
| 10923 | llevábase | 1 |
| 10924 | llevaba | 1 |
| 10925 | lleva | 1 |
| 10926 | llénese | 1 |
| 10927 | llegose | 1 |
| 10928 | llegaron | 1 |
| 10929 | llaneza | 1 |
| 10930 | llana | 1 |
| 10931 | llamola | 1 |
| 10932 | llamó | 1 |
| 10933 | llame | 1 |
| 10934 | llamáronle | 1 |
| 10935 | llamaré | 1 |
| 10936 | llámanse | 1 |
| 10937 | llaman | 1 |
| 10938 | llámame | 1 |
| 10939 | llamado | 1 |
| 10940 | liverpool | 1 |
| 10941 | liturgia | 1 |
| 10942 | listón | 1 |
| 10943 | lisonjear | 1 |
| 10944 | liso | 1 |
| 10945 | lisiar | 1 |
| 10946 | liquen | 1 |
| 10947 | linneo | 1 |
| 10948 | linfático | 1 |
| 10949 | lindeza | 1 |
| 10950 | lindero | 1 |
| 10951 | limpió | 1 |
| 10952 | limítrofe | 1 |
| 10953 | limitose | 1 |
| 10954 | limitado | 1 |
| 10955 | limbo | 1 |
| 10956 | lija | 1 |
| 10957 | ligera | 1 |
| 10958 | ligadura | 1 |
| 10959 | liga | 1 |
| 10960 | lidiar | 1 |
| 10961 | licencioso | 1 |
| 10962 | licenciatura | 1 |
| 10963 | licenciado | 1 |
| 10964 | libreta | 1 |
| 10965 | librepensador | 1 |
| 10966 | librecambista | 1 |
| 10967 | liado | 1 |
| 10968 | levántate | 1 |
| 10969 | levantamiento | 1 |
| 10970 | levantábase | 1 |
| 10971 | levanta | 1 |
| 10972 | levadura | 1 |
| 10973 | lesa | 1 |
| 10974 | lérida | 1 |
| 10975 | lepanto | 1 |
| 10976 | leopardo | 1 |
| 10977 | leo | 1 |
| 10978 | leñera | 1 |
| 10979 | leñador | 1 |
| 10980 | lentejuela | 1 |
| 10981 | lenteja | 1 |
| 10982 | lengüeta | 1 |
| 10983 | lenguado | 1 |
| 10984 | lelo | 1 |
| 10985 | legitimidad | 1 |
| 10986 | legalizar | 1 |
| 10987 | legación | 1 |
| 10988 | lee | 1 |
| 10989 | lechuzo | 1 |
| 10990 | lechuza | 1 |
| 10991 | lechuga | 1 |
| 10992 | lazada | 1 |
| 10993 | lavatorio | 1 |
| 10994 | lavandero | 1 |
| 10995 | lavadura | 1 |
| 10996 | lavado | 1 |
| 10997 | lavadero | 1 |
| 10998 | lavabo | 1 |
| 10999 | laura | 1 |
| 11000 | laudatorio | 1 |
| 11001 | laudable | 1 |
| 11002 | latino | 1 |
| 11003 | latina | 1 |
| 11004 | latigazo | 1 |
| 11005 | latido | 1 |
| 11006 | latente | 1 |
| 11007 | laringe | 1 |
| 11008 | lara | 1 |
| 11009 | lapso | 1 |
| 11010 | lanza | 1 |
| 11011 | lanuza | 1 |
| 11012 | lantigua | 1 |
| 11013 | langosta | 1 |
| 11014 | landó | 1 |
| 11015 | lanceta | 1 |
| 11016 | lamparilla | 1 |
| 11017 | lamido | 1 |
| 11018 | lamentación | 1 |
| 11019 | laico | 1 |
| 11020 | lagartijo | 1 |
| 11021 | laganitos | 1 |
| 11022 | ladronas | 1 |
| 11023 | ladrona | 1 |
| 11024 | ladinamente | 1 |
| 11025 | ladear | 1 |
| 11026 | lacrimoso | 1 |
| 11027 | lacio | 1 |
| 11028 | laceria | 1 |
| 11029 | lacerante | 1 |
| 11030 | laborar | 1 |
| 11031 | labiano | 1 |
| 11032 | juzgábase | 1 |
| 11033 | justificación | 1 |
| 11034 | justar | 1 |
| 11035 | justamente | 1 |
| 11036 | juro | 1 |
| 11037 | jurídico | 1 |
| 11038 | juraría | 1 |
| 11039 | júramelo | 1 |
| 11040 | júpiter | 1 |
| 11041 | juntose | 1 |
| 11042 | juntas | 1 |
| 11043 | juntáronse | 1 |
| 11044 | juliana | 1 |
| 11045 | jugoso | 1 |
| 11046 | jugarreta | 1 |
| 11047 | judaísmo | 1 |
| 11048 | júcar | 1 |
| 11049 | jubileo | 1 |
| 11050 | jubilación | 1 |
| 11051 | jovencito | 1 |
| 11052 | jovellar | 1 |
| 11053 | jovellanos | 1 |
| 11054 | joto | 1 |
| 11055 | josés | 1 |
| 11056 | josef | 1 |
| 11057 | jornada | 1 |
| 11058 | jordán | 1 |
| 11059 | jofaina | 1 |
| 11060 | job | 1 |
| 11061 | joaquina | 1 |
| 11062 | jilguero | 1 |
| 11063 | jícara | 1 |
| 11064 | jesuítico | 1 |
| 11065 | jesuíticamente | 1 |
| 11066 | jesuita | 1 |
| 11067 | jericó | 1 |
| 11068 | jena | 1 |
| 11069 | jaulones | 1 |
| 11070 | játiva | 1 |
| 11071 | jardinería | 1 |
| 11072 | jardinera | 1 |
| 11073 | jáquima | 1 |
| 11074 | jamona | 1 |
| 11075 | jalear | 1 |
| 11076 | jaez | 1 |
| 11077 | jactancia | 1 |
| 11078 | jacquard | 1 |
| 11079 | jacintillo | 1 |
| 11080 | jabonadura | 1 |
| 11081 | itinerario | 1 |
| 11082 | istmo | 1 |
| 11083 | israelita | 1 |
| 11084 | iscariote | 1 |
| 11085 | irujo | 1 |
| 11086 | irritabilidad | 1 |
| 11087 | irrevocable | 1 |
| 11088 | irreverentemente | 1 |
| 11089 | irreverente | 1 |
| 11090 | irreverencia | 1 |
| 11091 | irrespetuoso | 1 |
| 11092 | irremediable | 1 |
| 11093 | irme | 1 |
| 11094 | irisar | 1 |
| 11095 | irascibilidad | 1 |
| 11096 | irás | 1 |
| 11097 | iracundo | 1 |
| 11098 | irá | 1 |
| 11099 | inza | 1 |
| 11100 | involuntario | 1 |
| 11101 | involución | 1 |
| 11102 | invitado | 1 |
| 11103 | investigar | 1 |
| 11104 | investigador | 1 |
| 11105 | investigación | 1 |
| 11106 | inventor | 1 |
| 11107 | inventiva | 1 |
| 11108 | inventariar | 1 |
| 11109 | inusitado | 1 |
| 11110 | inundación | 1 |
| 11111 | intuitivo | 1 |
| 11112 | intruso | 1 |
| 11113 | introductor | 1 |
| 11114 | intríngulis | 1 |
| 11115 | intrigar | 1 |
| 11116 | intrigante | 1 |
| 11117 | intransitable | 1 |
| 11118 | intranquilizar | 1 |
| 11119 | intolerante | 1 |
| 11120 | intolerable | 1 |
| 11121 | interrumpió | 1 |
| 11122 | interrogó | 1 |
| 11123 | interrogador | 1 |
| 11124 | intérprete | 1 |
| 11125 | internar | 1 |
| 11126 | intermedio | 1 |
| 11127 | interjección | 1 |
| 11128 | interioridad | 1 |
| 11129 | interino | 1 |
| 11130 | interesado | 1 |
| 11131 | intensidad | 1 |
| 11132 | intensar | 1 |
| 11133 | intendente | 1 |
| 11134 | intencionado | 1 |
| 11135 | intempestivo | 1 |
| 11136 | intemperie | 1 |
| 11137 | inteligible | 1 |
| 11138 | insurreccionar | 1 |
| 11139 | insurrección | 1 |
| 11140 | insulto | 1 |
| 11141 | insuficiente | 1 |
| 11142 | instrumentar | 1 |
| 11143 | instruido | 1 |
| 11144 | instintos | 1 |
| 11145 | instancias | 1 |
| 11146 | instancia | 1 |
| 11147 | instalose | 1 |
| 11148 | inspirábale | 1 |
| 11149 | insolvente | 1 |
| 11150 | insoluble | 1 |
| 11151 | insistió | 1 |
| 11152 | insistente | 1 |
| 11153 | insípido | 1 |
| 11154 | insinuó | 1 |
| 11155 | insinuación | 1 |
| 11156 | insepulto | 1 |
| 11157 | inseparable | 1 |
| 11158 | insensatez | 1 |
| 11159 | insecto | 1 |
| 11160 | inquietamente | 1 |
| 11161 | inoportuno | 1 |
| 11162 | inopinadamente | 1 |
| 11163 | inocentes | 1 |
| 11164 | inocentada | 1 |
| 11165 | innumerable | 1 |
| 11166 | innovador | 1 |
| 11167 | innoble | 1 |
| 11168 | innegable | 1 |
| 11169 | inmutable | 1 |
| 11170 | inmunidad | 1 |
| 11171 | inmovilidad | 1 |
| 11172 | inmoralidad | 1 |
| 11173 | inmodestia | 1 |
| 11174 | inmensamente | 1 |
| 11175 | inmediaciones | 1 |
| 11176 | injurioso | 1 |
| 11177 | injurias | 1 |
| 11178 | injertar | 1 |
| 11179 | iniciación | 1 |
| 11180 | iniciábasele | 1 |
| 11181 | iniciábase | 1 |
| 11182 | inhumano | 1 |
| 11183 | inhabitable | 1 |
| 11184 | ingreso | 1 |
| 11185 | ingrata | 1 |
| 11186 | ingestión | 1 |
| 11187 | ingente | 1 |
| 11188 | ingénito | 1 |
| 11189 | infructuoso | 1 |
| 11190 | infranqueable | 1 |
| 11191 | informador | 1 |
| 11192 | influjo | 1 |
| 11193 | infligir | 1 |
| 11194 | inflexibilidad | 1 |
| 11195 | inflamación | 1 |
| 11196 | infinitivo | 1 |
| 11197 | infestar | 1 |
| 11198 | infantería | 1 |
| 11199 | infante | 1 |
| 11200 | infames | 1 |
| 11201 | infalibilidad | 1 |
| 11202 | inexpugnable | 1 |
| 11203 | inexpresivo | 1 |
| 11204 | inercia | 1 |
| 11205 | ineficaz | 1 |
| 11206 | industrioso | 1 |
| 11207 | indolente | 1 |
| 11208 | individualizar | 1 |
| 11209 | individualidad | 1 |
| 11210 | indisponer | 1 |
| 11211 | indisoluble | 1 |
| 11212 | indisciplinar | 1 |
| 11213 | indirectamente | 1 |
| 11214 | indio | 1 |
| 11215 | indigno | 1 |
| 11216 | indigesto | 1 |
| 11217 | indigente | 1 |
| 11218 | indicáronle | 1 |
| 11219 | indias | 1 |
| 11220 | indiano | 1 |
| 11221 | indiana | 1 |
| 11222 | indeterminado | 1 |
| 11223 | indestructible | 1 |
| 11224 | indefinido | 1 |
| 11225 | indefenso | 1 |
| 11226 | indecentes | 1 |
| 11227 | indagatorio | 1 |
| 11228 | indagador | 1 |
| 11229 | indagación | 1 |
| 11230 | incumbir | 1 |
| 11231 | incultura | 1 |
| 11232 | inculpabilidad | 1 |
| 11233 | incrustar | 1 |
| 11234 | incorruptible | 1 |
| 11235 | incorrecto | 1 |
| 11236 | incorrección | 1 |
| 11237 | incontrastable | 1 |
| 11238 | inconstancia | 1 |
| 11239 | inconsecuencia | 1 |
| 11240 | inconcuso | 1 |
| 11241 | incompatible | 1 |
| 11242 | incómodo | 1 |
| 11243 | incomodidad | 1 |
| 11244 | incoloro | 1 |
| 11245 | inclusive | 1 |
| 11246 | inclusero | 1 |
| 11247 | inclinábase | 1 |
| 11248 | incitante | 1 |
| 11249 | incipiente | 1 |
| 11250 | incienso | 1 |
| 11251 | incidencia | 1 |
| 11252 | incentivo | 1 |
| 11253 | incensario | 1 |
| 11254 | incendio | 1 |
| 11255 | incauto | 1 |
| 11256 | incautación | 1 |
| 11257 | incapacidad | 1 |
| 11258 | inaugurar | 1 |
| 11259 | inarmónico | 1 |
| 11260 | inapetente | 1 |
| 11261 | inanición | 1 |
| 11262 | inamovible | 1 |
| 11263 | inalterado | 1 |
| 11264 | inalterable | 1 |
| 11265 | inaguantable | 1 |
| 11266 | inagotable | 1 |
| 11267 | inactivo | 1 |
| 11268 | inactividad | 1 |
| 11269 | inaccesible | 1 |
| 11270 | imputar | 1 |
| 11271 | impuro | 1 |
| 11272 | impureza | 1 |
| 11273 | impulsión | 1 |
| 11274 | impúber | 1 |
| 11275 | improviso | 1 |
| 11276 | improvisación | 1 |
| 11277 | improbable | 1 |
| 11278 | impresiones | 1 |
| 11279 | impregnar | 1 |
| 11280 | imprecación | 1 |
| 11281 | imposición | 1 |
| 11282 | importunar | 1 |
| 11283 | importe | 1 |
| 11284 | importación | 1 |
| 11285 | implantar | 1 |
| 11286 | impiedad | 1 |
| 11287 | impíamente | 1 |
| 11288 | ímpetu | 1 |
| 11289 | impetrar | 1 |
| 11290 | impersonal | 1 |
| 11291 | imperfección | 1 |
| 11292 | imperativo | 1 |
| 11293 | imperar | 1 |
| 11294 | impenetrabilidad | 1 |
| 11295 | impávido | 1 |
| 11296 | impasible | 1 |
| 11297 | imparcialmente | 1 |
| 11298 | imparcial | 1 |
| 11299 | impar | 1 |
| 11300 | impalpable | 1 |
| 11301 | impaciente | 1 |
| 11302 | imítela | 1 |
| 11303 | imitativo | 1 |
| 11304 | imbuir | 1 |
| 11305 | imbecilidad | 1 |
| 11306 | imagínese | 1 |
| 11307 | imaginativo | 1 |
| 11308 | imaginario | 1 |
| 11309 | imaginándose | 1 |
| 11310 | ilustrísimo | 1 |
| 11311 | ilusionarse | 1 |
| 11312 | iluminación | 1 |
| 11313 | ilimitado | 1 |
| 11314 | ilegal | 1 |
| 11315 | ignorantes | 1 |
| 11316 | ignorado | 1 |
| 11317 | ignominioso | 1 |
| 11318 | ignominiosamente | 1 |
| 11319 | idumeo | 1 |
| 11320 | idos | 1 |
| 11321 | idólatra | 1 |
| 11322 | idealista | 1 |
| 11323 | idealismo | 1 |
| 11324 | iconografía | 1 |
| 11325 | hurgar | 1 |
| 11326 | huracán | 1 |
| 11327 | hundiose | 1 |
| 11328 | hundiéronse | 1 |
| 11329 | humorismo | 1 |
| 11330 | humillante | 1 |
| 11331 | humeante | 1 |
| 11332 | humanitario | 1 |
| 11333 | humanamente | 1 |
| 11334 | huelva | 1 |
| 11335 | huelgas | 1 |
| 11336 | huelga | 1 |
| 11337 | hoz | 1 |
| 11338 | hoyo | 1 |
| 11339 | hoyar | 1 |
| 11340 | hotel | 1 |
| 11341 | hosanna | 1 |
| 11342 | horquilla | 1 |
| 11343 | hormiguero | 1 |
| 11344 | horita | 1 |
| 11345 | horda | 1 |
| 11346 | horca | 1 |
| 11347 | horadar | 1 |
| 11348 | honorario | 1 |
| 11349 | honorabilidad | 1 |
| 11350 | honestidad | 1 |
| 11351 | homenaje | 1 |
| 11352 | hombros | 1 |
| 11353 | hombría | 1 |
| 11354 | hombres | 1 |
| 11355 | hombrada | 1 |
| 11356 | hollín | 1 |
| 11357 | hollar | 1 |
| 11358 | holgazanería | 1 |
| 11359 | holgar | 1 |
| 11360 | holgadamente | 1 |
| 11361 | hojuela | 1 |
| 11362 | hojita | 1 |
| 11363 | hojarasca | 1 |
| 11364 | hociquear | 1 |
| 11365 | hocicada | 1 |
| 11366 | hízome | 1 |
| 11367 | histrionismo | 1 |
| 11368 | historiador | 1 |
| 11369 | hispanófilo | 1 |
| 11370 | hispano | 1 |
| 11371 | hipotéticamente | 1 |
| 11372 | hipótesis | 1 |
| 11373 | hipódromo | 1 |
| 11374 | hipócrates | 1 |
| 11375 | hipo | 1 |
| 11376 | hiperbólicamente | 1 |
| 11377 | hipérbole | 1 |
| 11378 | hindostán | 1 |
| 11379 | hincósele | 1 |
| 11380 | hinchado | 1 |
| 11381 | hinchada | 1 |
| 11382 | hilvanar | 1 |
| 11383 | hileras | 1 |
| 11384 | hildebrando | 1 |
| 11385 | hijita | 1 |
| 11386 | hijastro | 1 |
| 11387 | higiénico | 1 |
| 11388 | higiene | 1 |
| 11389 | higa | 1 |
| 11390 | hierba | 1 |
| 11391 | hidropesía | 1 |
| 11392 | hiciéronle | 1 |
| 11393 | híceme | 1 |
| 11394 | heterogéneo | 1 |
| 11395 | heterodoxo | 1 |
| 11396 | hervor | 1 |
| 11397 | herrería | 1 |
| 11398 | herrar | 1 |
| 11399 | herraje | 1 |
| 11400 | hermosamente | 1 |
| 11401 | hermanas | 1 |
| 11402 | hermanar | 1 |
| 11403 | hermana | 1 |
| 11404 | hereditario | 1 |
| 11405 | heráldico | 1 |
| 11406 | hepático | 1 |
| 11407 | hendidura | 1 |
| 11408 | henchir | 1 |
| 11409 | hemorragia | 1 |
| 11410 | heliotropo | 1 |
| 11411 | helénico | 1 |
| 11412 | helena | 1 |
| 11413 | helecho | 1 |
| 11414 | helado | 1 |
| 11415 | heine | 1 |
| 11416 | hediondo | 1 |
| 11417 | hechicero | 1 |
| 11418 | hazlo | 1 |
| 11419 | hazle | 1 |
| 11420 | haymarket | 1 |
| 11421 | harta | 1 |
| 11422 | harina | 1 |
| 11423 | harías | 1 |
| 11424 | haría | 1 |
| 11425 | hamos | 1 |
| 11426 | hamo | 1 |
| 11427 | hamlet | 1 |
| 11428 | hamburgo | 1 |
| 11429 | hállase | 1 |
| 11430 | halláronse | 1 |
| 11431 | hallándose | 1 |
| 11432 | hálito | 1 |
| 11433 | halcón | 1 |
| 11434 | halagar | 1 |
| 11435 | hala | 1 |
| 11436 | hágolo | 1 |
| 11437 | hágalo | 1 |
| 11438 | haga | 1 |
| 11439 | haeckel | 1 |
| 11440 | hacinar | 1 |
| 11441 | haciendo | 1 |
| 11442 | hacíala | 1 |
| 11443 | hache | 1 |
| 11444 | haces | 1 |
| 11445 | hacendoso | 1 |
| 11446 | hacendista | 1 |
| 11447 | haced | 1 |
| 11448 | habríale | 1 |
| 11449 | habrase | 1 |
| 11450 | hablo | 1 |
| 11451 | hablan | 1 |
| 11452 | háblame | 1 |
| 11453 | habitado | 1 |
| 11454 | habilísimo | 1 |
| 11455 | habanero | 1 |
| 11456 | habanera | 1 |
| 11457 | haba | 1 |
| 11458 | guttenberg | 1 |
| 11459 | gustosamente | 1 |
| 11460 | gusanera | 1 |
| 11461 | guitarrista | 1 |
| 11462 | guita | 1 |
| 11463 | guisote | 1 |
| 11464 | guiso | 1 |
| 11465 | guirnalda | 1 |
| 11466 | guirigay | 1 |
| 11467 | guiñada | 1 |
| 11468 | guindalera | 1 |
| 11469 | guillermo | 1 |
| 11470 | guía | 1 |
| 11471 | guetaria | 1 |
| 11472 | guerrillero | 1 |
| 11473 | guerrero | 1 |
| 11474 | güeno | 1 |
| 11475 | guelbenzu | 1 |
| 11476 | gubernativo | 1 |
| 11477 | gubernación | 1 |
| 11478 | guasón | 1 |
| 11479 | guasear | 1 |
| 11480 | guarismo | 1 |
| 11481 | guardés | 1 |
| 11482 | guárdate | 1 |
| 11483 | guardando | 1 |
| 11484 | guardador | 1 |
| 11485 | guardacantón | 1 |
| 11486 | guardábalo | 1 |
| 11487 | guapetona | 1 |
| 11488 | guapamente | 1 |
| 11489 | guadalupe | 1 |
| 11490 | gruñó | 1 |
| 11491 | gruesa | 1 |
| 11492 | grúa | 1 |
| 11493 | grotesco | 1 |
| 11494 | gros | 1 |
| 11495 | grietar | 1 |
| 11496 | grieta | 1 |
| 11497 | griego | 1 |
| 11498 | gremios | 1 |
| 11499 | gremio | 1 |
| 11500 | gravitar | 1 |
| 11501 | gravísimo | 1 |
| 11502 | grasiento | 1 |
| 11503 | granulación | 1 |
| 11504 | grandullón | 1 |
| 11505 | grandísimas | 1 |
| 11506 | grandemente | 1 |
| 11507 | granadino | 1 |
| 11508 | gramatical | 1 |
| 11509 | grajear | 1 |
| 11510 | gráficamente | 1 |
| 11511 | graduar | 1 |
| 11512 | graduación | 1 |
| 11513 | gradación | 1 |
| 11514 | gracejo | 1 |
| 11515 | gozne | 1 |
| 11516 | gótico | 1 |
| 11517 | goterón | 1 |
| 11518 | gotear | 1 |
| 11519 | gorritas | 1 |
| 11520 | gorrino | 1 |
| 11521 | gorrina | 1 |
| 11522 | gorjear | 1 |
| 11523 | gordura | 1 |
| 11524 | gordito | 1 |
| 11525 | gorda | 1 |
| 11526 | golpes | 1 |
| 11527 | golondrina | 1 |
| 11528 | gollería | 1 |
| 11529 | gola | 1 |
| 11530 | goiri | 1 |
| 11531 | gobiernos | 1 |
| 11532 | gobernaor | 1 |
| 11533 | gobernable | 1 |
| 11534 | gobernábala | 1 |
| 11535 | glotón | 1 |
| 11536 | girasol | 1 |
| 11537 | gimnástica | 1 |
| 11538 | gigantón | 1 |
| 11539 | gigantesco | 1 |
| 11540 | gestión | 1 |
| 11541 | gestación | 1 |
| 11542 | germen | 1 |
| 11543 | germán | 1 |
| 11544 | genuino | 1 |
| 11545 | genuflexión | 1 |
| 11546 | gentualla | 1 |
| 11547 | gentileza | 1 |
| 11548 | generalización | 1 |
| 11549 | generador | 1 |
| 11550 | genealógico | 1 |
| 11551 | gemelo | 1 |
| 11552 | gaznate | 1 |
| 11553 | gaznápiro | 1 |
| 11554 | gatuno | 1 |
| 11555 | gatitos | 1 |
| 11556 | gaseosa | 1 |
| 11557 | gasa | 1 |
| 11558 | garrulería | 1 |
| 11559 | garrotazo | 1 |
| 11560 | garrapato | 1 |
| 11561 | garrafa | 1 |
| 11562 | garita | 1 |
| 11563 | garboso | 1 |
| 11564 | garantíceme | 1 |
| 11565 | garabito | 1 |
| 11566 | ganzúa | 1 |
| 11567 | ganso | 1 |
| 11568 | gangrenar | 1 |
| 11569 | gandía | 1 |
| 11570 | gande | 1 |
| 11571 | ganarás | 1 |
| 11572 | ganapán | 1 |
| 11573 | galo | 1 |
| 11574 | galleta | 1 |
| 11575 | gallardear | 1 |
| 11576 | galindo | 1 |
| 11577 | galimatías | 1 |
| 11578 | galileo | 1 |
| 11579 | galgo | 1 |
| 11580 | galería | 1 |
| 11581 | galdós | 1 |
| 11582 | gaeta | 1 |
| 11583 | gacha | 1 |
| 11584 | gacetilla | 1 |
| 11585 | gaceta | 1 |
| 11586 | fuste | 1 |
| 11587 | furtivo | 1 |
| 11588 | furiosamente | 1 |
| 11589 | fundado | 1 |
| 11590 | fundábase | 1 |
| 11591 | funcionario | 1 |
| 11592 | fumada | 1 |
| 11593 | fulminar | 1 |
| 11594 | fulminante | 1 |
| 11595 | fulastre | 1 |
| 11596 | fui | 1 |
| 11597 | fuguilla | 1 |
| 11598 | fuencarral | 1 |
| 11599 | fruslería | 1 |
| 11600 | fruición | 1 |
| 11601 | frugalidad | 1 |
| 11602 | frote | 1 |
| 11603 | frontero | 1 |
| 11604 | frondoso | 1 |
| 11605 | frívolo | 1 |
| 11606 | frivolidad | 1 |
| 11607 | frisar | 1 |
| 11608 | friolero | 1 |
| 11609 | fríamente | 1 |
| 11610 | fresno | 1 |
| 11611 | frecuentemente | 1 |
| 11612 | frascuelo | 1 |
| 11613 | franja | 1 |
| 11614 | franela | 1 |
| 11615 | francisca | 1 |
| 11616 | francesa | 1 |
| 11617 | francachela | 1 |
| 11618 | fragmento | 1 |
| 11619 | fouquier | 1 |
| 11620 | fotográfico | 1 |
| 11621 | fortunatita | 1 |
| 11622 | fortunatas | 1 |
| 11623 | fortunaaá | 1 |
| 11624 | fortificar | 1 |
| 11625 | fortalecimiento | 1 |
| 11626 | fortalecer | 1 |
| 11627 | foro | 1 |
| 11628 | formose | 1 |
| 11629 | fórmico | 1 |
| 11630 | formalmente | 1 |
| 11631 | formación | 1 |
| 11632 | forajido | 1 |
| 11633 | for | 1 |
| 11634 | fomentar | 1 |
| 11635 | folleto | 1 |
| 11636 | folletit | 1 |
| 11637 | fogón | 1 |
| 11638 | fofo | 1 |
| 11639 | flote | 1 |
| 11640 | flotar | 1 |
| 11641 | florido | 1 |
| 11642 | floreo | 1 |
| 11643 | florecer | 1 |
| 11644 | flojita | 1 |
| 11645 | flexión | 1 |
| 11646 | flexibilidad | 1 |
| 11647 | flema | 1 |
| 11648 | flechazo | 1 |
| 11649 | flatulento | 1 |
| 11650 | flanco | 1 |
| 11651 | flamear | 1 |
| 11652 | fláccido | 1 |
| 11653 | fiscalizar | 1 |
| 11654 | firmamento | 1 |
| 11655 | finiquito | 1 |
| 11656 | fingimiento | 1 |
| 11657 | fingidamente | 1 |
| 11658 | fincar | 1 |
| 11659 | finamente | 1 |
| 11660 | finalizar | 1 |
| 11661 | filosófica | 1 |
| 11662 | filipino | 1 |
| 11663 | filibustero | 1 |
| 11664 | filiación | 1 |
| 11665 | filete | 1 |
| 11666 | filantropía | 1 |
| 11667 | fíjese | 1 |
| 11668 | fijarse | 1 |
| 11669 | fijándose | 1 |
| 11670 | fija | 1 |
| 11671 | figurose | 1 |
| 11672 | figurón | 1 |
| 11673 | figurado | 1 |
| 11674 | figuerola | 1 |
| 11675 | fíese | 1 |
| 11676 | fierecilla | 1 |
| 11677 | fielmente | 1 |
| 11678 | fidedigno | 1 |
| 11679 | fichar | 1 |
| 11680 | ficha | 1 |
| 11681 | fiasco | 1 |
| 11682 | fiambrera | 1 |
| 11683 | feúcho | 1 |
| 11684 | fetiche | 1 |
| 11685 | festonear | 1 |
| 11686 | fervoroso | 1 |
| 11687 | ferviente | 1 |
| 11688 | férula | 1 |
| 11689 | fértil | 1 |
| 11690 | ferretería | 1 |
| 11691 | fernández | 1 |
| 11692 | fernán | 1 |
| 11693 | feote | 1 |
| 11694 | fénico | 1 |
| 11695 | fenicio | 1 |
| 11696 | fenelona | 1 |
| 11697 | femenil | 1 |
| 11698 | felpilla | 1 |
| 11699 | felpar | 1 |
| 11700 | felicíteme | 1 |
| 11701 | feíto | 1 |
| 11702 | fedro | 1 |
| 11703 | federal | 1 |
| 11704 | fecundísimo | 1 |
| 11705 | fecundar | 1 |
| 11706 | feculento | 1 |
| 11707 | fechar | 1 |
| 11708 | favorablemente | 1 |
| 11709 | fausto | 1 |
| 11710 | fauces | 1 |
| 11711 | fascinador | 1 |
| 11712 | fariseo | 1 |
| 11713 | fardar | 1 |
| 11714 | fantásticamente | 1 |
| 11715 | fantasmagórico | 1 |
| 11716 | fantasmagoría | 1 |
| 11717 | fantasma | 1 |
| 11718 | fanfarronería | 1 |
| 11719 | fanega | 1 |
| 11720 | faltón | 1 |
| 11721 | falsificar | 1 |
| 11722 | falsificación | 1 |
| 11723 | falsedad | 1 |
| 11724 | falsario | 1 |
| 11725 | falleció | 1 |
| 11726 | fallecimiento | 1 |
| 11727 | fallar | 1 |
| 11728 | faenar | 1 |
| 11729 | factura | 1 |
| 11730 | facilillo | 1 |
| 11731 | fabuloso | 1 |
| 11732 | f | 1 |
| 11733 | ezquerdo | 1 |
| 11734 | eylau | 1 |
| 11735 | exuberante | 1 |
| 11736 | extrañísimo | 1 |
| 11737 | extranjerizar | 1 |
| 11738 | extranjerismo | 1 |
| 11739 | extractor | 1 |
| 11740 | extracción | 1 |
| 11741 | extirpación | 1 |
| 11742 | exteriorizar | 1 |
| 11743 | extenuación | 1 |
| 11744 | extendido | 1 |
| 11745 | extático | 1 |
| 11746 | expuso | 1 |
| 11747 | expurgación | 1 |
| 11748 | exprisiones | 1 |
| 11749 | exprimir | 1 |
| 11750 | expresábase | 1 |
| 11751 | explícito | 1 |
| 11752 | explícitamente | 1 |
| 11753 | explícate | 1 |
| 11754 | explícame | 1 |
| 11755 | experimental | 1 |
| 11756 | experimentado | 1 |
| 11757 | expensas | 1 |
| 11758 | expender | 1 |
| 11759 | expediente | 1 |
| 11760 | exótico | 1 |
| 11761 | exordio | 1 |
| 11762 | exitazo | 1 |
| 11763 | exigente | 1 |
| 11764 | exhortar | 1 |
| 11765 | exhibición | 1 |
| 11766 | exhausto | 1 |
| 11767 | exentar | 1 |
| 11768 | exclusiva | 1 |
| 11769 | exclusión | 1 |
| 11770 | exclaustrado | 1 |
| 11771 | excesivamente | 1 |
| 11772 | excéntrico | 1 |
| 11773 | excentricidad | 1 |
| 11774 | excelentísimo | 1 |
| 11775 | exasperar | 1 |
| 11776 | examínalo | 1 |
| 11777 | exagerado | 1 |
| 11778 | exabrupto | 1 |
| 11779 | evocación | 1 |
| 11780 | evidenciar | 1 |
| 11781 | evidencia | 1 |
| 11782 | eventual | 1 |
| 11783 | evasivo | 1 |
| 11784 | evaporar | 1 |
| 11785 | evangelistas | 1 |
| 11786 | evangelios | 1 |
| 11787 | eugenio | 1 |
| 11788 | eton | 1 |
| 11789 | estúpidos | 1 |
| 11790 | estupefacto | 1 |
| 11791 | estudioso | 1 |
| 11792 | estudiantil | 1 |
| 11793 | estropicio | 1 |
| 11794 | estropajo | 1 |
| 11795 | estro | 1 |
| 11796 | estricto | 1 |
| 11797 | estrictamente | 1 |
| 11798 | estribación | 1 |
| 11799 | estreno | 1 |
| 11800 | estraza | 1 |
| 11801 | estratégico | 1 |
| 11802 | estrabismo | 1 |
| 11803 | estorbo | 1 |
| 11804 | estómagos | 1 |
| 11805 | estólido | 1 |
| 11806 | estolidez | 1 |
| 11807 | estoicismo | 1 |
| 11808 | estofar | 1 |
| 11809 | estofado | 1 |
| 11810 | estofa | 1 |
| 11811 | estimulante | 1 |
| 11812 | estigma | 1 |
| 11813 | estese | 1 |
| 11814 | esternón | 1 |
| 11815 | esterlina | 1 |
| 11816 | esterilidad | 1 |
| 11817 | esterar | 1 |
| 11818 | estera | 1 |
| 11819 | estepa | 1 |
| 11820 | estentóreo | 1 |
| 11821 | estela | 1 |
| 11822 | estatuario | 1 |
| 11823 | estarse | 1 |
| 11824 | estaribel | 1 |
| 11825 | estaré | 1 |
| 11826 | estantigua | 1 |
| 11827 | estantería | 1 |
| 11828 | estancar | 1 |
| 11829 | están | 1 |
| 11830 | estampita | 1 |
| 11831 | estampido | 1 |
| 11832 | estafeta | 1 |
| 11833 | estados | 1 |
| 11834 | estadística | 1 |
| 11835 | estacar | 1 |
| 11836 | estaca | 1 |
| 11837 | estable | 1 |
| 11838 | estábamos | 1 |
| 11839 | esquivar | 1 |
| 11840 | esquinazo | 1 |
| 11841 | esquela | 1 |
| 11842 | espuela | 1 |
| 11843 | espotrica | 1 |
| 11844 | espontáneo | 1 |
| 11845 | espontanear | 1 |
| 11846 | espontáneamente | 1 |
| 11847 | esponjar | 1 |
| 11848 | esponja | 1 |
| 11849 | espolvorear | 1 |
| 11850 | esplendor | 1 |
| 11851 | esplendidez | 1 |
| 11852 | espléndidamente | 1 |
| 11853 | espirituoso | 1 |
| 11854 | espiritui | 1 |
| 11855 | espiritualizar | 1 |
| 11856 | espiritualista | 1 |
| 11857 | espiritualidad | 1 |
| 11858 | espinoso | 1 |
| 11859 | espiar | 1 |
| 11860 | espía | 1 |
| 11861 | espérese | 1 |
| 11862 | espeluznante | 1 |
| 11863 | espejuelo | 1 |
| 11864 | especulativo | 1 |
| 11865 | especulación | 1 |
| 11866 | espectador | 1 |
| 11867 | especiar | 1 |
| 11868 | especia | 1 |
| 11869 | espátula | 1 |
| 11870 | espatarrar | 1 |
| 11871 | espárrago | 1 |
| 11872 | esparcido | 1 |
| 11873 | españolizar | 1 |
| 11874 | españita | 1 |
| 11875 | espantado | 1 |
| 11876 | espaldilla | 1 |
| 11877 | espaldarazo | 1 |
| 11878 | espaciar | 1 |
| 11879 | esos | 1 |
| 11880 | esmerose | 1 |
| 11881 | esmaltar | 1 |
| 11882 | eslabonar | 1 |
| 11883 | esforzábase | 1 |
| 11884 | escurridizo | 1 |
| 11885 | escupidera | 1 |
| 11886 | escultor | 1 |
| 11887 | esculapio | 1 |
| 11888 | escuerzo | 1 |
| 11889 | escudilla | 1 |
| 11890 | escudero | 1 |
| 11891 | escucha | 1 |
| 11892 | escuálido | 1 |
| 11893 | escualidez | 1 |
| 11894 | escuadrón | 1 |
| 11895 | escriturar | 1 |
| 11896 | escribirle | 1 |
| 11897 | escribiente | 1 |
| 11898 | escribiéndole | 1 |
| 11899 | escribe | 1 |
| 11900 | escorzo | 1 |
| 11901 | escoplo | 1 |
| 11902 | escopeta | 1 |
| 11903 | escollo | 1 |
| 11904 | escolástico | 1 |
| 11905 | escolar | 1 |
| 11906 | escogido | 1 |
| 11907 | escocia | 1 |
| 11908 | escobón | 1 |
| 11909 | esclarecer | 1 |
| 11910 | escénico | 1 |
| 11911 | escayolar | 1 |
| 11912 | escasez | 1 |
| 11913 | escarolar | 1 |
| 11914 | escarlatina | 1 |
| 11915 | escaray | 1 |
| 11916 | escaño | 1 |
| 11917 | escamoteo | 1 |
| 11918 | escamoso | 1 |
| 11919 | escama | 1 |
| 11920 | escaldar | 1 |
| 11921 | escalar | 1 |
| 11922 | escalafón | 1 |
| 11923 | esbozar | 1 |
| 11924 | erudito | 1 |
| 11925 | erre | 1 |
| 11926 | errar | 1 |
| 11927 | erizo | 1 |
| 11928 | erigir | 1 |
| 11929 | erección | 1 |
| 11930 | equivocadamente | 1 |
| 11931 | equilibrado | 1 |
| 11932 | equi | 1 |
| 11933 | epopeya | 1 |
| 11934 | epitafio | 1 |
| 11935 | episcopal | 1 |
| 11936 | epígrafe | 1 |
| 11937 | epidérmico | 1 |
| 11938 | epaminondas | 1 |
| 11939 | envolvíase | 1 |
| 11940 | envolverse | 1 |
| 11941 | envilecer | 1 |
| 11942 | envidiosa | 1 |
| 11943 | envidar | 1 |
| 11944 | envejecido | 1 |
| 11945 | envainar | 1 |
| 11946 | enturbiar | 1 |
| 11947 | entrevía | 1 |
| 11948 | entreverar | 1 |
| 11949 | entretenida | 1 |
| 11950 | entresacar | 1 |
| 11951 | entreabrir | 1 |
| 11952 | entreabierto | 1 |
| 11953 | entraré | 1 |
| 11954 | entrañas | 1 |
| 11955 | entrañable | 1 |
| 11956 | entramado | 1 |
| 11957 | entrábale | 1 |
| 11958 | entorpecimiento | 1 |
| 11959 | entonado | 1 |
| 11960 | entiendo | 1 |
| 11961 | entiéndete | 1 |
| 11962 | entiende | 1 |
| 11963 | enterrar | 1 |
| 11964 | entenebrecer | 1 |
| 11965 | entendía | 1 |
| 11966 | entendedor | 1 |
| 11967 | entendederas | 1 |
| 11968 | entarimado | 1 |
| 11969 | entablose | 1 |
| 11970 | ensordecedor | 1 |
| 11971 | enseñorear | 1 |
| 11972 | enséñemela | 1 |
| 11973 | ensartar | 1 |
| 11974 | ensarriá | 1 |
| 11975 | ensañar | 1 |
| 11976 | ensangrentado | 1 |
| 11977 | enronquecer | 1 |
| 11978 | enrejado | 1 |
| 11979 | enredador | 1 |
| 11980 | enranciar | 1 |
| 11981 | enramar | 1 |
| 11982 | enramada | 1 |
| 11983 | ennegrecer | 1 |
| 11984 | enmohecer | 1 |
| 11985 | enmascarar | 1 |
| 11986 | enjugar | 1 |
| 11987 | enjaretar | 1 |
| 11988 | enjabonáronle | 1 |
| 11989 | engullir | 1 |
| 11990 | engrasar | 1 |
| 11991 | engrandecer | 1 |
| 11992 | engranaje | 1 |
| 11993 | engomar | 1 |
| 11994 | engendro | 1 |
| 11995 | engastar | 1 |
| 11996 | engarzar | 1 |
| 11997 | engañoso | 1 |
| 11998 | engañarme | 1 |
| 11999 | engañador | 1 |
| 12000 | enfrascar | 1 |
| 12001 | enflaquecer | 1 |
| 12002 | enfermero | 1 |
| 12003 | enérgicamente | 1 |
| 12004 | enemistar | 1 |
| 12005 | eneas | 1 |
| 12006 | endurecimiento | 1 |
| 12007 | endurecer | 1 |
| 12008 | endiablar | 1 |
| 12009 | endemoniado | 1 |
| 12010 | encubrir | 1 |
| 12011 | encontrola | 1 |
| 12012 | encontrémela | 1 |
| 12013 | encontrarse | 1 |
| 12014 | encontrábase | 1 |
| 12015 | encono | 1 |
| 12016 | encomienda | 1 |
| 12017 | encomiar | 1 |
| 12018 | encinta | 1 |
| 12019 | enciclopédico | 1 |
| 12020 | encía | 1 |
| 12021 | encharcado | 1 |
| 12022 | encerrona | 1 |
| 12023 | encerrarse | 1 |
| 12024 | encerrarla | 1 |
| 12025 | encenagar | 1 |
| 12026 | encauzar | 1 |
| 12027 | encastillar | 1 |
| 12028 | encargábase | 1 |
| 12029 | encarecimiento | 1 |
| 12030 | encarcelar | 1 |
| 12031 | encanecer | 1 |
| 12032 | encandilar | 1 |
| 12033 | encandilado | 1 |
| 12034 | encajero | 1 |
| 12035 | encadenar | 1 |
| 12036 | enardecer | 1 |
| 12037 | enanito | 1 |
| 12038 | enamoriscar | 1 |
| 12039 | enamoramiento | 1 |
| 12040 | enajenación | 1 |
| 12041 | empujones | 1 |
| 12042 | empujole | 1 |
| 12043 | empujola | 1 |
| 12044 | empresario | 1 |
| 12045 | empozar | 1 |
| 12046 | emporcar | 1 |
| 12047 | empolvado | 1 |
| 12048 | empollar | 1 |
| 12049 | emplomar | 1 |
| 12050 | emplasto | 1 |
| 12051 | empinado | 1 |
| 12052 | empezamos | 1 |
| 12053 | emperifollar | 1 |
| 12054 | empequeñecer | 1 |
| 12055 | empeñadamente | 1 |
| 12056 | empeñábase | 1 |
| 12057 | empenachado | 1 |
| 12058 | emparrado | 1 |
| 12059 | emparentar | 1 |
| 12060 | emparejar | 1 |
| 12061 | empapelar | 1 |
| 12062 | empalme | 1 |
| 12063 | emolumento | 1 |
| 12064 | emoliente | 1 |
| 12065 | emocionar | 1 |
| 12066 | emisión | 1 |
| 12067 | eminentemente | 1 |
| 12068 | eminente | 1 |
| 12069 | emilion | 1 |
| 12070 | emilio | 1 |
| 12071 | emigrar | 1 |
| 12072 | embudo | 1 |
| 12073 | embrionario | 1 |
| 12074 | embotar | 1 |
| 12075 | emboscada | 1 |
| 12076 | embetunar | 1 |
| 12077 | embeber | 1 |
| 12078 | embebecimiento | 1 |
| 12079 | embaular | 1 |
| 12080 | embarcar | 1 |
| 12081 | embarazo | 1 |
| 12082 | embaldosar | 1 |
| 12083 | embalaje | 1 |
| 12084 | embajador | 1 |
| 12085 | eludir | 1 |
| 12086 | elevación | 1 |
| 12087 | electricidad | 1 |
| 12088 | elduayen | 1 |
| 12089 | elasticidad | 1 |
| 12090 | elaboración | 1 |
| 12091 | ejido | 1 |
| 12092 | ejercía | 1 |
| 12093 | ejemplos | 1 |
| 12094 | efeméride | 1 |
| 12095 | efectos | 1 |
| 12096 | efectividad | 1 |
| 12097 | edificante | 1 |
| 12098 | edecán | 1 |
| 12099 | ecuménico | 1 |
| 12100 | ecónomo | 1 |
| 12101 | economizar | 1 |
| 12102 | económicas | 1 |
| 12103 | eclipse | 1 |
| 12104 | echándose | 1 |
| 12105 | echamos | 1 |
| 12106 | echábalas | 1 |
| 12107 | echa | 1 |
| 12108 | ebro | 1 |
| 12109 | durmió | 1 |
| 12110 | durísimo | 1 |
| 12111 | duración | 1 |
| 12112 | duermes | 1 |
| 12113 | duerme | 1 |
| 12114 | duelos | 1 |
| 12115 | dudas | 1 |
| 12116 | dubitativo | 1 |
| 12117 | dubarry | 1 |
| 12118 | dualismo | 1 |
| 12119 | dromedario | 1 |
| 12120 | droguista | 1 |
| 12121 | drástico | 1 |
| 12122 | dramón | 1 |
| 12123 | doy | 1 |
| 12124 | dover | 1 |
| 12125 | dormirlas | 1 |
| 12126 | dormido | 1 |
| 12127 | dominó | 1 |
| 12128 | domini | 1 |
| 12129 | domiciliaria | 1 |
| 12130 | domiciliar | 1 |
| 12131 | domesticidad | 1 |
| 12132 | dolorosa | 1 |
| 12133 | doliente | 1 |
| 12134 | dolencia | 1 |
| 12135 | dogal | 1 |
| 12136 | doctrinario | 1 |
| 12137 | doctorar | 1 |
| 12138 | doctoral | 1 |
| 12139 | doblón | 1 |
| 12140 | doblegar | 1 |
| 12141 | doblado | 1 |
| 12142 | dobladillar | 1 |
| 12143 | do | 1 |
| 12144 | divulgar | 1 |
| 12145 | divisorio | 1 |
| 12146 | divinidades | 1 |
| 12147 | divertirse | 1 |
| 12148 | divertimiento | 1 |
| 12149 | diversidad | 1 |
| 12150 | diurno | 1 |
| 12151 | diurético | 1 |
| 12152 | distráete | 1 |
| 12153 | distraerme | 1 |
| 12154 | distingo | 1 |
| 12155 | distanciar | 1 |
| 12156 | disputábanse | 1 |
| 12157 | disponible | 1 |
| 12158 | dispone | 1 |
| 12159 | disperso | 1 |
| 12160 | dispersión | 1 |
| 12161 | dispénseme | 1 |
| 12162 | dispense | 1 |
| 12163 | dispensador | 1 |
| 12164 | disparo | 1 |
| 12165 | disparatadamente | 1 |
| 12166 | disolución | 1 |
| 12167 | dislocado | 1 |
| 12168 | disipación | 1 |
| 12169 | disimuladamente | 1 |
| 12170 | disfrute | 1 |
| 12171 | disfrazado | 1 |
| 12172 | disertar | 1 |
| 12173 | disertación | 1 |
| 12174 | diseño | 1 |
| 12175 | disentimiento | 1 |
| 12176 | disensión | 1 |
| 12177 | diseminar | 1 |
| 12178 | disección | 1 |
| 12179 | discutiose | 1 |
| 12180 | discurrió | 1 |
| 12181 | disculpose | 1 |
| 12182 | disculpa | 1 |
| 12183 | discernir | 1 |
| 12184 | dirigiose | 1 |
| 12185 | dirigiéndose | 1 |
| 12186 | diríase | 1 |
| 12187 | diré | 1 |
| 12188 | diranle | 1 |
| 12189 | diputación | 1 |
| 12190 | dipósito | 1 |
| 12191 | diploma | 1 |
| 12192 | dioses | 1 |
| 12193 | diosecito | 1 |
| 12194 | diosa | 1 |
| 12195 | díos | 1 |
| 12196 | diome | 1 |
| 12197 | diócesis | 1 |
| 12198 | dio | 1 |
| 12199 | dintel | 1 |
| 12200 | dinos | 1 |
| 12201 | dinastía | 1 |
| 12202 | dinamita | 1 |
| 12203 | dimpués | 1 |
| 12204 | diminuto | 1 |
| 12205 | dimetria | 1 |
| 12206 | dimensión | 1 |
| 12207 | dímelas | 1 |
| 12208 | diluvio | 1 |
| 12209 | diluviar | 1 |
| 12210 | dilucidar | 1 |
| 12211 | dilatado | 1 |
| 12212 | digresión | 1 |
| 12213 | dígolo | 1 |
| 12214 | dignísimo | 1 |
| 12215 | dignamente | 1 |
| 12216 | digital | 1 |
| 12217 | digestivo | 1 |
| 12218 | digestión | 1 |
| 12219 | digan | 1 |
| 12220 | dígamelo | 1 |
| 12221 | diga | 1 |
| 12222 | difundir | 1 |
| 12223 | dificilillo | 1 |
| 12224 | diferir | 1 |
| 12225 | difamatorio | 1 |
| 12226 | diestro | 1 |
| 12227 | diéronle | 1 |
| 12228 | diéranle | 1 |
| 12229 | diera | 1 |
| 12230 | dieciséis | 1 |
| 12231 | dictador | 1 |
| 12232 | diciendo | 1 |
| 12233 | dicharacho | 1 |
| 12234 | dicharachero | 1 |
| 12235 | diccionario | 1 |
| 12236 | díaz | 1 |
| 12237 | días | 1 |
| 12238 | diariamente | 1 |
| 12239 | diantre | 1 |
| 12240 | diamantino | 1 |
| 12241 | diagnóstico | 1 |
| 12242 | diáfano | 1 |
| 12243 | diafanidad | 1 |
| 12244 | diablos | 1 |
| 12245 | diablillo | 1 |
| 12246 | devolverle | 1 |
| 12247 | devocionario | 1 |
| 12248 | devastar | 1 |
| 12249 | devastador | 1 |
| 12250 | detiénese | 1 |
| 12251 | detestable | 1 |
| 12252 | determinose | 1 |
| 12253 | deteriorar | 1 |
| 12254 | detenimiento | 1 |
| 12255 | detallista | 1 |
| 12256 | desvivir | 1 |
| 12257 | desvergüenza | 1 |
| 12258 | desvergonzado | 1 |
| 12259 | desventura | 1 |
| 12260 | desventajoso | 1 |
| 12261 | desván | 1 |
| 12262 | desusar | 1 |
| 12263 | destructor | 1 |
| 12264 | destrución | 1 |
| 12265 | destinósele | 1 |
| 12266 | destinatario | 1 |
| 12267 | destiladera | 1 |
| 12268 | destierro | 1 |
| 12269 | desternillar | 1 |
| 12270 | destemplar | 1 |
| 12271 | destemplado | 1 |
| 12272 | destajo | 1 |
| 12273 | desquite | 1 |
| 12274 | desquiciamiento | 1 |
| 12275 | desprovisto | 1 |
| 12276 | desproporcionadamente | 1 |
| 12277 | desprevenido | 1 |
| 12278 | despreocupación | 1 |
| 12279 | despotricar | 1 |
| 12280 | despóticamente | 1 |
| 12281 | desplante | 1 |
| 12282 | despilfarro | 1 |
| 12283 | despilfarrar | 1 |
| 12284 | despidiéronla | 1 |
| 12285 | despidiéndose | 1 |
| 12286 | despídase | 1 |
| 12287 | despiadado | 1 |
| 12288 | desperezo | 1 |
| 12289 | despercudir | 1 |
| 12290 | despepitar | 1 |
| 12291 | despeñar | 1 |
| 12292 | despeñaperros | 1 |
| 12293 | desparramado | 1 |
| 12294 | desparpajo | 1 |
| 12295 | desorganización | 1 |
| 12296 | desollar | 1 |
| 12297 | desojar | 1 |
| 12298 | desobediente | 1 |
| 12299 | desobediencia | 1 |
| 12300 | desobedecer | 1 |
| 12301 | desnudez | 1 |
| 12302 | desmoralizar | 1 |
| 12303 | desmontar | 1 |
| 12304 | desmemoriar | 1 |
| 12305 | desmejorada | 1 |
| 12306 | desmedrado | 1 |
| 12307 | desmedir | 1 |
| 12308 | desmedidamente | 1 |
| 12309 | desmayo | 1 |
| 12310 | desmadejar | 1 |
| 12311 | deslucir | 1 |
| 12312 | deslizose | 1 |
| 12313 | desistir | 1 |
| 12314 | deshonor | 1 |
| 12315 | deshojar | 1 |
| 12316 | deshelar | 1 |
| 12317 | deshabitado | 1 |
| 12318 | desgranar | 1 |
| 12319 | desgobernar | 1 |
| 12320 | desgaste | 1 |
| 12321 | desgañitar | 1 |
| 12322 | desganar | 1 |
| 12323 | desfile | 1 |
| 12324 | desfavorecer | 1 |
| 12325 | desfavorablemente | 1 |
| 12326 | desfallecimiento | 1 |
| 12327 | desesperante | 1 |
| 12328 | desesperadamente | 1 |
| 12329 | desertar | 1 |
| 12330 | deserción | 1 |
| 12331 | desequilibrio | 1 |
| 12332 | desequilibrar | 1 |
| 12333 | desenvuelto | 1 |
| 12334 | desentrañar | 1 |
| 12335 | desentonar | 1 |
| 12336 | desentonado | 1 |
| 12337 | desenlace | 1 |
| 12338 | desengáñese | 1 |
| 12339 | desengañado | 1 |
| 12340 | desenfundar | 1 |
| 12341 | desenfadar | 1 |
| 12342 | desencajado | 1 |
| 12343 | desembozar | 1 |
| 12344 | desembozándose | 1 |
| 12345 | desembocar | 1 |
| 12346 | desembarco | 1 |
| 12347 | desembarcar | 1 |
| 12348 | desellar | 1 |
| 12349 | desdoro | 1 |
| 12350 | desdeñar | 1 |
| 12351 | desdentado | 1 |
| 12352 | descuidero | 1 |
| 12353 | descuento | 1 |
| 12354 | descubriolo | 1 |
| 12355 | descubierta | 1 |
| 12356 | descrismar | 1 |
| 12357 | descriptivo | 1 |
| 12358 | descosido | 1 |
| 12359 | descoser | 1 |
| 12360 | descorazonamiento | 1 |
| 12361 | descontento | 1 |
| 12362 | desconsolador | 1 |
| 12363 | desconsideradamente | 1 |
| 12364 | descompostura | 1 |
| 12365 | descomposición | 1 |
| 12366 | descomedir | 1 |
| 12367 | desclavar | 1 |
| 12368 | descastado | 1 |
| 12369 | descascarar | 1 |
| 12370 | descartar | 1 |
| 12371 | descarnar | 1 |
| 12372 | descargo | 1 |
| 12373 | descansado | 1 |
| 12374 | descamisar | 1 |
| 12375 | desbravar | 1 |
| 12376 | desbarajuste | 1 |
| 12377 | desbarajustar | 1 |
| 12378 | desbandada | 1 |
| 12379 | desazonar | 1 |
| 12380 | desayunar | 1 |
| 12381 | desaviar | 1 |
| 12382 | desavenido | 1 |
| 12383 | desaseo | 1 |
| 12384 | desasear | 1 |
| 12385 | desarraigar | 1 |
| 12386 | desaprobar | 1 |
| 12387 | desapacible | 1 |
| 12388 | desanimado | 1 |
| 12389 | desamparar | 1 |
| 12390 | desamortización | 1 |
| 12391 | desamor | 1 |
| 12392 | desalquilar | 1 |
| 12393 | desalmado | 1 |
| 12394 | desahucio | 1 |
| 12395 | desahogado | 1 |
| 12396 | desahogadamente | 1 |
| 12397 | desaguisado | 1 |
| 12398 | desagradablemente | 1 |
| 12399 | desafuero | 1 |
| 12400 | desaforadamente | 1 |
| 12401 | desafío | 1 |
| 12402 | desafiar | 1 |
| 12403 | desacorde | 1 |
| 12404 | desacertar | 1 |
| 12405 | desacato | 1 |
| 12406 | desacatar | 1 |
| 12407 | desabrochar | 1 |
| 12408 | desabrimiento | 1 |
| 12409 | desabrigado | 1 |
| 12410 | desabotonar | 1 |
| 12411 | derrotero | 1 |
| 12412 | derrochador | 1 |
| 12413 | derrengar | 1 |
| 12414 | derrame | 1 |
| 12415 | derramamiento | 1 |
| 12416 | derivación | 1 |
| 12417 | derechamente | 1 |
| 12418 | depurar | 1 |
| 12419 | deprisa | 1 |
| 12420 | depravar | 1 |
| 12421 | depravado | 1 |
| 12422 | depende | 1 |
| 12423 | departir | 1 |
| 12424 | denuesto | 1 |
| 12425 | dentición | 1 |
| 12426 | dentellar | 1 |
| 12427 | denotar | 1 |
| 12428 | denominar | 1 |
| 12429 | denme | 1 |
| 12430 | denle | 1 |
| 12431 | denegación | 1 |
| 12432 | demolición | 1 |
| 12433 | demoler | 1 |
| 12434 | demócrata | 1 |
| 12435 | demetria | 1 |
| 12436 | demanda | 1 |
| 12437 | demagogo | 1 |
| 12438 | demagógico | 1 |
| 12439 | delta | 1 |
| 12440 | delicias | 1 |
| 12441 | deliberar | 1 |
| 12442 | deliberadamente | 1 |
| 12443 | delfines | 1 |
| 12444 | deleznable | 1 |
| 12445 | deleitar | 1 |
| 12446 | delegar | 1 |
| 12447 | dele | 1 |
| 12448 | delatar | 1 |
| 12449 | delación | 1 |
| 12450 | dejoles | 1 |
| 12451 | dejémonos | 1 |
| 12452 | déjele | 1 |
| 12453 | déjase | 1 |
| 12454 | déjamele | 1 |
| 12455 | déjalo | 1 |
| 12456 | dejadez | 1 |
| 12457 | dejada | 1 |
| 12458 | dejábase | 1 |
| 12459 | dehesa | 1 |
| 12460 | degüello | 1 |
| 12461 | degradar | 1 |
| 12462 | degeneración | 1 |
| 12463 | defraudación | 1 |
| 12464 | definitiva | 1 |
| 12465 | déficit | 1 |
| 12466 | deficiencia | 1 |
| 12467 | defensor | 1 |
| 12468 | defensivo | 1 |
| 12469 | defendemos | 1 |
| 12470 | dédalo | 1 |
| 12471 | dedal | 1 |
| 12472 | decreto | 1 |
| 12473 | decorativo | 1 |
| 12474 | decorativamente | 1 |
| 12475 | declive | 1 |
| 12476 | declinación | 1 |
| 12477 | declaraba | 1 |
| 12478 | declamatorio | 1 |
| 12479 | declamación | 1 |
| 12480 | decisivo | 1 |
| 12481 | decirme | 1 |
| 12482 | décima | 1 |
| 12483 | decidor | 1 |
| 12484 | decidirse | 1 |
| 12485 | decididamente | 1 |
| 12486 | decible | 1 |
| 12487 | decíase | 1 |
| 12488 | decías | 1 |
| 12489 | decadente | 1 |
| 12490 | débito | 1 |
| 12491 | débilmente | 1 |
| 12492 | debes | 1 |
| 12493 | debatir | 1 |
| 12494 | deán | 1 |
| 12495 | davidson | 1 |
| 12496 | david | 1 |
| 12497 | dátiles | 1 |
| 12498 | darwin | 1 |
| 12499 | daría | 1 |
| 12500 | dañino | 1 |
| 12501 | dante | 1 |
| 12502 | danme | 1 |
| 12503 | daniel | 1 |
| 12504 | dándosela | 1 |
| 12505 | dándose | 1 |
| 12506 | dándole | 1 |
| 12507 | dámelo | 1 |
| 12508 | daganzo | 1 |
| 12509 | dadivoso | 1 |
| 12510 | dábase | 1 |
| 12511 | dabas | 1 |
| 12512 | curvo | 1 |
| 12513 | cursilería | 1 |
| 12514 | cursar | 1 |
| 12515 | curiosona | 1 |
| 12516 | curiosísimo | 1 |
| 12517 | curia | 1 |
| 12518 | curado | 1 |
| 12519 | cuneta | 1 |
| 12520 | cumplidamente | 1 |
| 12521 | cúmplase | 1 |
| 12522 | culpabilidad | 1 |
| 12523 | culminante | 1 |
| 12524 | culinario | 1 |
| 12525 | cuitado | 1 |
| 12526 | cuiste | 1 |
| 12527 | cuidarse | 1 |
| 12528 | cuidadoso | 1 |
| 12529 | cuidadito | 1 |
| 12530 | cuevas | 1 |
| 12531 | cueva | 1 |
| 12532 | cuentero | 1 |
| 12533 | cuente | 1 |
| 12534 | cuentan | 1 |
| 12535 | cuéntala | 1 |
| 12536 | cuco | 1 |
| 12537 | cuchillada | 1 |
| 12538 | cucaracha | 1 |
| 12539 | cubierto | 1 |
| 12540 | cuartos | 1 |
| 12541 | cuartilla | 1 |
| 12542 | cuarteto | 1 |
| 12543 | cuaresma | 1 |
| 12544 | cuantioso | 1 |
| 12545 | cuanta | 1 |
| 12546 | cuajo | 1 |
| 12547 | cuajado | 1 |
| 12548 | cuajada | 1 |
| 12549 | cuadrilongo | 1 |
| 12550 | cuadrilla | 1 |
| 12551 | cuadratura | 1 |
| 12552 | cuadra | 1 |
| 12553 | cuaderno | 1 |
| 12554 | cruzamiento | 1 |
| 12555 | cruelmente | 1 |
| 12556 | crudeza | 1 |
| 12557 | cruceta | 1 |
| 12558 | crónica | 1 |
| 12559 | cristianamente | 1 |
| 12560 | criáronle | 1 |
| 12561 | creyolo | 1 |
| 12562 | creyérase | 1 |
| 12563 | creyente | 1 |
| 12564 | crencha | 1 |
| 12565 | creíase | 1 |
| 12566 | creía | 1 |
| 12567 | creería | 1 |
| 12568 | creerá | 1 |
| 12569 | créemelo | 1 |
| 12570 | credulidad | 1 |
| 12571 | credo | 1 |
| 12572 | creció | 1 |
| 12573 | crecido | 1 |
| 12574 | creánmelo | 1 |
| 12575 | covacha | 1 |
| 12576 | courtray | 1 |
| 12577 | cotizar | 1 |
| 12578 | cotización | 1 |
| 12579 | cotidiano | 1 |
| 12580 | costera | 1 |
| 12581 | costados | 1 |
| 12582 | cósmico | 1 |
| 12583 | cosechero | 1 |
| 12584 | cosechar | 1 |
| 12585 | cosecha | 1 |
| 12586 | coruñas | 1 |
| 12587 | cortinilla | 1 |
| 12588 | cortésmente | 1 |
| 12589 | cortesano | 1 |
| 12590 | cortante | 1 |
| 12591 | cortada | 1 |
| 12592 | corsario | 1 |
| 12593 | corrompido | 1 |
| 12594 | corriole | 1 |
| 12595 | corrió | 1 |
| 12596 | corrígete | 1 |
| 12597 | corriéndose | 1 |
| 12598 | corríase | 1 |
| 12599 | corría | 1 |
| 12600 | correría | 1 |
| 12601 | correctivo | 1 |
| 12602 | correctísimo | 1 |
| 12603 | correa | 1 |
| 12604 | corral | 1 |
| 12605 | corpulento | 1 |
| 12606 | corpulencia | 1 |
| 12607 | corpóreo | 1 |
| 12608 | corporal | 1 |
| 12609 | coronado | 1 |
| 12610 | cornudo | 1 |
| 12611 | corifeo | 1 |
| 12612 | coria | 1 |
| 12613 | cordialidad | 1 |
| 12614 | cordelero | 1 |
| 12615 | cordelería | 1 |
| 12616 | corchete | 1 |
| 12617 | corbatín | 1 |
| 12618 | corazones | 1 |
| 12619 | corazoncito | 1 |
| 12620 | coraza | 1 |
| 12621 | corambre | 1 |
| 12622 | coquetear | 1 |
| 12623 | copulativo | 1 |
| 12624 | copudo | 1 |
| 12625 | copón | 1 |
| 12626 | copo | 1 |
| 12627 | copiosamente | 1 |
| 12628 | copiador | 1 |
| 12629 | copete | 1 |
| 12630 | convulsionar | 1 |
| 12631 | convulsión | 1 |
| 12632 | convocar | 1 |
| 12633 | convite | 1 |
| 12634 | convidado | 1 |
| 12635 | convexidad | 1 |
| 12636 | converso | 1 |
| 12637 | conversión | 1 |
| 12638 | conversar | 1 |
| 12639 | convénzase | 1 |
| 12640 | convenio | 1 |
| 12641 | convencionalismo | 1 |
| 12642 | convéncete | 1 |
| 12643 | contuso | 1 |
| 12644 | contristar | 1 |
| 12645 | contribución | 1 |
| 12646 | contreras | 1 |
| 12647 | contravenir | 1 |
| 12648 | contratista | 1 |
| 12649 | contratante | 1 |
| 12650 | contratación | 1 |
| 12651 | contrariábala | 1 |
| 12652 | contrahacer | 1 |
| 12653 | contradictorio | 1 |
| 12654 | contradicción | 1 |
| 12655 | contorno | 1 |
| 12656 | contonear | 1 |
| 12657 | contó | 1 |
| 12658 | continuadamente | 1 |
| 12659 | continuación | 1 |
| 12660 | continencia | 1 |
| 12661 | contiguo | 1 |
| 12662 | contienda | 1 |
| 12663 | contestole | 1 |
| 12664 | contera | 1 |
| 12665 | contentábase | 1 |
| 12666 | contenta | 1 |
| 12667 | contendiente | 1 |
| 12668 | contender | 1 |
| 12669 | contemporizador | 1 |
| 12670 | contempló | 1 |
| 12671 | contarle | 1 |
| 12672 | contándote | 1 |
| 12673 | contagioso | 1 |
| 12674 | contagiar | 1 |
| 12675 | contaduría | 1 |
| 12676 | contábale | 1 |
| 12677 | consunción | 1 |
| 12678 | consumidor | 1 |
| 12679 | consúltalo | 1 |
| 12680 | cónsul | 1 |
| 12681 | consuetudinario | 1 |
| 12682 | constipado | 1 |
| 12683 | constantino | 1 |
| 12684 | conspicuo | 1 |
| 12685 | consonante | 1 |
| 12686 | consonancia | 1 |
| 12687 | consolarse | 1 |
| 12688 | consolábase | 1 |
| 12689 | consola | 1 |
| 12690 | consistente | 1 |
| 12691 | considerándose | 1 |
| 12692 | considéralo | 1 |
| 12693 | considerábase | 1 |
| 12694 | considerábanla | 1 |
| 12695 | conservador | 1 |
| 12696 | conserva | 1 |
| 12697 | consecutivo | 1 |
| 12698 | consciente | 1 |
| 12699 | conociole | 1 |
| 12700 | conocía | 1 |
| 12701 | connivencia | 1 |
| 12702 | conminación | 1 |
| 12703 | conjurar | 1 |
| 12704 | conjeturar | 1 |
| 12705 | congrio | 1 |
| 12706 | congratular | 1 |
| 12707 | congestionar | 1 |
| 12708 | congestión | 1 |
| 12709 | confusamente | 1 |
| 12710 | confitería | 1 |
| 12711 | confitar | 1 |
| 12712 | confiésame | 1 |
| 12713 | confiado | 1 |
| 12714 | confesionario | 1 |
| 12715 | confección | 1 |
| 12716 | confabulación | 1 |
| 12717 | condújola | 1 |
| 12718 | condoler | 1 |
| 12719 | condiscípulo | 1 |
| 12720 | condimento | 1 |
| 12721 | condimentar | 1 |
| 12722 | condicional | 1 |
| 12723 | condenación | 1 |
| 12724 | condena | 1 |
| 12725 | concurrido | 1 |
| 12726 | concurrente | 1 |
| 12727 | conculcar | 1 |
| 12728 | concretamente | 1 |
| 12729 | concluyó | 1 |
| 12730 | concluyente | 1 |
| 12731 | concisión | 1 |
| 12732 | concilio | 1 |
| 12733 | concibe | 1 |
| 12734 | concesión | 1 |
| 12735 | concertado | 1 |
| 12736 | concernir | 1 |
| 12737 | concentración | 1 |
| 12738 | concatenación | 1 |
| 12739 | comunícase | 1 |
| 12740 | compuesto | 1 |
| 12741 | compuerta | 1 |
| 12742 | comprometido | 1 |
| 12743 | comprobar | 1 |
| 12744 | comprobación | 1 |
| 12745 | comprimiéndose | 1 |
| 12746 | compresión | 1 |
| 12747 | comprensible | 1 |
| 12748 | comprendiolo | 1 |
| 12749 | comprendió | 1 |
| 12750 | comprendiendo | 1 |
| 12751 | comprendido | 1 |
| 12752 | compras | 1 |
| 12753 | compositor | 1 |
| 12754 | complicar | 1 |
| 12755 | complemento | 1 |
| 12756 | complejo | 1 |
| 12757 | competir | 1 |
| 12758 | competidor | 1 |
| 12759 | compatible | 1 |
| 12760 | compatibilidad | 1 |
| 12761 | compasar | 1 |
| 12762 | comparó | 1 |
| 12763 | compañías | 1 |
| 12764 | compañerismo | 1 |
| 12765 | compadre | 1 |
| 12766 | compadécete | 1 |
| 12767 | compacto | 1 |
| 12768 | comisura | 1 |
| 12769 | comistrajo | 1 |
| 12770 | comió | 1 |
| 12771 | comino | 1 |
| 12772 | comilona | 1 |
| 12773 | comerías | 1 |
| 12774 | comento | 1 |
| 12775 | cómeme | 1 |
| 12776 | comedir | 1 |
| 12777 | come | 1 |
| 12778 | combustión | 1 |
| 12779 | combustible | 1 |
| 12780 | combate | 1 |
| 12781 | comanditario | 1 |
| 12782 | comadre | 1 |
| 12783 | colorete | 1 |
| 12784 | colón | 1 |
| 12785 | colocado | 1 |
| 12786 | colmillo | 1 |
| 12787 | colmar | 1 |
| 12788 | colmado | 1 |
| 12789 | collarín | 1 |
| 12790 | colisión | 1 |
| 12791 | coliflor | 1 |
| 12792 | colgajo | 1 |
| 12793 | colgadura | 1 |
| 12794 | coletazo | 1 |
| 12795 | colegiata | 1 |
| 12796 | colectivo | 1 |
| 12797 | colecta | 1 |
| 12798 | coleccionista | 1 |
| 12799 | coleccionar | 1 |
| 12800 | colapso | 1 |
| 12801 | cojera | 1 |
| 12802 | coja | 1 |
| 12803 | coincidencia | 1 |
| 12804 | cohete | 1 |
| 12805 | cogiola | 1 |
| 12806 | cogiéronse | 1 |
| 12807 | cogiditos | 1 |
| 12808 | cogida | 1 |
| 12809 | cógelo | 1 |
| 12810 | cofradía | 1 |
| 12811 | cofrade | 1 |
| 12812 | codorniz | 1 |
| 12813 | codillo | 1 |
| 12814 | código | 1 |
| 12815 | codificación | 1 |
| 12816 | codicioso | 1 |
| 12817 | codiciado | 1 |
| 12818 | codicia | 1 |
| 12819 | cochina | 1 |
| 12820 | cochecillo | 1 |
| 12821 | coca | 1 |
| 12822 | cobrábale | 1 |
| 12823 | cobardía | 1 |
| 12824 | cobalto | 1 |
| 12825 | clorhidrato | 1 |
| 12826 | cloral | 1 |
| 12827 | clima | 1 |
| 12828 | clientela | 1 |
| 12829 | clavel | 1 |
| 12830 | clave | 1 |
| 12831 | claudio | 1 |
| 12832 | clasificar | 1 |
| 12833 | clásico | 1 |
| 12834 | clases | 1 |
| 12835 | clarísimo | 1 |
| 12836 | clarín | 1 |
| 12837 | clarificar | 1 |
| 12838 | claridades | 1 |
| 12839 | claréate | 1 |
| 12840 | clandestino | 1 |
| 12841 | clamor | 1 |
| 12842 | cisne | 1 |
| 12843 | cirugía | 1 |
| 12844 | ciruela | 1 |
| 12845 | cirineo | 1 |
| 12846 | cirilo | 1 |
| 12847 | circunstancias | 1 |
| 12848 | circunspecto | 1 |
| 12849 | circunspección | 1 |
| 12850 | circunscribir | 1 |
| 12851 | circunloquio | 1 |
| 12852 | circunferencia | 1 |
| 12853 | circundar | 1 |
| 12854 | circo | 1 |
| 12855 | cinturón | 1 |
| 12856 | cincuentón | 1 |
| 12857 | cimarra | 1 |
| 12858 | cima | 1 |
| 12859 | cilindrar | 1 |
| 12860 | cilicio | 1 |
| 12861 | cigüeña | 1 |
| 12862 | cierro | 1 |
| 12863 | cierras | 1 |
| 12864 | cieno | 1 |
| 12865 | cienfuegos | 1 |
| 12866 | ciclón | 1 |
| 12867 | cicerone | 1 |
| 12868 | cicerón | 1 |
| 12869 | cicatriz | 1 |
| 12870 | cibeles | 1 |
| 12871 | chuzo | 1 |
| 12872 | churruca | 1 |
| 12873 | chupa | 1 |
| 12874 | chuletas | 1 |
| 12875 | chulesco | 1 |
| 12876 | chorrera | 1 |
| 12877 | choquezuela | 1 |
| 12878 | chopo | 1 |
| 12879 | chocolatero | 1 |
| 12880 | chochear | 1 |
| 12881 | chocarrero | 1 |
| 12882 | chitito | 1 |
| 12883 | chispazo | 1 |
| 12884 | chismoso | 1 |
| 12885 | chismorreo | 1 |
| 12886 | chismorrear | 1 |
| 12887 | chisgarabís | 1 |
| 12888 | chirrido | 1 |
| 12889 | chirimbolo | 1 |
| 12890 | chirigota | 1 |
| 12891 | chiquititas | 1 |
| 12892 | chiquillería | 1 |
| 12893 | chinchoso | 1 |
| 12894 | chinchón | 1 |
| 12895 | chinchilla | 1 |
| 12896 | chinar | 1 |
| 12897 | chillaba | 1 |
| 12898 | chilla | 1 |
| 12899 | chifladura | 1 |
| 12900 | chicooo | 1 |
| 12901 | chichón | 1 |
| 12902 | chicha | 1 |
| 12903 | chavo | 1 |
| 12904 | chavala | 1 |
| 12905 | chasquido | 1 |
| 12906 | charrán | 1 |
| 12907 | charolar | 1 |
| 12908 | chaquetar | 1 |
| 12909 | chapuzón | 1 |
| 12910 | chapoteo | 1 |
| 12911 | chapotear | 1 |
| 12912 | chanfaina | 1 |
| 12913 | chancleta | 1 |
| 12914 | champagne | 1 |
| 12915 | chambelán | 1 |
| 12916 | chalar | 1 |
| 12917 | chafarrinón | 1 |
| 12918 | chabacano | 1 |
| 12919 | cetro | 1 |
| 12920 | cetrería | 1 |
| 12921 | céspedes | 1 |
| 12922 | césar | 1 |
| 12923 | cerril | 1 |
| 12924 | cero | 1 |
| 12925 | cereza | 1 |
| 12926 | ceremoniosamente | 1 |
| 12927 | cerdear | 1 |
| 12928 | cerda | 1 |
| 12929 | cerciorose | 1 |
| 12930 | cerámica | 1 |
| 12931 | cepa | 1 |
| 12932 | ceñido | 1 |
| 12933 | centuplicar | 1 |
| 12934 | centrípeto | 1 |
| 12935 | centrífugo | 1 |
| 12936 | centímetro | 1 |
| 12937 | centenar | 1 |
| 12938 | centelleo | 1 |
| 12939 | cenital | 1 |
| 12940 | cenefa | 1 |
| 12941 | cencerro | 1 |
| 12942 | cenagoso | 1 |
| 12943 | celos | 1 |
| 12944 | célibe | 1 |
| 12945 | celibato | 1 |
| 12946 | celestina | 1 |
| 12947 | celeridad | 1 |
| 12948 | celebro | 1 |
| 12949 | celada | 1 |
| 12950 | ceguera | 1 |
| 12951 | cédula | 1 |
| 12952 | cedazo | 1 |
| 12953 | ceceoso | 1 |
| 12954 | ceceo | 1 |
| 12955 | cebón | 1 |
| 12956 | cebollino | 1 |
| 12957 | cazuela | 1 |
| 12958 | cazo | 1 |
| 12959 | cayose | 1 |
| 12960 | cavour | 1 |
| 12961 | cautivábale | 1 |
| 12962 | catre | 1 |
| 12963 | catolicismo | 1 |
| 12964 | católicamente | 1 |
| 12965 | caterva | 1 |
| 12966 | catequizar | 1 |
| 12967 | catarral | 1 |
| 12968 | catarata | 1 |
| 12969 | cataplasma | 1 |
| 12970 | catafalco | 1 |
| 12971 | catador | 1 |
| 12972 | casulla | 1 |
| 12973 | casualmente | 1 |
| 12974 | castro | 1 |
| 12975 | casto | 1 |
| 12976 | castizo | 1 |
| 12977 | castilla | 1 |
| 12978 | castellana | 1 |
| 12979 | castañuelo | 1 |
| 12980 | castañeteo | 1 |
| 12981 | castamente | 1 |
| 12982 | casquillo | 1 |
| 12983 | casquería | 1 |
| 12984 | caspitina | 1 |
| 12985 | caspa | 1 |
| 12986 | casose | 1 |
| 12987 | caseta | 1 |
| 12988 | cascajo | 1 |
| 12989 | cascado | 1 |
| 12990 | cásale | 1 |
| 12991 | casadita | 1 |
| 12992 | cartuja | 1 |
| 12993 | cartelón | 1 |
| 12994 | carroza | 1 |
| 12995 | carromato | 1 |
| 12996 | carrillera | 1 |
| 12997 | carrillar | 1 |
| 12998 | carrete | 1 |
| 12999 | carraspear | 1 |
| 13000 | carrasca | 1 |
| 13001 | carpetazo | 1 |
| 13002 | carnavales | 1 |
| 13003 | carnaval | 1 |
| 13004 | carmesí | 1 |
| 13005 | caricatura | 1 |
| 13006 | cariacontecido | 1 |
| 13007 | cargado | 1 |
| 13008 | cargábanle | 1 |
| 13009 | careto | 1 |
| 13010 | cardiaco | 1 |
| 13011 | cárdeno | 1 |
| 13012 | cardar | 1 |
| 13013 | carcomido | 1 |
| 13014 | caracoles | 1 |
| 13015 | carabanchel | 1 |
| 13016 | captura | 1 |
| 13017 | cápsulas | 1 |
| 13018 | capote | 1 |
| 13019 | capitanear | 1 |
| 13020 | capitalizar | 1 |
| 13021 | capitación | 1 |
| 13022 | capear | 1 |
| 13023 | caño | 1 |
| 13024 | cañamazo | 1 |
| 13025 | cantonal | 1 |
| 13026 | cantina | 1 |
| 13027 | canterac | 1 |
| 13028 | cantábrico | 1 |
| 13029 | canon | 1 |
| 13030 | cano | 1 |
| 13031 | canino | 1 |
| 13032 | canilla | 1 |
| 13033 | canijo | 1 |
| 13034 | caníbal | 1 |
| 13035 | canelo | 1 |
| 13036 | candil | 1 |
| 13037 | candidatura | 1 |
| 13038 | candidato | 1 |
| 13039 | candela | 1 |
| 13040 | candado | 1 |
| 13041 | cancillería | 1 |
| 13042 | cancelación | 1 |
| 13043 | cancel | 1 |
| 13044 | cancamurria | 1 |
| 13045 | canasto | 1 |
| 13046 | canasta | 1 |
| 13047 | canapé | 1 |
| 13048 | canallas | 1 |
| 13049 | canallada | 1 |
| 13050 | camús | 1 |
| 13051 | camuesa | 1 |
| 13052 | camposanto | 1 |
| 13053 | campos | 1 |
| 13054 | campestre | 1 |
| 13055 | campesino | 1 |
| 13056 | campanillas | 1 |
| 13057 | campaneo | 1 |
| 13058 | camita | 1 |
| 13059 | camisola | 1 |
| 13060 | camión | 1 |
| 13061 | caminata | 1 |
| 13062 | camilla | 1 |
| 13063 | cambrí | 1 |
| 13064 | camarín | 1 |
| 13065 | camarilla | 1 |
| 13066 | camaleón | 1 |
| 13067 | calzoncillos | 1 |
| 13068 | calvinista | 1 |
| 13069 | cálmese | 1 |
| 13070 | cálmate | 1 |
| 13071 | callémonos | 1 |
| 13072 | calleja | 1 |
| 13073 | cállatela | 1 |
| 13074 | callao | 1 |
| 13075 | cáliz | 1 |
| 13076 | caligráfico | 1 |
| 13077 | caligrafía | 1 |
| 13078 | calificado | 1 |
| 13079 | calibre | 1 |
| 13080 | calibrar | 1 |
| 13081 | calenturiento | 1 |
| 13082 | calendario | 1 |
| 13083 | caldo | 1 |
| 13084 | calderón | 1 |
| 13085 | calcula | 1 |
| 13086 | calco | 1 |
| 13087 | calcetín | 1 |
| 13088 | calcetar | 1 |
| 13089 | calcáreo | 1 |
| 13090 | calatravas | 1 |
| 13091 | calatrava | 1 |
| 13092 | calaínos | 1 |
| 13093 | calainos | 1 |
| 13094 | calado | 1 |
| 13095 | cajista | 1 |
| 13096 | cae | 1 |
| 13097 | caduco | 1 |
| 13098 | cadmio | 1 |
| 13099 | cadencioso | 1 |
| 13100 | cadencia | 1 |
| 13101 | cadavérico | 1 |
| 13102 | cacumen | 1 |
| 13103 | caciquismo | 1 |
| 13104 | cachucha | 1 |
| 13105 | cacharrería | 1 |
| 13106 | cacao | 1 |
| 13107 | cacahuete | 1 |
| 13108 | cabrón | 1 |
| 13109 | cabrito | 1 |
| 13110 | cabriolar | 1 |
| 13111 | cable | 1 |
| 13112 | cabestrillo | 1 |
| 13113 | cabecilla | 1 |
| 13114 | cabaña | 1 |
| 13115 | caballista | 1 |
| 13116 | caballeriza | 1 |
| 13117 | caballerete | 1 |
| 13118 | caballeresco | 1 |
| 13119 | buscarle | 1 |
| 13120 | buscaba | 1 |
| 13121 | burocracia | 1 |
| 13122 | búrlate | 1 |
| 13123 | burlador | 1 |
| 13124 | burguesía | 1 |
| 13125 | burgués | 1 |
| 13126 | burbujear | 1 |
| 13127 | buque | 1 |
| 13128 | buñuelo | 1 |
| 13129 | bufón | 1 |
| 13130 | bufido | 1 |
| 13131 | bruñir | 1 |
| 13132 | bruñido | 1 |
| 13133 | brr | 1 |
| 13134 | broza | 1 |
| 13135 | brote | 1 |
| 13136 | bromista | 1 |
| 13137 | brochazo | 1 |
| 13138 | brindose | 1 |
| 13139 | brillo | 1 |
| 13140 | brillantísimo | 1 |
| 13141 | brillantez | 1 |
| 13142 | brihuega | 1 |
| 13143 | bribonaza | 1 |
| 13144 | bribonada | 1 |
| 13145 | breviario | 1 |
| 13146 | brevedad | 1 |
| 13147 | brega | 1 |
| 13148 | brebaje | 1 |
| 13149 | brazada | 1 |
| 13150 | braveza | 1 |
| 13151 | brasa | 1 |
| 13152 | bramante | 1 |
| 13153 | bramaba | 1 |
| 13154 | bracero | 1 |
| 13155 | bracear | 1 |
| 13156 | bozal | 1 |
| 13157 | boya | 1 |
| 13158 | botoneras | 1 |
| 13159 | boteros | 1 |
| 13160 | botellazo | 1 |
| 13161 | bote | 1 |
| 13162 | botánica | 1 |
| 13163 | bosquejar | 1 |
| 13164 | borricada | 1 |
| 13165 | borrascoso | 1 |
| 13166 | borgias | 1 |
| 13167 | bordadores | 1 |
| 13168 | bordador | 1 |
| 13169 | borbotones | 1 |
| 13170 | borbones | 1 |
| 13171 | bonitamente | 1 |
| 13172 | bonillas | 1 |
| 13173 | bondadosamente | 1 |
| 13174 | bonancible | 1 |
| 13175 | bomberos | 1 |
| 13176 | bombero | 1 |
| 13177 | bolo | 1 |
| 13178 | bollero | 1 |
| 13179 | bollería | 1 |
| 13180 | bólido | 1 |
| 13181 | bohardilla | 1 |
| 13182 | bofes | 1 |
| 13183 | bocón | 1 |
| 13184 | bochorno | 1 |
| 13185 | bocanada | 1 |
| 13186 | bobada | 1 |
| 13187 | blonda | 1 |
| 13188 | blasonar | 1 |
| 13189 | blasfemo | 1 |
| 13190 | blasfemar | 1 |
| 13191 | blanquecino | 1 |
| 13192 | blandamente | 1 |
| 13193 | bizcochar | 1 |
| 13194 | bizantino | 1 |
| 13195 | bisoño | 1 |
| 13196 | bismark | 1 |
| 13197 | bismarck | 1 |
| 13198 | birmingham | 1 |
| 13199 | biombo | 1 |
| 13200 | bilbao | 1 |
| 13201 | bigotera | 1 |
| 13202 | bifurcación | 1 |
| 13203 | bienhechor | 1 |
| 13204 | bienaventuranza | 1 |
| 13205 | bienaventurados | 1 |
| 13206 | bicoca | 1 |
| 13207 | bichito | 1 |
| 13208 | bíblico | 1 |
| 13209 | betsabée | 1 |
| 13210 | besamanos | 1 |
| 13211 | berza | 1 |
| 13212 | berro | 1 |
| 13213 | bergante | 1 |
| 13214 | berdan | 1 |
| 13215 | benignita | 1 |
| 13216 | benignidad | 1 |
| 13217 | benévolamente | 1 |
| 13218 | bendita | 1 |
| 13219 | belladona | 1 |
| 13220 | belicoso | 1 |
| 13221 | belfort | 1 |
| 13222 | belencita | 1 |
| 13223 | beldar | 1 |
| 13224 | begonia | 1 |
| 13225 | befa | 1 |
| 13226 | becerrada | 1 |
| 13227 | bebedor | 1 |
| 13228 | bebe | 1 |
| 13229 | baztán | 1 |
| 13230 | batuta | 1 |
| 13231 | batlló | 1 |
| 13232 | batido | 1 |
| 13233 | batallita | 1 |
| 13234 | batahola | 1 |
| 13235 | batacazo | 1 |
| 13236 | basto | 1 |
| 13237 | bastión | 1 |
| 13238 | bastimento | 1 |
| 13239 | bastiat | 1 |
| 13240 | bastardo | 1 |
| 13241 | bastábale | 1 |
| 13242 | basílica | 1 |
| 13243 | basilea | 1 |
| 13244 | báscula | 1 |
| 13245 | basca | 1 |
| 13246 | basamento | 1 |
| 13247 | bártulo | 1 |
| 13248 | barroquismo | 1 |
| 13249 | barrigón | 1 |
| 13250 | barreno | 1 |
| 13251 | barredura | 1 |
| 13252 | barranco | 1 |
| 13253 | barranca | 1 |
| 13254 | barquinazo | 1 |
| 13255 | baronesa | 1 |
| 13256 | barón | 1 |
| 13257 | barnizar | 1 |
| 13258 | barniz | 1 |
| 13259 | bargueño | 1 |
| 13260 | bardal | 1 |
| 13261 | barcia | 1 |
| 13262 | barca | 1 |
| 13263 | barbilla | 1 |
| 13264 | barbería | 1 |
| 13265 | baratillo | 1 |
| 13266 | barástolis | 1 |
| 13267 | baraja | 1 |
| 13268 | bar | 1 |
| 13269 | baquetear | 1 |
| 13270 | bañar | 1 |
| 13271 | bañado | 1 |
| 13272 | banquero | 1 |
| 13273 | bandido | 1 |
| 13274 | banderita | 1 |
| 13275 | banderillero | 1 |
| 13276 | baluarte | 1 |
| 13277 | balsain | 1 |
| 13278 | balsa | 1 |
| 13279 | ballesta | 1 |
| 13280 | baldón | 1 |
| 13281 | baldío | 1 |
| 13282 | balanceo | 1 |
| 13283 | baladronada | 1 |
| 13284 | bajarlo | 1 |
| 13285 | bajáis | 1 |
| 13286 | bailotear | 1 |
| 13287 | bailly | 1 |
| 13288 | baillière | 1 |
| 13289 | bagaje | 1 |
| 13290 | badila | 1 |
| 13291 | bachillería | 1 |
| 13292 | bachiller | 1 |
| 13293 | bache | 1 |
| 13294 | babosa | 1 |
| 13295 | babilonia | 1 |
| 13296 | babieca | 1 |
| 13297 | babia | 1 |
| 13298 | babel | 1 |
| 13299 | b | 1 |
| 13300 | azulejo | 1 |
| 13301 | azulado | 1 |
| 13302 | azufre | 1 |
| 13303 | azucena | 1 |
| 13304 | azotaina | 1 |
| 13305 | azar | 1 |
| 13306 | azalea | 1 |
| 13307 | azada | 1 |
| 13308 | avieso | 1 |
| 13309 | avidez | 1 |
| 13310 | aventurábase | 1 |
| 13311 | avenida | 1 |
| 13312 | avenencia | 1 |
| 13313 | avellana | 1 |
| 13314 | avasallador | 1 |
| 13315 | avaro | 1 |
| 13316 | autorizado | 1 |
| 13317 | autenticidad | 1 |
| 13318 | austerlitz | 1 |
| 13319 | austeridad | 1 |
| 13320 | auspicios | 1 |
| 13321 | aurorita | 1 |
| 13322 | aureolar | 1 |
| 13323 | augurio | 1 |
| 13324 | audición | 1 |
| 13325 | atril | 1 |
| 13326 | atreviose | 1 |
| 13327 | atrevidilla | 1 |
| 13328 | atrayéndola | 1 |
| 13329 | atravesósele | 1 |
| 13330 | atragantar | 1 |
| 13331 | atosigar | 1 |
| 13332 | atonía | 1 |
| 13333 | atmosférico | 1 |
| 13334 | atleta | 1 |
| 13335 | atlas | 1 |
| 13336 | atiza | 1 |
| 13337 | atisbo | 1 |
| 13338 | atisbar | 1 |
| 13339 | atisbador | 1 |
| 13340 | atienda | 1 |
| 13341 | atestar | 1 |
| 13342 | atentísimamente | 1 |
| 13343 | atener | 1 |
| 13344 | ateneo | 1 |
| 13345 | ateísmo | 1 |
| 13346 | atavismo | 1 |
| 13347 | atarés | 1 |
| 13348 | atareado | 1 |
| 13349 | atañer | 1 |
| 13350 | atadijo | 1 |
| 13351 | asustose | 1 |
| 13352 | asustábase | 1 |
| 13353 | asturias | 1 |
| 13354 | astronomía | 1 |
| 13355 | astilla | 1 |
| 13356 | asquerosidad | 1 |
| 13357 | aspirador | 1 |
| 13358 | aspaventar | 1 |
| 13359 | aspasia | 1 |
| 13360 | asomose | 1 |
| 13361 | asombroso | 1 |
| 13362 | asolear | 1 |
| 13363 | asmático | 1 |
| 13364 | asistente | 1 |
| 13365 | asilado | 1 |
| 13366 | asia | 1 |
| 13367 | aserrar | 1 |
| 13368 | aseñorado | 1 |
| 13369 | asensio | 1 |
| 13370 | asegurado | 1 |
| 13371 | asear | 1 |
| 13372 | aseado | 1 |
| 13373 | ascetismo | 1 |
| 13374 | ascensión | 1 |
| 13375 | asamblea | 1 |
| 13376 | asaltáronle | 1 |
| 13377 | asadura | 1 |
| 13378 | asador | 1 |
| 13379 | asa | 1 |
| 13380 | artimaña | 1 |
| 13381 | artillero | 1 |
| 13382 | artillería | 1 |
| 13383 | artificioso | 1 |
| 13384 | artificio | 1 |
| 13385 | artesiano | 1 |
| 13386 | artesano | 1 |
| 13387 | artes | 1 |
| 13388 | arrumaco | 1 |
| 13389 | arrojo | 1 |
| 13390 | arrodillose | 1 |
| 13391 | arrobo | 1 |
| 13392 | arrimo | 1 |
| 13393 | arriesgar | 1 |
| 13394 | arrepentidas | 1 |
| 13395 | arremangar | 1 |
| 13396 | arremangado | 1 |
| 13397 | arreglole | 1 |
| 13398 | arréglame | 1 |
| 13399 | arredrar | 1 |
| 13400 | arreciar | 1 |
| 13401 | arrebolar | 1 |
| 13402 | arrear | 1 |
| 13403 | arrasar | 1 |
| 13404 | arrancose | 1 |
| 13405 | arquitecto | 1 |
| 13406 | arqueólogo | 1 |
| 13407 | arqueológico | 1 |
| 13408 | arqueología | 1 |
| 13409 | aroma | 1 |
| 13410 | arnés | 1 |
| 13411 | armónico | 1 |
| 13412 | armiño | 1 |
| 13413 | armería | 1 |
| 13414 | armador | 1 |
| 13415 | aristarco | 1 |
| 13416 | arisco | 1 |
| 13417 | arias | 1 |
| 13418 | arguyó | 1 |
| 13419 | argüir | 1 |
| 13420 | argüía | 1 |
| 13421 | argucia | 1 |
| 13422 | argolla | 1 |
| 13423 | arganda | 1 |
| 13424 | argamasillesca | 1 |
| 13425 | ardoroso | 1 |
| 13426 | arcola | 1 |
| 13427 | archivo | 1 |
| 13428 | archipámpano | 1 |
| 13429 | arcar | 1 |
| 13430 | arcada | 1 |
| 13431 | arboleda | 1 |
| 13432 | arbitrar | 1 |
| 13433 | aravaca | 1 |
| 13434 | arañazo | 1 |
| 13435 | araña | 1 |
| 13436 | arango | 1 |
| 13437 | aranceles | 1 |
| 13438 | arancel | 1 |
| 13439 | aragonés | 1 |
| 13440 | arábigo | 1 |
| 13441 | arabesco | 1 |
| 13442 | aquellas | 1 |
| 13443 | apuesto | 1 |
| 13444 | apuestas | 1 |
| 13445 | aprovechamiento | 1 |
| 13446 | apropiación | 1 |
| 13447 | aprobación | 1 |
| 13448 | apretura | 1 |
| 13449 | apresúrate | 1 |
| 13450 | apresurado | 1 |
| 13451 | apresuradamente | 1 |
| 13452 | aprendizaje | 1 |
| 13453 | aprendiz | 1 |
| 13454 | apréndete | 1 |
| 13455 | aprended | 1 |
| 13456 | apremiante | 1 |
| 13457 | apoyó | 1 |
| 13458 | apoyatura | 1 |
| 13459 | apóyate | 1 |
| 13460 | apostólico | 1 |
| 13461 | apóstoles | 1 |
| 13462 | aposentar | 1 |
| 13463 | aporreado | 1 |
| 13464 | apología | 1 |
| 13465 | apoderarse | 1 |
| 13466 | apócrifo | 1 |
| 13467 | apocamiento | 1 |
| 13468 | apocado | 1 |
| 13469 | aplauso | 1 |
| 13470 | apio | 1 |
| 13471 | apilar | 1 |
| 13472 | apetitoso | 1 |
| 13473 | aperrear | 1 |
| 13474 | apergaminar | 1 |
| 13475 | apercibir | 1 |
| 13476 | apeose | 1 |
| 13477 | apéndice | 1 |
| 13478 | apencar | 1 |
| 13479 | apegar | 1 |
| 13480 | apegado | 1 |
| 13481 | apáticamente | 1 |
| 13482 | apartola | 1 |
| 13483 | aparentemente | 1 |
| 13484 | aparejar | 1 |
| 13485 | aparatoso | 1 |
| 13486 | apandar | 1 |
| 13487 | apalabrar | 1 |
| 13488 | apaisado | 1 |
| 13489 | apacentar | 1 |
| 13490 | apabullar | 1 |
| 13491 | aorta | 1 |
| 13492 | años | 1 |
| 13493 | añada | 1 |
| 13494 | anudar | 1 |
| 13495 | anualmente | 1 |
| 13496 | antorcha | 1 |
| 13497 | antoñita | 1 |
| 13498 | antonieta | 1 |
| 13499 | antojo | 1 |
| 13500 | antojitos | 1 |
| 13501 | antípodas | 1 |
| 13502 | antipatriótico | 1 |
| 13503 | antioquía | 1 |
| 13504 | antigüedad | 1 |
| 13505 | antiguamente | 1 |
| 13506 | antigualla | 1 |
| 13507 | antiespasmódico | 1 |
| 13508 | antieconómico | 1 |
| 13509 | antidinásticas | 1 |
| 13510 | anticonstitucional | 1 |
| 13511 | anticipo | 1 |
| 13512 | anticipándome | 1 |
| 13513 | antequera | 1 |
| 13514 | anteponer | 1 |
| 13515 | antecedentes | 1 |
| 13516 | anteanoche | 1 |
| 13517 | antaño | 1 |
| 13518 | antagonista | 1 |
| 13519 | ansiado | 1 |
| 13520 | anotación | 1 |
| 13521 | anormal | 1 |
| 13522 | anómalo | 1 |
| 13523 | anomalía | 1 |
| 13524 | aniversario | 1 |
| 13525 | anisar | 1 |
| 13526 | aniquilamiento | 1 |
| 13527 | anímese | 1 |
| 13528 | animales | 1 |
| 13529 | anilla | 1 |
| 13530 | angustiado | 1 |
| 13531 | angulema | 1 |
| 13532 | anguila | 1 |
| 13533 | angostura | 1 |
| 13534 | angélico | 1 |
| 13535 | angélica | 1 |
| 13536 | anestésico | 1 |
| 13537 | andurrial | 1 |
| 13538 | andante | 1 |
| 13539 | andando | 1 |
| 13540 | andamiar | 1 |
| 13541 | andábanle | 1 |
| 13542 | anclar | 1 |
| 13543 | anchura | 1 |
| 13544 | anchoa | 1 |
| 13545 | análogo | 1 |
| 13546 | anacronismo | 1 |
| 13547 | anacleto | 1 |
| 13548 | anabaptista | 1 |
| 13549 | amputación | 1 |
| 13550 | ampolla | 1 |
| 13551 | amplísimo | 1 |
| 13552 | amplio | 1 |
| 13553 | amotinar | 1 |
| 13554 | amorrar | 1 |
| 13555 | amorosamente | 1 |
| 13556 | amorío | 1 |
| 13557 | amoniaco | 1 |
| 13558 | amodorrar | 1 |
| 13559 | amito | 1 |
| 13560 | amistoso | 1 |
| 13561 | amistosamente | 1 |
| 13562 | amistar | 1 |
| 13563 | amigos | 1 |
| 13564 | amigas | 1 |
| 13565 | amigablemente | 1 |
| 13566 | amenazador | 1 |
| 13567 | ambientar | 1 |
| 13568 | ambicionar | 1 |
| 13569 | ámbar | 1 |
| 13570 | amazónico | 1 |
| 13571 | amasábanlo | 1 |
| 13572 | amasábalo | 1 |
| 13573 | amas | 1 |
| 13574 | amartelamiento | 1 |
| 13575 | amarillento | 1 |
| 13576 | amargor | 1 |
| 13577 | amañar | 1 |
| 13578 | amanerado | 1 |
| 13579 | amancebar | 1 |
| 13580 | amalgamar | 1 |
| 13581 | amago | 1 |
| 13582 | amagar | 1 |
| 13583 | amaestrado | 1 |
| 13584 | amábale | 1 |
| 13585 | ama | 1 |
| 13586 | alzamiento | 1 |
| 13587 | alza | 1 |
| 13588 | alumbramiento | 1 |
| 13589 | aludido | 1 |
| 13590 | alucinado | 1 |
| 13591 | altozano | 1 |
| 13592 | altivez | 1 |
| 13593 | alteza | 1 |
| 13594 | alternativamente | 1 |
| 13595 | alternadamente | 1 |
| 13596 | altanería | 1 |
| 13597 | altaneramente | 1 |
| 13598 | alsacia | 1 |
| 13599 | alonar | 1 |
| 13600 | alojar | 1 |
| 13601 | alojamiento | 1 |
| 13602 | almuerzas | 1 |
| 13603 | almorzaré | 1 |
| 13604 | almoneda | 1 |
| 13605 | almohadón | 1 |
| 13606 | almidón | 1 |
| 13607 | almería | 1 |
| 13608 | almeja | 1 |
| 13609 | almansa | 1 |
| 13610 | almanaque | 1 |
| 13611 | almagre | 1 |
| 13612 | allego | 1 |
| 13613 | allegar | 1 |
| 13614 | allegado | 1 |
| 13615 | allegadizo | 1 |
| 13616 | allanamiento | 1 |
| 13617 | aliñar | 1 |
| 13618 | alijo | 1 |
| 13619 | alijar | 1 |
| 13620 | alifonso | 1 |
| 13621 | alicante | 1 |
| 13622 | alias | 1 |
| 13623 | aliar | 1 |
| 13624 | alianza | 1 |
| 13625 | alhambra | 1 |
| 13626 | álgido | 1 |
| 13627 | algeciras | 1 |
| 13628 | algarroba | 1 |
| 13629 | alga | 1 |
| 13630 | alfilerazo | 1 |
| 13631 | aleluya | 1 |
| 13632 | alelí | 1 |
| 13633 | alejose | 1 |
| 13634 | alejándose | 1 |
| 13635 | alegrose | 1 |
| 13636 | alegremente | 1 |
| 13637 | alegrarse | 1 |
| 13638 | alegórico | 1 |
| 13639 | alegoría | 1 |
| 13640 | aldeano | 1 |
| 13641 | alcorcón | 1 |
| 13642 | alcoholismo | 1 |
| 13643 | alcohólico | 1 |
| 13644 | alcira | 1 |
| 13645 | alcé | 1 |
| 13646 | alcarria | 1 |
| 13647 | alcarreño | 1 |
| 13648 | alcaraz | 1 |
| 13649 | alcantarillar | 1 |
| 13650 | alcanfor | 1 |
| 13651 | alcánceme | 1 |
| 13652 | alcaloide | 1 |
| 13653 | alcaldía | 1 |
| 13654 | alcahuete | 1 |
| 13655 | alcachofa | 1 |
| 13656 | alborozar | 1 |
| 13657 | alborotadamente | 1 |
| 13658 | albillo | 1 |
| 13659 | albedrío | 1 |
| 13660 | albaricoque | 1 |
| 13661 | albaicín | 1 |
| 13662 | albahaca | 1 |
| 13663 | alas | 1 |
| 13664 | alargamiento | 1 |
| 13665 | alameda | 1 |
| 13666 | alambrar | 1 |
| 13667 | alambicar | 1 |
| 13668 | alado | 1 |
| 13669 | alabarderos | 1 |
| 13670 | alabanza | 1 |
| 13671 | ajuste | 1 |
| 13672 | ajuntar | 1 |
| 13673 | ajardinar | 1 |
| 13674 | airear | 1 |
| 13675 | ahumado | 1 |
| 13676 | ahondar | 1 |
| 13677 | ahola | 1 |
| 13678 | ahitar | 1 |
| 13679 | ahijar | 1 |
| 13680 | agujerear | 1 |
| 13681 | aguirre | 1 |
| 13682 | aguinaldo | 1 |
| 13683 | aguileño | 1 |
| 13684 | agüero | 1 |
| 13685 | aguárdese | 1 |
| 13686 | aguárdate | 1 |
| 13687 | aguarda | 1 |
| 13688 | aguántate | 1 |
| 13689 | aguanta | 1 |
| 13690 | aguacero | 1 |
| 13691 | agrupar | 1 |
| 13692 | agricultura | 1 |
| 13693 | agregábansele | 1 |
| 13694 | agredir | 1 |
| 13695 | agraviar | 1 |
| 13696 | agravación | 1 |
| 13697 | agrado | 1 |
| 13698 | agradablemente | 1 |
| 13699 | agradabilísimo | 1 |
| 13700 | agotado | 1 |
| 13701 | agorar | 1 |
| 13702 | agonizar | 1 |
| 13703 | agobiar | 1 |
| 13704 | agitanar | 1 |
| 13705 | agenciar | 1 |
| 13706 | agarrotar | 1 |
| 13707 | agalla | 1 |
| 13708 | afortunar | 1 |
| 13709 | aforismo | 1 |
| 13710 | afluir | 1 |
| 13711 | afinado | 1 |
| 13712 | afiliar | 1 |
| 13713 | afilado | 1 |
| 13714 | afeite | 1 |
| 13715 | afeitada | 1 |
| 13716 | afección | 1 |
| 13717 | afanador | 1 |
| 13718 | adviértale | 1 |
| 13719 | advertía | 1 |
| 13720 | adversidad | 1 |
| 13721 | adventicio | 1 |
| 13722 | adúuultera | 1 |
| 13723 | adustez | 1 |
| 13724 | adúlteros | 1 |
| 13725 | adulón | 1 |
| 13726 | adulación | 1 |
| 13727 | adquirido | 1 |
| 13728 | adormilar | 1 |
| 13729 | adormidera | 1 |
| 13730 | adormecido | 1 |
| 13731 | adoptado | 1 |
| 13732 | adonis | 1 |
| 13733 | adonde | 1 |
| 13734 | adolecer | 1 |
| 13735 | adobar | 1 |
| 13736 | admisión | 1 |
| 13737 | admirábala | 1 |
| 13738 | adjetivo | 1 |
| 13739 | adivinanza | 1 |
| 13740 | adictoo | 1 |
| 13741 | adición | 1 |
| 13742 | adherido | 1 |
| 13743 | adeudar | 1 |
| 13744 | aderezo | 1 |
| 13745 | aderezar | 1 |
| 13746 | aderezado | 1 |
| 13747 | adepto | 1 |
| 13748 | adentros | 1 |
| 13749 | adela | 1 |
| 13750 | adán | 1 |
| 13751 | adamar | 1 |
| 13752 | ad | 1 |
| 13753 | acuñar | 1 |
| 13754 | acuéstese | 1 |
| 13755 | acuérdate | 1 |
| 13756 | acueducto | 1 |
| 13757 | acudimos | 1 |
| 13758 | acubilla | 1 |
| 13759 | actualmente | 1 |
| 13760 | activamente | 1 |
| 13761 | acta | 1 |
| 13762 | acrisolar | 1 |
| 13763 | acreditar | 1 |
| 13764 | acrecer | 1 |
| 13765 | acostumbrada | 1 |
| 13766 | acostáronle | 1 |
| 13767 | acostarme | 1 |
| 13768 | acostado | 1 |
| 13769 | acorazar | 1 |
| 13770 | acontecimiento | 1 |
| 13771 | aconséjele | 1 |
| 13772 | aconséjate | 1 |
| 13773 | acompañábanle | 1 |
| 13774 | acomodo | 1 |
| 13775 | acomodaticio | 1 |
| 13776 | acomodado | 1 |
| 13777 | acometida | 1 |
| 13778 | acometería | 1 |
| 13779 | acobardarme | 1 |
| 13780 | aclimatación | 1 |
| 13781 | aclaración | 1 |
| 13782 | aclamación | 1 |
| 13783 | acídulo | 1 |
| 13784 | acidez | 1 |
| 13785 | acicalar | 1 |
| 13786 | achicharrar | 1 |
| 13787 | achicar | 1 |
| 13788 | acetato | 1 |
| 13789 | acertijo | 1 |
| 13790 | acerqueme | 1 |
| 13791 | acerico | 1 |
| 13792 | acercósele | 1 |
| 13793 | acerado | 1 |
| 13794 | acéptelo | 1 |
| 13795 | acéptalo | 1 |
| 13796 | aceptación | 1 |
| 13797 | acentuación | 1 |
| 13798 | acémila | 1 |
| 13799 | acelerar | 1 |
| 13800 | acelerado | 1 |
| 13801 | aceitar | 1 |
| 13802 | acechador | 1 |
| 13803 | acebuche | 1 |
| 13804 | accionista | 1 |
| 13805 | accidentar | 1 |
| 13806 | acaudalado | 1 |
| 13807 | acatemos | 1 |
| 13808 | acatarrar | 1 |
| 13809 | acaparamiento | 1 |
| 13810 | acampar | 1 |
| 13811 | acaloradamente | 1 |
| 13812 | acaecer | 1 |
| 13813 | acacia | 1 |
| 13814 | acabose | 1 |
| 13815 | aburridísimo | 1 |
| 13816 | abstruso | 1 |
| 13817 | abstraerse | 1 |
| 13818 | abstraer | 1 |
| 13819 | abstinencia | 1 |
| 13820 | abstener | 1 |
| 13821 | absorción | 1 |
| 13822 | absolutista | 1 |
| 13823 | absoluta | 1 |
| 13824 | absolución | 1 |
| 13825 | abroñigal | 1 |
| 13826 | abriolo | 1 |
| 13827 | abriole | 1 |
| 13828 | abrigado | 1 |
| 13829 | abrevie | 1 |
| 13830 | abreviatura | 1 |
| 13831 | abre | 1 |
| 13832 | abovedado | 1 |
| 13833 | abotonar | 1 |
| 13834 | aborregado | 1 |
| 13835 | aborrecimiento | 1 |
| 13836 | aborrecido | 1 |
| 13837 | abonos | 1 |
| 13838 | abono | 1 |
| 13839 | abominar | 1 |
| 13840 | abolladura | 1 |
| 13841 | abogar | 1 |
| 13842 | abocose | 1 |
| 13843 | abochornar | 1 |
| 13844 | abigarrar | 1 |
| 13845 | abigarrado | 1 |
| 13846 | abiertamente | 1 |
| 13847 | aberración | 1 |
| 13848 | abejorro | 1 |
| 13849 | abejón | 1 |
| 13850 | abeja | 1 |
| 13851 | abdicar | 1 |
| 13852 | abatido | 1 |
| 13853 | abanicar | 1 |
| 13854 | abalorio | 1 |
| 13855 | abadesa | 1 |
|
|
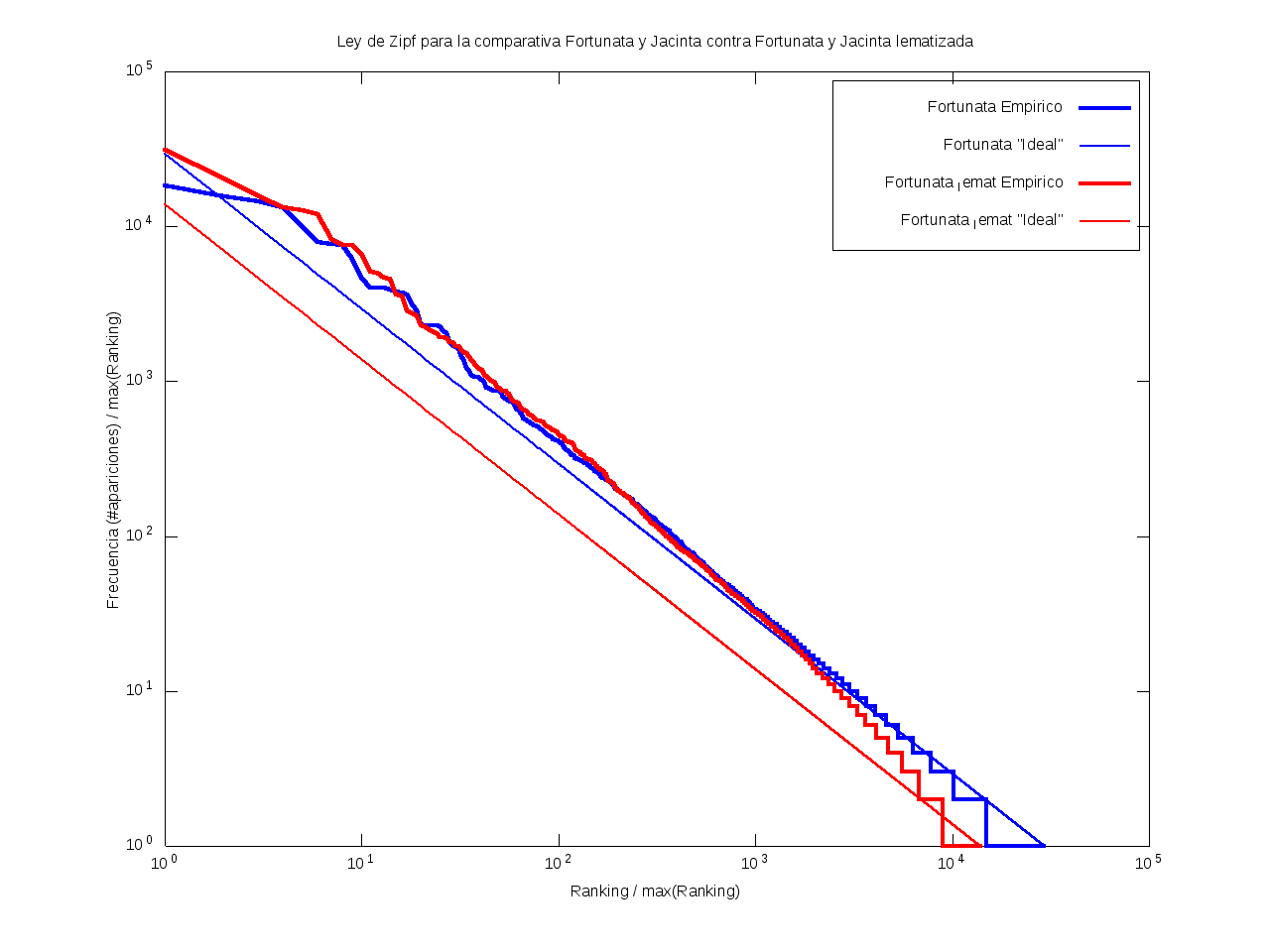
|
|
Mostrar todo
Recoger
|
Test de Dunning
El test de Dunning sirve para identificar las palabras distintivas de un texto.
En este caso lo utilizaremos para encontrar palabras distintivas de cada uno de los conjuntos que estamos comparando frente al otro.
Fórmula:
- 2 log(lambda) = 2 [ log L(p1,k1,n1)+log L(p2,k2,n2)-log L(p,k1,n1)-log L(p,k2,n2) ]
donde
L(p,k,n) = p^k * (1-p)^(n-k)
con
- ki = frecuencia (número de apariciones) de la palabra en el conjunto i.
- ni = número total de palabras del conjunto i.
- pi = probabilidad de la palabra en el conjunto i = ki/ni.
Para encontrar las palabras distintivas se enfrentará un conjunto (Fortunata) (conjunto 1)
contra el otro (Fortunata_lemat) (conjunto 2) y viceversa.
A continuación se muestra una lista de todas las palabras presentes en los textos,
ordenadas por su puntuación en la razón de verosimilitud, indicando de cuál de ellos son distintivas.
Haga click en la palabra para ver su definición según el diccionario de la RAE.
En este caso no tiene sentido aplicar el test de Dunning ya que los textos están en idiomas distintos.